

Falls Sie sich für Web-Scraping interessieren, kann Crawlee Ihnen dabei behilflich sein. Es handelt sich um eine schnelle, interaktive Scraping-Engine, die von Datenwissenschaftlern, Entwicklern und Forschern zum Sammeln von Webdaten verwendet wird. Crawlee ist einfach einzurichten und bietet Funktionen wie Proxy-Rotation und Session-Handling. Diese Funktionen sind für das Scraping großer bzw. dynamischer Websites unerlässlich, damit Ihre IP-Adresse nicht blockiert wird und eine reibungslose und ununterbrochene Datenerfassung gewährleistet ist.
In diesem Tutorial lernen Sie, Crawlee für Web-Scraping zu verwenden. Zunächst lernen Sie anhand eines einfachen Beispiels von Web-Scraping fortgeschrittenere Konzepte kennen, z. B. Sitzungsverwaltung und Scraping dynamischer Seiten.
Web-Scraping mit Crawlee
Ehe Sie mit diesem Tutorial loslegen, sollten Sie sicherstellen, dass Sie folgende Voraussetzungen auf Ihrem Rechner installiert haben:
- Node.js
- npm: Dies wird normalerweise mit Node.js mitgeliefert. Überprüfen Sie die Installation, indem Sie
node -vodernpm -vin Ihrem Terminal ausführen. - Ein Code-Editor Ihrer Wahl: In diesem Tutorial wird Visual Studio Code verwendet.
Einfaches Web-Scraping mit Crawlee
Sobald Sie alle Voraussetzungen erfüllen, beginnen wir mit dem Scraping der Website Books to Scrape, die sich aufgrund ihrer einfachen HTML-Struktur hervorragend für den Einstieg eignet.
Öffnen Sie Ihr Terminal oder Ihre Shell und beginnen Sie mit der Initialisierung eines Node.js-Projekts mit folgenden Befehlen:
mkdir crawlee-tutorial
cd crawlee-tutorial
npm init -y
Anschließend installieren Sie die Crawlee-Bibliothek mit folgendem Befehl:
npm install crawlee
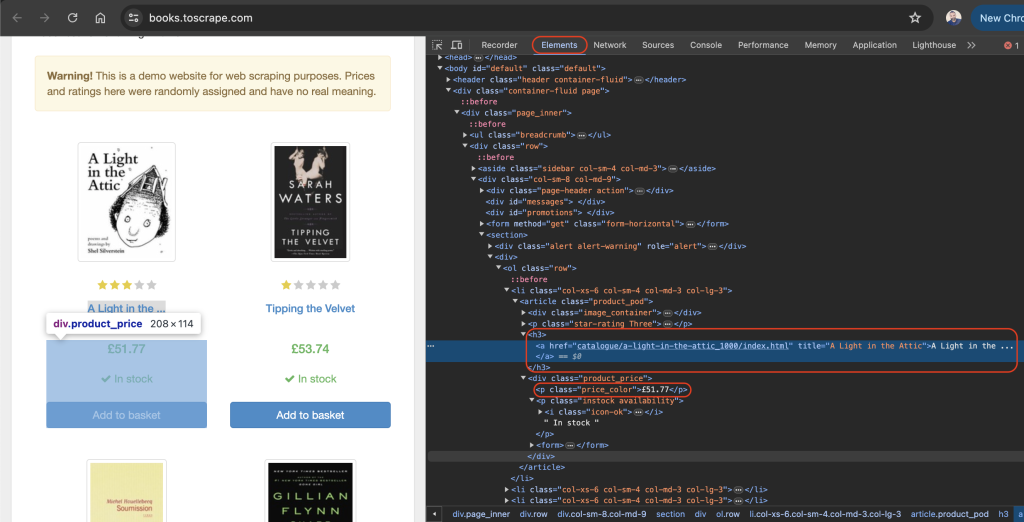
Um Daten von einer beliebigen Website effektiv zu scrapen, müssen Sie die zu scrappende Website inspizieren, um die Einzelheiten der HTML-Tags dieser Website zu ermitteln. Öffnen Sie dazu die Website in Ihrem Browser und öffnen Sie die Entwicklertools , indem Sie mit der rechten Maustaste auf eine beliebige Stelle der Website klicken. Klicken Sie nun auf Inspizieren oder Element inspizieren.
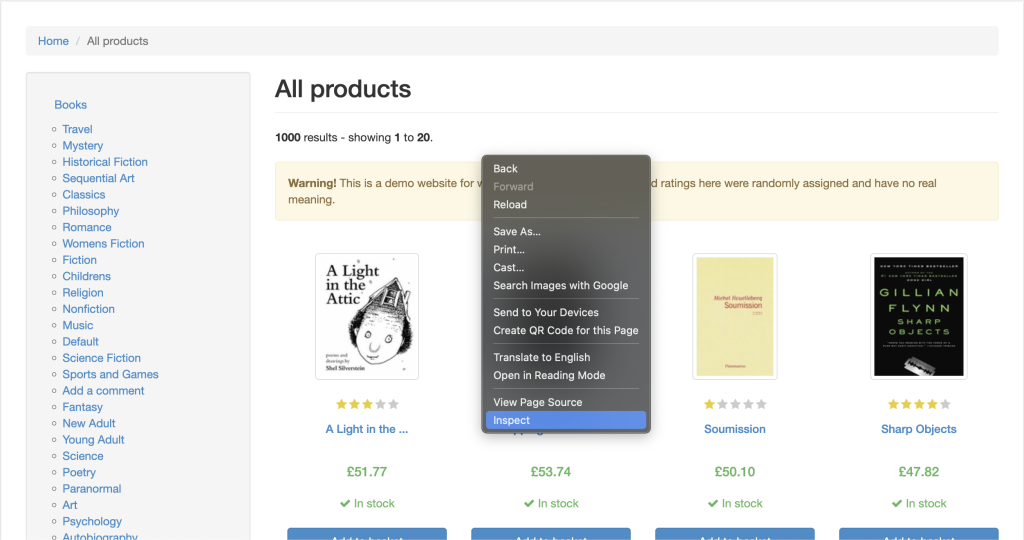
Die Registerkarte Elemente sollte standardmäßig aktiv sein. Diese Registerkarte stellt das HTML-Layout der Webseite dar. In diesem Beispiel ist jedes einzelne angezeigte Buch in einem Artikel-HTML-Tag der Klasse product_pod untergebracht. In jedem einzelnen Artikel ist der Titel des Buches in einem h3-Tag enthalten. Der eigentliche Titel des Buches ist im Titel-Attribut des a-Tags enthalten, der sich innerhalb des h3- Elements befindet. Der Preis des Buches befindet sich innerhalb des p-Tags der Klasse price_color:
Legen Sie im Stammverzeichnis Ihres Projekts eine Datei mit der Bezeichnung scrape.js an und fügen Sie folgenden Code ein:
const { CheerioCrawler } = require('crawlee');
const crawler = new CheerioCrawler({
async requestHandler({ request, $ }) {
const books = [];
$('article.product_pod').each((index, element) => {
const title = $(element).find('h3 a').attr('title');
const price = $(element).find('.price_color').text();
books.push({ title, price });
});
console.log(books);
},
});
crawler.run(['https://books.toscrape.com/']);
In diesem Code verwenden Sie CheerioCrawler von crawlee, um Buchtitel und -preise von https://books.toscrape.com/ abzurufen. Der Crawler holt HTML-Inhalte ein, extrahiert Daten aus article class=product_podElementen mit einer jQuery-ähnlichen Syntax und protokolliert deren Ergebnisse auf der Konsole.
Sobald Sie den vorherigen Code zu Ihrer scrape.js-Datei hinzugefügt haben, können Sie den Code mit dem folgenden Befehl ausführen:
node scrape.js
Ein Array mit Buchtiteln und -preisen sollte auf Ihrem Terminal erscheinen:
…output omitted…
{
title: 'The Boys in the Boat: Nine Americans and Their Epic Quest for Gold at the 1936 Berlin Olympics',
price: '£22.60'
},
{ title: 'The Black Maria', price: '£52.15' },
{
title: 'Starving Hearts (Triangular Trade Trilogy, #1)',
price: '£13.99'
},
{ title: "Shakespeare's Sonnets", price: '£20.66' },
{ title: 'Set Me Free', price: '£17.46' },
{
title: "Scott Pilgrim's Precious Little Life (Scott Pilgrim #1)",
price: '£52.29'
},
…output omitted…
Proxy-Rotation mit Crawlee
Ein Proxy ist der Vermittler zwischen Ihrem Rechner und dem Internet. Bei der Verwendung eines Proxys senden Sie Ihre Webanfragen an den Proxy-Server, der sie an die gewünschte Website weiterleitet. Der Proxy-Server sendet die Antwort von der Internetseite zurück, wobei der Proxy Ihre IP-Adresse verbirgt und Sie so vor einer Tarifbeschränkung oder IP-Sperre bewahrt.
Crawlee macht die Proxy-Implementierung denkbar einfach, denn es verfügt über eine integrierte Proxy-Verarbeitung, die Neuversuche und Fehler zuverlässig verwaltet. Crawlee bietet zudem eine Reihe von Proxy-Konfigurationen, um rotierende Proxys zu implementieren.
Im folgenden Abschnitt werden Sie einen Proxy einrichten, indem Sie zunächst einen gültigen Proxy erhalten. Anschließend stellen Sie sicher, dass Ihre Anfragen über die Proxys laufen.
Einrichtung eines Proxys
Kostenlose Proxys sind im Allgemeinen nicht zu empfehlen, da sie langsam und nicht zuverlässig genug sind und möglicherweise nicht die nötige Unterstützung für sensible Webaufgaben leisten. Nutzen Sie stattdessen einen sicheren, stabilen und zuverlässigen Proxy-Service wie Bright Data. Bright Data bietet auch eine kostenlose Testversion an, mit der Sie den Service testen können, bevor Sie sich verpflichten.
Zur Nutzung von Bright Data klicken Sie auf der Startseite auf die Schaltfläche Kostenlose Testversionstarten und geben Siedie zur Erstellung eines Kontos erforderlichen Informationen ein.
Nachdem Sie Ihr Konto eingerichtet haben, melden Sie sich beim Bright Data Dashboard an, öffnen Sieden Bereich Proxys und Scraping-Infrastruktur und fügen Sie einen neuen Proxy hinzu, indem Sie Residential-Proxys auswählen:
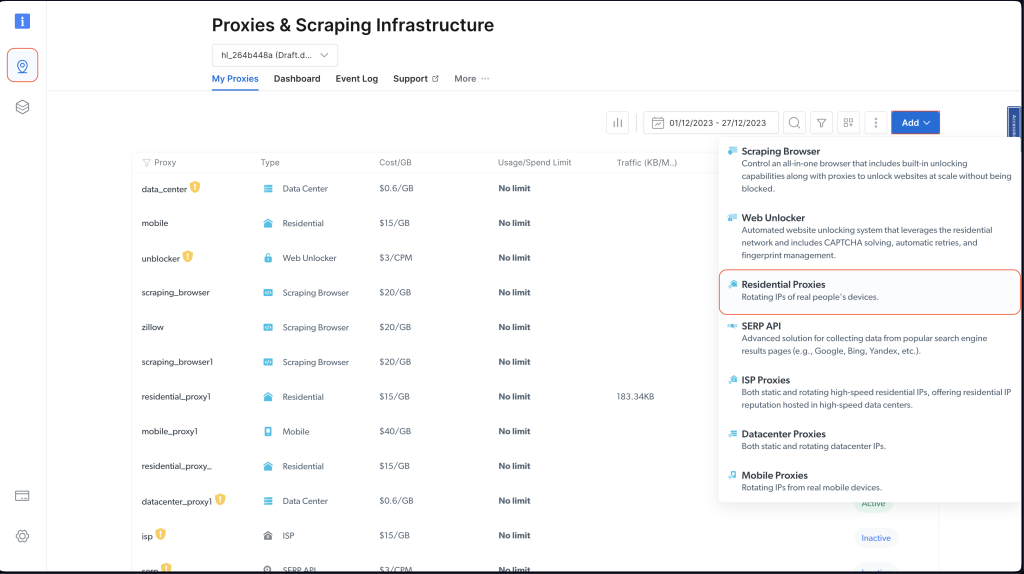
Behalten Sie die Standardeinstellungen bei und schließen Sie die Erstellung Ihres Residential-Proxys ab, indem Sie auf Hinzufügen klicken.
Sollten Sie aufgefordert werden, ein Zertifikat zu installieren, können Sie Ohne Zertifikat fortfahren wählen. Für Produktions- und reale Anwendungsfälle sollten Sie das Zertifikat jedoch einrichten, um Missbrauch zu verhindern, sollten Ihre Proxy-Daten jemals offengelegt werden.
Notieren Sie sich nach der Erstellung die Anmeldedaten des Proxy, einschließlich des Hosts, des Ports, des Benutzernamens und des Passworts. Diese Angaben sind für den nächsten Schritt erforderlich:
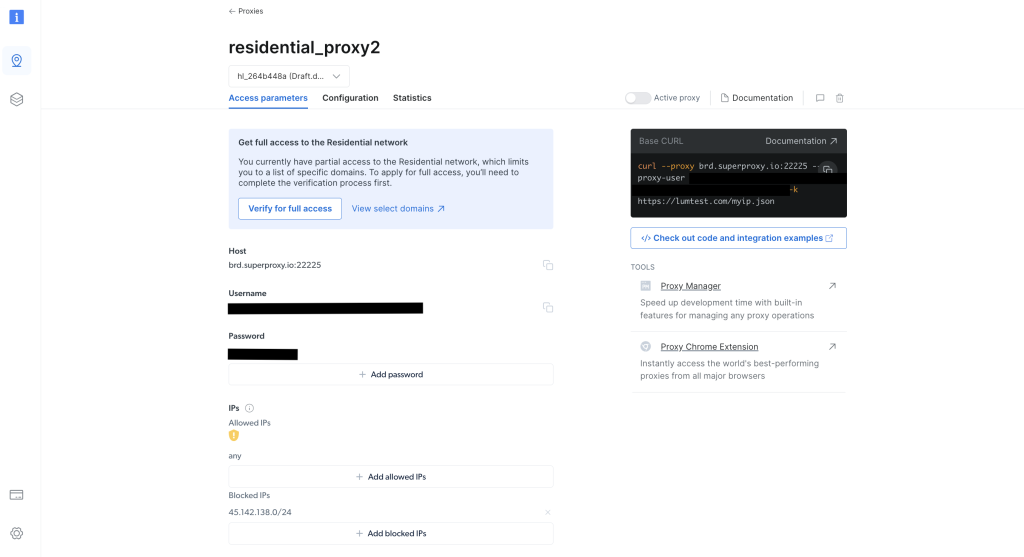
Führen Sie im Stammverzeichnis Ihres Projekts folgenden Befehl aus, um die axios-Bibliothek zu installieren:
npm install axios
Mithilfe der axios-Bibliothek stellen Sie eine GET-Anfrage an http://lumtest.com/myip.json, die bei jeder Ausführung des Skripts die Details des von Ihnen verwendeten Proxys übermittelt.
Als Nächstes erstellen Sie im Stammverzeichnis Ihres Projekts eine Datei mit der Bezeichnung scrapeWithProxy.js und fügen folgenden Code ein:
const { CheerioCrawler } = require("crawlee");
const { ProxyConfiguration } = require("crawlee");
const axios = require("axios");
const proxyConfiguration = new ProxyConfiguration({
proxyUrls: ["http://USERNAME:PASSWORD@HOST:PORT"],
});
const crawler = new CheerioCrawler({
proxyConfiguration,
async requestHandler({ request, $, response, proxies }) {
// Make a GET request to the proxy information URL
try {
const proxyInfo = await axios.get("http://lumtest.com/myip.json", {
proxy: {
host: "HOST",
port: PORT,
auth: {
username: "USERNAME",
password: "PASSWORD",
},
},
});
console.log("Proxy Information:", proxyInfo.data);
} catch (error) {
console.error("Error fetching proxy information:", error.message);
}
const books = [];
$("article.product_pod").each((index, element) => {
const title = $(element).find("h3 a").attr("title");
const price = $(element).find(".price_color").text();
books.push({ title, price });
});
console.log(books);
},
});
crawler.run(["https://books.toscrape.com/"]);
Hinweis: Achten Sie darauf, den
HOST,PORT,BENUTZERNAMENundPASSWORTdurch Ihre Anmeldedaten zu ersetzen.
In diesem Code verwenden Sie CheerioCrawler von crawlee , um Informationen von https://books.toscrape.com/ über einen bestimmten Proxy abzurufen. Den Proxy konfigurieren Sie mit ProxyConfiguration; anschließend rufen Sie über eine GET-Anfrage an http://lumtest.com/myip.json die Proxy-Details ab bzw. protokollieren diese. Schließlich extrahieren Sie die Buchtitel und -preise mithilfe der jQuery-ähnlichen Syntax von Cheerio und protokollieren die gescrapten Daten auf der Konsole.
Sie können den Code nun ausführen und testen, um die Funktionsfähigkeit der Proxys sicherzustellen:
node scrapeWithProxy.js
Sie werden ähnliche Ergebnisse wie zuvor erhalten, aber dieses Mal werden Ihre Anfragen über Bright-Data-Proxys geleitet. Außerdem sollten Sie die Details des Proxys in der Konsole protokolliert finden:
Proxy Information: {
country: 'US',
asn: { asnum: 21928, org_name: 'T-MOBILE-AS21928' },
geo: {
city: 'El Paso',
region: 'TX',
region_name: 'Texas',
postal_code: '79925',
latitude: 31.7899,
longitude: -106.3658,
tz: 'America/Denver',
lum_city: 'elpaso',
lum_region: 'tx'
}
}
[
{ title: 'A Light in the Attic', price: '£51.77' },
{ title: 'Tipping the Velvet', price: '£53.74' },
{ title: 'Soumission', price: '£50.10' },
{ title: 'Sharp Objects', price: '£47.82' },
{ title: 'Sapiens: A Brief History of Humankind', price: '£54.23' },
{ title: 'The Requiem Red', price: '£22.65' },
…output omitted..
Führen Sie das Skript erneut mit node scrapingWithBrightData.js aus, sollten Sie eine andere vom Proxy-Server von Bright Data verwendete IP-Adresse angezeigt bekommen. Dadurch wird bestätigt, dass Bright Data die Standorte und IPs bei jeder Ausführung Ihres Scraping-Skripts rotiert. Diese Rotation ist vor allem zur Umgehung von Blockaden oder IP-Sperren der Ziel-Websites wichtig.
Hinweis: In der
proxyConfigurationhätten Sie verschiedene Proxy-IPs angeben können, allerdings übernimmt Bright Data diese Aufgabe für Sie, sodass Sie die IPs nicht angeben müssen.
Sitzungsverwaltung mit Crawlee
Sitzungen helfen bei der Erhaltung des Status über mehrere Anfragen hinweg, was für Websites mit Cookies oder Anmeldesitzungen sinnvoll ist.
Zur Verwaltung einer Sitzung erstellen Sie eine Datei mit der Bezeichnung scrapeWithSessions.js im Stammverzeichnis Ihres Projekts und fügen dort folgenden Code ein:
const { CheerioCrawler, SessionPool } = require("crawlee");
(async () => {
// Open a session pool
const sessionPool = await SessionPool.open();
// Ensure there is a session in the pool
let session = await sessionPool.getSession();
if (!session) {
session = await sessionPool.createSession();
}
const crawler = new CheerioCrawler({
useSessionPool: true, // Enable session pool
async requestHandler({ request, $, response, session }) {
// Log the session information
console.log(`Using session: ${session.id}`);
// Extract book data and log it (for demonstration)
const books = [];
$("article.product_pod").each((index, element) => {
const title = $(element).find("h3 a").attr("title");
const price = $(element).find(".price_color").text();
books.push({ title, price });
});
console.log(books);
},
});
// First run
await crawler.run(["https://books.toscrape.com/"]);
console.log("First run completed.");
// Second run
await crawler.run(["https://books.toscrape.com/"]);
console.log("Second run completed.");
})();
Hier nutzen Sie den CheerioCrawler und den SessionPool von crawlee , um Daten von https://books.toscrape.com/ zu scrapen. Initialisieren Sie einen SessionPool und richten Sie den Crawler zur Nutzung dieser Sitzung entsprechend ein. Die Funktion requestHandler protokolliert die Sitzungsdaten und extrahiert Buchtitel und -preise mithilfe der jQuery-ähnlichen Selektoren von Cheerio. Dieser Code führt zwei aufeinanderfolgende Scraping-Läufe durch und protokolliert bei jedem Lauf die Sitzungs-ID.
Führen Sie den Code aus und testen Sie ihn, um sicherzustellen, dass verschiedene Sitzungen verwendet werden:
node scrapeWithSessions.js
Sie sollten ähnliche Ergebnisse erhalten wie zuvor, aber dieses Mal sollten Sie auch die Sitzungs-ID für jeden Durchlauf angezeigt bekommen:
Using session: session_GmKuZ2TnVX
[
{ title: 'A Light in the Attic', price: '£51.77' },
{ title: 'Tipping the Velvet', price: '£53.74' },
…output omitted…
Using session: session_lNRxE89hXu
[
{ title: 'A Light in the Attic', price: '£51.77' },
{ title: 'Tipping the Velvet', price: '£53.74' },
…output omitted…
Führen Sie den Code erneut aus, sollten Sie feststellen, dass eine andere Sitzungs-ID verwendet wird.
Umgang mit dynamischen Inhalten bei Crawlee
Bei dynamischen Websites (d. h. Websites mit Inhalten, die durch JavaScript gefüllt werden) kann Web-Scraping eine wahre Herausforderung darstellen, da Sie für den Zugriff auf die Daten JavaScript rendern müssen. In solchen Situationen ist Crawlee mit Puppeteer integriert, einem Headless-Browser, der JavaScript wiedergeben und wie ein Mensch mit der betreffenden Website interagieren kann.
Zur Verdeutlichung dieser Funktionalität scrapen wir Inhalte von dieser YouTube-Webseite. Bevor Sie etwas scrapen, sollten Sie sich wie immer mit den Regeln und Nutzungsbedingungen für diese Seite vertraut machen.
Erstellen Sie nach Durchsicht der Nutzungsbedingungen eine Datei mit der Bezeichnung scrapeDynamicContent.js im Stammverzeichnis Ihres Projekts und fügen Sie folgenden Code ein:
const { PuppeteerCrawler } = require("crawlee");
async function scrapeYouTube() {
const crawler = new PuppeteerCrawler({
async requestHandler({ page, request, enqueueLinks, log }) {
const { url } = request;
await page.goto(url, { waitUntil: "networkidle2" });
// Scraping first 10 comments
const comments = await page.evaluate(() => {
return Array.from(document.querySelectorAll("#comments #content-text"))
.slice(0, 10)
.map((el) => el.innerText);
});
log.info(`Comments: ${comments.join("n")}`);
},
launchContext: {
launchOptions: {
headless: true,
},
},
});
// Add the URL of the YouTube video you want to scrape
await crawler.run(["https://www.youtube.com/watch?v=wZ6cST5pexo"]);
}
scrapeYouTube();
Führen Sie den Code anschließend mit folgendem Befehl aus:
node scrapeDynamicContent.js
In diesem Code verwenden Sie den PuppeteerCrawler aus der Crawlee-Bibliothek, um YouTube-Videokommentare zu scrapen. Als Erstes initialisieren Sie einen Crawler, der zu einer bestimmten YouTube-Video-URL navigiert und darauf wartet, dass die Seite vollständig geladen ist. Sobald die Seite geladen ist, wertet der Code den Seiteninhalt aus, um durch Auswahl von Elementen mit dem angegebenen CSS-Selektor #comments #content-text die ersten zehn Kommentare zu extrahieren. Die Kommentare werden daraufhin in der Konsole protokolliert.
Ihre Ausgabe sollte die ersten zehn Kommentare zum ausgewählten Video enthalten:
INFO PuppeteerCrawler: Starting the crawler.
INFO PuppeteerCrawler: Comments: Who are you rooting for?? US Marines or Ex Cons
Bro Mateo is a beast, no lifting straps, close stance.
ex convict doing the pushups is a monster.
I love how quick this video was, without nonsense talk and long intros or outros
"They Both have combat experience" is wicked
That military guy doing that deadlift is really no joke.. ...
One lives to fight and the other fights to live.
Finally something that would test the real outcome on which narrative is true on movies
I like the comradery between all of them. Especially on the Bench Press ... Both team members quickly helped out on the spotting to protect from injury. Well done.
I like this style, no youtube funny business. Just straight to the lifts
…output omitted…
Den gesamten in diesem Tutorial verwendeten Code finden Sie auf GitHub.
Fazit
In diesem Artikel haben Sie gelernt, Crawlee für Web-Scraping zu verwenden und erfahren, wie Sie damit die Effizienz und Zuverlässigkeit Ihrer Web-Scraping-Projekte optimieren können.
Vergessen Sie nicht, beim Scraping von Daten immer die robots.txt-Datei und die Nutzungsbedingungen der Ziel-Website zu beherzigen.
Sind Sie bereit, Ihre Web-Scraping-Projekte durch professionelle Daten, Tools und Proxys zu optimieren? Erkunden Sie die umfassende Web- Scraping-Plattform von Bright Data, die gebrauchsfertige Datensätze und fortschrittliche Proxy-Services zur Optimierung Ihrer Datenerfassung bereitstellt.
Melden Sie sich jetzt an und starten Sie Ihre kostenlose Testversion!.





