

Die manuelle Inhaltsrecherche in Dutzenden von Google-Suchergebnissen nimmt zu viel Zeit in Anspruch und lässt oft wichtige, über mehrere Quellen verstreute Erkenntnisse außer Acht. Herkömmliches Web Scraping liefert zwar HTML-Rohdaten, aber es fehlt die Intelligenz, um Informationen zu kohärenten Erzählungen zusammenzufassen. Dieser Leitfaden zeigt Ihnen, wie Sie ein KI-gestütztes System entwickeln, das automatisch Google-SERP-Ergebnisse durchsucht, Inhalte mithilfe von Einbettungen analysiert und umfassende Artikel oder Skizzen erstellt.
Sie werden lernen:
- Wie Sie mit Bright Data und Vektoreinbettungen eine automatisierte Pipeline von der Recherche zum Artikel erstellen
- Wie Sie gescrapte Inhalte semantisch analysieren und wiederkehrende Themen identifizieren
- Wie man strukturierte Gliederungen und vollständige Artikel mit LLMs generiert
- Wie man eine interaktive Streamlit-Schnittstelle für die Inhaltserstellung erstellt
Fangen wir an!
Die Herausforderungen der Recherche für die Erstellung von Inhalten
Bei der Recherche von Themen für Artikel, Blogposts oder Marketingmaterialien stehen Autoren von Inhalten vor erheblichen Hindernissen. Bei der manuellen Recherche müssen Dutzende von Browser-Tabs geöffnet, lange Artikel gelesen und versucht werden, Informationen aus unterschiedlichen Quellen zusammenzufassen. Dieser Prozess ist anfällig für menschliche Fehler, zeitintensiv und schwer zu skalieren.
Herkömmliche Web-Scraping-Ansätze mit BeautifulSoup oder Scrapy liefern zwar HTML-Rohtext, verfügen aber nicht über die Intelligenz, den inhaltlichen Kontext zu verstehen, Schlüsselthemen zu identifizieren oder Informationen aus mehreren Quellen zusammenzufassen. Das Ergebnis ist eine Sammlung unstrukturierter Texte, die noch immer eine umfangreiche manuelle Bearbeitung erfordert.
Durch die Kombination der robusten Scraping-Funktionen von Bright Data mit modernen KI-Techniken wie Vektoreinbettungen und großen Sprachmodellen wird die gesamte Pipeline von der Recherche bis zum Artikel automatisiert. So wird aus stundenlanger manueller Arbeit eine minutenlange, automatisierte Analyse.
Was wir bauen: KI-gestütztes Content-Recherche-System
Sie erstellen ein intelligentes System zur Generierung von Inhalten, das automatisch Google-Suchergebnisse für jedes beliebige Stichwort durchsucht. Das System extrahiert den gesamten Inhalt der Zielwebseiten, analysiert die Informationen mit Hilfe von Vektoreinbettungen, um Themen und Erkenntnisse zu identifizieren, und generiert entweder strukturierte Artikelskizzen oder komplette Artikelentwürfe über eine intuitive Streamlit-Oberfläche.
Voraussetzungen
Richten Sie Ihre Entwicklungsumgebung mit diesen Anforderungen ein:
- Python 3.9 oder höher
- Bright Data-Konto: Melden Sie sich an und erstellen Sie ein API-Token (kostenloses Testguthaben verfügbar)
- OpenAI-API-Schlüssel: Erstellen Sie einen Schlüssel in Ihrem OpenAI Dashboard für Einbettungen und LLM-Zugang
- Virtuelle Python-Umgebung: Hält Abhängigkeiten isoliert
- LangChain + Vektor-Embeddings (FAISS): Handhabt die Inhaltsanalyse und Speicherung.
- Streamlit: Stellt die interaktive Benutzeroberfläche bereit, über die die Benutzer das Tool nutzen können.
Einrichtung der Umgebung
Erstellen Sie Ihr Projektverzeichnis und installieren Sie die Abhängigkeiten. Beginnen Sie damit, eine saubere virtuelle Umgebung einzurichten, um Konflikte mit anderen Python-Projekten zu vermeiden.
python -m venv venv
# macOS/Linux: Quelle venv/bin/activate
# Windows: venvScriptsactivate
pip install langchain langchain-community langchain-openai streamlit "crewai-tools[mcp]" crewai mcp python-dotenvErstellen Sie eine neue Datei namens article_generator.py und fügen Sie die folgenden Importe hinzu. Diese Bibliotheken behandeln Web Scraping, Textverarbeitung, Einbettungen und die Benutzeroberfläche.
importiere streamlit als st
importieren os
json importieren
from dotenv importieren load_dotenv
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_openai importiere OpenAIEmbeddings, OpenAI
from langchain_community.vectorstores import FAISS
from mcp importiere StdioServerParameter
from crewai_tools importiere MCPServerAdapter
load_dotenv()Helle Datenkonfiguration
Speichern Sie Ihre API-Anmeldeinformationen sicher mithilfe von Umgebungsvariablen. Erstellen Sie eine .env-Datei, um Ihre Anmeldeinformationen zu speichern und sensible Informationen von Ihrem Code getrennt zu halten.
BRIGHT_DATA_API_TOKEN="ihr_bright_data_api_token_hier"
BRIGHT_DATA_ZONE="ihr_serp_zone_name"
OPENAI_API_KEY="ihr_openai_api_schlüssel_hier"Sie benötigen:
- Bright Data API-Token: Generieren Sie es aus Ihrem Bright Data Dashboard
- SERP-Scraping-Zone: Erstellen Sie eine neue Web Scraper-Zone, die für Google SERP konfiguriert ist
- OpenAI-API-Schlüssel: Für Einbettungen und LLM-Textgenerierung
Konfigurieren Sie die API-Verbindungen in article_generator.py. Diese Klasse übernimmt die gesamte Kommunikation mit der Scraping-Infrastruktur von Bright Data.
class BrightDataScraper:
def __init__(self):
self.server_params = StdioServerParameters(
command="npx",
args=["@brightdata/mcp"],
env={
"API_TOKEN": os.getenv("BRIGHT_DATA_API_TOKEN"),
"WEB_UNLOCKER_ZONE": "mcp_unlocker",
"BROWSER_ZONE": "scraping_browser1",
},
)
def scrape_serp(self, keyword, num_results=10):
with MCPServerAdapter(self.server_params) as mcp_tools:
try:
if not mcp_tools:
st.warning("Keine MCP-Tools verfügbar")
return {'results': []}
for tool in mcp_tools:
try:
tool_name = getattr(tool, 'name', str(tool))
wenn 'search_engine' in tool_name und 'batch' nicht in tool_name:
try:
if hasattr(tool, '_run'):
Ergebnis = tool._run(query=keyword)
elif hasattr(tool, 'run'):
Ergebnis = tool.run(Abfrage=Schlüsselwort)
elif hasattr(tool, '__call__'):
Ergebnis = tool(Abfrage=Schlüsselwort)
sonst:
Ergebnis = tool.search_engine(Abfrage=Schlüsselwort)
if Ergebnis:
return self._parse_serp_results(result)
except Exception as method_error:
st.warning(f "Methode fehlgeschlagen für {tool_name}: {str(method_error)}")
weiter
except Exception as tool_error:
st.warning(f "Werkzeug {tool_name} fehlgeschlagen: {str(tool_error)}")
continue
st.warning(f "Kein Suchmaschinentool konnte verarbeiten: {keyword}")
return {'results': []}
except Exception as e:
st.error(f "MCP scraping failed: {str(e)}")
return {'results': []}
def _parse_serp_results(self, mcp_result):
"""Ergebnisse des MCP-Tools in das erwartete Format parsen."""
if isinstance(mcp_result, dict) und 'results' in mcp_result:
return mcp_result
elif isinstance(mcp_result, list):
return {'results': mcp_result}
elif isinstance(mcp_result, str):
return self._parse_html_search_results(mcp_result)
sonst:
try:
parsed = json.loads(str(mcp_result))
return parsed if isinstance(parsed, dict) else {'results': parsed}
except:
return {'results': []}
def _parse_html_search_results(self, html_content):
"""HTML-Suchergebnisseite parsen, um Suchergebnisse zu extrahieren."""
importieren re
results = []
link_pattern = r'<a[^>]*href="([^"]*)"[^>]*>(.*?)</a>'
title_pattern = r'<h3[^>]*>(.*?)</h3>'
links = re.findall(link_pattern, html_content, re.DOTALL)
for link_url, link_text in links:
if (link_url.startswith('http') and
not any(skip in link_url for skip in [
'google.com', 'accounts.google', 'support.google',
'/search?', 'javascript:', '#', 'mailto:'
])):
clean_title = re.sub(r'<[^>]+>', '', link_text).strip()
if clean_title und len(clean_title) > 10:
results.append({
'url': link_url,
title': clean_title[:200],
'snippet': '',
'position': len(results) + 1
})
wenn len(results) >= 10:
break
if not results:
specific_pattern = r'[(.*?)]((https?://[^)]+))'
matches = re.findall(specific_pattern, html_content)
for title, url in matches:
if not any(skip in url for skip in ['google.com', '/search?']):
results.append({
'url': url,
'title': title.strip(),
'snippet': '',
'position': len(results) + 1
})
wenn len(results) >= 10:
break
return {'Ergebnisse': Ergebnisse}Aufbau des Artikelgenerators
Schritt 1: SERP & Zielseiten scrapen
Die Grundlage unseres Systems ist eine umfassende Datenerfassung. Sie müssen einen Scraper erstellen, der zunächst die Google SERP-Ergebnisse extrahiert und dann diesen Links folgt, um den gesamten Seiteninhalt aus den relevantesten Quellen zu sammeln.
class ContentScraper:
def __init__(self):
self.bright_data = BrightDataScraper()
self.server_params = StdioServerParameters(
command="npx",
args=["@brightdata/mcp"],
env={
"API_TOKEN": os.getenv("BRIGHT_DATA_API_TOKEN"),
"WEB_UNLOCKER_ZONE": "mcp_unlocker",
"BROWSER_ZONE": "scraping_browser1",
},
)
def extract_serp_urls(self, keyword, max_results=10):
"""Extrahiere URLs aus Google SERP-Ergebnissen.""
serp_data = self.bright_data.scrape_serp(keyword, max_results)
urls = []
results_list = serp_data.get('results', [])
for result in results_list:
if 'url' in result und self.is_valid_url(result['url']):
urls.append({
'url': result['url'],
title': result.get('title', ''),
'snippet': result.get('snippet', ''),
'position': result.get('position', 0)
})
elif 'link' in result und self.is_valid_url(result['link']):
urls.append({
'url': result['link'],
title': result.get('title', ''),
'snippet': result.get('snippet', ''),
'position': result.get('position', 0)
})
urls zurückgeben
def is_valid_url(self, url):
"""Nicht-Artikel-URLs wie Bilder, PDFs oder soziale Medien herausfiltern."""
excluded_domains = ['youtube.com', 'facebook.com', 'twitter.com', 'instagram.com']
excluded_extensions = ['.pdf', '.jpg', '.png', '.gif', '.mp4']
return (not any(domain in url for domain in excluded_domains) und
not any(ext in url.lower() for ext in excluded_extensions))
def scrape_page_content(self, url, max_length=10000):
"""Extrahiere sauberen Textinhalt aus einer Webseite mit den Bright Data MCP-Tools."""
try:
with MCPServerAdapter(self.server_params) as mcp_tools:
if not mcp_tools:
st.warning("Keine MCP-Tools für Content Scraping verfügbar")
return ""
for tool in mcp_tools:
try:
tool_name = getattr(tool, 'name', str(tool))
if 'scrape_as_markdown' in tool_name:
try:
if hasattr(tool, '_run'):
Ergebnis = tool._run(url=url)
elif hasattr(tool, 'run'):
Ergebnis = tool.run(url=url)
elif hasattr(tool, '__call__'):
Ergebnis = tool(url=url)
sonst:
result = tool.scrape_as_markdown(url=url)
if result:
content = self._extract_content_from_result(result)
wenn Inhalt:
return self._clean_content(content, max_length)
except Exception as method_error:
st.warning(f "Methode fehlgeschlagen für {tool_name}: {str(method_error)}")
weiter
except Exception as tool_error:
st.warning(f "Tool {tool_name} failed for {url}: {str(tool_error)}")
continue
st.warning(f "Kein scrape_as_markdown Werkzeug konnte scrapen: {url}")
return ""
except Exception as e:
st.warning(f "Failed to scrape {url}: {str(e)}")
return ""
def _extract_content_from_result(self, result):
"""Extrahiere Inhalt aus dem Ergebnis des MCP-Tools."""
if isinstance(result, str):
return result
elif isinstance(result, dict):
for key in ['content', 'text', 'body', 'html']:
if key in result und result[key]:
return result[key]
elif isinstance(result, list) und len(result) > 0:
return str(result[0])
return str(ergebnis) if ergebnis else ""
def _clean_content(self, content, max_length):
"""Bereinige und formatiere den gescrapten Inhalt."""
if isinstance(content, dict):
content = content.get('text', content.get('content', str(content)))
wenn '<' in Inhalt und '>' in Inhalt:
import re
content = re.sub(r'<script[^>]*>.*?</script>', '', content, flags=re.DOTALL | re.IGNORECASE)
Inhalt = re.sub(r'<style[^>]*>.*?</style>', '', Inhalt, flags=re.DOTALL | re.IGNORECASE)
Inhalt = re.sub(r'<[^>]+>', '', Inhalt)
lines = (line.strip() for line in content.splitlines())
chunks = (phrase.strip() for line in lines for phrase in line.split(" ")))
text = ' '.join(chunk for chunk in chunks if chunk)
return text[:max_length]Dieser Scraper filtert auf intelligente Weise URLs, um sich auf den Inhalt von Artikeln zu konzentrieren, und vermeidet Multimedia-Dateien und Social-Media-Links, die keine wertvollen Textinhalte für die Analyse liefern.
Schritt 2: Vektoreinbettungen und Inhaltsanalyse
Wandeln Sie gescrapte Inhalte in durchsuchbare Vektoreinbettungen um, die die semantische Bedeutung erfassen und eine intelligente Inhaltsanalyse ermöglichen. Der Einbettungsprozess wandelt Text in numerische Repräsentationen um, die Maschinen verstehen und vergleichen können.
class ContentAnalyzer:
def __init__(self):
self.embeddings = OpenAIEmbeddings(openai_api_key=os.getenv("OPENAI_API_KEY"))
self.text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200,
separators=["nn", "n", ".", "!", "?", ",", " ", ""]
)
def process_content(self, scraped_data):
"""Den gescrapten Inhalt in Einbettungen umwandeln und die Themen analysieren."""
all_texts = []
metadata = []
for item in scraped_data:
if item['content']:
chunks = self.text_splitter.split_text(item['content'])
for chunk in chunks:
all_texts.append(chunk)
metadata.append({
'url': item['url'],
title': item['title'],
'position': item['position']
})
if not all_texts:
raise ValueError("Kein Inhalt für die Analyse verfügbar")
vectorstore = FAISS.from_texts(all_texts, self.embeddings, metadatas=metadata)
return vectorstore, alle_texte, Metadaten
def identify_themes(self, vectorstore, query_terms, k=5):
"""Benutze die semantische Suche, um Schlüsselthemen und -begriffe zu identifizieren.""
theme_analysis = {}
for term in query_terms:
similar_docs = vectorstore.similarity_search(term, k=k)
theme_analysis[term] = {
'relevant_chunks': len(similar_docs),
key_passages': [doc.page_content[:200] + "..." for doc in similar_docs[:3]],
'sources': list(set([doc.metadata['url'] for doc in similar_docs]))
}
return theme_analysis
def generate_content_summary(self, all_texts, metadata):
"""Statistische Zusammenfassung des gescrapten Inhalts generieren.""
total_words = sum(len(text.split()) for text in all_texts)
total_chunks = len(alle_texte)
avg_chunk_length = total_words / total_chunks if total_chunks > 0 else 0
return {
'total_sources': len(set(meta['url'] for meta in metadata)),
'total_chunks': total_chunks,
total_words': total_words,
avg_chunk_length': round(avg_chunk_length, 1)
}Der Analysator zerlegt Inhalte in semantische Chunks und erstellt eine durchsuchbare Vektordatenbank, die eine intelligente Themenidentifizierung und Inhaltssynthese ermöglicht.
Schritt 3: Artikel oder Gliederung mit LLM generieren
Wandeln Sie analysierte Inhalte in strukturierte Ausgaben um, indem Sie sorgfältig ausgearbeitete Eingabeaufforderungen verwenden, die die semantischen Erkenntnisse aus Ihrer Einbettungsanalyse nutzen. Der LLM nimmt Ihre Forschungsdaten und erstellt kohärente, gut strukturierte Inhalte.
class ArticleGenerator:
def __init__(self):
self.llm = OpenAI(
openai_api_key=os.getenv("OPENAI_API_KEY"),
temperature=0.7,
max_tokens=2000
)
def generate_outline(self, keyword, theme_analysis, content_summary):
"""Erzeugt eine strukturierte Artikelübersicht auf der Grundlage von Forschungsdaten."""
themes_text = self._format_themes_for_prompt(theme_analysis)
outline_prompt = f"""
Erstellen Sie auf der Grundlage umfassender Recherchen zu "{Schlüsselwort}" eine detaillierte Gliederung des Artikels.
Zusammenfassung der Recherche:
- Analysierte {content_summary['total_sources']} Quellen
- Verarbeitete {content_summary['total_words']} Wörter des Inhalts
- Identifizierung der wichtigsten Themen und Erkenntnisse
Gefundene Schlüsselthemen:
{themes_text}
Erstellen Sie eine strukturierte Gliederung mit:
1. Fesselnde Überschrift
2. Einleitungsaufhänger und Überblick
3. 4-6 Hauptabschnitte mit Unterabschnitten
4. Schlussfolgerung mit den wichtigsten Erkenntnissen
5. Vorgeschlagene Aufforderung zum Handeln
Formatierung als Markdown mit klarer Hierarchie.
"""
return self.llm(outline_prompt)
def generate_full_article(self, keyword, theme_analysis, content_summary, target_length=1500):
"""Erzeuge einen vollständigen Artikelentwurf."""
themes_text = self._format_themes_for_prompt(theme_analysis)
article_prompt = f"""
Schreiben Sie einen umfassenden Artikel mit {Ziellänge} Wörtern über "{Schlüsselwort}" auf der Grundlage umfangreicher Recherchen.
Recherchiere Stiftung:
{themes_text}
Inhaltliche Anforderungen:
- Fesselnde Einleitung, die den Leser fesselt
- Gut strukturierter Hauptteil mit klaren Abschnitten
- Einschließlich spezifischer Erkenntnisse und Daten aus der Forschung
- Professioneller, informativer Ton
- Starke Schlussfolgerung mit umsetzbaren Ergebnissen
- SEO-freundliche Struktur mit Zwischenüberschriften
Schreiben Sie den kompletten Artikel im Markdown-Format.
"""
return self.llm(artikel_prompt)
def _format_themes_for_prompt(self, theme_analysis):
"""Themenanalyse für LLM-Verbrauch formatieren."""
formatted_themes = []
for theme, data in theme_analysis.items():
theme_info = f "**{theme}**: Gefunden in {data['relevant_chunks']} Inhaltsabschnittenn"
theme_info += f "Wichtige Erkenntnisse: {data['key_passages'][0][:150]}...n"
theme_info += f "Quellen: {len(data['sources'])} unique referencesn"
formatted_themes.append(theme_info)
return "n".join(formatted_themes)Der Generator erzeugt zwei verschiedene Ausgabeformate: strukturierte Gliederungen für die Inhaltsplanung und vollständige Artikel für die sofortige Veröffentlichung. Beide Ausgaben beruhen auf der semantischen Analyse der gescrapten Inhalte.
Schritt 4: Streamlit UI erstellen
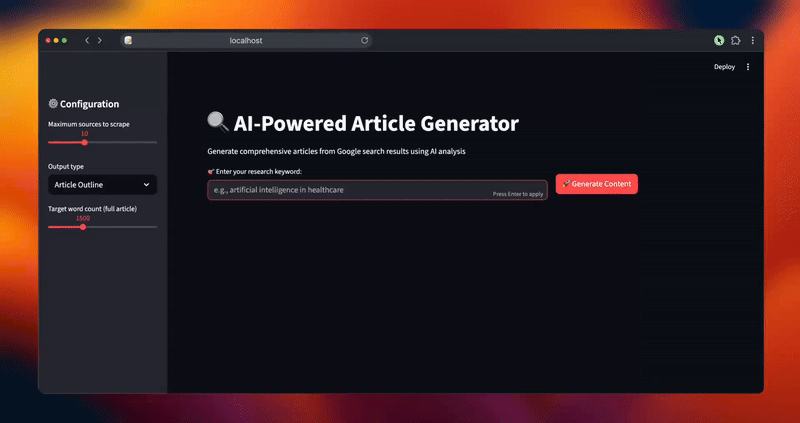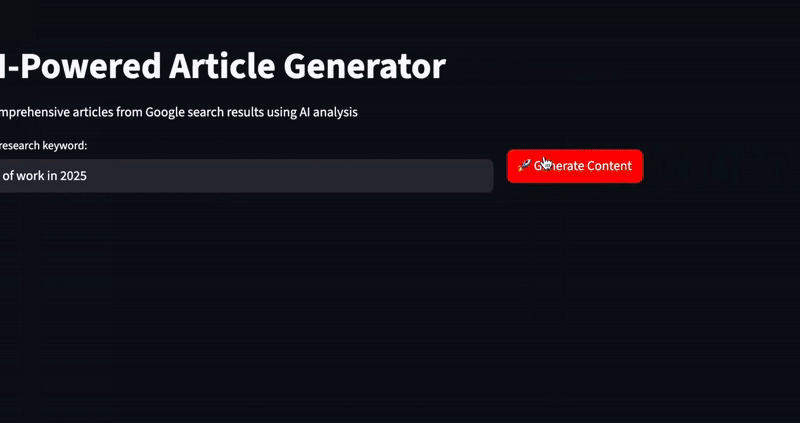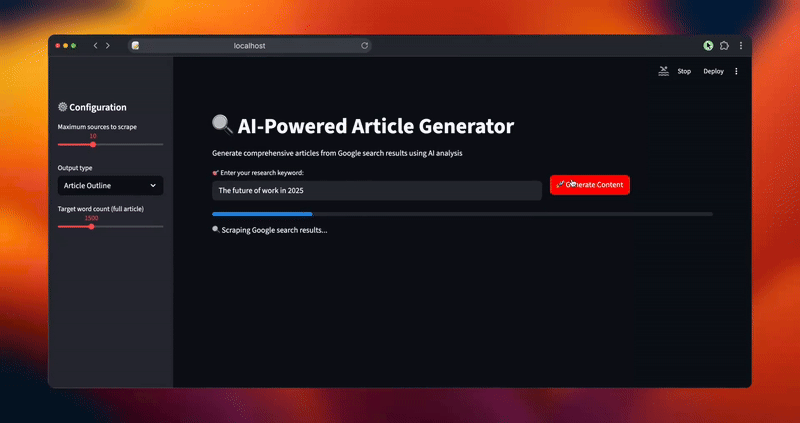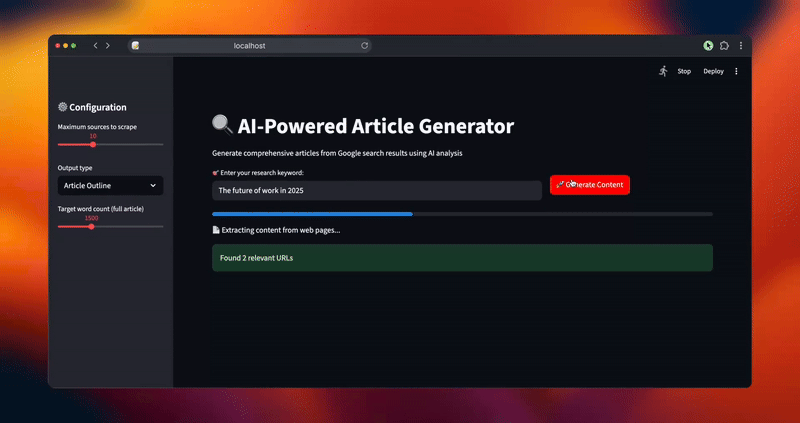
Erstellen Sie eine intuitive Benutzeroberfläche, die den Benutzer durch den Workflow der Inhaltserstellung mit Echtzeit-Feedback und Anpassungsoptionen führt. Die Schnittstelle macht komplexe KI-Operationen auch für nicht-technische Benutzer zugänglich.
def main():
st.set_page_config(page_title="AI Article Generator", page_icon="📝", layout="wide")
st.title("🔍 KI-gestützter Artikelgenerator")
st.markdown("Mit Hilfe von KI-Analysen umfassende Artikel aus Google-Suchergebnissen generieren")
scraper = ContentScraper()
analyzer = Inhalts-Analysator()
generator = ArtikelGenerator()
st.sidebar.header("⚙️ Konfiguration")
max_sources = st.sidebar.slider("Maximal zu scrappende Quellen", 5, 20, 10)
output_type = st.sidebar.selectbox("Ausgabeart", ["Artikelübersicht", "Vollständiger Artikel"])
target_length = st.sidebar.slider("Zielwortzahl (vollständiger Artikel)", 800, 3000, 1500)
col1, col2 = st.columns([2, 1])
mit sp1:
keyword = st.text_input("🎯 Geben Sie Ihr Forschungsstichwort ein:", placeholder="z.B., Künstliche Intelligenz im Gesundheitswesen")
with col2:
st.write("")
generate_button = st.button("🚀 Inhalt generieren", type="primary")
if generate_button und keyword:
try:
progress_bar = st.progress(0)
status_text = st.empty()
status_text.text("🔍 Scraping Google Suchergebnisse...")
progress_bar.progress(0.2)
urls = scraper.extract_serp_urls(keyword, max_sources)
st.success(f"{len(urls)} relevante URLs gefunden")
status_text.text("📄 Extrahieren von Inhalten aus Webseiten...")
progress_bar.progress(0.4)
scraped_data = []
for i, url_data in enumerate(urls):
content = scraper.scrape_page_content(url_data['url'])
scraped_data.append({
'url': url_data['url'],
Titel': url_data['Titel'],
'Inhalt': Inhalt,
'position': url_data['position']
})
progress_bar.progress(0.4 + (0.3 * (i + 1) / len(urls)))
status_text.text("🧠 Analyse von Inhalten mit KI-Einbettungen...")
progress_bar.progress(0.75)
vectorstore, all_texts, metadata = analyzer.process_content(scraped_data)
query_terms = [keyword] + stichwort.split()[:3]
theme_analysis = analyzer.identify_themes(vectorstore, query_terms)
content_summary = analyzer.generate_content_summary(all_texts, metadata)
status_text.text("✍️ Generierung von KI-gestützten Inhalten...")
progress_bar.progress(0.9)
wenn output_type == "Artikel Gliederung":
result = generator.generate_outline(keyword, theme_analysis, content_summary)
sonst:
result = generator.generate_full_article(keyword, theme_analysis, content_summary, target_length)
fortschrittsbalken.fortschritt(1.0)
status_text.text("✅ Inhaltserstellung abgeschlossen!")
st.markdown("---")
st.subheader(f"📊 Forschungsanalyse für '{Schlüsselwort}'")
col1, col2, col3, col4 = st.columns(4)
with col1:
st.metric("Analysierte Quellen", content_summary['total_sources'])
mit Spalte2:
st.metric("Content Chunks", content_summary['total_chunks'])
mit Spalte3:
st.metric("Total Words", content_summary['total_words'])
mit Spalte 4:
st.metric("Avg Chunk Size", f"{content_summary['avg_chunk_length']} words")
mit st.expander("🎯 Identifizierte Schlüsselthemen"):
for theme, data in theme_analysis.items():
st.write(f "**{Thema}**: {data['relevant_chunks']} relevante Abschnitte gefunden")
st.write(f "Beispielhafte Einsicht: {data['key_passages'][0][:200]}...")
st.write(f "Quellen: {len(data['sources'])} eindeutige Referenzen")
st.write("---")
st.markdown("---")
st.subheader(f"📝 Generated {output_type}")
st.markdown(result)
st.download_button(
label="💾 Inhalt herunterladen",
data=result,
file_name=f"{keyword.replace(' ', '_')}_{output_type.lower().replace(' ', '_')}.md",
mime="text/markdown"
)
except Exception as e:
st.error(f"❌ Generierung fehlgeschlagen: {str(e)}")
st.write("Bitte überprüfen Sie Ihre API-Anmeldedaten und versuchen Sie es erneut.")
if __name__ == "__main__":
main()Die Streamlit-Benutzeroberfläche bietet einen intuitiven Arbeitsablauf mit Fortschrittsverfolgung in Echtzeit, anpassbaren Parametern und einer sofortigen Vorschau sowohl der Forschungsanalyse als auch der generierten Inhalte. Benutzer können ihre Ergebnisse im Markdown-Format zur weiteren Bearbeitung oder Veröffentlichung herunterladen.
Ausführen Ihres Artikelgenerators
Führen Sie die Anwendung aus, um mit der Erstellung von Inhalten aus Web-Recherchen zu beginnen. Öffnen Sie Ihr Terminal und navigieren Sie zum Verzeichnis Ihres Projekts.
streamlit run article_generator.pySie werden den intelligenten Workflow des Systems sehen, während es Ihre Anfragen verarbeitet:
- Extrahiert umfassende Suchergebnisse aus der Google SERP mit Relevanzfilterung
- Extrahiert den gesamten Inhalt von Ziel-Webseiten mit Anti-Bot-Schutz
- Verarbeitet Inhalte semantisch mit Vektoreinbettungen und Themenidentifikation
- Analysiert wiederkehrende Muster und wichtige Erkenntnisse über mehrere Quellen hinweg
- Generiert strukturierte Inhalte mit korrektem Fluss und professioneller Formatierung
Abschließender Gedanke
Sie verfügen nun über ein komplettes System zur Artikelerstellung, das automatisch Recherchedaten aus verschiedenen Quellen sammelt und in umfassende Inhalte umwandelt. Das System führt eine semantische Inhaltsanalyse durch, identifiziert wiederkehrende Themen in verschiedenen Quellen und generiert strukturierte Artikel oder Gliederungen.
Sie können dieses Framework für verschiedene Branchen anpassen, indem Sie die Scraping-Ziele und Analysekriterien ändern. Der modulare Aufbau ermöglicht es Ihnen, neue Inhaltsplattformen, Einbettungsmodelle oder Generierungsvorlagen hinzuzufügen, wenn sich Ihre Anforderungen weiterentwickeln.
Für die Erstellung fortschrittlicherer Workflows können Sie die gesamte Palette der Lösungen in der Bright Data AI-Infrastruktur zum Abrufen, Validieren und Transformieren von Live-Webdaten erkunden.
Erstellen Sie ein kostenloses Bright Data-Konto und experimentieren Sie mit unseren KI-fähigen Webdatenlösungen!






