

In diesem Artikel erfahren Sie:
- Was Ruflo ist, welche Hauptfunktionen und Fähigkeiten es bietet und wo seine größten Einschränkungen liegen.
- Wie Sie diese Einschränkungen mit einer KI-fähigen Webdaten-Infrastrukturlösung wie Bright Data umgehen können.
- Die zwei wichtigsten Möglichkeiten, Bright Data und Ruflo in eine Claude Code- oder OpenAI Codex-Umgebung zu integrieren.
- Wie Sie mit Ruflo beginnen, indem Sie es in einem lokalen, von Claude Code betriebenen Projekt einrichten.
- Wie Sie die Websuche, Datenabfrage und Website-Interaktion von Bright Data auf Unternehmensebene über MCP in das Setup integrieren.
- Wie man dieselbe Integration mithilfe von Bright Data Claude-Skills erreicht.
- Was diese Ruflo + Bright Data-Konfiguration in einem agentischen Programmierassistenten ermöglicht.
Lassen Sie uns loslegen!
Eine Einführung in Ruflo: Die Agenten-Orchestrierungsplattform für Claude
Sie werden bald sehen, wie und warum Sie Ruflo mit den Funktionen von Bright Data zur Webdatenabfrage und -suche kombinieren sollten. Aber nehmen Sie sich zunächst einen Moment Zeit, um zu verstehen, was Ruflo ist und welche Vorteile es bietet!
Was ist Ruflo?
Ruflo (ehemals Claude Flow) ist ein KI-Orchestrierungs-Framework, das entwickelt wurde, um Claude Code (und OpenAI Codex) in ein funktionsreiches Multi-Agenten-Orchestrierungs-Framework zu verwandeln.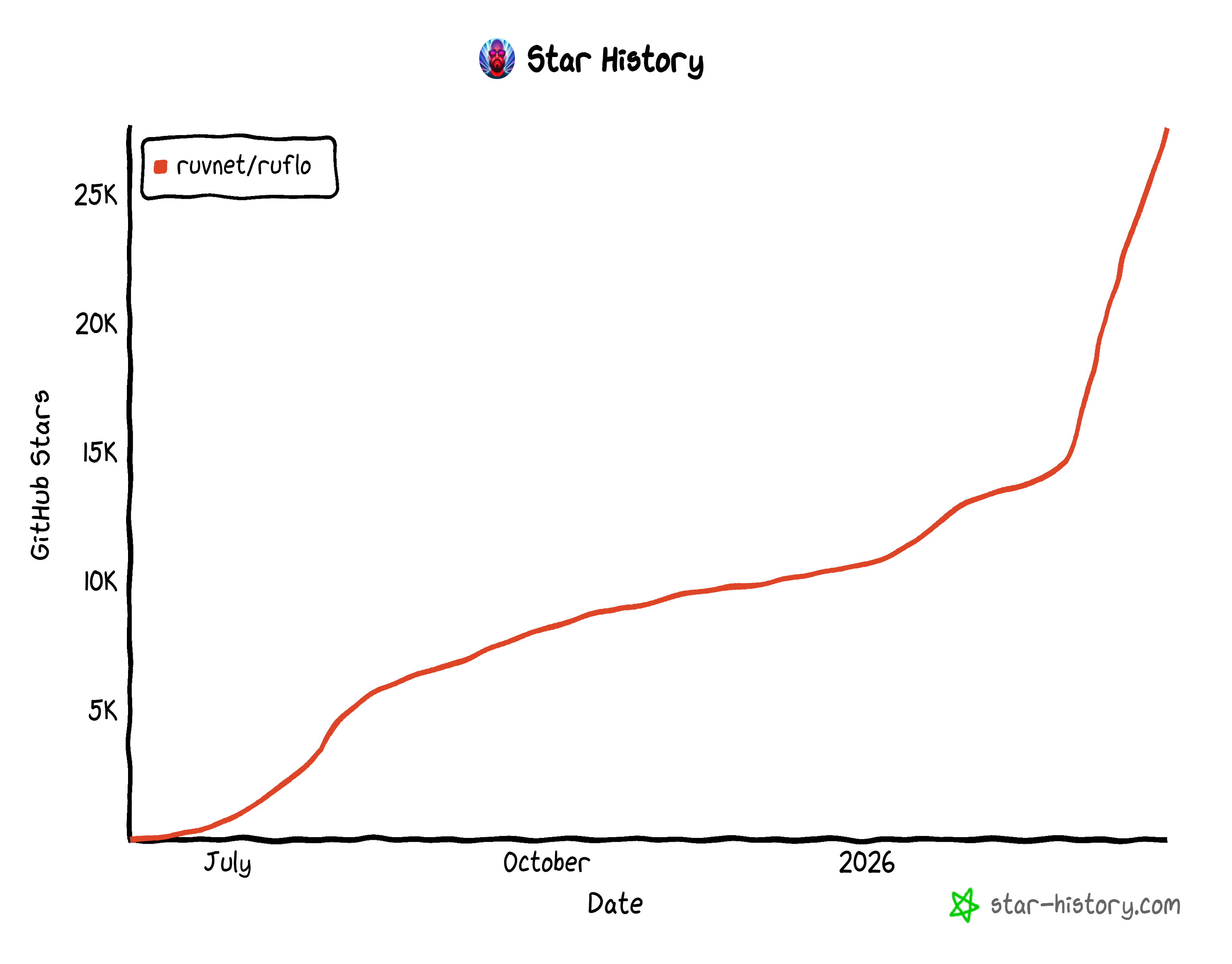
Im Einzelnen stattet es agentische Programmierassistenten mit einem koordinierten Satz von rund 100 spezialisierten KI-Agenten aus, die parallel arbeiten. Dies ermöglicht es Claude Code und OpenAI Codex, komplexe Softwareaufgaben über intelligentes Routing, gemeinsamen Speicher und selbstlernende Workflows zu bewältigen.
Als Open-Source-Projekt kann Ruflo über 27.000 GitHub-Stars und mehr als 6.000 Commits vorweisen. Dieses rasante Wachstum unterstreicht, wie schnell Ruflo in der Entwickler-Community an Bedeutung gewonnen hat.
Wie Ruflo KI-basierte Programmierassistenten auf die nächste Stufe hebt
Auf hoher Ebene sind die wichtigsten Funktionen von Ruflo:
- Multi-Agenten-Orchestrierung in großem Maßstab: Bereitstellung und Koordination von ~100 spezialisierten KI-Agenten, die parallel an komplexen Entwicklungsaufgaben arbeiten.
- Schwarmbasierte Zusammenarbeit: Agenten arbeiten in strukturierten „Schwärmen“ mit hierarchischer Koordination, Konsensmechanismen und gemeinsamen Zielen.
- Selbstlernendes und adaptives Routing: Lernt aus früheren Ausführungen und leitet Aufgaben mithilfe von Mustererkennung dynamisch an die effektivsten Agenten weiter.
- Persistenter Speicher und Wissensgraphen: Kombiniert Vektorsuche (HNSW), gemeinsamen Speicher und Wissensgraphen, um den Kontext über Sitzungen hinweg zu bewahren.
- Intelligente Kosten- und Leistungsoptimierung: Nutzt mehrstufiges Routing (WASM + LLMs), um die Latenz zu reduzieren und die API-Kosten um bis zu ~75 % zu senken.
- Multi-LLM-Unterstützung mit Failover: Funktioniert mit Claude, GPT, Gemini und lokalen Modellen und wählt automatisch den besten Anbieter pro Aufgabe aus.
- Produktionsreife Sicherheit und Erweiterbarkeit: Integrierte Schutzmechanismen (Prompt-Injection, Validierung) sowie ein Plugin-System zur Erweiterung von Agenten, Hooks und Workflows.
Dies führt zu einem wesentlichen Unterschied beim Vergleich von Claude Code mit und ohne Ruflo:
| Claude Code allein | Claude Code + Ruflo | |
|---|---|---|
| Agenten-Zusammenarbeit | Agenten arbeiten unabhängig | Agenten arbeiten über einen gemeinsamen Speicher zusammen |
| Koordination | Manuelles Aufgabenmanagement | Von einer Königin geführte Hierarchie mit automatisierter Koordination |
| Schwarmintelligenz | Nicht verfügbar | Kollektive Intelligenz über Agenten hinweg |
| Konsens | Keine Entscheidungen durch mehrere Agenten | Fehlertolerante Abstimmung nach Mehrheitsprinzip |
| Speicher | Nur für die Sitzung | Persistenter Vektorspeicher + Wissensgraph |
| Vektordatenbank | Keine | RuVector PostgreSQL, schnelle Suche und hohe QPS |
| Wissensgraph | Flache Listen | Hebt wichtige Erkenntnisse mithilfe von PageRank und Community-Erkennung hervor |
| Kollektives Gedächtnis | Kein gemeinsames Wissen | Gemeinsame Wissensbasis für alle Agenten |
| Lernen | Statisch, keine Anpassung | Selbstlernend mit schneller Anpassung und Wissenstransfer |
| Agenten-Scoping | Nur ein einzelnes Projekt | Mehrstufiger Speicher (Projekt/lokal/Benutzer) mit agentenübergreifender Übertragung |
| Aufgabenverteilung | Manuelle Agentenauswahl | Intelligente Zuweisung basierend auf erlernten Mustern |
| Komplexe Aufgaben | Manuelle Aufteilung erforderlich | Automatische Aufteilung über mehrere Bereiche |
| Hintergrund-Worker | Keine | Automatische Zuweisung bei Auslösern wie Dateiänderungen oder Mustern |
| LLM-Anbieter | Nur Anthropic | Mehrere Anbieter mit Failover und Kostenoptimierung |
| Sicherheit | Standardschutz | Gehärtet: Validierung, Verschlüsselung, CVE-Abwehr |
| Leistung | Basis | Schneller durch parallele Swarms und intelligentes Routing |
Größte Einschränkungen und wie man sie angeht
Unabhängig davon, wie umfangreich und vielseitig die rund 100 Agenten und die Gesamtfunktionen von Ruflo sind, gibt es eine grundlegende Einschränkung. Diese liegt in der Natur der LLMs selbst. Diese Modelle werden auf statischen Datensätzen trainiert, die an einem bestimmten Zeitpunkt enden, was ihr Wissen von Natur aus begrenzt.
Sicher, Ruflo enthält einen speziellen Browser-Automatisierungsagenten für die Websuche, Interaktion und Datenextraktion. Das Problem ist jedoch, dass die meisten Websites heutzutage über Anti-Bot-Systeme verfügen, die automatisierte Anfragen blockieren. Dazu gehören auch Anfragen von KI-gesteuerten Browser-Agenten. Daher kann die Wissensabfrage von Ruflo fehlschlagen oder nur auf einen Teil der benötigten Inhalte zugreifen.
Das ist ein kritisches Problem, denn genaues, aktuelles und kontextbezogenes Wissen ist es, was Multi-Agenten-Systeme wirklich effektiv macht. Um dieses Problem zu lösen, benötigt Ihr KI-Programmierassistent Tools, die speziell für die Live-Websuche, Datenextraktion und ungehinderte Webinteraktion entwickelt wurden.
Genau das bietet Bright Data!
Bright Data Web-Daten-Tools als Lösung
Als führende Webdatenplattform auf dem Markt bietet Bright Data KI-Agent-fähige Tools wie:
- SERP-API: Sammeln Sie Suchmaschinenergebnisse von Google, Bing und anderen, um fundierte Antworten zu generieren.
- Web Unlocker API: Greifen Sie auf rohen HTML- oder Markdown-Code von jeder Website zu und umgehen Sie dabei CAPTCHAs, IP-Sperren und Anti-Bot-Maßnahmen.
- Browser-API: Steuern Sie einen Remote-Browser programmgesteuert für automatisierte, ungehinderte Interaktion mit jeder Website.
- Web-Scraping-APIs: Sammeln Sie strukturierte Daten von Plattformen wie Amazon, Instagram, LinkedIn, Yahoo Finance und vielen anderen.
- Crawl-API: Konvertieren Sie ganze Websites in strukturierte Datensätze für nachgelagerte KI-Workflows.
Was Bright Data auszeichnet, ist seine Infrastruktur auf Unternehmensniveau. Aufgebaut auf einem globalen Proxy-Netzwerk mit über 400 Millionen IPs in 195 Ländern, unterstützt es unbegrenzte Skalierbarkeit bei einer Verfügbarkeit von 99,99 % und einer Erfolgsquote von 99,95 %.
Bright Data arbeitet mit Ruflo zusammen, um Ihrem agentenbasierten Codierungssystem die Möglichkeit zu geben, Live-Webdaten zu erkunden, abzurufen und zu analysieren. All das in großem Maßstab und ohne auf Hindernisse zu stoßen!
So kombinieren Sie Bright Data und Ruflo: Zwei Ansätze
Technisch gesehen können Sie Bright Data mithilfe des Plugin-SDK direkt in Ruflo integrieren. Dazu müssten Sie benutzerdefinierte Tools definieren, die eine Verbindung zu jedem Bright-Data-Produkt herstellen, das Sie nutzen möchten. Das ist jedoch nicht der schnellste Ansatz!
Anstatt das Rad neu zu erfinden, ist es viel einfacher, auf Folgendes zu setzen:
- Bright Data Web MCP: Ein All-in-One-Open-Source-Server, der über 60 Tools für Websuche, Navigation, Datenextraktion und Interaktion ohne Blockaden bereitstellt.
- Bright Data Skills: Vorgefertigte Funktionen, die Ihrem Programmieragenten beibringen, wie man KI-gestütztes Web-Scraping, Suchen und das Abrufen strukturierter Daten durchführt. Sie beinhalten eine Verbindung zum Web MCP.
Diese können direkt zu Claude Code (oder OpenAI Codex) hinzugefügt werden, was zu einer einheitlichen Programmierumgebung führt, die sowohl Ruflo als auch Bright Data kombiniert. Das zugrunde liegende LLM kann dann Tools aus beiden Lösungen koordiniert und synergetisch nutzen.
Hinweis: Die folgenden Beispiele verwenden Claude Code, aber Sie können sie problemlos an OpenAI Codex anpassen.
Sehen wir uns nun an, wie Sie Claude Code mit Bright Data und Ruflo entweder über MCP oder Skills erweitern können. Aber richten Sie zuerst Ruflo ein!
Erste Schritte mit Ruflo
Befolgen Sie die nachstehenden Anweisungen, um zu erfahren, wie Sie Ruflo in Ihrem Programmierprojekt konfigurieren.
Voraussetzungen
Um diesem Abschnitt folgen zu können, stellen Sie sicher, dass Sie Folgendes haben:
- Claude Code lokal installiert und konfiguriert ist.
- Node.js 20+ ist lokal installiert (die neueste LTS-Version wird empfohlen).
Schritt 1: Ruflo konfigurieren
Erstellen Sie einen neuen Ordner für Ihr Programmierprojekt (z. B. bright-data-ruflo-project). Dort werden Sie Ruflo initialisieren. Wechseln Sie anschließend in Ihrem Terminal in diesen Ordner:
mkdir bright-data-ruflo-project
cd bright-data-ruflo-projectHinweis: Sie können auch von einem bestehenden Projektordner aus starten. In den meisten Fällen werden Sie dies tun. Sie fügen Ruflo zu Ihrem Projekt hinzu, um dessen Funktionen zu nutzen.
Führen Sie den folgenden Befehl in Ihrem Terminal aus, um den Ruflo-Installationsassistenten über npm zu starten:
npx ruflo@latest init --wizardDie Installation des Ruflo- Pakets kann einige Minuten dauern, haben Sie also bitte etwas Geduld.
Dies ist die Ausgabe, die Sie erhalten sollten: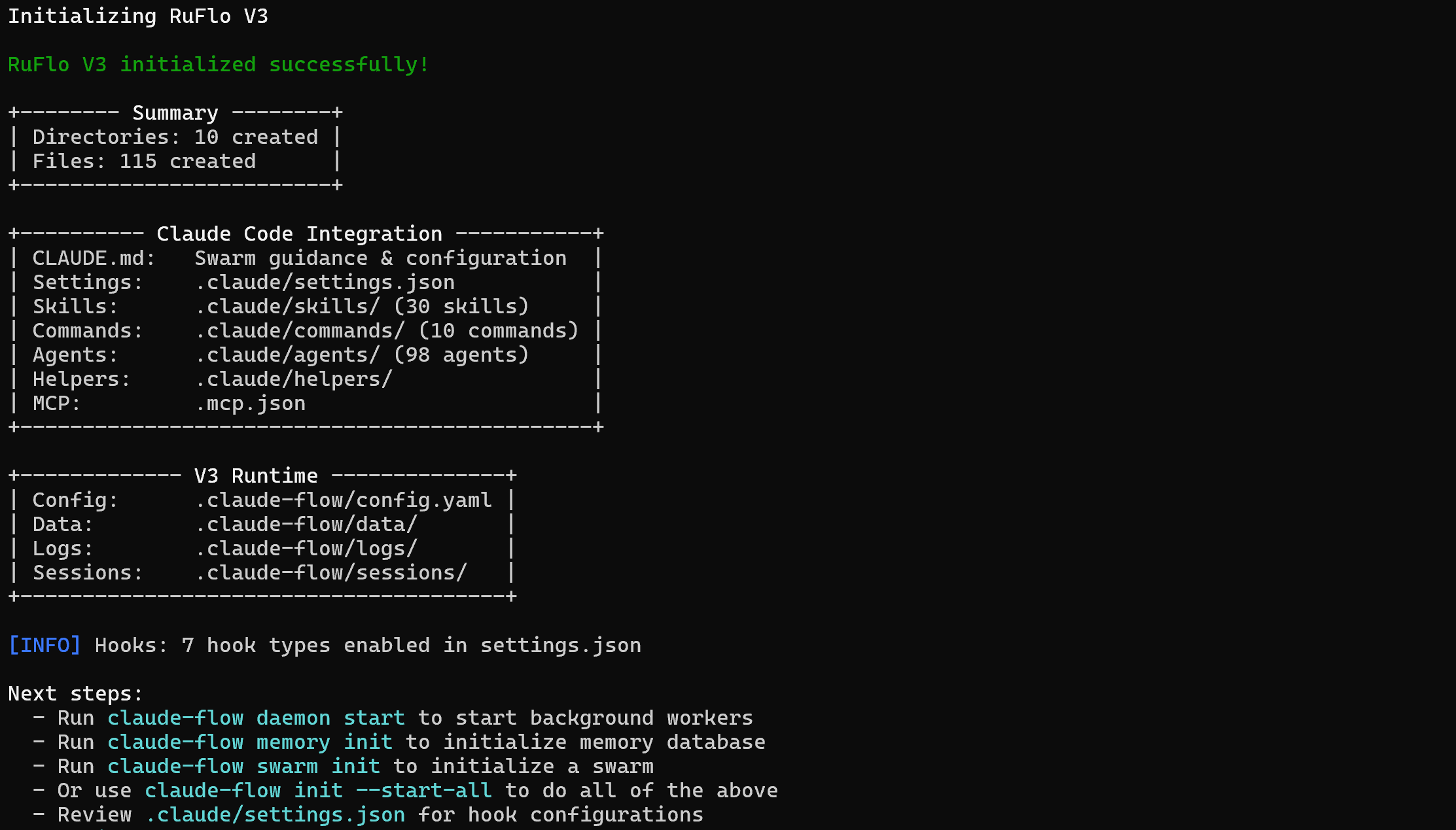
Hinweis: Die Ausgabe in der CLI könnte nahelegen, claude-flow-Befehle zur Initialisierung von Backend-Diensten, Speicherdatenbanken oder Swarms zu verwenden. Dies ist jedoch nicht korrekt. Bei der Installation von Ruflo über npm lautet der richtige Basisbefehl:
npx ruflo@latestDer Ordner Ihres Projekts enthält nun:
bright-data-ruflo-project/
├─── .claude/
│ ├─── agents/
│ ├─── commands/
│ ├─── helpers/
│ └─── skills/
├─── .claude-flow/
├─── .swarm/
├─── .mcp.json
└─── CLAUDE.mdIm Grunde enthält das „bright-data-ruflo-project“ alle Dateien, die Claude Code für den Zugriff auf neue Skills, Befehle und Agenten auf Projektebene benötigt. Mit anderen Worten: Ruflo ist vollständig in Ihre lokale Claude-Code-Konfiguration integriert. Gut gemacht!
Schritt 2: Ruflo starten
Ruflo hat mehrere Agenten, Befehle und Skills hinzugefügt. Damit Claude Code diese jedoch ausführen kann, müssen Sie Ruflo zunächst starten. Führen Sie dazu folgenden Befehl aus:
npx ruflo@latest startSie sollten eine Ausgabe wie diese sehen: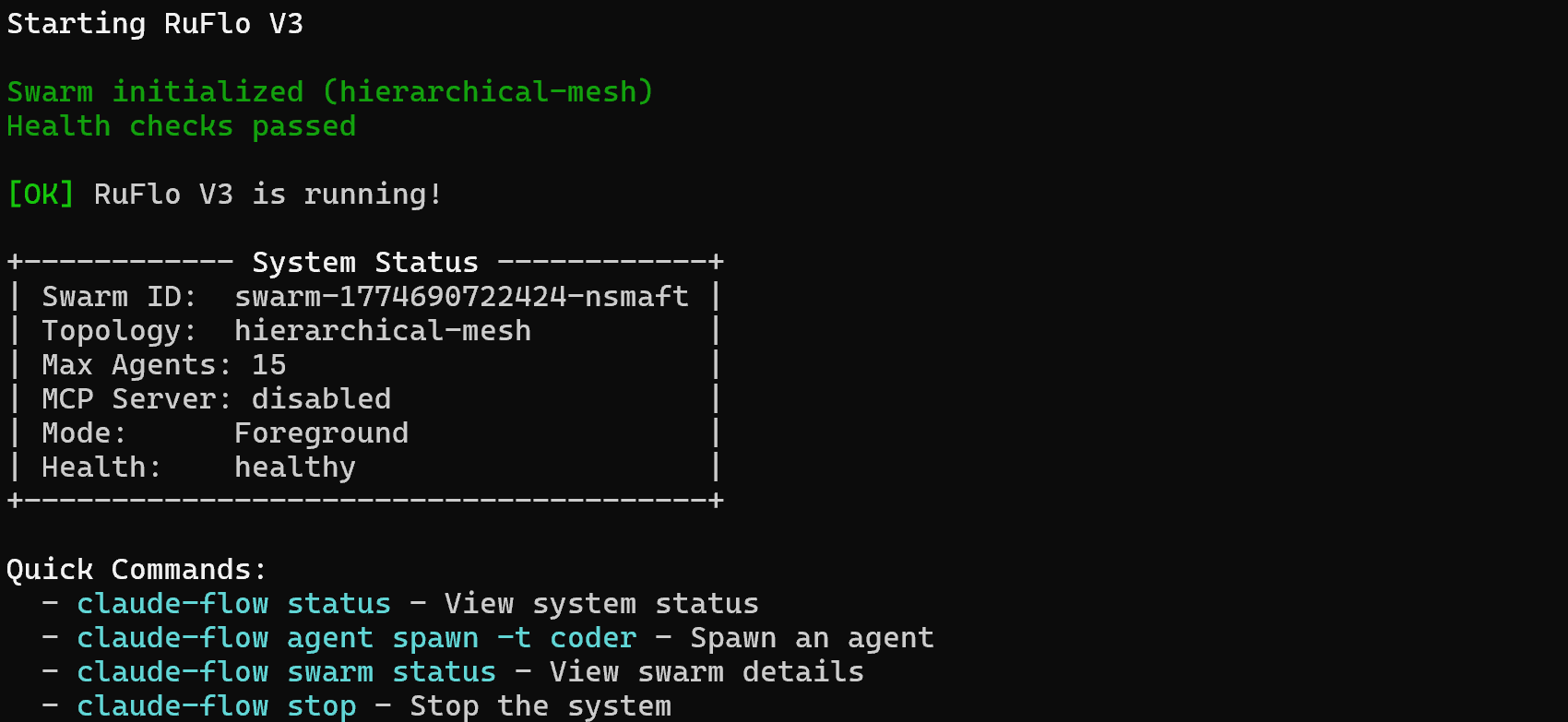
Fantastisch! Ihre Claude-Code-Konfiguration kann nun die erweiterten Funktionen von Ruflo nutzen.
Schritt 3: Überprüfen Sie die Integration
Starten Sie Claude Code in Ihrem Projektverzeichnis:
claudeMöglicherweise erhalten Sie eine Meldung wie diese:
Wählen Sie Option 1 oder Option 2. Auf diese Weise startet Claude Code den Ruflo-MCP-Server und stellt beim Start eine Verbindung zu ihm her.
Als Nächstes sehen Sie Protokolle, die deutlich zeigen, dass Ruflo in Claude Code verfügbar ist: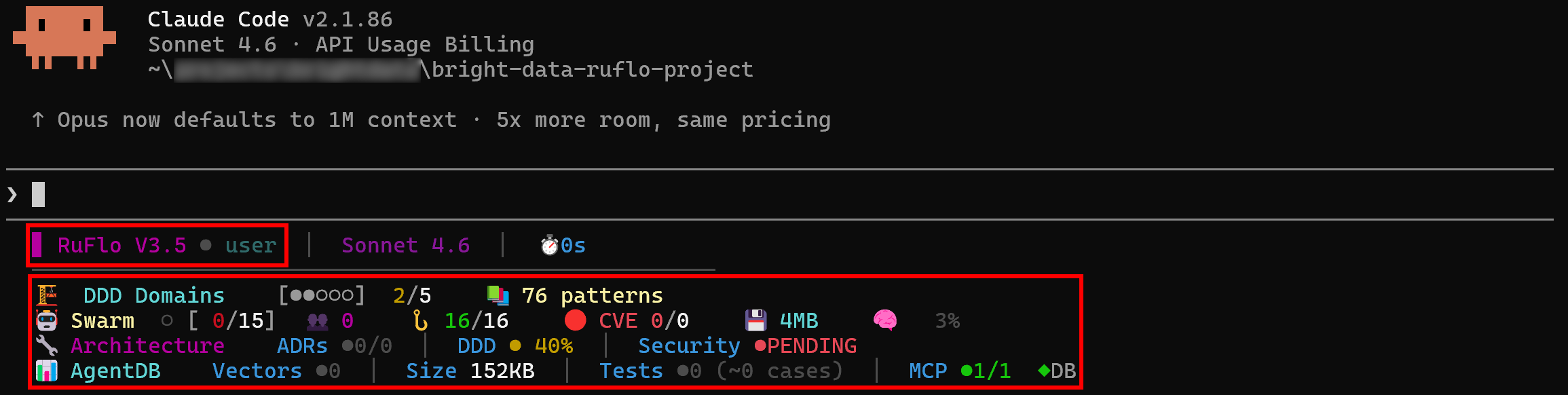
Geben Sie „/agent“ ein, und Sie sollten einige der zusätzlichen Ruflo-Befehle sehen:
Super! Claude Code hat erfolgreich eine Verbindung zu Ruflo hergestellt, was bestätigt, dass die Integration funktioniert.
Integrationsansatz Nr. 1: Ruflo MCP + Bright Data MCP
In diesem Abschnitt erfahren Sie, wie Sie Ihrem Claude Code-Setup über MCP sowohl Ruflo- als auch Bright Data-Funktionen hinzufügen können.
Voraussetzungen
Um diesen Abschnitt übersichtlich zu halten, gehen wir davon aus, dass Sie Bright Data Web MCP bereits in Ihr Claude Code-Setup integriert haben.
Falls Sie dies noch nicht getan haben, folgen Sie dem ausführlichen Tutorial„Integration von Claude Code mit Bright Datas Web-MCP“oder der Dokumentation„Claude Code MCP Server Integration“. Achten Sie darauf, die erforderliche Konfiguration in die lokale .mcp.json-Datei einzufügen, die von Ruflo während des init-Befehls erstellt wurde.
Kenntnisse über die Funktionsweise von MCP und die Verbindung von MCP-Servern mit Claude Code sind ebenfalls eine wichtige Voraussetzung.
Schritt 1: Überprüfen Sie die verfügbaren MCP-Server
Standardmäßig ist der Ruflo-MCP-Server in der lokalen .mcp.json-Datei konfiguriert. Diese Datei sollte auch die Konfiguration für die Verbindung mit dem Bright Data Web MCP enthalten.
Es wird erwartet, dass Claude Code beide MCP-Server automatisch erkennt und eine Verbindung zu ihnen herstellt. Um dies zu überprüfen, starten Sie Claude Code in Ihrem Projektordner und führen Sie den Befehl /mcp aus:
Sie sollten Folgendes sehen:
bright-data-web-mcp(oder den Namen, den Sie dem Bright Data Web MCP in der.mcp.json-Konfiguration gegeben haben).claude-flow(der Name des Ruflo-MCP-Servers).
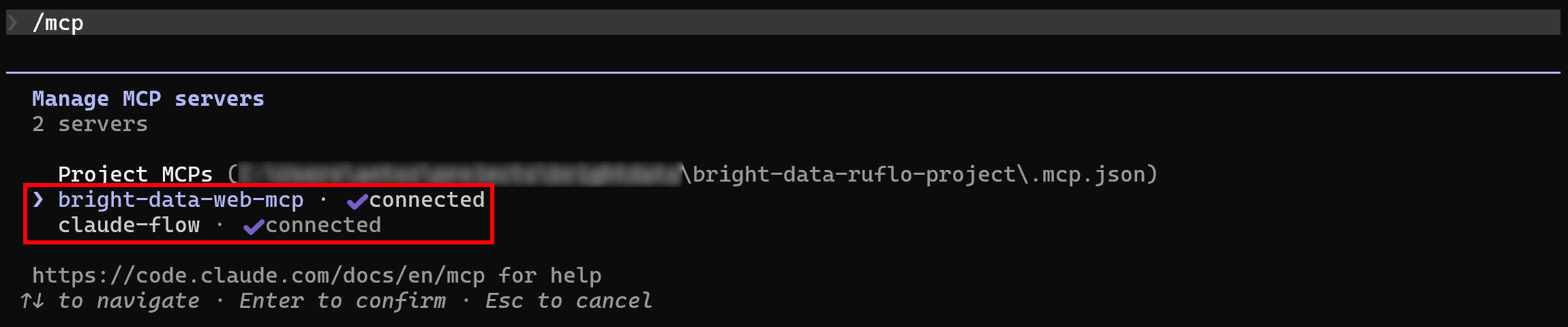
Großartig! Claude Code ist nun wie erwartet mit beiden MCP-Servern verbunden.
Schritt 2: Überprüfen Sie den Bright Data Web MCP-Server
Wählen Sie den Eintrag „bright-data-web-mcp“ (oder den Namen, den Sie ihm gegeben haben):
Wählen Sie die Option „Tools anzeigen“, um alle verfügbaren Tools zu sehen. Wenn Sie es im Pro-Modus konfiguriert haben, erhalten Sie alle über 65 Tools:
Andernfalls sehen Sie nur 4 Tools (scrape_as_markdown, search_engine und deren 2 Batch-Versionen).
Hervorragend! Der Bright Data Web MCP stellt seine Tools wie erwartet bereit.
Schritt 3: Überprüfen Sie den Ruflo MCP-Server
Wiederholen Sie den oben beschriebenen Vorgang, diesmal jedoch für das claude-flow MCP. Sie sollten Folgendes sehen:
Beachten Sie, dass das Ruflo MCP beeindruckende 254 Tools bereitstellt. Wow!
Integrationsansatz Nr. 2: Ruflo-Skills + Bright Data-Skills
Hier werden Sie durch den Prozess geführt, wie Sie Ihrem Claude-Code-Setup über Skills Ruflo- und Bright Data-Funktionen hinzufügen.
Voraussetzungen
Um diesen Abschnitt zu befolgen, stellen Sie sicher, dass Sie Folgendes haben:
- Claude Code auf einem Unix-basierten Betriebssystem (macOS, Linux oder WSL) eingerichtet ist.
- Git lokal installiert.
- Ein Bright Data-Konto mit einer eingerichteten Web Unlocker-Zone und einem konfigurierten API-Schlüssel.
- Grundlegendes Verständnis darüber, was Claude-Skills sind und wie man sie in Claude Code konfiguriert.
- Vertrautheit mit den Skills, die im offiziellen Bright Data Claude-Skill-Repository verfügbar sind.
Hinweis: Machen Sie sich vorerst keine Gedanken über die Einrichtung eines Bright Data-Kontos, da Sie im folgenden Schritt durch den Vorgang geführt werden.
Installieren Sie anschließend curl und jq, die beiden Voraussetzungen für die Bright Data Claude-Skills. Führen Sie unter macOS folgenden Befehl aus:
brew install curl jqEntsprechend führen Sie unter Linux folgenden Befehl aus:
sudo apt-get install curl jqStandardmäßig listet Claude Code nach der Einrichtung von Ruflo in Ihrem lokalen Projekt bereits dessen 118 Skills auf. Überprüfen Sie dies, indem Sie den Befehl /skills ausführen: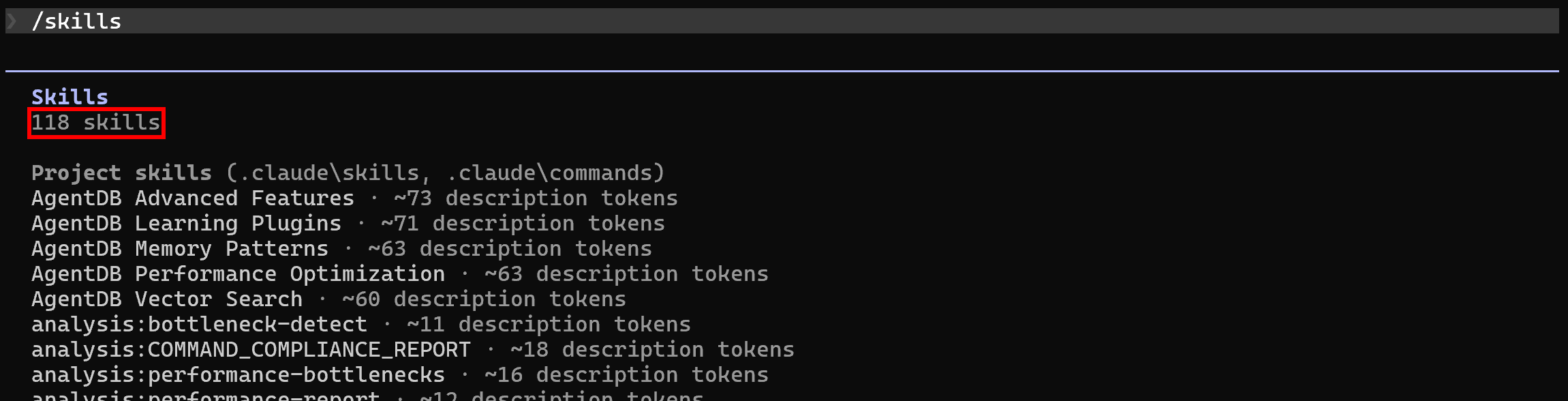
Schritt 1: Richten Sie Ihr Bright Data-Konto ein
Wie in der Dokumentation erläutert, müssen für die Bright Data Claude-Fähigkeiten die folgenden beiden Geheimnisse als globale Umgebungsvariablen festgelegt werden:
BRIGHTDATA_API_KEY: Ihr Bright Data-API-Schlüssel.BRIGHTDATA_UNLOCKER_ZONE: Der Name der in Ihrem Konto konfigurierten Web Unlocker-Zone.
Als Anleitung können Sie die Dokumentationsseite„Quick Start Guide for Bright Data’s Web Unlocker API“heranziehen. Alternativ befolgen Sie die nachstehenden Anweisungen.
Wenn Sie noch kein Bright Data-Konto haben, erstellen Sie eines. Andernfalls melden Sie sich einfach an. Rufen Sie das Control Panel auf und gehen Sie zur Seite „Proxies & Scraping“. Sehen Sie sich die Tabelle „My Zones“ an: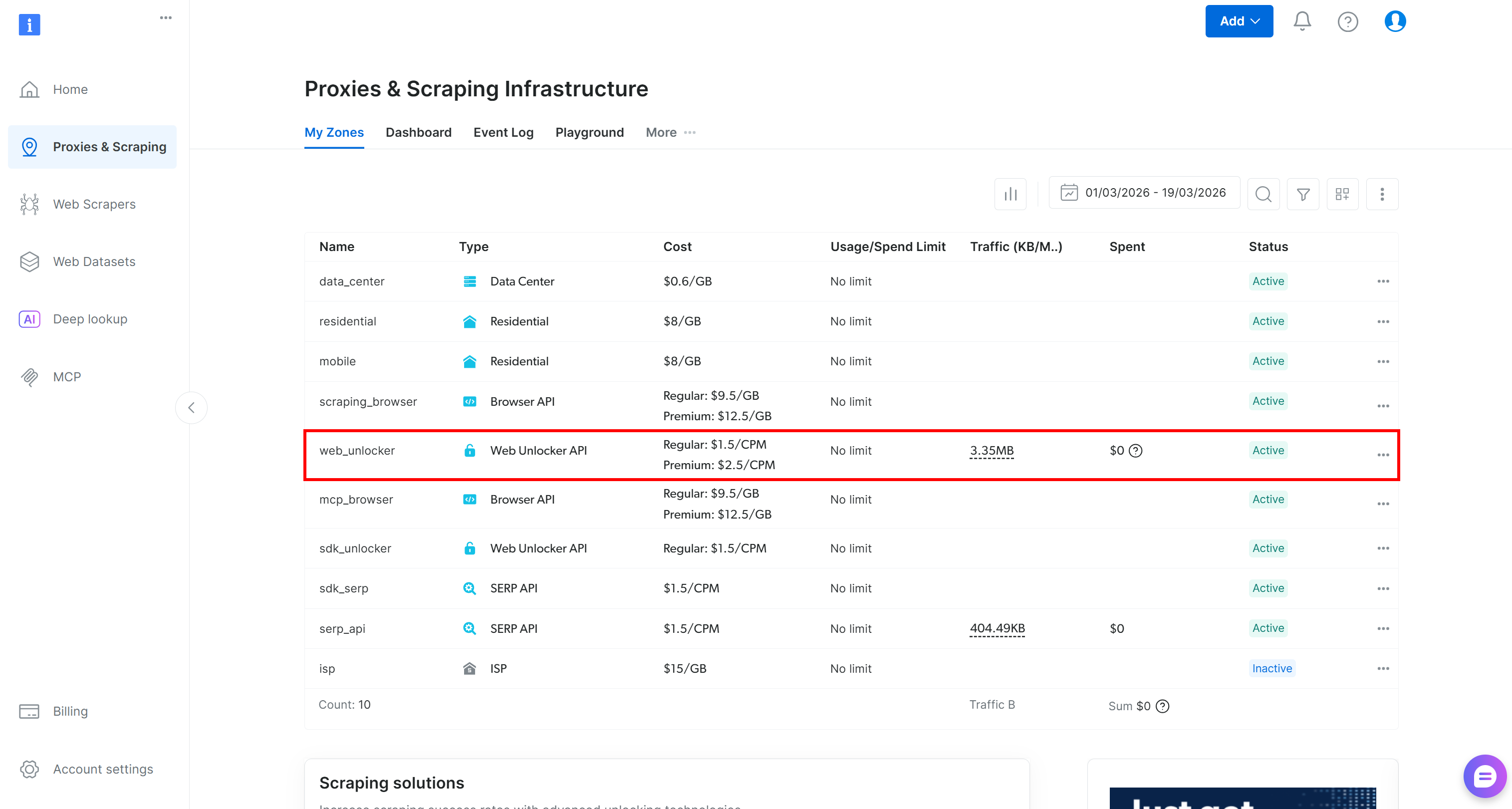
Wenn eine Web Unlocker API-Zone (z. B. web_unlocker) vorhanden ist, können Sie mit der Definition des API-Schlüssels fortfahren.
Falls diese fehlt, erstellen Sie eine neue Zone. Scrollen Sie dazu zur Karte „Unblocker API“, klicken Sie auf „Zone erstellen“ und folgen Sie den Anweisungen des Assistenten.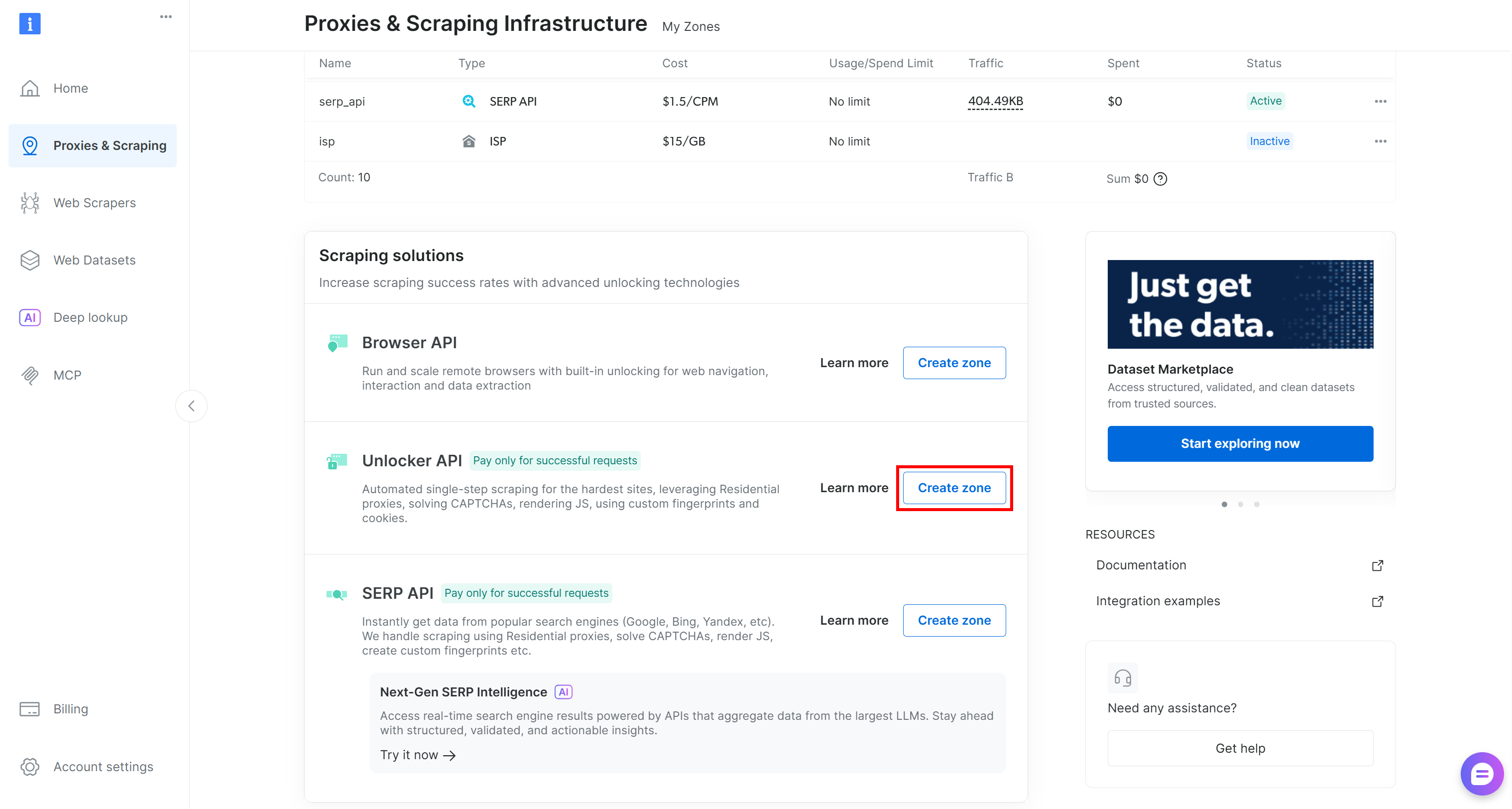
Befolgen Sie die Anweisungen im Assistenten und geben Sie Ihrer Zone einen aussagekräftigen Namen (z. B. web_unlocker).
Generieren Sie abschließend Ihren Bright Data API-Schlüssel. Definieren Sie nun mit Ihrem API-Token und dem Namen der Zone zwei globale Umgebungsvariablen wie folgt:
export BRIGHTDATA_API_KEY="<YOUR_BRIGHTDATA_API_KEY>"
export BRIGHTDATA_UNLOCKER_ZONE="<YOUR_BRIGHTDATA_UNLOCKER_ZONE>"Großartig! Die Bright Data Claude-Skills können sich nun mit Ihrem Konto verbinden und funktionieren einwandfrei.
Schritt 2: Die Bright Data-Skills abrufen
Um neue Skills zu Ihrer Konfiguration hinzuzufügen, kopieren Sie deren Ordner in das lokale Verzeichnis .claude/skills.
Beginnen Sie damit, das Bright Data Claude Skills-Repository in einen Ordner Ihrer Wahl zu klonen:
git clone https://github.com/brightdata/skillsDie geklonte Struktur sollte wie folgt aussehen:
skills/
├── .claude-plugin
├── skills/
│ ├── bright-data-best-practices/
│ ├── bright-data-mcp/
│ ├── brightdata-cli/
│ ├── data-feeds/
│ ├── design-mirror/
│ ├── python-sdk-best-practices/
│ ├── scrape/
│ ├── scraper-builder/
│ └── search/
├── .gitignore
├── LICENSE
└── README.mdDie Bright Data Claude-Skills sind:
search: Durchsucht Google und gibt strukturierte JSON-Ergebnisse zurück, einschließlich Titeln, Links und Beschreibungen.scrape: Extrahiert beliebige Webseiten als sauberes Markdown und umgeht dabei automatisch die Bot-Erkennung.data-feeds: Ruft strukturierte Daten von über 40 Websites mit automatischer Abfrage und Aktualisierung ab.bright-data-mcp: Koordiniert über 60 Bright Data MCP-Tools für Suche, Scraping, strukturierte Extraktion und Browser-Automatisierung.scraper-builder: Erstellt produktionsreife Scraper, einschließlich Website-Analyse, API-Auswahl, Selektoren, Paginierung und Implementierung.bright-data-best-practices: Referenz für Web Unlocker, SERP, Web Scraper und Browser-APIs.python-sdk-best-practices: Leitfaden für das Python-Paket„brightdata-sdk“: asynchrone/synchrone Clients, Scraper, Datensätze, Fehlerbehandlung und Muster.brightdata-cli: Terminal-Leitfaden für die Bright Data CLI: Scrapen, Suchen, Extrahieren von Daten, Verwalten von Proxy-Zonen und Überprüfen des Kontos.design-mirror: Replizieren Sie Design-System-Token und -Komponenten für eine konsistente, hochwertige UI-Implementierung.
Kopieren Sie die Ordner im Verzeichnis „skills/“ (bright-data-best-practices/, bright-data-mcp/ usw.) in das lokale Verzeichnis „.claude/skills“ in Ihrem Projektverzeichnis. Führen Sie dies manuell oder mit folgendem Befehl durch:
cp -r skills/skills/* <PATH_TO_YOUR_PROJECT>/.claude/skills/Perfekt! Die Bright Data Claude-Skills wurden Ihrem Projekt hinzugefügt.
Schritt 3: Überprüfen Sie die verfügbaren Skills
Starten Sie Claude Code erneut in Ihrem Projektordner und führen Sie den Befehl /skills aus: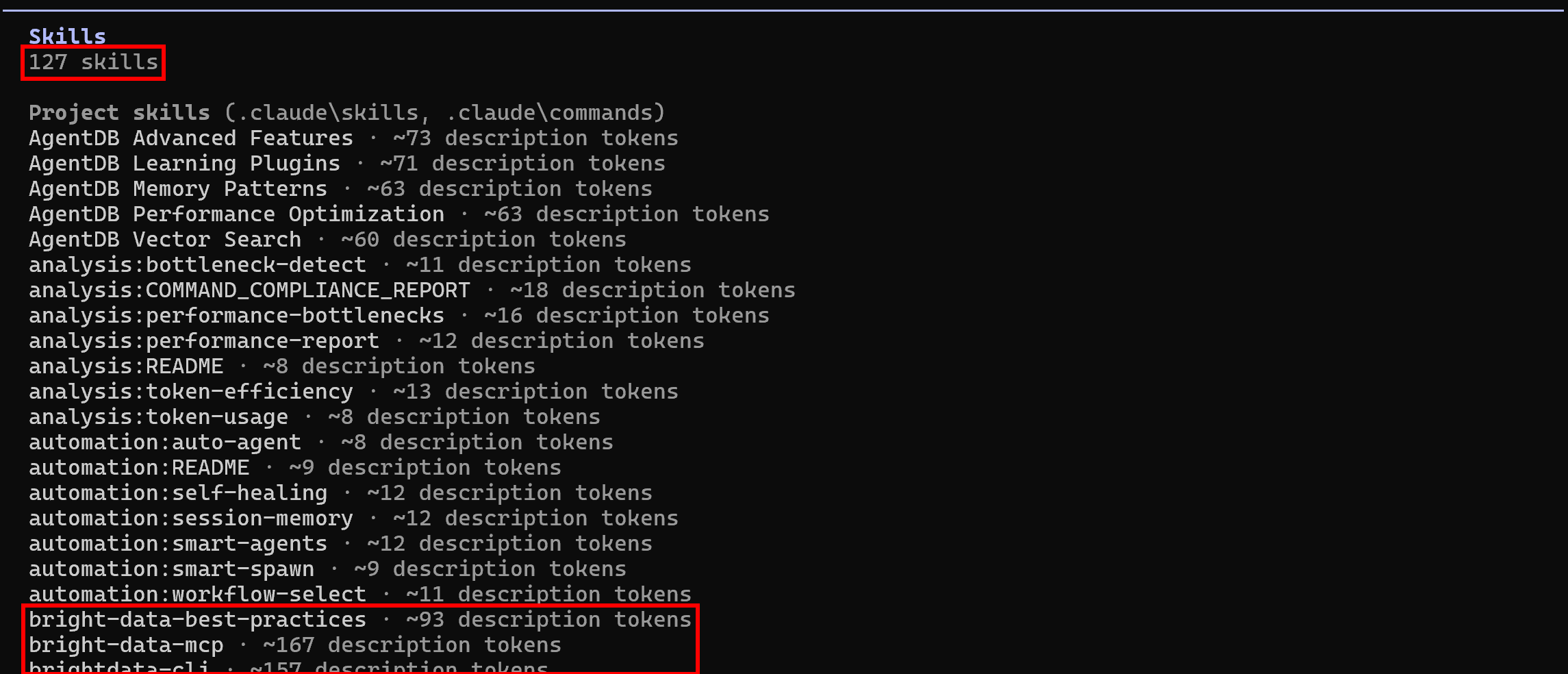
Diesmal sollten 127 Skills verfügbar sein (gegenüber ursprünglich 118), was zeigt, dass die Bright Data-Skills erfolgreich geladen wurden. Mission erfüllt! Ihr agentisches Programmiersystem kann nun die Bright Data-Skills für die programmatische Web-Datenextraktion, Web-Exploration und vieles mehr nutzen.
Ruflo + Bright Data: Alles zusammenführen
Ihre Claude-Code-Konfiguration hat nun Zugriff auf über 300 MCP-Tools oder mehr als 125 Skills. Diese ermöglichen koordinierte Programmierarbeiten und lassen Agenten gleichzeitig autonom im Web suchen, Daten scrapen und mit Webseiten interagieren – ganz ohne Einschränkungen hinsichtlich Blöcken oder Skalierbarkeit.
Dies eröffnet viele neue Möglichkeiten, darunter:
- Abrufen von Live-Suchergebnissen (SERP) und Einbetten von kontextbezogenen Links in
README.mdund andere Dokumentationsseiten. - Das Auffinden relevanter Tutorials oder Dokumentationen basierend auf Ihren aktuellen Programmieraufgaben, um Ihre Codebasis effizient zu verbessern.
- Das Scrapen aktueller öffentlicher Daten von Websites und deren lokale Speicherung für Mockups, Analysen oder die weitere Verarbeitung.
Diese Beispiele veranschaulichen den synergetischen Vorteil der Verwendung von Bright Data mit Ruflo in Ihrer Claude Code-/OpenAI Codex-Konfiguration. Diese Integration erweitert den ohnehin schon beeindruckenden Funktionsumfang von Ruflo noch weiter und unterstützt dank der Infrastruktur von Bright Data Anwendungsfälle auf Unternehmensebene.
Fazit
In diesem Blogbeitrag haben Sie erfahren, was Ruflo (früher bekannt als Claude Flow) ist und wie es die Agentenerfahrung in Claude Code und OpenAI Codex verändert. Mit einer Infrastruktur auf Unternehmensniveau, in der rund 100 Agenten parallel arbeiten, verbessert Ruflo die Leistung erheblich, einschließlich Geschwindigkeit, Token-Effizienz und Ausgabequalität.
Diesen Tools fehlt jedoch eine unternehmensgerechte Lösung für das Abrufen von Webdaten, die Websuche und die programmatische Interaktion mit Websites. Hier kommt Bright Data ins Spiel, dank eines dedizierten Web-MCP-Servers und einer offiziellen Reihe von Claude Skills. Diese erleichtern die Anbindung an die gesamte Palette der für KI entwickelten Tools, Dienste und Infrastruktur von Bright Data.
Hier haben Sie gelernt, wie Sie eine leistungsstarke Ruflo + Bright Data-Konfiguration in Claude Code einrichten, um die Effizienz und Effektivität der Codierungsunterstützung zu maximieren.
Erstellen Sie noch heute kostenlos ein Bright Data-Konto und entdecken Sie KI-fähige Webdatenlösungen!





