

Web-Scraping ist eine automatisierte Technik zum Extrahieren und Sammeln großer Datenmengen aus Websites unter Verwendung verschiedener Tools oder Programme. Es wird häufig zum Extrahieren von HTML-Tabellen verwendet, die in Spalten und Zeilen organisierte Daten enthalten. Nach dem Sammeln können diese Daten analysiert oder für Forschungszwecke verwendet werden. Eine ausführlichere Anleitung finden Sie in diesem Artikel überHTML-Web-Scraping.
In diesem Tutorial erfahren Sie, wie Sie HTML-Tabellen mit Python von Websites scrapen können.
Voraussetzungen
Bevor Sie mit diesem Tutorial beginnen, müssen SiePython Version 3.8 oder neuer installierenundeine virtuelle Umgebung erstellen. Wenn Sie noch keine Erfahrung mit Web-Scraping mit Python haben, istdieser Artikelein hilfreicher Ausgangspunkt.
Nachdem Sie die Umgebung erstellt haben, installieren Sie die folgenden Python-Pakete:
- Requests
- Beautiful Soup
- pandas
Sie können die Pakete mit dem folgenden Befehl installieren:
pip install requests beautifulsoup4 pandas
Die Struktur von Webseiten verstehen
In diesem Tutorial werden Sie Daten von derWorldometer-Website scrapen. Diese Webseite enthält aktuelle Daten zu Ländern auf der ganzen Welt, einschließlich ihrer jeweiligen Bevölkerungszahlen für 2024:
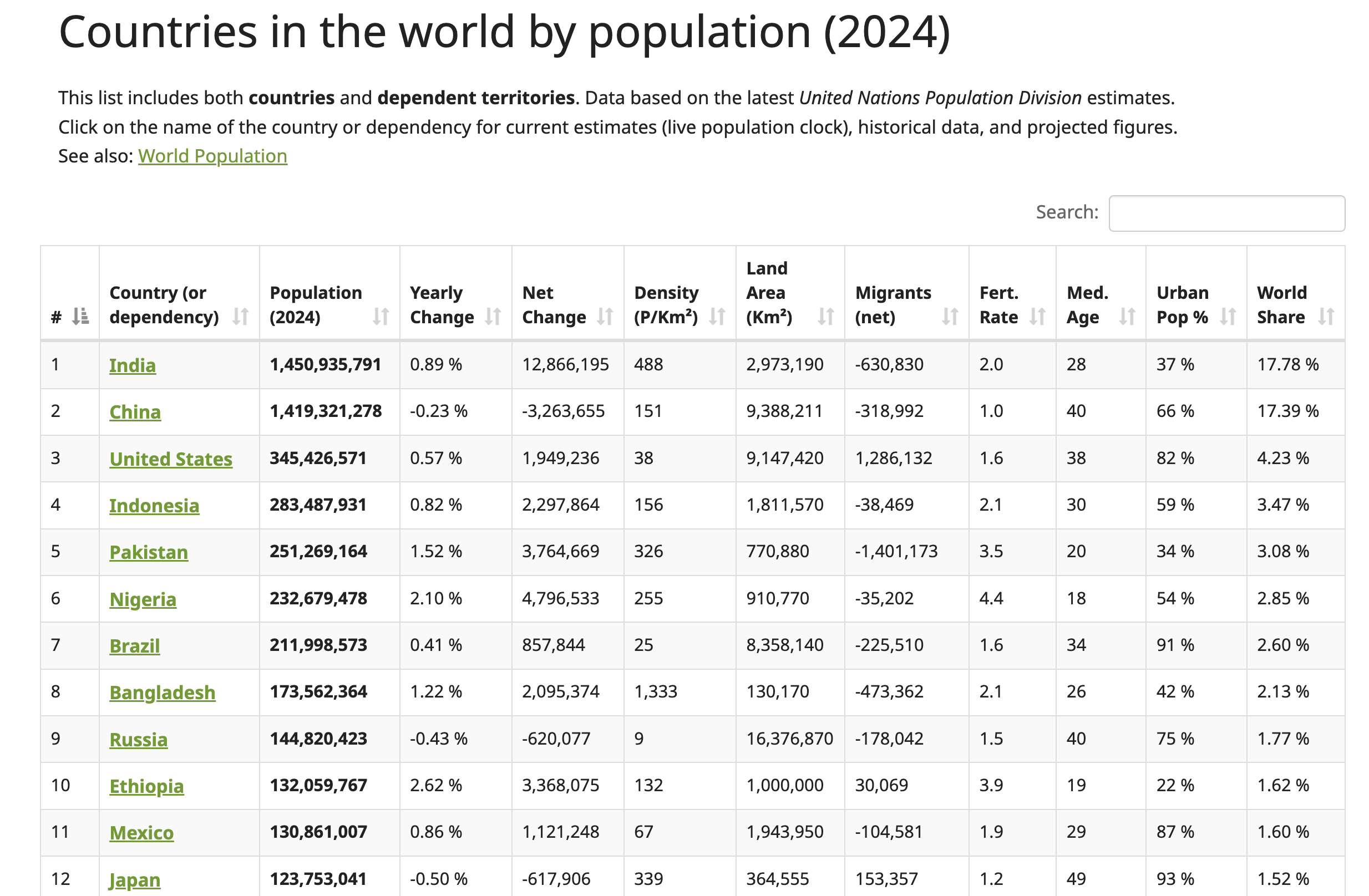
Um die HTML-Tabellenstruktur zu finden, klicken Sie mit der rechten Maustaste auf die Tabelle (siehe vorheriger Screenshot) und wählen Sie „Untersuchen“. Dadurch wird das Entwicklertools- Fenster geöffnet, in dem der HTML-Code der Seite angezeigt wird, wobei das ausgewählte Element hervorgehoben ist:
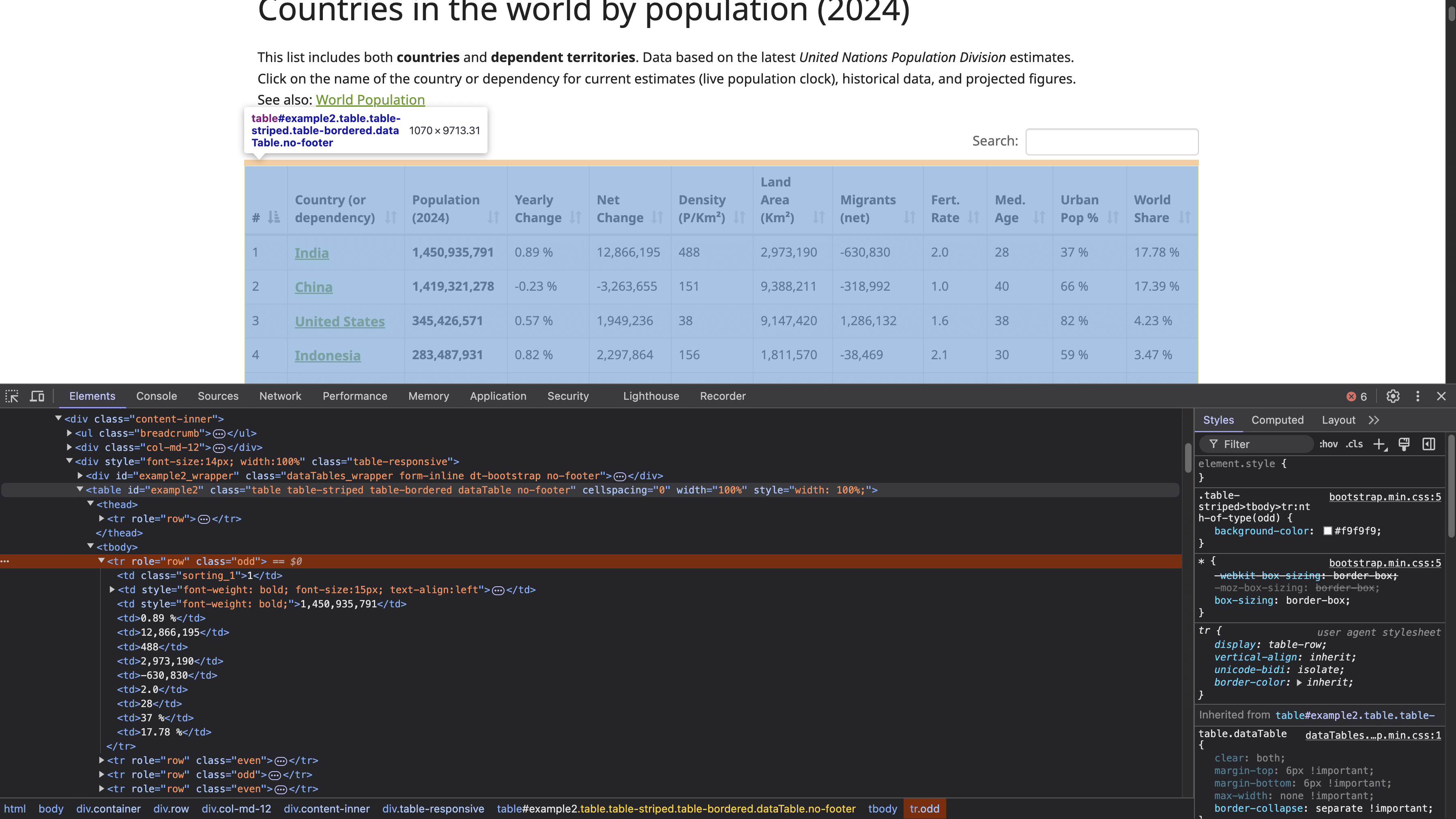
Das <table> -Tag mit der ID example2 definiert den Anfang der Tabellenstruktur. Diese Tabelle hat Kopfzeilen mit den <th> -Tags, und die Zeilen werden durch <tr> -Tags definiert, wobei jedes <tr> eine neue horizontale Zeile in der Tabelle darstellt. Innerhalb jedes <tr> erstellt das <td> -Tag einzelne Zellen innerhalb dieser Zeile, die die in jeder Zelle angezeigten Daten enthalten.
Hinweis: Bevor Sie mit dem Scraping beginnen, sollten Sie unbedingt die Datenschutzrichtlinien und Nutzungsbedingungen der Website lesen und einhalten, um sicherzustellen, dass Sie alle Einschränkungen hinsichtlich der Datennutzung und des automatisierten Zugriffs beachten.
Senden Sie eine HTTP-Anfrage, um auf die Webseite zuzugreifen
Um eine HTTP-Anfrage zu senden und auf die Webseite zuzugreifen, erstellen Sie eine Python-Datei (z. B. html_table_scraper.py) und importieren Sie die Pakete requests, BeautifulSoup und pandas:
# Pakete importieren
import requests
from bs4 import BeautifulSoup
import pandas as pd
Definieren Sie dann die URL der Webseite, die Sie scrapen möchten, und senden Sie eine GET-Anfrage an diese Webseite mit https://www.worldometers.info/world-population/population-by-country/:
# Anfrage an die Website senden, um den Seiteninhalt abzurufen
url = 'https://www.worldometers.info/world-population/population-by-country/'
Um zu überprüfen, ob die Antwort erfolgreich ist oder nicht, senden Sie eine Anfrage mit der Methode get() aus Requests:
# Den Inhalt der URL abrufen
response = requests.get(url)
# Den Status der Antwort überprüfen.
if response.status_code == 200:
print("Anfrage war erfolgreich!")
else:
print(f"Fehler: {response.status_code} - {response.text}")
Dieser Code sendet eine GET-Anfrage an eine bestimmte URL und überprüft dann den Status der Antwort. Eine 200- Antwort zeigt an, dass die Anfrage erfolgreich war.
Verwenden Sie den folgenden Befehl, um das Python-Skript in Ihrem Terminal auszuführen:
python html_table_scraper.py
Die Ausgabe sollte wie folgt aussehen:
Anfrage war erfolgreich!
Da die GET-Anfrage erfolgreich war, verfügen Sie nun über den HTML-Inhalt der gesamten Webseite, einschließlich der HTML-Tabelle.
Parsen Sie den HTML-Code mit Beautiful Soup
Beautiful Soup kann schlecht formatierte oder fehlerhafte HTML-Inhalte verarbeiten, was beim Web-Scraping häufig vorkommt. Hier verwenden Sie das Beautiful Soup-Paket, um Folgendes zu tun:
- Parsen Sie den HTML-Inhalt der Webseite, um die Tabelle mit den Bevölkerungsdaten zu finden.
- Sammeln Sie die Tabellenüberschriften.
- Sammeln Sie alle Daten, die in den Zeilen der Tabelle dargestellt sind.
Um die gesammelten Inhalte zu parsen, erstellen Sie ein Beautiful Soup-Objekt:
# Parsen Sie den HTML-Inhalt mit BeautifulSoup.
soup = BeautifulSoup(response.content, 'html.parser')
Suchen Sie als Nächstes das Tabellenelement im HTML-Code mit dem ID -Attribut „example2”. Diese Tabelle enthält die Bevölkerungszahlen der Länder im Jahr 2024:
# Die Tabelle mit den Bevölkerungsdaten suchen
table = soup.find('table', attrs={'id': 'example2'})
Tabellenkopfzeilen erfassen
Die Tabelle hat eine Kopfzeile, die sich in den HTML-Tags <thead> und <th> befindet. Verwenden Sie die Methode find() aus dem Beautiful Soup-Paket, um die Daten im Tag <thead> zu extrahieren, und die Methode find_all(), um alle Kopfzeilen zu sammeln:
# Sammeln Sie die Überschriften aus der Tabelle.
headers = []
# Suchen Sie die Überschriftenzeile innerhalb des Tags <thead>.
header_row = table.find('thead').find_all('th')
for th in header_row:
# Fügen Sie den Überschriftentext zur Liste „headers” hinzu.
headers.append(th.text.strip())
Dieser Code erstellt eine leere Python-Liste namens „headers“, sucht den HTML-Tag <thead>, um alle Kopfzeilen innerhalb der HTML-Tags <th> zu finden, und hängt dann jede gesammelte Kopfzeile an die Liste „headers“ an.
Tabellenzeilendaten sammeln
Um die Daten in jeder Zeile zu erfassen, erstellen Sie eine leere Python-Liste namens „data“, um die gescrapten Daten zu speichern:
# Initialisieren Sie eine leere Liste zum Speichern unserer Daten
data = []
Extrahieren Sie dann die Daten in jeder Zeile der Tabelle mit der Methode „find_all()“ und fügen Sie sie an die Python-Liste an:
# Durchlaufen Sie jede Zeile in der Tabelle (überspringen Sie die Kopfzeile)
for tr in table.find_all('tr')[1:]:
# Erstellen Sie eine Liste mit den Daten der aktuellen Zeile
row = []
# Alle Datenzellen in der aktuellen Zeile suchen
for td in tr.find_all('td'):
# Den Textinhalt der Zelle abrufen und zusätzliche Leerzeichen entfernen
cell_data = td.text.strip()
# Die bereinigten Zellendaten zur Zeilenliste hinzufügen
row.append(cell_data)
# Nachdem alle Zellen für diese Zeile abgerufen wurden, die Zeile zur Datenliste hinzufügen
data.append(row)
# Die gesammelten Daten zur einfacheren Verarbeitung in einen Pandas-DataFrame konvertieren
df = pd.DataFrame(data, columns=headers)
# Den DataFrame ausgeben, um die Anzahl der Zeilen und Spalten anzuzeigen
print(df.shape)
Dieser Code durchläuft alle <tr> -HTML-Tags, die in der Tabelle gefunden werden, beginnend mit der zweiten Zeile (die Kopfzeile wird übersprungen). Für jede Zeile (<tr>) wird eine leere Listenzeile erstellt, um die Daten aus den Zellen dieser Zeile zu speichern. Innerhalb der Zeile findet der Code alle <td> -HTML-Tags mit der Methode find_all(), die einzelne Datenzellen in der Zeile darstellen.
Für jedes HTML-Tag <td> extrahiert der Code den Textinhalt mit dem Attribut .textund wendet die Methode .strip() an, um alle führenden oder nachfolgenden Leerzeichen aus dem Text zu entfernen. Die bereinigten Zellendaten werden an die Zeilenliste angehängt. Nach der Verarbeitung aller Zellen in der aktuellen Zeile wird die gesamte Zeile an die Datenliste angehängt. Schließlich konvertieren Sie die gesammelten Daten in ein Pandas-DataFrame mit den durch die Headers-Liste definierten Spaltennamen und zeigen dann die Form der Daten an.
Das vollständige Python-Skript sollte wie folgt aussehen:
# Pakete importieren
import requests
from bs4 import BeautifulSoup
import pandas as pd
# Eine Anfrage an die Website senden, um den Seiteninhalt abzurufen
url = 'https://www.worldometers.info/world-population/population-by-country/'
# Den Inhalt der URL abrufen
response = requests.get(url)
# Überprüfen, ob die Anfrage erfolgreich war
if response.status_code == 200:
# HTML-Inhalt mit Beautiful Soup analysieren
soup = BeautifulSoup(response.content, 'html.parser')
# Tabelle mit Bevölkerungsdaten anhand ihrer ID suchen
table = soup.find('table', attrs={'id': 'example2'})
# Sammeln Sie die Kopfzeilen aus der Tabelle
headers = []
# Suchen Sie die Kopfzeilenreihe innerhalb des HTML-Tags <thead>
header_row = table.find('thead').find_all('th')
for th in header_row:
# Fügen Sie den Kopfzeilentext zur Liste der Kopfzeilen hinzu
headers.append(th.text.strip())
# Leere Liste initialisieren, um unsere Daten zu speichern
data = []
# Jede Zeile in der Tabelle durchlaufen (Kopfzeile überspringen)
for tr in table.find_all('tr')[1:]:
# Liste mit den Daten der aktuellen Zeile erstellen
row = []
# Alle Datenzellen in der aktuellen Zeile suchen
for td in tr.find_all('td'):
# Textinhalt der Zelle abrufen und zusätzliche Leerzeichen entfernen
cell_data = td.text.strip()
# Bereinigte Zellendaten zur Zeilenliste hinzufügen
row.append(cell_data)
# Nachdem alle Zellen für diese Zeile abgerufen wurden, die Zeile zu unserer Datenliste hinzufügen
data.append(row)
# Konvertieren Sie die gesammelten Daten in ein Pandas-DataFrame, um die Handhabung zu vereinfachen.
df = pd.DataFrame(data, columns=headers)
# Drucken Sie das DataFrame aus, um die gesammelten Daten anzuzeigen.
print(df.shape)
else:
print(f"Fehler: {response.status_code} - {response.text}")
Verwenden Sie den folgenden Befehl, um das Python-Skript in Ihrem Terminal auszuführen:
python html_table_scraper.py
Ihre Ausgabe sollte wie folgt aussehen:
(234,12)
Zu diesem Zeitpunkt haben Sie erfolgreich 234 Zeilen und 12 Spalten aus der HTML-Tabelle extrahiert.
Verwenden Sie als Nächstes die Methode head() aus pandas und print(), um die ersten zehn Zeilen der extrahierten Daten anzuzeigen:
print(df.head(10))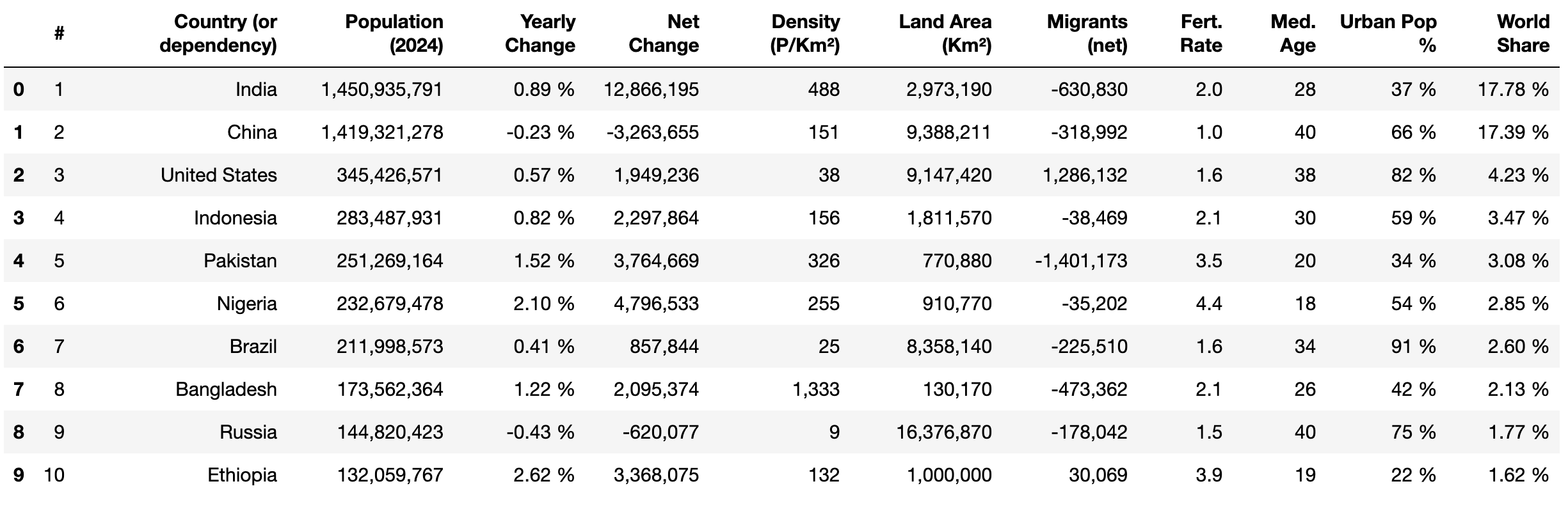
Daten bereinigen und strukturieren
Beim Scraping von Daten aus einer HTML-Tabelle ist es wichtig, die Daten zu bereinigen, um Konsistenz, Genauigkeit und eine ordnungsgemäße Verwendbarkeit für die Analyse sicherzustellen. Aus einer HTML-Tabelle extrahierte Rohdaten können verschiedene Probleme enthalten, wie fehlende Werte, Formatierungsprobleme, unerwünschte Zeichen oder falsche Datentypen. Diese Probleme können zu ungenauen Analysen und unzuverlässigen Ergebnissen führen. Eine ordnungsgemäße Bereinigung hilft bei der Standardisierung des Datensatzes und stellt sicher, dass er mit der für die Analyse vorgesehenen Struktur übereinstimmt.
In diesem Abschnitt werden die folgenden Datenbereinigungsaufgaben durchgeführt:
- Umbenennen von Spaltennamen
- Ersetzen fehlender Werte in den Zeilendaten
- Entfernen von Kommas und Konvertieren von Datentypen in das richtige Format
- Entfernen des Prozentzeichens (%) und Konvertieren der Datentypen in das richtige Format
- Ändern der Datentypen für numerische Spalten
Spaltennamen umbenennen
pandas verfügt über eine Methode namens rename(), mit der Sie den Namen einer bestimmten Spalte nach Belieben ändern können. Diese Methode ist nützlich, wenn Spaltennamen nicht aussagekräftig sind oder wenn Sie die Spaltennamen benutzerfreundlicher gestalten möchten.
Um eine bestimmte Spalte umzubenennen, übergeben Sie ein Wörterbuch an den Parameter columns, wobei die Schlüssel die aktuellen Spaltennamen und die Werte die neuen Namen sind, die Sie zuweisen möchten. Wenden Sie diese Methode an, um die folgenden Spaltennamen zu ändern:
#zuRangJährliche VeränderunginJährliche Veränderung %WeltmarktanteilinWeltmarktanteil %
# Spalten umbenennen
df.rename(columns={'#': 'Rank'}, inplace=True)
df.rename(columns={'Yearly Change': 'Yearly Change %'}, inplace=True)
df.rename(columns={'World Share': 'World Share %'}, inplace=True)
# Die ersten 5 Zeilen anzeigen
print(df.head())
Ihre Spalten sollten nun wie folgt aussehen:

Fehlende Werte ersetzen
Fehlende Werte in den Daten können Berechnungen wie Durchschnittswerte oder Summen beeinflussen und zu ungenauen Ergebnissen und falschen Erkenntnissen führen. Sie müssen diese Werte entfernen, ersetzen oder durch bestimmte Werte ersetzen, bevor Sie Berechnungen oder Analysen mit dem Datensatz durchführen.
Die Spalte „Urban Pop %” enthält derzeit fehlende Werte , die als N.A. gekennzeichnet sind . Ersetzen Sie N.A. durch 0 % mit der Methode replace() aus pandas wie folgt:
# Ersetzen Sie „N.A.” durch „0 %” in der Spalte „Urban Pop %”
df['Urban Pop %'] = df['Urban Pop %'].replace('N.A.', '0%')
Prozentzeichen entfernen und Datentypen konvertieren
Die Spalten „Yearly Change %”, „Urban Pop %” und „World Share %” enthalten numerische Werte, denen ein Prozentzeichen folgt (z. B. 37,0 %). Dies erschwert mathematische Operationen wie die Berechnung des Durchschnitts, des Maximums und der Standardabweichung für die Analyse.
Um dies zu beheben, können Sie die Methode replace() anwenden, um das %-Zeichen zu entfernen, und dann die Methode astype() anwenden, um sie für die Analyse in einen Float-Datentyp zu konvertieren:
# Prozentzeichen entfernen und in Float konvertieren
df['Jährliche Veränderung %'] = df['Jährliche Veränderung %'].replace('%', '', regex=True).astype(float)
df['Stadtbevölkerung %'] = df['Stadtbevölkerung %'].replace('%', '', regex=True).astype(float)
df['Weltanteil %'] = df['Weltanteil %'].replace('%', '', regex=True).astype(float)
# Die ersten 5 Zeilen anzeigen
df.head()
Dieser Code entfernt das %-Zeichen aus den Werten in den Spalten „Jährliche Veränderung %”, „Stadtbevölkerung %” und „Weltanteil %” mithilfe der Methode replace() mit einem regulären Ausdruck. Anschließend werden die bereinigten Werte mit astype(float) in einen Float-Datentyp konvertiert. Zuletzt werden die ersten fünf Zeilen des DataFrame mit df.head() angezeigt.
Ihre Ausgabe sollte wie folgt aussehen:

Kommas entfernen und Datentypen konvertieren
Derzeit enthalten die Spalten „Population (2024)”, „Net Change”, „Density (P/Km²)” und „Land Area (Km²)” sowie „Migrants (net) ” numerische Werte mit Kommas (z. B. 1.949.236). Dadurch ist es unmöglich, mathematische Operationen für die Analyse durchzuführen.
Um dies zu beheben, können Sie replace() und astype() anwenden, um Kommas zu entfernen und die Zahlen in den Datentyp „Ganzzahl” zu konvertieren:
# Kommas entfernen und in Ganzzahlen konvertieren
columns_to_convert = [
'Population (2024)', 'Net Change', 'Density (P/Km²)', 'Land Area (Km²)',
'Migrants (net)'
]
for column in columns_to_convert:
# Sicherstellen, dass die Spalte zunächst als Zeichenfolge behandelt wird
df[column] = df[column].astype(str)
# Kommas entfernen
df[column] = df[column].str.replace(',', '')
# In Ganzzahlen konvertieren
df[column] = df[column].astype(int)
Dieser Code definiert eine Liste, columns_to_convert, die die Namen der zu verarbeitenden Spalten enthält. Für jede Spalte in der Liste wird sichergestellt, dass die Spaltenwerte mit astype(str) als Zeichenfolgen behandelt werden. Anschließend werden alle Kommas aus den Werten mit str.replace(',', '') entfernt und die bereinigten Werte mit astype(int) in Ganzzahlen konvertiert, sodass die Werte für mathematische Operationen geeignet sind.
Ändern der Datentypen für numerische Spalten
Die Spalten „Rank”, „Med. Age” und „Fert. Rate” enthalten Daten, die als Objektdatentyp gespeichert sind, aber numerische Werte enthalten. Konvertieren Sie die Daten in diesen Spalten in Ganzzahl- oder Gleitkommadatentypen, um mathematische Operationen zu ermöglichen:
# In Ganzzahl- oder Gleitkommadatentypen und Ganzzahlen konvertieren
df['Rank'] = df['Rank'].astype(int)
df['Med. Age'] = df['Med. Age'].astype(int)
df['Fert. Rate'] = df['Fert. Rate'].astype(float)
Dieser Code konvertiert die Werte in den Spalten „Rank” und „Med. Age” in einen Integer-Datentyp und die Werte in „Fert. Rate” in einen Float-Datentyp.
Überprüfen Sie abschließend mit der Methode head(), ob die bereinigten Daten die richtigen Datentypen aufweisen:
print(df.head(10))
Ihre Ausgabe sollte wie folgt aussehen:
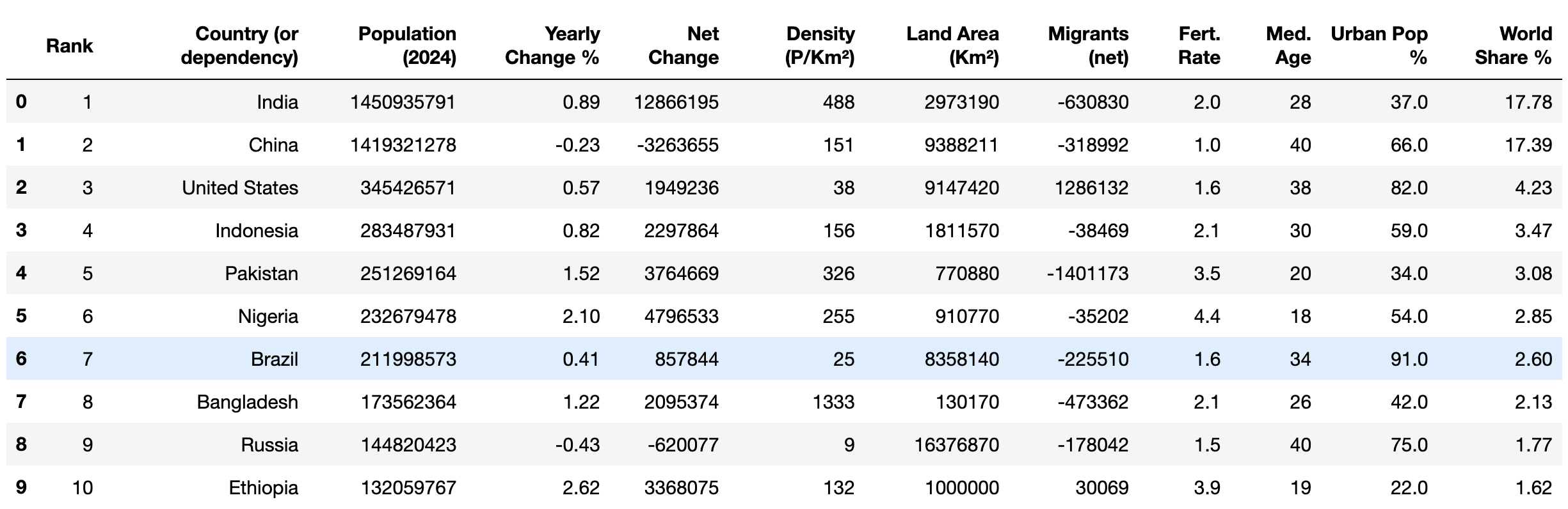
Nachdem die Daten nun bereinigt sind, können Sie verschiedene mathematische Operationen wieDurchschnitt und Modus sowie analytische Methoden wieKorrelation anwenden, um die Daten zu untersuchen.
Exportieren Sie die bereinigten Daten in eine CSV-Datei
Nach der Bereinigung Ihrer Daten ist es wichtig, die bereinigten Daten für die zukünftige Verwendung und Analyse zu speichern. Sie können die bereinigten Daten in eine CSV-Datei exportieren, wodurch Sie sie leicht mit anderen teilen oder mit verschiedenen unterstützten Tools und Software weiterverarbeiten/analysieren können.
Mit der Methode to_csv() in pandas können Sie die Daten aus einem DataFrame in eine CSV-Datei mit dem Namen world_population_by_country.csv exportieren:
# Speichern Sie die Daten in einer Datei.
filename = 'world_population_by_country.csv'
df.to_csv(filename, index=False)
Fazit
Mit dem Python-Paket Beautiful Soup können Sie HTML-Dokumente parsen und Daten aus einer HTML-Tabelle extrahieren. In diesem Artikel haben Sie gelernt, wie Sie Daten scrapen, bereinigen und in eine CSV-Datei exportieren können.
Obwohl dieses Tutorial recht einfach war, kann das Extrahieren von Daten aus komplexen Websites schwierig und zeitaufwändig sein. Beispielsweise erfordert die Arbeit mit paginierten HTML-Tabellen oder verschachtelten Strukturen, in denen Daten in über- und untergeordneten Elementen eingebettet sind, eine sorgfältige Analyse, um das Layout zu verstehen. Darüber hinaus können sich Website-Strukturen im Laufe der Zeit ändern, was eine kontinuierliche Pflege Ihres Codes und Ihrer Infrastruktur erforderlich macht.
Um Zeit zu sparen und die Arbeit zu vereinfachen, sollten Sie die Verwendung derBright Data Web Scraper API in Betracht ziehen. Dieses leistungsstarke Tool bietet eine vorgefertigte Scraping-Lösung, mit der Sie Daten aus komplexen Websites mit minimalen technischen Kenntnissen extrahieren können. Die API automatisiert die Datenerfassung und bewältigt Herausforderungen wie dynamische Inhalte, JavaScript-gerenderte Seiten und CAPTCHA-Verifizierung.
Melden Sie sich an und starten Sie Ihre kostenlose Testversion der Web Scraper API!





