

Google Travel sammelt aggregierte Reisedaten aus dem gesamten Internet für alle Arten von reisebezogenen Kategorien wie Flüge, Urlaubspakete und Hotelzimmer. Die Suche nach Hotels ist schwierig, und eine der größten Herausforderungen besteht darin, die Unmengen an werbefinanzierten Angeboten und zufälligen Zimmern zu sortieren, die für Ihre Suche einfach nicht in Frage kommen.
Wenn Sie kein Interesse am Scraping haben, sehen Sie sich unsere vorgefertigten Reisedatensätze an. Mit diesen Datensätzen übernehmen wir das Scraping für Sie. Wenn Sie bereit sind zum Scraping, lesen Sie weiter!
Voraussetzungen
Um Reisedaten zu scrapen, benötigen Sie Python und entweder Selenium, Requests oder AIOHTTP. Mit Selenium scrapen wir Hotelinformationen direkt aus Google Travel. Mit Requests und AIOHTTP verwenden wir die Booking.com-API von Bright Data.
Wenn Sie Selenium verwenden, müssen Sie sicherstellen, dass Sie Webdriver installiert haben. Wenn Sie mit Selenium nicht vertraut sind, können Sie sich diesen Leitfaden ansehen, um sich schnell damit vertraut zu machen.
Installieren Sie Selenium
pip install selenium
Installieren Sie Requests
pip install requests
AIOHTTP installieren
pip install aiohttp
Sobald Sie das Tool Ihrer Wahl installiert haben, können Sie loslegen.
Was Sie aus Google Travel extrahieren sollten
Wenn Sie sich dafür entscheiden, Google Travel manuell zu scrapen, müssen Sie sich zunächst ein besseres Verständnis davon verschaffen, welche Daten wir scrapen möchten. Alle unsere Hotelergebnisse sind in ein benutzerdefiniertes c-wiz-Element von Google Travel eingebettet.
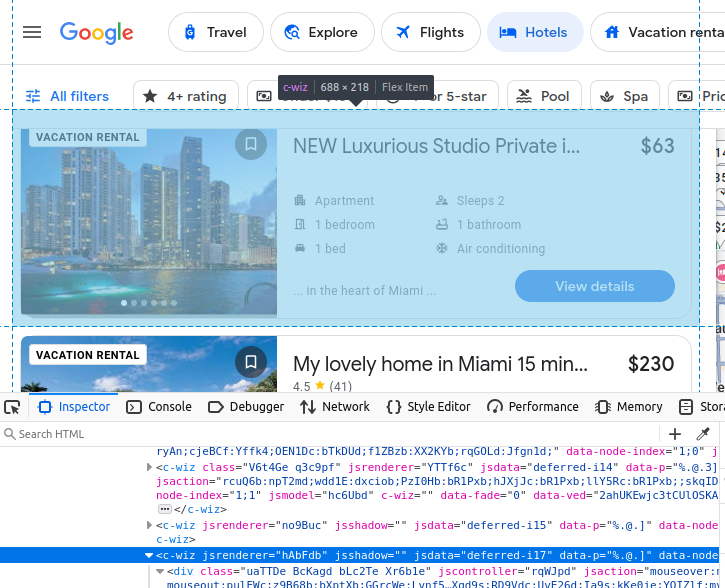
Es gibt jedoch viele c-wiz-Elemente auf der Seite. Jede unserer Hotelkarten enthält ein a-Element, das direkt von einem div-Element und diesem c-wiz-Element abstammt. Wir können einen CSS-Selektor schreiben, um alle a-Tags zu finden, die von diesen Elementen abstammen: c-wiz > div > a.
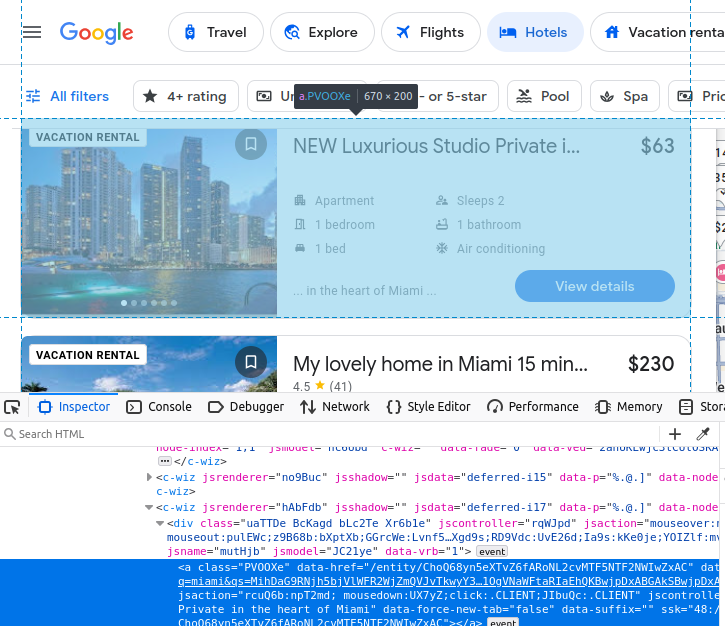
Der Name des Eintrags ist in einem h2 eingebettet.
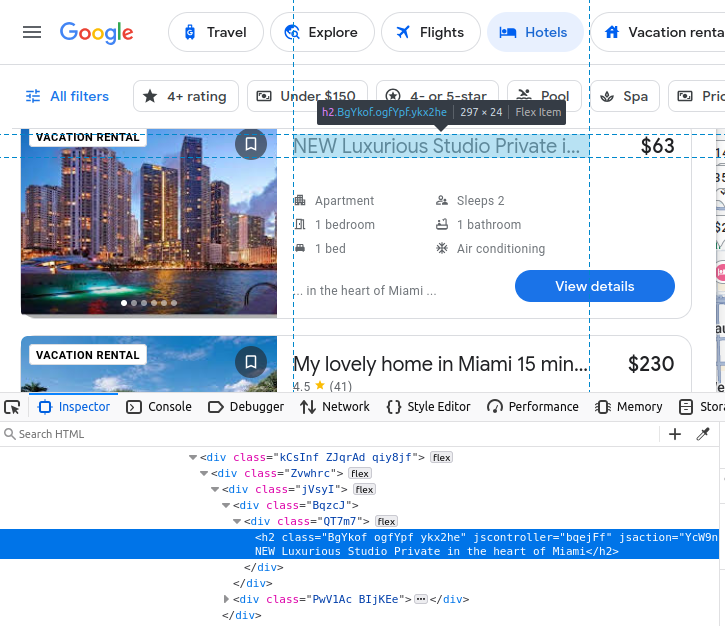
Unser Preis ist in einem span eingebettet.
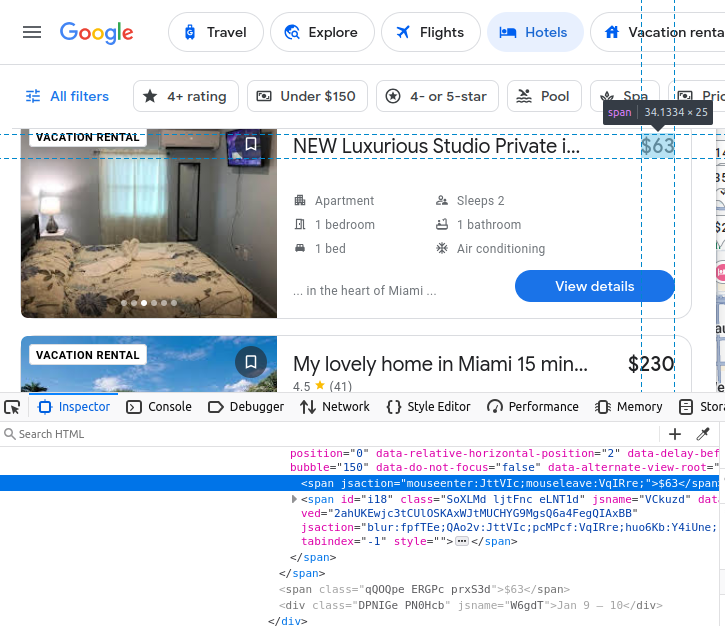
Unsere Annehmlichkeiten sind in li -Elementen (Liste) eingebettet.
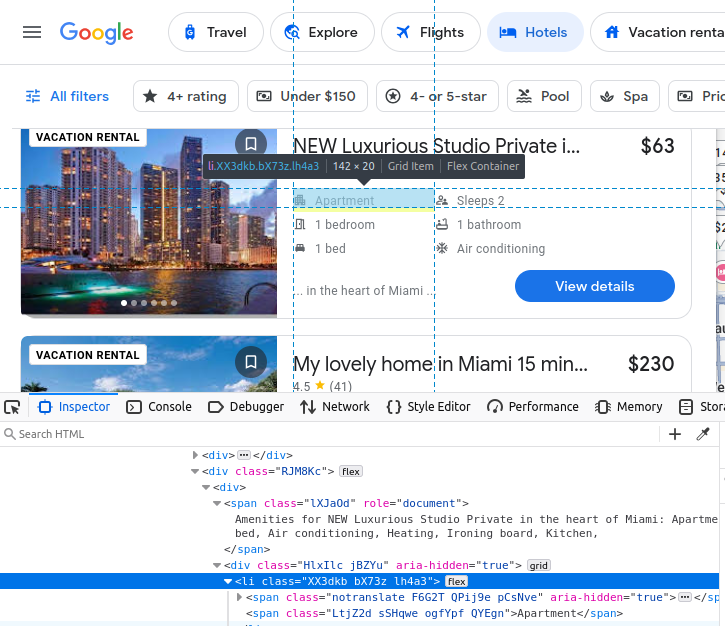
Nachdem wir unsere Hotelkarte gefunden haben, können wir alle oben genannten Daten daraus extrahieren.
Extrahieren der Daten mit Selenium
Das Extrahieren dieser Daten mit Selenium ist relativ einfach, sobald man weiß, wonach man suchen muss. Allerdings lädt Google Travel unsere Ergebnisse dynamisch, was den Vorgang etwas kompliziert macht, da er durch vorkonfigurierte Wartezeiten, Mausklicks und benutzerdefinierte Fenster zusammengehalten wird. Ohne das benutzerdefinierte Fenster werden Ihre Ergebnisse nicht richtig geladen.
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
import json
from time import sleep
OPTIONS = webdriver.ChromeOptions()
OPTIONS.add_argument("--headless")
OPTIONS.add_argument("--window-size=1920,1080")
def scrape_hotels(location, pages=5):
driver = webdriver.Chrome(options=OPTIONS)
actions = ActionChains(driver)
url = f"https://www.google.com/travel/search?q={location}"
driver.get(url)
done = False
found_hotels = []
page = 1
result_number = 1
while page <= pages:
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
sleep(5)
hotel_links = driver.find_elements(By.CSS_SELECTOR, "c-wiz > div > a")
print(f"-----------------PAGE {page}------------------")
print("GEFUNDENE ELEMENTE: ", len(hotel_links))
for hotel_link in hotel_links:
hotel_card = hotel_link.find_element(By.XPATH, "..")
try:
info = {}
info["url"] = hotel_link.get_attribute("href")
info["rating"] = 0.0
info["price"] = "n/a"
info["name"] = hotel_card.find_element(By.CSS_SELECTOR, "h2").text
price_holder = hotel_card.find_elements(By.CSS_SELECTOR, "span")
info["amenities"] = []
amenities_holders = hotel_card.find_elements(By.CSS_SELECTOR, "li")
for amenity in amenities_holders:
info["amenities"].append(amenity.text)
if "DEAL" in price_holder[0].text or "PRICE" in price_holder[0].text:
if price_holder[1].text[0] == "$":
info["price"] = price_holder[1].text
else:
info["price"] = price_holder[0].text
rating_holder = hotel_card.find_elements(By.CSS_SELECTOR, "span[role='img']")
if rating_holder:
info["rating"] = float(rating_holder[0].get_attribute("aria-label").split(" ")[0])
info["result_number"] = result_number
if info not in found_hotels:
found_hotels.append(info)
result_number+=1
except:
continue
print("Scraped Total:", len(found_hotels))
next_button = driver.find_elements(By.XPATH, "//span[text()='Next']")
if next_button:
print("Weiter-Button gefunden!")
sleep(1)
actions.move_to_element(next_button[0]).click().perform()
page+=1
sleep(5)
else:
done = True
driver.quit()
with open("scraped-hotels.json", "w") as file:
json.dump(found_hotels, file, indent=4)
if __name__ == "__main__":
PAGES = 2
scrape_hotels("miami", pages=PAGES)
- Zunächst erstellen wir eine Instanz von
ChromeOptions. Diese verwenden wir, um unsere Argumente--headlessund--window-size=1920,1080hinzuzufügen.- Ohne unsere benutzerdefinierte Fenstergröße werden die Ergebnisse nicht richtig geladen, sodass wir am Ende immer wieder dieselben Ergebnisse scrapen.
- Wenn wir den Browser starten, verwenden wir das Schlüsselwortargument
options=OPTIONS. Dadurch wird Chrome mit unseren benutzerdefinierten Optionen gestartet. ActionChains(driver)gibt uns eineActionChains-Instanz. Diese verwenden wir später in unserem Skript, um den Cursor auf die Schaltfläche„Weiter”zu bewegen und dann darauf zu klicken.- Wir verwenden eine
while-Schleife, um unsere Laufzeit zu begrenzen. Sobald das Scraping abgeschlossen ist, verlassen wir diese Schleife. hotel_links = driver.find_elements(By.CSS_SELECTOR, "c-wiz > div > a")liefert uns alle Hotel-Links auf der Seite. Wir finden ihre übergeordneten Elemente anhand ihres xpath:hotel_card = hotel_link.find_element(By.XPATH, "..").- Als Nächstes gehen wir alle einzelnen Daten durch, die wir uns zuvor angesehen haben, und extrahieren sie:
- url:
hotel_link.get_attribute("href") - name:
hotel_card.find_element(By.CSS_SELECTOR, "h2").text - Bei der Suche nach dem Preis gibt es manchmal zusätzliche Elemente in der Karte, wie z. B.
DEALundGREAT PRICE. Um sicherzustellen, dass wir immer den richtigen Preis erhalten, extrahieren wir dieSpan-Elementein einem Array. Wenn das Array diese Wörter enthält, nehmen wir das zweite Element (price_holder[1].text) anstelle des ersten (price_holder[0].text). - Wir verwenden die Methode
find_elements()auch bei der Suche nach der Bewertung. Wenn keine Bewertung vorhanden ist, geben wir einen Standardwert vonn/aan. hotel_card.find_elements(By.CSS_SELECTOR, „li”)liefert unsere Ausstattungshalter. Wir extrahieren jeden einzelnen anhand seinesTextattributs.
- url:
- Wir setzen diese Schleife fort, bis wir alle gewünschten Seiten gescrapt haben. Sobald wir unsere Daten haben, setzen wir
doneaufTrueund verlassen die Schleife. - Wir schließen den Browser und speichern alle gescrapten Daten mit
json.dump()in einer JSON-Datei.
Beim Scraping von Hotels aus Google Travel sind wir auf keine Blockierungsprobleme gestoßen, aber alles ist möglich. Sollten Sie auf Probleme stoßen, bieten wir sowohl Residential-Proxys als auch einen Proxy-integrierten Scraping-Browser an, um Ihnen zu helfen, alle Hindernisse zu überwinden.
Das Scraping dieser Ergebnisse mit Selenium ist sowohl mühsam als auch heikel, aber durchaus machbar.
Extrahieren Sie die Daten mit der Travel API von Bright Data
Manchmal möchten Sie sich nicht auf einen Scraper verlassen oder den ganzen Tag mit Selektoren und Locators verbringen. Das ist in Ordnung! Wir bieten verschiedene Arten von Reisedaten an. Sie können sogar Hoteldaten mit unserer Booking.com-API extrahieren. Sie müssen lediglich ein paar HTTP-Anfragen stellen. Wir kümmern uns um den Rest, damit Sie Ihren Tag fortsetzen können.
Anfragen
Der folgende Code richtet die Booking.com-API für Sie ein. Geben Sie einfach Ihren API-Schlüssel, den Reiseort, das Anreisedatum und das Abreisedatum ein. Zunächst wird eine Anfrage an die API gestellt, um die Daten zu generieren. Dann werden die Daten alle 10 Sekunden wiederholt überprüft, bis unser Bericht fertig ist. Sobald wir unsere Daten erhalten haben, speichern wir sie bequem in einer JSON-Datei.
import requests
import json
import time
def get_bookings(api_key, location, dates):
url = "https://api.brightdata.com/Datensätze/v3/trigger"
#booking.com dataset
dataset_id = "gd_m4bf7a917zfezv9d5"
endpoint = f"{url}?dataset_id={dataset_id}&include_errors=true"
auth_token = api_key
#
headers = {
"Authorization": f"Bearer {auth_token}",
"Content-Type": "application/json"
}
payload = [
{
"url": "https://www.booking.com",
"location": location,
"check_in": dates["check_in"],
"check_out": dates["check_out"],
"adults": 2,
"rooms": 1
}
]
response = requests.post(endpoint, headers=headers, json=payload)
if response.status_code == 200:
print("Anfrage erfolgreich. Antwort:")
print(json.dumps(response.json(), indent=4))
return response.json()["snapshot_id"]
else:
print(f"Fehler: {response.status_code}")
print(response.text)
def poll_and_retrieve_snapshot(api_key, snapshot_id, output_file="snapshot-data.json"):
#create the snapshot url
snapshot_url = f"https://api.brightdata.com/Datensätze/v3/snapshot/{snapshot_id}?format=json"
headers = {
"Authorization": f"Bearer {api_key}"
}
print(f"Polling snapshot for ID: {snapshot_id}...")
while True:
response = requests.get(snapshot_url, headers=headers)
if response.status_code == 200:
print("Snapshot ist bereit. Herunterladen...")
snapshot_data = response.json()
#Snapshot in eine neue JSON-Datei schreiben
with open(output_file, "w", encoding="utf-8") as file:
json.dump(snapshot_data, file, indent=4)
print(f"Snapshot saved to {output_file}")
break
elif response.status_code == 202:
print("Snapshot is not ready yet. Wiederholung in 10 Sekunden...")
else:
print(f"Fehler: {response.status_code}")
print(response.text)
break
time.sleep(10)
if __name__ == "__main__":
API_KEY = "your-bright-data-api-key"
LOCATION = "Miami"
CHECK_IN = "2026-02-01T00:00:00.000Z"
CHECK_OUT = "2026-02-02T00:00:00.000Z"
DATES = {
"check_in": CHECK_IN,
"check_out": CHECK_OUT
}
snapshot_id = get_bookings(API_KEY, LOCATION, DATES)
poll_and_retrieve_snapshot(API_KEY, snapshot_id)
get_bookings()benötigt IhrenAPI_KEY,LOCATIONundDATES. Anschließend wird eine Anfrage für die Daten gestellt und diesnapshot_idzurückgegeben.- Die
snapshot_idist sehr wichtig. Wir benötigen sie, um den Snapshot abzurufen. - Nachdem die
snapshot_idgeneriert wurde, überprüftpoll_and_retrieve_snapshot()alle 10 Sekunden, ob die Daten bereitstehen. - Sobald die Daten bereit sind, speichern wir sie mit
json.dump()in einer JSON-Datei.
Wenn Sie den Code ausführen, sollte in Ihrem Terminal etwa Folgendes angezeigt werden.
Anfrage erfolgreich. Antwort:
{
"snapshot_id": "s_m5moyblm1wikx4ntot"
}
Abfrage des Snapshots für ID: s_m5moyblm1wikx4ntot...
Der Snapshot ist noch nicht bereit. Wiederholung in 10 Sekunden...
Snapshot ist noch nicht bereit. Wiederholung in 10 Sekunden...
Snapshot ist noch nicht bereit. Wiederholung in 10 Sekunden...
Snapshot ist noch nicht bereit. Wiederholung in 10 Sekunden...
Snapshot ist bereit. Herunterladen...
Snapshot gespeichert in snapshot-data.json
Dann erhalten Sie eine JSON-Datei voller Objekte wie diese.
{
"input": {
"url": "https://www.booking.com",
"location": "Miami",
"check_in": "2026-02-01T00:00:00.000Z",
"check_out": "2026-02-02T00:00:00.000Z",
"adults": 2,
"rooms": 1
},
„url“: „https://www.booking.com/hotel/us/ramada-plaze-by-wyndham-marco-polo-beach-resort.html?checkin=2025-02-01&checkout=2025-02-02&group_adults=2&no_rooms=1&group_children=“,
„location“: „Miami“,
„check_in“: „2026-02-01T00:00:00.000Z“,
„check_out“: „2026-02-02T00:00:00.000Z“,
„adults”: 2,
„children”: null,
„rooms”: 1,
„id”: „55989”,
„title“: „Ramada Plaza by Wyndham Marco Polo Beach Resort“,
„address“: „19201 Collins Avenue“,
„city“: „Sunny Isles Beach (Florida)“,
„review_score“: 6,2,
„review_count“: „1788“,
„image”: „https://cf.bstatic.com/xdata/images/hotel/square600/414501733.webp?k=4c14cb1ec5373f40ee83d901f2dc9611bb0df76490f3673f94dfaae8a39988d8&o=",
„final_price“: 217,
„original_price“: 217,
„currency“: „USD“,
„tax_description”: null,
„nb_livingrooms”: 0,
„nb_kitchens”: 0,
„nb_bedrooms”: 0,
„nb_all_beds”: 2,
„full_location”: {
„description”: „Dies ist die Luftlinie auf der Karte. Die tatsächliche Entfernung kann variieren.“
„main_distance“: „11,4 Meilen vom Stadtzentrum entfernt“
„display_location“: „Miami Beach“
„beach_distance“: „Direkt am Strand“
„nearby_beach_names“: []
},
"no_prepayment": false,
"free_cancellation": true,
"property_sustainability": {
"is_sustainable": false,
"level_id": "L0",
"facilities": [
"436",
„490”,
„492”,
„496”,
„506”
]
},
„timestamp”: „2026-01-07T16:43:24.954Z”
},
AIOHTTP
Mit AIOHTTP können wir diesen Prozess erheblich beschleunigen. Wir können tatsächlich mehrere Datensätze gleichzeitig auslösen, abfragen und herunterladen. Der folgende Code baut auf unseren Konzepten aus dem obigen Requests-Beispiel auf, verwendet jedoch stattdessen die leistungsstarke Funktion aiohttp.ClientSession(), um mehrere Anfragen asynchron zu stellen.
import aiohttp
import asyncio
import json
async def get_bookings(api_key, location, dates):
url = "https://api.brightdata.com/Datensätze/v3/trigger"
dataset_id = "gd_m4bf7a917zfezv9d5"
endpoint = f"{url}?dataset_id={dataset_id}&include_errors=true"
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
payload = [
{
"url": "https://www.booking.com",
"location": location,
"check_in": dates["check_in"],
"check_out": dates["check_out"],
"adults": 2,
"rooms": 1
}
]
async with aiohttp.ClientSession(headers=headers) as session:
async with session.post(endpoint, json=payload) as response:
if response.status == 200:
response_data = await response.json()
print(f"Anfrage erfolgreich für Standort: {location}. Antwort:")
print(json.dumps(response_data, indent=4))
return response_data["snapshot_id"]
else:
print(f"Fehler für Standort: {location}. Status: {response.status}")
print(await response.text())
return None
async def poll_and_retrieve_snapshot(api_key, snapshot_id, output_file):
snapshot_url = f"https://api.brightdata.com/Datensätze/v3/snapshot/{snapshot_id}?format=json"
headers = {
"Authorization": f"Bearer {api_key}"
}
print(f"Polling snapshot for ID: {snapshot_id}...")
async with aiohttp.ClientSession(headers=headers) as session:
while True:
async with session.get(snapshot_url) as response:
if response.status == 200:
print(f"Snapshot für {output_file} ist bereit. Herunterladen...")
snapshot_data = await response.json()
# Snapshot-Daten in einer Datei speichern
with open(output_file, "w", encoding="utf-8") as file:
json.dump(snapshot_data, file, indent=4)
print(f"Snapshot in {output_file} gespeichert")
break
elif response.status == 202:
print(f"Snapshot für {output_file} ist noch nicht fertig. Wiederholung in 10 Sekunden...")
else:
print(f"Fehler beim Abrufen des Snapshots für {output_file}. Status: {response.status}")
print(await response.text())
break
await asyncio.sleep(10)
async def process_location(api_key, location, dates):
snapshot_id = await get_bookings(api_key, location, dates)
if snapshot_id:
output_file = f"snapshot-{location.replace(' ', '_').lower()}.json"
await poll_and_retrieve_snapshot(api_key, snapshot_id, output_file)
locations = ["Miami", "Key West"]
dates = {
"check_in": "2026-02-01T00:00:00.000Z",
"check_out": "2026-02-02T00:00:00.000Z"
}
# Alle Standorte parallel verarbeiten
tasks = [process_location(api_key, location, dates) for location in locations]
await asyncio.gather(*tasks)
if __name__ == "__main__":
asyncio.run(main())
- Sowohl
get_bookings()als auchpoll_and_retrieve_snapshot()verwenden nun unseraiohttp.ClientSession-Objekt, um asynchrone Anfragen an den Server zu erstellen. process_location()wird verwendet, um alle Daten für einen Standort zu verarbeiten.main()ermöglicht es uns,process_location()für alle Standorte gleichzeitig aufzurufen.
Mit AIOHTTP können Sie mehrere Datensätze gleichzeitig auslösen, abfragen und herunterladen. Auf diese Weise müssen Sie nicht unnötig auf die Fertigstellung eines Berichts warten, bevor Sie den nächsten erstellen können.
Sehen Sie sich die Ausgabe an. Wie Sie sehen können, lösen wir beide Berichte aus. Dann laden wir einen Bericht herunter, während wir noch auf den anderen warten. In großem Maßstab sparen Sie dadurch unglaublich viel Zeit.
Anfrage für Standort erfolgreich: Miami. Antwort:
{
"snapshot_id": "s_m5mtmtv62hwhlpyazw"
}
Anfrage für Standort erfolgreich: Key West. Antwort:
{
"snapshot_id": "s_m5mtmtv72gkkgxvdid"
}
Abfrage des Snapshots für ID: s_m5mtmtv62hwhlpyazw...
Abfrage des Snapshots für ID: s_m5mtmtv72gkkgxvdid...
Der Snapshot für snapshot-miami.json ist noch nicht bereit. Wiederholung in 10 Sekunden...
Der Snapshot für snapshot-key_west.json ist noch nicht bereit. Wiederholung in 10 Sekunden...
Snapshot für snapshot-key_west.json ist noch nicht bereit. Wiederholung in 10 Sekunden...
Snapshot für snapshot-miami.json ist noch nicht bereit. Wiederholung in 10 Sekunden...
Snapshot für snapshot-key_west.json ist noch nicht bereit. Wiederholung in 10 Sekunden...
Snapshot für snapshot-miami.json ist noch nicht bereit. Wiederholung in 10 Sekunden...
Snapshot für snapshot-miami.json ist bereit. Herunterladen...
Snapshot für snapshot-key_west.json ist noch nicht bereit. Wiederholung in 10 Sekunden...
Snapshot gespeichert in snapshot-miami.json
Snapshot für snapshot-key_west.json ist noch nicht bereit. Wiederholung in 10 Sekunden...
Der Snapshot für snapshot-key_west.json ist noch nicht fertig. Wiederholung in 10 Sekunden...
Der Snapshot für snapshot-key_west.json ist noch nicht fertig. Wiederholung in 10 Sekunden...
Der Snapshot für snapshot-key_west.json ist fertig. Herunterladen...
Snapshot in snapshot-key_west.json gespeichert
Alternative Lösungen von Bright Data
Neben unseren leistungsstarken Web-Scraper-APIs bietet Bright Data gebrauchsfertige Datensätze, die auf unterschiedliche Anforderungen zugeschnitten sind. Zu unseren gefragtesten Reisedatensätzen gehören:
- Hotel-Datensätze
- Expedia-Datensätze
- Tourismus-Datensätze
- Booking.com-Datensätze
- TripAdvisor-Datensätze
Mit Bright Data können Sie zwischen vollständig verwalteten oder selbst verwalteten benutzerdefinierten Datensätzen wählen, sodass Sie Daten von jeder öffentlichen Website extrahieren und genau an Ihre Anforderungen anpassen können.
Fazit
Beim Web-Scraping können Sie eine Fundgrube an Hotelinformationen von Google Travel finden. Ganz gleich, ob Sie das DIY-Modell mit Selenium bevorzugen oder einfach nur schnelle und bequeme Ergebnisse mit der Booking.com-API erzielen möchten, Sie können diese Daten nutzen, um wirklich wertvolle Erkenntnisse zu gewinnen. Ganz gleich, ob Sie historische Preise analysieren oder einfach nur effizient ein Zimmer buchen möchten, Sie haben gerade Ihrem Tech-Stack eine weitere nützliche Fähigkeit hinzugefügt!
Melden Sie sich jetzt an, um die Produkte von Bright Data kostenlos zu testen.






