

In diesem Artikel erfahren Sie:
- Was Apache Spark Structured Streaming ist und welche Vorteile es bietet.
- Warum die Integration der SERP-API von Bright Data in eine Spark Structured Streaming-Pipeline eine erfolgreiche Strategie ist.
- Wie man eine PySpark-Pipeline erstellt, die mithilfe der SERP-API von Bright Data kontinuierlich Live-Websuchergebnisse einliest.
Legen wir los!
Was ist Apache Spark Structured Streaming?
Apache Spark Structured Streaming ist eine skalierbare, fehlertolerante Stream-Verarbeitungs-Engine, die auf der Spark-SQL-Engine aufbaut. Im Gegensatz zur älteren Spark-Streaming-Bibliothek (die Daten mithilfe von DStreams in diskrete RDD-basierte Mikro-Batches aufteilt) behandelt Structured Streaming einen Live-Datenstrom als unbegrenzte Tabelle, an die kontinuierlich Daten angehängt werden. Sie schreiben denselben DataFrame- und SQL-API-Code, den Sie für einen statischen Batch-Job schreiben würden, und Spark kümmert sich darum, ihn schrittweise auszuführen, sobald neue Daten eintreffen.
Die Engine arbeitet standardmäßig in einem Mikro-Batch-Ausführungsmodell. Bei jedem Trigger-Intervall liest Spark die neuesten Daten aus der Quelle, verarbeitet sie und schreibt die Ergebnisse in einen Sink. Der Fortschritt wird über Checkpoints verfolgt, sodass die Pipeline nach Ausfällen wiederhergestellt werden und genau dort fortfahren kann, wo sie aufgehört hat, was durchgängige, fehlertolerante Garantien bietet.
Structured Streaming unterstützt eine Vielzahl integrierter Quellen: Kafka-Topics, Delta-Tabellen, Cloud-Objektspeicher über Auto Loader, Rate-Generatoren (für Tests) und mehr. Für Quellen, die nicht nativ abgedeckt sind (wie z. B. eine REST-API), können Sie die foreachBatch-Erweiterungsmethode verwenden, die jeden Mikro-Batch an eine Python-Funktion übergibt, in der Sie beliebige Erfassungslogik definieren können. Dies ist der Ansatz, den wir hier verwenden werden.
Spark Streaming vs. Spark Structured Streaming: Was ist der Unterschied?
Wenn Sie mit der älteren Spark-Streaming-Bibliothek vertraut sind, fragen Sie sich vielleicht, in welcher Beziehung diese zu Structured Streaming steht. Beide nutzen dieselbe zugrunde liegende Spark-Engine, unterscheiden sich jedoch in wesentlichen Punkten:
Spark Streaming basiert auf DStreams, einer Folge von RDDs, die durch die Aufteilung eines eingehenden Streams in zeitlich begrenzte Batches erzeugt werden. Alle Transformationen werden auf RDDs angewendet, was bedeutet, dass Sie auf einer API niedrigerer Ebene arbeiten. Es bietet nur begrenzte Unterstützung für Event-Time-Semantik (d. h. die Sortierung von Daten nach dem Zeitpunkt ihrer Erzeugung, nicht nach dem Zeitpunkt ihrer Erfassung) und wird nicht mehr aktiv weiterentwickelt.
Spark Structured Streaming basiert auf den DataFrame- und Dataset-APIs und bietet Ihnen Zugriff auf den vollständigen Spark-SQL-Optimierer. Es bietet native Event-Time-Fensterung, Watermarking zur Behandlung verspäteter Daten, zustandsbehaftete Aggregationen und ein übersichtlicheres Fehlertoleranzmodell durch Checkpointing. Da es dieselbe API wie Batch-DataFrames verwendet, können Sie Streaming- und statische Daten im selben Job mischen (z. B. Streaming-Joins mit einer statischen Lookup-Tabelle).
Kurz gesagt: Spark Streaming ist ein Legacy-Projekt, das aus Gründen der Abwärtskompatibilität beibehalten wird, während Structured Streaming die aktiv weiterentwickelte, empfohlene Engine für alle neuen Streaming-Workloads ist.
Warum die SERP-API von Bright Data in Spark Structured Streaming integrieren?
Spark Structured Streaming bietet eine leistungsstarke Engine für die Transformation und Aggregation von Daten in großem Maßstab, benötigt jedoch eine zuverlässige, strukturierte Quelle für Live-Webdaten, auf die es zugreifen kann. Hier kommt die SERP-API von Bright Data ins Spiel.
Mit der SERP-API können Sie programmgesteuert Abfragen an große Suchmaschinen (einschließlich Google, Bing, DuckDuckGo, Yandex und weitere) senden und vollständige Suchergebnisseiten (SERPs) abrufen, ohne blockiert zu werden. Die Ergebnisse werden in verschiedenen Formaten zurückgegeben: geparstes JSON, eine schlanke „parsed_light“-Variante mit nur den obersten organischen Ergebnissen, rohes HTML oder bereinigtes, KI-fähiges Markdown. Da das direkte Scraping von Suchmaschinen aufgrund von Anti-Bot-Maßnahmen, Ratenbeschränkungen und dynamischem Rendering bekanntermaßen schwierig ist, beseitigt die Weiterleitung Ihrer Abfragen über die Infrastruktur von Bright Data all diese Komplexität aus Ihrer Pipeline.
In Kombination mit der Micro-Batch-Engine von Spark Structured Streaming entsteht so eine kontinuierlich laufende Pipeline, die regelmäßig aktuelle SERP-Daten abruft, Transformationen und Aggregationen in großem Maßstab durchführt und strukturierte Ergebnisse in einen beliebigen Speicher Ihrer Wahl schreibt, ohne dass Sie sich um Proxys, CAPTCHAs oder die Scraping-Infrastruktur kümmern müssen.
Dieser Ansatz eignet sich besonders für:
- Überwachen Sie in regelmäßigen Abständen, wie eine Reihe von Ziel-Keywords in Suchmaschinen rankt, schreiben Sie die Ergebnisse in eine Delta-Tabelle und berechnen Sie Rank-Veränderungen im Zeitverlauf.
- Rufen Sie kontinuierlich SERPs für Markennamen oder Produkte von Wettbewerbern ab, führen Sie das Parsing der strukturierten Ergebnisse durch und streamen Sie diese zur Dashboard-Anzeige in ein Data Warehouse.
- Abfragen von Google News-Suchergebnissen zu mehreren Themen in parallelen Mikro-Batches, Deduplizieren von Artikeln mithilfe der zustandsbehafteten Aggregationen von Spark und Speichern der kuratierten Ergebnisse in einem Data Lake.
- Leiten Sie SERP-Ergebnisse kontinuierlich ein, um zu erkennen, wann bezahlte Anzeigen für Ihre Ziel-Keywords erscheinen, erfassen Sie den Anzeigentext und die URLs und benachrichtigen Sie nachgelagerte Systeme.
Durch die Kombination der verteilten, skalierbaren Verarbeitung von Spark Structured Streaming mit der Webzugriffsinfrastruktur von Bright Data für KI und Datenpipelines erstellen Sie Pipelines, die kontinuierlich auf reale Suchdaten reagieren, ohne dass Sie eine eigene Scraping-Infrastruktur unterhalten müssen.
So erstellen Sie eine Pipeline zur kontinuierlichen SERP-Erfassung mit Spark Structured Streaming
In diesem geführten Abschnitt erstellen Sie eine PySpark-Pipeline, die:
- nach einem Zeitplan ausgelöst wird, wobei die in Spark integrierte Rate-Source als Taktgeber dient.
- innerhalb einer
foreachBatch-Funktion bei jedem Mikro-Batchdie SERP-API von Bright Data aufruft, um Live-Ergebnisse von Google News für ein Zielthema abzurufen. - Parsing der strukturierten JSON-Antwortund Umwandlung in einen sauberen Spark DataFrame.
- die Ergebnisse in einen Sink schreibt (sowohl in ein lokales JSON-Ausgabeverzeichnis als auch in die Konsole), damit Sie die Live-Daten überprüfen können.
Hinweis: Dieses Beispiel veranschaulicht einen Anwendungsfall für die Nachrichtenüberwachung, aber das gleiche Muster gilt für jedes Szenario der kontinuierlichen SERP-Erfassung: Keyword-Ranking-Tracking, Anzeigenüberwachung, Preisvergleiche über die Websuche und so weiter.
Voraussetzungen
Um mitmachen zu können, stellen Sie sicher, dass Sie Folgendes haben:
- Python 3.8+ installiert ist.
- Apache Spark 3.3+ lokal installiert oder Zugriff auf einen Databricks-/AWS EMR-/Google Dataproc-Cluster.
- PySpark installiert:
pip install pyspark. - Die
requests-Bibliothek ist installiert:pip install requests. - Ein Bright Data-Konto mit einer aktiven SERP-API-Zone und einem API-Schlüssel (mit Administratorrechten).
Befolgen Sie die offizielle Bright Data-Dokumentation, um Ihre SERP-API-Zone einzurichten und Ihren API-Schlüssel abzurufen. Bewahren Sie sowohl Ihren API-Schlüssel als auch den Zonennamen an einem sicheren Ort auf; Sie werden sie in Kürze benötigen.
Schritt 1: Richten Sie Ihr Projekt ein
Erstellen Sie ein neues Projektverzeichnis und richten Sie die benötigten Dateien ein:
mkdir spark-serp-pipeline
cd spark-serp-pipeline
touch pipeline.py
touch config.py
mkdir -p output/checkpointÖffnen Sie config.py und fügen Sie Ihre Bright Data-Anmeldedaten sowie die Suchkonfiguration hinzu:
# config.py
BRIGHT_DATA_API_KEY = "YOUR_BRIGHT_DATA_API_KEY"
SERP_API_ZONE = "YOUR_SERP_API_ZONE"
# Die zu überwachende Suchanfrage (passen Sie diese an Ihren Anwendungsfall an)
SEARCH_QUERY = "artificial intelligence news"
# Wie oft ein neuer Mikro-Batch ausgelöst werden soll (in Sekunden)
TRIGGER_INTERVAL_SECONDS = 60
# Ausgabeverzeichnis für JSON-Ergebnisse
OUTPUT_PATH = "output/serp_results"
CHECKPOINT_PATH = "output/checkpoint"Sicherheitstipp: Vermeiden Sie in einer Produktionsumgebung die feste Einbindung von Anmeldedaten in Quelldateien. Verwenden Sie Umgebungsvariablen, einen Secrets-Manager (z. B. AWS Secrets Manager, Azure Key Vault, HashiCorp Vault) oder Databricks Secrets, um diese Werte zur Laufzeit einzufügen.
Schritt 2: Initialisieren Sie die SparkSession
Öffnen Sie pipeline.py und erstellen Sie zunächst Ihre SparkSession. Dies ist der Einstiegspunkt für alle Spark-Funktionen:
# pipeline.py
from pyspark.sql import SparkSession
from pyspark.sql.types import (
StructType, StructField, StringType, IntegerType, ArrayType
)
from pyspark.sql import functions as F
import requests
import json
import config
# Initialisieren der SparkSession
spark = SparkSession.builder
.appName("BrightDataSERPStream")
.config("spark.sql.shuffle.partitions", "4")
.getOrCreate()
# Reduzieren der Protokollausgabe für übersichtlichere Ergebnisse
spark.sparkContext.setLogLevel("WARN")
print("SparkSession initialisiert.")Die Einstellung von spark.sql.shuffle.partitions auf einen kleinen Wert wie 4 ist für eine lokale Entwicklungsumgebung geeignet. In einem Cluster würden Sie diesen Wert entsprechend der Datenmenge und der Anzahl der Executor-Kerne anpassen.
Schritt 3: Definieren der SERP-API-Abruf-Funktion
Definieren Sie als Nächstes die Python-Funktion, die die SERP-API von Bright Data aufruft und die geparsten Ergebnisse zurückgibt. Diese Funktion wird innerhalb des Spark-foreachBatch-Callbacks auf dem Driver aufgerufen, daher verwendet sie die Standard-Requests- Bibliothek anstelle eines verteilten Spark-Mechanismus:
# pipeline.py (Fortsetzung)
def fetch_serp_results(query: str) -> list[dict]:
"""
Ruft die SERP-API von Bright Data auf und gibt eine Liste der geparsten Nachrichtenergebnisse zurück.
Verwendet das Datenformat „parsed_light“ für eine kompakte, strukturierte JSON-Ausgabe.
"""
url = "https://api.brightdata.com/request"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {config.BRIGHT_DATA_API_KEY}"
}
payload = {
"Zone": config.SERP_API_ZONE,
"url": f"https://www.google.com/search?q={query}&tbm=nws&hl=en&gl=us",
"format": "raw",
"data_format": "parsed_light"
}
try:
response = requests.post(url, headers=headers, json=payload, timeout=30)
response.raise_for_status()
data = response.json()
# Das parsed_light-Format gibt ein „news“-Array mit Ergebnisobjekten zurück
results = data.get("news", [])
print(f"[SERP-API] {len(results)} Ergebnisse für die Suchanfrage: '{query}' abgerufen")
return results
except requests.exceptions.RequestException as e:
print(f"[SERP-API] Anfrage fehlgeschlagen: {e}")
return []Schauen wir uns die wichtigsten Anfrageparameter genauer an:
zone: Der Name Ihrer SERP-API-Zone aus dem Bright Data-Dashboard.url: Die Google-Such-URL. Der Parametertbm=nwsbeschränkt die Ergebnisse auf Google News.hl=enlegt die Sprache der Benutzeroberfläche auf Englisch fest, undgl=uszielt auf die Vereinigten Staaten ab, um geografisch gezielte Ergebnisse zu erhalten.format: Setzen Sie diesen Wert auf„raw“, um den Antworttext direkt zu erhalten.data_format: Setzen Sie den Wert auf„parsed_light“, um ein bereinigtes JSON-Array der wichtigsten organischen/Nachrichten-Ergebnisse mit Titeln, URLs, Quellen und Datumsangaben zu erhalten – ohne Anzeigen oder Knowledge Panels. Für vollständige SERP-Daten einschließlich Anzeigen und Knowledge Panels verwenden Sie„parsed“. Für eine LLM-freundliche Ausgabe verwenden Sie„markdown“.
Schritt 4: Erstellen der Streaming-Quelle mit dem Rate Generator
Da Spark Structured Streaming keine native HTTP-Quelle hat, verwenden wir ein bewährtes Muster: Die integrierte Rate-Quelle fungiert als Taktgeber und generiert eine Zeile pro Sekunde (oder pro konfigurierter Rate). Jeder von der Rate-Quelle erzeugte Mikro-Batch löst unseren foreachBatch-Callback aus, in dem wir die SERP-API aufrufen.
Fügen Sie die Rate-Stream-Definition zu pipeline.py hinzu:
# pipeline.py (Fortsetzung)
rate_stream = spark.readStream
.format("rate")
.option("rowsPerSecond", 1)
.load()
print("Rate-Stream erstellt. Die Pipeline wird in jedem Mikro-Batch-Intervall ausgelöst.")Die Rate-Quelle ist ausdrücklich für Tests und uhrgesteuerte Szenarien wie dieses konzipiert. Da in der Praxis API-Ratenbeschränkungen gelten, konfigurieren wir das Trigger-Intervall in Schritt 5 so, dass die Pipeline die SERP-API nur einmal pro Minute aufruft, nicht einmal pro Sekunde.
Schritt 5: Definieren des foreachBatch -Handlers
Der „foreachBatch“-Handler ist das Herzstück der Pipeline. Spark ruft diese Funktion bei jedem Mikro-Batch auf und übergibt dabei ein DataFrame mit den Zeilen dieses Batches sowie eine eindeutige Batch-ID. Innerhalb der Funktion rufen wir die SERP-API auf, konvertieren die Ergebnisse in ein Spark-DataFrame, wenden Transformationen an und schreiben in den Output-Sink:
# pipeline.py (Fortsetzung)
# Definieren des Schemas für geparste SERP-Ergebnisse
serp_schema = StructType([
StructField("title", StringType(), True),
StructField("link", StringType(), True),
StructField("source", StringType(), True),
StructField("date", StringType(), True),
StructField("global_rank", IntegerType(), True),
])
def process_batch(batch_df, batch_id):
"""
Wird von Spark bei jedem Micro-Batch-Trigger aufgerufen.
Ruft SERP-Daten von Bright Data ab, konvertiert die Ergebnisse in einen DataFrame
und schreibt sie in den Output-Sink.
"""
print(f"n--- Verarbeitung von Batch {batch_id} ---")
# Abrufen von Live-SERP-Ergebnissen von Bright Data
results = fetch_serp_results(config.SEARCH_QUERY)
if not results:
print(f"Batch {batch_id}: Keine Ergebnisse zurückgegeben. Schreiben überspringen.")
return
# Konvertiert die Ergebnisliste in einen Spark DataFrame
results_df = spark.createDataFrame(results, schema=serp_schema)
# Metadaten-Spalten zur Nachverfolgung hinzufügen
enriched_df = results_df
.withColumn("query", F.lit(config.SEARCH_QUERY))
.withColumn("batch_id", F.lit(batch_id))
.withColumn("ingested_at", F.current_timestamp())
# Zur besseren Übersicht auf die Konsole ausgeben
enriched_df.show(truncate=False)
# In JSON-Datei schreiben (Anfüge-Modus, partitioniert nach Erfassungsdatum)
enriched_df
.withColumn("ingestion_date", F.to_date("ingested_at"))
.write
.mode("append")
.partitionBy("ingestion_date")
.json(config.OUTPUT_PATH)
print(f"Batch {batch_id}: {enriched_df.count()} Datensätze in {config.OUTPUT_PATH} geschrieben")Einige Anmerkungen zu diesem Entwurf:
spark.createDataFrame(results, schema=serp_schema) konvertiert die von der SERP-API zurückgegebene Python-Liste von Dictionaries in einen typisierten Spark DataFrame. Die Angabe eines expliziten Schemas ist der Schema-Inferenz vorzuziehen – sie macht den Job schneller und vorhersehbarer.
F.lit(batch_id) fügt jeder Zeile die aktuelle Mikro-Batch-ID hinzu, was für die Deduplizierung nützlich ist, wenn die Pipeline einen fehlgeschlagenen Batch erneut versucht (da foreachBatch standardmäßig eine „At-Least-Once“-Zustellungsgarantie bietet).
F.current_timestamp() versieht jede Zeile mit einem Zeitstempel, der die Erfassungszeit auf dem Treiber angibt, und liefert Ihnen so einen zuverlässigen Prüfpfad darüber, wann jedes Ergebnis in die Pipeline gelangt ist.
Schritt 6: Starten der Streaming-Abfrage
Verbinden Sie nun alles miteinander, indem Sie den foreachBatch -Handler an den Rate-Stream anhängen und die Abfrage starten:
# pipeline.py (Fortsetzung)
# Den foreachBatch-Handler anhängen und das Trigger-Intervall konfigurieren
query = rate_stream.writeStream
.foreachBatch(process_batch)
.trigger(processingTime=f"{config.TRIGGER_INTERVAL_SECONDS} Sekunden")
.option("checkpointLocation", config.CHECKPOINT_PATH)
.start()
print(f"Streaming-Abfrage gestartet. Wird alle {config.TRIGGER_INTERVAL_SECONDS} Sekunden ausgelöst.")
print("Drücken Sie Strg+C, um zu stoppen.")
# Warten, bis die Abfrage beendet ist (läuft unbegrenzt, bis sie unterbrochen wird)
query.awaitTermination()Der Aufruf .trigger(processingTime="60 seconds") weist Spark an, alle 60 Sekunden – einmal pro Minute – einen neuen Mikro-Batch auszulösen, unabhängig davon, wie viele Zeilen die Rate-Quelle generiert hat. Dies ist der Mechanismus, der Ihre SERP-API-Aufrufe taktet und dafür sorgt, dass Sie die Ratenbeschränkungen einhalten, während der Betrieb dennoch kontinuierlich läuft.
Die Option .option("checkpointLocation", ...) ist entscheidend für die Fehlertoleranz. Spark schreibt die Metadaten zum Fortschritt der Abfrage (Offsets, festgeschriebene Batches) in dieses Verzeichnis. Wenn der Prozess abstürzt und neu gestartet wird, liest Spark den Checkpoint, um festzustellen, welche Batches bereits verarbeitet wurden, und setzt den Vorgang sauber an der richtigen Stelle fort.
Schritt 7: Ausführen und Überprüfen der Ergebnisse
Führen Sie die Pipeline von Ihrem Terminal aus aus:
python pipeline.pyNach dem Auslösen des ersten Triggers sollten Sie eine Ausgabe ähnlich der folgenden sehen:
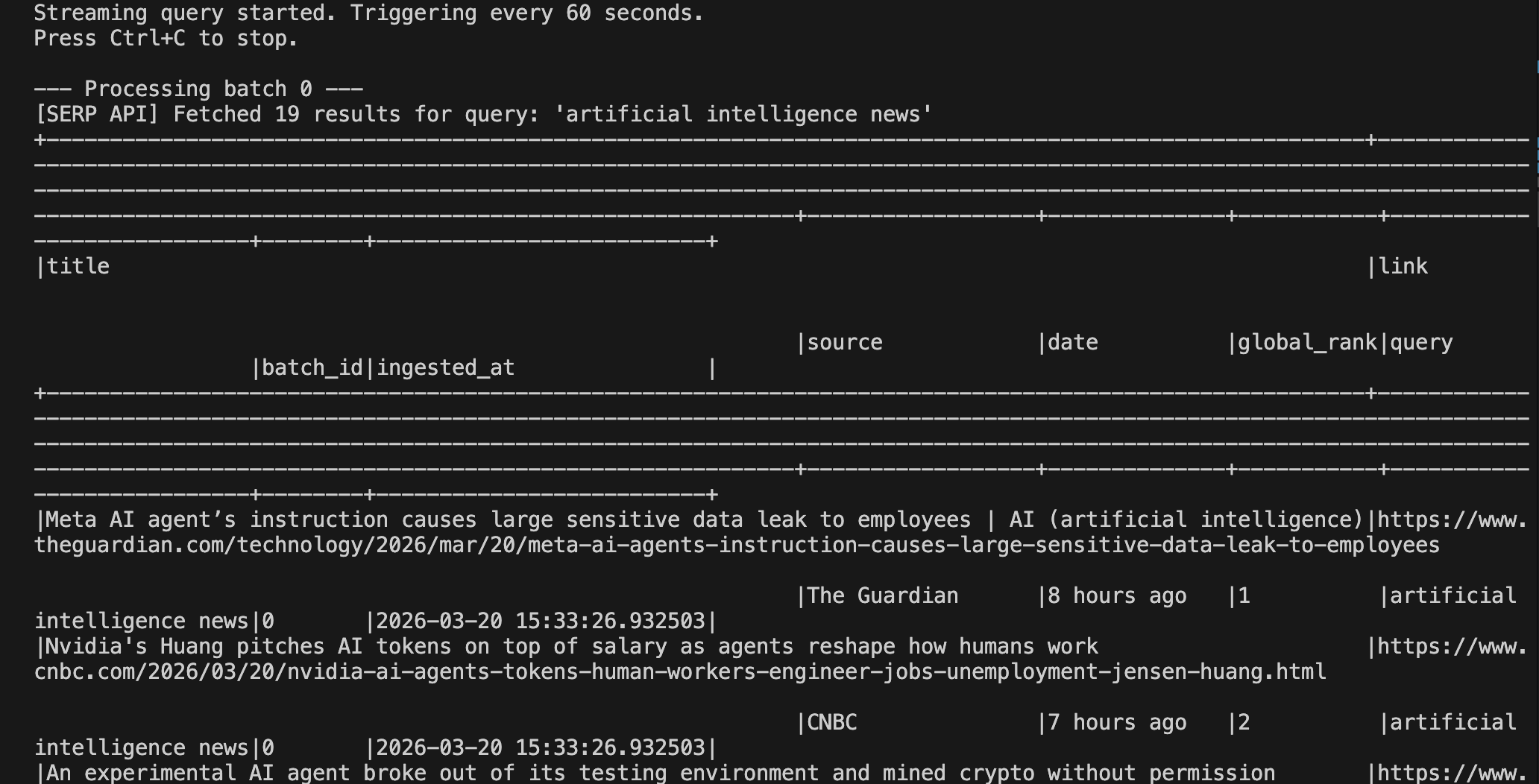
Sie können die Ausgabe auf Spark unter localhost:4040 sehen:
Überprüfen Sie nach einigen Minuten Laufzeit das Ausgabeverzeichnis:
ls output/serp_results/
ls output/serp_results/ingestion_date=2025-03-19/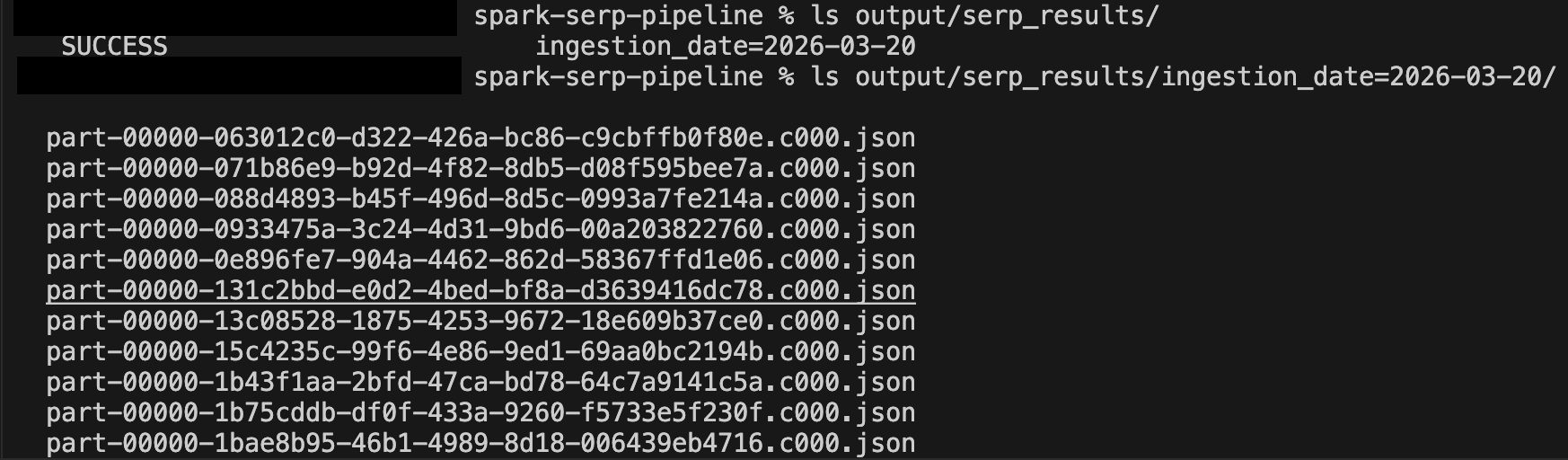
Sie können die Ergebnisse jederzeit zur Ad-hoc-Analyse wieder in Spark einlesen:
# Die gesammelten Ergebnisse zurücklesen
df = spark.read.json("output/serp_results/")
df.orderBy("ingested_at", ascending=False).show(20, truncate=False)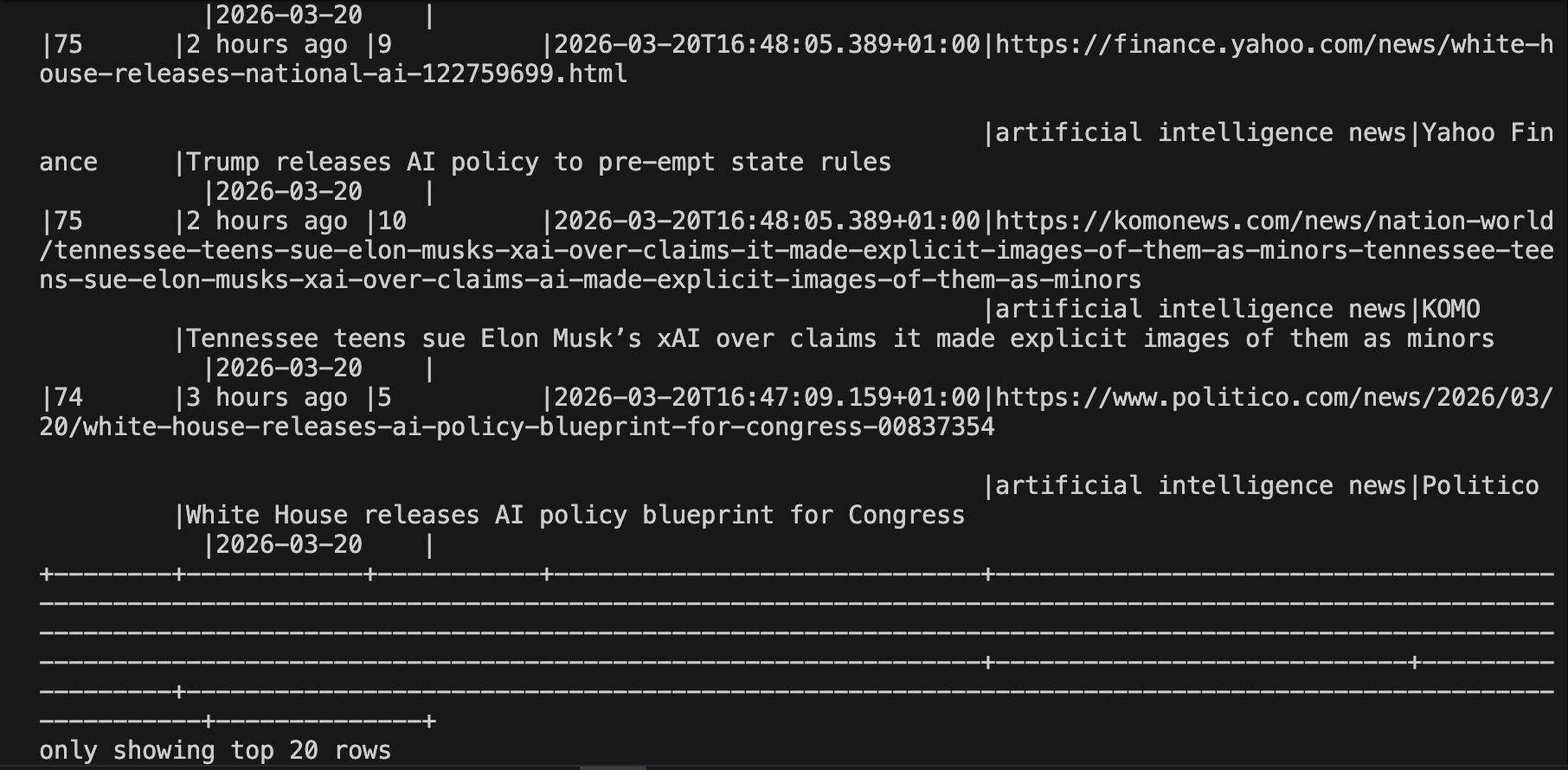
Hier finden Sie den vollständigen Pipeline-Code an einem Ort zur einfachen Bezugnahme.
Weiterführende Möglichkeiten
Dieses Beispiel veranschaulicht ein grundlegendes Erfassungsmuster, aber es gibt viele Möglichkeiten, wie Sie darauf aufbauen können:
- Anstelle eines einzigen Themas können Sie eine Liste von Schlüsselwörtern führen und innerhalb jedes
foreachBatch-Aufrufs parallele SERP-API-Aufrufe ausführen. Verwenden Sie Python’sconcurrent.futures.ThreadPoolExecutor, um die API für mehrere Abfragen gleichzeitig innerhalb desselben Mikro-Batches aufzurufen. - Ersetzen Sie den JSON-Sink durch eine Delta-Tabelle für ACID-konforme, inkrementelle Schreibvorgänge mit Unterstützung für Schema-Evolution. Dies vereinfacht historische Abfragen und die Deduplizierung erheblich.
- Die SERP-API von Bright Data unterstützt neben Google, DuckDuckGo und Yandex auch Suchanfragen bei der Bing-Suchmaschine. Abfragen Sie mehrere Suchmaschinen parallel innerhalb desselben Batches ab und führen Sie die Ergebnismengen zusammen.
- Verwenden Sie den Web Unlocker von Bright Data, um den von der SERP-API zurückgegebenen URLs zu folgen und den vollständigen HTML- oder Markdown-Inhalt jedes Artikels abzurufen. Leiten Sie diesen Inhalt in eine nachgelagerte NLP-Stufe innerhalb derselben Spark-Pipeline weiter.
- Stellen Sie die Pipeline auf Databricks, AWS EMR oder Google Dataproc bereit, um Skalierbarkeit auf Produktionsniveau zu erreichen. Auf Databricks können Sie außerdem Delta Live Tables verwenden, um die Pipeline deklarativ zu verwalten.
- Schreiben Sie die angereicherten SERP-Ergebnisse in ein Kafka-Topic und nutzen Sie sie in Echtzeit in nachgelagerten Microservices, Dashboards oder Warnsystemen.
Fazit
In diesem Tutorial haben Sie gelernt, wie Sie die SERP-API von Bright Data nutzen, um kontinuierlich Live-Suchergebnisse zu erfassen und diese mit Apache Spark Structured Streaming zu verarbeiten. Unter Verwendung der Rate-Source als Scheduling-Clock und foreachBatch als Integrationsbrücke haben Sie eine kontinuierlich laufende Pipeline erstellt, die bei jedem Trigger aktuelle SERP-Daten abruft, diese in ein typisiertes Spark DataFrame umwandelt und die Ergebnisse in einen partitionierten JSON-Sink schreibt – alles mit integrierter fehlertoleranter Checkpointing-Funktion.
Dieses Muster ist ideal für jedes Team, das Web-Suchsignale in Echtzeit und in großem Umfang verarbeiten muss: Keyword-Ranking-Tracking, Wettbewerbsbeobachtung, Nachrichtenaggregation, Ad Intelligence und mehr. Im Gegensatz zu ad-hoc-Skript-basierten Abfragen bietet Ihnen eine Spark Structured Streaming-Pipeline eine verteilte, wiederherstellbare und leicht erweiterbare Grundlage, die mit Ihren Datenmengen mitwächst.
Um komplexere Pipelines zu erstellen, entdecken Sie die gesamte Palette an Webdatenprodukten von Bright Data, darunter den Web Unlocker zum Umgehen von Bot-Schutzmaßnahmen auf beliebigen URLs, den Scraping-Browser für JavaScript-lastige Websites und vorgefertigte Datensätze für die beliebtesten Plattformen.
Eröffnen Sie noch heuteein kostenloses Bright Data-Konto und versorgen Sie Ihre Datenpipelines mit zuverlässigen Webdaten in Echtzeit.






