

In diesem Leitfaden erfahren Sie Folgendes:
- Was ein AliExpress-Scraper ist und wie er funktioniert
- Welche Arten von Daten Sie automatisch von AliExpress abrufen können
- Wie Sie mit Python ein AliExpress-Scraping-Skript erstellen
Lassen Sie uns loslegen!
Was ist ein AliExpress-Scraper?
Ein AliExpress-Scraper ruft automatisch bestimmte Daten von AliExpress-Seiten ab. Er navigiert durch AliExpress-Seiten, indem er die Surfgewohnheiten der Benutzer nachahmt. Er wandelt den Inhalt von Webseiten in ein nutzbares Format um – beispielsweise CSV oder JSON – und steuert Interaktionen wie die Paginierung. Sein Endziel ist es, strukturierte Informationen wie Produktbilder, Produktdetails, Kundenfeedback, Preise und mehr abzurufen.
Wenn Sie mehr über die Erstellung von Web-Scrapers erfahren möchten, lesen Sie unseren Leitfaden zur Erstellung eines Scraping-Bots.
Daten, die Sie von AliExpress scrapen können: Schritt-für-Schritt-Anleitung
AliExpress enthält eine Vielzahl von Informationen, darunter:
- Produktdetails: Namen, Beschreibungen, Bilder, Preisklassen, Verkäuferinformationen und mehr.
- Kundenfeedback: Bewertungen, Produktrezensionen und mehr.
- Kategorien und Tags: Produktkategorien, relevante Tags oder Labels.
Jetzt lernen Sie, wie Sie diese Daten extrahieren können!
AliExpress in Python scrapen
Dieser Tutorial-Abschnitt enthält eine Schritt-für-Schritt-Anleitung zum Erstellen eines AliExpress-Scrapers.
Das Ziel ist es, Ihnen zu zeigen, wie Sie ein Python-Skript schreiben, das automatisch Informationen von der AliExpress-Seite „ergonomischer Stuhl” abruft:
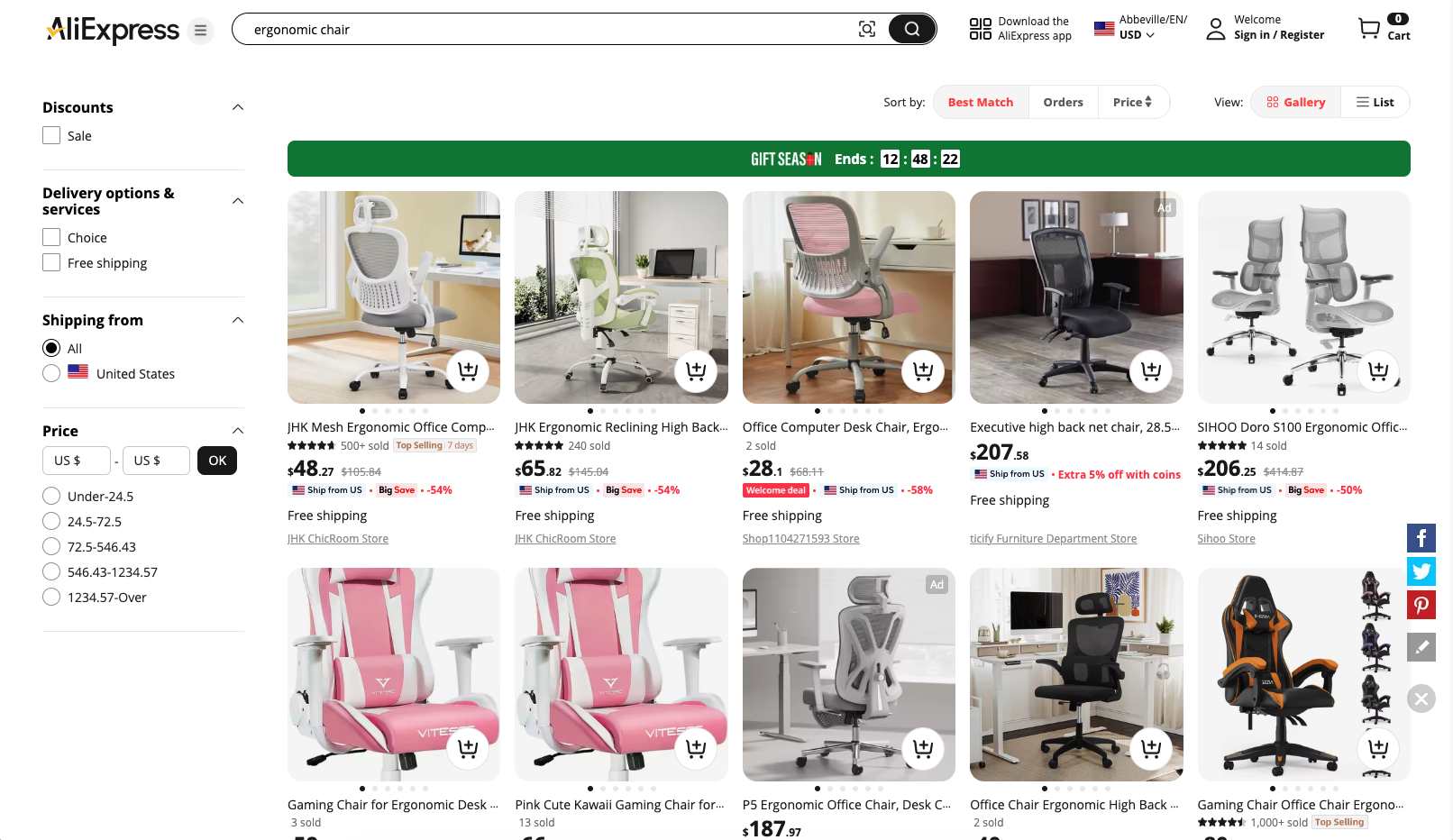
Schritt 1: Projekt einrichten
Stellen Sie sicher, dass Python 3 auf Ihrem lokalen Computer installiert ist. Falls nicht, laden Sie es von der offiziellen Dokumentation herunter und folgen Sie dem Installationsassistenten, um es einzurichten.
Verwenden Sie anschließend den folgenden Befehl, um Ihr Projektverzeichnis zu erstellen:
mkdir aliexpress-scraper
Dieses Verzeichnis wird Ihren Python-Code enthalten.
Geben Sie das Verzeichnis in Ihrem Terminal ein und erstellen Sie darin eine virtuelle Umgebung:
cd aliexpress-Scraper
python -m venv env
Laden Sie nun den Projektordner in Ihre bevorzugte Python-IDE, z. B. Visual Studio Code mit der Python-Erweiterung.
Aktivieren Sie die virtuelle Umgebung im Terminal Ihrer IDE. Führen Sie den folgenden Befehl aus, wenn Sie macOS oder Linux verwenden:
.env/bin/activate
Unter Windows verwenden Sie stattdessen diesen Befehl:
env/Scripts/activate
Gut!
Erstellen Sie in Ihrem Projekt-Stammverzeichnis eine Datei namens scraper.py. Ihr Projekt sollte nun folgende Ordnerstruktur aufweisen:
Super! Ihre Python-Umgebung für das Web-Scraping von AliExpress ist bereit.
Schritt 2: Wählen Sie die Scraping-Bibliothek aus
Das aktuelle Ziel ist es, festzustellen, ob AliExpress dynamische oder statische Seiten verwendet. Navigieren Sie in Ihrem Browser im privaten oder Inkognito-Modus zu Ihrer Zielseite von AliExpress. Klicken Sie dann mit der rechten Maustaste auf eine leere Stelle im Hintergrund der Webseite, wählen Sie die Option „Untersuchen“, navigieren Sie zur Registerkarte „Netzwerk“, wenden Sie den Filter „Fetch/XHR“ an und aktualisieren Sie die Seite:
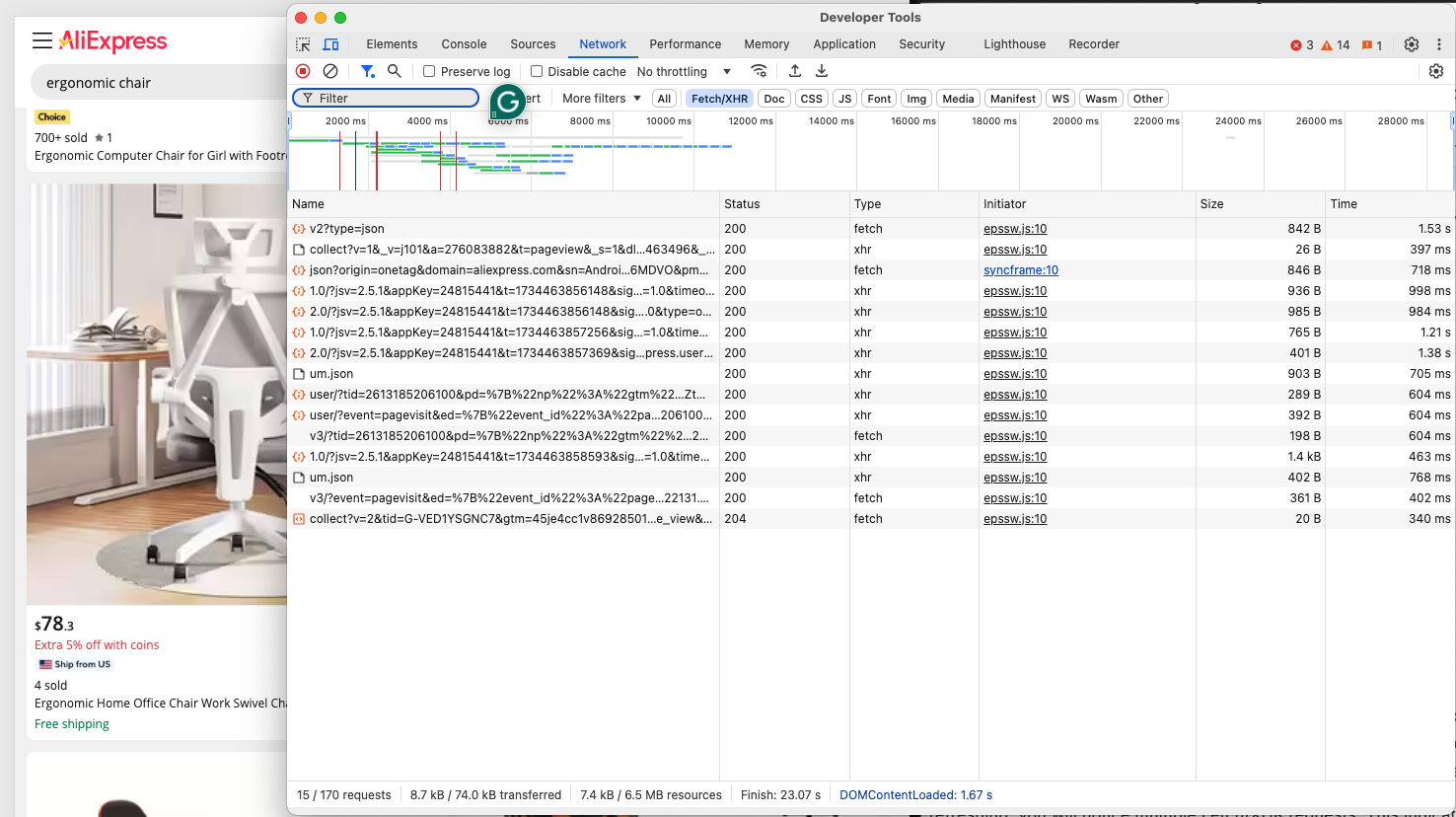
Überprüfen Sie in diesem DevTools-Bereich, ob die Seite dynamische Abfragen durchführt. Nach dem Aktualisieren der Seite werden Sie mehrere Fetch/XHR-Anfragen bemerken. Dies deutet darauf hin, dass die Seite dynamische Anfragen verwendet, um zusätzliche Inhalte zu laden. Wenn Sie sich das DOM der Seite im Vergleich zum vom Server zurückgegebenen HTML-Dokument ansehen, werden Sie auch feststellen, dass AliExpress JavaScript-Rendering verwendet.
Um AliExpress effektiv zu scrapen, benötigen Sie ein Browser-Automatisierungstool wie Selenium, da die Zielseite für das Rendering auf JavaScript angewiesen ist. Unser Blog über Selenium-Web-Scraping ist eine hervorragende Ressource für Anfänger.
Mit Selenium können Sie einen Webbrowser manipulieren, Benutzerinteraktionen nachahmen und JavaScript-gerenderte Inhalte scrapen. Installieren Sie es und legen Sie los!
Schritt 3: Selenium installieren und konfigurieren
Installieren Sie Selenium in der aktivierten virtuellen Umgebung mit diesem Befehl:
pip install -U selenium
Importieren Sie in der Datei scraper.py WebDriver aus Selenium und initialisieren Sie es.
from selenium import webdriver
# Chrome-Treiber initialisieren
driver = webdriver.Chrome()
# Scraping-Logik...
# Treiber schließen
driver.quit()
Im obigen Code wird ein WebDriver initialisiert, um eine Chrome-Instanz zu verarbeiten. Es ist zu beachten, dass AliExpress über Anti-Scraping-Maßnahmen verfügt, die den Zugriff von Headless-Browsern auf die Website verhindern könnten.
Es ist daher nicht ratsam, das Flag--headless zu setzen. Ziehen Sie stattdessen eine alternative Option wie Playwright Stealth in Betracht.
Nachdem Sie nun vollständig für das Scraping von AliExpress konfiguriert sind, wollen wir uns ansehen, wie Sie eine Verbindung zur Zielseite herstellen können.
Schritt 4: Verbindung zur Zielseite herstellen
Verwenden Sie die vom Selenium WebDriver-Objekt bereitgestellte get() -Methode, um die Zielseite aufzurufen. Die Datei scraper.py sollte nun wie folgt aussehen:
from selenium import webdriver
# Chrome-Treiber initialisieren
driver = webdriver.Chrome()
# URL der Zielseite
url = "https://www.aliexpress.com/w/wholesale-ergonomic-chair.html?spm=a2g0o.productlist.search.0"
# Verbindung zur Zielseite herstellen
driver.get(url)
# Scraping-Logik...
# Treiber schließen
driver.quit()
Setzen Sie einen Debugging-Haltepunkt in die letzte Zeile und starten Sie das Skript mit dem Debugger. Der gesteuerte Chrome-Browser sollte sich automatisch wie unten gezeigt öffnen:
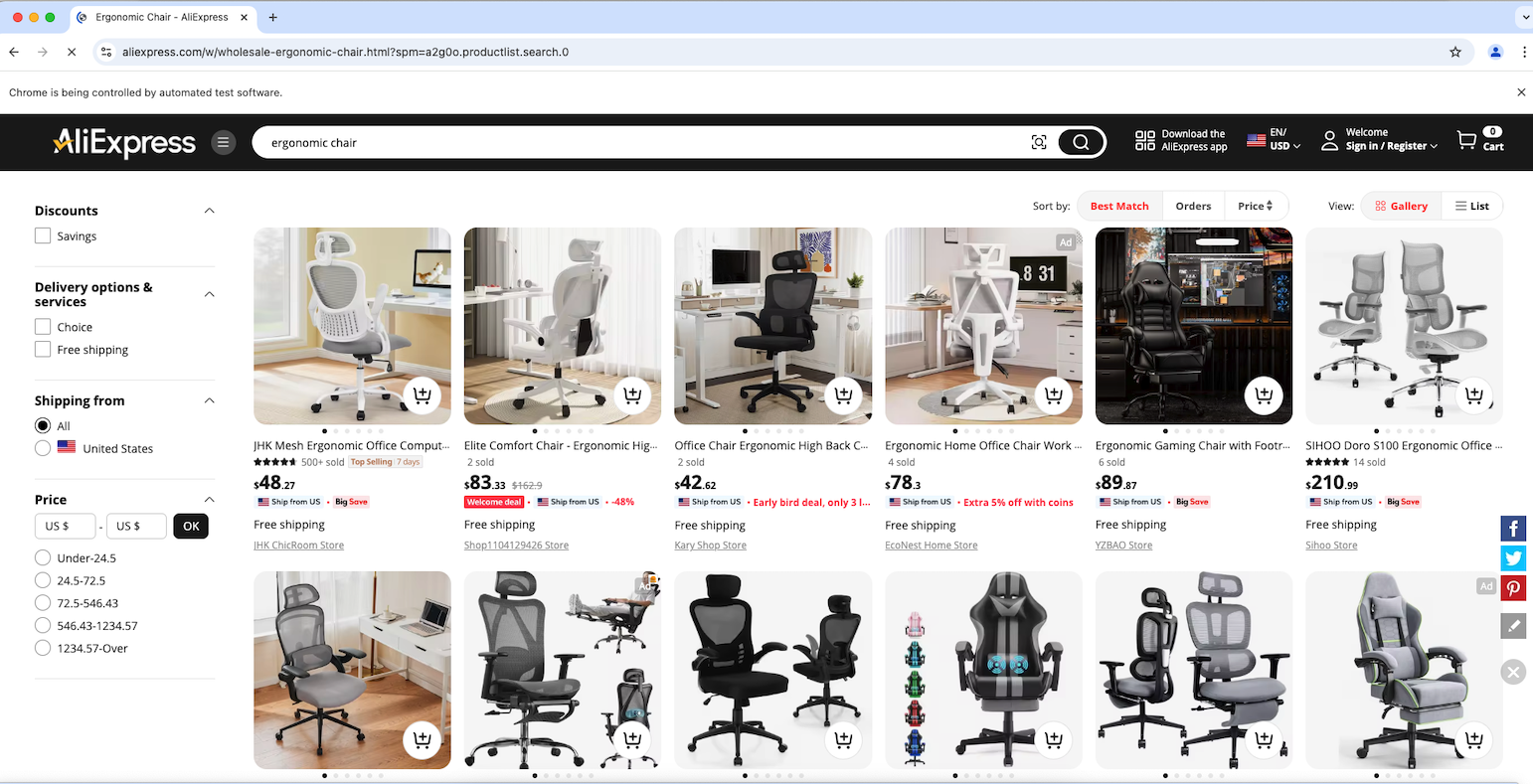
Großartig! Die Meldung „Chrome wird von automatisierter Testsoftware gesteuert“ zeigt an, dass Selenium Chrome wie konfiguriert erfolgreich steuert.
Schritt 5: Wählen Sie die Produktelemente aus
Da die AliExpress-Produktseite mehrere Produkte enthält, müssen Sie zunächst eine Datenstruktur initialisieren, um die gescrapten Daten zu speichern. Zu diesem Zweck eignet sich ein Array perfekt:
products = []
Um sicherzustellen, dass Ihr Scraper auch dann weiter funktioniert, wenn sich das Layout der Website ändert, sollten Sie eine Hilfsfunktion erstellen, die Ihre Selektoren widerstandsfähiger gegen diese Änderungen macht:
def find_element_smart(parent, by_list):
"""Probieren Sie mehrere Selektoren aus, bis ein Element gefunden wird"""
for by_type, selector in by_list:
try:
element = parent.find_element(by_type, selector)
if element.is_displayed():
return element
except:
continue
return None
Die Funktion find_element_smart() durchläuft eine Liste von by_list-Selektorstrategien, um ein Element innerhalb eines bestimmten übergeordneten Elements zu finden. Sie probiert jedes Paar <by_type, selector> aus, bis sie ein sichtbares Element findet, und gibt es bei Erfolg zurück. Andernfalls gibt sie None zurück, wenn kein passendes Element gefunden wird.
Als Nächstes untersuchen Sie die HTML-Elemente der Produkte auf der Seite, um zu verstehen, wie sie ausgewählt werden, um den Typ der darin enthaltenen Daten zu identifizieren und um zu bestimmen, wie diese Daten extrahiert werden können.
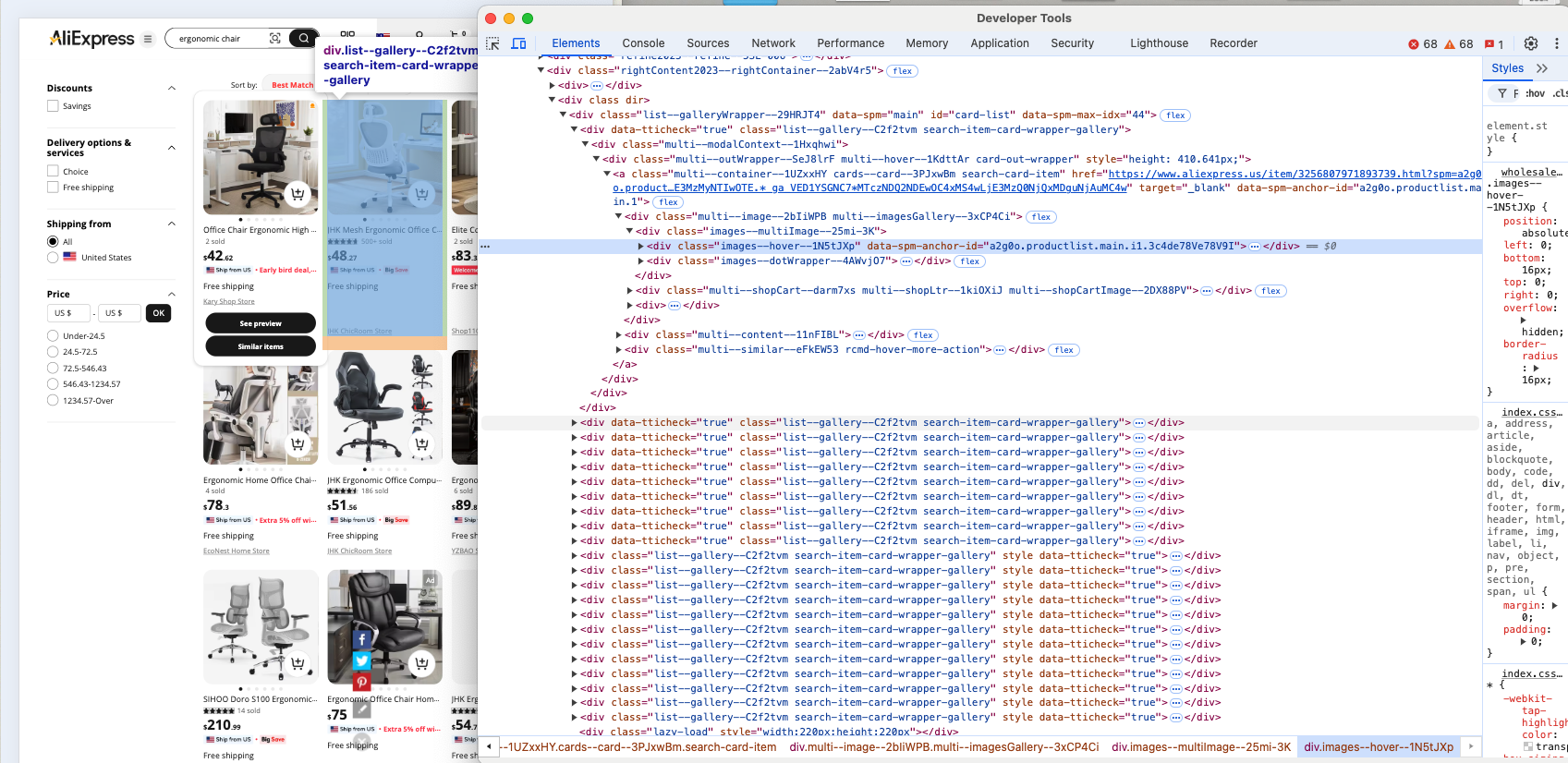
Es ist offensichtlich, dass jedes Produktelement ein .list-–gallery—-C2f2tvm -Knoten ist.
Beachten Sie, dass sich list--gallery--C2f2tvm jederzeit ändern kann, da es eine zufällig generierte Zeichenfolge enthält. Sie sollten sich daher bei der Elementauswahl nicht auf diese Klasse verlassen. Stattdessen sollten Sie zunächst Produkte anhand ihrer Struktur suchen, z. B. div-Elemente, die sowohl Bilder als auch Links enthalten. Wenn dies nicht funktioniert, suchen Sie Produkte anhand ihres Inhalts oder konzentrieren Sie sich auf spezifischere HTML-Elemente.
Implementieren Sie die Produktwahl-Logik wie folgt:
# Finden Sie zuerst Produkte anhand von Strukturmustern und greifen Sie dann auf Klassenmuster zurück.
product_selectors = [
(By.XPATH, "//div[.//img and .//a[contains(@href, 'item')]]"),
(By.XPATH, "//div[.//img and .//*[contains(text(), '$')]]"),
(By.CSS_SELECTOR, "div[class*='gallery']")
]
# Auf Produkte warten und diese abrufen
wait.until(EC.presence_of_all_elements_located((By.CSS_SELECTOR, "div[class*='gallery']")))
products_found = []
for selector_type, selector in product_selectors:
try:
elements = wait.until(EC.presence_of_all_elements_located((selector_type, selector)))
if elements:
products_found = elements
break
except:
continue
Der obige Code wendet die Selektorstrategie an, um Elemente auf der Seite mit generischen CSS-Selektoren abzurufen.
Fügen Sie den folgenden Import in Ihr Python-Skript ein:
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
Fügen Sie dann direkt nach der Initialisierung des WebDrivers, aber vor jeglicher Interaktion mit der Seite, eine WebDriverWait- Instanz ein:
wait = WebDriverWait(driver, 20)
Anstatt beim Web-Scraping dynamischer Websites wie AliExpress sofort nach Elementen auf einer Seite zu suchen, weist WebDriverWait den Scraper an, geduldig zu sein und bis zu einer bestimmten Zeit (in diesem Fall 20 Sekunden) zu warten, bis die Elemente angezeigt werden. Dies ist wichtig, da Webseiten Elemente mit unterschiedlichen Geschwindigkeiten laden und der Scraper ohne angemessene Wartezeit möglicherweise mit noch nicht geladenen Elementen arbeitet, was zu Fehlern führen kann.
Sie sind nun nur noch einen Schritt davon entfernt, AliExpress vollständig zu scrapen!
Schritt 6: Scrapen Sie die AliExpress-Produktelemente
Untersuchen Sie ein Produktelement, um seine HTML-Struktur zu verstehen:
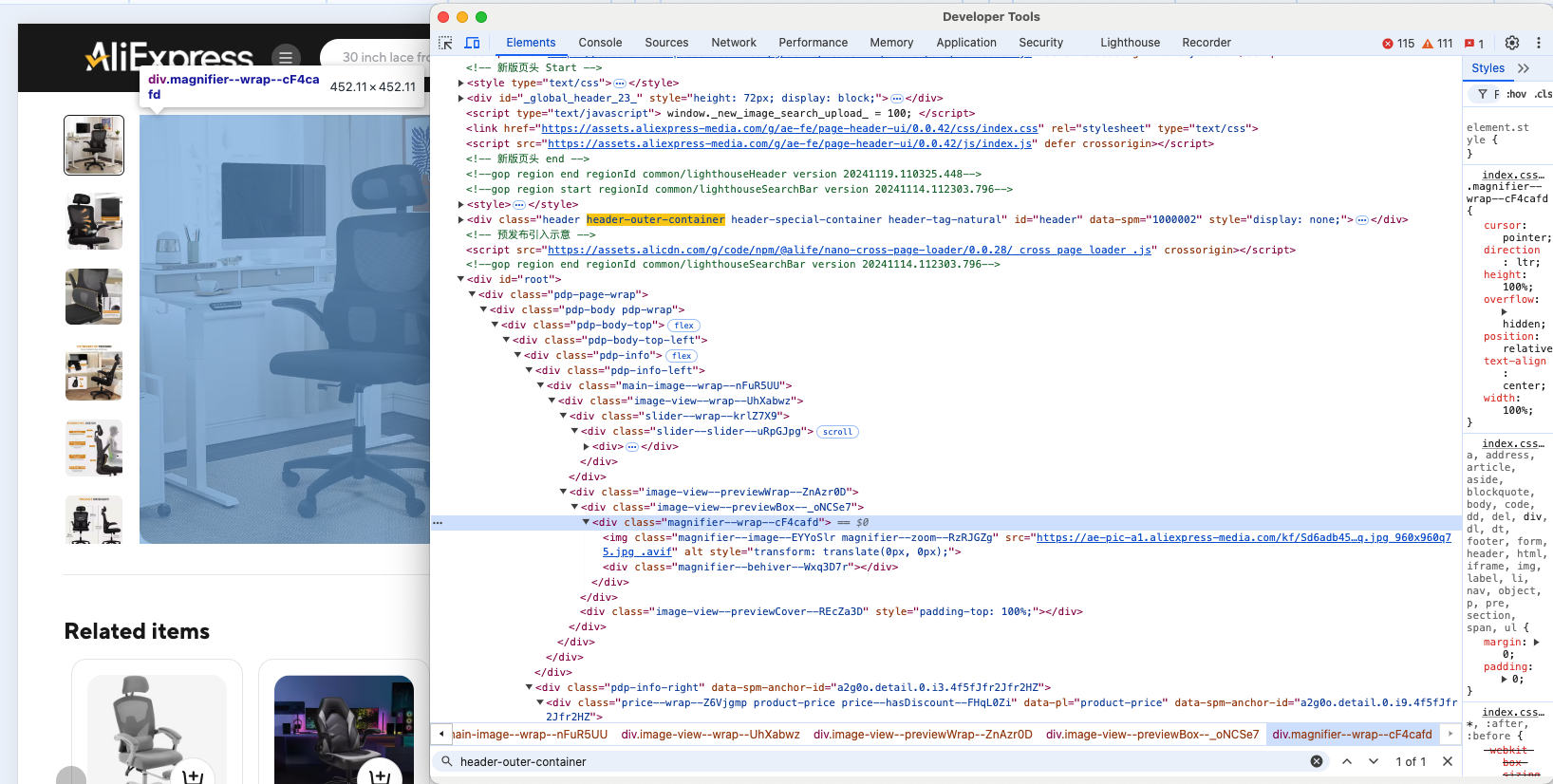
Es ist offensichtlich, dass Sie das Produktbild, die URL, den Namen oder Titel, den Preis und den Rabatt scrapen können.
Bevor Sie jedes Produkt scrapen, überprüfen Sie, ob es im Viewport sichtbar ist:
wait.until(EC.visibility_of(product))
Richten Sie nun Selektoren ein, um die Daten jedes Produkts zu scrapen. Verwenden Sie anstelle von spezifischen Klassennamen, die beschädigt werden könnten, Muster wie diese:
# Bild abrufen – nach Produktbildern anhand von Quellenmustern suchen
img_element = find_element_smart(product, [
(By.XPATH, ".//img[contains(@src, 'item') or contains(@src, 'product')]"),
(By.CSS_SELECTOR, "img[src*='item']"),
(By.CSS_SELECTOR, "img[class*='image']")
])
# URL abrufen – nach Produktlinks suchen
url_element = find_element_smart(product, [
(By.CSS_SELECTOR, "a[href*='item']"),
(By.XPATH, ".//a[contains(@href, 'product')]")
])
# Titel abrufen – zuerst nach dem längsten Textelement suchen
price_element = find_element_smart(product, [
(By.CSS_SELECTOR, "*[class*='price-sale']"),
(By.CSS_SELECTOR, "*[class*='price']"),
(By.XPATH, ".//*[contains(@class, 'price')]")
])
# Preis abrufen – nach Währungssymbolen/-mustern suchen
price_element = find_element_smart(product, [
(By.XPATH, ".//*[contains(text(), '$') or contains(text(), 'US') or contains(text(), 'GHS')]"),
(By.XPATH, ".//*[contains(@class, 'price')]")
])
# Versuchen Sie, einen Rabatt zu erhalten, falls verfügbar
discount_element = find_element_smart(product, [
(By.XPATH, ".//*[contains(text(), '%') or contains(text(), 'OFF')]"),
(By.CSS_SELECTOR, "[class*='discount']")
])
Die Funktion find_element() gibt das erste Element zurück, das dem angegebenen CSS-Selektor entspricht. Anschließend können Sie das Textattribut verwenden, um dessen Textinhalt zu extrahieren.
Fügen Sie die gescrapten Daten zum Array „products” hinzu und verwenden Sie sie, um ein Produktwörterbuch zu füllen:
products.append({
"image_url": img_element.get_attribute("src"),
"product_url": url_element.get_attribute("href"),
"product_title": title_element.text.strip(),
"product_price": price_element.text.strip(),
"product_discount": discount_element.text.strip() if discount_element else "N/A"
})
Ihre Logik zur Datenextraktion ist nun vollständig und einsatzbereit.
Schritt 7: Exportieren Sie die gescrapten Daten in eine CSV-Datei
In Ihrer aktuellen Konfiguration werden die gescrapten Daten im Array „products“ gespeichert. Damit sie für andere zugänglich und gemeinsam nutzbar sind, müssen Sie sie in ein für Menschen lesbares Format wie eine CSV-Datei exportieren. So können Sie eine CSV-Datei mit den gescrapten Daten erstellen und füllen:
# Daten in CSV schreiben
csv_file_name = "aliexpress_products.csv"
with open(csv_file_name, mode="w", newline="", encoding="utf-8") as csv_file:
fieldnames = ["image_url", "product_url", "product_title", "product_price", "product_discount"]
writer = csv.DictWriter(csv_file, fieldnames=fieldnames)
writer.writeheader()
for product in products:
writer.writerow(product)
Dieser Code erstellt eine CSV-Datei, die wie eine Tabellenkalkulation funktioniert – jedes Produkt erhält eine eigene Zeile, und verschiedene Details zum Produkt (Bild, URL, Titel, Preis und etwaige Rabatte) werden in separate Spalten eingetragen. Wenn Sie die fertige Datei „aliexpress_products.csv” öffnen, sehen Sie alle Ihre gescrapten AliExpress-Produktinformationen übersichtlich in Spalten angeordnet.
Importieren Sie abschließend aus der Python-Standardbibliothek die CSV -Bibliothek in Ihr Skript:
import csv
Schritt 8: Alles zusammenfügen
So sollte Ihr endgültiges Skript zum Scrapen aussehen, nachdem Sie den gesamten Code zusammengefügt haben:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import csv
def find_element_smart(parent, by_list):
"""Probieren Sie mehrere Selektoren aus, bis ein Element gefunden wird"""
for by_type, selector in by_list:
try:
element = parent.find_element(by_type, selector)
if element.is_displayed():
return element
except:
continue
return None
# Initialize driver
driver = webdriver.Chrome()
wait = WebDriverWait(driver, 20)
# Ziel-URL
url = "https://www.aliexpress.com/w/wholesale-ergonomic-chair.html?spm=a2g0o.productlist.search.0"
driver.get(url)
# Warten, bis die ersten Produkte geladen sind
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, "div[class*='gallery']")))
# Speicherort für die gescrapten Daten
products = []
# Produkte zuerst anhand von Mustern suchen, dann auf Klassenmuster zurückgreifen
product_selectors = [
(By.XPATH, "//div[.//img and .//a[contains(@href, 'item')]]"),
(By.XPATH, "//div[.//img and .//*[contains(text(), '$')]]"),
(By.CSS_SELECTOR, "div[class*='gallery']")
]
# Auf Produkte warten und diese abrufen
wait.until(EC.presence_of_all_elements_located((By.CSS_SELECTOR, "div[class*='gallery']")))
products_found = []
for selector_type, selector in product_selectors:
try:
elements = wait.until(EC.presence_of_all_elements_located((selector_type, selector)))
if elements:
products_found = elements
break
except:
continue
# Durchlaufen der gefundenen Produkte und Extrahieren der Daten
for product in products_found:
# Warten, bis das Produkt sichtbar und interaktiv ist
wait.until(EC.visibility_of(product))
# Bild abrufen – nach Produktbildern anhand von Quellmustern suchen
img_element = find_element_smart(product, [
(By.XPATH, ".//img[contains(@src, 'item') or contains(@src, 'product')]"),
(By.CSS_SELECTOR, "img[src*='item']"),
(By.CSS_SELECTOR, "img[class*='image']")
])
# URL abrufen – nach Produktlinks suchen
url_element = find_element_smart(product, [
(By.CSS_SELECTOR, "a[href*='item']"),
(By.XPATH, ".//a[contains(@href, 'product')]")
])
# Titel abrufen – zuerst nach dem längsten Textelement suchen
title_element = find_element_smart(product, [
(By.XPATH, ".//div[string-length(text()) > 20]"),
(By.XPATH, ".//*[contains(@class, 'title')]"),
(By.CSS_SELECTOR, "[class*='name']")
])
# Preis abrufen
price_element = find_element_smart(product, [
(By.CSS_SELECTOR, "*[class*='price-sale']"),
(By.CSS_SELECTOR, "*[class*='price']"),
(By.XPATH, ".//*[contains(@class, 'price')]")
])
if all([img_element, url_element, title_element, price_element]):
# Rabatt abrufen, falls verfügbar
discount_element = find_element_smart(product, [
(By.XPATH, ".//*[contains(text(), '%') or contains(text(), 'OFF')]"),
(By.CSS_SELECTOR, "[class*='discount']")
])
products.append({
"image_url": img_element.get_attribute("src"),
"product_url": url_element.get_attribute("href"),
"product_title": title_element.text.strip(),
"product_price": price_element.text.strip(),
"product_discount": discount_element.text.strip() if discount_element else "N/A"
})
# Ergebnisse speichern
csv_file_name = "aliexpress_products.csv"
with open(csv_file_name, mode="w", newline="", encoding="utf-8") as csv_file:
writer = csv.DictWriter(csv_file, fieldnames=["image_url", "product_url", "product_title", "product_price", "product_discount"])
writer.writeheader()
writer.writerows(products)
driver.quit()
Starten Sie nun den Scraper mit dem folgenden Befehl:
python Scraper.py
Das Skript sollte erfolgreich ausgeführt werden, und die Datei aliexpress_products.csv sollte die extrahierten Daten wie folgt enthalten:
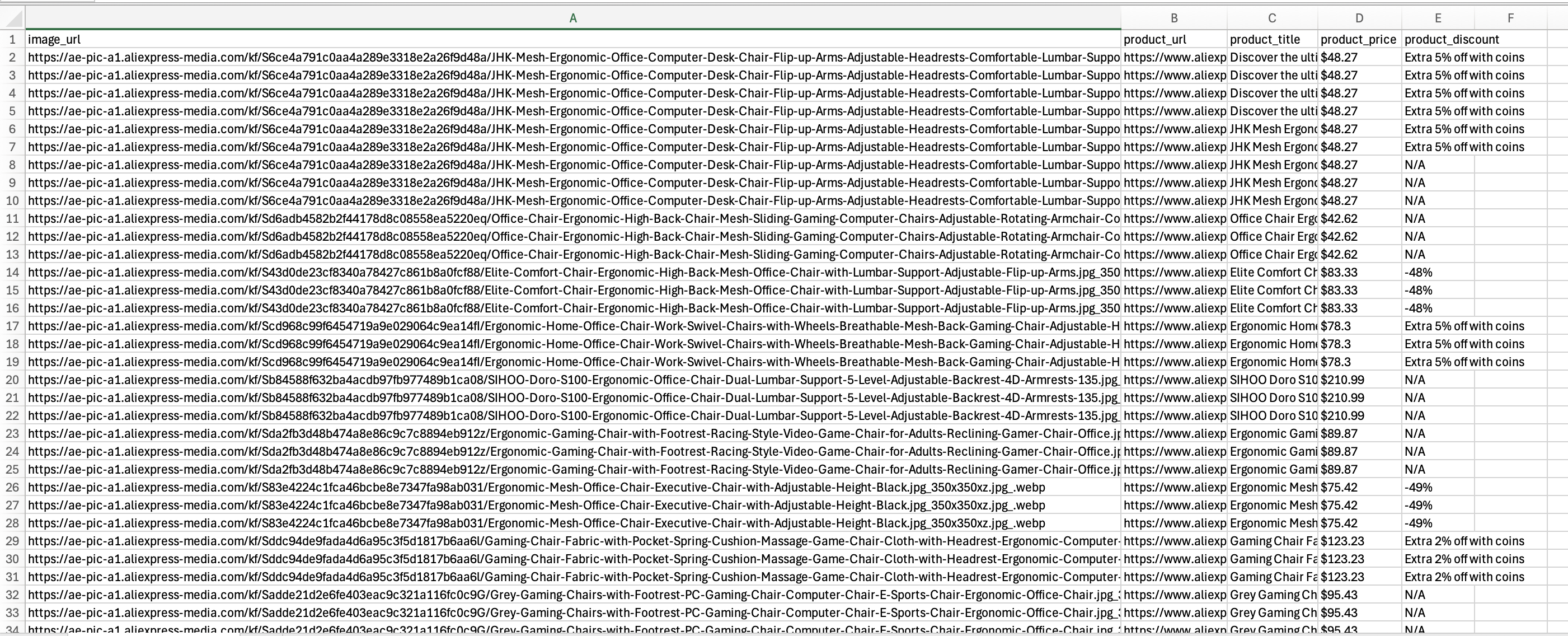
Nachdem Sie ein funktionsfähiges Scraping-Skript erstellt haben, können Sie mehrere zusätzliche Schritte durchführen. Dazu gehören die Automatisierung des Ausführungsprozesses und die Implementierung von Optimierungen, um sicherzustellen, dass der Scraper auch langfristig wertvolle Daten liefert.
Fazit
In diesem Leitfaden haben Sie erfahren, was ein AliExpress-Scraper ist und welche Arten von Daten er extrahieren kann. Außerdem haben Sie gelernt, wie Sie mit minimalem Code ein Python-Skript zum Scraping von AliExpress-Produkten erstellen können.
Das Scraping von AliExpress birgt jedoch einige Herausforderungen. Die Plattform verfügt über strenge Anti-Bot-Schutzmaßnahmen und verwendet Funktionen wie Paginierung, die den Scraping-Prozess zusätzlich erschweren. Die Entwicklung einer leistungsfähigen Alibaba-Scraping-Lösung kann eine ziemliche Herausforderung sein.
Unsere AliExpress Scraper API bietet eine spezialisierte Lösung, mit der Sie diese Herausforderungen beseitigen können. Mit einfachen API-Aufrufen können Sie nahtlos Daten von der Zielwebsite abrufen und gleichzeitig das Risiko einer Blockierung verringern. Benötigen Sie die Daten schnell?
Möchten Sie unsere Scraper-APIs ausprobieren oder unsere Datensätze erkunden? Erstellen Sie noch heute ein Bright Data-Konto und starten Sie die Gratis-Testversion!






