
Web-Scraper scheitern auf drei Arten: HTML ist leer, weil JavaScript die Seite rendert, CSS-Selektoren stimmen nach einem Frontend-Update nicht mehr überein, und Anfragen werden von Anti-Bot-Produkten wie Cloudflare blockiert. Scrapling ist eine Open-Source-Python-Bibliothek, die alle drei Probleme löst. Dieser Leitfaden zeigt jeden Teil anhand von Live-Websites und erläutert, wann ein verwalteter Proxy-Dienst im Produktionsmaßstab notwendig wird.
TL;DR
Scrapling kombiniert drei Fetcher-Klassen (HTTP, Chromium, Stealth-Firefox), einen adaptiven Parser, der Elemente nach Klassenumbenennungen wiederfindet, und einen Scrapy-ähnlichen Spider in einer Python-Bibliothek für produktionsreifes Web-Scraping.
- Wähle den günstigsten Fetcher, der funktioniert; eskaliere zu StealthyFetcher für bot-geschützte Seiten.
- Adaptive Selektoren erholen sich von Markup-Änderungen, wenn du zuerst eine bekannte Seite als Fingerprint speicherst.
- Für die Produktion verpacke die Parse-Logik in einen Spider mit Checkpointing und einem Alarm bei leeren Ergebnissen.
- Wenn lokales Stealth nicht mehr ausreicht (IP-Reputation, Enterprise-Anti-Bot-Produkte), wechsle zu Residential-Proxys oder einem verwalteten Unblocking-Endpunkt.
Warum Scrapling, wenn requests + BS4 bereits existiert?
Die Kombination aus requests und BeautifulSoup funktioniert nach wie vor für statische Seiten mit stabilem Markup. Die Probleme beginnen, sobald du einen Scraper einsetzt, der dauerhaft funktionieren muss.
Selektoren stimmen nicht mehr überein, wenn ein Frontend-Team Elemente umbenennt oder umstrukturiert. Seiten werden dieses Quartal serverseitig und nächstes Quartal clientseitig gerendert. Eine Website, die du seit einem Jahr gescrapt hast, fügt plötzlich Cloudflare Bot Management hinzu, und jede Anfrage gibt eine Challenge-Seite zurück.
Keines dieser Probleme ist ungewöhnlich, aber jedes erfordert seine eigene Lösung. Die Kombination dieser Lösungen in einem requests-Skript führt tendenziell zu einer fragilen Sammlung von try/except-Blöcken und Selektor-Fallbacks. (Für Jobs mit niedrigem Volumen, bei denen sich Selektoren häufig ändern, ist ein LLM-Extraktionsdurchlauf über das gerenderte HTML jetzt eine praktikable Alternative. Scrapling lohnt den Einrichtungsaufwand, wenn die Kosten pro Seite wichtig sind und du im großen Maßstab renderst.)
Scrapling fasst die gängigen Lösungen in einer Bibliothek zusammen:
- Drei Fetcher, eine API. Ein schneller HTTP-Client mit TLS-Fingerprint-Impersonation (Fetcher), ein Playwright-gesteuerter Browser (DynamicFetcher) und ein Stealth-Browser basierend auf Camoufox, einem gepatchten Firefox-Build, der gängige Automatisierungssignale maskiert (StealthyFetcher). Alle geben dasselbe Parser-Objekt zurück, sodass das Wechseln von Fetchern nicht bedeutet, den Selektor-Code neu zu schreiben.
- Selektoren, die Markup-Änderungen überleben. Speichere den strukturellen Fingerprint eines Elements beim ersten Durchlauf, und bei späteren Durchläufen kann Scrapling dasselbe Element finden, auch wenn sich Klassen, IDs oder Positionen geändert haben.
- Ein integriertes Spider-Framework. Parallele Anfragen, domänenspezifisches Throttling, Pause und Wiederaufnahme, robots.txt-Konformität und JSON/JSONL-Export – alles integriert.
- Proxy-Rotation integriert. Ein ProxyRotator-Helfer integriert sich in alle Sitzungstypen mit Überschreibungen pro Anfrage.
Die drei Fetcher entsprechen drei Schwierigkeitsstufen, sodass die Entscheidung, welchen zu verwenden, normalerweise offensichtlich ist, sobald du das Ziel überprüfst:
| Wenn die Seite… | Verwende diesen Fetcher | Kosten pro Anfrage (Zeit, Speicher) |
|---|---|---|
| Statisches HTML, kein Anti-Bot | Fetcher | Millisekunden, kein Browser |
| JavaScript-gerendert, kein Anti-Bot | DynamicFetcher | Sekunden, Chromium-Speicher |
| Hinter Cloudflare oder ähnlichem Anti-Bot | StealthyFetcher | Sekunden, Camoufox-Speicher |
Scrapling’s Parser ist ungefähr so schnell wie Parsel und lxml und schneller als BeautifulSoup für große Dokumente. Für ein Dokument mit 5.000 Elementen zeigen die offiziellen Benchmarks etwa 2 ms gegenüber über 1,5 Sekunden für bs4 + lxml. Im kleinen Maßstab kaum relevant, aber bei Millionen von Seiten pro Monat summiert es sich.
Bevor du eine Scraping-Bibliothek auswählst, prüfe kurz: Bietet das Ziel eine offizielle API, einen RSS- oder Atom-Feed, eine Sitemap, ein JSON-LD-Embed oder einen öffentlichen Datendump? Wenn diese existieren, ist ein API-Aufruf in der Regel schneller und günstiger als Web-Scraping. Scraping ist die richtige Antwort, wenn es keine API gibt, wenn die API kostenpflichtig oder stärker ratenlimitiert ist, als der Anwendungsfall sich leisten kann, oder wenn die benötigten Daten nicht über die API zugänglich sind.
Scrapling ist nicht für alles das richtige Werkzeug:
- Im verteilten Cluster-Maßstab skalieren Scrapy-Cluster und framework-spezifische verteilte Runner besser.
- Für curl-äquivalente Scrapes, die requests und ein 5-zeiliger BeautifulSoup-Selektor bereits erledigen, verwende diese.
- Wenn du einen verwalteten Scraper ohne Code benötigst, ist eine No-Code-Plattform besser geeignet.
Die stärkste Eignung ist der Produktions-Scraper, der Woche für Woche weiter funktionieren muss: komplex genug, dass Wartung wichtig ist, aber nicht so umfangreich, dass ein Cluster benötigt wird.
Scrapling ist BSD-3-lizenziert; dieser Leitfaden wurde gegen v0.4.7 (April 2026) verifiziert. Die im Leitfaden verwendeten API-Namen sind stabil; überprüfe das Changelog für neuere Versionen, wenn deine Standardwerte abweichen. Typ-Hints decken die öffentliche API ab, was wichtig ist, wenn du Antworten durch eine typisierte Pipeline leitest.
Scrapling installieren
Die Fetcher-Abhängigkeiten sind ein explizites Opt-in, sodass Playwright und Camoufox nicht auf einem Rechner installiert werden, der nur den Parser benötigt. Installiere mit den Fetcher-Extras und den Browser-Binaries:
# pip
pip install "scrapling[fetchers]"
# oder mit uv (schneller, lockfile-bewusst)
uv pip install "scrapling[fetchers]"
scrapling installDer erste Befehl installiert die Bibliothek sowie HTTP- und Browser-Fetcher. Der zweite lädt die Browser-Binaries herunter (Camoufox für StealthyFetcher, Chromium für DynamicFetcher) zusammen mit den benötigten Systemabhängigkeiten. Unter Windows führe das Terminal beim ersten Mal als Administrator aus, damit die Binaries systemweit installiert werden können.
Um zu überprüfen, ob alles sauber installiert wurde:
from scrapling.fetchers import Fetcher
page = Fetcher.get('https://httpbin.org/headers')
print(page.status, page.json()['headers']['User-Agent'])Eine funktionierende Installation gibt 200 und einen Chrome-ähnlichen User-Agent-String aus. Wenn der User-Agent stattdessen wie python-requests/x.x aussieht, führst du den nur-Parser-Build aus; installiere mit dem [fetchers]-Extra neu, damit pip auch curl_cffi installiert (die Bibliothek, die die TLS-Impersonation von Fetcher bereitstellt).
Zwei weitere Extras sind wissenswert:
- scrapling[shell] fügt eine interaktive IPython-Shell (scrapling shell), einen curl-zu-Scrapling-Konverter und eine scrapling extract-CLI hinzu, um Inhalte in einer Zeile vom Terminal abzurufen. Zum Beispiel schreibt scrapling extract get https://example.com out.md die Seite (oder eine CSS-Selektor-Teilmenge davon) als Markdown.
- scrapling[all] installiert alles, einschließlich des MCP (Model Context Protocol)-Servers für KI-Agenten-Integrationen; siehe die Projektdokumentation.
scrapling[fetchers] deckt alle nachfolgenden Beispiele ab.
Dein erster Scrape: Zitate von einer statischen Seite extrahieren
Die Standard-Sandbox ist quotes.toscrape.com, die zehn Zitate pro Seite in einfachem server-gerendertem HTML darstellt. Es gibt kein JavaScript, kein Anti-Bot und kein Ratenlimit, daher ist es ein guter erster Test für den Fetcher-Pfad:
from scrapling.fetchers import Fetcher
page = Fetcher.get('https://quotes.toscrape.com/', stealthy_headers=True)
for quote in page.css('.quote'):
text = quote.css('.text::text').get()
author = quote.css('.author::text').get()
tags = quote.css('.tag::text').getall()
print(f"{author}: {text[:60]}... [{', '.join(tags)}]")Fetcher.get() gibt ein Response-Objekt zurück, das auch als Parser-Handle fungiert. Das Setzen von stealthy_headers=True veranlasst Scrapling, realistische Browser-Header zu senden, einschließlich User-Agent, Accept, Accept-Language und sec-ch-ua, anstatt eines Standard-python-requests-Header-Sets. Bei einer Sandbox unnötig, aber Produktionsseiten filtern oft auf Header-Konsistenz.
page.css(‘.quote’) gibt einen Selectors-Container aller übereinstimmenden Elemente zurück. Das ::text-Pseudo-Element ist eine Scrapy/Parsel-Konvention, die den Textknoten direkt extrahiert, anstatt des umgebenden Tags.
Die Ausgabe sieht so aus:
Albert Einstein: "The world as we have created it is a process of our t... [change, deep-thoughts, thinking, world]
J.K. Rowling: "It is our choices, Harry, that show what we truly are,... [abilities, choices]
Albert Einstein: "There are only two ways to live your life. One is as t... [inspirational, life, live, miracle, miracles]
...Wenn du Scrapy bereits verwendet hast, ist die API absichtlich vertraut. Wenn du BeautifulSoup verwendet hast, hat Scrapling auch find_all und find_by_text:
quotes = page.find_all('div', class_='quote')
einstein = page.find_by_text('Einstein', partial=True)Ein echtes Ziel scrapen: die Hacker News Startseite
Sandbox-Seiten dienen nur der Übung. Dieselbe Code-Struktur funktioniert bei echten Zielen, mit zwei Änderungen: Selektoren werden durch Inspektion des tatsächlichen Markups gewonnen, und die Daten benötigen mehr Bereinigung. Hacker News ist ein nützliches erstes echtes Ziel (stabiles HTML, kein Anti-Bot) und sein Layout hat eine ungewöhnliche Struktur: Jede Story ist eine \-Zeile, mit den Metadaten (Punkte, Benutzer, Alter) in der unmittelbar folgenden Geschwister-Zeile. Der Scraper:
from scrapling.fetchers import Fetcher
page = Fetcher.get('https://news.ycombinator.com/', stealthy_headers=True)
stories = []
for athing in page.css('tr.athing'):
title = athing.css('.titleline a::text').get()
href = athing.css('.titleline a::attr(href)').get()
rank = athing.css('.rank::text').get()
# Metadaten befinden sich in der nächsten Geschwister-Zeile
subline = athing.next.css('.subline')
points_text = subline.css('.score::text').get() or '0 points'
user = subline.css('.hnuser::text').get()
age = subline.css('.age a::text').get()
stories.append({
'rank': int(rank.rstrip('.')) if rank else None,
'title': title,
'url': href,
'points': int(points_text.split()[0]),
'user': user,
'age': age,
'id': athing.attrib.get('id'),
})
print(f"scraped {len(stories)} stories")
for s in stories[:3]:
print(f" {s['rank']}. [{s['points']:>4}] {s['title'][:55]} by {s['user']}")Der Ausschnitt verwendet drei Muster, die die Sandbox-Beispiele nicht zeigen:
- athing.next navigiert zum nächsten Geschwister-Element, nützlich wenn strukturell verwandte Zeilen Daten teilen (ein häufiges Muster in älterem tabellenbasiertem Markup).
- .attrib.get(‘id’) liest ein rohes HTML-Attribut, wenn es keine praktische ::attr()-Abkürzung gibt.
- Der or ‘0 points’-Standardwert deckt Job-Postings ab, die auf der Hacker News Startseite ohne Punktestand erscheinen.
Echte Ziele haben fast immer diese kleinen Unregelmäßigkeiten (fehlende Felder, gemischte Elementtypen, gelegentlich fehlerhafte Zeilen). Passe Selektoren an und füge kleine Standardwerte hinzu; die Struktur des Codes bleibt dieselbe.
Scraper ohne Selektoren schreiben mit find_similar
Manchmal muss man den Zeilen-Selektor gar nicht selbst schreiben. Starte vom sichtbaren Text, navigiere zum richtigen Container und lass Scrapling jedes strukturell ähnliche Element finden:
sample = page.find_by_text("1.") # das Rang-Label bei Story #1
row = sample.find_ancestor(lambda e: e.tag == "tr") # nach oben zur Story-Zeile navigieren
peers = row.find_similar() # jede ähnliche Zeile finden
print(f"Found {len(peers) + 1} story rows without writing a CSS selector for the row")Auf der Live-Startseite gibt dies 30 aus (jede Story-Zeile, gefunden durch strukturelle Ähnlichkeit mit der Ausgangsstory). find_similar nimmt einen optionalen similarity_threshold (Standard 0.2; niedrigere Werte bedeuten eine strengere strukturelle Übereinstimmung) und eine ignore_attributes-Liste (standardmäßig href und src), damit URL-Unterschiede die Übereinstimmung nicht verhindern. Für Seiten, bei denen sich das Markup schneller ändert als Selektoren gewartet werden können, hält die Kombination aus find_by_text und find_similar besser stand als das Nachverfolgen von Klassennamen.
Tabellen extrahieren: Länderdaten von Wikipedia
Tabellen sind eine weitere häufige Form von realen Daten: Finanzkennzahlen, Sportergebnisse, Referenzlisten. Wikipedia stellt seine Datentabellen unter einer einzigen table.wikitable-Klasse bereit, die in der gesamten Enzyklopädie konsistent ist, sodass dasselbe Selektormuster fast überall funktioniert. Der Länder-Bevölkerungs-Scrape:
from scrapling.fetchers import Fetcher
URL = 'https://en.wikipedia.org/wiki/List_of_countries_by_population_(United_Nations)'
page = Fetcher.get(URL, stealthy_headers=True)
table = page.css('table.wikitable')[0]
countries = []
for row in table.css('tbody tr'):
cells = row.css('td')
if len(cells) < 3: # Kopf- und Gruppierungszeilen überspringen
continue
name = cells[0].css('a::attr(title)').get()
pop_text = cells[1].text.strip()
if not name or not pop_text:
continue
countries.append({
'country': name,
'population': int(pop_text.replace(',', '')),
})
print(f"scraped {len(countries)} country rows")
top = sorted(countries, key=lambda c: c['population'], reverse=True)[:3]
for c in top:
print(f" {c['country']:<20} {c['population']:>15,}")Zwei Muster sind hier wichtig. cells[0].css(‘a::attr(title)’).get() extrahiert den Ländernamen aus dem title-Attribut des Links, was sauberer ist als .text, da es die Flaggen-Icon-Unordnung in derselben Zelle überspringt. Der if len(cells) < 3-Guard überspringt die unregelmäßigen Kopf- und Gruppierungszeilen, die in fast jeder HTML-Tabelle von Drittanbietern auftauchen.
Selektoren, die Website-Änderungen überleben
Eine Website benennt eine Klasse von .product-card in .product-tile um. Dein Scraper beginnt, leere Ergebnisse zurückzugeben. Du bemerkst es erst, wenn ein späterer Schritt in deiner Pipeline fehlende Daten meldet.
Scrapling’s Antwort ist eine Konfigurationsoption plus zwei Flags. Jedes tut eine Sache:
| Was du schreibst | Wann du es schreibst | Was es tut |
|---|---|---|
| selector_config={‘adaptive’: True} beim Fetcher-Aufruf | Immer (erster UND spätere Durchläufe) | Aktiviert die Funktion. Ohne dies ignoriert Scrapling die anderen beiden Flags stillschweigend. |
| auto_save=True bei .css() | Erster Durchlauf | Speichert den strukturellen Fingerprint des übereinstimmenden Elements (Tag, Attribute, Position, umgebender Text) in einer kleinen lokalen SQLite-Datei. |
| adaptive=True bei .css() | Spätere Durchläufe | Wenn der Selektor nichts zurückgibt, verwendet er den gespeicherten Fingerprint, um das Element erneut zu finden. |
Der Lebenszyklus, von Anfang bis Ende:
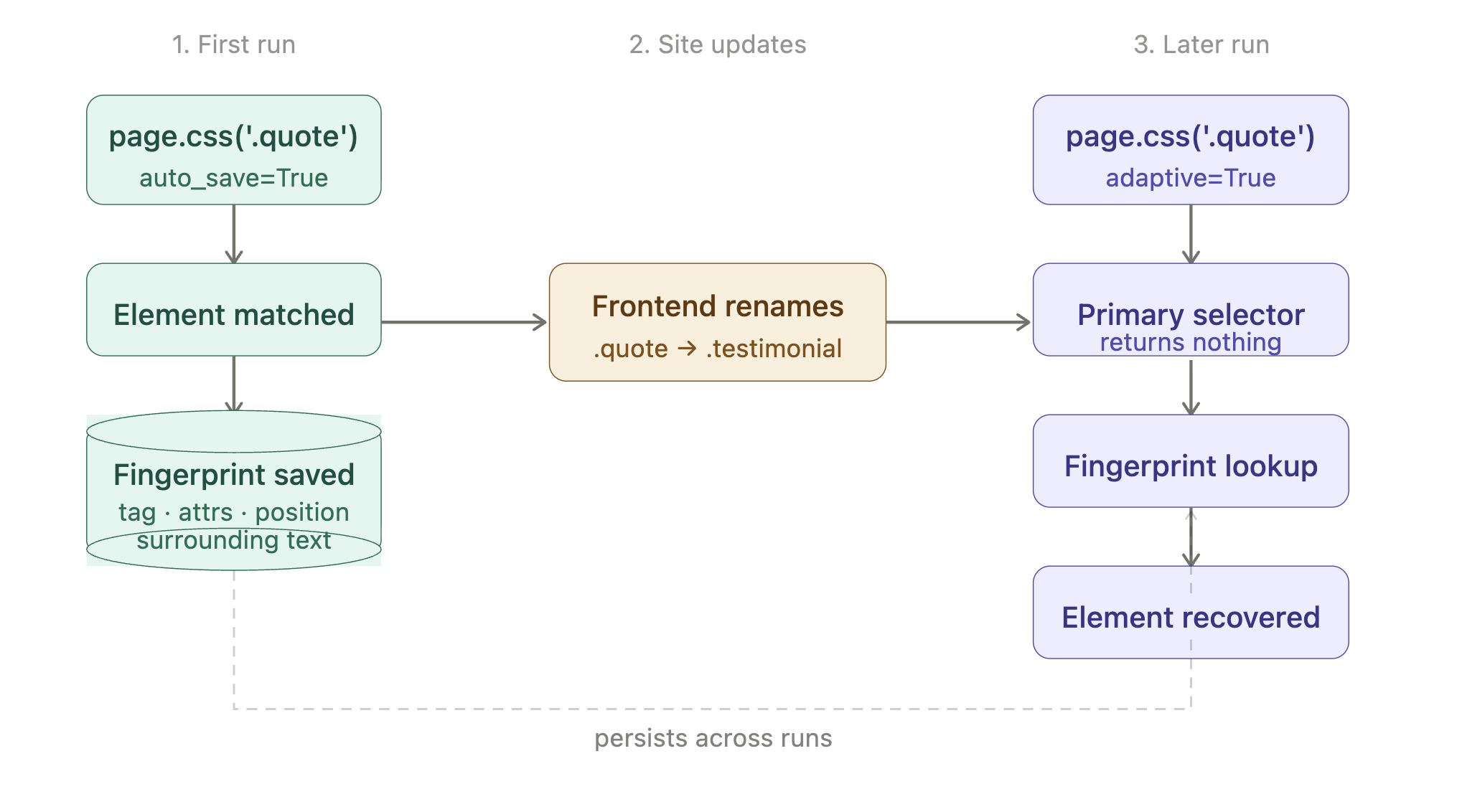
Im Code sieht das so aus:
from scrapling.fetchers import Fetcher
# Erster Durchlauf: adaptiv am Fetcher aktivieren, Fingerprints mit auto_save speichern
page = Fetcher.get(
'https://quotes.toscrape.com/',
selector_config={'adaptive': True},
)
quotes = page.css('.quote', auto_save=True)
print(f"Found {len(quotes)} quotes on first run")
# Späterer Durchlauf: gleicher Selektor, plus adaptive=True für den Fallback-Pfad.
# Wenn die Seite `.quote` umbenannt hat, stellt der Fingerprint die Elemente wieder her.
page = Fetcher.get(
'https://quotes.toscrape.com/',
selector_config={'adaptive': True},
)
quotes = page.css('.quote', adaptive=True)
print(f"Found {len(quotes)} quotes (recovered via fingerprint if needed)")Die Fingerprint-Datenbank wird neben deinem Skript gespeichert, sodass dasselbe Skript die gespeicherten Fingerprints über Durchläufe hinweg wiederverwendet. Das Muster funktioniert bei jedem Fetcher gleich: Übergib selector_config einmal beim Fetch-Aufruf, dann verwende auto_save und adaptive bei den .css()-Aufrufen.
Behandle die Fingerprint-Datei wie ein Migrations-Artefakt: Committe sie für reproduzierbare CI-Durchläufe, mounte sie als Volume in Docker, und führe auto_save=True niemals gegen eine Seite aus, die du nicht verifiziert hast. Eine mit auto_save gescrapte CAPTCHA-Wand vergiftet den Fingerprint, sodass spätere Durchläufe das falsche Element wiederherstellen. Lösche die Datei zum Zurücksetzen.
Einschränkung: Adaptives Matching funktioniert nur, wenn der Inhalt des Elements ungefähr stabil bleibt und sich nur das Markup ändert. Wenn die Website den gesamten Abschnitt durch eine andere Funktion ersetzt, kann kein Algorithmus ihn wiederherstellen. Halte Alarme für leere Ergebnismengen aktiv, damit du bemerkst, wenn sich eine Seite so verändert hat, dass der Fingerprint nicht damit umgehen kann.
JavaScript-gerenderte Seiten scrapen
Viele Seiten senden ein fast leeres HTML-Gerüst und rendern dann den eigentlichen Inhalt clientseitig. Die Standard-Testseite dafür ist quotes.toscrape.com/js, die dieselben Zitate wie die statische Version liefert, sie aber über JavaScript einfügt. Wenn du Fetcher darauf zeigst, ist das Ergebnis vorhersehbar:
from scrapling.fetchers import Fetcher
page = Fetcher.get('https://quotes.toscrape.com/js/')
print(page.css('.quote::text').getall())
# []Leer. Der Text ist in einer var data = […] JavaScript-Variable gespeichert, die der Browser beim Laden der Seite ausführt, und ein einfacher HTTP-Client führt dieses Skript nie aus. Die Lösung ist die Verwendung von DynamicFetcher, der intern eine echte Chromium-Instanz steuert:
from scrapling.fetchers import DynamicFetcher
page = DynamicFetcher.fetch(
'https://quotes.toscrape.com/js/',
headless=True,
network_idle=True,
)
for quote in page.css('.quote'):
print(quote.css('.text::text').get())Zwei Flags in diesem Ausschnitt sind wichtig. headless=True ist das, was du auf einem Server willst. network_idle=True wartet, bis die Netzwerkaktivität gestoppt ist, bevor der Parser die Seite liest, was die meisten JavaScript-gerenderten Seiten abdeckt. Bei hydratisierungslastigen SPAs (Next.js, Remix, SvelteKit) kann das Netzwerk idle werden, während React noch hydratisiert; übergib in diesen Fällen stattdessen oder zusätzlich wait_selector=”…” mit einem bekannten stabilen Element.
Sobald der Browser die Seite hat, ist der Rest der API identisch mit dem statischen Fetcher-Beispiel.
Jede Browser-Sitzung benötigt ungefähr 1 GB RAM (der Abschnitt zur Produktionsskalierung enthält die Aufschlüsselung). Für ein paar hundert Seiten pro Tag reicht ein 2-GB-Worker; jenseits von Zehntausenden pro Tag, verwende Browser über Anfragen hinweg mit DynamicSession wieder, oder verlagere die Arbeit auf einen verwalteten Scraping-Browser außerhalb deiner eigenen Server.
Anti-Bot-Abwehrmaßnahmen mit StealthyFetcher umgehen
Moderne Anti-Bot-Produkte wie Cloudflare Turnstile, DataDome und HUMAN Bot Defender (früher PerimeterX) prüfen Dutzende von Signalen, um festzustellen, ob eine Anfrage von einem echten Browser kommt. Die Liste umfasst TLS-Handshake-Fingerprints (JA3 und JA4 sind die gängigen Formate), HTTP/2-Frame-Reihenfolge, Navigator-Eigenschaften (navigator.webdriver, Plugin-Listen, Sprach-Header), Canvas- und WebGL-Hashes sowie Timing-Muster. Sobald diese statischen Prüfungen bestanden sind, übernimmt oft eine Verhaltensebene (Mausbewegungsentropie, Scroll-Kadenz, Verweildauer). Eine normale Playwright- oder Selenium-Sitzung legt standardmäßig mehrere dieser Signale offen, weshalb “Ich habe Playwright hinzugefügt und werde immer noch blockiert” eine häufige Frage in Scraping-Foren ist.
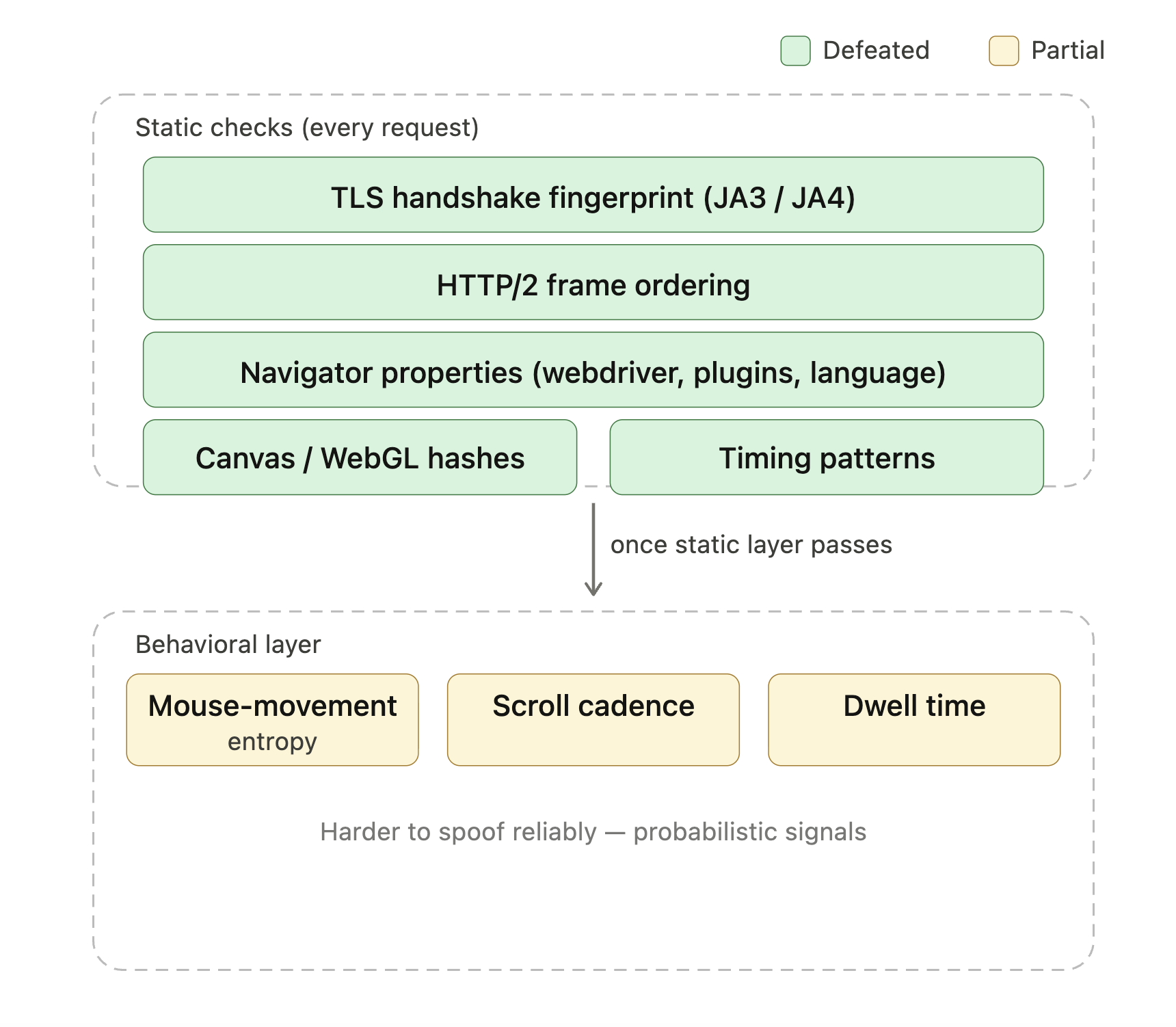
Grüne Schichten sind das, womit die Camoufox-Basis von StealthyFetcher selbst umgeht; gelb ist der Bereich, wo Verhaltens-Scoring einsetzt und verwaltetes Unblocking seinen Preis rechtfertigt.
StealthyFetcher verwendet Camoufox, einen gepatchten Firefox-Build, der gängige Automatisierungssignale maskiert, um die Headless-Browser- und Playwright-Fingerprints zu überwinden, nach denen diese Systeme suchen. Für Cloudflares leichtere Bot-Management-Stufen reicht das oft allein aus. Enterprise-Deployments, die Turnstile mit Verhaltens-Scoring kombinieren, blockieren lokale Stealth-Setups weiterhin; dort wird verwaltetes Unblocking zur praktischen Lösung (im Abschnitt zur Produktionsskalierung behandelt). Für Seiten, die explizit Turnstile-Challenges ausführen, hat Scrapling ein solve_cloudflare-Flag, das die Challenge automatisch löst:
from scrapling.fetchers import StealthyFetcher
page = StealthyFetcher.fetch(
'https://nopecha.com/demo/cloudflare',
headless=True,
solve_cloudflare=True,
network_idle=True,
)
links = page.css('#padded_content a::attr(href)').getall()
print(f"Found {len(links)} links past the challenge")Die Seite in diesem Beispiel ist eine öffentliche Cloudflare-Demo, die eine echte Turnstile-Challenge ausführt.
Einige reale Grenzen sind es wert, sich zu merken:
- Der solve_cloudflare-Pfad funktioniert für verwaltete Turnstile-Challenges. Er verspricht nicht, jede CAPTCHA-Kategorie zu behandeln. Bild-Raster-Challenges (älteres reCAPTCHA, hCaptcha-Bild-Puzzles) benötigen entweder einen Drittanbieter-Solver-Dienst (2Captcha, CapSolver), der in eine Seitenaktion eingebunden ist, oder einen verwalteten Unblocking-Endpunkt, der die Challenge-Schicht vollständig verwaltet.
- Stealth-Bypass-Techniken ändern sich häufig. Plane regelmäßige Überprüfungen bei deinen echten Zielen, nicht ein einmaliges Setup.
- Die Ergebnisse hängen auch von der IP-Reputation ab. Eine Datacenter-IP, die bei einem Ziel bereits markiert ist, wird nicht erfolgreich sein, egal wie gut der Browser-Fingerprint ist.
Für Seiten, die kein Cloudflare verwenden, erhältst du die Stealth-Vorteile ohne den Challenge-Solver:
page = StealthyFetcher.fetch('https://example.com', headless=True)Die Standard-Fingerprinting-Schutzmaßnahmen gelten, und solve_cloudflare tut nichts, wenn es keine Challenge zu lösen gibt.
Ein Muster, das man kennen sollte: die versteckte Blockierung
Anti-Bot-Systeme geben manchmal ein 200 OK mit einer getarnten Blockierungsseite zurück (eine CAPTCHA-Wand, eine leere Ergebnisseite oder ein “Verifying you are human”-Interstitial) anstatt eines expliziten 403 oder 503. Eine Leergebnissprüfung (im produktionsreifen Skript gezeigt) fängt die offensichtlichen Fälle ab. Für versteckte Blockierungen, bei denen die Struktur intakt ist und nur die Daten falsch sind, solltest du eine inhaltliche Prüfung durchführen: Vergleiche die Antwortlänge mit einem Basiswert, suche nach verräterischen Zeichenfolgen (“captcha”, “are you human”, “access denied” im Body) oder überprüfe die erwarteten Felder eines bekannten stabilen Elements. Keine ist perfekt; zusammen fangen sie die meisten stillen Blockierungen ab, bevor schlechte Daten weiterverarbeitet werden.
Das Spider-Framework bietet einen is_blocked-Hook dafür: Überschreibe ihn (ebenfalls async def) und Scrapling wiederholt blockierte Antworten automatisch bis zu max_blocked_retries (Standard 3):
class MySpider(Spider):
max_blocked_retries = 5
async def is_blocked(self, response: Response) -> bool:
body = (response.body or b'').lower()
return b'are you human' in body or b'captcha' in bodyBlockierungs-Wiederholungszähler erscheinen in result.stats.blocked_requests_count nach dem Crawl. Verwende diesen Zähler als deine Produktions-Alert-Metrik.
Seiten hinter einem Login scrapen mit FetcherSession
Echte Ziele erfordern oft einen Login. Das Muster mit FetcherSession ist der Standard-CSRF-und-Cookie-Flow, den du mit requests + Session schreiben würdest, nur dass Scrapling’s Parser die Antwort verarbeitet. Die Quotes-to-Scrape-Sandbox enthält einen funktionierenden Login unter /login, was es zu einem einfachen Testfall macht:
from scrapling.fetchers import FetcherSession
with FetcherSession(impersonate='chrome') as session:
# 1. GET der Login-Seite um den CSRF-Token zu holen
login_page = session.get('https://quotes.toscrape.com/login')
csrf = login_page.css('input[name="csrf_token"]::attr(value)').get()
# 2. POST der Anmeldedaten. Cookies bleiben automatisch in der Sitzung erhalten.
session.post(
'https://quotes.toscrape.com/login',
data={'csrf_token': csrf, 'username': 'demo', 'password': 'demo'},
)
# 3. Eine Seite abrufen, die hinter dem Login gesperrt ist.
page = session.get('https://quotes.toscrape.com/')
if page.css('a[href="/logout"]').get():
print("Logged in OK")
# Eingeloggte Seiten in dieser Sandbox zeigen zusätzliche Goodreads-Links pro Zitat
print("first goodreads link:", page.css('a[href*="goodreads"]::attr(href)').get())Drei Dinge sind hier wichtig:
- Verwende eine Sitzung, keine einzelnen Fetcher.get()-Aufrufe. FetcherSession speichert Cookies (und alle Set-Cookie, die der Server zurückgibt) zwischen Anfragen; einzelne Fetcher.get()-Aufrufe teilen keinen Zustand.
- Lese den CSRF-Token aus dem Login-Formular. Die meisten modernen Frameworks enthalten einen und lehnen POST-Anfragen ohne ihn ab. Der Feldname variiert je nach Framework: Django verwendet csrfmiddlewaretoken, Rails verwendet authenticity_token, und viele SPAs senden den Token stattdessen in einem Header, also inspiziere das Formular, bevor du einen Namen annimmst.
- Verifiziere, dass der Login erfolgreich war, bevor du weiter machst. Prüfe auf einen Logout-Link, einen Benutzernamen in der Navigationsleiste oder das Fehlen eines Login-Formulars. Wenn der Login ohne Fehler scheitert und du die öffentliche Seite scrapst, erhältst du Daten, die korrekt aussehen, aber tatsächlich falsch sind.
Für Seiten mit 2FA, OAuth oder Login-Flows, die langlebige Tokens ausgeben, ist der einfachste Ansatz, sich einmal manuell einzuloggen (oder über die API der Seite), die resultierenden Cookies oder Token zu erfassen und wiederzuverwenden. FetcherSession akzeptiert ein cookies={…}-Dict bei der Erstellung, sodass du eine Sitzung aus gespeicherten Cookies befüllen kannst.
Gleichzeitige Fetches mit AsyncFetcher
Wenn du eine Liste von URLs hast und sie alle benötigst, serialisiert der synchrone Fetcher sie. AsyncFetcher stellt dieselbe API als Coroutine bereit, sodass du alle Anfragen gleichzeitig mit asyncio.gather ausgeben und mehrere Netzwerk-Round-Trips parallel laufen lassen kannst (dasselbe Muster wie asynchrones Scraping mit AIOHTTP, mit einem bereits angehängten Parser):
import asyncio
from scrapling.fetchers import AsyncFetcher
URLS = [f'https://quotes.toscrape.com/page/{i}/' for i in range(1, 11)]
async def fetch_all():
tasks = [AsyncFetcher.get(u, stealthy_headers=True) for u in URLS]
pages = await asyncio.gather(*tasks)
return [q.css('.text::text').get()
for p in pages for q in p.css('.quote')]
quotes = asyncio.run(fetch_all())
print(f"scraped {len(quotes)} quotes")Auf denselben 10 Zitat-Seiten reduziert dies einen sequenziellen 9-Sekunden-Fetch auf etwa 1 Sekunde bei einer typischen Heimverbindung. FetcherSession funktioniert selbst unter async with, sodass du Cookies und Header über asynchrone Aufrufe hinweg genauso wiederverwenden kannst wie in synchronem Code. Für vollständige Crawls mit Throttling, Dedup und Resume ist das Spider-Framework in der Regel die bessere Wahl. AsyncFetcher ist wichtig, wenn du eine bekannte Liste von URLs hast und sie einfach parallel abrufen möchtest.
Eine Falle: Nacktes asyncio.gather(\*tasks) wirft die erste Ausnahme sofort, aber die anderen Tasks laufen im Hintergrund weiter; du verlierst den Zugriff auf ihre Ergebnisse, ohne die Arbeit zu stoppen. Für Produktionslisten, bei denen du teilweise Erfolge willst, übergib return_exceptions=True und filtere die Ergebnisse, oder verwende asyncio.TaskGroup (3.11+), das Geschwister beim ersten Fehler abbricht und dir explizite Fehlerbehandlung pro Task gibt.
Einen mehrseitigen Crawler mit dem Spider-Framework bauen
Ein echter Scraping-Job ist selten eine einzelne Seite. Du folgst der Paginierung, folgst Produkt-Links, deduplizierst URLs, begrenzt Anfrage-Raten, schreibst alles auf die Festplatte und setzt nach Fehlern graceful fort. Scrapling bietet dafür ein Spider-Framework mit einer Spider/parse/yield-Form, die Scrapy-Nutzern vertraut sein wird. Spider, die sich nicht auf Scrapy’s Middlewares, Pipelines oder Signale stützen, können größtenteils mechanisch portiert werden; der Rest braucht Neuentwicklungen gegen Scrapling’s Hooks und die async-parse-Signatur.
Ein einfacher Crawler über books.toscrape.com, das einen fünfzigseitigen paginierten Katalog mit etwa tausend Büchern hat:
from scrapling.spiders import Spider, Response
class BooksSpider(Spider):
name = "books"
start_urls = ["https://books.toscrape.com/"]
concurrent_requests = 8
download_delay = 0.5 # Sekunden zwischen Anfragen pro Domain
async def parse(self, response: Response):
for book in response.css('article.product_pod'):
yield {
"title": book.css('h3 a::attr(title)').get(),
"price": book.css('.price_color::text').get(),
"rating": book.css('p.star-rating::attr(class)').get(),
"url": response.urljoin(book.css('h3 a::attr(href)').get()),
}
next_page = response.css('li.next a::attr(href)').get()
if next_page:
yield response.follow(next_page, callback=self.parse)
if __name__ == "__main__":
result = BooksSpider().start()
print(f"Scraped {len(result.items)} books")
result.items.to_jsonl("books.jsonl")Einige Dinge, die dieser Ausschnitt tut, die du sonst von Hand bauen würdest. concurrent_requests führt acht Anfragen gleichzeitig aus, was bei books.toscrape.com einen vollständigen Crawl von Minuten auf Sekunden reduziert. download_delay erzwingt eine domänenspezifische Lücke, damit du einen einzelnen Host nicht überlastest. response.follow() löst relative URLs gegen die aktuelle Seite auf, was einen der häufigsten Paginierungsfehler beseitigt (vergessen, einen relativen next-Link zu verbinden). Die async-parse-Signatur ermöglicht es dir, seiten-spezifische I/O durchzuführen (Detailseiten abrufen, externe APIs aufrufen) ohne die Crawl-Schleife zu blockieren.
Zwei Parser-Methoden sind es wert zu kennen. .re_first(pattern) auf einem .css()-Ergebnis gibt die erste Regex-Übereinstimmung zurück, nützlich um numerische Werte aus formatiertem Text zu extrahieren:
# wandelt '£51.77' in 51.77 in einem Ausdruck um
price = float(book.css('.price_color::text').re_first(r'[\d.]+'))Und der Selectors-Container, den .css() zurückgibt, hat eine .filter()-Methode, die ein Prädikat akzeptiert, sodass du die Daten, die Scrapling bereits hat, einschränken kannst, ohne eine zweite Schleife zu schreiben:
expensive = response.css('article.product_pod').filter(
lambda b: float(b.css('.price_color::text').re_first(r'[\d.]+')) >= 50
)
yield {'count_over_50': len(expensive)}Nützlich, wenn die Seite keinen URL-Filterparameter für das Feld bereitstellt, nach dem du filtern möchtest.
Der Export am Ende schreibt ein JSON-Objekt pro Zeile, was die meisten nachgelagerten Pipelines erwarten. Du kannst auch .to_json() für ein einzelnes JSON-Array verwenden oder deine eigene Pipeline schreiben, indem du den process_item-Hook überschreibst.
Für Pipelines, die Items während des Scrapings benötigen, anstatt auf den Abschluss des gesamten Crawls zu warten, stellt der Spider .stream() als asynchronen Generator bereit:
import asyncio
async def main():
async for item in BooksSpider().stream():
await write_to_kafka(item) # oder ein anderer nachgelagerter Sink
asyncio.run(main())Für längere Crawls lohnt es sich, den Pause-und-Resume-Mechanismus von Anfang an einzurichten:
result = BooksSpider(crawldir="./crawl_data").start()Übergib ein crawldir und Scrapling checkpointiert besuchte URLs und ausstehende Anfragen auf die Festplatte. Drücke Strg+C und der Crawl fährt gracefully herunter. Führe ihn erneut mit demselben crawldir aus und er setzt dort fort, wo er aufgehört hat. Für einen fünfzigseitigen Crawl ist das unnötig, aber für langläufige Produktions-Crawls (Katalog-Refreshes, Marktforschung, Preisüberwachung) ist es der Unterschied zwischen dem Verlust eines Tagesfortschritts und dem Verlust von nichts.
Wenn dein Ziel die ressourcenintensiveren Fetcher erfordert, kann der Spider Anfragen über verschiedene Sitzungen pro URL routen:
from scrapling.spiders import Spider, Request, Response
from scrapling.fetchers import FetcherSession, AsyncStealthySession
class HybridSpider(Spider):
name = "hybrid"
start_urls = ["https://example.com/catalog"]
def configure_sessions(self, manager):
manager.add("fast", FetcherSession(impersonate="chrome"))
manager.add("stealth", AsyncStealthySession(headless=True), lazy=True)
async def parse(self, response: Response):
for link in response.css('a::attr(href)').getall():
if "/protected/" in link:
yield Request(link, sid="stealth", callback=self.parse_protected)
else:
yield Request(link, sid="fast", callback=self.parse)
async def parse_protected(self, response: Response):
yield {"url": response.url, "title": response.css('h1::text').get()}Als Routing-Diagramm visualisiert:
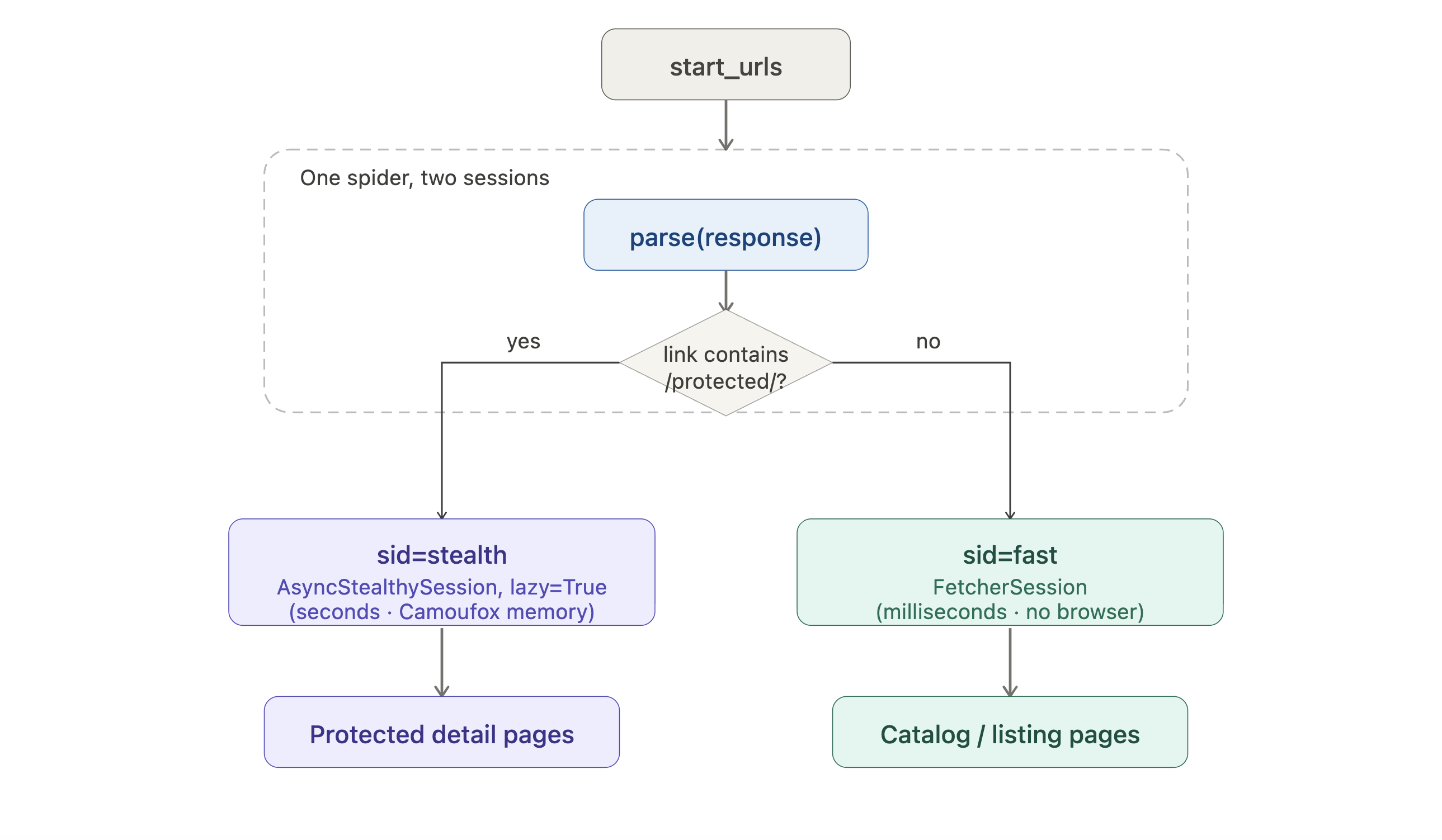
Listing-Seiten nehmen den günstigen HTTP-Pfad; nur geschützte Detailseiten zahlen die Browser-Kosten. lazy=True verzögert den Browser-Start bis zur ersten Stealth-Anfrage, sodass ein Crawl, der nur Listings trifft, Camoufox nie öffnet.
Einige Details in diesem Beispiel sind aus dem Code nicht offensichtlich. AsyncStealthySession und AsyncDynamicSession sind langlebige Browser-Sitzungen. Verwende sie über viele Anfragen hinweg wieder, anstatt StealthyFetcher.fetch() oder DynamicFetcher.fetch(), die bei jedem Aufruf einen neuen Browser starten.
configure_sessions empfängt einen manager (das Sitzungsregister des Spiders); manager.add(name, session) registriert eine Sitzung unter einem Namen, zu dem du später mit Request(url, sid=name) routen kannst. Das lazy=True-Flag auf der Stealth-Sitzung verzögert das Öffnen des Browsers bis zur ersten Stealth-Anfrage, sodass ein Crawl, der nur öffentliche Seiten anfragt, keinen Browser-Start-Overhead verursacht.
Die fast-Sitzung verwendet den günstigen HTTP-Fetcher für die Listing-Seiten, und nur die geschützten Detailseiten benötigen einen echten Browser. Diese Art von Routing ist schwer nachträglich zu einem Allzweck-Crawler hinzuzufügen.
Paginierung bei echten Seiten
Echte Ziele haben selten einen einfachen .next-Link wie books.toscrape.com. Drei Muster behandeln die meisten Fälle, die du sehen wirst:
- Nummerierte Paginierung (zum Beispiel ?page=1, 2, 3…) ist am einfachsten. Generiere die URLs direkt in start_urls, oder yield Request-Objekte aus parse in einer Schleife.
- Infinite Scroll basiert normalerweise auf einem JSON-XHR-Endpunkt. Öffne DevTools → Network, scrolle die Seite und suche nach der Anfrage, die den nächsten Batch von Items zurückgibt. Rufe dann diesen Endpunkt mit Fetcher auf (viel günstiger als jeden Scroll in einem Browser zu rendern).
- “Mehr laden”-Buttons benötigen einen echten Klick im Browser. DynamicFetcher und StealthyFetcher akzeptieren ein page_action-Callable, das die zugrunde liegende Playwright-Seite empfängt; klicke dort den Button, warte auf den neuen Inhalt, dann lass den Parser die Seite lesen, wenn die Funktion zurückkehrt:
from scrapling.fetchers import DynamicFetcher
def click_load_more(page):
# `page` ist die zugrunde liegende synchrone Playwright-Seite.
for _ in range(5):
page.click("button.load-more")
page.wait_for_load_state("networkidle")
return page
result = DynamicFetcher.fetch(
"https://example.com/products",
page_action=click_load_more,
headless=True,
)
items = result.css(".product")Passe den Selektor und die Klick-Anzahl an das Ziel an. Die async-Sitzungsklassen (AsyncDynamicSession, AsyncStealthySession) nehmen ein async-Äquivalent desselben Callables.
Scrapling für die Produktion skalieren: Proxys und Unblocking
Die Architektur ändert sich, sobald du ein echtes Produktionsziel im großen Maßstab scrapst. Drei Einschränkungen treten normalerweise zusammen auf:
- IP-Reputation. Eine einzelne Residential- oder Datacenter-IP, die tausend Anfragen pro Stunde an dieselbe Seite sendet, ähnelt keinem echten Nutzer. Die meisten Produktionsziele drosseln, dann limitieren, dann blockieren. Die Lösung ist ein Pool von IPs, idealerweise Residential (echte Verbraucherverbindungen) oder ISP (vom Carrier zugewiesene Datacenter-IPs, die für Anti-Bot-Scoring wie Residential aussehen), die pro Anfrage oder pro Sitzung rotieren.
- Geografisches Targeting. Einige Seiten liefern unterschiedliche Inhalte (oder unterschiedliche Preise) je nach Land, Bundesstaat oder Stadt. Um diese Ansichten zu reproduzieren, werden Proxys in diesen Standorten benötigt.
- CDN-grade Anti-Bot. Jenseits von Cloudflares grundlegendem Turnstile blockiert Akamai Bot Manager (und DataDome oder HUMAN im strengen Modus) oft lokale Stealth-Setups. An diesem Punkt funktioniert ein verwalteter Unblocking-Endpunkt, der seinen eigenen Browser-Pool und Challenge-Solver unterhält, in der Regel besser als eine eigene Lösung.
Wiederholungen, Timeouts und vorübergehende Fehler
Netzwerkfehler sind im großen Maßstab unvermeidlich: Verbindungsabbrüche, gelegentliche 503er unter Last, 429er wenn du ratenlimitiert wirst. FetcherSession akzeptiert retries=, retry_delay= und timeout= bei der Erstellung (Standardwerte in v0.4.7: 3, 1 Sekunde, 30 Sekunden; bestätige mit help(FetcherSession) auf deiner installierten Version). Die Browser-Fetcher (StealthyFetcher, DynamicFetcher) akzeptieren dieselben Parameter pro Fetch bei jedem .fetch()-Aufruf stattdessen.
Für zielspezifische Ratenlimits, bei denen der Server einen Retry-After-Header bei einem 429 sendet, lese diesen Header in deiner parse-Methode und yield die Request erneut mit einer Verzögerung. Die Standard-Wiederholung respektiert Retry-After nicht, sodass du auf diese Weise dasselbe 429 wieder erhältst.
Browser-Speicher: konkrete Größenangaben
Einen echten Browser zu betreiben ist der Preis für die Verwendung von DynamicFetcher und StealthyFetcher. Auf einer typischen Inhaltsseite (~200 KB HTML, keine medienlastigen SPAs) verbraucht eine einzelne Camoufox- oder Chromium-Sitzung im Headless-Modus auf Linux x86_64 etwa 700-900 MB RAM. Die Größe ändert sich kaum zwischen Fetches in derselben Sitzung, also plane für etwa 1 GB pro gleichzeitiger Browser-Sitzung beim Dimensionieren von Containern: Ein 4-GB-Worker betreibt komfortabel 3-4 gleichzeitige Sitzungen, ein 8-GB-Worker verarbeitet 6-8. Schwerere Ziele (bildreiche Seiten, dichte SPAs, Seiten, die Dutzende von Analytics-Skripten laden) erhöhen die Pro-Sitzungs-Kosten auf 1,2-1,5 GB. Verwende deine Sitzungen wieder, anstatt einmalige .fetch()-Aufrufe zu machen, damit du keine Browser-Start-Verzögerung bei jeder Anfrage verursachst.
Zwei Browser-Fetcher-Flags sind bei Produktionsvolumen wichtig. block_ads=True aktiviert Scrapling’s eingebaute Blockliste (etwa 3.500 Werbe- und Tracker-Domains) und reduziert die Fetch-Zeit bei werbelastigen Seiten, indem irrelevante Netzwerkanfragen übersprungen werden. dns_over_https=True leitet DNS-Abfragen über Cloudflares DoH (DNS over HTTPS)-Endpunkt und hilft, DNS-Lecks zu verhindern, wenn du Traffic über einen Residential-Proxy leitest. Beide gelten für DynamicFetcher und StealthyFetcher (HTTP-Fetcher-Anfragen laden keine Seitenressourcen, daher benötigen sie keines der Flags).
Selbstverwaltete Proxy-Rotation
Scrapling hat einen ProxyRotator-Helfer, der den grundlegenden Rotationsfall direkt behandelt:
from scrapling.fetchers import FetcherSession
from scrapling.engines.toolbelt.proxy_rotation import ProxyRotator
rotator = ProxyRotator([
"http://user:[email protected]:8000",
"http://user:[email protected]:8000",
"http://user:[email protected]:8000",
])
with FetcherSession(proxy_rotator=rotator) as session:
for url in target_urls:
page = session.get(url)
process(page)Für ein kleines Projekt mit einer Handvoll statischer Proxys ist das alles, was du brauchst. Für größere Projekte möchtest du in der Regel einen einzelnen Endpunkt, der dir eine frische IP pro Anfrage (oder eine sticky Session pro Nutzer) gibt, und dort macht die Bezahlung für einen kommerziellen Anbieter Sinn.
Bright Data’s Residential-Proxy-Netzwerk integriert sich mit Scrapling über dasselbe Proxy-URL-Muster: Es ist ein einzelner HTTP-Proxy-Endpunkt mit Benutzername- und Passwort-Authentifizierung, und der Benutzername enthält die Routing-Parameter, die das Netzwerk benötigt, einschließlich Land und sticky Session-ID. Die Werte kommen von der Access parameters-Seite der Zone im Bright Data Dashboard.
Um das folgende Beispiel auszuführen: Registriere dich unter brightdata.com (kostenloser Test, keine Karte erforderlich), erstelle eine Residential-Proxy-Zone im Dashboard und kopiere deine id, zone und password in die Proxy-URL. Residential-Proxys erfordern eine einmalige KYC-Überprüfung vor der Zonen-Aktivierung. Hier ist ein typisches Setup für die Rotation pro Anfrage:
from scrapling.fetchers import FetcherSession
# Ersetze <id>, <zone> und <password> durch die Werte aus deinem Dashboard.
PROXY = "http://brd-customer-<id>-zone-<zone>:<password>@brd.superproxy.io:33335"
with FetcherSession(impersonate="chrome", verify=False) as session:
page = session.get(
"https://quotes.toscrape.com/",
proxy=PROXY,
stealthy_headers=True,
)Zwei Hinweise zu diesem Setup:
- Übergib proxy= pro Anfrage, nicht im FetcherSession-Konstruktor. Pro-Anfrage-proxy= verhält sich konsistent über Fetcher-Typen hinweg und ist der einfachste Weg, pro Aufruf zu überschreiben. Dies gilt für jeden Anbieter, nicht nur Bright Data.
- Setze verify=False auf der Sitzung. Das Bright Data Residential-Netzwerk beendet den Proxy-Hop mit einer selbstsignierten Zertifikatskette (Standard für Residential-Proxy-Dienste). Die Verifizierung ist nur für den lokalen Hop zum Proxy deaktiviert; die Zielverbindung ist weiterhin End-to-End-TLS über die CONNECT-Methode des Proxys. Das sauberere Muster für die Produktion ist, Bright Data’s CA-Zertifikat in deinem Trust-Store zu installieren und verify=False vollständig zu entfernen; vermeide es, es in Code-Pfade zu kopieren, die nicht durch den Residential-Proxy gehen.
Für sticky Sessions (dieselbe IP über mehrere Anfragen hinweg, um einen Warenkorb oder Login-Zustand zu erhalten) enthält der Benutzername eine Session-ID, zum Beispiel brd-customer-\
Die gleiche Scrapling-Integration funktioniert mit Bright Data’s anderen Proxy-Typen (ISP-Proxys für höhervolumige Residential-qualitäts-IPs, Mobile-Proxys für mobile-only-Ansichten) mit nur dem Zonennamen in der URL, der sich ändert.
Für die schwierigsten Ziele lohnt es sich, das Web Unlocker-Muster zu kennen. Anstatt einen eigenen Stealth-Browser zu betreiben und Fingerprints zu aktualisieren, wenn ein Anbieter eine neue Erkennungsprüfung liefert, zeigst du den Fetcher auf einen einzelnen Endpunkt; Rendering, Fingerprinting, IP-Rotation und Challenge-Lösung finden remote statt. Bright Data’s Web Unlocker basiert auf diesem Muster, mit länderspezifischem Targeting und domänenspezifischer Unblocking-Logik, die vom Anbieter gepflegt wird. Dein Parsing-Code bleibt derselbe; nur die Fetch-Zeile ändert sich.
Derselbe Trade-off gilt für JavaScript-lastige Ziele. Camoufox oder Chromium lokal zu betreiben funktioniert für moderates Volumen. Sobald du viele Browser-Container verwaltest, nimmt ein verwalteter Bright Data Scraping-Browser das Unblocking und die Fingerprint-Pflege von deinem Team. Der Scraping-Browser ist ein Remote-Browser, mit dem du über eine WebSocket-Verbindung mit demselben Protokoll verbindest, das Playwright intern verwendet, sodass er in denselben Code-Pfad wie ein lokaler Chromium-Browser passt.
Zwei praktische Hinweise gelten bei der Wahl zwischen diesen:
- Wenn dein Problem ist “Ich brauche eine andere IP pro Anfrage, um Ratenlimits zu vermeiden”, sind Residential-Proxys plus der lokale Fetcher oder StealthyFetcher in der Regel ausreichend. Du zahlst für IPs, nicht für die Arbeit, Blockierungen zu umgehen.
- Wenn dein Problem ist “Ich erhalte CAPTCHA-Challenges, die ich nicht lösen kann, und die Seite ändert ihren Schutz alle paar Wochen”, spart ein verwalteter Unblocking-Endpunkt in der Regel genug Engineering-Zeit, um die höheren Kosten pro Anfrage zu rechtfertigen.
Ein vollständiges produktionsreifes Scrapling-Skript
Ein einfacher BooksSpider läuft sauber auf einer Sandbox. Fünf Ergänzungen machen ihn produktionsreif, mit nummerierten Kommentaren unten markiert:
import logging
from datetime import datetime, timezone
from scrapling.spiders import Spider, Response
logging.basicConfig(
level=logging.INFO,
format="%(asctime)s %(levelname)s %(message)s",
)
log = logging.getLogger("books")
class BooksSpider(Spider):
name = "books_production"
start_urls = ["https://books.toscrape.com/"]
concurrent_requests = 8
download_delay = 0.5
robots_txt_obey = True # 1. robots.txt und Crawl-delay respektieren
async def parse(self, response: Response):
if response.status != 200: # 2. Nicht-200-Antworten explizit behandeln
log.warning("Non-200 status %s on %s", response.status, response.url)
return
books_on_page = response.css('article.product_pod')
if not books_on_page: # 3. Veraltete Selektoren frühzeitig erkennen
log.error("No books found on %s; selector may be outdated", response.url)
return
for book in books_on_page:
yield {
"scraped_at": datetime.now(timezone.utc).isoformat(), # 4. Jeden Datensatz mit Zeitstempel versehen
"title": book.css('h3 a::attr(title)').get(),
"price": book.css('.price_color::text').get(),
"rating": book.css('p.star-rating::attr(class)').get(),
"url": response.urljoin(book.css('h3 a::attr(href)').get()),
}
next_page = response.css('li.next a::attr(href)').get()
if next_page:
yield response.follow(next_page, callback=self.parse)
if __name__ == "__main__":
spider = BooksSpider(crawldir="./crawl_data") # 5. Checkpoint für Pause/Wiederaufnahme
result = spider.start()
log.info("Scraped %d items", len(result.items))
result.items.to_jsonl("books.jsonl")Was jede Ergänzung bringt:
- robots_txt_obey respektiert robots.txt– und Crawl-delay-Direktiven automatisch.
- Die Status-Prüfung lässt den Spider serverseitige Fehler explizit aufzeichnen, anstatt sie als “keine Items gefunden” zu behandeln.
- Die Leergebnissprüfung erkennt einen veralteten Selektor am nächsten Morgen, anstatt drei Wochen später, wenn ein nachgelagerter Bericht keine Daten zeigt.
- Der Zeitstempel zeichnet auf, wann jeder Datensatz gescrapt wurde, sodass Wiederholungen über mehrere Tage nicht ineinander verschwimmen.
- crawldir bedeutet, dass ein Strg+C, ein Kernel-Panic oder eine verlorene Netzwerkverbindung den Crawl-Fortschritt nicht zerstört.
Um dasselbe Skript auf Residential-Proxys umzustellen, ist die einzige Änderung die Fetcher-Sitzung. Um auf einen Web Unlocker-Endpunkt umzustellen, ändere die Proxy-URL zum Unblocking-Dienst. Die Parsing-Logik und das Spider-Verhalten bleiben identisch.
Nach einem Zeitplan ausführen
Verpacke das Skript in Cron, einen systemd-Timer oder einen Orchestrator wie Airflow oder Prefect. Verwende ein pro-Lauf-crawldir (zum Beispiel ./crawl_data/$(date +%Y%m%d)), damit der Resume-Zustand eines vorherigen Laufs nicht in einen neuen übertragen wird, und sende die Ausgabe in dauerhaften Speicher, anstatt sie auf der Festplatte des Worker-Rechners zu lassen. Gängige Ziele: Parquet auf S3 oder GCS, das von polars oder DuckDB für Ad-hoc-Analysen gelesen wird, oder eine Postgres-Tabelle, wenn du relationale Abfragen benötigst.
Für Ziele jenseits von JSONL-Dateien überschreibe die Spider’s on_start-, on_scraped_item– und on_close-Hooks (alle drei sind async def). Öffne eine Datenbankverbindung oder einen Message-Queue-Producer einmal in on_start. Schreibe jedes Item aus on_scraped_item, wenn es geliefert wird (gib das Item zurück, um es weiterzuleiten, gib None zurück, um es zu verwerfen). Räume in on_close auf.
import asyncpg
from scrapling.spiders import Spider, Response
class BooksToPostgres(Spider):
name = "books_to_pg"
start_urls = ["https://books.toscrape.com/"]
async def on_start(self, resuming: bool = False) -> None:
self.db = await asyncpg.connect(DSN)
async def parse(self, response: Response):
for book in response.css('article.product_pod'):
yield {
"title": book.css('h3 a::attr(title)').get(),
"price": book.css('.price_color::text').get(),
}
async def on_scraped_item(self, item):
await self.db.execute(
"INSERT INTO books (title, price) VALUES ($1, $2)",
item["title"], item["price"],
)
return item # auch nachgelagert weiterleiten
async def on_close(self) -> None:
await self.db.close()Wenn Scraping bricht: eine Debugging-Checkliste
Produktions-Scraper scheitern auf Weisen, die Unit-Tests nicht erkennen. Einige schnelle Prüfungen behandeln den Großteil davon.
Öffne den Browser im sichtbaren Modus. Übergib headless=False an StealthyFetcher.fetch() oder DynamicFetcher.fetch() und beobachte, wie die Seite gerendert wird. CAPTCHA-Challenges, Redirect-Ketten, Geo-IP-Redirects und Anti-Bot-Erkennungsseiten werden oft erst offensichtlich, wenn du sehen kannst, was passiert. Führe es lokal aus; für Headless-Server speichere stattdessen einen Screenshot über page_action.
Speichere das Antwort-HTML auf die Festplatte. Wenn ein Selektor nichts zurückgibt, speichere die rohe Antwort und öffne sie in einem Browser:
page = Fetcher.get('https://example.com')
with open('debug.html', 'wb') as f:
f.write(page.body)Vergleiche dann, was der Parser erhalten hat, mit dem, was du erwartet hast. Meistens stellt sich heraus, dass was du gescrapt hast eine CAPTCHA-Wand, eine anderssprachige Weiterleitung oder eine Leergebnisseite ist, die auf den ersten Blick identisch mit dem Erfolgsfall aussieht. Das HTML zeigt die Wahrheit, auch wenn der Status-Code irreführend ist.
Verwende die interaktive Shell. Installiere scrapling[shell] und führe scrapling shell aus. Es lädt eine IPython-Sitzung mit vorinstalliertem Scrapling plus zwei nützliche Helfer: uncurl(…) parst einen curl-Befehl (aus DevTools’ Copy as cURL) in ein Scrapling-Request-Objekt, damit du genau prüfen kannst, was gesendet wird, und curl2fetcher(…) parst und führt es aus, gibt ein geparste Response zurück. Klicke mit der rechten Maustaste auf einen XHR-Aufruf in DevTools, kopiere als cURL, füge ihn in die Shell ein und du hast einen funktionierenden Scrapling-Fetch.
Einen Selektor aus einem bereits vorhandenen Element zurückentwickeln. Wenn du ein Element über find_by_text, Navigation oder anderweitig gefunden hast, geben dir die Eigenschaften .generate_css_selector und .generate_xpath_selector (Hinweis: Eigenschaften, keine Methoden) einen wiederverwendbaren Selektor dafür:
einstein = page.find_by_text("Albert Einstein")
print(einstein.generate_css_selector)
# body > div > div:nth-of-type(2) > div > div > span:nth-of-type(2) > smallDie Ausgabe ist nicht menschenlesbar, aber wiederverwendbar und übersteht Inhaltsänderungen, die das Element nicht verschieben.
Ein Hinweis darauf, was zuerst zu prüfen ist. Wenn ein Scraper, der gestern funktioniert hat, heute bricht, arbeite von der schnellsten zur langsamsten Prüfung: Leergebnissprüfung (“Selektor hat nichts zurückgegeben”), gespeichertes HTML (“Wurde die Seite überhaupt gerendert?”), dann headless=False (“Fordert die Seite den Browser heraus?”).
parse() iterieren, ohne eine weitere Anfrage an das Ziel zu senden. Setze development_mode = True und development_cache_dir = “./_dev” auf deiner Spider-Klasse:
class MySpider(Spider):
name = "iter"
start_urls = ["https://target.example.com/"]
development_mode = True
development_cache_dir = "./_dev"
async def parse(self, response):
...Der erste Durchlauf trifft das Netzwerk und speichert jede Antwort auf der Festplatte; spätere Durchläufe werden aus dem Cache abgespielt (etwa 50 ms gegenüber 1,2 Sekunden auf den Sandbox-Seiten, ungefähr 24-fache Beschleunigung). Während du Selektoren anpasst und Daten bereinigst, musst du nicht mehr bei jedem Testdurchlauf auf das Netzwerk warten. Setze development_mode vor dem Deployment auf False zurück.
Nächste Schritte
Wähle ein echtes Ziel, das du scrapen möchtest, und beginne mit dem leichtesten Fetcher, der dafür funktioniert. Fetcher verarbeitet statisches HTML; verwende DynamicFetcher, wenn Inhalte JavaScript-gerendert sind, StealthyFetcher, wenn die Seite hinter Cloudflare oder einem vergleichbaren Anti-Bot-Anbieter liegt.
Für alles, was du weiter betreiben möchtest, setze diese Standardwerte von Anfang an:
- Verpacke die Parse-Logik in einen Spider mit crawldir, robots_txt_obey=True und einer Leergebnissprüfung auf jeder Seite.
- Aktiviere selector_config={‘adaptive’: True} und auto_save=True beim ersten Durchlauf, damit der strukturelle Fingerprint auf der Festplatte ist, bevor die Seite ihr Markup ändert.
- Setze download_delay auf mindestens 0,5–1 s auf geteilter Infrastruktur, und lese den Retry-After-Header in deiner parse-Methode für alle 429-Antworten.
Wenn lokales Stealth nicht mehr ausreicht (IP-Reputation, Skalierung der Parallelität, CDN-grade Anti-Bot), wechsle zu einem Residential-Proxy oder einem verwalteten Unblocking-Endpunkt, indem du ein einzelnes proxy=-Argument bei jedem Fetch-Aufruf hinzufügst. Jeder Anbieter, der einen HTTP-Proxy mit Basic Authentication bereitstellt, funktioniert auf dieselbe Weise.
Die vollständige Referenz findest du in der offiziellen Dokumentation.
FAQ
Kann ich Scrapling in einem kommerziellen Produkt verwenden?
Ja. Scrapling ist BSD-3-Clause-lizenziert, sodass du es in kommerziellen Produkten, SaaS-Backends oder internen Tools ohne Lizenzgebühren oder einen kostenpflichtigen Tier einsetzen kannst. Du zahlst nur für optionale Drittanbieterdienste, die du wählst, wie einen Residential-Proxy oder einen CAPTCHA-Solver. Kein Feature in Scrapling selbst ist durch eine Lizenz gesperrt.
Wie vergleicht sich Scrapling mit Playwright oder Selenium?
Scrapling ist speziell für Web-Scraping gebaut; Playwright und Selenium sind allgemeine Browser-Automatisierungstools. Scrapling umhüllt einen stealth-gepatchten Camoufox-Build (gesteuert über Playwright), Wiederholungen, Sitzungswiederverwendung und adaptive Selektoren, sodass du weniger Glue-Code schreibst und die Chromium-CDP-Fingerprints vermeidest, die normales Playwright offenlegt.
Löst Scrapling CAPTCHAs?
Teilweise. StealthyFetcher löst verwaltete Cloudflare Turnstile-Challenges, wenn solve_cloudflare=True gesetzt ist. Andere Kategorien (Bild-Raster-hCaptcha, Audio-CAPTCHAs, benutzerdefinierte Enterprise-Challenges) benötigen einen Drittanbieter-Solver (2Captcha, CapSolver) oder einen verwalteten Unblocking-Endpunkt, der die Challenge-Schicht vollständig verwaltet.
Kann Scrapling mit Scrapy zusammenarbeiten?
Ja. Scrapling’s Parser verwendet dieselbe Pseudo-Element-Syntax (::text, ::attr(href)) wie Parsel, sodass ein Scrapling-Selektor in einem Scrapy-Callback funktioniert, wobei die meisten Selektoren unverändert bleiben. Die Spider/parse/yield-Form wird übernommen; Spider ohne umfangreiche Middlewares oder Pipelines können größtenteils mechanisch portiert werden.
Brauche ich einen Proxy-Dienst, um Scrapling zu verwenden?
Nein, Scrapling funktioniert ohne Proxy bei kleinen Jobs. Bei Produktionsvolumen verwende Scrapling’s integrierten ProxyRotator mit einer statischen Liste, wenn du volle Kontrolle willst, oder einen verwalteten Residential-, ISP- oder Mobile-Endpunkt, wenn du frische IPs pro Anfrage oder länderspezifisches Targeting benötigst.
Kann Scrapling in Docker ausgeführt werden?
Ja. Das Projekt stellt ein offizielles Docker-Image mit allen vorinstallierten Browser-Abhängigkeiten bereit. Für StealthyFetcher und DynamicFetcher spart das offizielle Image etwa eine Stunde, um Camoufox und Chromium in einem benutzerdefinierten Container zum Laufen zu bringen. Für den einfachen Fetcher funktioniert jedes Standard-Python-Image.





