
In diesem Artikel erfahren Sie:
- Was ein Amazon-Preis-Tracker ist und warum er nützlich ist
- Wie Sie einen solchen Tracker mit einer Schritt-für-Schritt-Anleitung in Python erstellen
- Die Grenzen dieses Ansatzes und wie man sie überwinden kann
Lassen Sie uns loslegen!
Was ist ein Amazon-Preis-Tracker?
Ein Amazon-Preis-Tracker ist ein Tool, ein Dienst oder ein Skript, mit dem Sie den Preis eines oder mehrerer Amazon-Produkte über einen bestimmten Zeitraum hinweg überwachen können. Er liefert regelmäßig Updates zu Preisänderungen, sodass Sie Preissenkungen, Rabatte oder Schwankungen erkennen können.
Warum sollte man den Preis eines Amazon-Artikels verfolgen?
Die Verfolgung von Amazon-Preisen hilft Ihnen dabei
- Geld zu sparen, indem Sie Produkte zum niedrigsten Preis kaufen
- Käufe während Sonderangeboten oder Werbeaktionen zeitlich zu planen
- Wettbewerbsfähige Preise für Ihre Produkte festzulegen, wenn Sie Verkäufer sind
Darüber hinaus ist die Preisüberwachung von Amazon unerlässlich, um saisonale Trends zu beobachten und die Marktdynamik zu verstehen.
Erstellen eines Amazon-Preis-Trackers: Schritt-für-Schritt-Anleitung
In diesem Tutorial-Abschnitt erfahren Sie, wie Sie mit Python einen Amazon-Preis-Tracker erstellen. Befolgen Sie die folgenden Schritte, um einen Scraping-Bot zu erstellen, der:
- eine Verbindung zu den Amazon-Seiten bestimmter Produkte herstellt
- Preisdaten von diesen Seiten scrapt
- Preisänderungen im Laufe der Zeit verfolgt
Wenn Sie auch an anderen Daten interessiert sind, lesen Sie unsere Anleitung zum Scrapen von Amazon-Produktdaten.
Zeit, ein Amazon-Preisverfolgungsskript zu implementieren!
Schritt 1: Projekt einrichten
Bevor Sie beginnen, stellen Sie sicher, dass Python 3+ auf Ihrem Computer installiert ist. Falls nicht, laden Sie es von der offiziellen Website herunter und befolgen Sie die Installationsanweisungen.
Erstellen Sie dann mit diesem Befehl ein Verzeichnis für Ihr Amazon-Preisverfolgungsprojekt:
mkdir amazon-price-tracker
Navigieren Sie in dieses Verzeichnis und richten Sie darin eine virtuelle Umgebung ein:
cd amazon-price-tracker
python -m venv venv
Öffnen Sie den Projektordner in Ihrer bevorzugten Python-IDE. Visual Studio Code mit der Python-Erweiterung oder PyCharm Community Edition sind beide eine gute Wahl.
Erstellen Sie eine Datei namens scraper.py im Projektordner, der nun folgende Dateistruktur aufweisen sollte:
scraper.py enthält die Logik zur Verfolgung der Amazon-Preise.
Aktivieren Sie die virtuelle Umgebung im Terminal Ihrer IDE. Unter Linux oder macOS verwenden Sie:
./venv/bin/activate
Unter Windows führen Sie stattdessen folgenden Befehl aus:
venv/Scripts/activate
Großartig! Sie sind nun eingerichtet und können loslegen.
Schritt 2: Konfigurieren Sie die Scraping-Bibliotheken
Wie in unserem Leitfaden zum Scraping von E-Commerce-Websites erläutert, erfordert das Scraping von Amazon ein Browser-Automatisierungstool. Das liegt nicht daran, dass die Website besonders dynamisch ist, sondern daran, dass Amazon Anti-Bot-Maßnahmen einsetzt, um automatisierte Anfragen zu erkennen und zu blockieren.
Einfach ausgedrückt benötigen Sie ein Browser-Automatisierungstool wie Selenium, um Daten von Amazon abzurufen. Installieren Sie Selenium zunächst wie folgt:
pip install selenium
Wenn Sie mit dieser Bibliothek nicht vertraut sind, lesen Sie unser Tutorial zum Selenium-Web-Scraping.
Importieren Sie die Selenium-Bibliothek in Ihr scraper.py -Skript:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
Erstellen Sie als Nächstes ein ChromeDriver -Objekt, um eine Chrome-Browserinstanz zu steuern:
# Initialisieren Sie den WebDriver zur Steuerung von Chrome.
driver = webdriver.Chrome(service=Service())
# Scraping-Logik...
# Geben Sie die Treiberressourcen frei.
driver.quit()
driver wird verwendet, um mit der Amazon-Produktseite zu interagieren und Preise zu verfolgen.
Beachten Sie, dass Amazon Anti-Scraping-Maßnahmen einsetzt, die Headless-Browser blockieren können. Um Probleme zu vermeiden, lassen Sie Ihren Selenium-gesteuerten Browser im Headed-Modus.
Großartig! Jetzt ist es an der Zeit, Ihre Amazon-Scraping-Logik zu automatisieren.
Schritt 3: Verbindung zur Zielseite herstellen
Angenommen, Sie möchten den Preis der PS5 auf Amazon verfolgen:
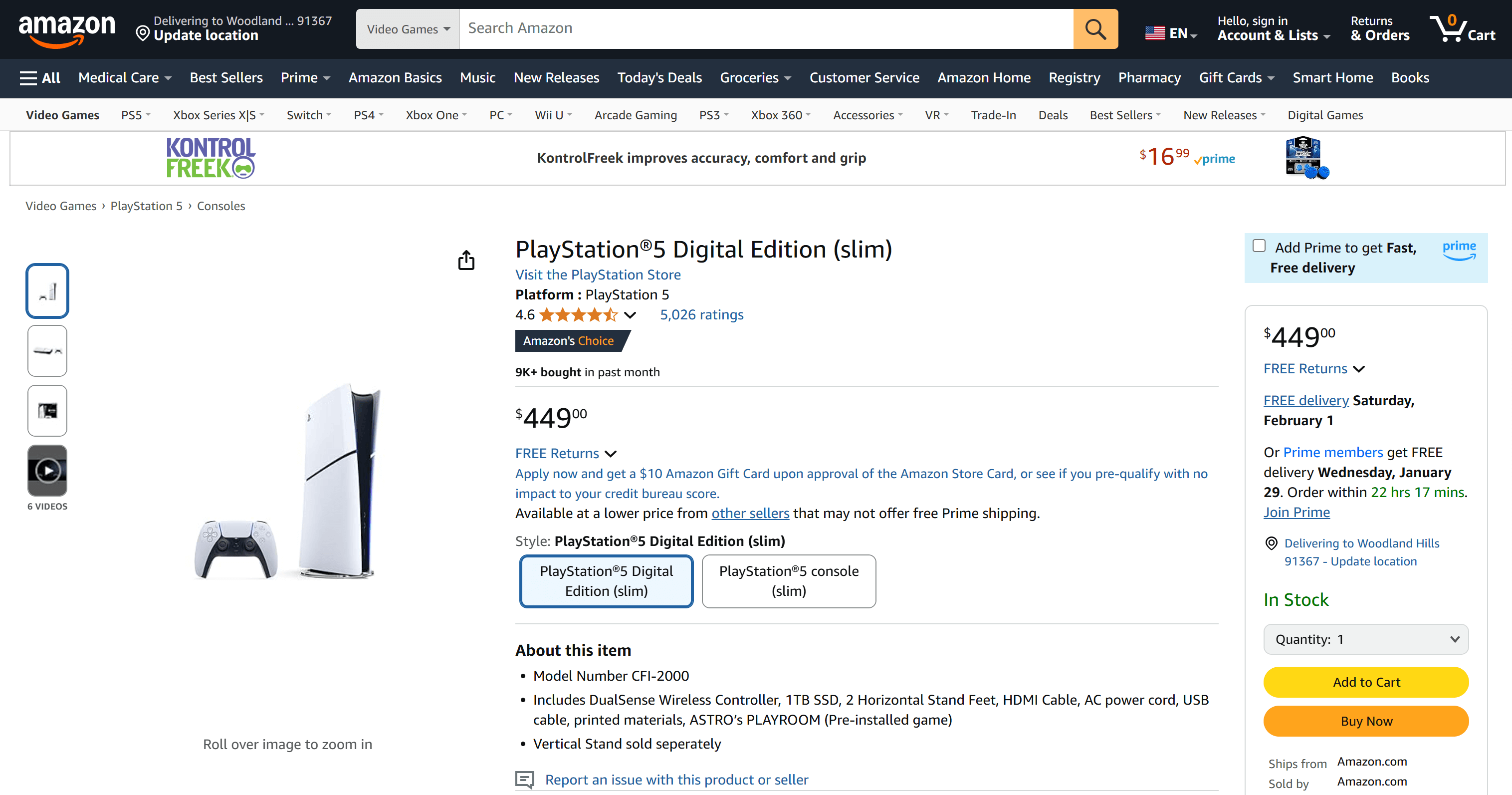
Hier ist die URL der Produktseite:
https://www.amazon.com/PlayStation%C2%AE5-Digital-slim-PlayStation-5/dp/B0CL5KNB9M/
Der Teil nach amazon.com ist nur ein Slug zur besseren Lesbarkeit, aber der wichtige Teil ist der Code nach /dp/. Dieser Code wird als Amazon ASIN bezeichnet, eine eindeutige Kennung für Amazon-Produkte.
Mit anderen Worten: Sie können direkt über die ASIN im folgenden Format auf dieselbe Produktseite zugreifen:
https://www.amazon.com/product/dp/<AMAZON_ASIN>
In diesem Beispiel lautet die ASIN für die PS5 B0CL5KNB9M. Speichern Sie diese ASIN in einer Variablen und verwenden Sie sie, um die Amazon-Produkt-URL zu generieren:
amazon_asin = "B0CL5KNB9M"
amazon_url = f"https://www.amazon.com/product/dp/{amazon_asin}"
Verwenden Sie anschließend die Methode get() von Selenium, um den Browser anzuweisen, zur Zielseite zu navigieren:
driver.get(amazon_url)
Setzen Sie einen Haltepunkt vor der Anweisung driver.quit() und führen Sie dann das Skript aus. Nun sollte die Amazon-Produktseite im Browser geladen sein:
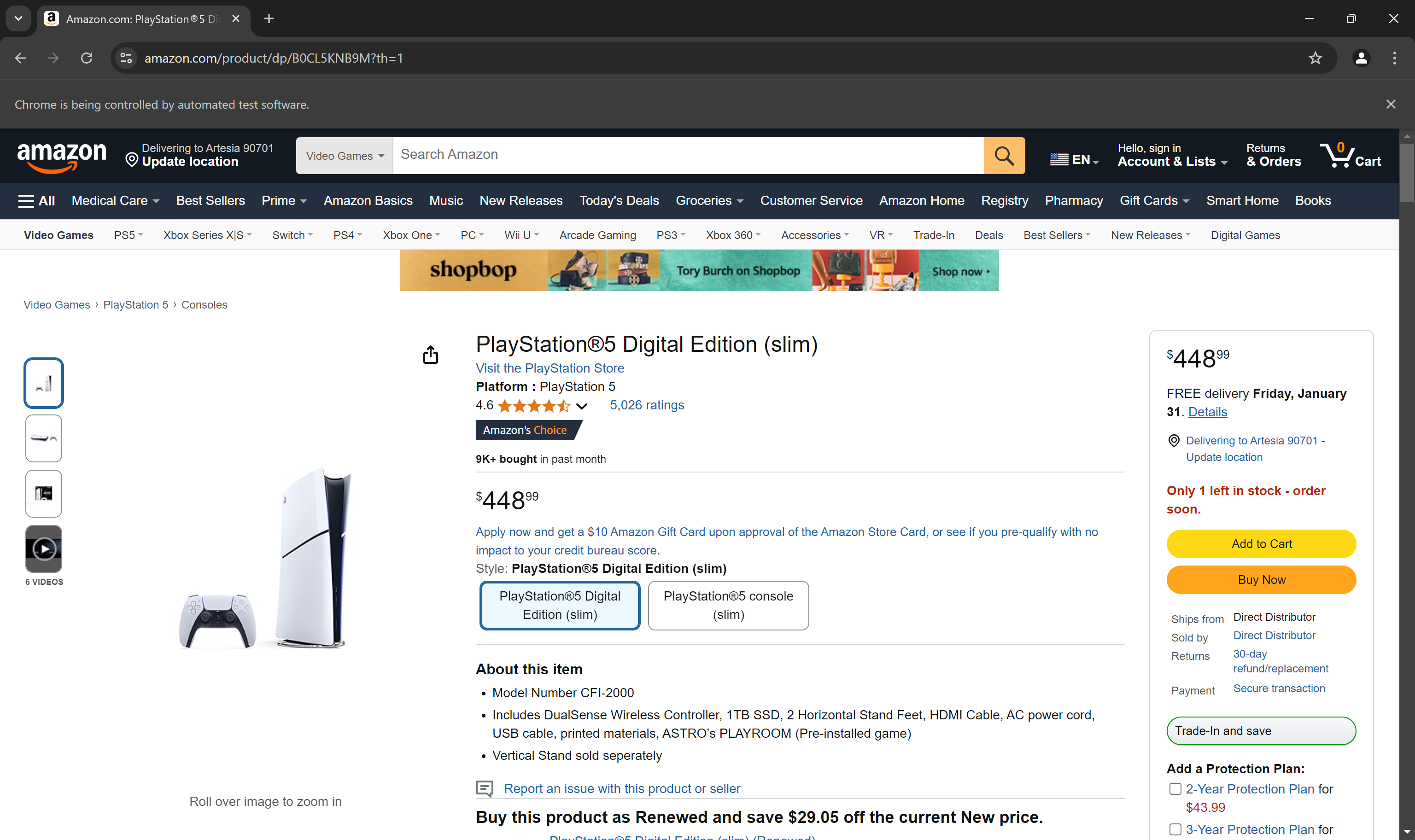
Die Meldung „Chrome wird von automatisierter Software gesteuert“ belegt, dass Selenium wie gewünscht im Browser ausgeführt wird.
Beachten Sie, dass Amazon Anti-Bot-Maßnahmen einsetzt, die zu CAPTCHA-Herausforderungen oder blockierten Anfragen führen können. Keine Sorge, wir werden später in diesem Artikel Strategien zur Bewältigung dieser Probleme besprechen.
Erfahren Sie hier mehr über den Amazon ASIN Scraper von Bright Data.
Schritt 4: Scrapen Sie die Preisinformationen
Öffnen Sie die Zielproduktseite in Ihrem Browser im Inkognito-Modus. Klicken Sie dann mit der rechten Maustaste auf den auf der Seite angezeigten Preis und wählen Sie die Option „Untersuchen“:
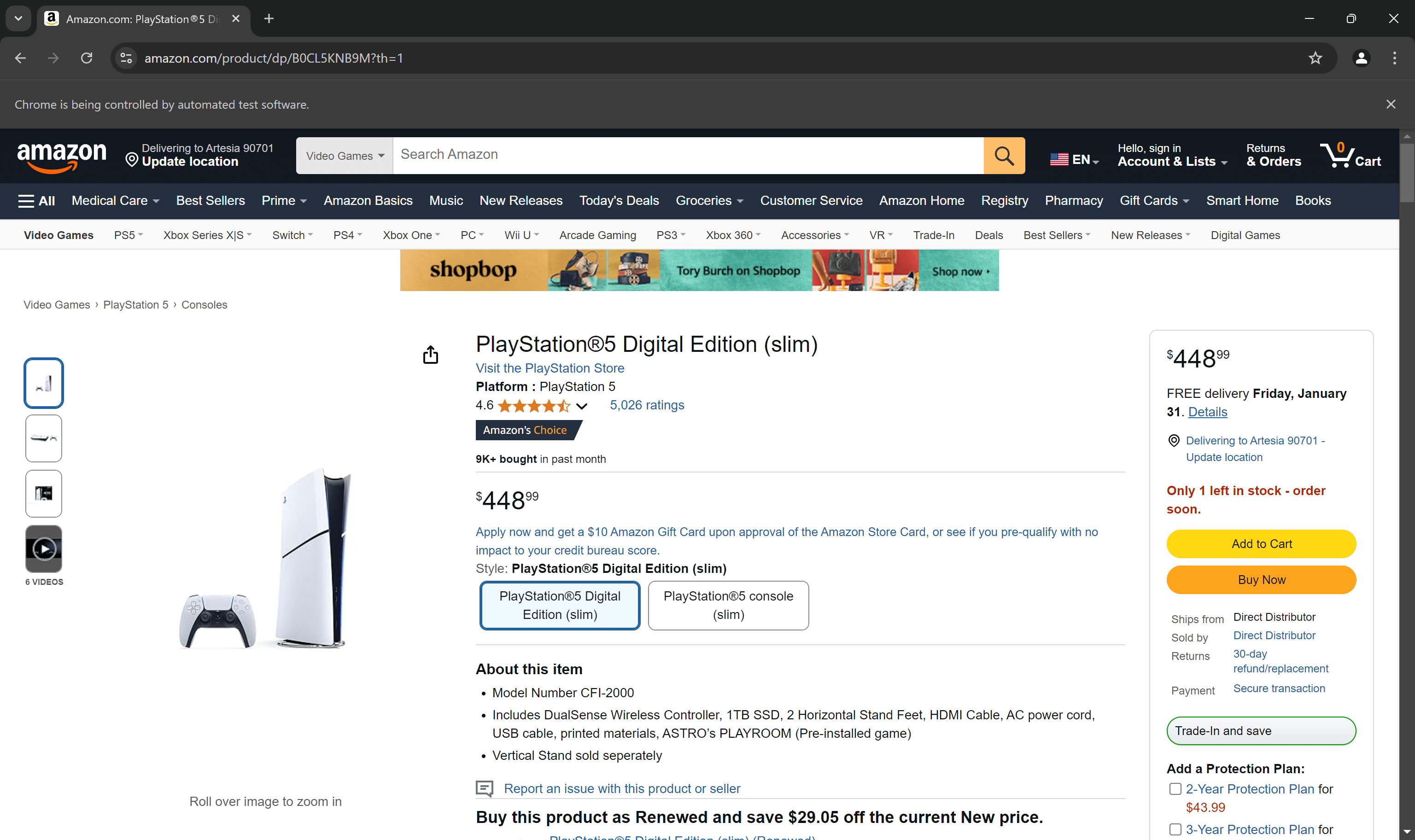
Sehen Sie sich im Abschnitt „DevTools“ den HTML-Code des Preiselements an. Beachten Sie, dass sich der Preis innerhalb eines .a-price-Elements befindet.
Wählen Sie das Element mit einem CSS-Selektor aus und extrahieren Sie die Daten daraus:
price_element = driver.find_element(By.CLASS_NAME, "a-price")
price = price_element.text.replace("n", ".")
Die Funktion replace() wird verwendet, um den Preis von Zeilenumbruchzeichen zu bereinigen.
Vergessen Sie nicht, By zu importieren:
from selenium.webdriver.common.by import By
Großartig! Sie haben die wichtigste Funktion Ihres Amazon Price Trackers erfolgreich implementiert – das Scraping des Preises.
Schritt 5: Speichern Sie die Preise
Die herausragende Funktion eines Amazon-Preis-Trackers ist die Möglichkeit, die Preisentwicklung zu verfolgen, sodass Sie Veränderungen und Schwankungen im Laufe der Zeit bewerten können. Dazu müssen Sie die Preisdaten irgendwo speichern, beispielsweise in einer Datenbank oder einer Datei.
Der Einfachheit halber verwenden wir eine JSON-Datei als Datenbank. Die Datei speichert die ASIN des Produkts und eine Liste der historischen Preise.
Stellen Sie zunächst sicher, dass die JSON-Datei mit der folgenden Struktur vorhanden ist:
{
"asin": "<AMAZON_ASIN>",
"prices": []
}
So initialisieren Sie eine solche Datei in Python, wenn sie nicht vorhanden ist:
# JSON-Datenbankdateiname und Anfangsdaten
file_name = "price_history.json"
initial_data = {
"asin": amazon_asin,
"prices": []
}
# Schreiben Sie die JSON-DB-Datei, wenn sie nicht vorhanden ist
if not os.path.exists(file_name):
with open(file_name, "w") as file:
json.dump(initial_data, file, indent=4)
# Selenium-Logik...
Damit der obige Ausschnitt funktioniert, sind die folgenden beiden Importe erforderlich:
import os
import json
Laden Sie vor der Scraping-Logik die JSON-Datei, um auf die aktuellen Daten zuzugreifen:
# Öffnen Sie die JSON-Datei zum Lesen und Schreiben.
with open(file_name, "r+") as file:
# Laden Sie die aktuellen Preisdaten.
price_data = json.load(file)
# Scraping-Logik...
Fügen Sie nach dem Scraping des Preises den neuen Preis zusammen mit einem Zeitstempel zur Pre isliste hinzu:
price = price_element.text.replace("n", "")
# Aktueller Zeitstempel
timestamp = datetime.now().isoformat()
# Neuen Preisinformationspunkt hinzufügen
price_data["prices"].append({
"price": price,
"timestamp": timestamp
})
Fügen Sie den folgenden Import hinzu:
from datetime import datetime
Aktualisieren Sie abschließend die JSON-Datei:
# Verschieben Sie den Dateizeiger an den Anfang
file.seek(0)
# Überschreiben Sie die gescrapten Daten
json.dump(price_data, file, indent=4)
# Kürzen Sie die Datei, damit bei neuen Inhalten, die kürzer als das Original sind, die überschüssigen Daten gelöscht werden
file.truncate()
Fantastisch! Die Preisverfolgungslogik wurde implementiert.
Schritt 6: Planen Sie die Preisverfolgungslogik
Derzeit müssen Sie das Skript manuell ausführen, wenn Sie Amazon-Preise scrapen und verfolgen möchten. Das mag für den gelegentlichen Gebrauch funktionieren. Dennoch ist es viel effektiver, das Skript so zu automatisieren, dass es in regelmäßigen Abständen ausgeführt wird.
Dies erreichen Sie mit der Python-Bibliothek „schedule “. Diese bietet eine intuitive API für die Planung von Aufgaben in Python.
Installieren Sie die Bibliothek, indem Sie den folgenden Befehl in Ihrer aktivierten virtuellen Umgebung ausführen:
pip install schedule
Kapseln Sie dann Ihre gesamte Amazon-Preisverfolgungslogik in eine Funktion, die die ASIN als Parameter akzeptiert:
def track_price(amazon_asin):
# Gesamte Amazon-Preisverfolgungslogik...
Sie haben nun einen Python-Job, den Sie so planen können, dass er alle 12 Stunden ausgeführt wird:
# Sofort ausführen
amazon_asin="B0CL5KNB9M"
track_price(amazon_asin)
# Planen Sie dann den Job so, dass er alle 12 Stunden ausgeführt wird.
schedule.every(12).hours.do(track_price, amazon_asin=amazon_asin)
while True:
schedule.run_pending()
time.sleep(1)
Die while -Schleife stellt sicher, dass das Skript aktiv bleibt, um geplante Aufgaben zu verarbeiten.
Vergessen Sie nicht die folgenden beiden Importe:
import schedule
import time
Perfekt! Sie haben gerade den gesamten Prozess automatisiert und Ihr Skript in einen automatischen Amazon-Preis-Tracker verwandelt.
Schritt 7: Alles zusammenfügen
So sollte Ihr Python-Amazon-Preis-Tracker nun aussehen:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
import json
import os
from datetime import datetime
import schedule
import time
def track_price(amazon_asin):
# Initialize the WebDriver to control Chrome
driver = webdriver.Chrome(service=Service())
# Amazon-Produkt-URL generieren
amazon_url = f"https://www.amazon.com/product/dp/{amazon_asin}"
# JSON-DB-Dateiname und Anfangsdaten
file_name = "price_history.json"
initial_data = {
"asin": amazon_asin,
"prices": []
}
# JSON-DB-Datei schreiben, falls sie nicht existiert
if not os.path.exists(file_name):
with open(file_name, "w") as file:
json.dump(initial_data, file, indent=4)
# JSON-Datei zum Lesen und Schreiben öffnen
with open(file_name, "r+") as file:
# Aktuelle Preisdaten laden
price_data = json.load(file)
# Zur Zielseite navigieren
driver.get(amazon_url)
# Preis scrapen
price_element = driver.find_element(By.CSS_SELECTOR, ".a-price")
price = price_element.text.replace("n", ".")
# Aktueller Zeitstempel
timestamp = datetime.now().isoformat()
# Neuen Preisinformationspunkt hinzufügen
price_data["prices"].append({
"price": price,
"timestamp": timestamp
})
# Dateizeiger an den Anfang verschieben
file.seek(0)
# Die gescraped Daten überschreiben
json.dump(price_data, file, indent=4)
# Die Datei kürzen, damit bei neuen Inhalten, die kürzer als das Original sind, die überschüssigen Daten gelöscht werden.
file.truncate()
# Die Treiberressourcen freigeben
driver.quit()
# Sofort ausführen
amazon_asin="B0CL5KNB9M"
track_price(amazon_asin)
# Dann den Job so planen, dass er alle 12 Stunden ausgeführt wird
schedule.every(12).hours.do(track_price, amazon_asin=amazon_asin)
while True:
schedule.run_pending()
time.sleep(1)
Starten Sie es wie folgt:
python3 Scraper.py
Oder unter Windows:
python Scraper.py
Lassen Sie das Skript mehrere Stunden lang laufen. Das Skript generiert eine Datei „price_history.json”, die in etwa wie folgt aussieht:
{
"asin": "B0CL5KNB9M",
"prices": [
{
"price": "$449.00",
"timestamp": "2026-01-27T08:02:20.333369"
},
{
"price": "$449.00",
"timestamp": "2026-01-27T20:02:20.935339"
},
{
"price": "$449.00",
"timestamp": "2026-01-28T08:02:21.109284"
},
{
"price": "$449.00",
"timestamp": "2026-01-28T20:02:21.385681"
},
{
"price": "$449.00",
"timestamp": "2026-01-29T08:02:22.123612"
}
]
}
Beachten Sie, dass jeder Eintrag im Array „preise” genau 12 Stunden nach dem vorherigen Eintrag aufgezeichnet wird.
Mission abgeschlossen!
Schritt 8: Nächste Schritte
Sie haben gerade einen funktionsfähigen Amazon-Preis-Tracker erstellt, aber es gibt noch Verbesserungspotenzial, um ihn auf die nächste Stufe zu heben. Mögliche Verbesserungen sind:
- Protokollierung hinzufügen: Wie bei jedem unbeaufsichtigten Prozess ist es wichtig zu verstehen, was gerade passiert. Fügen Sie dazu eine Protokollierung hinzu, um die Aktionen des Skripts zu verfolgen.
- Verwenden Sie eine Datenbank: Ersetzen Sie die JSON-Datei durch eine Datenbank, um Daten zu speichern. Dies erleichtert die Freigabe und den Zugriff auf die Preisentwicklung von mehreren Geräten oder Anwendungen aus.
- Implementieren Sie eine Fehlerbehandlung: Fügen Sie eine robuste Fehlerbehandlung hinzu, um Anti-Bot-Maßnahmen, Netzwerk-Timeouts und unerwartete Ausfälle zu verwalten. Stellen Sie sicher, dass das Skript bei Fehlern einen erneuten Versuch unternimmt oder den Vorgang ordnungsgemäß überspringt.
- Optionen aus der CLI lesen: Ermöglichen Sie dem Skript, Eingaben aus der Befehlszeile zu akzeptieren, z. B. die ASIN und Planungsoptionen. Dadurch wird es flexibler.
- Benachrichtigungssystem: Integrieren Sie Benachrichtigungen per E-Mail oder Messaging-Apps, um Sie über wichtige Preisänderungen zu informieren.
Einschränkungen dieses Ansatzes und wie man sie überwinden kann
Das im vorherigen Kapitel erstellte Amazon-Preisverfolgungsskript ist nur ein einfaches Beispiel. Sie können sich nicht langfristig auf ein so einfaches Skript verlassen, es sei denn, Sie führen die nächsten Schritte durch. Diese Schritte verbessern zwar das Skript, machen es aber auch komplexer und schwieriger zu verwalten.
Unabhängig davon, wie ausgefeilt Ihr Skript auch sein mag, Amazon kann es dennoch mit CAPTCHAs blockieren:
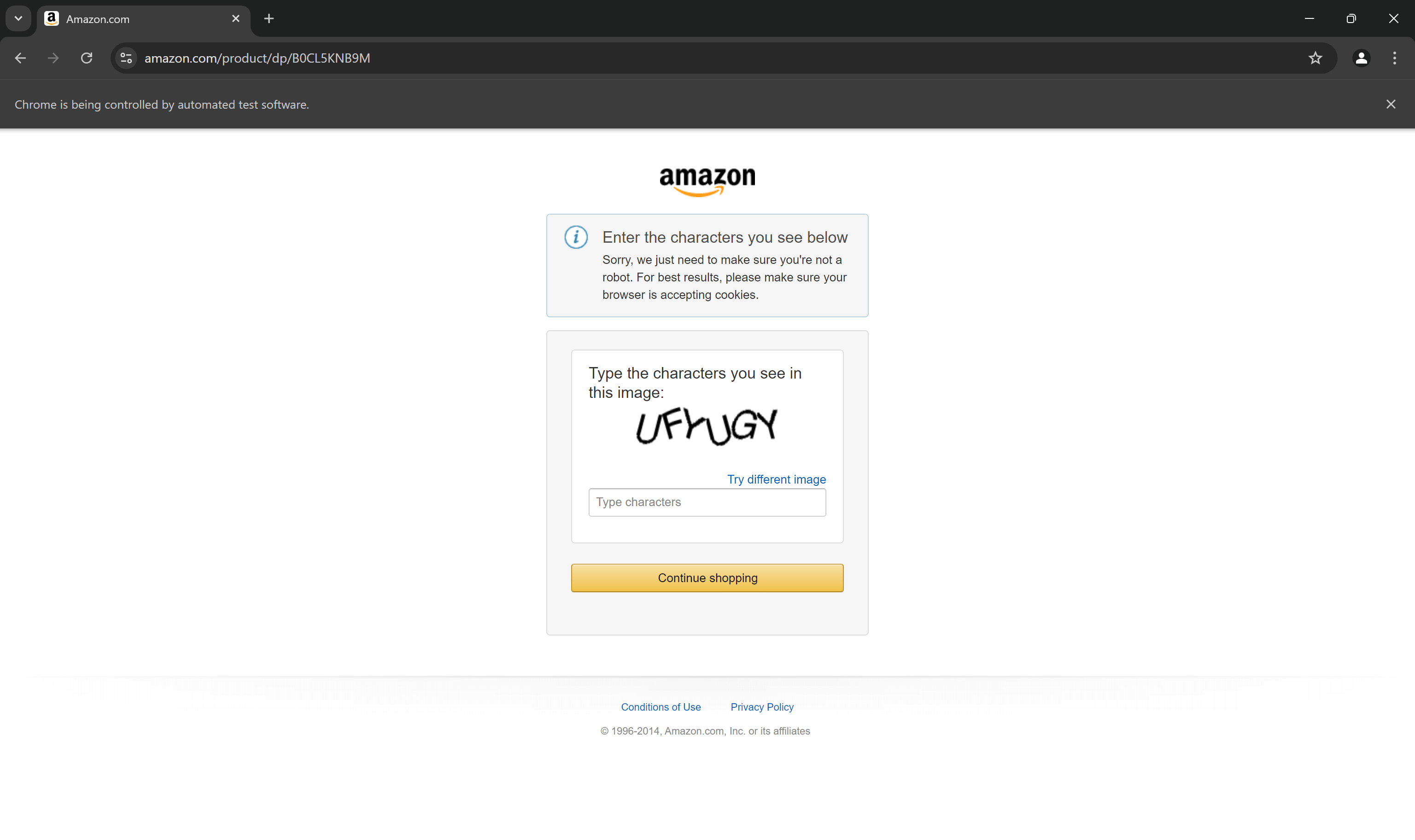
Tatsächlich ist es sehr wahrscheinlich, dass Ihr aktuelles Selenium-basiertes Amazon-Scraping-Skript bereits durch CAPTCHAs blockiert wird. Als ersten Schritt sollten Sie unsere Anleitung zum Umgehen von CAPTCHAs in Python befolgen.
Dennoch kann es aufgrund strenger Ratenbeschränkungen zu 429 Too Many Requests-Fehlern kommen. In solchen Fällen ist es eine gute Strategie, einen Proxy in Selenium zu integrieren, um Ihre Exit-IP zu rotieren.
Diese Herausforderungen zeigen, wie frustrierend das Scraping von Websites wie Amazon ohne die richtigen Tools sein kann. Darüber hinaus macht die Unmöglichkeit, Browser-Automatisierungstools zu verwenden, Ihr Skript langsam und ressourcenintensiv.
Sollten Sie also aufgeben? Keineswegs! Die wirkliche Lösung besteht darin, sich auf einen Dienst wie Bright Insights zu verlassen, der Ihnen umsetzbare, KI-gestützte E-Commerce-Erkenntnisse liefert, die Ihnen helfen
- Verlorene Einnahmen zu sparen: Identifizieren und beheben Sie Umsatzverluste aufgrund von Delistings, ausverkauften Artikeln oder Sichtbarkeitsproblemen.
- Verkäufe und Marktanteile zu verfolgen: Entdecken Sie ungenutzte Chancen, verfolgen Sie die Verkäufe Ihrer Mitbewerber und erkennen Sie Trends frühzeitig.
- Preise zu optimieren: Beobachten Sie die Preise Ihrer Mitbewerber in Echtzeit, um wettbewerbsfähig zu bleiben.
- Maximieren Sie Ihre Einzelhandelsmedien: Nutzen Sie Analysen, um Ihre Werbung zu optimieren, Ihren ROI zu maximieren und wachsende Ergebnisse sicherzustellen.
- Optimieren Sie Ihr Produktsortiment: Verbessern Sie Ihr Produktsortiment, indem Sie Wettbewerber verfolgen und Ihren Umsatz maximieren.
- Cross-Channel-Optimierung: Nutzen Sie Cross-Channel-Informationen, um den Produktverkauf zu steuern und auf allen Plattformen erfolgreich zu sein.
Bright Insights liefert Ihnen alle E-Commerce-Daten, die Sie benötigen, einschließlich Funktionen zur Preisverfolgung bei Amazon.
Fazit
In diesem Blogbeitrag haben Sie erfahren, was ein Amazon-Preis-Tracker ist und welche Vorteile er bietet. Außerdem haben Sie gesehen, wie Sie einen solchen Tracker mit Python und Selenium für das Web-Scraping erstellen können.
Die Herausforderung besteht darin, dass Amazon strenge Anti-Bot-Maßnahmen wie CAPTCHAs, Browser-Fingerprinting und IP-Sperren einsetzt, um automatisierte Skripte zu blockieren. Mit unserem Amazon-Preis-Tracker können Sie diese Herausforderungen jedoch vergessen und Amazon-Preise abrufen.
Wenn Sie sich für Web-Scraping interessieren und verschiedene Arten von Amazon-Daten nutzen möchten, sollten Sie auch unsere Amazon Scraper API in Betracht ziehen!
Erstellen Sie noch heute ein kostenloses Bright Data-Konto und entdecken Sie unsere Dienste.






