
In diesem Leitfaden erfahren Sie mehr:
- Was Pydantic AI ist und was es als Rahmen für die Entwicklung von KI-Agenten einzigartig macht.
- Warum sich Pydantic AI gut mit dem Web MCP-Server von Bright Data kombinieren lässt, um Agenten zu erstellen, die auf das Internet zugreifen können.
- Wie man Pydantic mit Bright Data’s Web MCP integriert, um einen KI-Agenten zu erstellen, der auf echten Daten basiert.
Lasst uns eintauchen!
Was ist Pydantic AI?
Pydantic AI ist ein Python-Agenten-Framework, das von den Schöpfern von Pydantic, der am weitesten verbreiteten Datenvalidierungsbibliothek für Python, entwickelt wurde.
Im Vergleich zu anderen KI-Agenten-Frameworks legt Pydantic AI den Schwerpunkt auf Typsicherheit, strukturierte Ausgaben und die Integration mit realen Daten und Tools. Im Einzelnen sind einige der wichtigsten Merkmale:
- Unterstützung für OpenAI, Anthropic, Gemini, Cohere, Mistral, Groq, HuggingFace, Deepseek, Ollama und andere LLM-Anbieter.
- Strukturierte Output-Validierung über pydantische Modelle.
- Debugging und Überwachung über Pydantic Logfire.
- Optionale Injektion von Abhängigkeiten für Tools, Prompts und Validatoren.
- Gestreamte LLM-Antworten mit fließender Datenvalidierung.
- Unterstützung von Multi-Agenten und Graphen für komplexe Arbeitsabläufe.
- Tool-Integration über MCP und einschließlich HTTP-Aufrufe.
- Vertrauter Python-Flow, um KI-Agenten wie Standard-Python-Anwendungen zu erstellen.
- Integrierte Unterstützung für Unit-Tests und iterative Entwicklung.
Die Bibliothek ist quelloffen und hat bereits über 11k Sterne auf GitHub erreicht.
Warum sollte man Pydantic AI mit einem MCP-Server für die Abfrage von Webdaten kombinieren?
KI-Agenten, die mit Pydantic AI entwickelt werden, erben die Einschränkungen des zugrunde liegenden LLM. Dazu gehört der fehlende Zugang zu Echtzeitinformationen, was zu ungenauen Antworten führen kann. Glücklicherweise kann dieses Problem leicht behoben werden, indem der Agent mit aktuellen Daten ausgestattet wird und die Möglichkeit erhält, das Internet live zu erkunden.
An dieser Stelle kommt der Web-MCP von Bright Data ins Spiel. Dieser MCP-Server basiert auf Node.js und ist mit der Bright Data-Suite von KI-fähigen Datenabfragetools integriert. Diese Tools ermöglichen es Ihrem Agenten, auf Webinhalte zuzugreifen, strukturierte Datensätze abzufragen, das Web zu durchsuchen und mit Webseiten on the fly zu interagieren.
Zu den MCP-Tools auf dem Server gehören derzeit:
| Werkzeug | Beschreibung |
|---|---|
scrape_as_markdown |
Scrapen Sie Inhalte von einer einzelnen URL mit erweiterten Extraktionsoptionen und geben Sie die Ergebnisse als Markdown zurück. Kann die Bot-Erkennung und CAPTCHA umgehen. |
Suchmaschine |
Extrahiert Suchergebnisse von Google, Bing oder Yandex und gibt SERP-Daten im Markdown-Format (URL, Titel, Snippet) zurück. |
scrape_as_html |
Abrufen von Webseiteninhalten aus einer URL mit erweiterten Extraktionsoptionen, die den vollständigen HTML-Code zurückgeben. Kann die Bot-Erkennung und CAPTCHA umgehen. |
session_stats |
Bereitstellung von Statistiken über die Nutzung des Tools während der aktuellen Sitzung. |
scraping_browser_go_back |
Navigieren Sie zurück zur vorherigen Seite in der Scraping-Browser-Sitzung. |
scraping_browser_go_forward |
Navigieren Sie in der Scraping-Browser-Sitzung zur nächsten Seite. |
scraping_browser_click |
Ausführen einer Klick-Aktion auf ein bestimmtes Element per Selektor. |
scraping_browser_links |
Ruft alle Links, einschließlich Text und Selektoren, auf der aktuellen Seite ab. |
scraping_browser_type |
Eingabe von Text in ein bestimmtes Element innerhalb des Scraping-Browsers. |
scraping_browser_wait_for |
Warten Sie, bis ein bestimmtes Element auf der Seite sichtbar wird, bevor Sie fortfahren. |
scrapen_browser_bildschirmfoto |
Erfassen Sie einen Screenshot der aktuellen Browserseite. |
scraping_browser_get_html |
Ruft den HTML-Inhalt der aktuellen Seite im Browser ab. |
scraping_browser_get_text |
Extrahiert den sichtbaren Textinhalt aus der aktuellen Seite. |
Darüber hinaus gibt es über 40 spezialisierte Tools zum Sammeln strukturierter Daten von einer Vielzahl von Websites (z. B. Amazon, Yahoo Finance, TikTok, LinkedIn und mehr) unter Verwendung von Web Scraper APIs. Das Tool web_data_amazon_product beispielsweise sammelt detaillierte, strukturierte Produktinformationen von Amazon, indem es eine gültige Produkt-URL als Eingabe akzeptiert.
Sehen Sie sich jetzt an, wie Sie diese MCP-Tools in Pydantic AI verwenden können!
Integration von Pydantic AI mit dem Bright MCP Server in Python
In diesem Abschnitt lernen Sie, wie Sie mit Pydantic AI einen KI-Agenten erstellen. Der Agent wird mit Live-Daten-Scraping-, Abruf- und Interaktionsfunktionen vom Web-MCP-Server ausgestattet.
Als Beispiel werden wir demonstrieren, wie der Agent Produktdaten von Amazon abrufen kann. Denken Sie daran, dass dies nur einer von vielen möglichen Anwendungsfällen ist. Der KI-Agent kann auf jedes der über 50 Tools zugreifen, die über den MCP-Server verfügbar sind, um eine Vielzahl von Aufgaben auszuführen.
Folgen Sie dieser Anleitung, um Ihren Gemini + Bright Data MCP-gesteuerten KI-Agenten mit Pydantic AI zu erstellen!
Voraussetzungen
Um das Code-Beispiel nachzubilden, stellen Sie sicher, dass Sie das Folgende lokal installiert haben:
- Python 3.10 oder höher.
- Node.js (wir empfehlen die neueste LTS-Version).
Sie benötigen außerdem:
- Ein Bright Data-Konto.
- Ein Gemini-API-Schlüssel (oder ein API-Schlüssel für einen anderen unterstützten LLM-Anbieter, wie OpenAI, Anthropic, Deepseek, Ollama, Groq, Cohere und Mistral).
Kümmern Sie sich jetzt noch nicht um die Einrichtung der API-Schlüssel. Die folgenden Schritte führen Sie durch die Konfiguration der Bright Data- und Gemini-Anmeldeinformationen, wenn es so weit ist.
Dieses Hintergrundwissen ist zwar nicht unbedingt erforderlich, aber es wird Ihnen helfen, dem Lernprogramm zu folgen:
- Ein allgemeines Verständnis der Funktionsweise von MCP.
- Grundlegende Vertrautheit mit der Funktionsweise von KI-Agenten.
- Gewisse Kenntnisse des Web-MCP-Servers und seiner verfügbaren Tools.
- Grundkenntnisse in asynchroner Programmierung in Python.
Schritt #1: Erstellen Sie Ihr Python-Projekt
Öffnen Sie Ihr Terminal und erstellen Sie einen neuen Ordner für Ihr Projekt:
mkdir pydantic-ai-mcp-agentDer Ordner pydantic-ai-mcp-agent enthält den gesamten Code für Ihren Python-KI-Agenten.
Navigieren Sie zu dem neu erstellten Ordner und richten Sie darin eine virtuelle Umgebung ein:
cd pydantic-ai-mcp-agent
python -m venv venvÖffnen Sie nun den Projektordner in Ihrer bevorzugten Python-IDE. Wir empfehlen Visual Studio Code mit der Python-Erweiterung oder PyCharm Community Edition.
Erstellen Sie eine Datei namens agent.py im Stammverzeichnis Ihres Projekts. Zu diesem Zeitpunkt sollte Ihre Ordnerstruktur wie folgt aussehen:
pydantic-ai-mcp-agent/
├── venv/
└── agent.pyDie Datei agent.py ist derzeit noch leer, wird aber bald die Logik für die Integration von Pydantic AI mit dem Bright Data Web MCP-Server enthalten.
Aktivieren Sie die virtuelle Umgebung über das Terminal in Ihrer IDE. Unter Linux oder macOS führen Sie diesen Befehl aus:
source venv/bin/activateStarten Sie unter Windows die entsprechende Funktion:
venv/Scripts/activateSie sind bereit! Sie haben jetzt eine Python-Umgebung, um einen KI-Agenten mit Webdatenzugriff zu erstellen.
Schritt #2: Pydantic AI installieren
Installieren Sie in Ihrer aktivierten virtuellen Umgebung alle erforderlichen Pydantic AI-Pakete mit:
pip install "pydantic-ai-slim[google,mcp]" Dies installiert pydantic-ai-slim, eine abgespeckte Version des vollständigen pydantic-ai-Pakets, das keine unnötigen Abhängigkeiten mit sich bringt.
Da Sie in diesem Fall planen, Ihren Agenten in den Bright Data Web MCP Server zu integrieren, benötigen Sie die mcp-Erweiterung. Und da wir Gemini als LLM-Anbieter integrieren werden, benötigen Sie auch die google-Erweiterung.
Hinweis: Bei anderen Modellen oder Anbietern ist in der Modelldokumentation nachzulesen, welche optionalen Abhängigkeiten erforderlich sind.
Als nächstes fügen Sie diese Importe in Ihre agent.py-Datei ein:
from pydantic_ai import Agent
from pydantic_ai.mcp import MCPServerStdio
from pydantic_ai.models.google import GoogleModel
from pydantic_ai.providers.google import GoogleProviderSuper! Sie können jetzt Pydantic AI für den Aufbau von Agenten verwenden.
Schritt #3: Einrichten von Umgebungsvariablen Lesen
Ihr KI-Agent interagiert mit Diensten von Drittanbietern wie Bright Data und Gemini über eine API. Programmieren Sie Ihre API-Schlüssel nicht fest in Ihren Python-Code ein. Laden Sie sie stattdessen aus Umgebungsvariablen, um die Sicherheit und Wartungsfreundlichkeit zu erhöhen.
Um den Prozess zu vereinfachen, nutzen Sie die python-dotenv-Bibliothek. Wenn Ihre virtuelle Umgebung aktiviert ist, installieren Sie sie, indem Sie sie ausführen:
pip install python-dotenvDann importieren Sie in Ihrer agent.py-Datei die Bibliothek und laden die Umgebungsvariablen mit load_dotenv():
from dotenv import load_dotenv
load_dotenv()Dies ermöglicht es dem Skript, Umgebungsvariablen aus einer lokalen .env-Datei zu lesen. Legen Sie also eine .env-Datei in Ihrem Projektordner an:
pydantic-ai-mcp-agent/
├── venv/
├── agent.py
└── .env # <---------------Sie können nun wie folgt auf Umgebungsvariablen zugreifen:
env_value = os.getenv("<ENV_NAME>")Vergessen Sie nicht, das Modul os aus der Python-Standardbibliothek zu importieren:
import osSo geht’s! Sie sind nun in der Lage, Api-Schlüssel sicher aus der .env-Datei zu laden.
Schritt Nr. 4: Erste Schritte mit dem Bright Data MCP-Server
Falls Sie dies noch nicht getan haben, erstellen Sie ein Bright Data-Konto. Wenn Sie bereits eines haben, melden Sie sich einfach an.
Folgen Sie dann den offiziellen Anweisungen, um Ihren Bright Data-API-Schlüssel einzurichten. Der Einfachheit halber gehen wir davon aus, dass Sie in diesem Abschnitt ein Token mit Admin-Berechtigungen verwenden.
Installieren Sie den Web MCP von Bright Data global über npm:
npm install -g @brightdata/mcpTesten Sie dann mit dem folgenden Bash-Befehl, ob alles funktioniert:
API_TOKEN="<YOUR_BRIGHT_DATA_API>" npx -y @brightdata/mcpOder unter Windows lautet der entsprechende PowerShell-Befehl:
$env:API_TOKEN="<YOUR_BRIGHT_DATA_API>"; npx -y @brightdata/mcpErsetzen Sie im obigen Befehl den Platzhalter durch die tatsächliche Bright Data-API, die Sie zuvor abgerufen haben. Beide Befehle setzen die erforderliche Umgebungsvariable API_TOKEN und starten den MCP-Server über das npm-Paket @brightdata/mcp.
Wenn alles richtig funktioniert, zeigt Ihr Terminal ähnliche Protokolle an wie dieses:

Wenn Sie den MCP-Server zum ersten Mal starten, werden automatisch zwei Standardzonen in Ihrem Bright Data-Konto erstellt:
mcp_unlocker: Eine Zone für Web Unlocker.mcp_browser: Eine Zone für die Browser-API.
Diese beiden Zonen ermöglichen es dem MCP-Server, alle Tools auszuführen, die er zur Verfügung stellt.
Um dies zu überprüfen, melden Sie sich bei Ihrem Bright Data-Dashboard an und navigieren Sie zur Seite“Proxies & Scraping-Infrastruktur“. Sie sehen, dass die folgenden Zonen automatisch erstellt wurden:
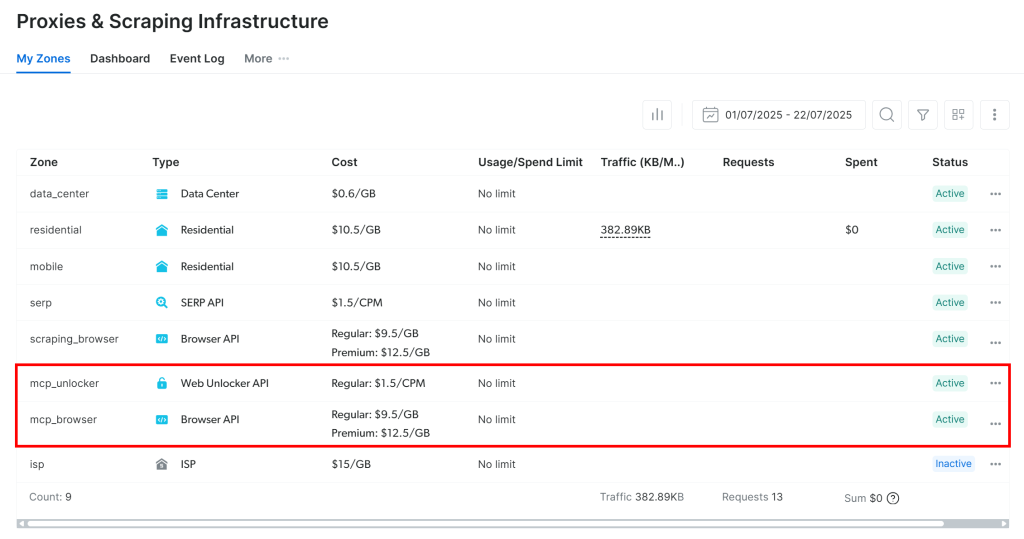
Hinweis: Wenn Sie kein API-Token mit Admin-Rechten verwenden, müssen Sie die Zonen manuell erstellen. In jedem Fall können Sie die Zonennamen in den Umgebungsvariablen angeben, wie in der offiziellen Dokumentation beschrieben.
Standardmäßig stellt die Web MCP nur die Werkzeuge search_engine und scrape_as_markdown zur Verfügung. Um erweiterte Funktionen wie Browser-Automatisierung und Extraktion strukturierter Daten freizuschalten, müssen Sie den Pro-Modus aktivieren, indem Sie die Umgebungsvariable PRO_MODE=true setzen.
Großartig! Das Web MCP funktioniert wie ein Zauber.
Schritt Nr. 5: Verbindung zum Web MCP
Nachdem Sie nun bestätigt haben, dass Ihr Rechner den Web MCP ausführen kann, stellen Sie eine Verbindung her!
Fügen Sie zunächst Ihren Bright Data-API-Schlüssel in die .env-Datei ein:
BRIGHT_DATA_API_KEY="<YOUR_BRIGHT_DATA_API_KEY>"Ersetzen Sie den Platzhalter durch den tatsächlichen Bright Data-API-Schlüssel, den Sie zuvor erhalten haben.
Dann lesen Sie es in der Datei agent.py mit:
BRIGHT_DATA_API_KEY = os.getenv("BRIGHT_DATA_API_KEY")Beachten Sie, dass Pydantic AI drei Methoden zur Verbindung mit einem MCP-Server unterstützt:
- Verwendung des Streamable HTTP-Transports.
- Verwendung des HTTP SSE-Transports.
- Ausführen des Servers als Unterprozess und Verbindung über
stdio.
Wenn Sie mit den ersten beiden Methoden nicht vertraut sind, lesen Sie unseren Leitfaden zu SSE vs. Streamable HTTP, um eine genauere Erklärung zu erhalten.
In diesem Fall möchten Sie den Server als Unterprozess laufen lassen (dritte Methode). Zu diesem Zweck initialisieren Sie eine MCPServerStdio-Instanz wie unten gezeigt:
server = MCPServerStdio(
"npx",
args=[
"-y",
"@brightdata/mcp",
],
env={
"API_TOKEN": BRIGHT_DATA_API_KEY,
"PRO_MODE": "true" # Enable the Pro Mode to access all Bright Data tools
},
)Diese Codezeilen bewirken im Wesentlichen, dass Web MCP mit demselben npx-Befehl gestartet wird, den Sie zuvor ausgeführt haben. Er setzt die Umgebungsvariable API_TOKEN mit Ihrem Bright Data-API-Schlüssel zur Authentifizierung. Außerdem wird der PRO_MODE aktiviert, so dass Sie Zugriff auf alle verfügbaren Tools haben, auch auf die erweiterten Tools.
Sehr gut! Sie haben nun erfolgreich die Verbindung zu Ihrem lokalen Web MCP im Code konfiguriert.
Schritt #6: Konfigurieren Sie das LLM
Hinweis: Dieser Abschnitt bezieht sich auf Gemini, den für das Tutorial gewählten LLM. Sie können ihn jedoch leicht an OpenAI oder jeden anderen unterstützten LLM anpassen, indem Sie der offiziellen Dokumentation folgen.
Beginnen Sie damit, Ihren Gemini-API-Schlüssel abzurufen und fügen Sie ihn wie folgt zu Ihrer .env-Datei hinzu:
GOOGLE_API_KEY="<YOUR_GOOGLE_API_KEY>"Ersetzen Sie den Platzhalter durch Ihren tatsächlichen API-Schlüssel.
Als Nächstes importieren Sie die erforderlichen Pydantic AI-Bibliotheken für die Integration in Gemini:
from pydantic_ai.models.google import GoogleModel
from pydantic_ai.providers.google import GoogleProviderDiese Importe ermöglichen es Ihnen, sich mit den Google-APIs zu verbinden und ein Gemini-Modell zu konfigurieren. Beachten Sie, dass Sie den GOOGLE_API_KEY nicht manuell aus der .env-Datei lesen müssen. Der Grund dafür ist, dass GoogleProvider unter der Haube google-genai verwendet, das automatisch den API-Schlüssel aus der GOOGLE_API_KEY env-Datei liest.
Initialisieren Sie nun die Anbieter- und Modellinstanzen:
provider = GoogleProvider()
model = GoogleModel("gemini-2.5-flash", provider=provider)Erstaunlich! Dadurch kann der Pydantic-KI-Agent über die kostenlos nutzbare Google-API eine Verbindung zum gemini-2.5-Flash-Modell herstellen.
Schritt #7: Definieren Sie den Pydantic AI Agent
Definieren Sie einen Pydantic AI Agent, der das zuvor konfigurierte LLM verwendet und eine Verbindung zum Web MCP Server herstellt:
agent = Agent(model, toolsets=[server])Perfekt! Mit nur einer einzigen Codezeile haben Sie gerade ein Agent-Objekt instanziiert. Dieses stellt einen KI-Agenten dar, der Ihre Aufgaben mithilfe der vom Web-MCP-Server bereitgestellten Tools erledigen kann.
Schritt #8: Starten Sie Ihren Agenten
Um Ihren KI-Agenten zu testen, müssen Sie eine Eingabeaufforderung schreiben, die eine Aufgabe zur Extraktion von Webdaten (bei Interaktion) beinhaltet. So können Sie überprüfen, ob der Agent die Bright Data-Tools wie erwartet verwendet.
Ein guter Ausgangspunkt ist die Aufforderung, Produktdaten von einer Amazon-Seite abzurufen, etwa so:
“Geben Sie mir Produktdaten von https://www.amazon.com/AmazonBasics-Pound-Neoprene-Dumbbells-Weights/dp/B01LR5S6HK/”
Wenn Sie eine solche Anfrage direkt an Gemini senden, würde normalerweise eines von zwei Dingen passieren:
- Die Anfrage würde an Amazons Anti-Bot-Systemen (z. B. dem Amazon CAPTCHA) scheitern, die Gemini daran hindern, auf den Seiteninhalt zuzugreifen.
- Sie würde halluzinierte oder erfundene Produktinformationen zurückgeben, da sie nicht auf die Live-Seite zugreifen kann.
Versuchen Sie die Eingabeaufforderung direkt in Gemini. Wahrscheinlich erhalten Sie die Meldung, dass kein Zugriff auf die Amazon-Seite möglich war, gefolgt von gefälschten Produktdetails, wie unten dargestellt:

Dank der Integration mit dem Web MCP-Server sollte dies in Ihrem Setup nicht passieren. Anstatt zu scheitern oder zu raten, sollte Ihr Agent das web_data_amazon_product-Tool verwenden, um strukturierte Produktdaten in Echtzeit von der Amazon-Seite abzurufen und sie dann in einem sauberen, lesbaren Format zurückzugeben.
Da die Methode zur Abfrage des Pydantic AI-Agenten asynchron ist, verpacken Sie die Ausführungslogik wie folgt in eine asynchrone Funktion:
async def main():
async with agent:
result = await agent.run("Give me product data from https://www.amazon.com/AmazonBasics-Pound-Neoprene-Dumbbells-Weights/dp/B01LR5S6HK/")
output = result.output
print(output)
if __name__ == "__main__":
asyncio.run(main())Vergessen Sie nicht, asyncio aus der Python-Standardbibliothek zu importieren:
import asyncioAuftrag erfüllt! Jetzt müssen wir nur noch den vollständigen Code ausführen und sehen, ob der Agent die Erwartungen erfüllt.
Schritt #9: Alles zusammenfügen
Dies ist der endgültige Code in agent.py:
from pydantic_ai import Agent
from pydantic_ai.mcp import MCPServerStdio
from pydantic_ai.models.google import GoogleModel
from pydantic_ai.providers.google import GoogleProvider
from dotenv import load_dotenv
import os
import asyncio
# Load the environment variables from the .env file
load_dotenv()
# Read the API key from the envs for integration with the Bright Data Web MCP server
BRIGHT_DATA_API_KEY = os.getenv("BRIGHT_DATA_API_KEY")
# Connect to the Bright Data Web MCP server
server = MCPServerStdio(
"npx",
args=[
"-y",
"@brightdata/mcp",
],
env={
"API_TOKEN": BRIGHT_DATA_API_KEY,
"PRO_MODE": "true" # Enable the Pro Mode to access all Bright Data tools
},
)
# Configure the Google LLM model
provider = GoogleProvider()
model = GoogleModel("gemini-2.5-flash", provider=provider)
# Initialize the AI agent with Gemini and Bright Data's Web MCP server integration
agent = Agent(model, toolsets=[server])
async def main():
async with agent:
# Ask the AI Agent to perform a scraping task
result = await agent.run("Give me product data from https://www.amazon.com/AmazonBasics-Pound-Neoprene-Dumbbells-Weights/dp/B01LR5S6HK/")
# Get the result produced by the agent and print it
output = result.output
print(output)
if __name__ == "__main__":
asyncio.run(main())Wow! Dank Pydantic AI und Bright Data haben Sie soeben in etwa 50 Zeilen Code einen leistungsstarken MCP-gestützten KI-Agenten erstellt.
Führen Sie den KI-Agenten mit aus:
python agent.pyIm Terminal sollten Sie eine Ausgabe wie folgt sehen:

Wie Sie anhand der in der Aufforderung genannten Amazon-Produktseite sehen können, sind die vom KI-Agenten zurückgegebenen Informationen korrekt:
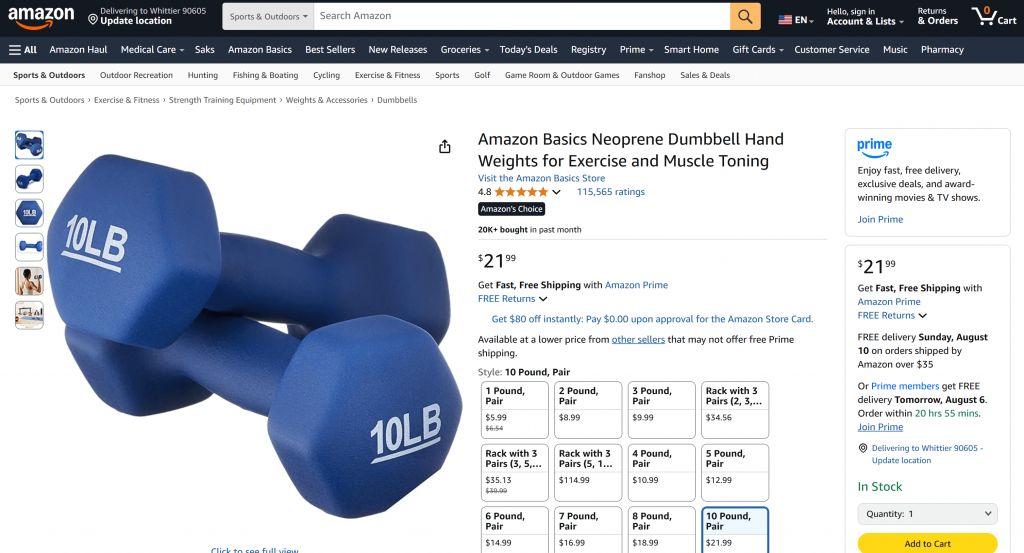
Das liegt daran, dass der Agent das vom Web-MCP-Server bereitgestellte Tool web_data_amazon_product verwendet, um frische, strukturierte Produktdaten von Amazon im JSON-Format abzurufen.
Et voilà! Die Erwartungen wurden erfüllt, und die KI- und MCP-Integration von Pydantic funktionierte genau wie vorgesehen.
Nächste Schritte
Der hier erstellte KI-Agent ist funktionsfähig, aber er dient nur als Ausgangspunkt. Erwägen Sie, ihn auf die nächste Stufe zu heben, indem Sie:
- Implementierung einer REPL-Schleife zum Chatten mit dem Agenten in der CLI oder Integration mit GUI-Chat-Tools wie Gradio.
- Erweiterung der Bright Data MCP-Tools durch die Definition eigener benutzerdefinierter Tools.
- Hinzufügen von Debugging und Überwachung mit Pydantic Logfire.
- Umwandlung Ihres Agenten in einen autonomen RAG-Agenten innerhalb eines Multi-Agenten-Workflows.
- Definition von benutzerdefinierten Funktionsvalidatoren für die Integrität der Ausgabedaten.
Schlussfolgerung
In diesem Artikel haben Sie gelernt, wie Sie Pydantic AI mit dem Web MCP-Server von Bright Data integrieren, um einen AI-Agenten zu erstellen, der auf das Internet zugreifen kann. Diese Integration wird durch die in Pydantic AI integrierte Unterstützung für MCP ermöglicht.
Um anspruchsvollere Agenten zu erstellen, können Sie die gesamte Palette der in der Bright Data AI-Infrastruktur verfügbaren Services nutzen. Diese Lösungen können eine Vielzahl von Agentenszenarien unterstützen.
Erstellen Sie ein kostenloses Bright Data-Konto und experimentieren Sie mit unseren KI-fähigen Webdatentools!




