

In diesem Blogbeitrag erfahren Sie:
- Was Cartesia ist und was es für die Entwicklung von KI-Sprachagenten bietet.
- Warum Sprachassistenten (wie alle anderen Assistenten auch) Zugriff auf das Internet benötigen, um effektiv und wirklich vertrauenswürdig zu sein.
- Wie Sie einem Cartesia-KI-Sprachagenten mithilfe der Bright-Data-Integration die Fähigkeit verleihen, im Internet zu suchen und Informationen zu extrahieren.
Lassen Sie uns loslegen!
Was ist Cartesia?
Cartesia ist eine entwicklerorientierte Plattform zur Erstellung von Echtzeit-KI-Sprachagenten. Sie kombiniert Sprachmodelle mit geringer Latenz mit einem vollständigen Entwicklungs-Stack für Agenten und bietet alles, was Sie benötigen, um von der Idee zu einem produktionsreifen Sprachagenten zu gelangen.
Die Plattform ist auf schnelle Iteration ausgelegt und ermöglicht es Entwicklern, Dialogagenten mit minimalem Aufwand zu prototypisieren, bereitzustellen und zu verfeinern. Sie vereint Sprache, Schlussfolgerungen, Bereitstellung und Tests in einem einzigen, einheitlichen Ökosystem.
Der Sprachstack von Cartesia basiert auf zwei zentralen hauseigenen Modellen:
- Sonic: Ein Streaming-Text-to-Speech-Modell (TTS), das für extrem niedrige Latenz und eine ausdrucksstarke Ausgabe optimiert ist. Es kann lachen, Emotionen zeigen und natürliche, menschenähnliche Sprache in über 40 Sprachen wiedergeben.
- Ink: Ein schnelles und präzises Speech-to-Text-Modell (STT), das für reale Gespräche entwickelt wurde und mit Störgeräuschen, Akzenten und Sprachstörungen umgeht, während es eine Transkriptionsgeschwindigkeit nahezu in Echtzeit beibehält.
Zur Erstellung von Agenten bietet Cartesia sowohl einen integrierten Web-Agent-Builder als auch Line, sein Open-Source-SDK. Das Cartesia-SDK unterstützt Vorlagen, Tool-Integration, Multi-Agent-Orchestrierung und vieles mehr. Damit haben Sie alles, was Sie benötigen, um intelligente, produktionsreife Sprachagenten zu entwickeln.
Warum Sprachagenten Webzugriff benötigen
Cartesia ist zweifellos eine funktionsreiche Lösung für die Entwicklung von KI-Sprachagenten, die über LiteLLM mehr als 100 LLMs unterstützt. Doch trotz dieser großen Auswahl haben alle LLMs dieselbe inhärente Einschränkung: Ihr Wissen ist auf einen bestimmten Zeitpunkt eingefroren. Dies kann zu veralteten Antworten, Halluzinationen oder Lücken führen, wenn Agenten reale, aktuelle Aufgaben bewältigen müssen.
Zudem können LLMs nicht nativ auf das Web zugreifen oder mit externen Systemen interagieren. Infolgedessen bleiben Standard-Agenten-Workflows durch die Einschränkungen der Modelle begrenzt. Um dies zu überwinden, ist die Integration mit externen Diensten über benutzerdefinierte Tools unerlässlich.
Hier kommt Bright Data ins Spiel. Durch die Verbindung von Cartesia mit Bright Data können Ihre Agenten auf Echtzeitinformationen, Suchergebnisse und strukturierte Daten von jeder beliebigen Website zugreifen.
Die Infrastruktur von Bright Data auf Unternehmensniveau verfügt über eines der größten Proxy-Netzwerke der Welt mit über 400 Millionen IP-Adressen in 195 Ländern und ermöglicht einen sicheren, zuverlässigen und skalierbaren Zugriff auf Live-Webinhalte.
Zu den wichtigsten Bright Data-Produkten, mit denen Sie Cartesia-Sprachagenten ausstatten können, gehören:
- SERP-API: Sammeln Sie Suchmaschinenergebnisse von Google, Bing und anderen, um fundierte Antworten zu ermöglichen.
- Web Unlocker API: Greifen Sie auf Inhalte jeder Website im Raw-HTML- oder Markdown-Format zu und umgehen Sie dabei CAPTCHAs und Anti-Bot-Schutzmaßnahmen.
- Web Scraper APIs: Extrahieren Sie strukturierte Daten von Plattformen wie Amazon, LinkedIn und Instagram.
- Crawl API: Wandeln Sie ganze Websites in strukturierte Datensätze für nachgelagerte KI-Workflows um.
Mit Bright Data sind Cartesia-Agenten nicht mehr auf vorab trainiertes Wissen beschränkt. Sie können aktuelle, verlässliche Webdaten erkunden, abrufen und auswerten. Dadurch können sie genauere, kontextbezogene und umsetzbare Antworten liefern.
So erstellen Sie einen Cartesia-KI-Sprachagenten auf Basis der Webdatenabfrage von Bright Data
In dieser Schritt-für-Schritt-Anleitung erfahren Sie, wie Sie mit Cartesia einen KI-Sprachagenten erstellen. Der Agent wird mithilfe von Bright Data um Funktionen zur Websuche und zum Web-Scraping erweitert.
Insbesondere simuliert der KI-Sprachagent die Erstellung eines kurzen, nachrichtenartigen Berichts zu einem bestimmten Thema, den Sie sich anhören können. Sie können auch mit dem Agenten chatten, um Folgefragen zu stellen und das Thema weiter zu vertiefen.
Hinweis: Dies ist nur eine mögliche Implementierung eines KI-Sprachagenten. Die Integration von Bright Data unterstützt viele weitere Anwendungsfälle.
Konkret werden Sie zwei der KI-fähigen Produkte von Bright Data integrieren:
- Web Unlocker API, um dem Agenten die Möglichkeit zu geben, Daten aus beliebigen URLs zu extrahieren.
- SERP-API, damit der Agent das Web durchsuchen kann.
Zusammen ermöglichen diese Tools dem KI-Agenten, das Such- und Extraktionsmuster anzuwenden. Das ist ideal für die Datenerfassung und Web-Erkundung.
Für mehr programmatische Kontrolle beim Erstellen des Agenten werden wir auf Line (d. h. das Cartesia SDK) zurückgreifen. Der Grund dafür ist, dass sich der Agent Builder zwar hervorragend für das Prototyping eignet, aber etwas eingeschränkt ist.
Befolgen Sie die nachstehenden Anweisungen!
Voraussetzungen
Um dieses Tutorial mitverfolgen zu können, stellen Sie sicher, dass Sie über Folgendes verfügen:
- Ein Unix-basiertes Betriebssystem (Linux, macOS oder WSL unter Windows).
- Python 3.9+ lokal installiert.
uvlokal installiert.- Ein API-Schlüssel von einem der von Cartesia unterstützten LLM-Anbieter (hier verwenden wir einen Gemini-API-Schlüssel).
- Ein Bright Data-Konto mit eingerichteter Web Unlocker API und SERP-API sowie einem API-Schlüssel.
- Ein Cartesia-Konto mit einem konfigurierten API-Schlüssel.
Machen Sie sich vorerst keine Gedanken über die Einrichtung der Bright Data- und Cartesia-Konten, da Sie in den entsprechenden Unterkapiteln durch den Prozess geführt werden.
Schritt 1: Ein Cartesia-Projekt initialisieren
Erstellen Sie zunächst mit uv einen Ordner für Ihr Projekt (dies ist der im Cartesia-Schnellstartleitfaden empfohlene Ansatz):
uv init cartesia-bright-data-voice-agentWechseln Sie in den Projektordner:
cd cartesia-bright-data-voice-agentSie sollten eine Ordnerstruktur wie diese sehen:
cartesia-bright-data-voice-agent/
├── .git/
├── .gitignore
├── .python-version
├── README.md
├── main.py
└── pyproject.tomlDies ist das Ergebnis des Befehls „uv init “.
Konzentrieren Sie sich auf die Datei main.py. Dort fügen Sie Ihre Cartesia-Logik hinzu, um einen KI-Sprachagenten zu entwerfen, der mit Funktionen zum Abrufen und Suchen von Webdaten mithilfe von Bright Data erweitert ist.
Installieren Sie als Nächstes die Projektabhängigkeiten mit:
uv add cartesia-line requestsDie beiden erforderlichen Bibliotheken sind:
cartesia-line: Das Cartesia Line SDK zum Erstellen intelligenter Sprachagenten mit geringer Latenz.requests: Der beliebte Python-HTTP-Client, der zum Aufrufen der Bright Data-APIs in benutzerdefinierten Cartesia-Tools verwendet wird.
Diese Bibliotheken werden von uv automatisch in einer virtuellen.venv- Umgebung installiert. Jetzt können Sie das Projekt direkt in Ihrer bevorzugten Python-IDE öffnen.
Gut gemacht! Ihr leeres Cartesia-Projekt ist startklar.
Schritt 2: Erste Schritte mit der Cartesia-CLI
Um einen Cartesia-Agenten lokal zu testen, müssen Sie die Cartesia-CLI installieren und sich dort anmelden. Für die Authentifizierung benötigen Sie einen Cartesia-API-Schlüssel, also bereiten wir diesen zuerst vor!
Wenn Sie noch kein Konto haben, erstellen Sie ein neues Cartesia-Konto. Andernfalls melden Sie sich an. Nach der Anmeldung gelangen Sie zum Dashboard:
Wechseln Sie nun zur Seite „API Keys“ und klicken Sie auf die Schaltfläche „New“:
Geben Sie Ihrem API-Schlüssel einen Namen (z. B. „Bright Data-Powered Voice Agent“), klicken Sie auf „Create“, und der API-Schlüssel wird in einem Modal angezeigt.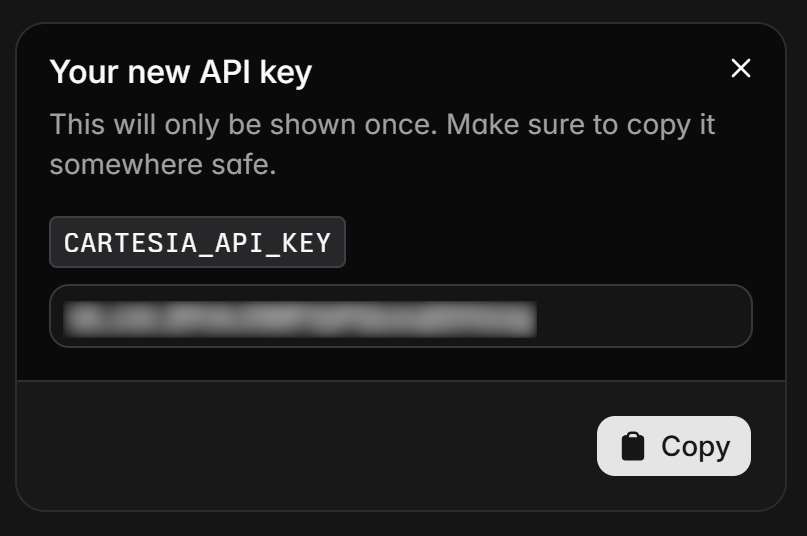
Kopieren Sie den API-Token und bewahren Sie ihn sicher auf, da Sie ihn bald benötigen werden.
Installieren Sie in Ihrem Unix-basierten Terminal die Cartesia-CLI mit:
curl -fsSL https://cartesia.sh | shStarten Sie nach der Installation Ihre Shell neu, damit Sie den Befehl „cartesia“ von überall aus verwenden können.
Um sich in der CLI zu authentifizieren, führen Sie folgenden Befehl aus:
cartesia auth loginSie werden aufgefordert, Ihren Cartesia-API-Schlüssel einzugeben. Fügen Sie ihn ein und drücken Sie die Eingabetaste. Bei erfolgreicher Anmeldung sollte eine Meldung wie diese angezeigt werden: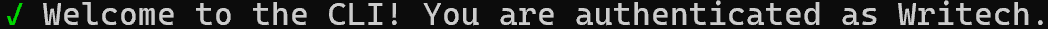
Hinweis: In diesem Beispiel lautet „Writech“ der Name der Cartesia-Organisation. In Ihrem Fall wird eine auf Ihre Organisation zugeschnittene Meldung angezeigt.
Perfekt! Jetzt ist es an der Zeit, Ihr Bright Data-Konto einzurichten, um die ersten Voraussetzungen zu erfüllen.
Schritt 3: Richten Sie ein Bright Data-Konto ein
Um die SERP-API und den Web Unlocker in Cartesia zu verbinden, benötigen Sie zunächst ein Bright Data-Konto, in dem sowohl eine SERP-API-Zone als auch eine Web Unlocker-API-Zone eingerichtet sind, sowie einen API-Schlüssel.
Wenn Sie noch kein Bright Data-Konto haben, erstellen Sie ein neues. Wenn Sie bereits ein Konto haben, melden Sie sich an. Gehen Sie zu Ihrem Control Panel, navigieren Sie zur Seite „Proxies & Scraping“ und überprüfen Sie die Tabelle „My Zones“: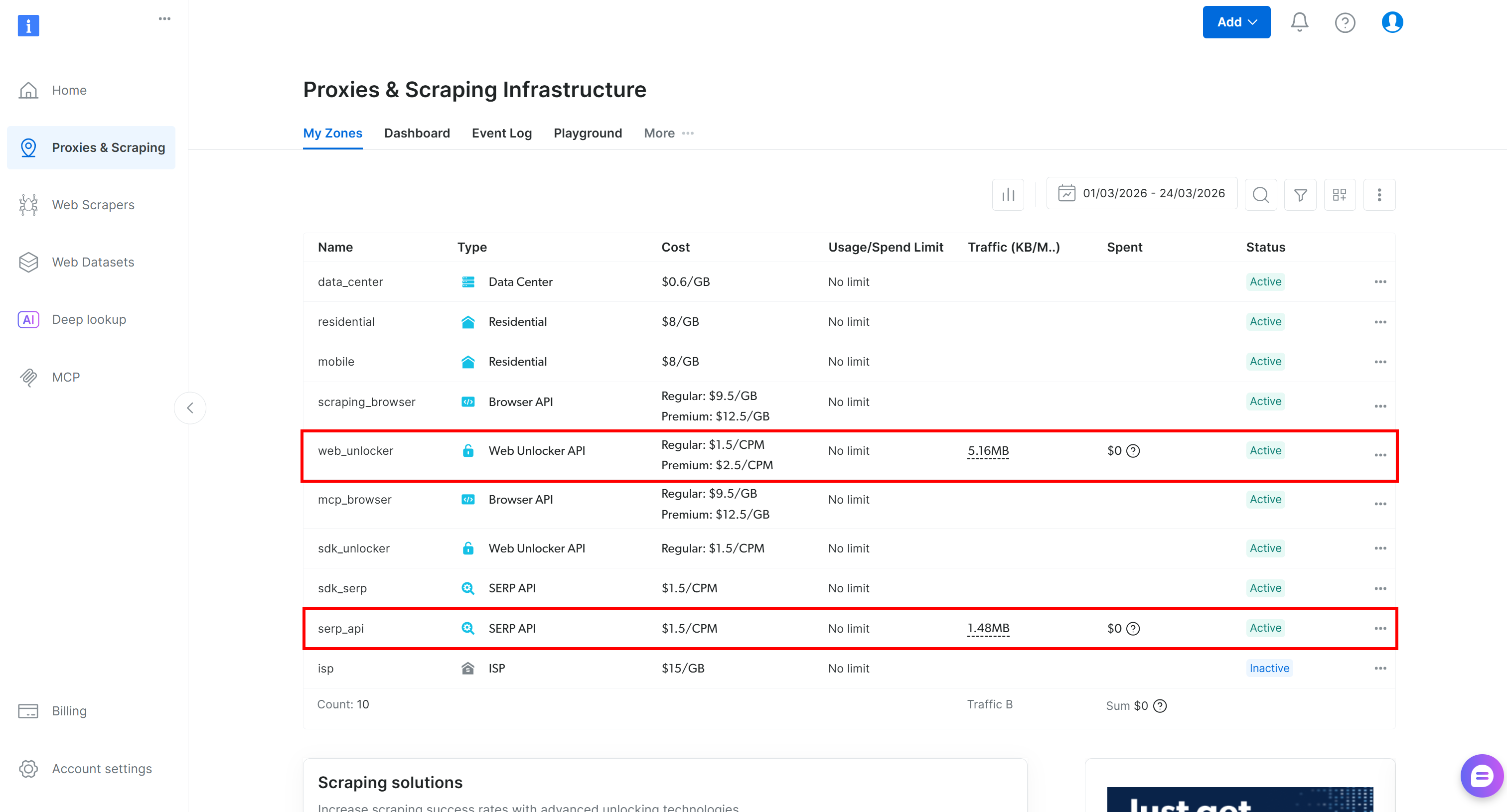
Wenn in der Tabelle bereits eine Web Unlocker-API-Zone (z. B. web_unlocker) und eine SERP-API-Zone (z. B. serp_api) aufgeführt sind, sind Sie startklar. Diese beiden Zonen werden verwendet, um die Web Unlocker- und SERP-API-Dienste über benutzerdefinierte Tools aufzurufen.
Falls eine der Zonen fehlt, erstellen Sie sie. Scrollen Sie zu den Karten „Unblocker API“ und „SERP-API“ und klicken Sie dann auf „Zone erstellen“. Folgen Sie den Anweisungen des Assistenten, um beide Zonen hinzuzufügen: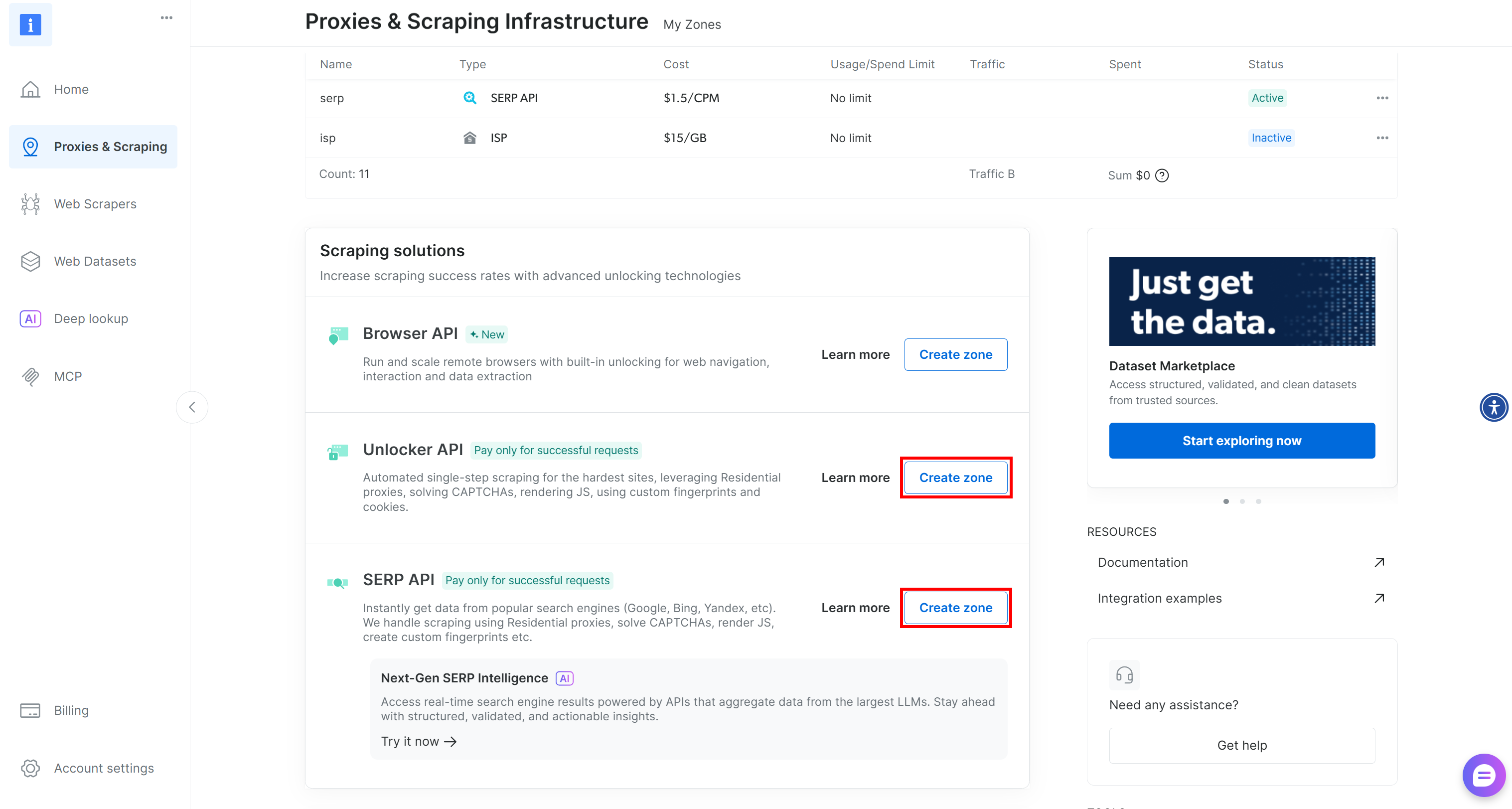
Ausführliche Anleitungen finden Sie auf diesen Dokumentationsseiten:
Merken Sie sich die Namen, die Sie beiden Zonen zuweisen, da Sie diese im nächsten Schritt benötigen. Erstellen Sie abschließend Ihren Bright Data API-Schlüssel und bewahren Sie ihn sicher auf.
Großartig! Bright Data ist nun bereit für die Integration in Cartesia.
Schritt 4: Konfigurieren des Lesens von Umgebungsvariablen
Dieser Workflow für den KI-Sprachagenten hängt von einigen geheimen Daten ab: einem LLM-Anbieter (in diesem Fall Gemini) und Bright Data (API-Schlüssel + Zonennamen). Das Festschreiben dieser geheimen Daten in Ihrem Code stellt ein Sicherheitsrisiko dar, daher ist es besser, sie in Umgebungsvariablen zu speichern.
Die Cartesia-CLI liest automatisch im Hintergrund mithilfe von python-dotenv eine .env-Datei ein, sodass Sie alle Ihre Geheimnisse dort speichern können. Fügen Sie zunächst eine .env- Datei zu Ihrem Projektverzeichnis hinzu:
cartesia-bright-data-voice-agent/
├── .git/
├── .env # <-----------
├── .gitignore
├── .python-version
├── README.md
├── main.py
└── pyproject.tomlFügen Sie dann Ihre Geheimnisse ein:
GEMINI_API_KEY="<YOUR_GEMINI_API_KEY>"
BRIGHT_DATA_API_KEY="<YOUR_BRIGHT_DATA_API_KEY>"
BRIGHT_DATA_WEB_UNLOCKER_ZONE="<YOUR_BRIGHT_DATA_WEB_UNLOCKER_ZONE>" # z. B. "web_unlocker"
BRIGHT_DATA_SERP_API_ZONE="<YOUR_BRIGHT_DATA_SERP_API_ZONE>" # z. B. "serp_api"Ersetzen Sie alle Platzhalter durch Ihre tatsächlichen Werte. Da der Workflow erst starten sollte, wenn alle diese Geheimnisse festgelegt sind, fügen Sie die folgende Logik zu main.py hinzu:
import os
GEMINI_API_KEY = os.getenv("GEMINI_API_KEY")
if not GEMINI_API_KEY:
raise EnvironmentError("Fehlende Umgebungsvariable: GEMINI_API_KEY")
BRIGHT_DATA_API_KEY = os.getenv("BRIGHT_DATA_API_KEY")
if not BRIGHT_DATA_API_KEY:
raise EnvironmentError("Fehlende Umgebungsvariable: BRIGHT_DATA_API_KEY")
BRIGHT_DATA_SERP_API_ZONE = os.getenv("BRIGHT_DATA_SERP_API_ZONE")
if not BRIGHT_DATA_SERP_API_ZONE:
raise EnvironmentError("Fehlende Umgebungsvariable: BRIGHT_DATA_SERP_API_ZONE")
BRIGHT_DATA_WEB_UNLOCKER_ZONE = os.getenv("BRIGHT_DATA_WEB_UNLOCKER_ZONE")
if not BRIGHT_DATA_WEB_UNLOCKER_ZONE:
raise EnvironmentError("Fehlende Umgebungsvariable: BRIGHT_DATA_WEB_UNLOCKER_ZONE")Beachten Sie, dass die Verwendung einer .env-Datei nicht erforderlich ist. Sie können die Umgebungsvariablen auch direkt in Ihrem Terminal mit folgendem Befehl setzen:
export GEMINI_API_KEY="<YOUR_GEMINI_API_KEY>" BRIGHT_DATA_API_KEY="<YOUR_BRIGHT_DATA_API_KEY>" BRIGHT_DATA_WEB_UNLOCKER_ZONE="<YOUR_BRIGHT_DATA_WEB_UNLOCKER_ZONE>" BRIGHT_DATA_SERP_API_ZONE="<YOUR_BRIGHT_DATA_SERP_API_ZONE>"Hervorragend! Ihre Umgebungsvariablen sind nun sicher eingerichtet. Als Nächstes: Implementierung der Bright Data-Tools für Web-Scraping und Suche.
Schritt 5: Definieren Sie das Web Unlocker-Tool für das Web-Scraping
Standardmäßig kann ein Cartesia-KI-Sprachagent nicht auf das externe Web zugreifen. Um dies zu ermöglichen, müssen Sie ihn mit benutzerdefinierten Tools ausstatten, die der Agent aufrufen kann. Hier definieren Sie ein Tool zur Verbindung mit der Web Unlocker-API von Bright Data für das Web-Scraping.
In Cartesia ist ein Tool nichts anderes als eine Funktion, die mit einem der verfügbaren Tool-Dekoratoren versehen ist. Im Folgenden wird gezeigt, wie Sie ein Cartesia-Web-Scraping-Tool erstellen, das eine Verbindung zur Web Unlocker-API herstellt:
@loopback_tool
def bright_data_web_unlocker(
ctx,
page_url: Annotated[str, "Die URL der zu scrapenden Seite"]
) -> str:
"""
Abrufen von Webseiteninhalten mithilfe der Bright Data Web Unlocker API
"""
url = "https://api.brightdata.com/request"
data = {
"Zone": BRIGHT_DATA_WEB_UNLOCKER_ZONE,
"url": page_url,
"format": "raw",
"data_format": "markdown"
}
headers = {
"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}",
"Content-Type": "application/json"
}
# Anfrage an die Bright Data Web Unlocker API senden
response = requests.post(url, json=data, headers=headers)
response.raise_for_status()
return response.textBeachten Sie, dass das Cartesia SDK den Docstring der Funktion als Tool-Beschreibung und die Typ-Annotationen für ihre Parameter verwendet. Außerdem muss der erste Parameter jedes Tools ctx sein, der den Tool-Kontext darstellt. Dies ermöglicht den Zugriff auf den Konversationsstatus und gewährleistet Vorwärtskompatibilität.
Die Funktion `bright_data_web_unlocker()` nutzt den Requests-HTTP-Client, um eine POST-Anfrage an Ihre Bright Data Web Unlocker API-Zone zu senden. Dies gibt die Markdown-Version der im Argument ` page_url` angegebenen Webseite zurück. Weitere Details zu den verfügbaren Parametern und Optionen finden Sie in der Bright Data-Dokumentation.
Beachten Sie, dass das Argument data_format auf „markdown“ gesetzt ist. Dadurch wird die Funktion„Scrape as Markdown“aktiviert, um den gescrapten Inhalt in einem KI-optimierten Markdown-Format zu erhalten –ideal für die LLM-Aufnahme. Das Argument format ist auf „raw“ gesetzt, sodass die API mit dem reinen gescrapten Markdown-Inhalt antwortet, anstatt ihn in JSON zu verpacken.
Großartig! Ihre Cartesia-KI-Anwendung enthält nun ein Tool für das erfolgreiche Web-Scraping beliebiger Websites mit Bright Data.
Schritt 6: Definieren Sie das SERP-API-Tool für die Websuche
Definieren Sie auf ähnliche Weise ein benutzerdefiniertes Funktionstool, um die SERP-API aufzurufen:
@loopback_tool
def bright_data_serp_api(
ctx,
query: Annotated[str, "Die Google-Suchanfrage"]
) -> str:
"""
Durchsuche das Web nach einem bestimmten Begriff mithilfe der SERP-API von Bright Data.
"""
url = "https://api.brightdata.com/request"
data = {
"zone": BRIGHT_DATA_SERP_API_ZONE,
"url": f"https://www.google.com/search?q={urllib.parse.quote_plus(query)}&brd_json=1",
"format": "raw"
}
headers = {
"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}",
"Content-Type": "application/json"
}
# Anfrage an die Bright Data SERP-API senden
response = requests.post(url, json=data, headers=headers)
response.raise_for_status()
return response.textDiese Funktion sendet eine POST-Anfrage an Ihre SERP-API-Zone. Sie sendet eine Abfrage an Google und ruft die geparsten Suchergebnisse über Bright Data ab. Weitere Informationen finden Sie in der Dokumentation zur Bright Data SERP-API.
Großartig! Ihre Cartesia-Anwendung enthält nun die erforderlichen, von Bright Data unterstützten Tools.
Schritt 7: Definieren Sie den Cartesia-Sprachagenten
Zu diesem Zeitpunkt verfügen Sie über alle Bausteine, die Sie zur Definition Ihres Cartesia-Agents benötigen. Der empfohlene Ansatz ist die Verwendung der integrierten LlmAgent-Klasse, die über LiteLLM mehr als 100 LLM-Anbieter unterstützt.
Um den Sprachagenten zu definieren, übergeben Sie der Klasse:
- Das LLM-Modell und den API-Schlüssel.
- Die Tools, die er verwenden kann.
- Eine Systemaufforderung, die beschreibt, was der Agent tun soll.
- Eine Startnachricht.
So fügen Sie alles zusammen:
from line.llm_agent import LlmAgent, LlmConfig, end_call
from line.voice_agent_app import VoiceAgentApp
async def get_agent(env, call_request):
# Definiere den KI-Sprachagenten
SYSTEM_PROMPT = """
Du bist ein hilfsbereiter Assistent, der im Internet recherchieren kann, um aktuelle Informationen abzurufen.
Antworte in einem klaren, nachrichtenartigen und informativen Ton.
"""
return LlmAgent(
model="gemini/gemini-3-flash-preview",
api_key=GEMINI_API_KEY,
tools=[
end_call,
bright_data_web_unlocker,
bright_data_serp_api
],
config=LlmConfig(
system_prompt=SYSTEM_PROMPT,
introduction="Hallo! Wie kann ich Ihnen heute helfen?",
),
)Ein paar Dinge, die zu beachten sind:
- Das
Tools-Array enthält die beiden zuvor definierten benutzerdefinierten Bright Data-Tools (bright_data_web_unlockerundbright_data_serp_api). - Das integrierte Tool
„end_call“ist erforderlich, damit der Agent eine Konversation ordnungsgemäß beenden kann. - Das konfigurierte LLM-Modell ist Gemini 3 Flash, aber jedes andere Gemini-Modell ist ebenfalls geeignet.
Registrieren Sie den Agenten abschließend in der Klasse „VoiceAgentApp“ und führen Sie ihn aus:
app = VoiceAgentApp(get_agent=get_agent)
if __name__ == "__main__":
app.run()Mission erfüllt! Sie haben einen KI-Sprachagenten für Antworten im Nachrichtenstil erstellt. Dieser Agent ist in der Lage, Echtzeitinformationen aus dem Internet zu suchen und abzurufen, um genauere und aktuellere Antworten zu liefern.
Schritt 8: Endgültiger Code
Dies sollte die Datei main.py nun enthalten:
# uv add cartesia-line requests
import os
from line.llm_agent import loopback_tool
from typing import Annotated
import requests
import urllib
from line.llm_agent import LlmAgent, LlmConfig, end_call
from line.voice_agent_app import VoiceAgentApp
# Die erforderlichen Geheimnisse aus der Umgebung lesen
GEMINI_API_KEY = os.getenv("GEMINI_API_KEY")
if not GEMINI_API_KEY:
raise EnvironmentError("Fehlende Umgebungsvariable: GEMINI_API_KEY")
BRIGHT_DATA_API_KEY = os.getenv("BRIGHT_DATA_API_KEY")
if not BRIGHT_DATA_API_KEY:
raise EnvironmentError("Fehlende Umgebungsvariable: BRIGHT_DATA_API_KEY")
BRIGHT_DATA_SERP_API_ZONE = os.getenv("BRIGHT_DATA_SERP_API_ZONE")
if not BRIGHT_DATA_SERP_API_ZONE:
raise EnvironmentError("Fehlende Umgebungsvariable: BRIGHT_DATA_SERP_API_ZONE")
BRIGHT_DATA_WEB_UNLOCKER_ZONE = os.getenv("BRIGHT_DATA_WEB_UNLOCKER_ZONE")
if not BRIGHT_DATA_WEB_UNLOCKER_ZONE:
raise EnvironmentError("Fehlende Umgebungsvariable: BRIGHT_DATA_WEB_UNLOCKER_ZONE")
@loopback_tool
def bright_data_web_unlocker(
ctx,
page_url: Annotated[str, "Die URL der zu scrapenden Seite"]
) -> str:
"""
Abrufen des Webseiteninhalts mithilfe der Bright Data Web Unlocker API
"""
url = "https://api.brightdata.com/request"
data = {
"Zone": BRIGHT_DATA_WEB_UNLOCKER_ZONE,
"url": page_url,
"format": "raw",
"data_format": "markdown"
}
headers = {
"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}",
"Content-Type": "application/json"
}
# Anfrage an die Bright Data Web Unlocker API senden
response = requests.post(url, json=data, headers=headers)
response.raise_for_status()
return response.text
@loopback_tool
def bright_data_serp_api(
ctx,
query: Annotated[str, "Die Google-Suchanfrage"]
) -> str:
"""
Durchsuche das Web nach einem bestimmten Begriff mithilfe der SERP-API von Bright Data.
"""
url = "https://api.brightdata.com/request"
data = {
"Zone": BRIGHT_DATA_SERP_API_ZONE,
"url": f"https://www.google.com/search?q={urllib.parse.quote_plus(query)}&brd_json=1",
"format": "raw"
}
headers = {
"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}",
"Content-Type": "application/json"
}
# Anfrage an die Bright Data SERP-API senden
response = requests.post(url, json=data, headers=headers)
response.raise_for_status()
return response.text
async def get_agent(env, call_request):
# Den KI-Sprachassistenten definieren
SYSTEM_PROMPT = """
Du bist ein hilfsbereiter Assistent, der im Internet suchen kann, um aktuelle Informationen abzurufen.
Antworte in einem klaren, nachrichtenartigen und informativen Ton.
"""
return LlmAgent(
model="gemini/gemini-2.5-flash",
api_key=GEMINI_API_KEY,
tools=[
end_call,
bright_data_web_unlocker,
bright_data_serp_api
],
config=LlmConfig(
system_prompt=SYSTEM_PROMPT,
introduction="Hallo! Wie kann ich Ihnen heute helfen?",
),
)
app = VoiceAgentApp(get_agent=get_agent)
if __name__ == "__main__":
app.run()Cool! Mit nur etwa 100 Zeilen Python-Code haben Sie einen leistungsstarken Sprach-KI-Agenten mit Funktionen zur Erkennung von Webdaten erstellt.
Schritt 9: Testen des Sprachagenten
Stellen Sie sicher, dass Sie alle erforderlichen Umgebungsvariablen definiert haben (entweder in einer .env-Datei oder über einen export- Befehl). Starten Sie dann den Agenten mit:
PORT=8000 uv run python main.pyDadurch wird die Cartesia-App lokal unter http://localhost:8000 gestartet, wie in den Protokollen zu sehen ist:
Interagieren Sie in einem separaten Terminal mit Ihrem Agenten, indem Sie Folgendes ausführen:
cartesia chat 8000Die Cartesia-Chat-Umgebung wird direkt in Ihrem Terminal gestartet: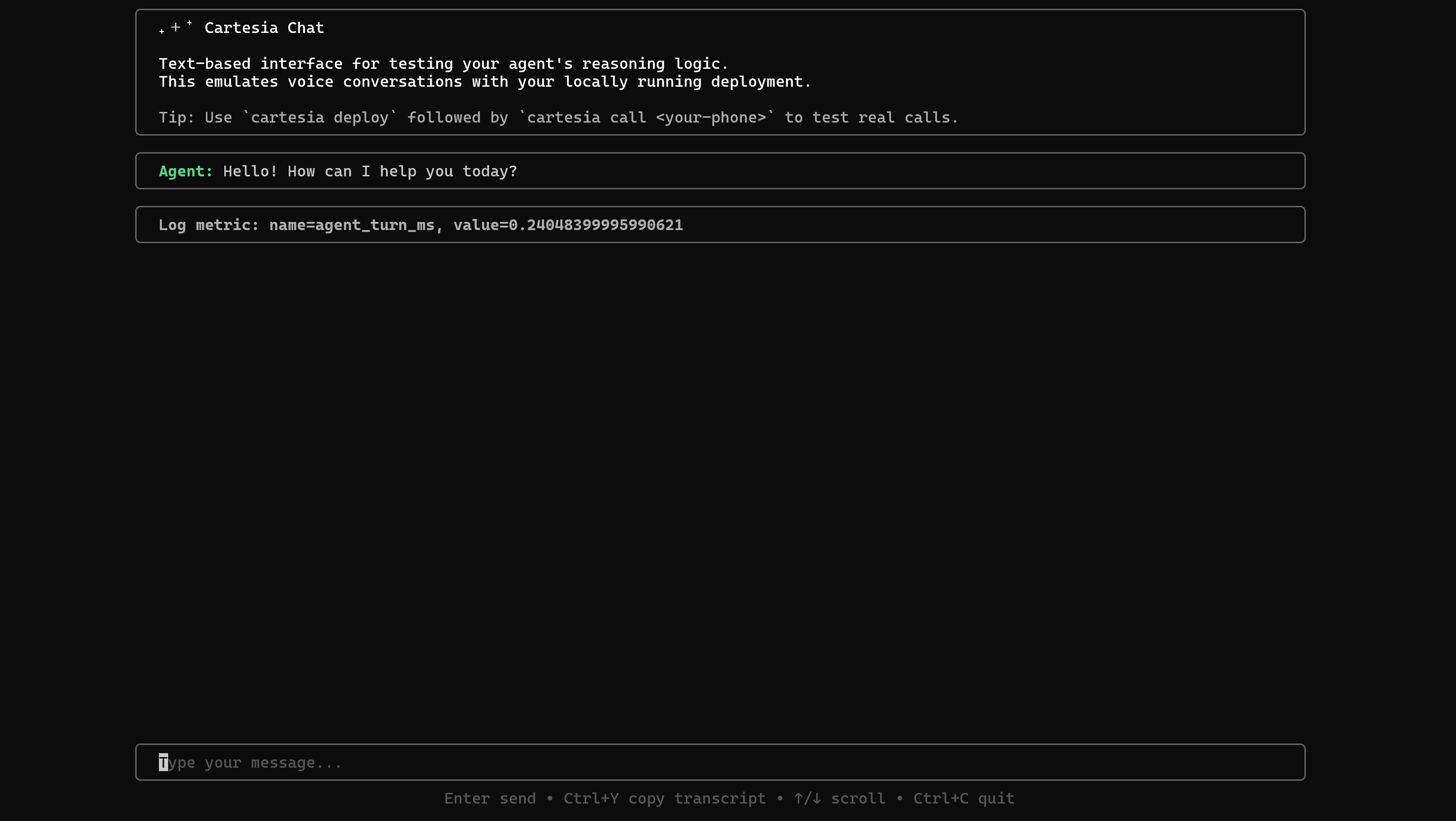
Mit dieser Konfiguration können Sie Gespräche per Chat statt per Sprache simulieren, was das Testen erheblich vereinfacht.
Probieren Sie eine Eingabe wie diese aus:
Suchen Sie im Internet nach der Suchanfrage „US inflation news“, wählen Sie 3 bis 5 spezifische Artikel aus (keine Nachrichten-Hub-Seiten), extrahieren Sie deren Inhalt und erstellen Sie anhand dieser Informationen einen etwa 3-minütigen Podcast, der die wichtigsten Erkenntnisse zusammenfasst und die Quellen angibt.Im Folgenden sehen Sie, was passieren sollte:
Beachten Sie, wie der Agent zunächst das Tool „bright_data_serp_api“ mit der Suchanfrage „US inflation news“ aufruft . Im anderen Terminal sehen Sie Protokolle mit den JSON-Ergebnissen, die von der Bright Data SERP-API zurückgegeben werden . Aus diesen Ergebnissen wählt der Agent 3 relevante Artikel-URLs aus: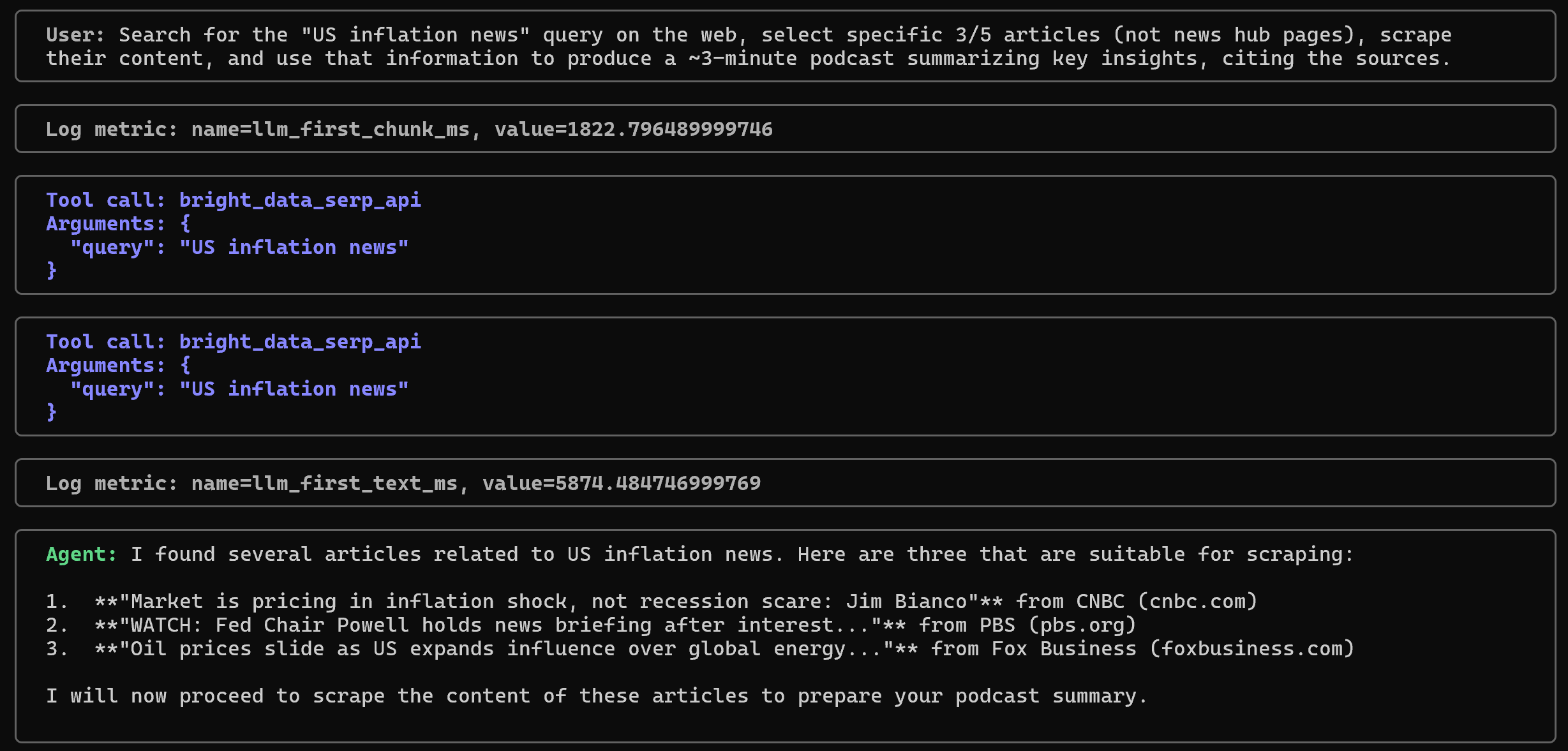
Anschließend extrahiert er den Inhalt jeder Seite mithilfe des Tools „bright_data_web_unlocker“ und erstellt eine durch Quellen belegte Zusammenfassung: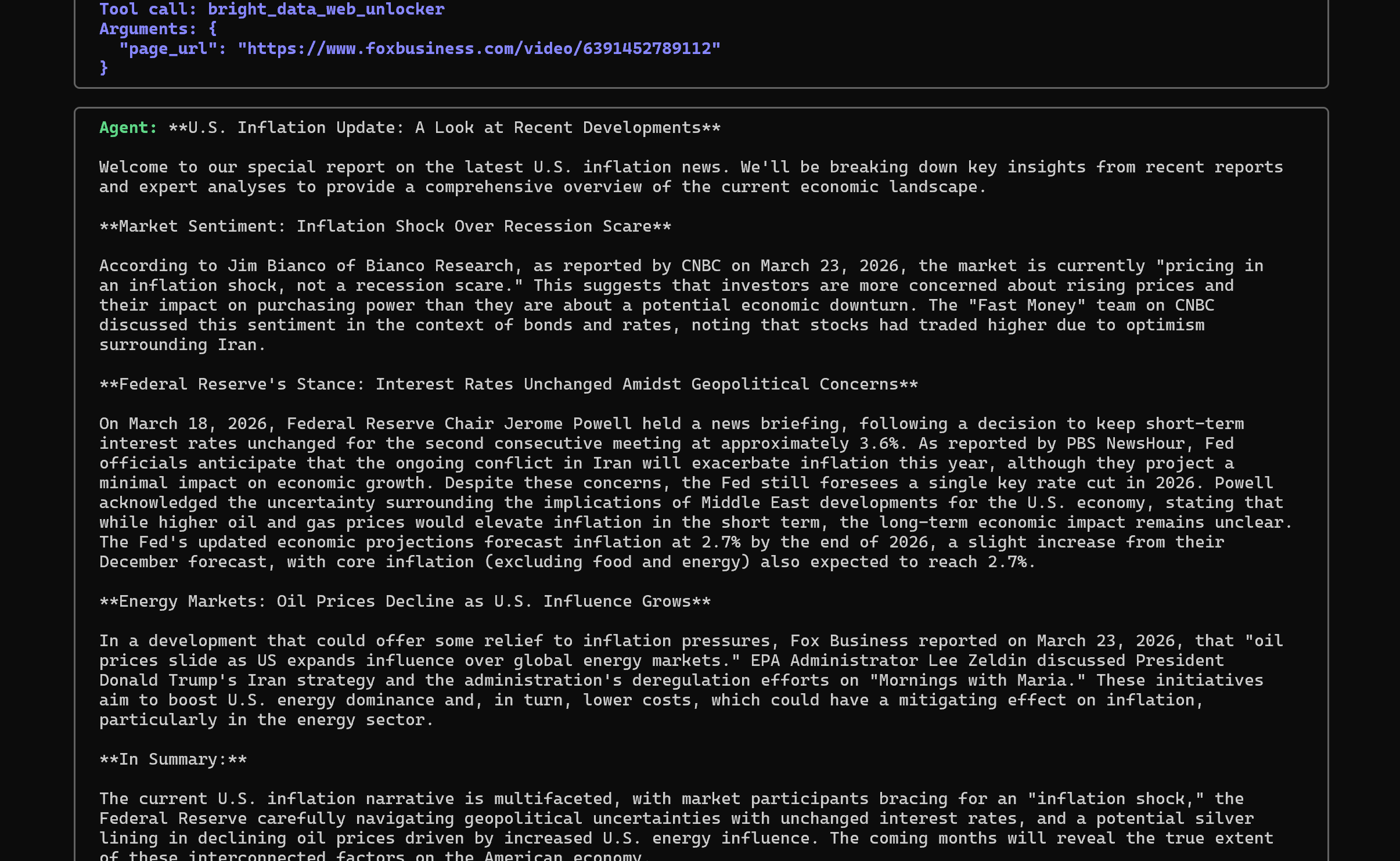
Beachten Sie, wie der Ton der Antwort dem eines Journalisten ähnelt und mit der zuvor definierten Systemaufforderung übereinstimmt.
Et voilà! Sie haben erfolgreich einen Sprachagenten erstellt, der aktiv im Web suchen und Informationen abrufen kann, was zu kontextbezogeneren und genaueren Antworten führt. Ohne die Integration der Such- und Scraping-Tools von Bright Data wäre dies nicht möglich gewesen.
Nächste Schritte
Nachdem Sie nun über einen funktionierenden KI-Sprachassistenten verfügen, besteht der nächste Schritt darin, ihn in Cartesia bereitzustellen und von Ihrem Smartphone aus aufzurufen. Um Ihren Assistenten weiter zu verfeinern und an Ihre Bedürfnisse anzupassen, lesen Sie die Dokumentation.
Beachten Sie schließlich, dass Sie – genau wie wir in diesem Tutorial gezeigt haben – andere API-basierte Produkte von Bright Data integrieren können. Dadurch wird Ihr Agent um zusätzliche Funktionen erweitert.
Denken Sie daran, dass Cartesia viele Integrationen unterstützt, darunter LiveKit (eine weitere Technologie zur Erstellung von KI-Sprachagenten). Weitere Informationen finden Sie unter „So integrieren Sie Bright Data in LiveKit“.
Fazit
In diesem Blogbeitrag haben Sie erfahren, was Cartesia ist und welche Vorteile es für die Entwicklung von KI-Sprachagenten bietet. Sie haben auch gesehen, wo seine Grenzen liegen und wie Sie diese Einschränkungen mithilfe von Bright Data-Integrationen überwinden können.
Durch das Hinzufügen von zwei spezialisierten Tools zu Ihren Sprachagenten haben Sie ihnen die Möglichkeit gegeben, das Web zu durchsuchen und Daten von Webseiten zu extrahieren. Dies wurde durch die Anbindung Ihrer Agenten an benutzerdefinierte Tools ermöglicht, die auf der SERP-API und der Web Unlocker-API von Bright Data basieren.
Um die Funktionalität noch weiter zu erweitern – beispielsweise durch den Zugriff auf Live-Web-Feeds oder die Automatisierung von Web-Interaktionen – integrieren Sie Cartesia-Sprachagenten in die gesamte Palette der Bright Data-Dienste für KI.
Eröffnen Sie noch heute kostenlos ein Bright Data-Konto und beginnen Sie damit, KI-fähige Webdatenlösungen in Ihre Agenten zu integrieren!





