

Etsy ist eine Website, die bekanntermaßen schwer zu scrapen ist. Sie verwendet eine Vielzahl von Blockierungstaktiken und verfügt über eines der ausgefeiltesten Bot-Blockierungssysteme im Internet. Von detaillierten Header-Analysen bis hin zu einer scheinbar endlosen Flut von CAPTCHAs ist Etsy der Fluch aller Web-Scraper weltweit. Wenn Sie diese Hindernisse überwinden können, ist Etsy eine relativ leicht zu scrapen Website.
Wenn Sie Etsy scrapen können, erhalten Sie Zugriff auf eine Fülle von Daten zu kleinen Unternehmen aus einem der größten Marktplätze, die das Internet zu bieten hat. Folgen Sie uns noch heute, und Sie werden Etsy in kürzester Zeit wie ein Profi scrapen. Wir werden lernen, wie man alle folgenden Seitentypen von Etsy scrapt.
- Suchergebnisse
- Produktseiten
- Shop-Seiten
Erste Schritte
Python Requests und BeautifulSoup sind die Tools unserer Wahl für dieses Tutorial. Sie können sie mit den folgenden Befehlen installieren. Mit Requests können wir HTTP-Anfragen stellen und mit den Servern von Etsy kommunizieren. BeautifulSoup gibt uns die Möglichkeit, die Webseiten mit Python zu parsen. Wir empfehlen Ihnen, zunächst unseren Leitfaden zur Verwendung von BeautifulSoup für das Web-Scraping zu lesen.
Requests installieren
pip install requests
BeautifulSoup installieren
pip install beautifulsoup4
Was Sie von Etsy scrapen sollten
Wenn Sie eine Etsy-Seite untersuchen, könnten Sie sich in einem unübersichtlichen Netz verschachtelter Elemente verfangen. Wenn Sie wissen, wo Sie suchen müssen, ist dies jedoch leicht zu überwinden. Die Seiten von Etsy verwenden JSON-Daten, um die Seite im Browser darzustellen. Wenn Sie die JSON-Daten finden, können Sie alle Daten finden, die zum Erstellen der Seite verwendet wurden, ohne sich zu tief in den HTML-Code des Dokuments vertiefen zu müssen.
Suchergebnisse
Die Suchseiten von Etsy enthalten eine Reihe von JSON-Objekten. Wenn Sie sich das Bild unten ansehen, finden Sie alle diese Daten in einem Skriptelement mit dem Typ „application/ld+json”. Wenn Sie genau hinschauen, enthalten diese JSON-Daten ein Array namens „itemListElement”. Wenn wir dieses Array extrahieren können, erhalten wir alle Daten, die zum Erstellen der Seite verwendet wurden.
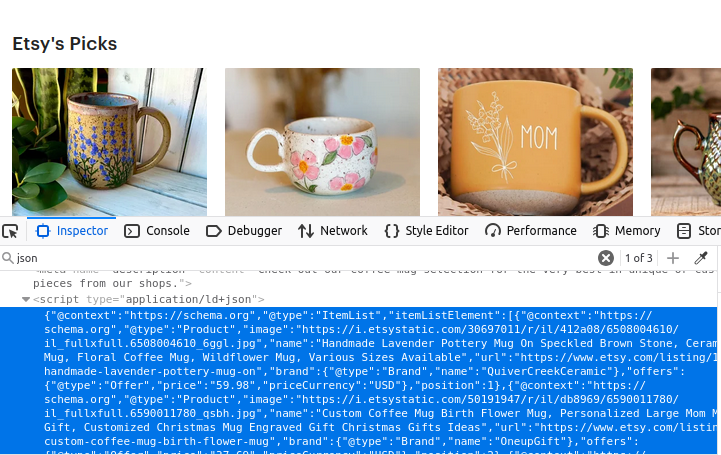
Produktinformationen
Die Produktseiten unterscheiden sich nicht wesentlich davon. Schauen Sie sich das Bild unten an: Auch hier haben wir wieder ein Skript-Tag mit type="application/ld+json". Dieses Tag enthält alle Informationen, die zum Erstellen der Produktseite verwendet wurden.
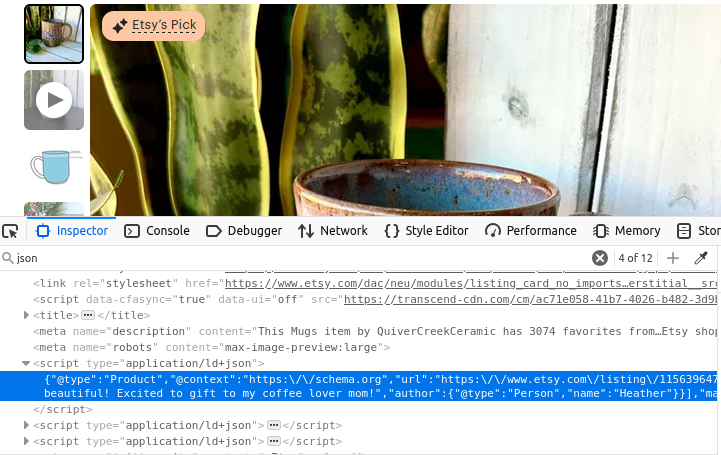
Shops
Wie Sie wahrscheinlich schon vermutet haben, sind auch unsere Shop-Seiten auf die gleiche Weise aufgebaut. Suchen Sie das erste Skript-Objekt auf der Seite mit type="application/ld+json" und Sie haben Ihre Daten.
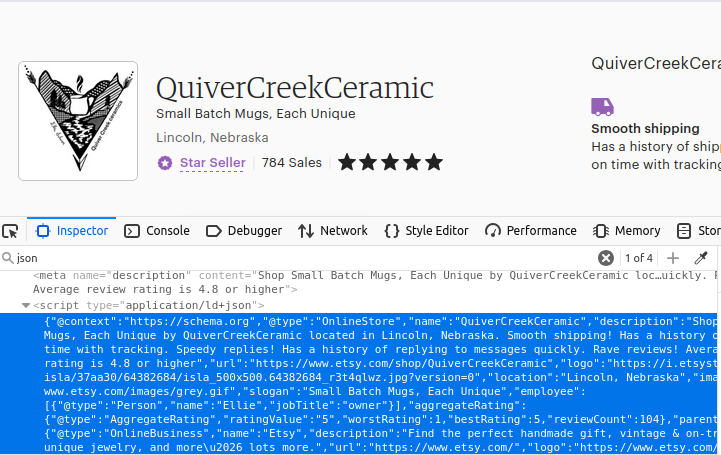
Wie man Etsy mit Python scrapt
Nun gehen wir alle erforderlichen Komponenten durch, die wir erstellen müssen. Wie bereits erwähnt, setzt Etsy verschiedene Taktiken ein, um uns den Zugriff auf die Website zu verwehren. Wir verwenden Web Unlocker als Schweizer Taschenmesser für diese Blockaden. Es verwaltet nicht nur Proxy-Verbindungen für uns, sondern bietet auch eine CAPTCHA-Lösung für alle CAPTCHAs, die uns in den Weg kommen. Sie können es gerne ohne Proxy versuchen, aber in unseren ersten Tests konnten wir die Blockiersysteme von Etsy ohne Web Unlocker nicht umgehen.
Sobald Sie eine Web Unlocker-Instanz haben, können Sie Ihre Proxy-Verbindung einrichten, indem Sie ein einfaches Dict erstellen. Wir verwenden das SSL-Zertifikat von Bright Data, um sicherzustellen, dass unsere Daten während der Übertragung verschlüsselt bleiben. Im folgenden Code geben wir den Pfad zu unserem SSL-Zertifikat an und verwenden dann unseren Benutzernamen, den Namen der Zone und das Passwort, um die Proxy-URL zu erstellen. Unsere Proxys werden durch die Erstellung einer benutzerdefinierten URL aufgebaut, die alle unsere Anfragen über einen der Proxy-Dienste von Bright Data weiterleitet.
path_to_cert = "bright-data-cert.crt"
proxies = {
'http': 'http://brd-customer-<IHR-BENUTZERNAME>-zone-<IHR-ZONENNAME>:<IHR-PASSWORT>@brd.superproxy.io:33335',
'https': 'http://brd-customer-<IHR-BENUTZERNAME>-zone-<IHR-ZONENNAME>:<IHR-PASSWORT>@brd.superproxy.io:33335'
}
Suchergebnisse
Um unsere Suchergebnisse zu extrahieren, senden wir eine Anfrage über unsere Proxys. Anschließend verwenden wir BeautifulSoup, um das eingehende HTML-Dokument zu parsen. Wir finden die Daten innerhalb des Skript-Tags und laden sie als JSON-Objekt. Dann geben wir das Feld „itemListElement” aus dem JSON zurück.
def etsy_search(keyword):
encoded_keyword = urlencode({"q": keyword})
url = f"https://www.etsy.com/search?{encoded_keyword}"
response = requests.get(url, proxies=proxies, verify=path_to_cert)
soup = BeautifulSoup(response.text, "html.parser")
script = soup.find("script", attrs={"type": "application/ld+json"})
full_json = json.loads(script.text)
return full_json["itemListElement"]
Produktinformationen
Unsere Produktinformationen werden im Grunde genommen auf die gleiche Weise extrahiert. Der einzige wirkliche Unterschied besteht darin, dass itemListElement fehlt. Dieses Mal verwenden wir unsere listing_id, um unsere URL zu erstellen, und extrahieren das gesamte JSON-Objekt.
def etsy_product(listing_id):
url = f"https://www.etsy.com/listing/{listing_id}/"
response = requests.get(url, proxies=proxies, verify=path_to_cert)
soup = BeautifulSoup(response.text, "html.parser")
script = soup.find("script", attrs={"type": "application/ld+json"})
return json.loads(script.text)
Shops
Beim Extrahieren von Shops folgen wir dem gleichen Modell, das wir bei Produkten verwendet haben. Wir verwenden den shop_name, um die URL zu erstellen. Sobald wir die Antwort erhalten haben, suchen wir die JSON-Datei, laden sie als JSON und geben die extrahierten Seitendaten zurück.
def etsy_shop(shop_name):
url = f"https://www.etsy.com/shop/{shop_name}"
response = requests.get(url, proxies=proxies, verify=path_to_cert)
soup = BeautifulSoup(response.text, "html.parser")
script = soup.find("script", attrs={"type": "application/ld+json"})
return json.loads(script.text)
Speichern der Daten
Sobald wir unsere Daten extrahiert haben, liegen sie in einer übersichtlichen JSON-Struktur vor. Wir können unsere Ausgabe mit Hilfe der grundlegenden Dateiverwaltung von Python und json.dumps() in eine Datei schreiben. Wir schreiben sie mit indent=4, damit sie übersichtlich und lesbar ist, wenn Menschen die Datei ansehen.
with open("products.json", "w") as file:
json.dump(products, file, indent=4)
Alles zusammenfügen
Nachdem wir nun wissen, wie wir unsere Teile erstellen, fügen wir alles zusammen. Der folgende Code verwendet die Funktionen, die wir gerade geschrieben haben, und gibt unsere gewünschten Daten im JSON-Format zurück. Anschließend schreiben wir jedes dieser Objekte in seine eigene JSON-Datei.
import requests
import json
from bs4 import BeautifulSoup
from urllib.parse import urlencode
# Proxy- und Zertifikateinrichtung (HARD-CODED CREDENTIALS)
path_to_cert = "bright-data-cert.crt"
proxies = {
'http': 'http://brd-customer-<IHR-BENUTZERNAME>-zone-<IHR-ZONENNAME>:<IHR-PASSWORT>@brd.superproxy.io:22225',
'https': 'http://brd-customer-<IHR-BENUTZERNAME>-zone-<IHR-ZONENNAME>:<IHR-PASSWORT>@brd.superproxy.io:22225'
}
def fetch_etsy_data(url):
"""JSON-LD-Daten von einer Etsy-Seite abrufen und analysieren."""
try:
response = requests.get(url, proxies=proxies, verify=path_to_cert)
response.raise_for_status()
except requests.exceptions.RequestException as e:
print(f"Request failed: {e}")
return None
soup = BeautifulSoup(response.text, "html.parser")
script = soup.find("script", attrs={"type": "application/ld+json"})
if not script:
print("JSON-LD-Skript auf der Seite nicht gefunden.")
return None
try:
return json.loads(script.text)
except json.JSONDecodeError as e:
print(f"JSON-Parsing-Fehler: {e}")
return None
def etsy_search(keyword):
"""Suche auf Etsy nach einem bestimmten Stichwort und gib die Ergebnisse zurück."""
encoded_keyword = urlencode({"q": keyword})
url = f"https://www.etsy.com/search?{encoded_keyword}"
data = fetch_etsy_data(url)
return data.get("itemListElement", []) if data else None
def etsy_product(listing_id):
"""Produktdetails aus einem Etsy-Eintrag abrufen."""
url = f"https://www.etsy.com/listing/{listing_id}/"
return fetch_etsy_data(url)
def etsy_shop(shop_name):
"""Hole Shop-Details aus einer Etsy-Shop-Seite."""
url = f"https://www.etsy.com/shop/{shop_name}"
return fetch_etsy_data(url)
def save_to_json(data, filename):
"""Speichern von Daten in einer JSON-Datei mit Fehlerbehandlung."""
try:
with open(filename, "w", encoding="utf-8") as file:
json.dump(data, file, indent=4, ensure_ascii=False, default=str)
print(f"Daten erfolgreich in {filename} gespeichert")
except (IOError, TypeError) as e:
print(f"Fehler beim Speichern der Daten in {filename}: {e}")
if __name__ == "__main__":
# Produktsuche
products = etsy_search("coffee mug")
if products:
save_to_json(products, "products.json")
# Bestimmter Artikel
item_info = etsy_product(1156396477)
if item_info:
save_to_json(item_info, "item.json")
# Etsy-Shop
shop = etsy_shop("QuiverCreekCeramic")
if shop:
save_to_json(shop, "shop.json")
Nachfolgend finden Sie einige Beispieldaten aus products.json.
{
"@context": "https://schema.org",
„@type”: „Product”,
„image”: „https://i.etsystatic.com/34923795/r/il/8f3bba/5855230678/il_fullxfull.5855230678_n9el.jpg”,
"name": "Individuelle Kaffeetasse mit Foto, personalisierte Kaffeetasse mit Bild, Jubiläumstasse als Geschenk für ihn/sie, individuell gestaltbare Tasse mit Logo und Text für Männer und Frauen",
„url“: „https://www.etsy.com/listing/1193808036/custom-coffee-mug-with-photo“,
„brand“: {
„@type“: „Brand“,
„name“: „TheGiftBucks“
},
"offers": {
"@type": "Offer",
"price": "14.99",
"priceCurrency": "USD"
},
"position": 1
},
Erwägen Sie die Verwendung von Datensätzen
Unsere Datensätze bieten eine großartige Alternative zum Web-Scraping. Sie können gebrauchsfertige Etsy-Datensätze oder einen unserer anderen E-Commerce-Datensätze kaufen und Ihren Scraping-Prozess vollständig eliminieren! Sobald Sie ein Konto haben, besuchen Sie unseren Datensatz-Marktplatz.
Geben Sie „Etsy“ ein und klicken Sie auf den Etsy-Datensatz.

Damit haben Sie Zugriff auf Millionen von Datensätzen aus Etsy-Daten – direkt auf Knopfdruck. Sie können sogar Beispieldaten herunterladen, um zu sehen, wie die Arbeit damit aussieht.
Fazit
In diesem Tutorial haben wir uns ausführlich mit dem Scraping von Etsy befasst. Sie haben einen Crashkurs in Proxy-Integration erhalten. Sie wissen, wie Sie mit Web Unlocker selbst die strengsten Bot-Blocker umgehen können. Sie wissen, wie Sie die Daten extrahieren und wie Sie sie speichern können. Außerdem haben Sie einen Eindruck von unseren vorgefertigten Datensätzen bekommen, die Ihnen das Scraping komplett ersparen. Wie auch immer Sie an Ihre Daten kommen, wir haben die Lösung für Sie.
Melden Sie sich jetzt an und testen Sie gratis.





