

Wenn Sie schon länger Web-Scraping betreiben, sind Sie vielleicht schon einmal auf eine gesperrte Website hinter einem Geofence oder einer IP-Sperre gestoßen. Proxy-Server helfen Ihnen, solche Situationen zu umgehen, indem sie Ihre wahre Identität verschleiern und Ihnen Zugang zu gesperrten Ressourcen gewähren.
Mit Rust -Proxy-Servern können Sie ganz einfach Folgendes tun:
- IP-Sperren vermeiden: Mit einer neuen Proxy-IP können Sie die Sperre umgehen und das Scraping fortsetzen.
- Geoblocking umgehen: Wenn Sie an Inhalten aus einem anderen Land interessiert sind, gewährt Ihnen ein lokaler Proxy vorübergehend Online-Staatsbürgerschaft, sodass Sie auf eingeschränkte Inhalte zugreifen können.
- Anonymität genießen: Ein Proxy-Server verbirgt Ihre echte IP-Adresse und schützt Ihre Privatsphäre vor neugierigen Blicken.
Und das ist nur die Spitze des Eisbergs! Die leistungsstarken Bibliotheken und die robuste Syntax von Rust machen die Einrichtung und Verwaltung von Proxys zum Kinderspiel. In diesem Artikel erfahren Sie alles über Proxy-Server und wie Sie einen Proxy-Server in Rust für das Web-Scraping verwenden können.
Verwendung eines Proxy-Servers in Rust
Bevor Sie einen Proxy-Server in Rust verwenden können, müssen Sie einen einrichten. In diesem Tutorial richten Sie einen Proxy in einem Nginx-Server auf Ihrem lokalen Rechner ein und verwenden ihn, um Scraping-Anfragen von einer Rust-Binärdatei an eine Scraping-Sandbox (z. B. https://toscrape.com/) zu senden.
Beginnen Sie mit der Installation von Nginx auf Ihrem lokalen System. Unter Linux können Sie es mit Homebrew mit dem folgenden Befehl installieren:
sudo apt install nginxStarten Sie dann den Server mit dem folgenden Befehl:
nginx
Als Nächstes müssen Sie den Server so konfigurieren, dass er als Proxy für bestimmte Standorte fungiert. Sie könnten ihn beispielsweise so konfigurieren, dass er als Proxy für den Standort / fungiert und jeder Anfrage, die er bearbeitet, einen Header (z. B. X-Proxy-Server) hinzufügt. Dazu müssen Sie die Datei nginx.conf bearbeiten.
Der Speicherort der Datei hängt von Ihrem Host-Betriebssystem ab. Weitere Informationen finden Sie in der Nginx-Dokumentation. Unter Linux finden Sie nginx.conf unter /etc/nginx/nginx.conf. Öffnen Sie die Datei und fügen Sie den folgenden Code-Block zum http.server -Objekt in der Datei hinzu:
http {
server {
# Fügen Sie den folgenden Block hinzu
location / {
resolver 8.8.8.8;
proxy_pass http://$http_host$request_uri;
proxy_set_header 'X-Proxy-Server' 'Nginx';
}
}
}
Dadurch wird der Proxy so konfiguriert, dass er alle eingehenden Anfragen an die ursprüngliche URL weiterleitet und gleichzeitig einen Header zur Anfrage hinzufügt. Wenn Sie Zugriff auf die Protokolle auf dem Zielserver hätten, könnten Sie diesen Header überprüfen, um festzustellen, ob die Anfrage über den Proxy oder direkt vom Client kam.
Führen Sie nun den folgenden Befehl aus, um den Nginx-Server neu zu starten:
nginx -s reload
Dieser Server kann nun als Forward-Proxy für das Scraping verwendet werden.
Erstellen eines Web-Scraping-Projekts in Rust
Um ein neues Scraping-Projekt einzurichten, erstellen Sie mit Cargo eine neue Rust-Binärdatei, indem Sie den folgenden Befehl ausführen:
cargo new rust-scraper
Sobald das Projekt erstellt ist, müssen Sie drei Crates hinzufügen. Zunächst fügen Sie reqwest und Scraper hinzu. Sie verwenden reqwest, um Anfragen an die Zielressource zu senden, und Scraper, um die erforderlichen Daten aus dem von reqwest empfangenen HTML zu extrahieren. Dann fügen Sie Ihre dritte Crate, tokio, hinzu, um asynchrone Netzwerkaufrufe über reqwest zu verarbeiten.
Um diese zu installieren, führen Sie den folgenden Befehl im Projektverzeichnis aus:
cargo add Scraper reqwest tokio --features "reqwest/blocking tokio/full"
Öffnen Sie als Nächstes die Datei src/main.rs und fügen Sie den folgenden Code hinzu:
use reqwest;
use std::error::Error;
#[tokio::main]
async fn main() -> Result<(), Box<dyn Error>>{
let url = "http://books.toscrape.com/";
let client = reqwest::Client::new();
let response = client
.get(url)
.send()
.await?;
let html_content = response.text().await?;
extract_products(&html_content);
Ok(())
}
fn extract_products(html_content: &str) {
let document = Scraper::Html::parse_document(&html_content);
let html_product_selector = Scraper::Selector::parse("article.product_pod").unwrap();
let html_products = document.select(&html_product_selector);
let mut products: Vec<PRODUCT> = Vec::new();
for html_product in html_products {
let url = html_product
.select(&Scraper::Selector::parse("a").unwrap())
.next()
.and_then(|a| a.value().attr("href"))
.map(str::to_owned);
let image = html_product
.select(&Scraper::Selector::parse("img").unwrap())
.next()
.and_then(|img| img.value().attr("src"))
.map(str::to_owned);
let name = html_product
.select(&Scraper::Selector::parse("h3").unwrap())
.next()
.map(|title| title.text().collect::<STRING>());
let price = html_product
.select(&Scraper::Selector::parse(".price_color").unwrap())
.next()
.map(|price| price.text().collect::<STRING>());
let product = Product {
url,
image,
name,
price,
};
products.push(product);
}
println!("{:?}", products);
}
#[derive(Debug)]
struct Product {
url: Option<String>,
image: Option<String>,
name: Option<String>,
price: Option<String>,
}
Dieser Code verwendet die Crate „reqwest“, um einen Client zu erstellen und die Webseite unter der URL https://books.toscrape.com abzurufen. Anschließend verarbeitet er den HTML-Code der Seite in einer Funktion namens „extract_products“, um eine Liste der Produkte aus der Seite zu extrahieren. Die Extraktionslogik wird mithilfe der Crate „Scraper“ implementiert und bleibt unabhängig davon, ob Sie einen Proxy verwenden oder nicht, unverändert.
Nun ist es an der Zeit, diese Binärdatei auszuführen, um zu sehen, ob sie die Liste der Produkte korrekt extrahiert. Führen Sie dazu den folgenden Befehl aus:
cargo run
In Ihrem Terminal sollte eine Ausgabe erscheinen, die in etwa so aussieht:
Finished dev [unoptimized + debuginfo] target(s) in 0.80s
Running `target/debug/rust_scraper`
[Produkt { url: Some("catalogue/a-light-in-the-attic_1000/index.html"), image: Some("media/cache/2c/da/2cdad67c44b002e7ead0cc35693c0e8b.jpg"), name: Some("A Light in the ..."), price: Some("£51.77") }, Produkt { url: Some("catalogue/tipping-the-velvet_999/index.html"), image: Some("media/cache/26/0c/260c6ae16bce31c8f8c95daddd9f4a1c.jpg"), name: Some("Tipping the Velvet"), price: Some("£53.74") }, Product { url: Some("catalogue/soumission_998/index.html"), image: Some("media/cache/3e/ef/3eef99c9d9adef34639f510662022830.jpg"), name: Some("Soumission"), price: Some("£50.10") }, Product { url: Some("catalogue/sharp-objects_997/index.html"), image: Some("media/cache/32/51/3251cf3a3412f53f339e42cac2134093.jpg"), name: Some("Sharp Objects"), price: Some("£47.82") }, Produkt { url: Some("catalogue/sapiens-a-brief-history-of-humankind_996/index.html"), image: Some("media/cache/be/a5/bea5697f2534a2f86a3ef27b5a8c12a6.jpg"), name: Some("Sapiens: A Brief History ..."), price: Some("£54.23") }, Product { url: Some("catalogue/the-requiem-red_995/index.html"), image: Some("media/cache/68/33/68339b4c9bc034267e1da611ab3b34f8.jpg"), name: Some("The Requiem Red"), price: Some("£22.65") }, Product { url: Some("catalogue/the-dirty-little-secrets-of-getting-your-dream-job_994/index.html"), image: Some("media/cache/92/27/92274a95b7c251fea59a2b8a78275ab4.jpg"), name: Some("The Dirty Little Secrets ..."), price: Some("£33.34") }, Product { url: Some("catalogue/the-coming-woman-a-novel-based-on-the-life-of-the-infamous-feminist-victoria-woodhull_993/index.html"), image: Some("media/cache/3d/54/3d54940e57e662c4dd1f3ff00c78cc64.jpg"), name: Some("The Coming Woman: A ..."), price: Some("£17.93") }, Product { url: Some("catalogue/the-boys-in-the-boat-nine-americans-and-their-epic-quest-for-gold-at-the-1936-berlin-olympics_992/index.html"), image: Some("media/cache/66/88/66883b91f6804b2323c8369331cb7dd1.jpg"), name: Some("The Boys in the ..."), price: Some("£22.60") }, Product { url: Some("catalogue/the-black-maria_991/index.html"), image: Some("media/cache/58/46/5846057e28022268153beff6d352b06c.jpg"), name: Some("The Black Maria"), price: Some("£52.15") }, Product { url: Some("catalogue/starving-hearts-triangular-trade-trilogy-1_990/index.html"), image: Some("media/cache/be/f4/bef44da28c98f905a3ebec0b87be8530.jpg"), name: Some("Starving Hearts (Triangular Trade ..."), price: Some("13,99 £") }, Produkt { url: Some("catalogue/shakespeares-sonnets_989/index.html"), image: Some("media/cache/10/48/1048f63d3b5061cd2f424d20b3f9b666.jpg"), name: Some("Shakespeare's Sonnets"), price: Some("£20.66") }, Product { url: Some("catalogue/set-me-free_988/index.html"), image: Some("media/cache/5b/88/5b88c52633f53cacf162c15f4f823153.jpg"), name: Some("Set Me Free"), price: Some("£17.46") }, Produkt { url: Some("catalogue/scott-pilgrims-precious-little-life-scott-pilgrim-1_987/index.html"), image: Some("media/cache/94/b1/94b1b8b244bce9677c2f29ccc890d4d2.jpg"), name: Some("Scott Pilgrim's Precious Little ..."), price: Some("£52.29") }, Product { url: Some("catalogue/rip-it-up-and-start-again_986/index.html"), image: Some("media/cache/81/c4/81c4a973364e17d01f217e1188253d5e.jpg"), name: Some("Rip it Up and ..."), price: Some("£35,02") }, Produkt { url: Some("catalogue/our-band-could-be-your-life-scenes-from-the-american-indie-underground-1981-1991_985/index.html"), image: Some("media/cache/54/60/54607fe8945897cdcced0044103b10b6.jpg"), name: Some("Our Band Could Be ..."), price: Some("£57.25") }, Product { url: Some("catalogue/olio_984/index.html"), image: Some("media/cache/55/33/553310a7162dfbc2c6d19a84da0df9e1.jpg"), name: Some("Olio"), price: Some("£23.88") }, Product { url: Some("catalogue/mesaerion-the-best-science-fiction-stories-1800-1849_983/index.html"), image: Some("media/cache/09/a3/09a3aef48557576e1a85ba7efea8ecb7.jpg"), name: Some("Mesaerion: The Best Science ..."), price: Some("£37.59") }, Product { url: Some("catalogue/libertarianism-for-beginners_982/index.html"), image: Some("media/cache/0b/bc/0bbcd0a6f4bcd81ccb1049a52736406e.jpg"), name: Some("Libertarianism for Beginners"), price: Some("£51.33") }, Produkt { url: Some("catalogue/its-only-the-himalayas_981/index.html"), image: Some("media/cache/27/a5/27a53d0bb95bdd88288eaf66c9230d7e.jpg"), name: Some("It's Only the Himalayas"), price: Some("£45.17") }]
Das bedeutet, dass die Scraping-Logik korrekt funktioniert. Jetzt können Sie Ihren Nginx-Proxy zu diesem Scraper hinzufügen.
Nutzung Ihres Proxys
Sie werden feststellen, dass die Scraping-Anfrage über einen vollwertigen Reqwest-Client in der Funktion main() gesendet wird (anstatt über einen einmaligen Get-Aufruf ). Das bedeutet, dass Sie beim Erstellen des Clients ganz einfach einen Proxy konfigurieren können.
Um den Client zu konfigurieren, aktualisieren Sie die folgende Codezeile:
async fn main() -> Result<(), Box<dyn Error>>{
let url = "https://books.toscrape.com/";
# Ersetzen Sie diese Zeile
let client = reqwest::Client::new();
# Durch diese
let client = reqwest::Client::builder()
.Proxy(reqwest::Proxy::https("http://localhost:8080")?)
.build()?;
//...
Ok(())
}
Bei der Konfiguration des Proxys mit
reqwestist es wichtig zu wissen, dass einige Proxy-Anbieter (einschließlich Bright Data) sowohl mitHTTP-als auch mitHTTPS-Konfigurationenarbeiten, jedoch möglicherweise zusätzliche Konfigurationen erfordern. Wenn bei der Verwendung vonHTTPSProbleme auftreten, versuchen Sie, zur Ausführung der App aufHTTPumzuschalten.
Versuchen Sie nun, die Binärdatei erneut mit dem Befehl cargo run auszuführen. Sie sollten eine ähnliche Antwort wie zuvor erhalten. Überprüfen Sie jedoch in den Protokollen Ihres Nginx-Servers, ob eine Anfrage über einen Proxy geleitet wurde.
Suchen Sie die Protokolle Ihres Nginx-Servers anhand der Anweisungen für Ihr Betriebssystem. Bei einer Homebrew-basierten Installation auf einem Mac befinden sich die Zugriffs- und Fehlerprotokolldateien im Ordner „/opt/homebrew/var/log/nginx “. Öffnen Sie die Datei „access.log“ und Sie sollten am Ende der Datei eine Zeile wie diese sehen:
127.0.0.1 - - [07/Jan/2024:05:19:54 +0530] „GET https://books.toscrape.com/ HTTP/1.1” 200 18 „-” „-”
Dies zeigt an, dass die Anfrage über den Nginx-Server als Proxy weitergeleitet wurde. Jetzt können Sie den Server auf einem Remote-Host einrichten, um damit geografische Beschränkungen oder IP-Sperren zu umgehen.
Rotierende Proxys
Bei der Arbeit an Web-Scraping-Projekten müssen Sie möglicherweise zwischen einer Reihe von Proxys rotieren. Auf diese Weise können Sie Ihre Scraping-Arbeitslast auf mehrere IPs verteilen und vermeiden, dass Sie aufgrund des hohen Traffics von einer einzigen Quelle oder einem einzigen Standort entdeckt werden.
Um rotierende Proxys zu implementieren, müssen Sie die folgenden Funktionen zu Ihrer Datei main.rs hinzufügen:
#[derive(Debug)]
struct Proxy {
ip: String,
port: String,
}
fn get_proxies() -> Vec<PROXY> {
let mut proxies = Vec::new();
proxies.push(Proxy {
ip: "http://localhost".to_string(),
port: "8082".to_string(),
});
// Fügen Sie hier weitere proxies.push-Anweisungen hinzu, um einen größeren Satz von Proxys zu erstellen.
proxies
}
Auf diese Weise können Sie die Gruppe von Proxys ganz einfach definieren. Anschließend müssen Sie die Hauptfunktion wie folgt aktualisieren, um einen zufälligen Proxy zu verwenden:
#[tokio::main]
async fn main() -> Result<(), Box<dyn Error>> {
let url = "https://books.toscrape.com/";
// Fügen Sie diese beiden Zeilen hinzu
let proxies = get_proxies();
let random_proxy = proxies.choose(&mut rand::thread_rng()).unwrap();
let client = reqwest::Client::builder()
// Aktualisieren Sie die folgende Zeile entsprechend
.proxy(reqwest::Proxy::http(format!("{0}:{1}", random_proxy.ip, random_proxy.port))?)
.build()?;
// Der Rest bleibt unverändert.
let response = client
.get(url)
.send()
.await?;
let html_content = response.text().await?;
extract_products(&html_content);
Ok(())
}
Nun müssen Sie die Rand-Crate installieren, um eine zufällige Auswahl eines Proxys aus dem Array der Proxys zu ermöglichen. Dazu führen Sie den folgenden Befehl aus:
cargo add rand
Fügen Sie dann die folgende Zeile am Anfang Ihrer Datei main.rs hinzu, um die Rand-Crate zu importieren:
use rand::seq::SliceRandom;
Versuchen Sie nun, die Binärdatei erneut auszuführen, um zu sehen, ob sie mit dem Befehl cargo run funktioniert. Es sollte die gleiche Ausgabe wie zuvor angezeigt werden, was darauf hinweist, dass die zufällige Proxy-Liste korrekt eingerichtet ist.
Bright Data Proxy Server
Wie Sie gesehen haben, kann die manuelle Einrichtung eines Proxys sehr aufwendig sein. Außerdem müssen Sie den Proxy-Server auf einem Remote-Server hosten, um alle Vorteile einer neuen IP-Adresse und eines neuen Standorts nutzen zu können. Wenn Sie sich diesen Aufwand ersparen möchten, sollten Sie einen derBright Data-Proxy-Server in Betracht ziehen.
Es gibt zwar unzählige Proxy-Anbieter, aber Bright Data ist für seine schiere Größe und Flexibilität bekannt. Mit Bright Data erhalten Sie ein weitläufiges Netzwerk von 400M+ monthly Residential-, Mobile-, Rechenzentrums- und ISP-Proxys, die über 195 Länder verteilt sind. Dank der großen Anzahl an Residential-Proxys können Sie bestimmte Länder, Städte oder sogar Mobilfunkanbieter für ein zielgerichtetes Scraping auswählen.
Darüber hinaus fügen sich die Residential-Proxys von Bright Data nahtlos in den echten Traffic ein, während die Rechenzentrums- und Mobiloptionen blitzschnelle Geschwindigkeiten und zuverlässige Verbindungen bieten. Die automatische Rotation von Bright Data sorgt für ein agiles Scraping und minimiert das Risiko, entdeckt und gesperrt zu werden.
Um es selbst auszuprobieren, gehen Sie zu https://brightdata.com/ und klicken Sie oben rechts auf „Gratis testen ”. Nach der Anmeldung gelangen Sie zur Seite „Systemsteuerung ”:
Klicken Sie auf dieser Seite auf „Proxy-Produkte anzeigen“, um zur Seite „Proxys & Scraping-Infrastruktur“ zu gelangen:
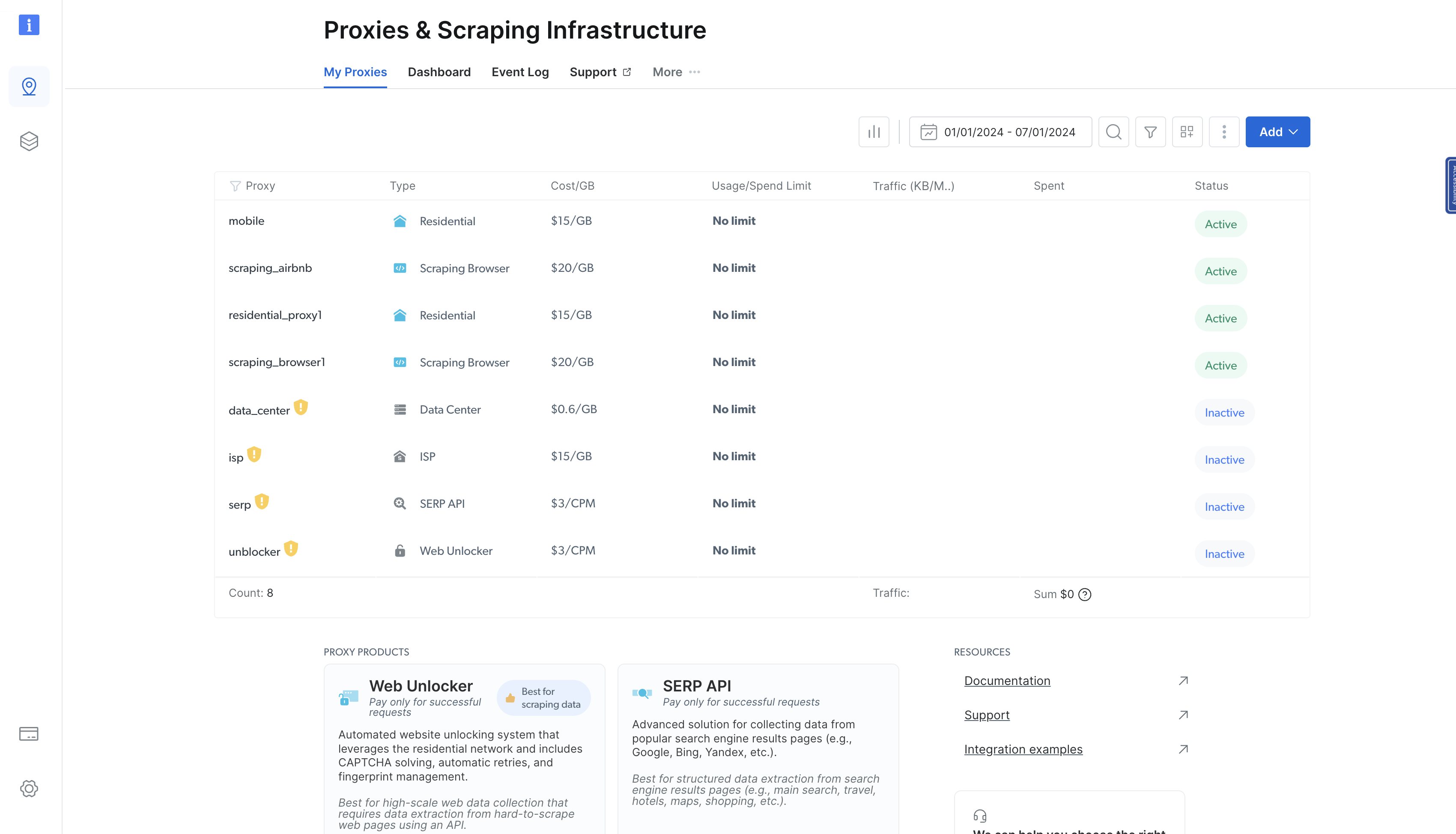
Auf dieser Seite werden alle Proxys aufgelistet, die Sie zuvor bereitgestellt haben. Um einen Proxy hinzuzufügen, klicken Sie oben rechts auf die blaue Schaltfläche „Hinzufügen“ und wählen Sie „Residential-Proxys“:
Es erscheint ein Formular, in dem Sie Ihren neuen Residential-Proxy konfigurieren können. Behalten Sie die Standardoptionen bei, scrollen Sie zum Ende der Seite und klicken Sie auf „Hinzufügen“.
Sobald der Residential-Proxy erstellt wurde, werden Sie zu einer Seite weitergeleitet, auf der die Details des neu erstellten Proxys angezeigt werden. Klicken Sie auf die Registerkarte „Zugriffsparameter“, um den Host, den Benutzernamen und das Passwort des Proxys anzuzeigen:
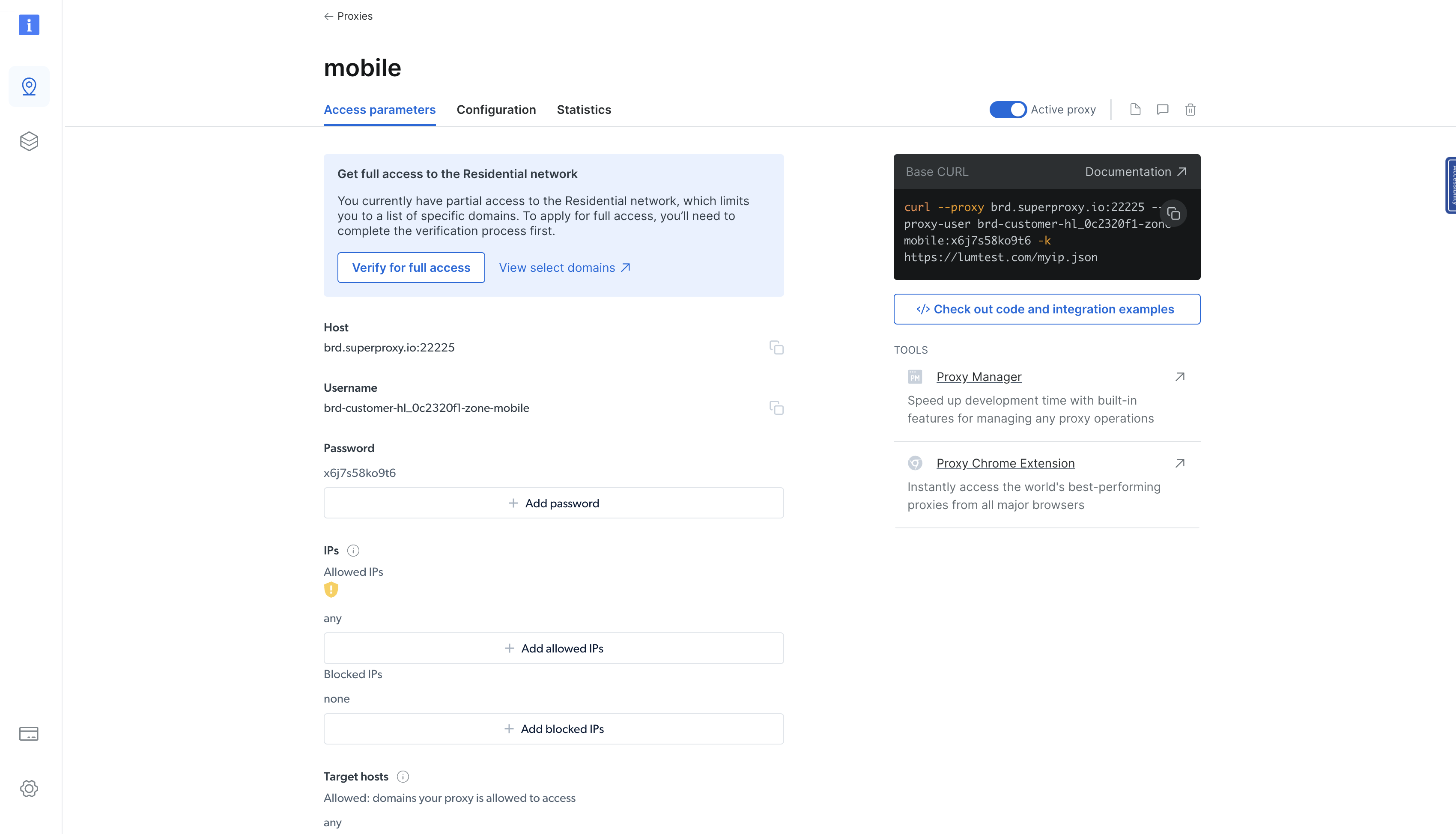
Sie können diese Parameter verwenden, um den Proxy in Ihre Rust-Binärdatei zu integrieren. Aktualisieren Sie dazu die Funktion „main()“ in der Datei „src/main.rs“ wie folgt:
#[tokio::main]
async fn main() -> Result<(), Box<dyn Error>> {
let url = "https://books.toscrape.com/";
// Aktualisieren Sie den folgenden Block mit den Angaben aus der Seite mit den Proxy-Details von Bright Data.
let client = reqwest::Client::builder()
.proxy(reqwest::Proxy::http("<BD-Proxy-Hostname & Port>")?
.basic_auth("<IHR BD-Benutzername>", "<IHR BD-Passwort>"))
.build()?;
// Der Rest bleibt unverändert.
let response = client
.get(url)
.send()
.await?;
let html_content = response.text().await?;
extract_products(&html_content);
Ok(())
}
Versuchen Sie dann, die Binärdatei erneut auszuführen. Sie sollte wie zuvor die richtige Antwort zurückgeben. Der einzige wesentliche Unterschied besteht darin, dass die Anfrage über einen Proxy von Bright Data weitergeleitet wird, wodurch Ihre Identität und Ihr tatsächlicher Standort verborgen bleiben.
Sie können dies überprüfen, indem Sie eine Anfrage an eine API senden, die die IP-Adresse des Clients anzeigt, und zwar mit dem folgenden Code-Schnipsel:
use reqwest;
use std::error::Error;
#[tokio::main]
async fn main() -> Result<(), Box<dyn Error>> {
let url = "http://lumtest.com/myip.json";
// Aktualisieren Sie den folgenden Block mit den Details aus der Bright Data-Proxy-Detailseite.
let client = reqwest::Client::builder()
.proxy(reqwest::Proxy::http("<BD-Proxy-Hostname & Port>")?
.basic_auth("<IHR BD-Benutzername>", "<IHR BD-Passwort>"))
.build()?;
// Der Rest bleibt unverändert.
let response = client
.get(url)
.send()
.await?;
let html_content = response.text().await?;
println!("{:?}", html_content);
Ok(())
}Wenn Sie den Code mit dem Befehl „cargo run“ ausführen, sollte eine Ausgabe angezeigt werden, die wie folgt aussieht:
"{"ip":"209.169.64.172","country":"US","asn":{"asnum":6300,"org_name":"CCI-TEXAS"},"geo":{"city":"Conroe","region":"TX","region_name":"Texas","postal_code":"77304","latitude":30.3228,"longitude":-95.5298,"tz":"America/Chicago","lum_city":"conroe","lum_region":"tx"}}"
Dies spiegelt die IP-Adresse und die Standortdetails des Proxy-Servers wider, den Sie für die Abfrage der Seite verwenden.
Fazit
In diesem Artikel haben Sie gelernt, wie Sie Proxys mit Rust verwenden können. Denken Sie daran, dass Proxys wie digitale Masken sind, mit denen Sie Online-Beschränkungen umgehen und hinter die Beschränkungen von Websites blicken können. Außerdem ermöglichen sie Ihnen, beim Surfen im Internet anonym zu bleiben.
Die Einrichtung eines eigenen Proxys ist jedoch ein komplexer Vorgang. In der Regel wird empfohlen, sich für einen etablierten Proxy-Anbieter wieBright Data zu entscheiden, der einen Proxy-Pool mit 400M+ monthly benutzerfreundlichen Proxys anbietet.






