

Wenn Sie sich für Web-Scraping interessieren, ist das Verständnis von HTML entscheidend, da jede Website damit erstellt wird. Web-Scraping kann in allen möglichen Szenarien eingesetzt werden und dabei helfen, Daten von Websites ohne API zu sammeln, Preisüberwachung durchzuführen, Lead-Listen zu erstellen, akademische Forschung zu betreiben und vieles mehr.
In diesem Artikel lernen Sie die Grundlagen von HTML kennen und erfahren, wie Sie Daten mit Python extrahieren, parsen und verarbeiten können.
Sind Sie an einer ausführlichen Anleitung zum Python-Web-Scraping interessiert? Klicken Sie hier.
So scrapen Sie Websites und extrahieren HTML
Bevor Sie mit diesem Tutorial beginnen, lassen Sie uns einen Moment innehalten, um die wesentlichen Komponenten von HTML zu wiederholen.
Einführung in HTML
HTML ist eine Sammlung von Tags, die einem Browser die Struktur und Elemente einer Website mitteilen. Beispielsweise teilt<h1> Text </h1>einem Browser mit, dass der auf den Tag folgende Textabschnitt eine Überschrift ist, und<a href=""> link </a>identifiziert einen Hyperlink.
Ein HTML-Attribut liefert zusätzliche Informationen zu einem Tag. Dashref-Attributfür das Tag<a> </a>gibt Ihnen beispielsweise Informationen über die URL der Seite, auf die das Attribut verweist.
Klassen und IDssind wichtige Attribute, um Elemente auf einer Seite genau zu identifizieren. Klassen gruppieren ähnliche Elemente, um sie mithilfe von CSS einheitlich zu gestalten oder mit JavaScript einheitlich zu bearbeiten. Klassen werden mit.class-name angesprochen.
Auf der Website W3Schools sehen Klassengruppen wie folgt aus:
<div class="city">
<h2>London</h2>
<p>London ist die Hauptstadt von England.</p>
</div>
<div class="city">
<h2>Paris</h2>
<p>Paris ist die Hauptstadt von Frankreich.</p>
</div>
<div class="city">
<h2>Tokio</h2>
<p>Tokio ist die Hauptstadt Japans.</p>
</div>
Sie können sehen, wie jeder Titel und jeder Stadtblock mit einem div-Element umschlossen ist, das dieselbe Stadtklasse hat.
Im Gegensatz dazu sind IDs für jedes Element einzigartig (d. h. zwei Elemente können nicht dieselbe ID haben). Die folgenden H1-Elemente haben beispielsweise eindeutige IDs und können individuell gestaltet/bearbeitet werden:
<h1 id="header1">Hallo Welt!</h1>
<h1 id="header2">Lorem Ipsum Dolor</h1>
Die Syntax zum Ansprechen von Elementen mit IDs lautet #id-name.
Nachdem Sie nun die Grundlagen von HTML kennen, können wir mit dem Web-Scraping beginnen.
Richten Sie Ihre Scraping-Umgebung ein
Dieses Tutorial verwendet Python, da es viele HTML-Scraping-Bibliotheken bietet und die Sprache leicht zu erlernen ist. Um zu überprüfen, ob Python auf Ihrem Computer installiert ist, führen Sie den folgenden Befehl in PowerShell (Windows) oder Ihrem Terminal (macOS) aus:
python3
Wenn Python installiert ist, wird die Versionsnummer angezeigt; wenn nicht, erhalten Sie eine Fehlermeldung.InstallierenSiePython, falls Sie es noch nicht haben.
Erstellen Sie als Nächstes einen Ordner namens„WebScraper“und erstellen Sie darin eine Datei mit dem Namen„scraper.py“. Öffnen Sie diese dann in der integrierten Entwicklungsumgebung (IDE) Ihrer Wahl. Hier wirdVisual Studio Codeverwendet:
Eine IDE ist eine Mehrzweckanwendung, mit der Programmierer Code schreiben, debuggen, Programme testen, Automatisierungen erstellen und vieles mehr können. Sie verwenden sie hier, um Ihren HTML-Scraper zu programmieren.
Als Nächstes müssen Sie Ihre globale Python-Installation von Ihrem Scraping-Projekt trennen, indem Sie eine virtuelle Umgebung erstellen. Dies hilft, Abhängigkeitskonflikte zu vermeiden und die gesamte Anwendung übersichtlich zu halten.
Installieren Sie dazu die virtualenv -Bibliothek mit dem folgenden Befehl:
pip3 install virtualenv
Navigieren Sie zu Ihrem Projektordner:
cd WebScraper
Erstellen Sie dann eine virtuelle Umgebung:
python<version> -m venv <virtual-environment-name>
Dieser Befehl erstellt einen Ordner für alle Pakete und Skripte in Ihrem Projektordner:
Nun müssen Sie die virtuelle Umgebung mit einem der folgenden Befehle (je nach Ihrer Plattform) aktivieren:
source <Name der virtuellen Umgebung>/bin/activate #Unter MacOS und Linux
<Name der virtuellen Umgebung>/Scripts/activate.bat #Unter CMD
<Name der virtuellen Umgebung>/Scripts/Activate.ps1 #Unter Powershell
Nach erfolgreicher Aktivierung wird der Name Ihrer virtuellen Umgebung auf der linken Seite des Bildschirms angezeigt:
Nachdem Ihre virtuelle Umgebung aktiviert ist, müssen Sie eine Web-Scraping-Bibliothek installieren. Es gibt zahlreiche Optionen, darunter Playwright, Selenium, Beautiful Soup und Scrapy. Hier verwenden Sie Playwright, da es einfach zu bedienen ist, mehrere Browser unterstützt, dynamische Inhalte verarbeiten kann und einen Headless-Modus (Scraping ohne grafische Benutzeroberfläche (GUI)) bietet.
Führen Sie pip install pytest-playwright aus, um Playwright zu installieren, und installieren Sie anschließend die erforderlichen Browser mit playwright install.
Nach der Installation von Playwright können Sie mit dem Web-Scraping beginnen.
HTML aus einer Website extrahieren
Der erste Schritt eines jeden Web-Scraping-Projekts besteht darin, die Website zu identifizieren, die Sie scrapen möchten. Hier verwenden Sie diese Testseite.
Als Nächstes müssen Sie die Informationen identifizieren, die Sie von der Seite scrapen möchten. In diesem Fall ist es der gesamte HTML-Inhalt der Seite.
Sobald Sie die Informationen identifiziert haben, die Sie scrapen möchten, können Sie mit der Programmierung des Scrapers beginnen. In Python besteht der erste Schritt darin,die erforderlichen Bibliotheken für Playwright zu importieren. Mit Playwright können Sie zwei Arten von APIs importieren:sync und async. Die async-Bibliothek wird nur beim Schreiben von asynchronem Code verwendet, daher importieren Sie die sync-Bibliothek mit dem folgenden Befehl:
from playwright.sync_api import sync_playwright
Nach dem Importieren der sync-Bibliothek müssen Sie eine Python-Funktion mit dem folgenden Code-Schnipsel deklarieren:
def main():
#Der Rest des Codes befindet sich innerhalb dieser Funktion
Wie Sie aus der vorstehenden Anmerkung ersehen können, schreiben Sie Ihren Web-Scraping-Code innerhalb dieser Funktion.
Um Informationen von einer Website zu erhalten, öffnen Sie normalerweise einen Webbrowser, erstellen einen neuen Tab und besuchen die Website. Um die Website zu scrapen, müssen Sie diese Aktionen in Code übersetzen, wofür Sie Playwright verwenden. Inder Dokumentationwird gezeigt, dass Sie die zuvor importiertesync_apiaufrufen und einen Browser mit diesem Ausschnitt öffnen können:
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
Durch Hinzufügen von headless=False innerhalb der Klammern können Sie den Inhalt der Website sehen.
Öffnen Sie nach dem Öffnen Ihres Browsers einen neuen Tab und rufen Sie die Ziel-URL auf:
page = browser.new_page()
try:
page.goto("https://webscraper.io/test-sites/e-commerce/static")
except:
print("Error")
Hinweis: Die vorangehenden Zeilen müssen unter den Zeilen hinzugefügt werden, die zuvor den Browser gestartet haben. Der gesamte Code befindet sich innerhalb der Hauptfunktion und in einer Datei.
Dieser Codeausschnitt umschließt die Funktiongoto()mit einemtry-except-Block, um Fehler besser behandeln zu können.
Wenn Sie die URL einer Website in die Suchleiste eingeben, müssen Sie warten, bis sie geladen ist. Um dies im Code nachzuahmen, können Sie Folgendes verwenden:
page.wait_for_timeout(7000) #Millisekundenwert in Klammern
Hinweis: Diese Zeilen müssen unter den vorherigen Zeilen hinzugefügt werden.
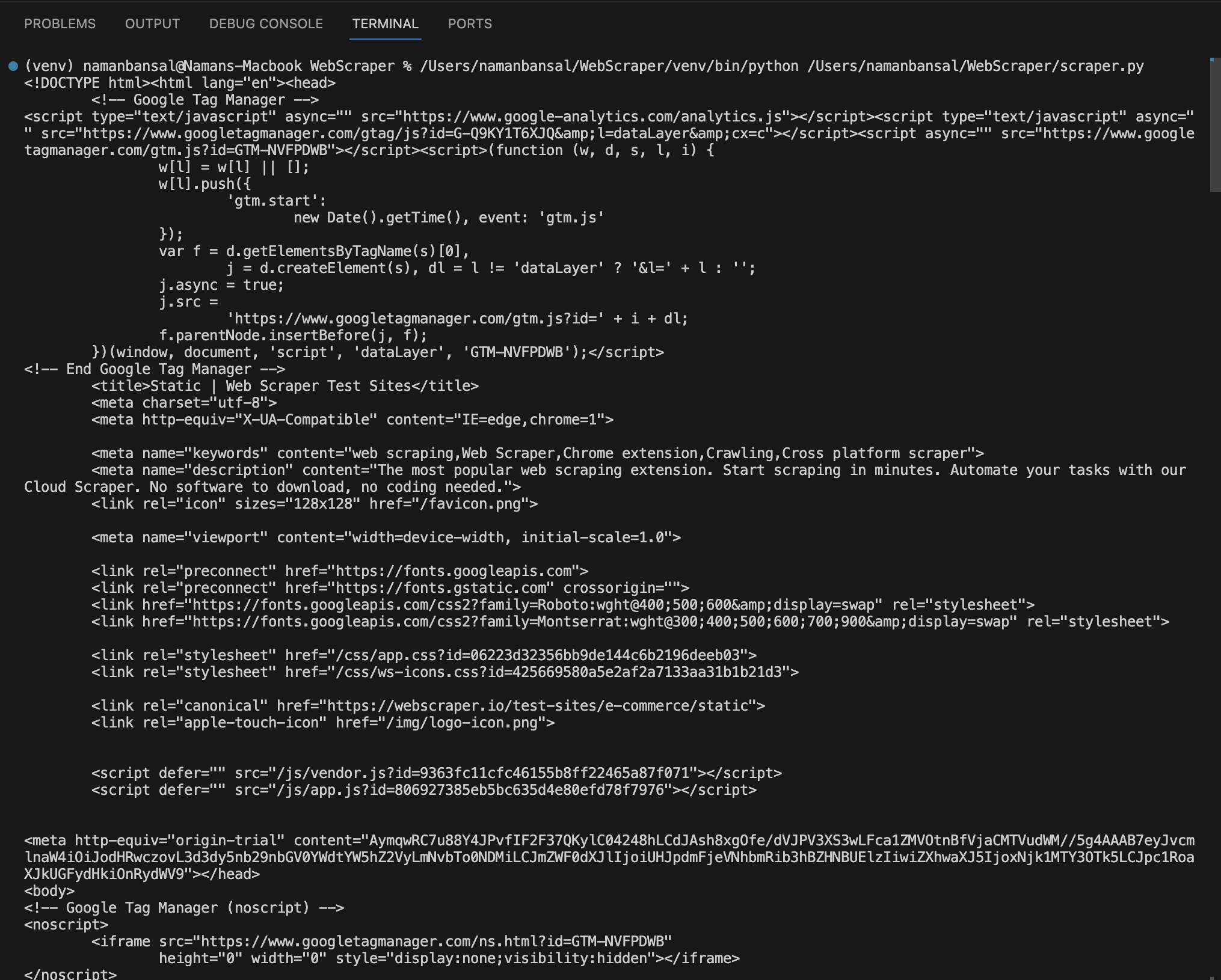
Schließlich ist es an der Zeit, den gesamten HTML-Inhalt der Seite mit dieser Codezeile zu extrahieren:
print(page.content())
Der vollständige Code zum Extrahieren des HTML-Codes einer Seite sieht wie folgt aus:
from playwright.sync_api import sync_playwright
def main():
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
try:
page.goto("https://webscraper.io/test-sites/e-commerce/static")
except:
print("Fehler")
page.wait_for_timeout(7000)
print(page.content())
main()
In Visual Studio Code sieht der extrahierte HTML-Code wie folgt aus:
HTML anhand bestimmter Attribute extrahieren
Zuvor haben Sie alle Elemente der Web-Scraper-Webseite extrahiert. Web-Scraping ist jedoch nur dann sinnvoll, wenn Sie sich darauf beschränken, nur die Informationen zu scrapen, die Sie benötigen. In diesem Abschnitt extrahieren Sie nur die Titel aller Laptops auf der ersten Seite der Website:
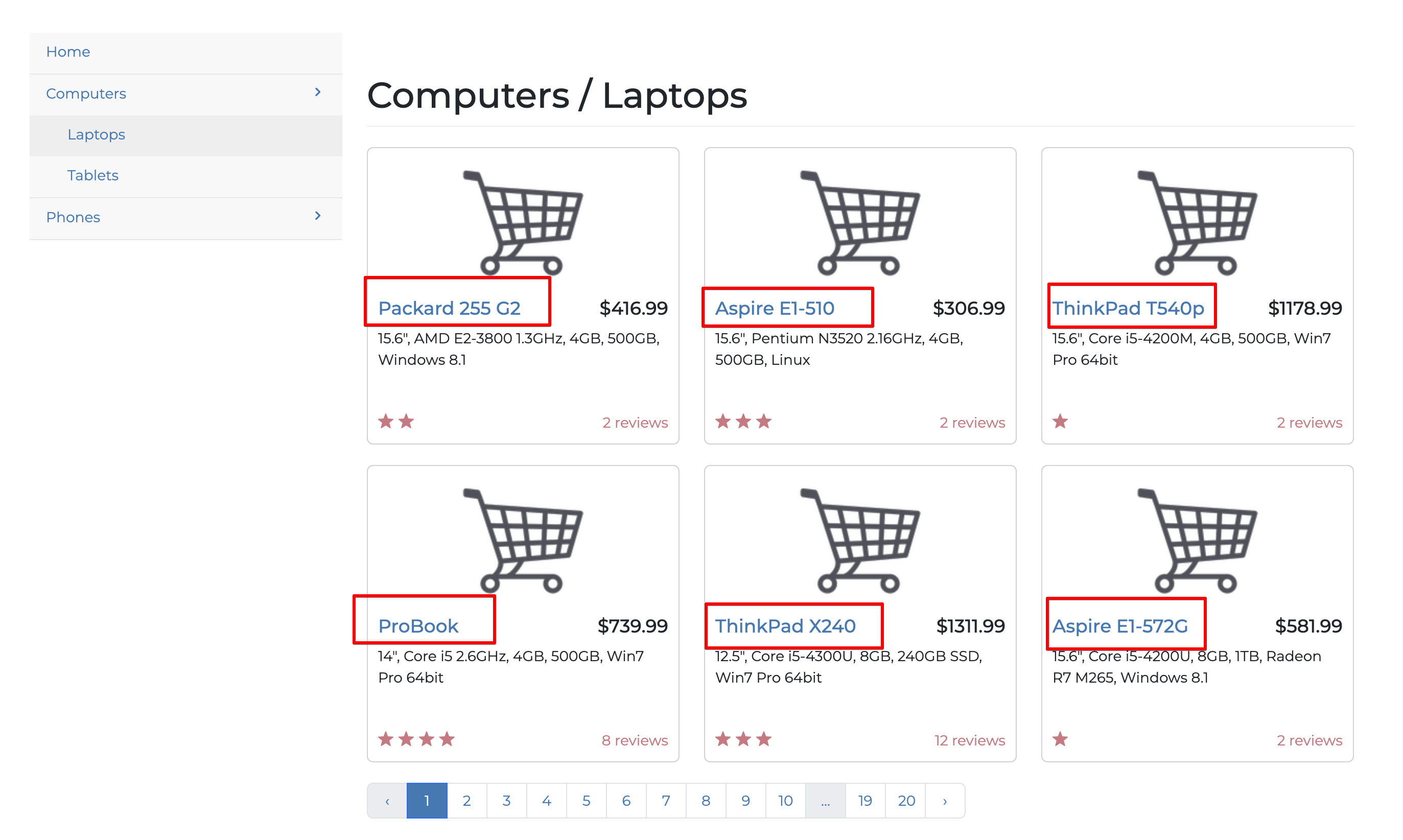
Um bestimmte Elemente zu extrahieren, müssen Sie die Struktur der Zielwebsite verstehen. Dazu klicken Sie mit der rechten Maustaste und wählen die Option„Untersuchen“wie folgt aus:
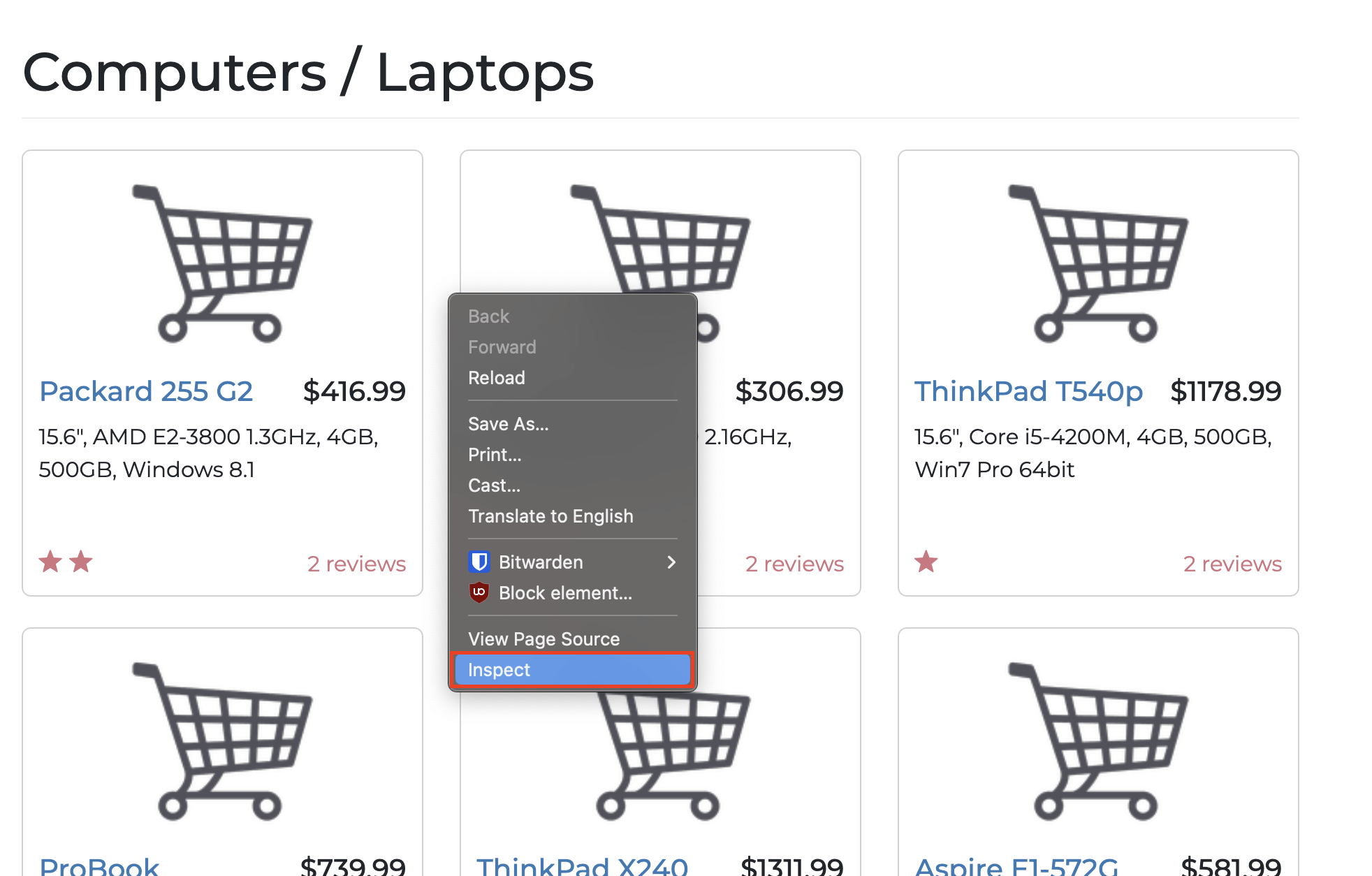
Alternativ können Sie auch diese Tastenkombinationen verwenden:
- Für macOS verwenden SieCmd + Option + I
- Für Windows verwenden SieStrg + Umschalt + C
Hier ist die Struktur der Zielseite:
Sie können den Code für ein bestimmtes Element auf einer Seite mit dem Auswahlwerkzeug oben links im Fenster„Untersuchen“anzeigen:

Wählen Sie einen der Laptop-Titel in IhremInspektionsfensteraus:
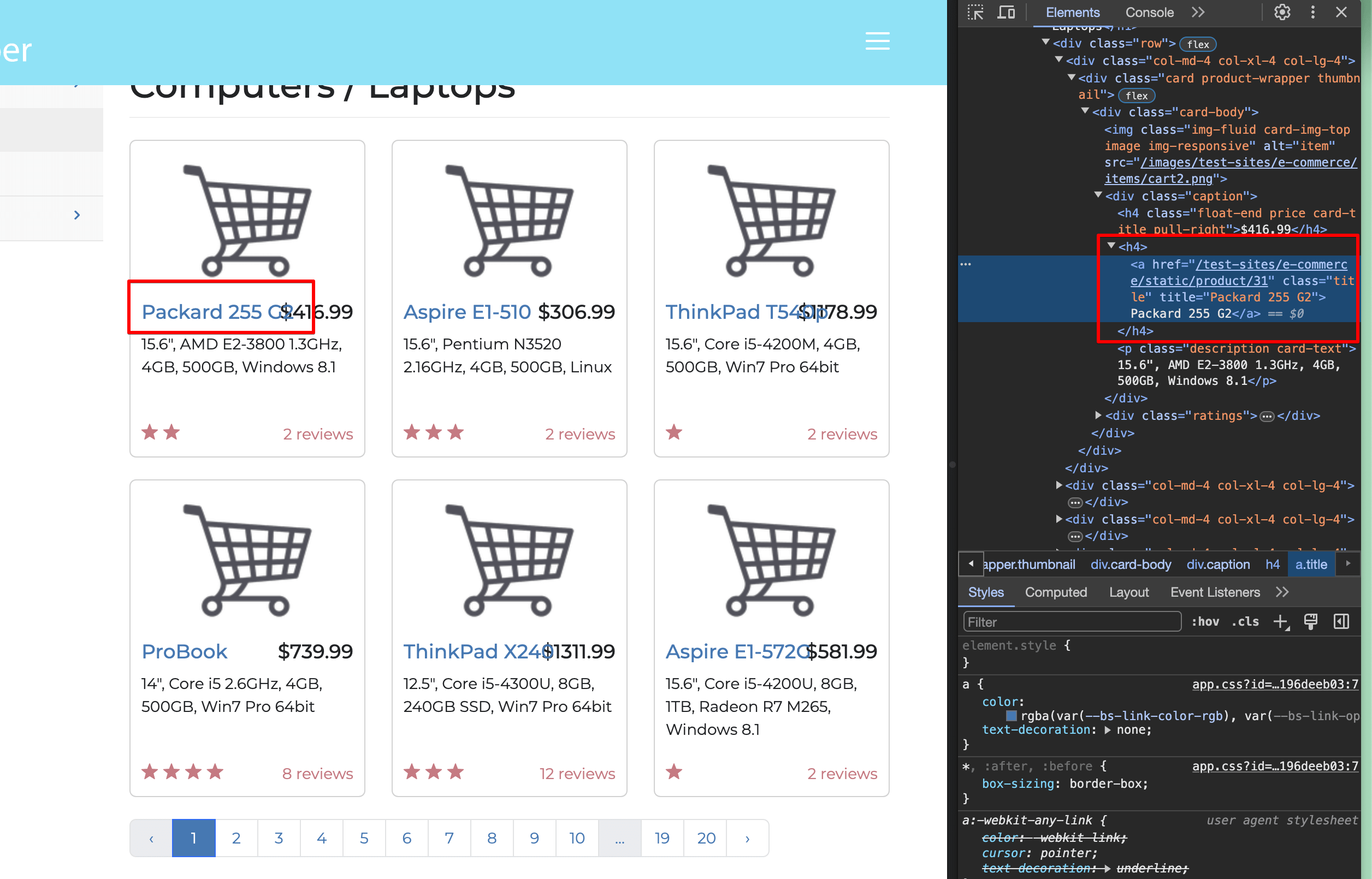
Sie sehen, dass sich der Titel innerhalb eines <a> </a> -Tags befindet, das von einem h4-Tag umschlossen ist, und dass der Link eine Klasse namens „title“ hat. Das bedeutet, dass Sie nach <a href> -Tags (URLs) innerhalb von <h4> -Tags suchen, die eine Klasse namens „title“ haben.
Um ein Scraping-Programm zu erstellen, das genau auf diese Elemente abzielt, müssen Sie die Bibliotheken importieren, um eine Python-Funktion zu erstellen, den Browser starten und zur Zielwebsite navigieren:
from playwright.sync_api import sync_playwright
def main():
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
try:
page.goto("https://webscraper.io/test-sites/e-commerce/static/computers/laptops")
except:
print("Error")
page.wait_for_timeout(7000)
Beachten Sie, dass die Ziel-URL innerhalb der Funktion page.goto() aktualisiert wurde, sodass sie nun auf die erste Seite verweist, die die Liste der Laptops enthält.
Nachdem Sie das Scraping-Programm erstellt haben, müssen Sie das Zielelement anhand Ihrer Website-Strukturanalyse lokalisieren. Playwright verfügt über ein Tool namensLocators, mit dem Sie Elemente auf einer Seite anhand verschiedener Attribute lokalisieren können, wie zum Beispiel:
get_by_label()findet das Zielelement anhand der mit einem Element verknüpften Bezeichnung.get_by_text()findet das Zielelement anhand des Textes, den das Element enthält.get_by_alt_text()findet das Zielelement und führt Aktionen für Bilder anhand ihres Alt-Textes aus.get_by_test_id()findet das Zielelement anhand der Test-ID eines Elements.
Weitere Methoden zum Auffinden von Elementen finden Sie inder offiziellen Dokumentation.
Um alle Laptop-Titel zu scrapen, müssen Sie die <h4> -Tags finden, da diese alle Laptop-Titel umschließen. Mit dem Locator get_by_role() können Sie Elemente anhand ihrer Funktion finden, z. B. Schaltflächen, Kontrollkästchen und Überschriften. Das bedeutet, dass Sie Folgendes schreiben müssen, um alle Überschriften auf der Seite zu finden:
titles = page.get_by_role("heading").all()
Anschließend können Sie es mit dem folgenden Code in Ihrer Konsole ausgeben:
print(titles)
Nach dem Ausgeben werden Sie feststellen, dass eine Reihe von Elementen angezeigt wird:
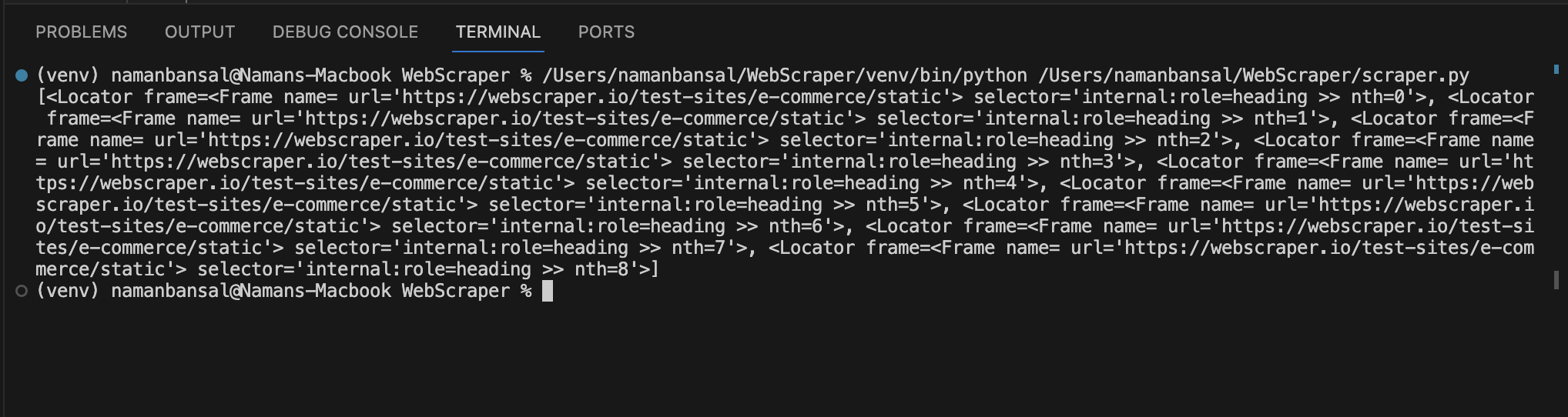
Diese Ausgabe enthält keine Titel, sondern verweist auf Elemente, die den Selektorbedingungen entsprechen. Sie müssen diese Elemente durchlaufen, um ein <a> -Tag mit einer Titelklasse und dem darin enthaltenen Text zu finden.
Es wird empfohlen, den CSS-Locator zu verwenden, um ein Element anhand seines Pfads und seiner Klasse zu finden. Mit der Funktion all_inner_texts() können Sie den inneren Text eines Elements wie folgt extrahieren:
for title in titles:
laptop = title.locator("a.title").all_inner_texts()
Nach Ausführung dieses Codes sollte Ihre Ausgabe wie folgt aussehen:
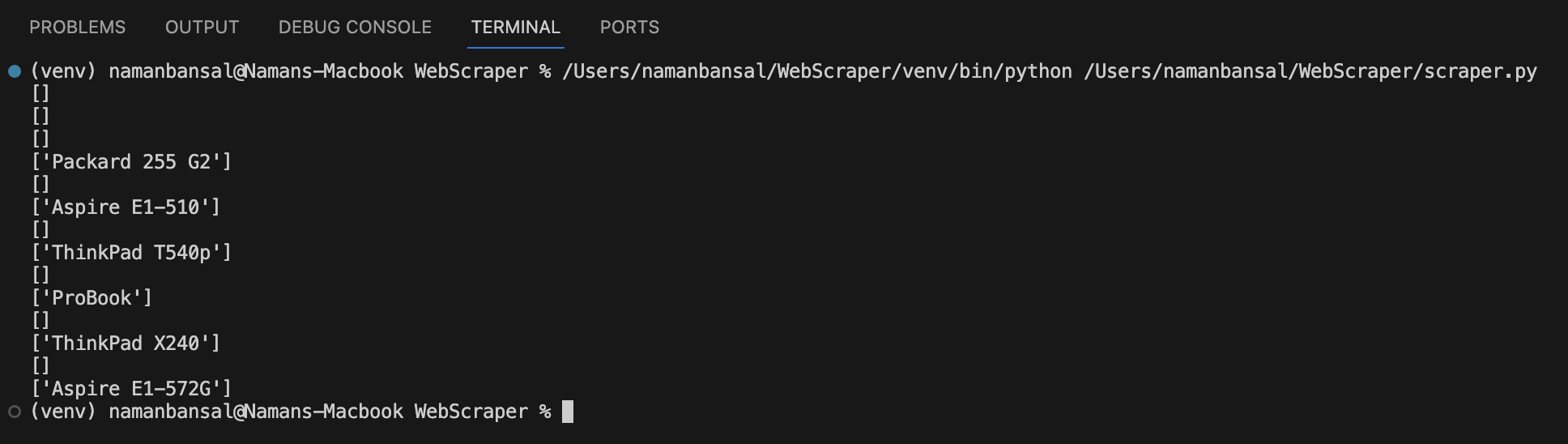
Um Arrays ohne Werte abzulehnen, schreiben Sie Folgendes:
if len(laptop) == 1:
print(laptop[0])
Sobald Sie Arrays ohne Werte abgelehnt haben, haben Sie erfolgreich ein Scraping-Programm erstellt, das nur bestimmte Elemente extrahiert.
Hier ist der vollständige Code für diesen Scraper:
from playwright.sync_api import sync_playwright
def main():
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
try:
page.goto("https://webscraper.io/test-sites/e-commerce/static/computers/laptops")
except:
print("Error")
page.wait_for_timeout(7000)
titles = page.get_by_role("heading").all()
for title in titles:
laptop = title.locator("a.title").all_inner_texts()
if len(laptop) == 1:
print(laptop[0])
main()
Mit Elementen interagieren
Lassen Sie uns nun einen Schritt weiter gehen und ein Programm erstellen, das die Titel von der ersten Seite mit Laptops extrahiert, zur zweiten Seite navigiert und auch diese Titel extrahiert.
Da Sie bereits wissen, wie man Titel aus einer Seite extrahiert, müssen Sie nur noch herausfinden, wie man zur nächsten Seite mit Laptops navigiert.
Möglicherweise haben Sie bereits die Paginierungsschaltflächenauf der Seite bemerkt, auf der Sie sich gerade befinden.
Sie müssendie 2finden und mit Ihrem Scraping-Programm darauf klicken. Wenn Sie die Seite untersuchen, werden Sie feststellen, dass das erforderliche Element ein Listenelement (<li>-Tag) ist und den inneren Text2 enthält:
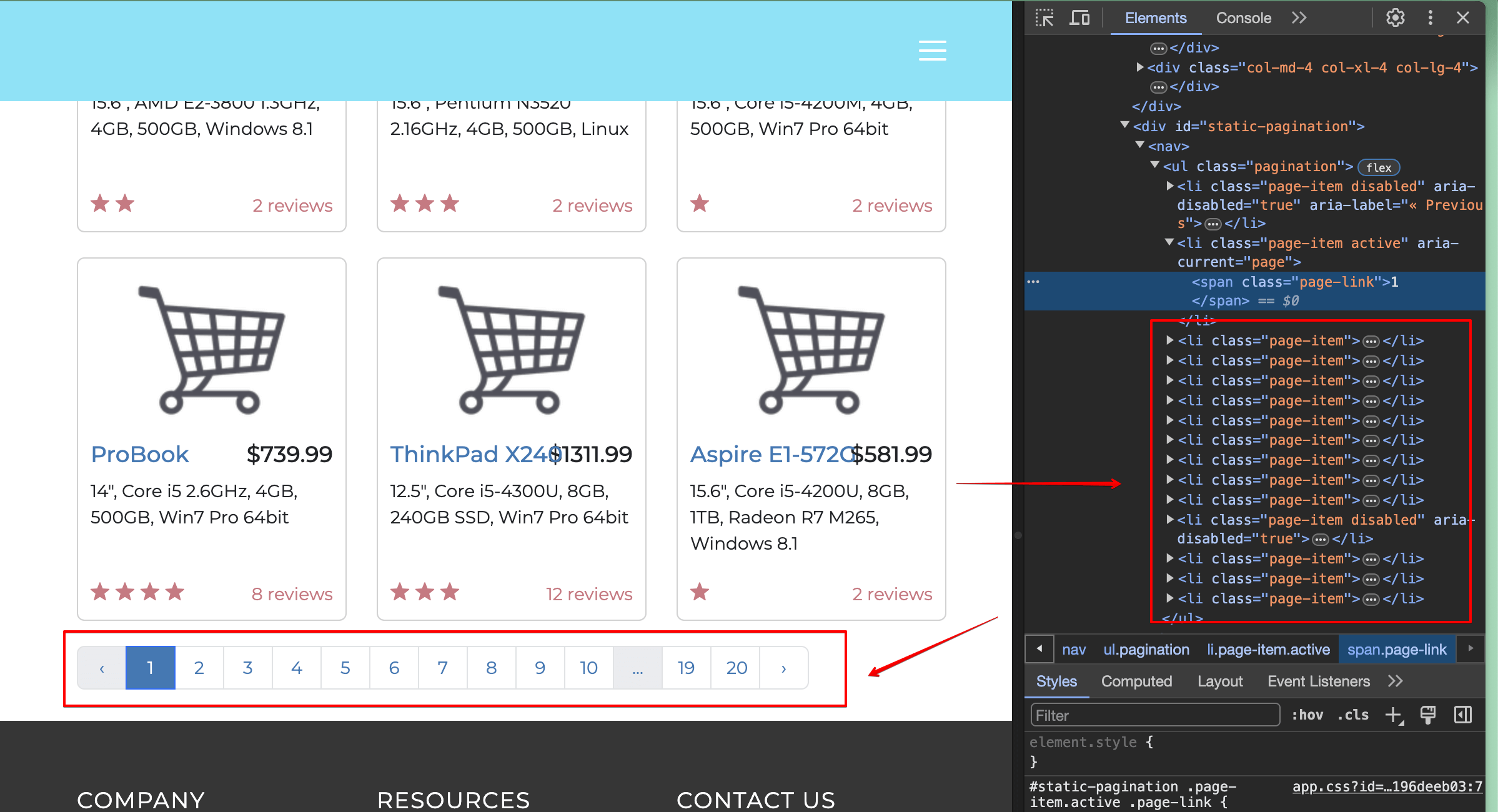
Das bedeutet, dass Sie den Selektor get_by_role() verwenden können, um ein Listenelement zu finden, und den Selektor get_by_text(), um ein Element mit dem Text 2 zu finden.
So programmieren Sie dies in Ihrer Datei:
page.get_by_role("listitem").get_by_text("2", exact=True)
Dadurch wird ein Element gefunden, das zwei Bedingungen erfüllt: Erstens muss es ein Listenelement sein und zweitens muss es den Text 2 enthalten.
exact=True ist ein Funktionsargument, um das Element mit dem angegebenen Text zu finden.
Um auf die Schaltfläche zu klicken, ändern Sie den vorherigen Code so, dass er wie folgt aussieht:
page.get_by_role("listitem").get_by_text("2", exact=True).click()
In diesem Code klickt die Funktion click() auf das angegebene Element.
Warten Sie, bis die Seite geladen ist, und extrahieren Sie erneut alle Titel:
page.wait_for_timeout(5000)
titles = page.get_by_role("heading").all()
for title in titles:
laptop = title.locator("a.title").all_inner_texts()
if len(laptop) == 1:
print(laptop[0])
Ihr vollständiger Code-Block sollte nun wie folgt aussehen:
from playwright.sync_api import sync_playwright
def main():
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
try:
page.goto("https://webscraper.io/test-sites/e-commerce/static/computers/laptops")
except:
print("Fehler")
page.wait_for_timeout(7000)
titles = page.get_by_role("heading").all()
for title in titles:
laptop = title.locator("a.title").all_inner_texts()
if len(laptop) == 1:
print(laptop[0])
page.get_by_role("listitem").get_by_text("2", exact=True).click()
page.wait_for_timeout(5000)
titles = page.get_by_role("heading").all()
for title in titles:
laptop = title.locator("a.title").all_inner_texts()
if len(laptop) == 1:
print(laptop[0])
main()
HTML extrahieren und in eine CSV-Datei schreiben
Wenn Sie die gesammelten Daten nicht speichern und analysieren, sind sie nutzlos. In diesem Abschnitt erstellen Sie ein erweitertes Programm, das die Anzahl der zu durchsuchenden Laptop-Seiten vom Benutzer erfasst, die Titel extrahiert und sie in einer CSV-Datei in Ihrem Projektordner speichert.
Für dieses Programm benötigen Sie eine vorinstallierte CSV-Bibliothek, die mit dem folgenden Befehl importiert werden kann:
import csv
Nachdem Sie die CSV-Bibliothek installiert haben, müssen Sie herausfinden, wie Sie je nach Benutzereingabe eine variable Anzahl von Seiten aufrufen können.
Wenn Sie sich die URL-Struktur der Website ansehen, werden Sie feststellen, dass jede Seite mit Laptops durch einen URL-Parameter gekennzeichnet ist. Die URL der zweiten Seite im Laptop-Verzeichnis lautet beispielsweise https://webscraper.io/test-sites/e-commerce/static/computers/laptops?page=2.
Sie können verschiedene Seiten aufrufen, indem Sie den URL-Parameter ?page=2 durch unterschiedliche numerische Werte ersetzen. Das bedeutet, dass Sie den Benutzer auffordern müssen, die Anzahl der zu scrappenden Seiten mit dem folgenden Befehl einzugeben:
pages = int(input("Geben Sie die Anzahl der zu scrapend Seiten ein: "))
Um jede Seite von 1 bis zur vom Benutzer eingegebenen Anzahl von Seiten aufzurufen, verwenden Sie eine for- Schleife wie diese:
for i in range(1, pages+1):
Innerhalb dieser Range-Funktion verwenden Sie 1 und pages+1 als Funktionsargumente, um die Werte darzustellen, bei denen die Schleife beginnt und endet. Das zweite Funktionsargument wird aus der Schleife ausgeschlossen. Wenn die Range-Funktion beispielsweise range(1,5) lautet, würde das Programm nur von 1 bis 4 durchlaufen.
Als Nächstes müssen Sie jede Seite aufrufen, indem Sie den Wertials URL-Parameter in der Iteration eingeben. MitPython-F-Strings können Sie Variablen zu einer Zeichenfolge hinzufügen.
Bei der Ausgabe einer Zeichenfolge setzen Sie vor die Anführungszeichen ein f, um anzuzeigen, dass es sich um eine f-Zeichenfolge handelt. Innerhalb der Anführungszeichen können Sie geschweifte Klammern verwenden, um Variablen anzugeben.
Hier ist ein Beispiel dafür, wie Sie f-Strings verwenden können, um Variablen zusammen mit Strings auszugeben:
print(f"Der Wert der Variablen ist {variable_name_goes_here}")
Zurück zum Scraper: Sie können f-Strings verwenden, indem Sie diesen Code-Block in die Datei schreiben:
try:
page.goto(f"https://webscraper.io/test-sites/e-commerce/static/computers/laptops?page={i}")
except:
print("Error")
Warten Sie mit einer Timeout-Funktion, bis die Seite geladen ist, und extrahieren Sie die Titel mit folgendem Befehl:
page.wait_for_timeout(7000)
titles = page.get_by_role("heading").all()
Sobald Sie alle Titelelemente haben, müssen Sie Ihre CSV-Datei öffnen, jede Zeile durchlaufen, den erforderlichen Text extrahieren und in Ihre Datei schreiben.
Um eine CSV-Datei zu öffnen, verwenden Sie die folgende Syntax:
with open("laptops.csv", "a") as csvfile:
Hier öffnen Sie die Dateilaptops.csvim Modus „Anhängen“ (a). Sie verwenden hier den Modus „Anhängen“, da Sie nicht möchten, dass jedes Mal, wenn die Datei geöffnet wird, alte Daten verloren gehen. Wenn die Datei nicht existiert, erstellt die Bibliothek eine solche im Projektordner.CSV bietet mehrere Modizum Öffnen einer Datei, darunter die folgenden:
- rist die Standardoption, die verwendet wird, wenn nichts angegeben ist. Die Datei wird schreibgeschützt geöffnet.
- wöffnet eine Datei zum Schreiben. Bei jedem Öffnen der Datei werden die vorherigen Daten überschrieben.
- aöffnet eine Datei zum Anhängen von Daten. Vorherige Daten werden nicht überschrieben.
- r+öffnet eine Datei sowohl zum Lesen als auch zum Schreiben.
- xerstellt eine neue Datei.
Unterhalb des vorherigen Codes müssen SieeinWriter-Objekt deklarieren, mit dem Sie die CSV-Datei bearbeiten können:
writer = csv.writer(csvfile)
Als Nächstes durchlaufen Sie jedes Titelelement und extrahieren den Text mit folgendem Befehl:
for title in titles:
laptop = title.locator("a.title").all_inner_texts()
Dadurch erhalten Sie mehrere Arrays, die jeweils den Titel einzelner Laptops enthalten. Um leere Arrays zu verwerfen, schreiben Sie den folgenden bedingten Code in die CSV-Datei:
if len(laptop) == 1:
writer.writerow([laptop[0]])
Mit der Funktion writerow können Sie neue Zeilen in eine CSV-Datei schreiben.
Hier ist der gesamte Code für das Programm:
from playwright.sync_api import sync_playwright
import csv
def main():
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
pages = int(input("enter the number of pages to scrape: "))
for i in range(1, pages+1):
try:
page.goto(f"https://webscraper.io/test-sites/e-commerce/static/computers/laptops?page={i}")
except:
print("Fehler")
page.wait_for_timeout(7000)
titles = page.get_by_role("heading").all()
with open("laptops.csv", "a") as csvfile:
writer = csv.writer(csvfile)
for title in titles:
laptop = title.locator("a.title").all_inner_texts()
if len(laptop) == 1:
writer.writerow([laptop[0]])
browser.close()
main()
Nach Ausführung dieses Codes sollte Ihre CSV-Datei wie folgt aussehen:
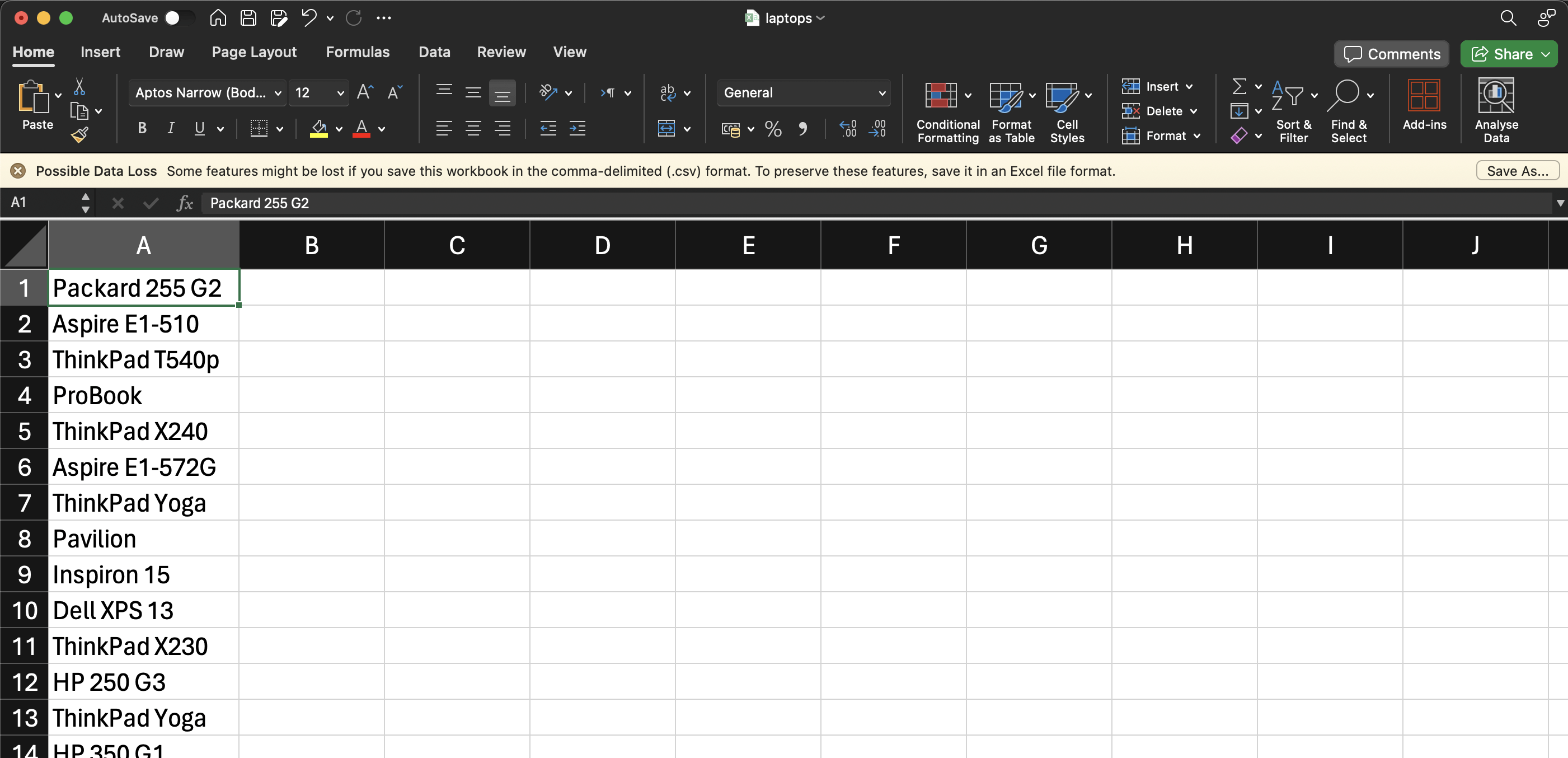
Fazit
In diesem Artikel haben Sie gelernt, wie Sie HTML mit Python extrahieren, parsen und speichern können.
Dieses Tutorial war relativ einfach, aber in der Praxis würden Sie beim Scraping wahrscheinlich auf verschiedene Hindernisse stoßen, darunter CAPTCHAs, Ratenbeschränkungen, Änderungen am Layout der Website oder gesetzliche Anforderungen. Glücklicherweise kannBright DataIhnen dabei helfen. Bright Data bietet Tools wieerweiterte Residential-Proxyszur Verbesserung Ihres Web-Scrapings, eineWebScraper IDEzum Erstellen von Scrapers in großem Maßstab und einenWeb Unblockerzum Entsperren öffentlicher Websites, einschließlich einer CAPTCHA-Lösung. Diese Tools können Ihnen dabei helfen, genaue Daten in großem Maßstab zu sammeln und Hindernisse zu überwinden. Darüber hinaus stellt Bright Data durch sein Engagement für ethisches Scraping sicher, dass Sie die Nutzungsbedingungen der Website und die gesetzlichen Bestimmungen einhalten.
Mit der funktionsreichen Plattform von Bright Data können Sie sich auf die Extraktion der wertvollen Daten konzentrieren, die Sie benötigen, und die Komplexität des Web-Scrapings hinter sich lassen. Testen Sie die Plattform noch heute gratis!





