

In diesem Tutorial erfahren Sie:
- Die Definition eines Buchungsscrapers
- Welche Daten Sie damit extrahieren können
- Wie Sie mit Python ein Skript zum Scrapen von Booking.com erstellen
Lassen Sie uns loslegen!
Was ist ein Booking-Scraper?
EinBooking.com-Scraper ist ein Tool zum automatischen Extrahieren von Daten aus Booking.com-Seiten. Damit können Sie Informationen aus Immobilienanzeigen abrufen, z. B. Hotelnamen, Preise, Bewertungen, Ausstattungsmerkmale und Verfügbarkeit. Diese Daten können für verschiedene Zwecke verwendet werden, darunter Marktanalysen, Preisvergleiche und die Erstellung von Datensätzen zum Thema Reisen.
Daten, die Sie von Booking.com scrapen können
Nachfolgend finden Sie eine Liste der Datenpunkte, die Sie von Booking.com abrufen können:
- Details zur Unterkunft: Name des Hotels, Adresse, Entfernung zu Sehenswürdigkeiten (z. B. Stadtzentrum, Innenstadt usw.)
- Preisinformationen: Regulärer Preis, reduzierter Preis (falls verfügbar)
- Bewertungen und Bewertungen: Bewertungsergebnis, Anzahl der Bewertungen, Gästefeedback
- Verfügbarkeit: Verfügbare Zimmertypen, Buchungsoptionen (z. B. kostenlose Stornierung, Frühstück inbegriffen), Termine mit Verfügbarkeit
- Medien: Bilder der Unterkunft, Bilder der Zimmer
- Ausstattung: Angebotene Einrichtungen (z. B. WLAN, Parkplätze, Pool), zimmerspezifische Ausstattung
- Sonderangebote: Sonderangebote oder Rabatte, zeitlich begrenzte Angebote
- Richtlinien: Stornierungsbedingungen, Check-in- und Check-out-Zeiten
- Zusätzliche Details: Beschreibung der Unterkunft, Sehenswürdigkeiten in der Nähe, Anzahl der verfügbaren Zimmer für bestimmte Daten
Booking.com in Python scrapen: Schritt-für-Schritt-Anleitung
In diesem Abschnitt erfahren Sie, wie Sie einen Booking.com-Scraper erstellen.
Das Ziel ist es, ein Python-Skript zu erstellen, das automatisch Daten von der Unterkunftsseite sammelt:
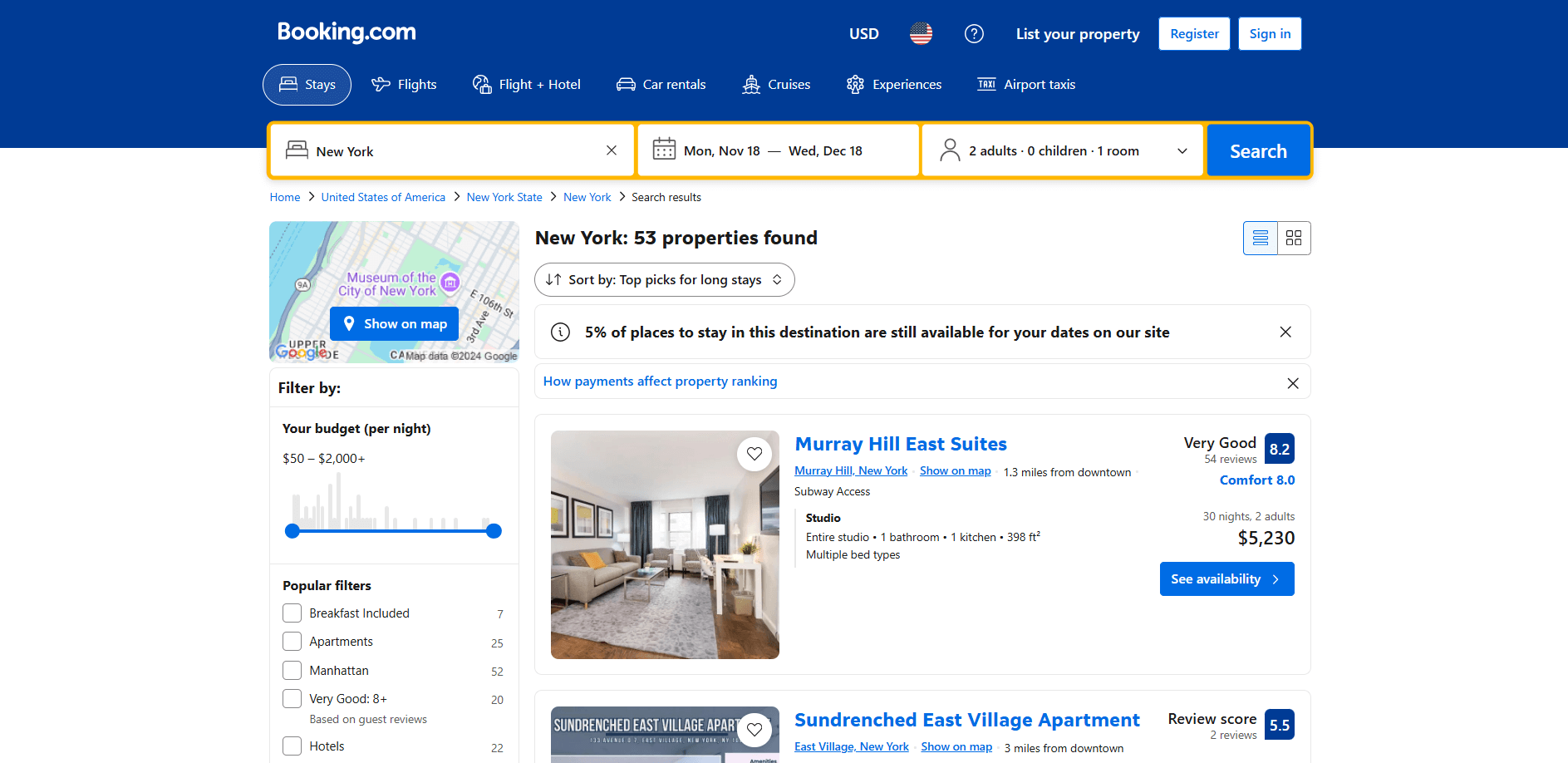
Befolgen Sie die folgenden Schritte!
Schritt 1: Projekt einrichten
Bevor Sie beginnen, stellen Sie sicher, dass Python 3 auf Ihrem Computer installiert ist. Ist dies nicht der Fall, laden Sie es herunter, starten Sie die ausführbare Datei und folgen Sie den Anweisungen des Installationsassistenten.
Verwenden Sie nun die folgenden Befehle, um einen Ordner für Ihr Projekt zu erstellen:
mkdir booking-scraper
Das Verzeichnis „booking-scraper” ist der Projektordner Ihres Python-Skripts zum Scrapen von Booking.com.
Öffnen Sie es und initialisieren Sie darin eine virtuelle Umgebung:
cd booking-Scraper
python -m venv env
Laden Sie den Projektordner in Ihre bevorzugte Python-IDE. Visual Studio Code mit der Python-Erweiterung und PyCharm Community Edition sind beide eine gute Wahl.
Erstellen Sie eine Datei namens scraper.py im Projektordner, die folgende Dateistruktur enthalten sollte:
scraper.py ist jetzt ein leeres Python-Skript, wird aber bald die Scraping-Logik enthalten.
Aktivieren Sie die virtuelle Umgebung im Terminal der IDE. Führen Sie dazu unter Linux oder macOS diesen Befehl aus:
./env/bin/activate
Unter Windows führen Sie stattdessen folgenden Befehl aus:
env/Scripts/activate
Großartig, Sie haben jetzt eine Python-Umgebung für das Web-Scraping!
Schritt 2: Wählen Sie die Scraping-Bibliothek aus
Nun muss festgestellt werden, ob Booking.com eine statische oder dynamische Website ist, um die entsprechende Scraping-Bibliothek auszuwählen. Dazu kann das Verhalten der Website untersucht werden. Öffnen Sie zunächst Booking.com in Ihrem Browser. Führen Sie eine Suche durch und navigieren Sie zur Seite der Unterkunft:
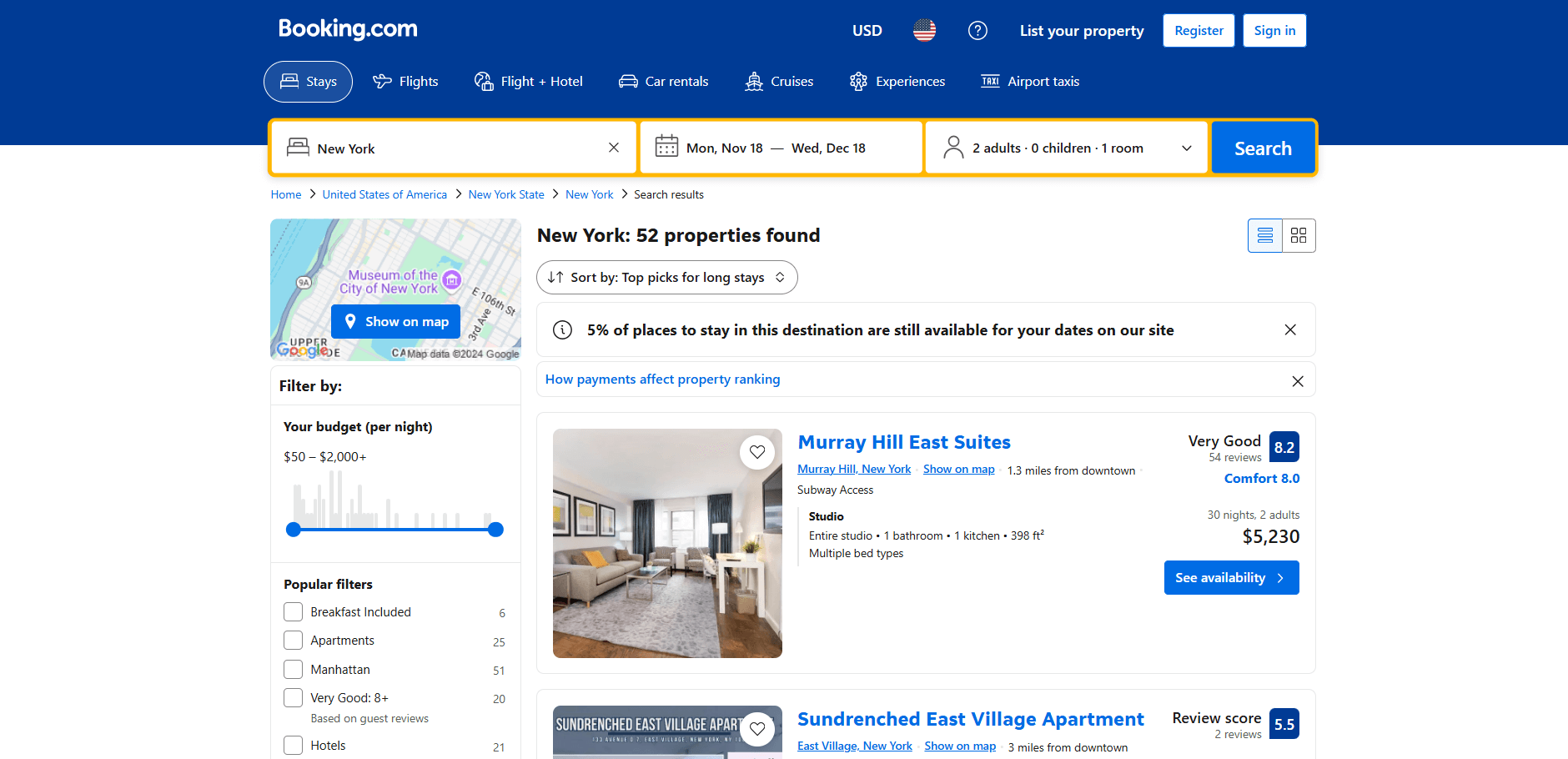
Beachten Sie, dass die Seite beim Herunterscrollen dynamisch neue Daten lädt:
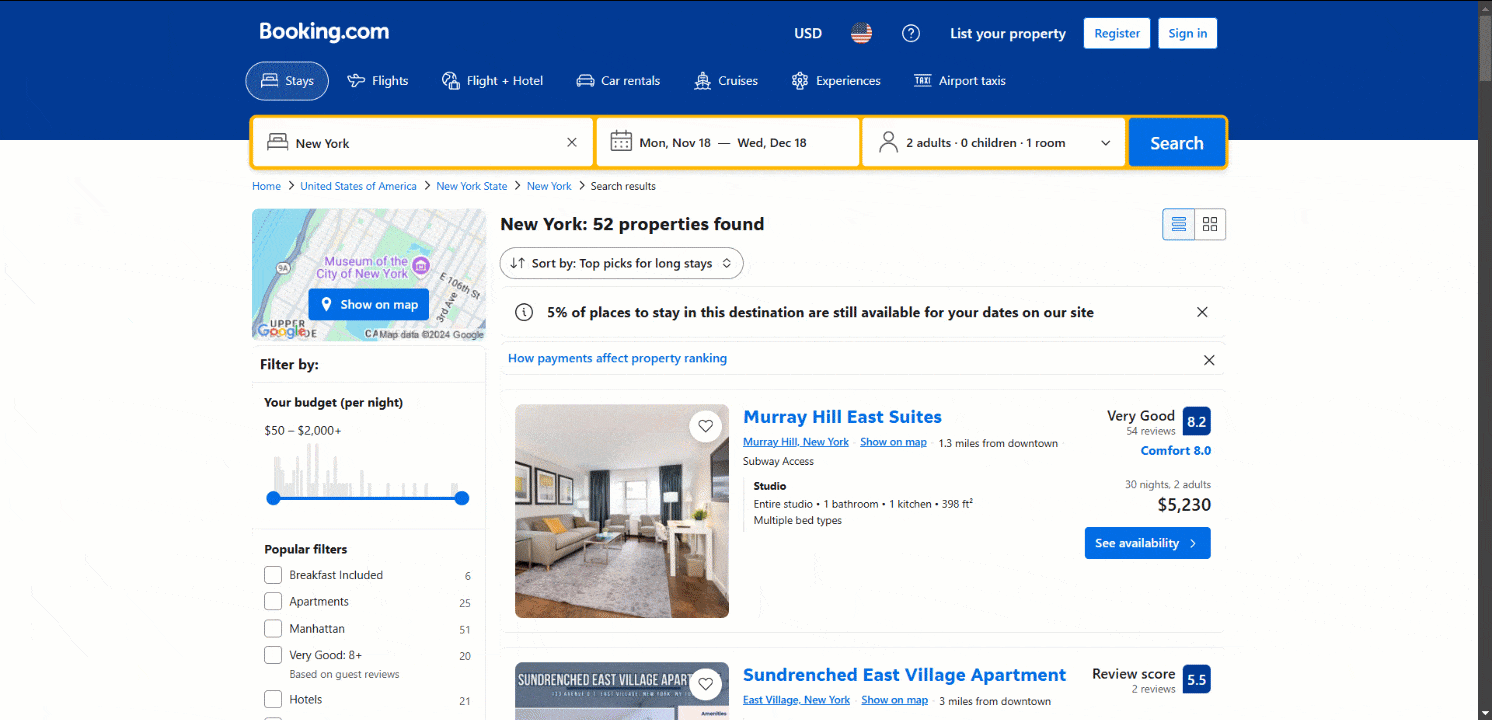
Dieses Muster wird als unendliches Scrollen bezeichnet und ist ein Kennzeichen dynamischer Websites. Erfahren Sie mehr darüber, wie Sie Web-Scraping auf dynamischen Websites durchführen können.
Ohne uns mit dem HTML-Code des vom Server zurückgegebenen Dokuments zu befassen oder die Registerkarte „Netzwerk“ in DevTools zu überprüfen (zwei gängige Schritte, um zu verstehen, ob eine Website statisch ist oder nicht), können wir bereits feststellen, dass Booking.com eine dynamische Website ist.
Der beste Ansatz zum Scraping einer Website mit dynamischen Inhalten ist die Verwendung eines Browser-Automatisierungstools. Mit diesen Lösungen können Sie einen Browser steuern und bestimmte Interaktionen auf der Seite ausführen, um Daten effektiv zu extrahieren.
Eines der leistungsstärksten Browser-Automatisierungstools für Python ist Selenium, das sich hervorragend für das Scraping von Booking.com eignet. Bereiten Sie sich auf die Installation vor, da es die primäre Bibliothek für diese Aufgabe sein wird!
Schritt 3: Selenium installieren und konfigurieren
In Python ist Selenium über das Selenium -Pip-Paket verfügbar. Installieren Sie es in einer aktivierten virtuellen Python-Umgebung mit diesem Befehl:
pip install selenium
Anleitungen zur Verwendung des Tools finden Sie in unserem Tutorial zum Web-Scraping mit Selenium.
Importieren Sie Selenium in scraper.py und initialisieren Sie ein WebDriver -Objekt, um eine Chrome-Instanz zu steuern:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# Erstellen Sie eine Chrome-Webtreiberinstanz.
driver = webdriver.Chrome(service=Service())
Der obige Code initialisiert eine Chrome-WebDriver-Instanz zur Steuerung eines Chrome-Browsers. Beachten Sie, dass Booking.com offenbar eine Anti-Scraping-Technologie verwendet, die Headless-Browser blockiert. Vermeiden Sie daher die Einstellung des Flags --headless. Als alternative Lösung lesen Sie unseren Leitfaden zu Playwright Stealth.
Denken Sie daran, den Webtreiber als letzte Zeile Ihres Scrapers zu schließen:
driver.quit()
Großartig! Sie sind nun vollständig konfiguriert, um mit dem Scraping von Booking.com zu beginnen.
Schritt 4: Besuchen Sie die Zielseite
Die Seiten von Booking.com bieten zahlreiche interaktive Funktionen, mit denen Sie Ihre Suche verfeinern können:
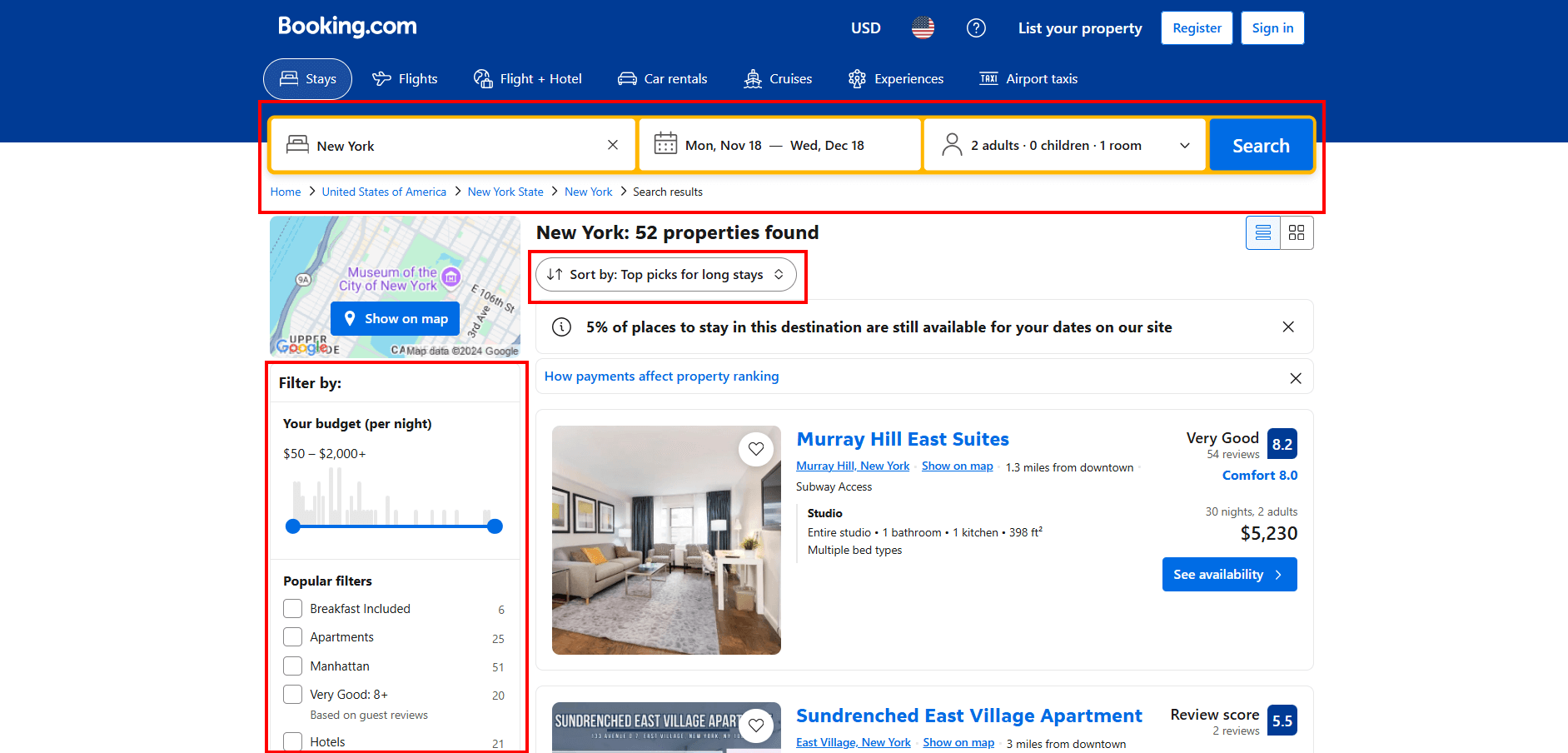
All diese Interaktionen mit Selenium programmgesteuert zu simulieren, wäre komplex und zeitaufwändig. Um den Vorgang zu vereinfachen und zu beschleunigen, führen Sie die Interaktionen zunächst manuell in Ihrem Browser durch.
Wenn Sie eine Suchanfrage konfiguriert haben, kopieren Sie die URL der resultierenden Seite aus der Adressleiste Ihres Browsers.
Die obige URL steht beispielsweise für eine Suche nach Apartments in New York vom 18. November bis zum 18. Dezember für zwei Erwachsene.
Kopieren Sie die URL und geben Sie sie in die von Selenium angebotene get() -Methode ein:
driver.get("https://www.booking.com/searchresults.html?ss=New+York&ssne=New+York&ssne_untouched=New+York&label=gen173nr-1FCAEoggI46AdIM1gEaHGIAQGYATG4ARfIAQzYAQHoAQH4AQKIAgGoAgO4Aof767kGwAIB0gIkNGE2MTI1MjgtZjJlNC00YWM4LWFlMmQtOGIxZjM3NWIyNDlm2AIF4AIB&sid=b91524e727f20006ae00489afb379d3a&aid=304142&lang=en-us&sb=1&src_elem=sb&src=index&dest_id=20088325&dest_type=city&checkin=2024-11-18&checkout=2024-12-18&group_adults=2&no_rooms=1&group_children=0")
Ihr Scraping-Skript stellt automatisch eine Verbindung zur gewünschten Booking.com-Seite her.
Die Datei scraper.py enthält nun folgende Codezeilen:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# Chrome-Webtreiberinstanz erstellen
driver = webdriver.Chrome(service=Service())
# Verbindung zur Zielseite herstellen
driver.get("https://www.booking.com/searchresults.html?ss=New+York&ssne=New+York&ssne_untouched=New+York&label=gen173nr-1FCAEoggI46AdIM1gEaHGIAQGYATG4ARfIAQzYAQHoAQH4AQKIAgGoAgO4Aof767kGwAIB0gIkNGE2MTI1MjgtZjJlNC00YWM4LWFlMmQtOGIxZjM3NWIyNDlm2AIF4AIB&sid=b91524e727f20006ae00489afb379d3a&aid=304142&lang=en-us&sb=1&src_elem=sb&src=index&dest_id=20088325&dest_type=city&checkin=2024-11-18&checkout=2024-12-18&group_adults=2&no_rooms=1&group_children=0")
# Scraping-Logik...
# Schließen Sie den Webtreiber und geben Sie seine Ressourcen frei.
driver.quit()
Setzen Sie einen Debugging-Haltepunkt in die letzte Zeile und führen Sie das Skript aus. Unten sehen Sie, was Sie sehen sollten:
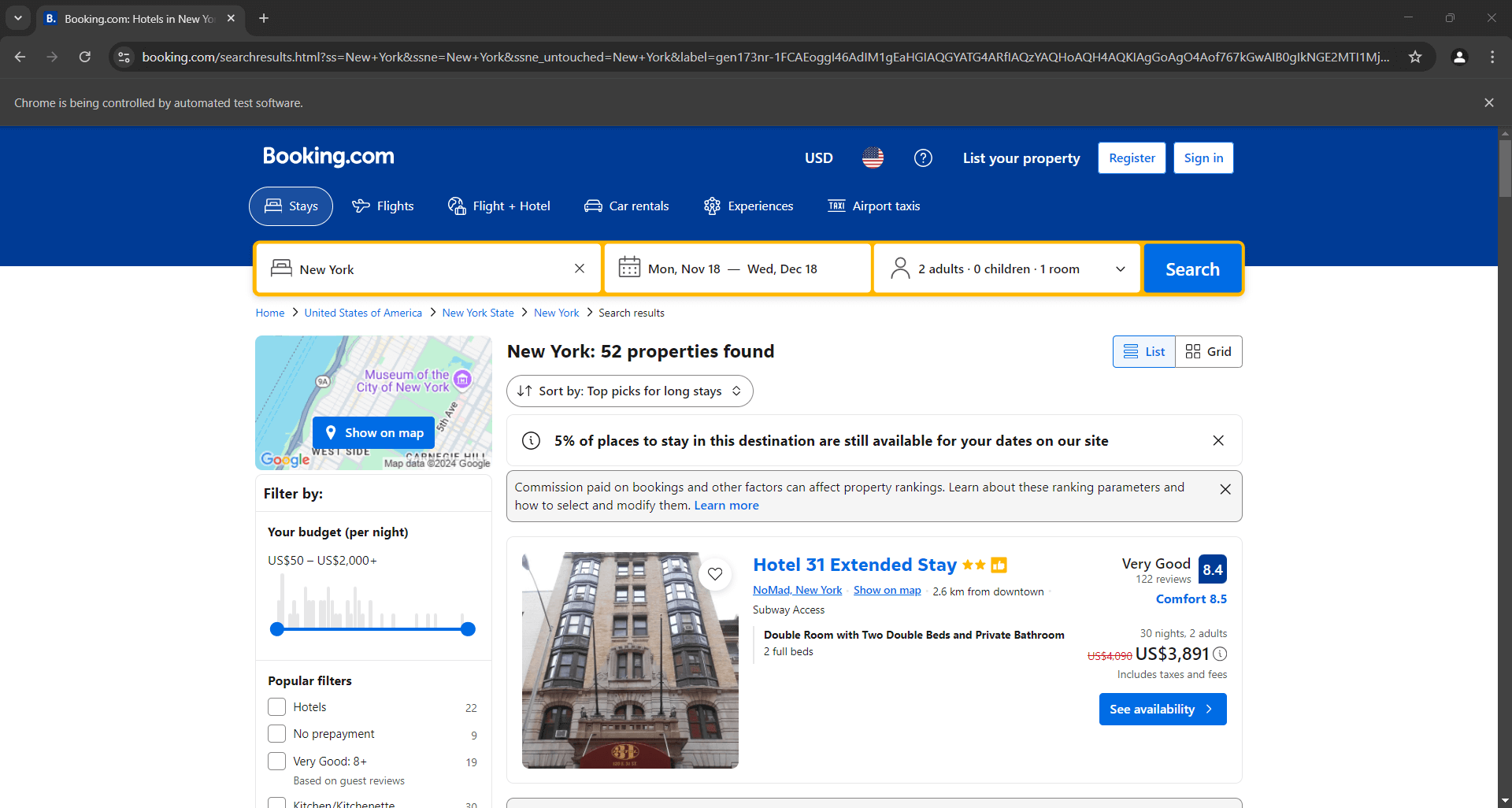
Die Meldung „Chrome wird von einer automatisierten Testsoftware gesteuert“ bestätigt, dass Selenium wie gewünscht in Chrome funktioniert. Gut gemacht!
Schritt 5: Umgang mit der Anmeldeaufforderung
Wenn Sie Booking.com zum ersten Mal in einem Browser besuchen, zeigt die Website oft innerhalb der ersten 20 Sekunden eine Anmeldeaufforderung an. Diese blockiert den Zugriff auf den Inhalt der Seite und erschwert das Web-Scraping:
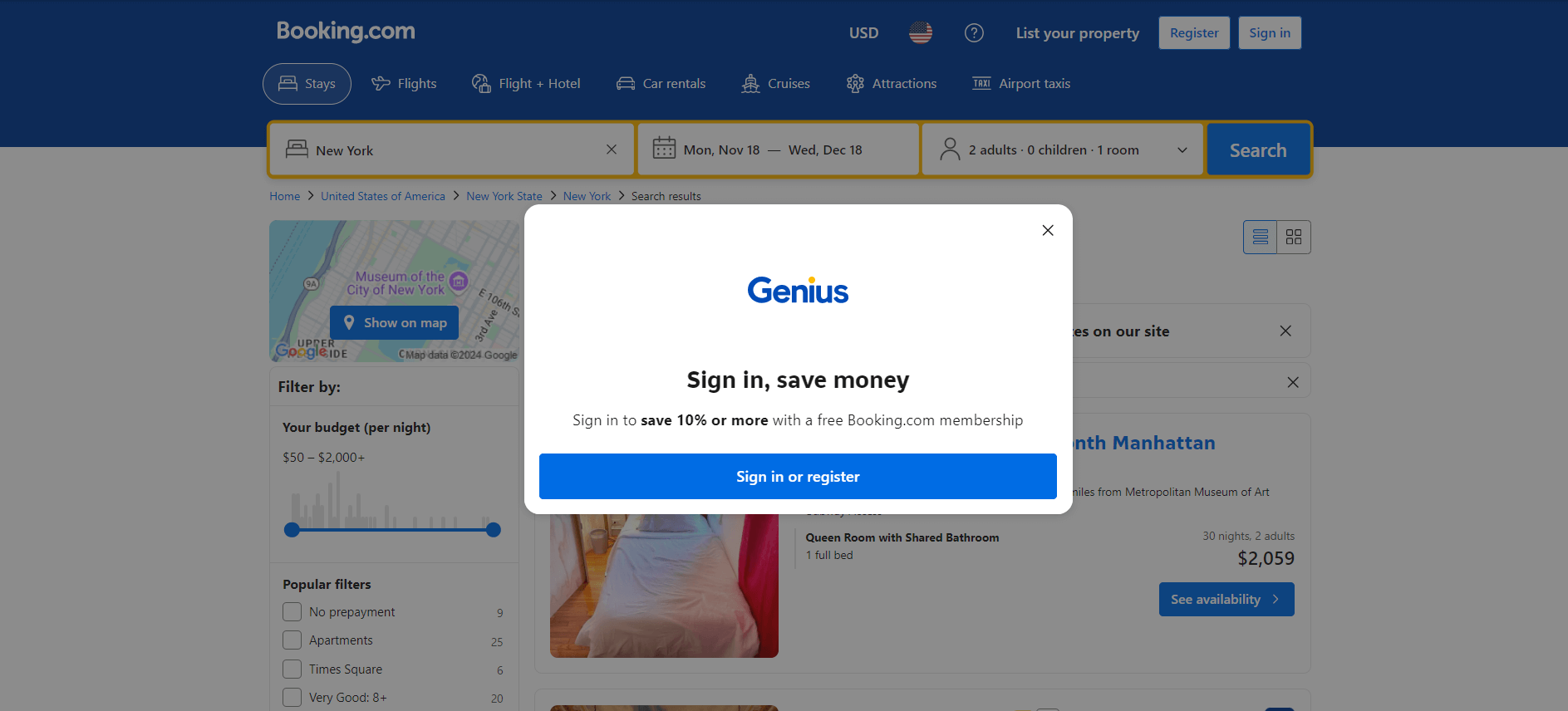
Solange Sie nicht darauf reagieren, können Sie nicht auf die Inhalte der zugrunde liegenden Seite zugreifen.
Um die Warnmeldung zu schließen, verwenden Sie Selenium. Klicken Sie mit der rechten Maustaste auf die Schaltfläche „Schließen“ und wählen Sie im Kontextmenü die Option „Untersuchen“:
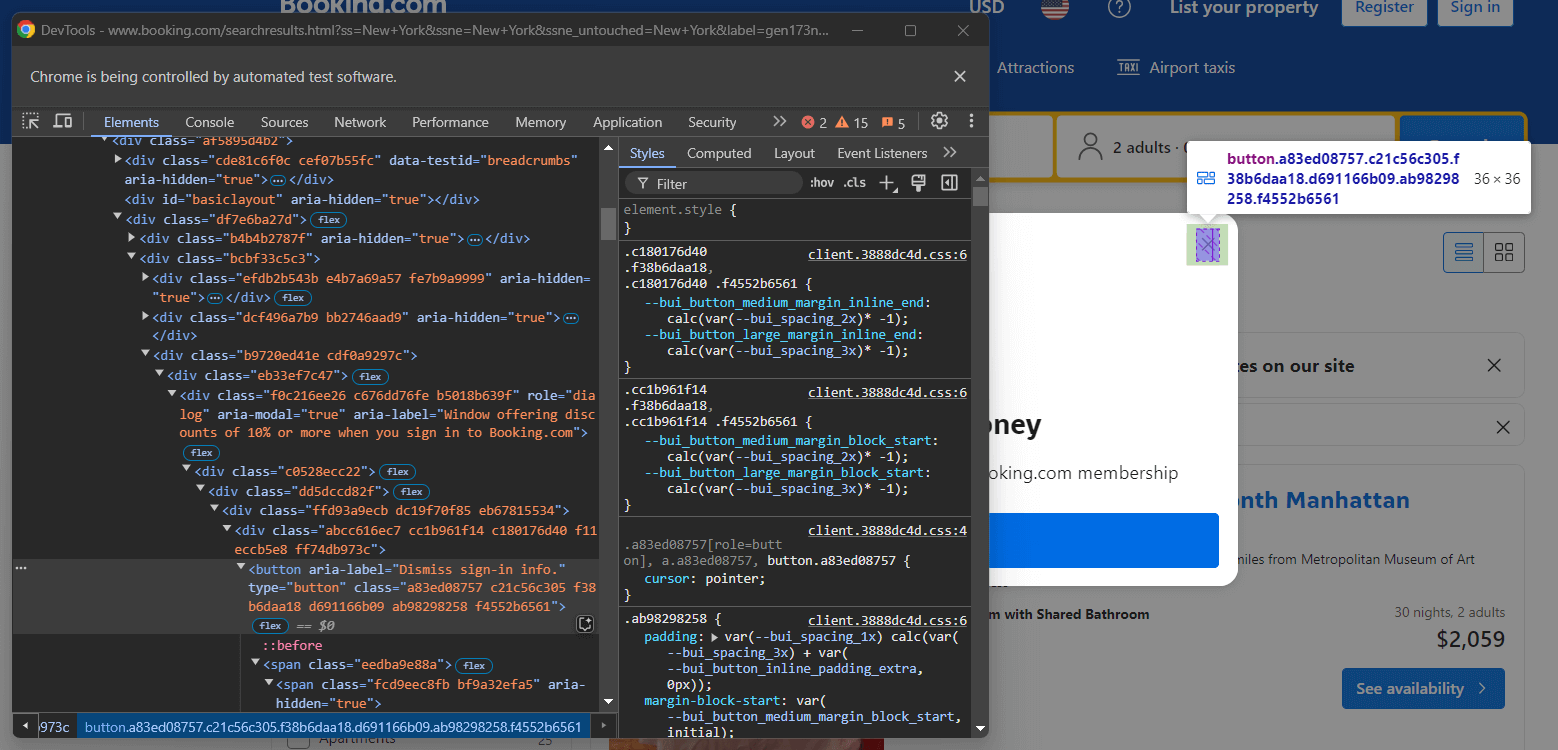
Beachten Sie, dass Sie das Modalfenster schließen können, indem Sie die Schaltfläche mit dem folgenden CSS-Selektor auswählen:
[role="dialog"] button[aria-label="Anmeldeinformationen schließen."]
Weisen Sie Selenium nun an, bis zu 10 Sekunden zu warten, bis die Warnmeldung erscheint. Sobald sie angezeigt wird, schließen Sie sie, indem Sie auf die Schaltfläche „Dismiss“ (Schließen) klicken. Da das Modal möglicherweise nicht immer angezeigt wird, ist es sinnvoll, diese Logik in einen try...except-Block einzubinden:
try:
# bis zu 20 Sekunden warten, bis die Anmelde-Warnmeldung erscheint
close_button = WebDriverWait(driver, 20).until(
EC.presence_of_element_located((By.CSS_SELECTOR, "[role="dialog"] button[aria-label="Anmeldeinformationen schließen."]"))
)
# auf die Schaltfläche „Schließen” klicken
close_button.click()
except TimeoutException:
print("Anmeldemodal wurde nicht angezeigt, Fortsetzung...")
WebDriverWait ist eine spezielle Selenium-Klasse, die das Skript pausiert, bis eine bestimmte Bedingung auf der Seite erfüllt ist. Im obigen Beispiel wartet es bis zu 10 Sekunden, bis die Schaltfläche zum Schließen der Warnmeldung auf der Seite erscheint.
Wenn die Warnmeldung nicht angezeigt wird, löst Selenium die Ausnahme „TimeoutException“ aus. Importieren Sie sie zusammen mit WebDriverWait, EC und By wie folgt:
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.common.exceptions import TimeoutException
Großartig! Die Anmelde-Warnmeldung ist nun kein Problem mehr.
Schritt 6: Wählen Sie die Booking.com-Elemente aus
Beachten Sie, dass die zu scrapend Seite von Booking.com mehrere Elemente enthält. Da Sie alle Elemente scrapen möchten, initialisieren Sie ein Array, in dem die gescrapend Daten gespeichert werden sollen:
items = []
Nun müssen Sie verstehen, wie Sie die mit diesen Elementen verbundenen HTML-Elemente auswählen können. Öffnen Sie Booking.com in Ihrem Browser, führen Sie eine Suche durch und überprüfen Sie eines der Immobilienelemente:
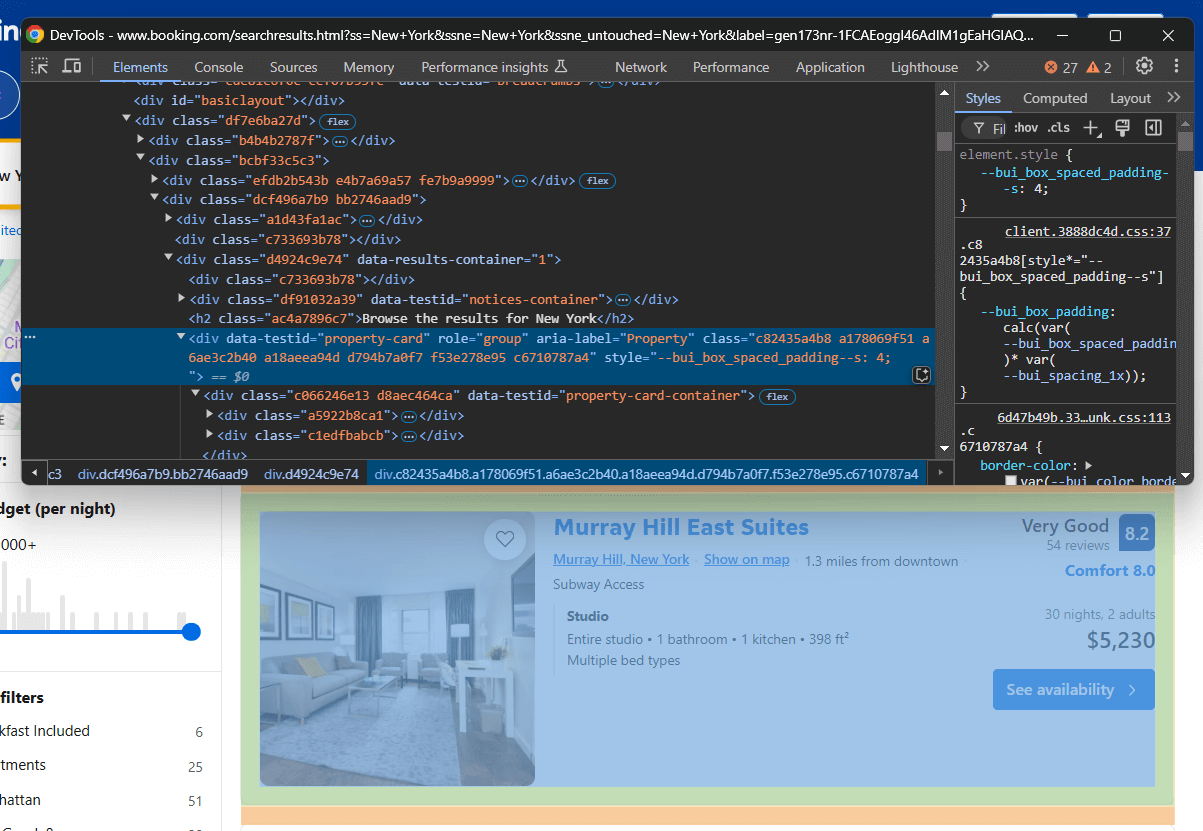
Beachten Sie, dass die Klassen der HTML-Elemente zufällig generiert zu sein scheinen. Das bedeutet, dass sie sich wahrscheinlich bei jeder Website-Bereitstellung ändern, was sie für die Elementauswahl unzuverlässig macht. Konzentrieren Sie sich stattdessen auf stabilere Attribute wie data-testid.
data-* -Attribute eignen sich hervorragend für das Web-Scraping.
Verwenden Sie die Selenium-Methode find_elements(), um einen CSS-Selektor auf die Seite anzuwenden und die gewünschten Elemente auszuwählen:
property_items = driver.find_elements(By.CSS_SELECTOR, "[data-testid="property-card"]")
Durchlaufen Sie die Property-Elemente und bereiten Sie Ihren Booking.com-Scraper vor, um einige Daten zu extrahieren:
for property_item in property_items:
# Scraping-Logik...
Großartig! Der nächste Schritt besteht darin, Daten aus diesen Elementen zu scrapen.
Schritt 7: Scrapen der Booking.com-Elemente
Sehen Sie sich die Property-Elemente auf der Seite an und beachten Sie, dass die darin enthaltenen Elemente uneinheitlich sind:
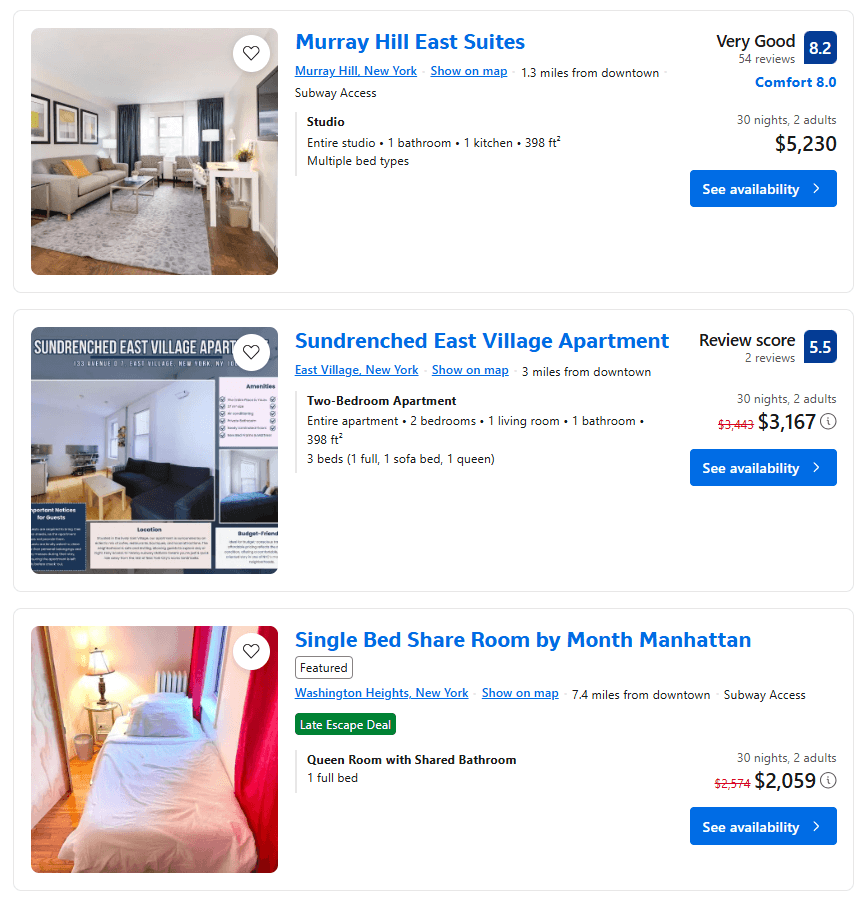
Einige haben eine Bewertungsnote, andere nicht. Einige haben einen reduzierten Preis, andere nicht.
Diese Unterschiede erschweren es, eine einheitliche Scraping-Logik für alle Immobilienobjekte zu schreiben. Wenn Sie versuchen, ein Element auszuwählen, das nicht auf der Seite vorhanden ist, löst Selenium eine NoSuchElementException aus. Daher ist es sinnvoll, eine Funktion zu definieren, die dieses Szenario behandelt:
def handle_no_such_element_exception(data_extraction_task):
try:
return data_extraction_task()
except NoSuchElementException as e:
return None
Die obige Funktion akzeptiert eine Lambda-Funktion und versucht, diese auszuführen. Wenn sie eine NoSuchElementException auslöst, fängt sie die Ausnahme ab und gibt None zurück. Dadurch kann Ihr Booking.com-Scraping-Skript ohne Unterbrechung fortgesetzt werden.
Importieren Sie NoSuchElementException:
from selenium.common import NoSuchElementException
Überprüfen Sie ein Element, das alle Elemente enthält (Bewertung, reduzierter Preis usw.):
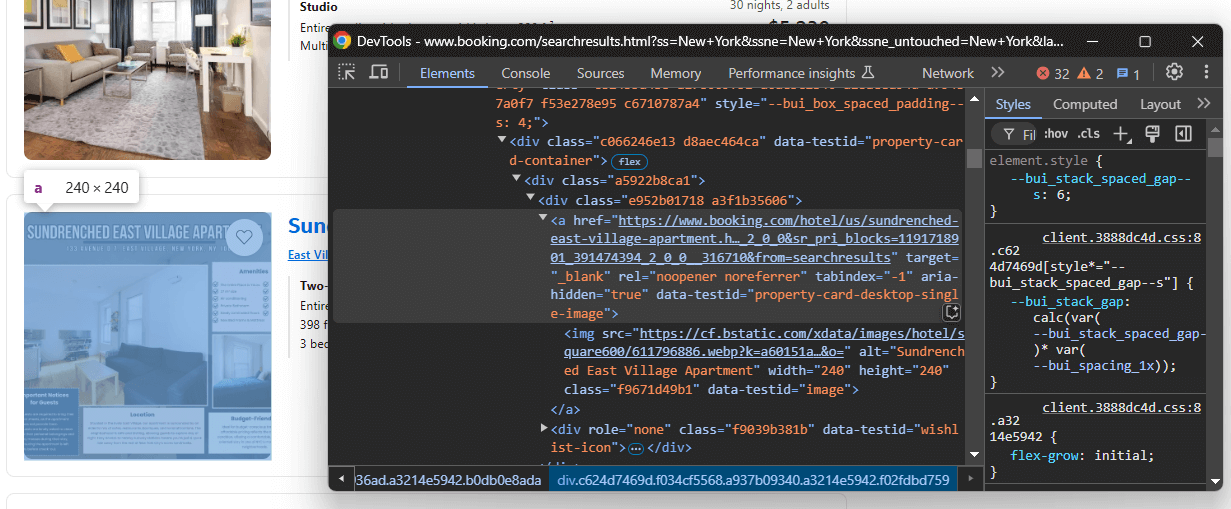
Beachten Sie, dass Sie Folgendes extrahieren können:
- Den Link zur Unterkunft aus
a[data-testid="property-card-desktop-single-image"] - Das Immobilienbild aus
img[data-testid=image]
Wenden Sie in der for- Schleife die aktuelle Logik an, um diese Elemente auszuwählen und Daten daraus zu extrahieren:
url = handle_no_such_element_exception(lambda: property_item.find_element(By.CSS_SELECTOR, "a[data-testid="property-card-desktop-single-image"]").get_attribute("href"))
image = handle_no_such_element_exception(lambda: property_item.find_element(By.CSS_SELECTOR, "img[data-testid="image"]").get_attribute("src"))
find_element() wählt einen einzelnen Knoten auf der Seite aus, während get_attribute() den Inhalt innerhalb des angegebenen HTML-Attributs abruft. Beachten Sie, dass die Anweisungen zur Datenextraktion von handle_no_such_element_exception umschlossen sind, um NoSuchElementExceptionszu behandeln.
Konzentrieren Sie sich ebenfalls auf die Informationen im Titelbereich und direkt darunter:
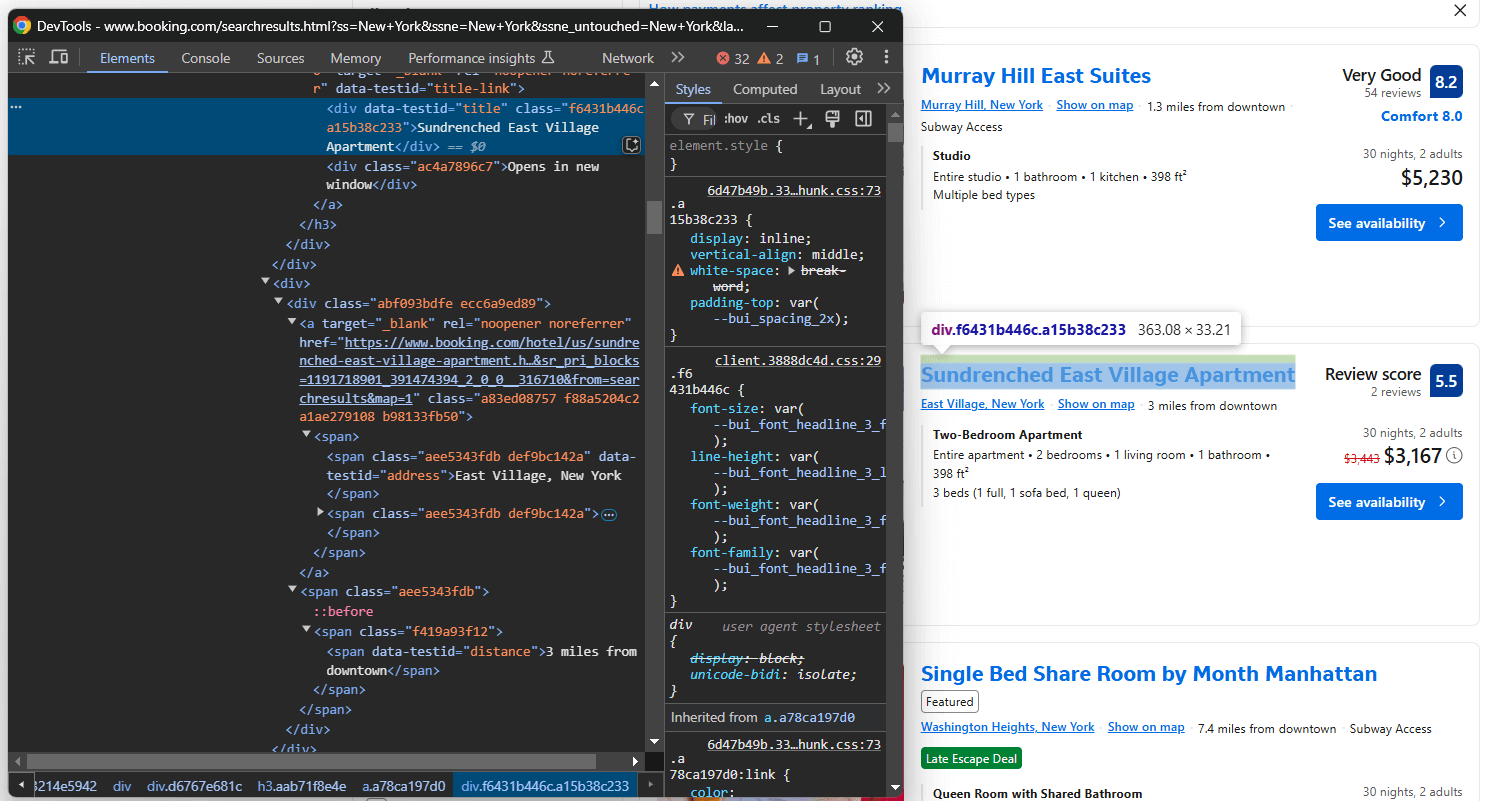
Hier erhalten Sie:
- Die Eigenschaft „title” aus
[data-testid="title"] - Die Eigenschaft „address” aus
[data-testid="address"] - Die Eigenschaft „distance” aus
[data-testid="distance"]
Kopieren Sie alle mit:
title = handle_no_such_element_exception(lambda: property_item.find_element(By.CSS_SELECTOR, "[data-testid="title"]").text)
address = handle_no_such_element_exception(lambda: property_item.find_element(By.CSS_SELECTOR, "[data-testid="address"]").text)
distance = handle_no_such_element_exception(lambda: property_item.find_element(By.CSS_SELECTOR, "[data-testid="distance"]").text)
Das Textattribut enthält den Text innerhalb der ausgewählten Elemente.
Als Nächstes konzentrieren Sie sich auf den Knoten „Bewertung“:
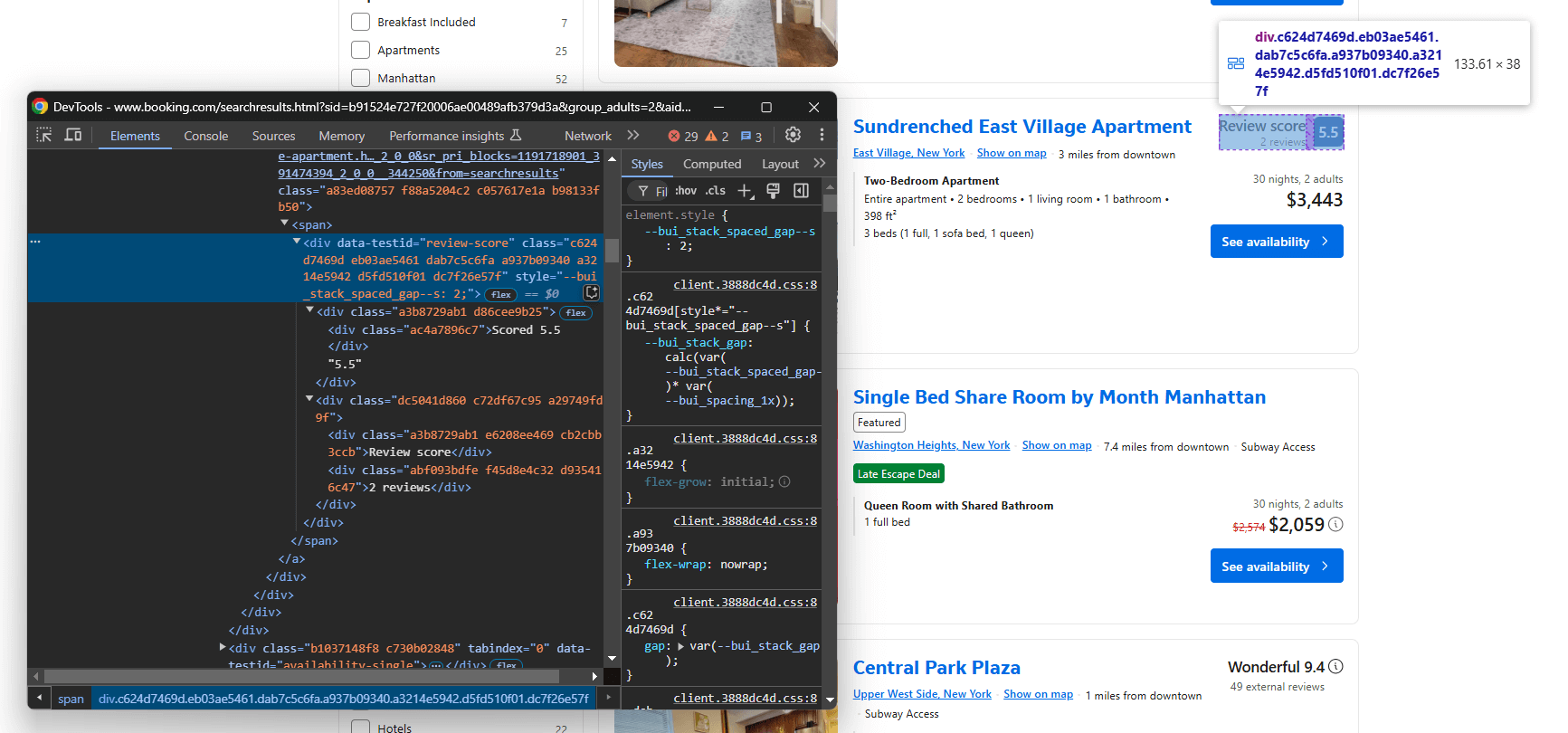
Wählen Sie ihn mit data-testid="review-score" aus und extrahieren Sie seinen Text. Beachten Sie, dass der Text ein spezielles Format hat, wie in diesem Beispiel:
„Bewertung 8,4n8,4nSehr gutn120 Bewertungen”
Mit einer benutzerdefinierten Logik können Sie die Bewertungsnote und die Anzahl der Bewertungen daraus extrahieren:
review_score = None
review_count = None
review_text = handle_no_such_element_exception(lambda: property_item.find_element(By.CSS_SELECTOR, "[data-testid="review-score"]").text)
if review_text is not None:
# split the review string by n
parts = review_text.split("n")
# jeden Teil verarbeiten
for part in parts:
part = part.strip()
# prüfen, ob dieser Teil eine Zahl ist (mögliche Bewertungsnote)
if part.replace(".", "", 1).isdigit():
review_score = float(part)
# Überprüfen, ob er die Zeichenfolge „reviews” enthält
elif „reviews” in Teil:
# Die Zahl vor „reviews” extrahieren
review_count = int(Teil.split(„ ”)[0].replace(„,”, „”))
Das Beschreibungselement anvisieren:
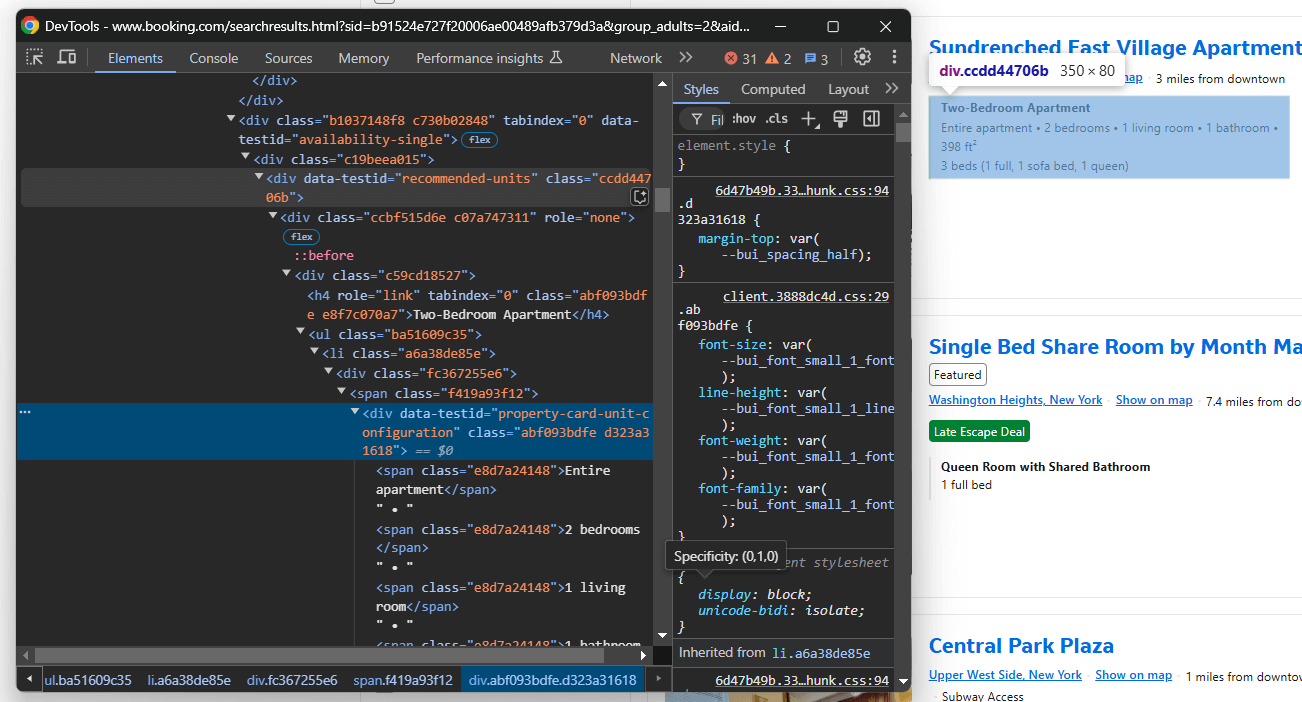
Wählen Sie es mit data-testid="recommended-units" aus und extrahieren Sie die Beschreibung:
description = handle_no_such_element_exception(lambda: property_item.find_element(By.CSS_SELECTOR, "[data-testid="recommended-units"]").text)
Konzentrieren Sie sich zuletzt auf die Preis-Elemente:
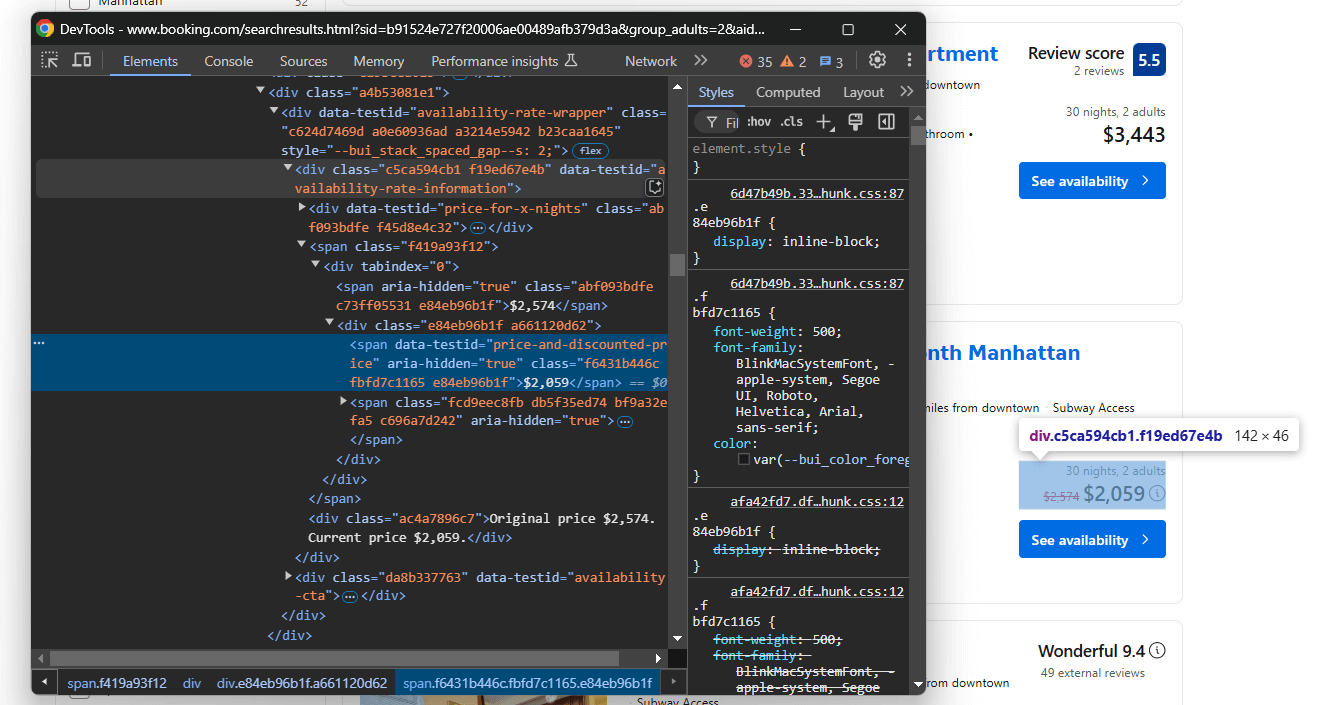
Wählen Sie aus dem Element data-testid="availability-rate-information" Folgendes aus:
- Den ursprünglichen Preis aus dem Knoten, der das Attribut
aria-hidden="true"hat und nicht über das Attributdata-testidverfügt - Den reduzierten/aktuellen Preis aus
data-testid="price-and-discounted-price"
Schreiben Sie die Logik zur Preisextraktion wie folgt:
price_element = handle_no_such_element_exception(lambda: (property_item.find_element(By.CSS_SELECTOR, "[data-testid="availability-rate-information"]")))
if price_element is not None:
original_price = handle_no_such_element_exception(lambda: (
price_element.find_element(By.CSS_SELECTOR, "[aria-hidden="true"]:not([data-testid])").text.replace(",", "")
))
price = handle_no_such_element_exception(lambda: (
price_element.find_element(By.CSS_SELECTOR, "[data-testid="price-and-discounted-price"]").text.replace(",", "")
))
Wow! Die Scraping-Logik für Booking.com ist fast fertig.
Schritt 7: Sammeln Sie die gescrapten Daten
Die gescrapten Daten sind nun über mehrere Variablen innerhalb der for-Schleife verteilt. Erstellen Sie ein neues Elementobjekt, füllen Sie es mit diesen Daten und hängen Sie es an das Array „items” an:
item = {
"url": url,
"image": image,
"title": title,
"address": address,
"distance": distance,
"review_score": review_score,
"review_count": review_count,
"description": description,
"original_price": original_price,
"price": price
}
items.append(item)
Am Ende der for- Schleife enthält items alle Ihre Scraping-Daten. Überprüfen Sie dies, indem Sie items ausgeben :
print(items)
Dies erzeugt folgende Ausgabe:
[{'url': 'https://www.booking.com/hotel/us/murray-hill-east-manhattan.html?label=gen173nr-1FCAEoggI46AdIM1gEaHGIAQGYATG4ARfIAQzYAQHoAQH4AQKIAgGoAgO4Aof767kGwAIB0gIkNGE2MTI1MjgtZjJlNC00YWM4LWFlMmQtOGIxZjM3NWIyNDlm2AIF4AIB&sid=b91524e727f20006ae00489afb379d3a&aid=304142&ucfs=1&arphpl=1&checkin=2024-11-18&checkout=2024-12-18&dest_id=20088325&dest_type=city&group_adults=2&req_adults=2&no_rooms=1&group_children=0&req_children=0&hpos=1&hapos=1&sr_order=popularity&srpvid=c6926559ebaa0862&srepoch=1731939905&all_sr_blocks=5604802_204869446_2_0_0&highlighted_blocks=5604802_204869446_2_0_0&matching_block_id=5604802_204869446_2_0_0&sr_pri_blocks=5604802_204869446_2_0_0__523000&from=searchresults', 'image': 'https://cf.bstatic.com/xdata/images/hotel/square600/84564452.webp?k=ff50b7387e08e01ba7a400effa788e668f894cabe4a295f60d6cd018ec9ac4d0&o=', 'title': 'Murray Hill East Suites', 'address': 'Murray Hill, New York', 'distance': '1,3 Meilen von der Innenstadt entfernt', 'review_score': 8,2, 'review_count': 54, 'description': 'StudionGesamtes Studio • 1 Badezimmer • 1 Küche • 398 ft²nMehrere Bettentypen', 'original_price': Keine, 'price': '5230 $'},
# der Kürze halber ausgelassen...
, {'url': 'https://www.booking.com/hotel/us/renaissance-times-square.html?label=gen173nr-1FCAEoggI46AdIM1gEaHGIAQGYATG4ARfIAQzYAQHoAQH4AQKIAgGoAgO4Aof767kGwAIB0gIkNGE2MTI1MjgtZjJlNC00YWM4LWFlMmQtOGIxZjM3NWIyNDlm2AIF4AIB&sid=b91524e727f20006ae00489afb379d3a&aid=304142&ucfs=1&arphpl=1&checkin=2024-11-18&checkout=2024-12-18&dest_id=20088325&dest_type=city&group_adults=2&req_adults=2&no_rooms=1&group_children=0&req_children=0&hpos=12&hapos=12&sr_order=popularity&srpvid=c6926559ebaa0862&srepoch=1731939905&all_sr_blocks=2315604_274565698_0_2_0&highlighted_blocks=2315604_274565698_0_2_0&matching_block_id=2315604_274565698_0_2_0&sr_pri_blocks=2315604_274565698_0_2_0__1805400&from_sustainable_property_sr=1&from=searchresults', 'image': 'https://cf.bstatic.com/xdata/images/hotel/square600/437371642.webp?k=d1a06036e365573e326e6b0f1b045f8f43b6ad0d18e119cfb92d92cc81fa5c88&o=', 'title': 'Renaissance New York Times Square by Marriott', 'address': 'Manhattan, New York', 'distance': '0,6 Meilen vom Stadtzentrum entfernt', 'review_score': 8,4, 'review_count': 2209, 'description': 'King Roomn1 Kingsize-Bett', 'original_price': '20060 $', 'price': '18054 $'}]
Fantastisch! Jetzt müssen Sie diese Informationen nur noch in eine für Menschen lesbare Datei wie CSV exportieren.
Schritt 8: In CSV exportieren
Importieren Sie das CSV -Paket aus der Python-Standardbibliothek:
import csv
Verwenden Sie es dann, um Elemente in eine CSV-Datei zu exportieren:
# Geben Sie den Namen der CSV-Ausgabedatei an.
output_file = "properties.csv"
# Exportieren Sie die Elementliste in eine CSV-Datei.
with open(output_file, mode="w", newline="", encoding="utf-8") as file:
# CSV-Writer-Objekt erstellen
writer = csv.DictWriter(file, fieldnames=["url", "image", "title", "address", "distance", "review_score", "review_count", "description", "original_price", "price"])
# Header-Zeile schreiben
writer.writeheader()
# Jedes Element als Zeile in die CSV-Datei schreiben
writer.writerows(items)
Dieser Ausschnitt füllt eine CSV-Datei namens properties.csv mit Daten aus den Element-Arrays. Die wichtigsten oben verwendeten Funktionen sind:
open(): Öffnet die angegebene Datei im Schreibmodus mit UTF-8-Kodierung.csv.DictWriter(): Erstellt einen CSV-Writer mit den angegebenen Feldnamen.writeheader(): Schreibt die Kopfzeile basierend auf den angegebenen Feldnamen in die CSV-Datei.writer.writerow(): Schreibt jedes Wörterbuchelement als Zeile in die CSV-Datei.
Schritt 9: Alles zusammenfügen
scraper.py sollte nun folgende Zeilen enthalten:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.common.exceptions import TimeoutException
from selenium.common import NoSuchElementException
import csv
def handle_no_such_element_exception(data_extraction_task):
try:
return data_extraction_task()
except NoSuchElementException as e:
return None
# Chrome-Webtreiberinstanz erstellen
driver = webdriver.Chrome(service=Service())
# Verbindung zur Zielseite herstellen
driver.get("https://www.booking.com/searchresults.html?ss=New+York&ssne=New+York&ssne_untouched=New+York&label=gen173nr-1FCAEoggI46AdIM1gEaHGIAQGYATG4ARfIAQzYAQHoAQH4AQKIAgGoAgO4Aof767kGwAIB0gIkNGE2MTI1MjgtZjJlNC00YWM4LWFlMmQtOGIxZjM3NWIyNDlm2AIF4AIB&sid=b91524e727f20006ae00489afb379d3a&aid=304142&lang=en-us&sb=1&src_elem=sb&src=index&dest_id=20088325&dest_type=city&checkin=2024-11-18&checkout=2024-12-18&group_adults=2&no_rooms=1&group_children=0")
# Anmeldebenachrichtigung verarbeiten
try:
# bis zu 20 Sekunden warten, bis die Anmeldeaufforderung erscheint
close_button = WebDriverWait(driver, 20).until(
EC.presence_of_element_located((By.CSS_SELECTOR, "[role="dialog"] button[aria-label="Anmeldeinformationen schließen."]"))
)
# Klicken Sie auf die Schaltfläche „Schließen“
close_button.click()
except e:
print("Anmeldemodal wurde nicht angezeigt, Fortsetzung...")
# wo die gescrapten Daten gespeichert werden sollen
items = []
# alle Immobilienobjekte auf der Seite auswählen
property_items = driver.find_elements(By.CSS_SELECTOR, "[data-testid="property-card"]")
# die Immobilienobjekte durchlaufen und
# Daten daraus extrahieren
for property_item in property_items:
# Scraping-Logik...
url = handle_no_such_element_exception(lambda: property_item.find_element(By.CSS_SELECTOR, "a[data-testid="property-card-desktop-single-image"]").get_attribute("href"))
image = handle_no_such_element_exception(lambda: property_item.find_element(By.CSS_SELECTOR, "img[data-testid="image"]").get_attribute("src"))
title = handle_no_such_element_exception(lambda: property_item.find_element(By.CSS_SELECTOR, "[data-testid="title"]").text)
address = handle_no_such_element_exception(lambda: property_item.find_element(By.CSS_SELECTOR, "[data-testid="address"]").text)
distance = handle_no_such_element_exception(lambda: property_item.find_element(By.CSS_SELECTOR, "[data-testid="distance"]").text)
review_score = None
review_count = None
review_text = handle_no_such_element_exception(lambda: property_item.find_element(By.CSS_SELECTOR, "[data-testid="review-score"]").text)
if review_text is not None:
# split the review string by n
parts = review_text.split("n")
# jeden Teil verarbeiten
for part in parts:
part = part.strip()
# prüfen, ob dieser Teil eine Zahl ist (mögliche Bewertungszahl)
if part.replace(".", "", 1).isdigit():
review_score = float(part)
# prüfen, ob er die Zeichenfolge „reviews” enthält
elif „reviews” in part:
# extrahiere die Zahl vor „reviews”
review_count = int(part.split(" ")[0].replace(",", ""))
decription = handle_no_such_element_exception(lambda: property_item.find_element(By.CSS_SELECTOR, "[data-testid="recommended-units"]").text)
price_element = handle_no_such_element_exception(lambda: (property_item.find_element(By.CSS_SELECTOR, "[data-testid="availability-rate-information"]")))
if price_element is not None:
original_price = handle_no_such_element_exception(lambda: (
price_element.find_element(By.CSS_SELECTOR, "[aria-hidden="true"]:not([data-testid])").text.replace(",", "")
))
price = handle_no_such_element_exception(lambda: (
price_element.find_element(By.CSS_SELECTOR, "[data-testid="price-and-discounted-price"]").text.replace(",", "")
))
# neues Element mit den gescrapten Daten füllen
item = {
"url": url,
"image": image,
"title": title,
"address": address,
"distance": distance,
"review_score": review_score,
"review_count": review_count,
"decription": decription,
"original_price": original_price,
"price": price
}
# Füge den neuen Eintrag zur Liste der gescrapten Einträge hinzu.
items.append(item)
# Namen der CSV-Ausgabedatei angeben
output_file = "properties.csv"
# Elementliste in CSV-Datei exportieren
with open(output_file, mode="w", newline="", encoding="utf-8") as file:
# CSV-Writer-Objekt erstellen
writer = csv.DictWriter(file, fieldnames=["url", "image", "title", "address", "distance", "review_score", "review_count", "decription", "original_price", "price"])
# Header-Zeile schreiben
writer.writeheader()
# Jedes Element als Zeile in die CSV-Datei schreiben
writer.writerows(items)
# Webtreiber schließen und Ressourcen freigeben
driver.quit()
Kaum zu glauben, oder? Mit nur etwa 110 Zeilen haben Sie gerade einen Python-Scraper für Booking.com erstellt.
Überprüfen Sie, ob er funktioniert, indem Sie das Scraping-Skript ausführen. Unter Windows führen Sie den Scraper mit folgendem Befehl aus:
python Scraper.py
Unter Linux oder macOS führen Sie stattdessen Folgendes aus:
python3 Scraper.py
Warten Sie, bis das Skript vollständig ausgeführt wurde. Im Stammverzeichnis Ihres Projekts wird eine Datei namens „properties.csv“ angezeigt. Öffnen Sie die Datei, um die extrahierten Daten anzuzeigen:
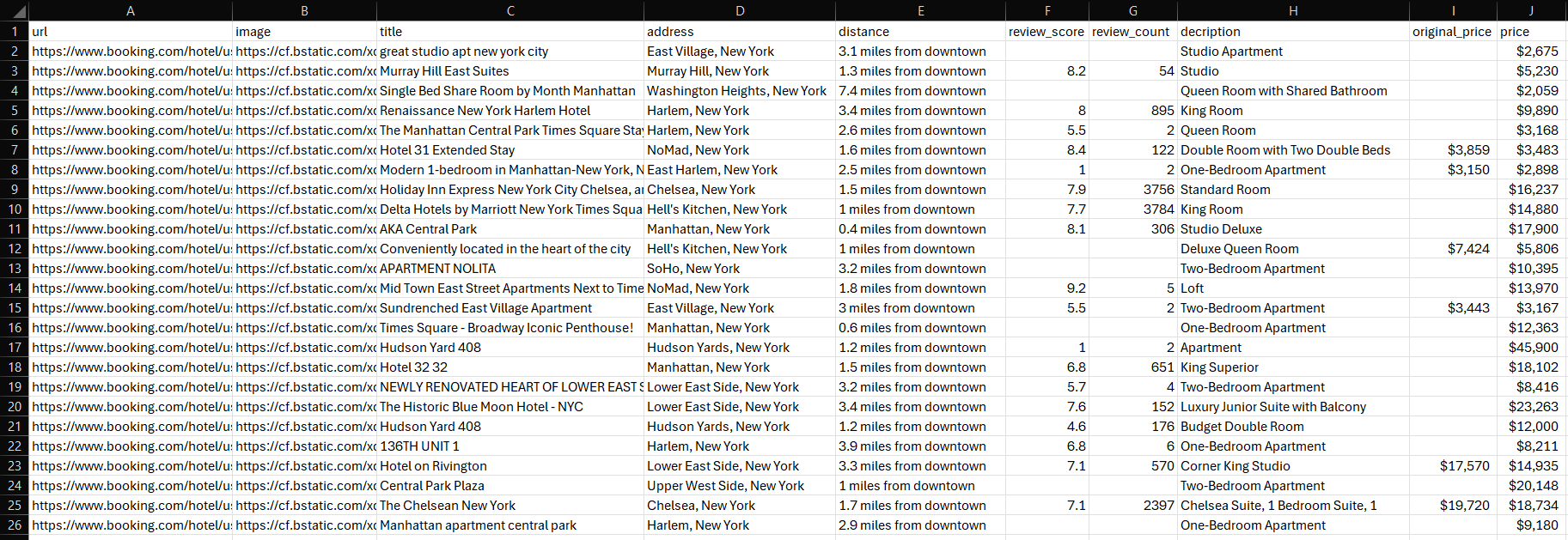
Herzlichen Glückwunsch, Mission erfüllt!
Fazit
In diesem Tutorial haben Sie gelernt, was ein Booking.com-Scraper ist und wie man einen solchen mit Python erstellt. Wie gezeigt, sind nur wenige Zeilen Code erforderlich, um ein einfaches Skript zum automatischen Abrufen von Daten von Booking.com zu erstellen.
Das hier vorgestellte Beispiel geht jedoch nicht auf viele der Herausforderungen ein, denen Sie beim Scraping von Booking.com begegnen können. Probleme wie Anti-Headless-Browser-Maßnahmen, die Verarbeitung von Benutzerinteraktionen zur Generierung von Suchergebnissen und der Umgang mit unendlichem Scrollen können Ihre Scraping-Vorgänge schnell komplizieren.
Suchen Sie nach einer einfacheren, voll ausgestatteten und leistungsstarken Scraper-Lösung? Probieren Sie die Booking Scraper API von Bright Data aus!
Die Booking Scraper API bietet leistungsstarke Endpunkte zum Scrapen öffentlicher Hoteldaten, Bewertungen, Rezensionen und mehr. Mit einfachen API-Aufrufen können Sie Daten im JSON- oder HTML-Format abrufen.
Bevorzugen Sie vorgefertigte Lösungen? Bright Data bietet auch gebrauchsfertige Booking.com-Datensätze an!
Erstellen Sie noch heute ein kostenloses Bright Data-Konto, um unsere Scraper-APIs auszuprobieren oder unsere Datensätze zu erkunden.





