

Eine Schritt-für-Schritt-Anleitung zum Aufbau einer serverlosen Scraping-Pipeline auf Google Cloud mit Cloud Run, Firestore, BigQuery, Workflows und Cloud Scheduler.
In diesem Artikel erfahren Sie:
- Warum eine serverlose Architektur für Web-Scraping-Pipelines gut geeignet ist.
- Wie Sie die erforderliche Google Cloud-Infrastruktur von Grund auf einrichten.
- Wie Sie einen privaten Scraper-Dienst und einen öffentlichen API-Dienst auf Cloud Run bereitstellen.
- Wie Sie Scrape-Läufe mit Cloud Workflows orchestrieren und mit Cloud Scheduler automatisieren.
- Wie Sie gescrapte Daten mit Firestore und BigQuery speichern und abfragen.
- Wie Sie überprüfen können, ob Ihre gesamte Pipeline durchgängig funktioniert.
Lassen Sie uns loslegen!
Warum eine serverlose Scraping-Pipeline erstellen?
Die meisten Scraping-Tutorials beschränken sich auf das Skript. Sie erhalten etwas HTML, analysieren vielleicht ein paar Felder, und das war’s. Wenn es jedoch darum geht, Scraper in der Produktion einzusetzen, müssen Sie schwierigere Fragen beantworten: Wohin gehen die Daten? Wie führen Sie sie nach einem Zeitplan aus? Wie fragen Sie später die Ergebnisse ab? Wie halten Sie die Kosten niedrig, wenn der Scraper nicht läuft?
Hier kommt Serverless ins Spiel. Google Cloud Run berechnet Ihnen nur dann Kosten, wenn Ihre Dienste Anfragen bearbeiten. Es gibt keine Server zu verwalten, keine Leerlauf-Rechner, die über Nacht Geld verbrennen. Kombinieren Sie dies mit Firestore für die Auftragsverfolgung, BigQuery für Analysen und Cloud Workflows für die Orchestrierung, und Sie erhalten eine Datenpipeline-Architektur, die bei Leerlauf auf Null skaliert und bei Bedarf hochfährt.
Am Ende dieses Leitfadens verfügen Sie über:
- Einen privaten
Scraper-Dienstauf Cloud Run, der das eigentliche Scraping durchführt. - Einen öffentlichen
API-Dienstauf Cloud Run, der Ihre Daten verfügbar macht. - Firestore-Sammlungen, die den Status und die Ergebnisse von Jobs verfolgen.
- Eine BigQuery-Tabelle, die Sie für Analysen abfragen können.
- Einen Cloud Workflow, der den gesamten Scrape-Vorgang koordiniert.
- Ein Cloud Scheduler-Job, der ihn auf einem Cron auslöst.
Die Architektur verstehen
Bevor wir mit der Ausführung von Befehlen beginnen, ist es hilfreich zu verstehen, wie alle Teile miteinander verbunden sind. Wir haben viel Zeit damit verbracht, die richtige Architektur zu finden, als wir dies zum ersten Mal aufgebaut haben, daher möchten wir Ihnen diese nun vorstellen.
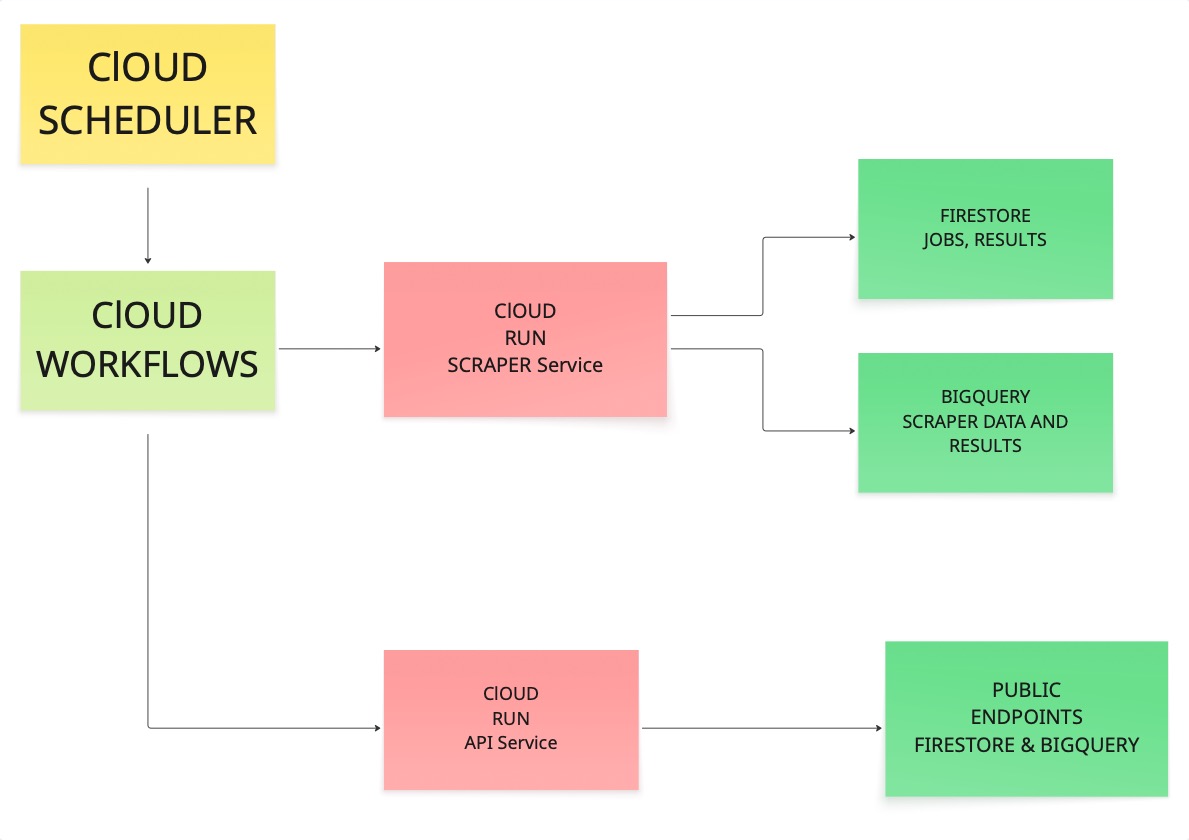
Der Scheduler löst einen Workflow aus. Der Workflow ruft den Scraper auf. Der Scraper besucht URLs, ruft Inhalte ab und schreibt die Ergebnisse sowohl in Firestore als auch in BigQuery. Anschließend liest der API-Dienst aus diesen Speichern und stellt die Daten über öffentliche Endpunkte zur Verfügung.
Wenn jeder Link in dieser Kette funktioniert, haben Sie etwas, auf das Sie sich in der Produktion verlassen können.
Voraussetzungen
Bevor Sie beginnen, stellen Sie sicher, dass Sie über Folgendes verfügen:
- Ein Google-Konto.
- Ein GCP-Projekt mit aktivierter Abrechnung (die Kosten sind minimal, aber die Abrechnung muss aktiv sein).
- Node.js 18 oder höher.
- Die
gcloud-CLI auf Ihrem Computer installiert.
Führen Sie eine kurze Funktionsprüfung durch:
node --version
npm --version
gcloud --versionWenn alle drei Versionsnummern angezeigt werden, können Sie fortfahren.
Einrichten Ihres Google Cloud-Projekts
Rufen Sie die Cloud Console auf und erstellen Sie ein neues Projekt. Wir haben unser Projekt „cloud-run-scraper“ genannt, aber Sie können es nach Belieben benennen.
So gehen Sie vor:
- Geben Sie Ihren Projektnamen ein.
- Klicken Sie auf „Erstellen“.
- Kopieren Sie die generierte Projekt-ID (etwa
„cloud-run-scraper-123456”). Sie benötigen diese ID im weiteren Verlauf der Anleitung. - Gehen Sie zu „Abrechnung“ und verknüpfen Sie ein Abrechnungskonto mit dem Projekt.
So sieht dieser Bildschirm aus:
Konfigurieren Ihrer Shell
Wir empfehlen, vorab einige Umgebungsvariablen festzulegen, damit Sie nicht überall Projekt-IDs kopieren und einfügen müssen. So bleiben Ihre Befehle übersichtlich und wiederverwendbar:
export PROJECT_ID="IHRE_PROJEKT-ID"
export REGION="us-central1"
export REPO_NAME="cloud-run-scraper-repo"
export BQ_DATASET="scraper_data"
export BQ_TABLE="scraped_results"Weisen Sie dann gcloud auf Ihr Projekt hin:
gcloud config set project "$PROJECT_ID"
gcloud config set run/region "$REGION"Und authentifizieren Sie sich (dadurch wird Ihr Browser geöffnet):
gcloud auth login
gcloud auth application-default loginAktivieren der erforderlichen APIs
Eine Sache, die viele Nutzer bei Google Cloud verwirrt, ist, dass nichts funktioniert, bis Sie die benötigten APIs explizit aktivieren. Stellen Sie sich das wie das Umlegen von Sicherungshebern vor. Führen Sie diesen Befehl einmal aus, und schon sind Sie fertig:
gcloud services enable
run.googleapis.com
cloudbuild.googleapis.com
workflows.googleapis.com
artifactregistry.googleapis.com
cloudscheduler.googleapis.com
bigquery.googleapis.com
firestore.googleapis.com
secretmanager.googleapis.comSie können überprüfen, ob alle aktiviert sind, mit:
gcloud services list --enabled | rg "run.googleapis.com|cloudbuild.googleapis.com|workflows.googleapis.com|artifactregistry.googleapis.com|cloudscheduler.googleapis.com|bigquery.googleapis.com|firestore.googleapis.com"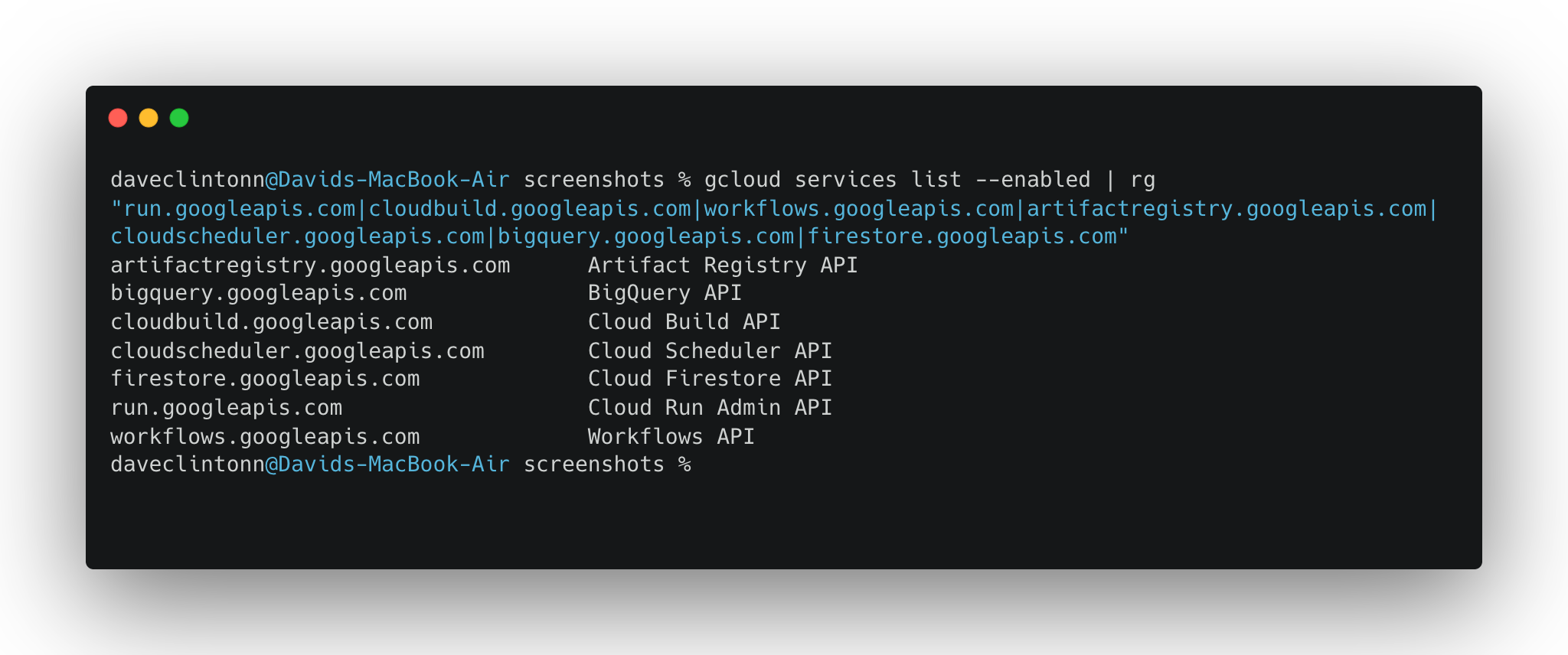
Einrichten von Firestore
Wir benötigen Firestore im nativen Modus, um Job-Tracking-Daten zu speichern und Ergebnisse zu scrapen:
gcloud firestore databases create --location="$REGION" --type=firestore-nativeWenn Sie Firestore bereits in diesem Projekt eingerichtet haben, können Sie diesen Schritt überspringen. Es wird eine Fehlermeldung angezeigt, dass die Datenbank bereits existiert.
Erstellen der Artifact Registry
Die Artifact Registry ist der Ort, an dem Ihre Docker-Images gespeichert werden. Stellen Sie sich diese als private Container-Registry auf GCP vor:
gcloud artifacts repositories create "$REPO_NAME"
--repository-format=docker
--location="$REGION"
--description="Docker-Images für cloud-run-Scraper"Teilen Sie Docker anschließend mit, wie die Authentifizierung erfolgen soll:
gcloud auth configure-docker "$REGION-docker.pkg.dev"Einrichten von BigQuery
Jetzt erstellen wir den BigQuery-Datensatz und die Tabelle, in der die gescrapten Daten landen werden. Das macht die gesamte Pipeline so nützlich – ein gut strukturierter ETL-Pipeline-Flow ermöglicht es Ihnen, SQL-Abfragen über alle Ihre gescrapten Daten hinweg auszuführen, um Trends aufzudecken, nach Quellen zu filtern oder Dashboards zu erstellen.
Erstellen Sie den Datensatz:
bq --location="$REGION" mk -d "$PROJECT_ID:$BQ_DATASET"Erstellen Sie dann die Tabelle mit dem vom Scraper verwendeten Schema:
bq mk --table
"$PROJECT_ID:$BQ_DATASET.$BQ_TABLE"
url:STRING,title:STRING,content:STRING,scraped_at:TIMESTAMP,job_id:STRING,source:STRING,metadata:STRINGÜberprüfen Sie kurz, ob es funktioniert hat:
bq show "$PROJECT_ID:$BQ_DATASET.$BQ_TABLE"Die richtigen IAM-Berechtigungen einrichten
Dieser Teil ist nicht besonders spannend, aber sehr wichtig. Ihre Cloud Run-Dienste benötigen Berechtigungen, um mit Firestore, BigQuery und untereinander zu kommunizieren. Ohne diese IAM-Bindungen erhalten Sie mysteriöse 403-Fehler ohne klare Erklärung.
Rufen Sie zunächst Ihr Compute-Dienstkonto ab:
PROJECT_NUMBER=$(gcloud projects describe "$PROJECT_ID" --format="value(projectNumber)")
COMPUTE_SA="${PROJECT_NUMBER}[email protected]"
echo "$COMPUTE_SA"Weisen Sie dann die erforderlichen Rollen zu:
gcloud projects add-iam-policy-binding "$PROJECT_ID"
--member="serviceAccount:${COMPUTE_SA}"
--role="roles/datastore.user"
gcloud projects add-iam-policy-binding "$PROJECT_ID"
--member="serviceAccount:${COMPUTE_SA}"
--role="roles/bigquery.dataEditor"
gcloud projects add-iam-policy-binding "$PROJECT_ID"
--member="serviceAccount:${COMPUTE_SA}"
--role="roles/bigquery.jobUser"
gcloud projects add-iam-policy-binding "$PROJECT_ID"
--member="serviceAccount:${COMPUTE_SA}"
--role="roles/run.invoker"
gcloud projects add-iam-policy-binding "$PROJECT_ID"
--member="serviceAccount:${COMPUTE_SA}"
--role="roles/workflows.invoker"Das sind fünf Rollenbindungen. Jede davon ermöglicht dem Dienstkonto eine bestimmte Aktion: Lesen/Schreiben in Firestore, Einfügen in BigQuery, Aufrufen von Cloud Run-Diensten und Auslösen von Workflows.
Installieren von Abhängigkeiten
Installieren Sie vom Repo-Stammverzeichnis aus die Abhängigkeiten für beide Dienste:
npm --prefix scraper-service install
npm --prefix api-service installBereitstellen des Scraper-Dienstes
Dies ist das Arbeitspferd der gesamten Pipeline. Es handelt sich um den Dienst, der URLs aufruft, Inhalte abruft und die Ergebnisse in Firestore und BigQuery schreibt. Wenn Sie komplexere Anti-Bot-Szenarien in Ihrem Scraper verarbeiten möchten, lohnt es sich, Tools wie den Scraping-Browser von Bright Data für die cloudbasierte Browser-Automatisierung in großem Maßstab zu prüfen.
Wir stellen ihn als privaten Dienst bereit. Beachten Sie das Flag --no-allow-unauthenticated. Nur authentifizierte Anfragen, wie die aus unserem Workflow, können ihn aufrufen:
gcloud run deploy scraper-service
--source ./scraper-service
--region "$REGION"
--memory 2Gi
--cpu 2
--timeout 300
--no-allow-unauthenticated
--set-env-vars NODE_ENV=productionRufen Sie die URL ab, sobald sie bereitgestellt ist:
SCRAPER_URL=$(gcloud run services describe Scraper-service --region "$REGION" --format='value(status.url)')
echo "$SCRAPER_URL"Speichern Sie diese URL. Sie benötigen sie für die Workflow-Konfiguration.
Bereitstellen des API-Dienstes
Der API-Dienst ist die öffentlich zugängliche Seite der Pipeline. Er liest aus Firestore und BigQuery und stellt Endpunkte bereit, damit Sie oder Ihr Frontend auf die gescrapten Daten zugreifen können:
gcloud run deploy api-service
--source ./api-service
--region "$REGION"
--memory 512Mi
--cpu 1
--timeout 60
--allow-unauthenticated
--set-env-vars NODE_ENV=productionRufen Sie die URL ab:
API_URL=$(gcloud run services describe api-service --region "$REGION" --format='value(status.url)')
echo "$API_URL"Testen Ihrer bereitgestellten Dienste
Jetzt kommt der spaßige Teil: Sie rufen Ihre Live-Dienste auf und stellen sicher, dass alles funktioniert. Beachten Sie, dass häufige Herausforderungen beim Web-Scraping wie IP-Blockierung und Ratenbegrenzung Ihren Scraper auch in einer serverlosen Umgebung beeinträchtigen können. Es lohnt sich daher, von Anfang an eine Strategie für diese Herausforderungen zu haben.
Probieren Sie diese gegen Ihren API-Dienst aus:
curl -s "$API_URL/"
curl -s "$API_URL/jobs?limit=10"
curl -s "$API_URL/analytics/summary"Für den Scraper müssen Sie ein Authentifizierungstoken übergeben, da es sich um einen privaten Dienst handelt:
curl -s -X POST
-H "Authorization: Bearer $(gcloud auth print-identity-token)"
-H "Content-Type: application/json"
-d '{"url":"http://books.toscrape.com"}'
"$SCRAPER_URL/scrape"Sie können auch benutzerdefinierte CSS-Selektoren übergeben, wenn Sie bestimmte Elemente auf einer Seite ansprechen möchten:
curl -s -X POST
-H "Authorization: Bearer $(gcloud auth print-identity-token)"
-H "Content-Type: application/json"
-d '{"url":"http://books.toscrape.com","selectors":{"title":"h1, h2","content":"p, article"}}'
"$SCRAPER_URL/scrape"Einrichten des Workflows
Der Workflow verbindet den Scraper mit einem Zeitplan. Es handelt sich um eine YAML-Datei, die Cloud Workflows anweist, den Scraper für jede URL in der Liste aufzurufen.
Öffnen Sie workflows/scrape-pipeline.yaml und setzen Sie scraper_url auf die URL, die Sie im Schritt zur Bereitstellung des Scrapers erhalten haben.
Stellen Sie ihn dann bereit:
gcloud workflows deploy scrape-pipeline
--location "$REGION"
--source workflows/scrape-pipeline.yaml
--service-account "$COMPUTE_SA"Erstellen des Scheduler-Jobs
An dieser Stelle wird die Pipeline vollständig automatisiert. Wir richten einen Cron-Job ein, der den Workflow jeden Tag um 6:00 Uhr UTC ausführt:
gcloud scheduler jobs create http scrape-pipeline-daily
--location "$REGION"
--schedule "0 6 * * *"
--uri "https://workflowexecutions.googleapis.com/v1/projects/${PROJECT_ID}/locations/${REGION}/workflows/scrape-pipeline/executions"
--http-method POST
--oauth-service-account-email "$COMPUTE_SA"
--oauth-token-scope "https://www.googleapis.com/auth/cloud-platform"
--message-body '{"argument":"{"urls":["http://books.toscrape.com","http://quotes.toscrape.com"]}"}'Wenn der Job bereits existiert und Sie ihn nur aktualisieren möchten:
gcloud scheduler jobs update http scrape-pipeline-daily
--location "$REGION"
--schedule "0 6 * * *"
--uri "https://workflowexecutions.googleapis.com/v1/projects/${PROJECT_ID}/locations/${REGION}/workflows/scrape-pipeline/executions"
--http-method POST
--oauth-service-account-email "$COMPUTE_SA"
--oauth-token-scope „https://www.googleapis.com/auth/cloud-platform“
--message-body '{"argument":"{"urls":["http://books.toscrape.com","http://quotes.toscrape.com"]}"}'Ausführen Ihres ersten vollständigen Tests
Warten Sie nicht auf den Scheduler. Lösen Sie den Workflow manuell aus und beobachten Sie den gesamten Ablauf der Pipeline:
gcloud workflows run scrape-pipeline
--location "$REGION"
--data '{"urls":["http://books.toscrape.com","http://quotes.toscrape.com"]}'Sie können die Ausführung überwachen mit:
gcloud workflows executions list scrape-pipeline --location "$REGION"Warten Sie ein bis zwei Minuten. Sobald die Ausführung den Status SUCCEEDED anzeigt, sollten Ihre Daten in Firestore und BigQuery fließen.
Überprüfen der Daten
Lassen Sie uns nun überprüfen, ob die Daten tatsächlich dort gelandet sind, wo sie hingehören.
Überprüfen Sie die Zeilenanzahl in BigQuery:
bq query --use_legacy_sql=false "SELECT COUNT(*) AS total_rows FROM `${PROJECT_ID}.${BQ_DATASET}.${BQ_TABLE}`"Sehen Sie sich die neuesten Scraping-Ergebnisse an:
bq query --use_legacy_sql=false "SELECT source, url, scraped_at, job_id FROM `${PROJECT_ID}.${BQ_DATASET}.${BQ_TABLE}` ORDER BY scraped_at DESC LIMIT 10"Überprüfen Sie Firestore in der Konsole. Sie sollten zwei Sammlungen sehen: „jobs “ und „results“.
Rufen Sie dann die API auf, um zu überprüfen, ob sie alles lesen kann:
curl -s "$API_URL/jobs?limit=1"Nehmen Sie eine jobId aus der Antwort und gehen Sie näher darauf ein:
curl -s "$API_URL/jobs/YOUR_JOB_ID"
curl -s "$API_URL/results/YOUR_JOB_ID"Wenn all dies Daten zurückgibt, funktioniert Ihre Pipeline durchgängig.
CI/CD mit Cloud Build
Das Repository enthält eine Datei „cloudbuild.yaml“, die das Erstellen und Bereitstellen beider Dienste in einem Schritt übernimmt. Wenn Sie Änderungen ausliefern möchten, führen Sie einfach Folgendes aus:
gcloud builds submit --config cloudbuild.yaml .Mit diesem einzigen Befehl werden beide Docker-Images erstellt, an Artifact Registry übertragen und beide Cloud Run-Dienste bereitgestellt. Wenn Sie über eine einzelne Pipeline hinaus skalieren möchten, sehen Sie sich diese Übersicht der besten Tools für Web-Scraping an, um zu erfahren, wie verschiedene Lösungen eine cloudbasierte Einrichtung wie diese ergänzen können.
Abschließende Checkliste
Bevor Sie den Vorgang als abgeschlossen betrachten, führen Sie die folgenden Überprüfungsschritte durch:
gcloud run services list --region us-central1sollte beide Dienste anzeigen.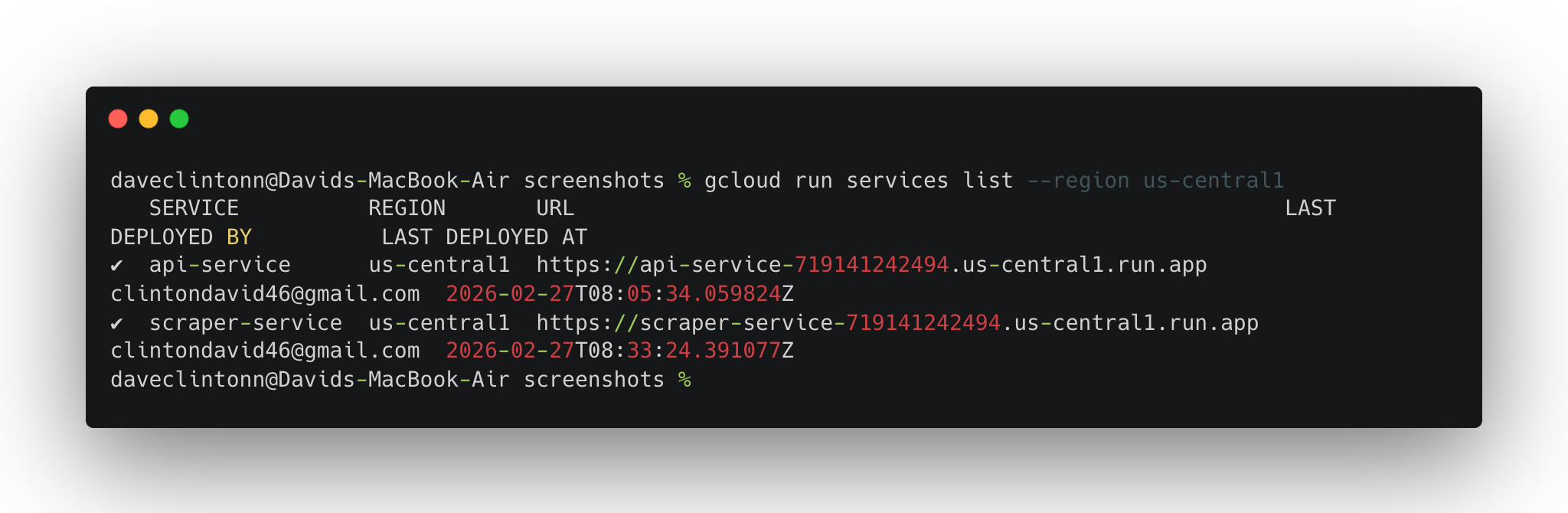
gcloud workflows describe scrape-pipeline --location us-central1sollte die Workflow-Details zurückgeben.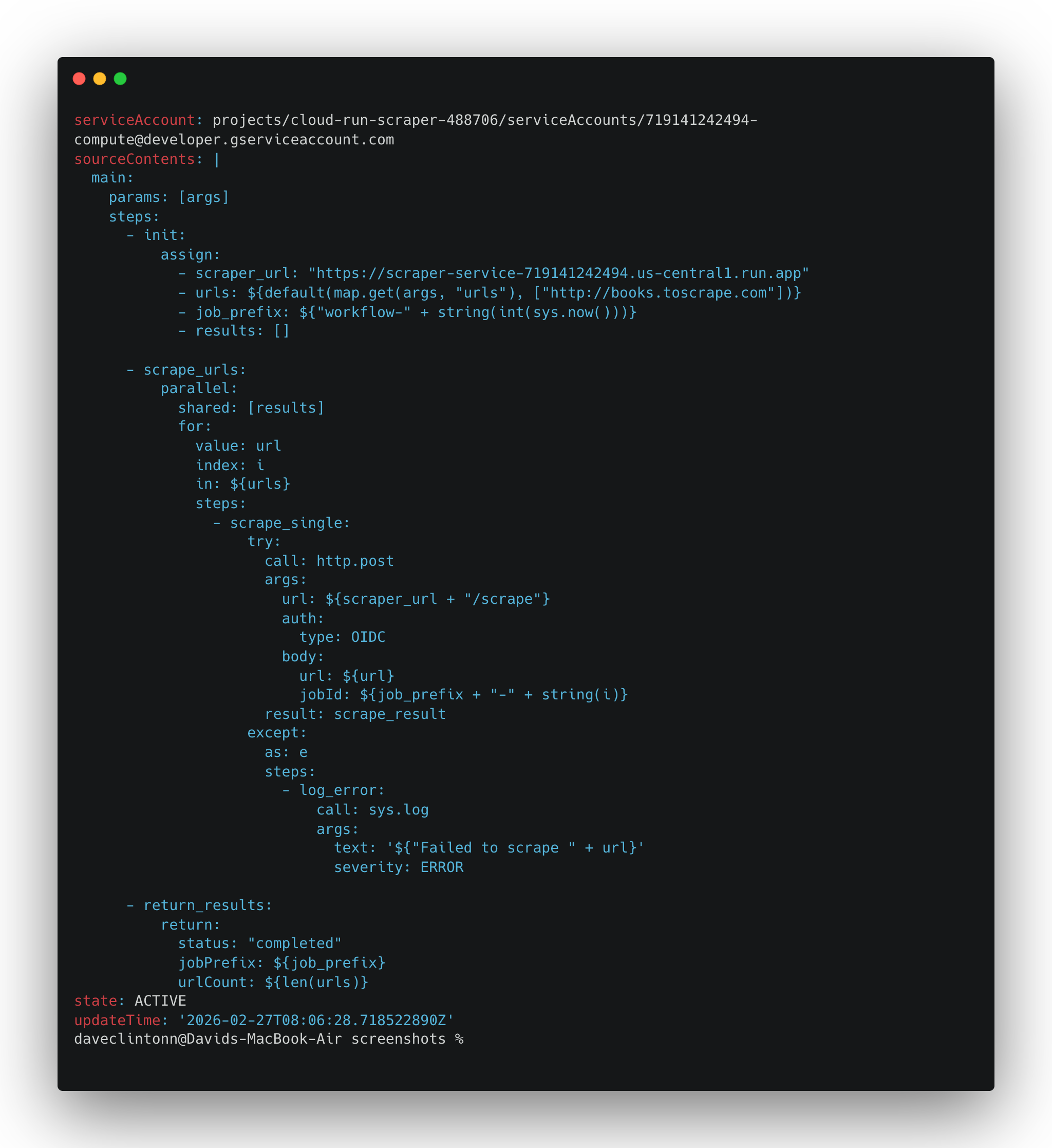
gcloud scheduler jobs list --location us-central1sollte den Scheduler-Job anzeigen.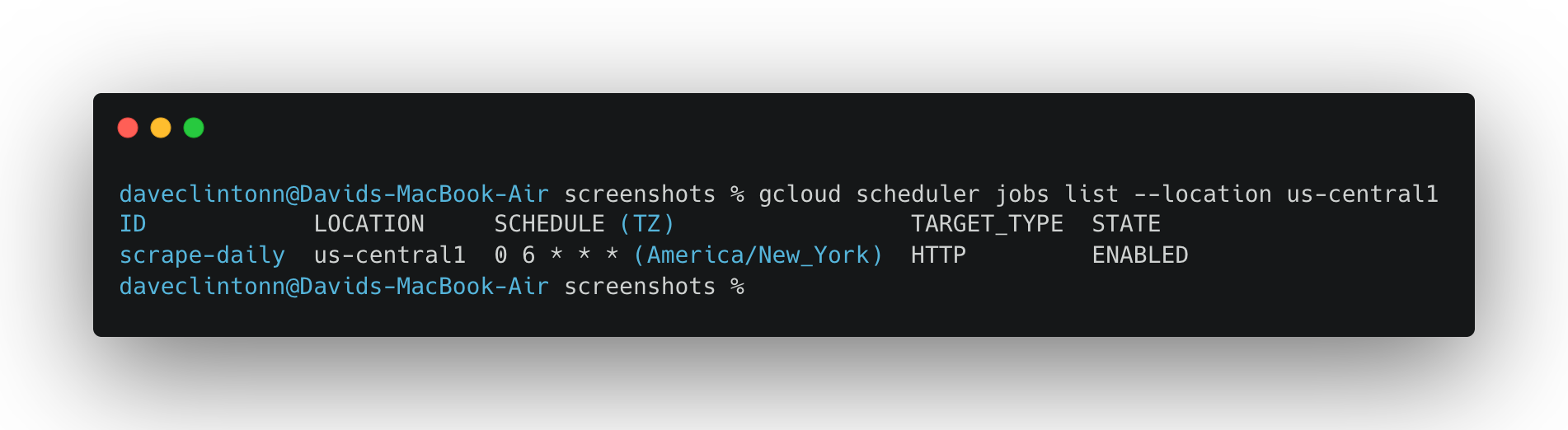
- Firestore sollte über
JobsundErgebnissammlungenverfügen. - Die BigQuery-Tabelle sollte Zeilen enthalten.
- Der API
-/jobs-Endpunkt sollte tatsächliche Datensätze zurückgeben.
Wenn alle sechs Punkte zutreffen, handelt es sich nicht mehr um eine Demo. Sie verfügen über eine echte Pipeline, die planmäßig scrapt, Daten an zwei Orten speichert und über eine öffentliche API bereitstellt.
Fazit
In diesem Leitfaden haben wir die Erstellung einer vollständigen serverlosen Web-Scraping-Pipeline auf Google Cloud durchlaufen. Wir haben die Einrichtung der Infrastruktur, die Bereitstellung von zwei Cloud Run-Diensten, die Orchestrierung von Scrape-Läufen mit Cloud Workflows und die Automatisierung aller Vorgänge mit Cloud Scheduler behandelt.
Wenn Sie einen verwalteten Ansatz gegenüber der Wartung Ihrer eigenen Infrastruktur bevorzugen, können Sie die vorab gesammelten Datensätze von Bright Data oder Scraper Studio nutzen, um jede Website in eine fertige Datenpipeline zu verwandeln. Sie können auch unseren Leitfaden zum serverlosen Scraping mit Scrapy und AWS lesen, um zu sehen, wie eine ähnliche Architektur bei einem anderen Cloud-Anbieter aussieht. Klonen Sie das Projekt, tauschen Sie Ihre eigenen Ziel-URLs aus, und schon haben Sie eine Scraping-Pipeline, die einsatzbereit ist.






