

In modernen Datenprojekten werden Felder und Datensätze systemübergreifend abgeglichen, damit die Informationen ihre Bedeutung behalten, wenn sie zwischen Datenbanken und Anwendungen übertragen werden. Was früher manuell und spröde war, profitiert heute von KI. In diesem Leitfaden erfahren Sie, wie KI das Datenmapping verändert, welche Schlüsseltechniken dahinter stehen und wie Sie öffentliche Webdaten in analysefähige Datensätze verwandeln können.
Was ist Data Mapping und warum ist es eine Herausforderung?
Datenmapping teilt Systemen einfach mit, wie Datenfelder einander entsprechen. So wird beispielsweise die E-Mail-Adresse eines Kunden in einer Datenbank der E-Mail-Adresse in einer anderen Datenbank zugeordnet. Ohne ordnungsgemäßes Mapping können Daten, die zwischen Systemen übertragen werden, ihren Kontext verlieren oder zu Duplikaten führen. Mapping ist für die Integration, Migration und Analyse von entscheidender Bedeutung: Es stellt sicher, dass bei der Übertragung von Daten in ein neues Tool oder Warehouse alle Werte an der richtigen Stelle landen.
Das herkömmliche Mapping ist jedoch langsam und fehleranfällig. In großen Unternehmen sind die Daten in Hunderten von verschiedenen Quellen und Formaten vorhanden. Teams müssen oft benutzerdefinierte Skripte schreiben oder komplexe ETL-Tools verwenden und jedes Feld manuell abgleichen. Diese Methode ist nicht skalierbar: Projekte können Monate dauern, und menschliche Fehler sind häufig.
Die Herausforderung wird noch größer, wenn mit Webdaten gearbeitet wird – unstrukturierte HTML-Seiten, inkonsistente Feldbezeichnungen und unübersichtliche Formatierungen sorgen für zusätzliche Komplexität. Quelldaten von schlechter Qualität führen zu schlechten Mapping-Ergebnissen, unabhängig davon, wie fortschrittlich Ihre KI-Tools sind.
Wie KI das Datenmapping verändert
KI-gestütztes Datenmapping nutzt maschinelles Lernen und die Verarbeitung natürlicher Sprache, um Quell- und Zielschemata zu analysieren, Feldnamen und Kontext zu interpretieren und aus früheren Mappings zu lernen, um genaue Übereinstimmungen vorzuschlagen, anstatt manuelle Feldcodierung zu erfordern.
KI erkennt, dass cust_ID, customerID und customer_id das gleiche Konzept darstellen. Plattformen erkennen Datentypen und schlagen dementsprechend Zielfelder vor, wodurch Mapping-Aufgaben von Stunden auf Minuten reduziert werden.
Hier sind die wichtigsten Vorteile des KI-Datenmappings:
- Geschwindigkeit und Effizienz. Die Automatisierung übernimmt sich wiederholende Mapping- und Transformationsvorgänge und reduziert den manuellen Aufwand.
- Genauigkeit und Lernfähigkeit. Die Systeme lernen aus Ihren Akzeptanz-/Ablehnungsentscheidungen und verbessern die Vorschläge mit der Zeit.
- Skalierbarkeit. KI-Mapping kann große, komplexe Datensätze verarbeiten. Da das Datenvolumen und die Datenvielfalt wachsen, können moderne Tools gleichzeitig mehrere Schemata und Quellen analysieren.
- Anpassungsfähigkeit. Im Gegensatz zu statischen Skripten passt sich AI-Mapping an Veränderungen an. Wenn neue Felder oder Formate auftauchen, leitet die KI die Beziehungen aus dem Kontext oder dem Feedback der Benutzer ab. Das System erlernt die Datenmuster Ihres Unternehmens, sodass im Laufe der Zeit weniger menschliche Korrekturen erforderlich sind.
- Bessere Datenqualität und -verwaltung. Automatisiertes Mapping hilft bei der Durchsetzung von Konsistenz und Governance. Durch die Dokumentation der Zuordnung von Feldern sorgen KI-Tools für die Wahrung der Datenreihenfolge und unterstützen die Einhaltung von Vorschriften, indem sie die Weiterleitung sensibler Daten verfolgen.
- Niedrigere Kosten. Diese Vorteile senken die Kosten durch weniger manuelle Arbeit, weniger Fehler, die Nacharbeit erfordern, und einen schnelleren Projektabschluss.
Technologien hinter AI Data Mapping
Mehrere KI-Techniken ermöglichen modernes Datenmapping:
- Verarbeitung natürlicher Sprache (NLP). NLP interpretiert die Bedeutung von Feldnamen und Beschriftungen (z. B. E-Mail-Adresse vs. E-Mail) und kann die Dokumentation verarbeiten, um den Kontext zu extrahieren, was das Mapping robuster macht, selbst wenn die Namen stark voneinander abweichen.
- Modelle für maschinelles Lernen. ML-Modelle klassifizieren und prognostizieren Mappings auf der Grundlage erlernter Muster. Jede frühere Zuordnung fließt in das Modell ein: Wenn viele Datensätze zeigen, dass account_manager in einem Abrechnungssystem auf sales_rep abgebildet wird, wird das Modell diesem Vorschlag beim nächsten Mal Vorrang einräumen – und so die Empfehlungen im Laufe der Zeit verbessern, ohne dass ein Mensch daran beteiligt ist.
- Wissensgraphen. Einige Plattformen unterhalten interne Wissensgraphen, die Entitäten und Beziehungen zwischen verschiedenen Systemen verknüpfen. Ein Graph kann darstellen, dass eine Kunden-ID in einem System dasselbe ist wie eine Kontonummer in einem anderen und dass sich beide auf eine Rechnungsreferenz beziehen, was dabei hilft, indirekte Zuordnungen abzuleiten und Schemata konsistent zu halten.
- Deep Learning und Computer Vision. Für unstrukturierte oder halbstrukturierte Dokumente (z. B. PDFs, gescannte Formulare) kann Deep Learning Text, Tabellen und Schlüssel-Wert-Paare extrahieren, damit Sie sie strukturierten Zielen zuordnen können.
- Semantischer Abgleich und Schemaabgleich. Moderne Tools integrieren Algorithmen für den Schemaabgleich (einschließlich Graphen-/Ontologieabgleich), die lexikalische, strukturelle und instanzbasierte Daten sowie ggf. Domänenwörterbücher kombinieren, um Entsprechungen zu finden.
Wie KI-Datenmapping funktioniert (Schritt für Schritt)
KI-Datenmapping-Tools folgen diesem Arbeitsablauf:
- Datenquellen verbinden. Das Tool stellt eine Verbindung zu Ihren Quell- und Zielsystemen (Datenbanken, Dateien, APIs) her, prüft Feldnamen, Datentypen, Beispielwerte und Metadaten und verwendet NLP, um Bezeichnungen/Beschreibungen zu lesen, damit es den Kontext versteht, bevor es Übereinstimmungen vorschlägt.
- Analysieren Sie und schlagen Sie Übereinstimmungen vor. Es wendet die automatische Zuordnung nach Name/Position und semantischer Ähnlichkeit an, um Kandidatenpaare zu generieren, oft mit Vertrauenswerten. Zum Beispiel kann country_code mit CountryID verknüpft werden. Wird eine Typinkongruenz festgestellt (Text wie “Qty: 12” gegenüber einem numerischen Ziel), wird vor dem endgültigen Mapping eine Parse/Cast-Transformation vorgeschlagen.
- Überprüfen und verfeinern. Übereinstimmungen mit hoher Konfidenz können automatisch akzeptiert werden, während mehrdeutige Übereinstimmungen zur Überprüfung durch den Steward gekennzeichnet werden. Angenommene und abgelehnte Aktionen werden für die Prüfung erfasst und zur Verbesserung künftiger Vorschläge verwendet.
- KI lernt aus Feedback. Das System verinnerlicht Ihre Entscheidungen (Ihr institutionelles Gedächtnis), sodass ähnliche Datensätze beim nächsten Mal schneller zugeordnet werden können und die Empfehlungen mit Ihren Namenskonventionen und Richtlinien übereinstimmen.
- Bereitstellung von Transformationen. Sobald die Mappings genehmigt sind, generiert und operationalisiert die Plattform die erforderlichen Transformationen (Casts, Verkettungen, Standardisierungen) und führt sie in verwalteten ETL/ELT-Pipelines mit Zeitplanung, Überwachung und Lineage-Erfassung aus.
Mapping-fähige Daten aus dem Web erhalten
Bevor KI Ihre Daten effektiv zuordnen kann, benötigen Sie saubere, strukturierte Eingaben. Webdaten sind oft unordentlich – inkonsistente Formatierung, verschachteltes HTML, wechselnde Seitenstrukturen. Daher ist die richtige Erfassung von Webdaten für erfolgreiche Mapping-Projekte entscheidend.
Bright Data bietet eine Plattform zum Extrahieren und Aufbereiten von Webdaten für KI, sodass das Mapping mit sauberen Eingaben beginnt:
- AI Web Scraper. Identifizieren Sie die Seitenstruktur und extrahieren Sie strukturierte Daten von modernen Websites; liefern Sie JSON/CSV über API oder Webhooks.
- Datensätze (vordefiniert). Vorgefertigte, aktualisierte Datensätze mit dokumentierten Schemata (z. B. Amazon-Produkte), damit Feldnamen und -typen von Anfang an konsistent sind.
- Proxy und Web Unlocker. Zuverlässiger Zugriff auf öffentliche Websites durch die Handhabung von Sperren und CAPTCHAs – so können Sie die Daten vor dem Mapping sammeln, selbst auf schwierigen Websites.
- Browser-API und serverlose Funktionen. Führen Sie programmierbare, gehostete Scraping-Workflows für die mehrstufige Erfassung vor dem Mapping aus.
- Integrationen. Verbinden Sie gescrapte oder Datensatzausgaben mit KI-App-Frameworks (z. B. LangChain, LlamaIndex) oder Ihren Speicherzielen.
Da Bright Data die Sammlung und anfängliche Strukturierung übernimmt, können Sie sich auf das Mapping und die Transformation konzentrieren.
Einfaches Beispiel – Mapping eines Amazon-Produktdatensatzes
Lassen Sie uns ein praktisches Beispiel mit Amazon-Produktdaten durchgehen. Anstatt unübersichtliche Produktseiten manuell zu scrapen, verwenden wir den Amazon-Produktdatensatz von Bright Data, der saubere, strukturierte Datensätze liefert, die sich perfekt für das AI-Mapping eignen.
Das Dataset enthält Felder wie Titel, Marke, initial_price, Währung und Verfügbarkeit. Ein Beispieldatensatz sieht so aus:
{
"Titel": "Hanes Girls' Cami Tops, 100% Baumwolle Camisoles...",
"Marke": "Hanes Unterwäsche für Mädchen 7-16",
"initial_price": 10.00,
"Währung": "USD",
"Verfügbarkeit": true
}Angenommen, unser Ziel-Analyseschema benötigt ProductName, Brand, PriceUSD und InStock. Das AI-Mapping-Tool würde diese Transformationen vorschlagen:
- Titel → Produktname (hohe semantische Übereinstimmung)
- Marke → Marke (exakte Namensübereinstimmung)
- initial_price + currency → PriceUSD (Felder kombinieren, auf USD normalisieren)
- Verfügbarkeit → InStock (boolesche Umwandlung)
Nach Mapping und Transformation:
{
"Produktname": "Hanes Girls' Cami Tops, ...",
"Brand": "Hanes Mädchen 7-16 Unterwäsche",
"PriceUSD": 10.00,
"InStock": true
}Das AI-Mapping-Tool hat die meisten Zuordnungen automatisch vorgeschlagen, da die Quelldaten sauber und einheitlich formatiert waren.
Für benutzerdefinierte Anforderungen können Sie den AI Web Scraper verwenden, um bestimmte Amazon-Felder in Ihr bevorzugtes Format zu extrahieren und diese dann Ihrem Zielschema zuzuordnen.
Hinweis: Halten Sie den Menschen auf dem Laufenden. KI-Mapping funktioniert am besten als intelligenter Assistent, nicht als Ersatz für Datenexpertise. Überprüfen Sie kritische Mappings immer, insbesondere bei sensiblen Feldern oder der Einhaltung von Vorschriften.
Fortgeschrittenes Mapping mit Abfragen in natürlicher Sprache
Manchmal müssen Sie Daten recherchieren und zuordnen, die nicht in vorgefertigten Formaten vorliegen. Mit Deep Lookup von Bright Data können Sie benutzerdefinierte Datensätze mithilfe von Abfragen in natürlicher Sprache generieren und die Ergebnisse dann Ihrem Zielschema zuordnen. Ein Beispiel:
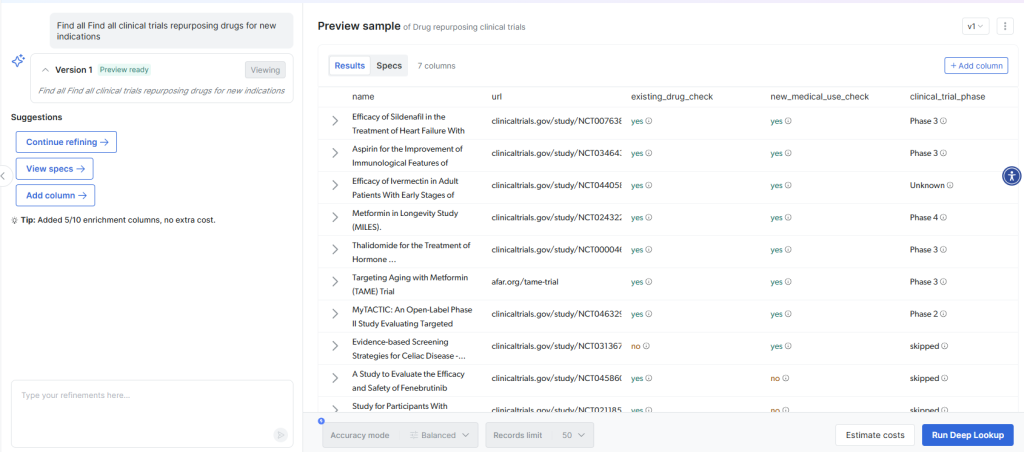
Deep Lookup durchsucht Webdaten, um passende Unternehmen zu finden, und liefert strukturierte Ergebnisse, die dann zugeordnet werden können:

Damit entfällt der herkömmliche Arbeitsablauf “Recherchieren – Strukturieren – Zuordnen”, da direkt aus natürlichsprachlichen Abfragen mappingfähige Daten geliefert werden.
Fazit
KI-Datenmapping verändert die Art und Weise, wie Unternehmen öffentliche Webdaten in Analyse- und KI-Workflows integrieren. Der Erfolg beginnt bereits vor dem Mapping: Hochwertige, gut strukturierte Quelldaten verbessern die Mapping-Genauigkeit und reduzieren manuelle Eingriffe.
Die Lösungen von Bright Data übernehmen die Erfassung und Strukturierung, sodass Sie sich auf die Zuordnung von Webdaten zu Ihren spezifischen Geschäftsanforderungen und analytischen Frameworks konzentrieren können.
Sind Sie bereit, die Auswirkungen von sauberen Webdaten auf Ihre Mapping-Projekte zu erkennen? Setzen Sie sich mit uns in Verbindung, um schnell strukturierte, Mapping-fähige Datensätze zu erhalten.





