

In diesem Leitfaden erfahren Sie:
- Was CloudScraper ist und wofür es nützlich ist
- Warum Sie Proxys in Cloudscraper integrieren sollten
- Wie Sie dies in einer Schritt-für-Schritt-Anleitung tun können
- Wie Sie die Proxy-Rotation in Cloudscraper implementieren
- Wie Sie mit authentifizierten Proxys umgehen
- Wie man einen Premium-Proxy-Anbieter wie Bright Data nutzt
Lassen Sie uns loslegen!
Was ist CloudScraper?
CloudScraper ist ein Python-Modul, das entwickelt wurde, um die Anti-Bot-Seite von Cloudflare (allgemein bekannt als„I’m Under Attack Mode” oder IUAM) zu umgehen. Im Hintergrund wird es mit Requests implementiert, einem der beliebtesten Python-HTTP-Clients.
Diese Bibliothek ist besonders nützlich für das Scraping oder Crawling von Websites, die durch Cloudflare geschützt sind. Die Anti-Bot-Seite überprüft derzeit, ob der Client JavaScript unterstützt, aber Cloudflare könnte in Zukunft zusätzliche Techniken einführen.
Da Cloudflare seine Anti-Bot-Lösungen regelmäßig aktualisiert, wird auch die Bibliothek regelmäßig aktualisiert, um funktionsfähig zu bleiben.
Warum Proxys mit CloudScraper verwenden?
Cloudflare kann Ihre IP-Adresse blockieren, wenn Sie zu viele Anfragen stellen. Ebenso kann es komplexere Abwehrmaßnahmen auslösen, die selbst mit Tools wie CloudScraper nur schwer zu umgehen sind. Um dies zu vermeiden, benötigen Sie eine zuverlässige Methode, um Ihre IP-Adresse zu rotieren.
Hier kommt ein Proxy-Server ins Spiel. Proxys fungieren als Vermittler zwischen Ihrem Scraper und der Zielwebsite und maskieren Ihre echte IP-Adresse mit der IP des Proxy-Servers. Wenn eine IP gesperrt wird, können Sie schnell zu einem neuen Proxy wechseln und so einen unterbrechungsfreien Zugriff gewährleisten.
Proxys bieten zwei wesentliche Vorteile für das Web-Scraping mit CloudScraper:
- Erhöhte Sicherheit und Anonymität: Durch die Weiterleitung von Anfragen über einen Proxy bleibt Ihre wahre Identität verborgen, wodurch das Risiko einer Entdeckung verringert wird.
- Vermeidung von Sperren und Unterbrechungen: Proxys ermöglichen es Ihnen, IP-Adressen dynamisch zu wechseln, wodurch Sie Sperren und Ratenbegrenzer umgehen können.
Durch die Kombination von Proxys mit Tools wie CloudScraper können Sie eine robuste Web-Scraping-Konfiguration erstellen, die Risiken minimiert und die Effizienz maximiert. Dieser zweistufige Ansatz gewährleistet eine sichere und nahtlose Datenextraktion selbst von Websites mit fortschrittlichen Anti-Scraping-Maßnahmen.
Einrichten eines Proxys mit CloudScraper: Schritt-für-Schritt-Anleitung
In diesem Abschnitt erfahren Sie, wie Sie Proxys mit CloudScraper verwenden können!
Schritt 1: CloudScraper installieren
Sie können CloudScraper über das CloudScraper- Pip-Paket mit diesem Befehl installieren:
pip install -U cloudscraper
Beachten Sie, dass Cloudflare seine Anti-Bot-Engine ständig aktualisiert. Fügen Sie daher bei der Installation des Pakets die Option -U hinzu, um sicherzustellen, dass Sie die neueste Version erhalten.
Schritt 2: Cloudscraper initialisieren
Um zu beginnen, importieren Sie zunächst CloudScraper:
import cloudscraper
Erstellen Sie als Nächstes eine CloudScraper-Instanz mit der Methode create_scraper():
Scraper = cloudscraper.create_scraper()
Das Scraper-Objekt funktioniert ähnlich wie das Session- Objekt aus der Requests-Bibliothek. Insbesondere ermöglicht es Ihnen, HTTP-Anfragen zu stellen und dabei die Anti-Bot-Maßnahmen von Cloudflare zu umgehen.
Schritt 3: Proxy integrieren
Da CloudScraper auf Requests basiert, funktioniert die Integration von Proxys genauso wiein Requests. Wenn Sie mit diesem Verfahren nicht vertraut sind, lesen Sie unser Tutorial zum Einrichten eines Proxys in Requests.
Um einen Proxy mit CloudScraper zu verwenden, müssen Sie ein Proxy -Wörterbuch definieren und es wie unten gezeigt an die get() -Methode übergeben:
proxies = {
"http": "<YOUR_HTTP_PROXY_URL>",
"https": "<YOUR_HTTPS_PROXY_URL>"
}
# Führen Sie eine Anfrage über den angegebenen Proxy durch.
response = scraper.get("<YOUR_TARGET_URL>", proxies=proxies)
Der Parameter proxies in der Methode get() wird an Requests weitergegeben. Dadurch kann der HTTP-Client Ihre Anfrage je nach Protokoll Ihrer Ziel-URL über den angegebenen HTTP- oder HTTPS-Proxy-Server weiterleiten.
Schritt 4: Testen Sie die Einrichtung der CloudScraper-Proxy-Integration
Zu Demonstrationszwecken verwenden wir den Endpunkt /ip des HTTPBin-Projekts. Dieser Endpunkt gibt die IP-Adresse des Aufrufers zurück. Wenn alles wie erwartet funktioniert, sollte die Antwort die IP-Adresse des Proxy-Servers anzeigen.
Zum Testen der Einrichtung können Sie eine Proxy-Server-IP aus einer kostenlosen Proxy-Liste beziehen.
Warnung: Kostenlose Proxys sind oft unzuverlässig, sammeln Daten und sind potenziell unsicher – insbesondere, wenn sie nicht von einem der besten Proxy-Anbieter auf dem Markt stammen. Verwenden Sie sie daher nur zu Bildungszwecken.
Angenommen, dies ist die URL für Ihren Proxy-Server:
http://202.159.35.121:443
So können Sie ihn in CloudScraper integrieren:
import cloudscraper
# Erstellen Sie eine CloudScraper-Instanz.
scraper = cloudscraper.create_scraper()
# Geben Sie Ihren Proxy an.
proxies = {
"http": "http://202.159.35.121:443",
"https": "http://202.159.35.121:443"
}
# Eine Anfrage über den Proxy stellen
response = Scraper.get("https://httpbin.io/ip", proxies=proxies)
# Die Antwort vom Endpunkt "/ip" ausgeben
print(response.text)
Bei korrekter Einrichtung sollte eine Antwort wie die folgende angezeigt werden:
{
"origin": "202.159.35.121:1819"
}
Beachten Sie, dass die IP in der Antwort wie erwartet mit der IP des Proxy-Servers übereinstimmt.
Hinweis: Kostenlose Proxy-Server sind oft nur von kurzer Dauer. Daher funktioniert der im folgenden Beispiel verwendete Proxy möglicherweise nicht mehr, wenn Sie diesen Artikel lesen.
Gut gemacht! Sie haben eine einfache CloudScraper-Proxy-Integration abgeschlossen.
So implementieren Sie eine Proxy-Rotation
Die Verwendung eines Proxys mit Cloudscraper hilft dabei, Ihre IP-Adresse zu verbergen. Zielseiten können jedoch weiterhin IPs blockieren. Dies geschieht, wenn zu viele Anfragen von derselben Adresse kommen, unabhängig davon, ob es sich um Ihre eigene IP oder die des Proxys handelt.
Um IP-Sperren zu vermeiden, ist es wichtig, Ihre Proxy-IPs regelmäßig zu rotieren. Indem Sie Ihre Anfragen auf mehrere IP-Adressen verteilen, können Sie Ihren Traffic so erscheinen lassen, als käme er von verschiedenen Benutzern. Das verringert die Wahrscheinlichkeit einer Erkennung.
Um die Proxy-Rotation zu implementieren, rufen Sie zunächst eine Liste von Proxys von einem zuverlässigen Anbieter ab. Speichern Sie diese in einem Array:
proxy_list = [
{"http": "<YOUR_PROXY_URL_1>", "https": "<YOUR_PROXY_URL_1>"},
# ...
{"http": "<IHRE_PROXY_URL_n>", "https": "<IHRE_PROXY_URL_n>"},
]
Verwenden Sie anschließend die Methode random.choice(), um einen Proxy aus der Liste zufällig auszuwählen:
random_proxy = random.choice(proxy_list)
Vergessen Sie nicht, random aus der Python-Standardbibliothek zu importieren:
import random
Danach legen Sie einfach den zufällig ausgewählten Proxy in der get() -Anfrage fest:
response = Scraper.get("<YOUR_TARGET_URL>", proxies=random_proxy)
Wenn alles korrekt eingerichtet ist, verwendet die Anfrage bei jedem Durchlauf einen anderen Proxy aus der Liste. Hier ist der vollständige Code:
import cloudscraper
import random
# Erstellen Sie eine Cloudscraper-Instanz.
scraper = cloudscraper.create_scraper()
# Liste der Proxy-URLs (durch tatsächliche Proxy-URLs ersetzen)
proxy_list = [
{"http": "<YOUR_PROXY_URL_1>", "https": "<YOUR_PROXY_URL_1>"},
# ...
{"http": "<IHRE_PROXY-URL_n>", "https": "<IHRE_PROXY-URL_n>"},
]
# Wähle zufällig einen Proxy aus der Liste aus
random_proxy = random.choice(proxy_list)
# Stelle eine Anfrage über den zufällig ausgewählten Proxy
# (ersetze durch die tatsächliche Ziel-URL)
response = scraper.get("<DEINE_ZIEL-URL>", proxies=random_proxy)
Herzlichen Glückwunsch! Sie haben nun die Proxy-Rotation in Cloudscraper integriert.
Verwenden Sie „Authentifizierte Proxys” in CloudScraper
Die meisten Anbieter stellen authentifizierte Proxy-Server bereit, auf die nur zahlende Benutzer zugreifen können. In der Regel müssen Sie einen Benutzernamen und ein Passwort angeben, um auf diese Proxy-Server zugreifen zu können.
Um einen Proxy in CloudScraper zu authentifizieren, müssen Sie die erforderlichen Anmeldedaten direkt in die Proxy-URL einfügen. Das Format für die Benutzernamen- und Passwortauthentifizierung lautet wie folgt:
<PROXY_PROTOCOL>://<YOUR_USERNAME>:<YOUR_PASSWORD>@<PROXY_IP_ADDRESS>:<PROXY_PORT>
Mit diesem Format würde Ihre CloudScraper-Proxy-Konfiguration wie folgt aussehen:
import cloudscraper
# Erstellen Sie eine Cloudscraper-Instanz.
scraper = cloudscraper.create_scraper()
# Definieren Sie Ihren authentifizierten Proxy
proxies = {
"http": "<PROXY_PROTOCOL>://<IHR_BENUTZERNAME>:<IHR_PASSWORT>@<PROXY_IP_ADDRESS>:<PROXY_PORT>",
"https": "<PROXY_PROTOCOL>://<YOUR_USERNAME>:<YOUR_PASSWORD>@<PROXY_IP_ADDRESS>:<PROXY_PORT>"
}
# Führen Sie eine Anfrage über den angegebenen authentifizierten Proxy durch.
response = scraper.get("<IHRE_ZIEL-URL>", proxies=proxies)
Großartig! Sie sind nun bereit, um zu erfahren, wie Sie Premium-Proxys in Cloudflare verwenden können.
Premium-Proxys in Cloudscraper integrieren
Für zuverlässige Ergebnisse in Produktions-Scraping-Umgebungen sollten Sie Proxys von erstklassigen Anbietern wie Bright Data verwenden. Bright Data verfügt über ein hochwertiges Netzwerk mit mehr als 150 Millionen IPs in 195 Ländern und unterstützt alle vier Haupttypen von Proxys:
- Rechenzentrums-Proxys
- Residential-Proxys
- Mobile-Proxy
- ISP-Proxy
Mit Funktionen wie automatischer IP-Rotation, 100 % Verfügbarkeit und Sticky-IP-Sitzungen positioniert sich Bright Data als führender Proxy-Anbieter auf dem Markt.
Um die Proxys von Bright Data in CloudScraper zu integrieren, erstellen Sie ein Konto oder melden Sie sich an. Rufen Sie das Dashboard auf und klicken Sie in der Tabelle auf die Zone „Residential“:
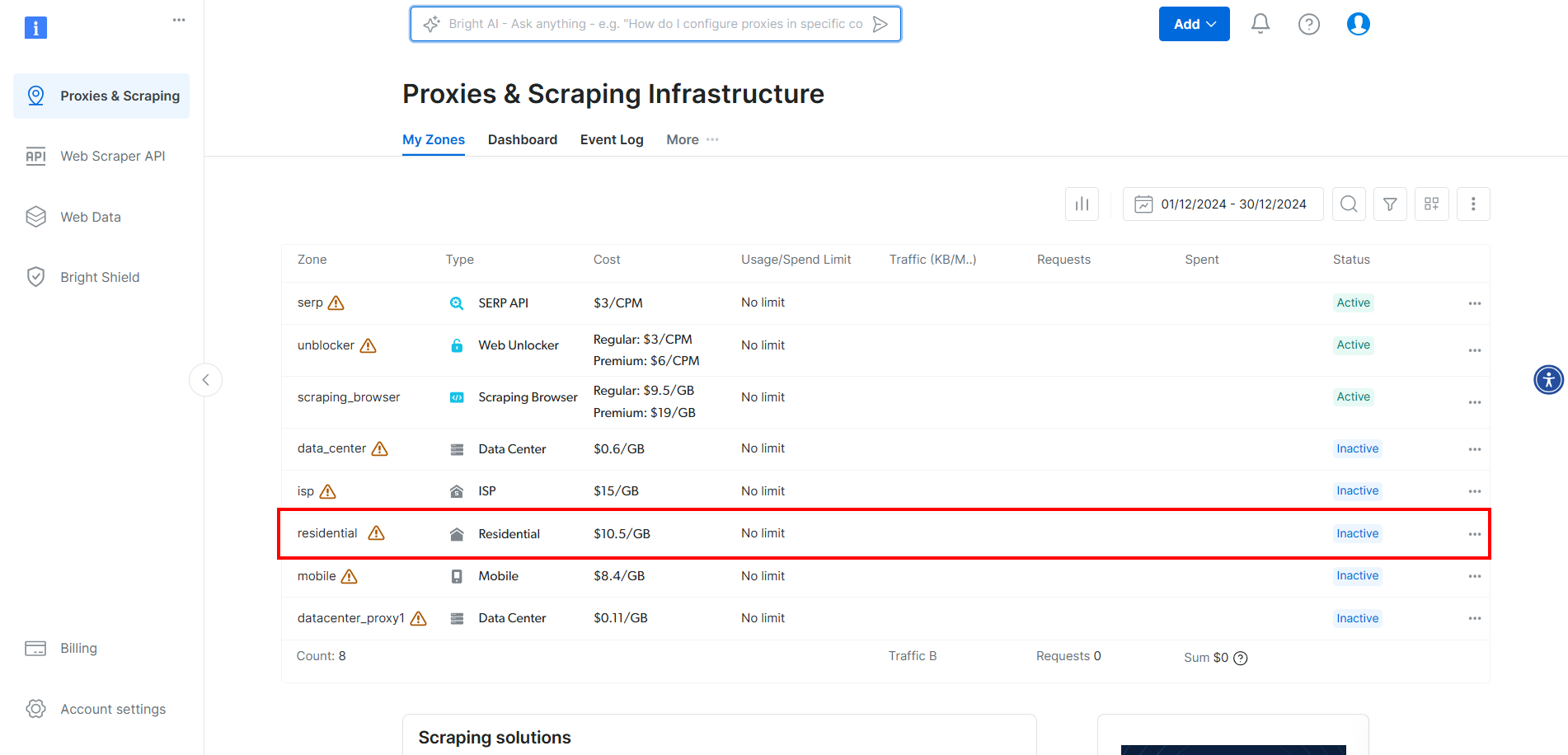
Aktivieren Sie hier die Proxys, indem Sie auf den Schalter klicken:
Das sollten Sie nun sehen:

Kopieren Sie im Abschnitt „Access Details“ den Proxy-Host, den Benutzernamen und das Passwort:
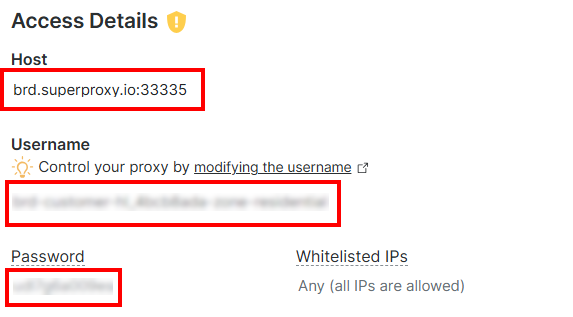
Ihre Bright Data-Proxy-URL sieht dann wie folgt aus:
http://<PROXY_USERNAME>:<PROXY_PASSOWRD>@brd.superproxy.io:33335
Integrieren Sie nun den Proxy wie folgt in Cloudscraper:
import cloudscraper
# CloudScraper-Instanz erstellen
scraper = cloudscraper.create_scraper()
# Den Bright Data-Proxy definieren
proxies = {
"http": "http://<PROXY_USERNAME>:<PROXY_PASSOWRD>@brd.superproxy.io:33335",
"https": "http://<PROXY_USERNAME>:<PROXY_PASSOWRD>@brd.superproxy.io:33335"
}
# Führen Sie eine Anfrage über den Proxy durch.
response = scraper.get("https://httpbin.io/ip", proxies=proxies)
# Geben Sie die Antwort aus.
print(response.text)
Beachten Sie, dass die Residential-Proxys von Bright Data automatisch rotieren. Sie erhalten also jedes Mal, wenn Sie das Skript ausführen, eine andere IP-Adresse.
Et voilà! Die CloudScraper-Proxy-Integration ist abgeschlossen.
Fazit
In diesem Tutorial haben Sie gesehen, wie Sie Cloudscraper mit Proxys für maximale Effektivität einsetzen können. Sie haben die Grundlagen der Proxy-Integration mit dem Python-Tool Cloudflare-bypass kennengelernt und auch fortgeschrittenere Techniken wie die Proxy-Rotation erkundet.
Mit hochwertigen Proxy-Servern von einem erstklassigen Anbieter wie Bright Data lassen sich viel leichter bessere Ergebnisse erzielen.
Bright Data kontrolliert die besten Proxy-Server der Welt und bedient Fortune-500-Unternehmen sowie über 20.000 Kunden. Das weltweite Proxy-Netzwerk umfasst:
- Datacenter-Proxys – Über 770.000 Rechenzentrums-IPs.
- Residential-Proxys– Über 150 Millionen Residential-IPs in mehr als 195 Ländern.
- ISP-Proxys – Über 700.000 ISP-IPs.
- Mobile-Proxy – Über 7 Millionen mobile IPs.
Insgesamt handelt es sich um eines der größten und zuverlässigsten Proxy-Netzwerke auf dem Markt.
Erstellen Sie noch heute ein kostenloses Bright Data-Konto, um unsere Proxy-Server zu testen.





