

In diesem Tutorial lernst du:
- Wie man Snowflake einrichtet, um Daten aus der Lieferinfrastruktur von Bright Data zu empfangen.
- Den Goodreads-Bücher-Datensatz so konfigurieren, dass er direkt in einen internen Snowflake-Stage geliefert wird.
- Einen Snapshot auslösen und in eine abfragbare Tabelle laden, dann SQL gegen über 6 Millionen Bucheinträge ausführen.
Los geht’s!
Der Snowflake-Ingestion-Workflow im Überblick
Die Pipeline besteht auf hoher Ebene aus drei Phasen, die jeweils in einem eigenen Abschnitt behandelt werden:
- Snowflake-Einrichtung: Erstelle die Datenbank, den Stage, die Rolle und den Service-Benutzer, gegen den sich Bright Data authentifiziert. Dies ist der SQL-intensivste Teil, aber jeder Befehl wird vollständig angegeben und läuft der Reihe nach.
- Bright Data-Konfiguration: Wähle einen Datensatz aus dem Marketplace, verbinde ihn mit deiner Snowflake-Umgebung und löse einen Snapshot aus. Bright Data überträgt die Dateien direkt in deinen internen Stage.
- Laden und Abfragen: Ein einziger
COPY INTO-Befehl verschiebt die gestagten Dateien in eine strukturierte Tabelle. Der Rest ist Standard-SQL.
Das Ergebnis ist eine vollständig abfragbare Snowflake-Tabelle, die mit strukturierten Web-Daten befüllt ist und nach dem für deinen Anwendungsfall erforderlichen Zeitplan aktualisiert wird. Keine CSV-Exporte, kein benutzerdefinierter ETL-Verbindungscode.
Erfahre mehr über jede Phase und wie du sie umsetzt!
1. Snowflake-Einrichtung
Bright Data liefert Dateien, indem es sich direkt in deinen Snowflake-Account authentifiziert. Dazu ist ein dedizierter interner Stage (eine Ladezone für eingehende Dateien), eine Service-Rolle mit Schreibzugriff auf diesen Stage und ein dieser Rolle zugewiesener Service-Benutzer erforderlich.
Die Verwendung dedizierter Objekte für diesen Zweck hält die Ingestion von deinen analytischen Arbeitslasten getrennt und erleichtert das spätere Prüfen, Widerrufen oder Rotieren von Anmeldeinformationen.
2. Bright Data-Datensatz-Konfiguration und Snapshot-Lieferung
Der Dataset Marketplace von Bright Data enthält vorgefertigte, validierte Datensätze zu Amazon, LinkedIn, Crunchbase, Glassdoor, Hoteleinträgen, Immobilien, Stellenanzeigen und mehr. Jeder Datensatz wird mit einer vollständigen Feldreferenz geliefert, sodass du dein Snowflake-Schema entwerfen kannst, bevor das erste Byte ankommt.
Die direkte Snowflake-Lieferung ist für das Datasets-Produkt verfügbar. Wenn du stattdessen die Web Scraper APIs verwendest, liefere Dateien in einen S3-Bucket und lade sie aus einem externen Stage.
Sobald du Snowflake als Lieferziel konfigurierst, übernimmt Bright Data die Übertragung. Es authentifiziert sich mit dem von dir erstellten Service-Benutzer, staged die Dateien in deinen internen Stage und protokolliert die Lieferung im Control Panel. Du kannst Snapshots auf Anfrage, nach einem Zeitplan oder über die Marketplace Dataset API auslösen.
3. Laden und Abfragen
Mit Dateien im Stage lädt ein einziger COPY INTO-Befehl sie in deine Tabelle. Von dort aus kannst du mit Standard-SQL abfragen, ohne spezielle Syntax oder neue Tools.
Snowflake für den Empfang von Bright Data einrichten
Beginnen wir mit dem Aufbau der Pipeline, indem wir die Snowflake-Seite vorbereiten. Alle Befehle in diesem Abschnitt werden im SQL-Arbeitsblatt von Snowsight oder über SnowSQL ausgeführt. Führe dies zuerst aus, um sicherzustellen, dass du die erforderlichen Berechtigungen zum Erstellen von Datenbanken, Rollen und Benutzern hast:
USE ROLE ACCOUNTADMIN;Voraussetzungen
Um diesem Abschnitt zu folgen, solltest du Folgendes haben:
- Einen Snowflake-Account mit
ACCOUNTADMIN– oderSYSADMIN-Berechtigungen. - Grundlegende Vertrautheit mit der Snowflake-Benutzeroberfläche (Snowsight).
Schritt #1: Datenbank und Schema erstellen
In Snowflake ist eine Datenbank der übergeordnete Container für alle deine Datenobjekte. Ein Schema befindet sich innerhalb einer Datenbank und gruppiert zusammengehörige Tabellen, Stages und andere Objekte. Das Erstellen einer dedizierten Datenbank und eines Schemas für Bright Data hält deren Objekte von deinen bestehenden Daten getrennt und erleichtert die Verwaltung von Berechtigungen.
CREATE DATABASE IF NOT EXISTS bright_data_db;
CREATE SCHEMA IF NOT EXISTS bright_data_db.web_data;Du kannst auch eine bestehende Datenbank verwenden. Ersetze ihren Namen überall dort, wo bright_data_db in den folgenden Befehlen erscheint.
Schritt #2: Einen dedizierten Warehouse erstellen
In Snowflake ist ein Warehouse der Compute-Cluster, der SQL-Anweisungen ausführt, einschließlich COPY INTO. Er ist vom Speicher getrennt, was bedeutet, dass du nur für Compute bezahlst, während er aktiv läuft. Ein dedizierter Warehouse für die Bright Data-Ingestion macht diese Compute-Kosten sichtbar und verhindert, dass Ingestion-Workloads mit deinen analytischen Abfragen um Ressourcen konkurrieren.
CREATE WAREHOUSE IF NOT EXISTS bright_data_wh
WAREHOUSE_SIZE = 'XSMALL'
AUTO_SUSPEND = 60
AUTO_RESUME = TRUE;AUTO_SUSPEND = 60 fährt den Warehouse nach 60 Sekunden Inaktivität herunter, damit er zwischen Lieferungen nicht im Leerlauf läuft. AUTO_RESUME = TRUE startet ihn automatisch wieder, wenn der nächste COPY INTO-Befehl ausgeführt wird. XSmall bewältigt die meisten Bright Data-Lieferungen problemlos. Passe die Größe an, wenn das Volumen wächst.
Schritt #3: Einen internen benannten Stage erstellen
In Snowflake ist ein Stage ein benannter Ort, an dem Dateien liegen, bevor sie in eine Tabelle geladen werden. Ein interner benannter Stage befindet sich innerhalb von Snowflake selbst. Kein S3-Bucket oder externer Cloud-Speicher erforderlich.
Dieser Stage ist die Brücke zwischen Bright Data und deiner Tabelle. Anstatt Daten direkt Zeile für Zeile in eine Tabelle zu laden, legt Bright Data zuerst strukturierte Dateien (Parquet oder JSON) in den Stage. Snowflake liest diese Dateien dann per Massenverarbeitung über COPY INTO, was deutlich schneller und kostengünstiger als zeilenweise Einfügungen ist. Es gibt dir auch einen Kontrollpunkt: Du kannst die Dateien im Stage inspizieren, prüfen, ob sie korrekt aussehen, und wählen, wann du den Ladevorgang auslöst.
CREATE STAGE IF NOT EXISTS bright_data_db.web_data.bright_data_stage
COMMENT = 'Landing zone for Bright Data dataset deliveries';Schritt #4: Eine Rolle erstellen und ihr die richtigen Berechtigungen erteilen
In Snowflake ist eine Rolle eine Sammlung von Berechtigungen, die Benutzern zugewiesen werden können. Anstatt Berechtigungen direkt einem Benutzer zu gewähren, erteilst du sie einer Rolle und weist diese Rolle dem Benutzer zu. Dies erleichtert das spätere Widerrufen oder Ändern des Zugriffs, ohne das Benutzerkonto selbst anzufassen.
Diese Rolle gibt Bright Data genau den benötigten Zugriff und nicht mehr.
CREATE ROLE IF NOT EXISTS bright_data_loader;
-- Allow the role to use the database and schema
GRANT USAGE ON DATABASE bright_data_db TO ROLE bright_data_loader;
GRANT USAGE ON SCHEMA bright_data_db.web_data TO ROLE bright_data_loader;
-- Allow the role to use and operate the warehouse
GRANT USAGE ON WAREHOUSE bright_data_wh TO ROLE bright_data_loader;
GRANT OPERATE ON WAREHOUSE bright_data_wh TO ROLE bright_data_loader;
-- Allow the role to write files into the stage
-- READ must be granted alongside WRITE; Snowflake requires it for COPY INTO ... FROM @stage
GRANT READ ON STAGE bright_data_db.web_data.bright_data_stage
TO ROLE bright_data_loader;
GRANT WRITE ON STAGE bright_data_db.web_data.bright_data_stage
TO ROLE bright_data_loader;Hier ist, was jede Erteilung bewirkt und warum sie erforderlich ist:
- USAGE auf Datenbank und Schema: Ermöglicht der Rolle, die darin enthaltenen Objekte zu sehen und zu navigieren. Ohne dies gibt Snowflake einen Fehler “Objekt existiert nicht” zurück, selbst wenn die Rolle direkte Berechtigungen für den Stage hat.
- USAGE auf Warehouse: Ermöglicht der Rolle, SQL-Anweisungen gegen den Warehouse auszuführen. Das ist es, was
COPY INTOtatsächlich ausführen lässt. - OPERATE auf Warehouse: Ermöglicht der Rolle, den Warehouse fortzusetzen, wenn er angehalten wurde. Ohne dies wird ein automatisch angehaltener Warehouse nicht wieder hochgefahren, wenn Bright Data einen Ladevorgang auslöst.
- READ auf Stage: Erforderlich, damit
COPY INTOdie Dateien aus dem Stage lesen und in die Tabelle laden kann. - WRITE auf Stage: Erforderlich, damit Bright Data überhaupt Dateien in den Stage ablegen kann.
Schritt #5: Den Bright Data Service-Benutzer erstellen
Ein Service-Benutzer ist ein Snowflake-Account, der für ein System oder eine Anwendung anstelle einer Person erstellt wird. Die Verwendung eines dedizierten Service-Benutzers bedeutet, dass der Zugriff von Bright Data von menschlichen Benutzerkonten isoliert ist, und du seine Anmeldeinformationen rotieren oder widerrufen kannst, ohne andere zu beeinflussen.
CREATE USER IF NOT EXISTS brightdata_svc
PASSWORD = 'YourStrongPasswordHere'
LOGIN_NAME = 'brightdata_svc'
DEFAULT_ROLE = bright_data_loader
DEFAULT_WAREHOUSE = bright_data_wh
DEFAULT_NAMESPACE = bright_data_db.web_data
MUST_CHANGE_PASSWORD = FALSE
DISABLED = FALSE
COMMENT = 'Service user for Bright Data dataset delivery';
GRANT ROLE bright_data_loader TO USER brightdata_svc;MUST_CHANGE_PASSWORD = FALSE verhindert, dass Snowflake beim ersten Login zur Passwortänderung auffordert, was eine automatisierte Verbindung unterbrechen würde. DEFAULT_ROLE, DEFAULT_WAREHOUSE und DEFAULT_NAMESPACE stellen sicher, dass der Service-Benutzer immer mit dem richtigen Kontext verbindet, unabhängig davon, wie die Sitzung initiiert wird. Die letzte Zeile weist dem Benutzer die Rolle bright_data_loader zu und gibt ihm genau die in Schritt #4 definierten Berechtigungen.
Speichere Benutzername und Passwort sicher. Du wirst sie im nächsten Abschnitt in das Bright Data Control Panel einfügen.
Schritt #6: Bright Data-IPs zur Allowlist hinzufügen (bei Verwendung einer Netzwerkrichtlinie)
Wenn dein Snowflake-Account eine Netzwerkrichtlinie durchsetzt, müssen die Lieferserver von Bright Data zur erlaubten Liste hinzugefügt werden. Die folgenden IPs waren zum Zeitpunkt der Erstellung aktuell. Überprüfe die neuesten Bereiche mit dem Bright Data-Support oder deren Dokumentation, bevor du sie anwendest, da sich Statische IPs ändern können:
ALTER NETWORK POLICY your_policy_name
SET ALLOWED_IP_LIST = (
-- paste your existing allowed IPs here,
'35.169.71.210',
'34.233.211.38',
'44.194.183.74',
'54.243.177.151'
);Wenn dein Account keine aktive Netzwerkrichtlinie hat, überspringe diesen Schritt.
Schritt #7: Die Zieltabelle erstellen
Dieses Tutorial verwendet Goodreads-Buchdaten als Beispiel. Das folgende Schema bildet direkt die Feldnamen ab, die der Goodreads-Bücher-Datensatz von Bright Data in JSON liefert:
CREATE TABLE IF NOT EXISTS bright_data_db.web_data.goodreads_books (
id VARCHAR, -- Goodreads book ID
name VARCHAR, -- book title
url VARCHAR,
author VARIANT, -- array: [{name, num_books, num_followers}]
star_rating FLOAT, -- average rating 1-5
num_ratings INT, -- total number of ratings
num_reviews VARCHAR, -- total reviews (may be formatted, e.g. "1,234")
summary VARCHAR, -- book description/blurb
genres VARIANT, -- array of genre strings
first_published VARCHAR, -- publication date as text
about_author VARIANT, -- object: {name, num_books, num_followers}
community_reviews VARIANT -- object: {5_stars, 4_stars, ...} with counts and percentages
);VARIANT ist Snowflakes halbstrukturierter Typ. Er speichert Arrays und verschachtelte Objekte unverändert und ermöglicht dir, mit Punktnotation und Klammernsyntax darauf zuzugreifen (author[0]:name, community_reviews['5_stars']:reviews_num). Dies vermeidet das Abflachen komplexer verschachtelter Felder beim Laden. Du kannst das später mit einer View oder einem LATERAL FLATTEN tun, sobald du weißt, welche Unterfelder du benötigst.
Einige Feldentscheidungen sind es wert, verstanden zu werden:
authorals VARIANT: Jedes Buch kann mehrere Autoren haben. Das Feld kommt als Array von Objekten an. Die Speicherung als VARIANT bewahrt alle Autorendaten, ohne eine separate Join-Tabelle zu benötigen.genresals VARIANT: Genre ist ebenfalls ein Array. Ein Buch kann mehreren Genres angehören. Flache es mitLATERAL FLATTEN(INPUT => genres)ab, wenn du nach Genre abfragen musst.num_reviewsals VARCHAR: Das Datenwörterbuch von Bright Data kennzeichnet dieses Feld als Text statt als Zahl, was bedeutet, dass es formatiert ankommen kann (z. B."1.234"statt1234). Konvertiere es zur Abfragezeit mitTO_NUMBER(REPLACE(num_reviews, ',', '')), wenn du darüber aggregieren musst.community_reviewsals VARIANT: Enthält eine Aufschlüsselung der Bewertungen nach Sternenanzahl, jeweils mit einer Anzahl und einem Prozentsatz. Speichere als VARIANT und frage spezifische Sternebenen nach Bedarf ab.
Hinweis: Wenn du einen anderen Datensatz aus dem Marketplace auswählst (LinkedIn-Unternehmen, Stellenanzeigen, Amazon-Produkte usw.), passe das Schema an dessen Feldliste an. Bright Data stellt für jeden Datensatz eine vollständige Feldreferenz auf der Datensatzseite im Control Panel bereit.
Ausgezeichnet! Deine Snowflake-Umgebung ist jetzt bereit, Daten von Bright Data zu empfangen.
Bright Data für die Lieferung an Snowflake konfigurieren
Mit der Snowflake-Seite an Ort und Stelle konfigurieren wir nun Bright Data, um Daten dorthin zu übertragen.
Voraussetzungen
Um diesem Abschnitt zu folgen, solltest du Folgendes haben:
- Einen Bright Data-Account mit einem aktiven Abonnement oder einer Testversion.
- Die Snowflake-Verbindungsdetails aus dem vorherigen Abschnitt: Account-Bezeichner, Benutzername, Passwort, Datenbank, Schema, Stage und Warehouse-Namen.
Schritt #1: Einen Datensatz auswählen
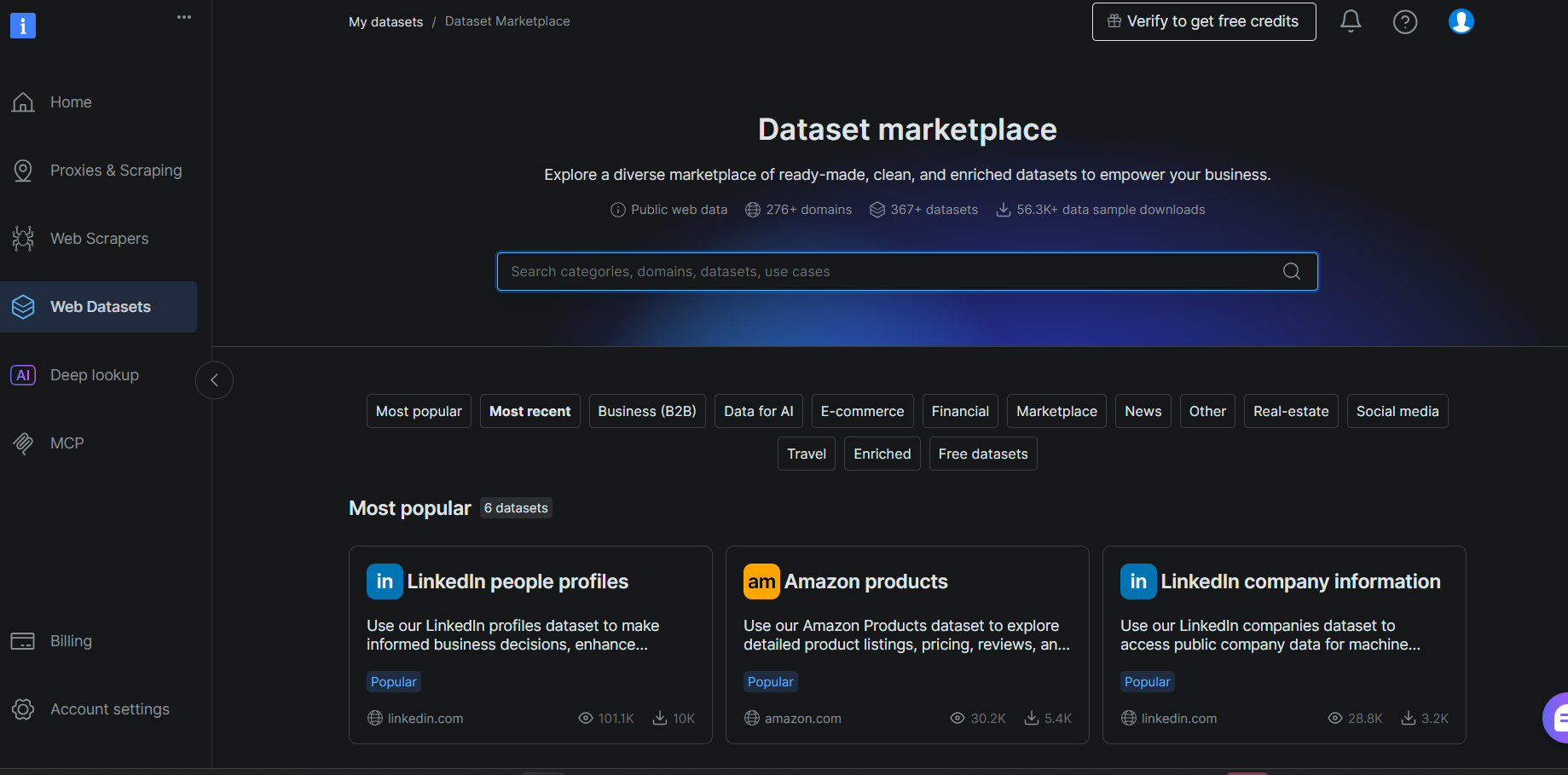
Melde dich in deinem Bright Data-Account an und navigiere zu Web Datasets > Dataset Marketplace. Suche nach Goodreads und wähle den Goodreads Books-Datensatz aus den Ergebnissen aus.
Überprüfe auf der Datensatzseite die Feldliste im linken Panel. Beachte, wie jedes Feld direkt einer Spalte in der in Schritt #7 erstellten Tabelle entspricht. Dies bestätigt, dass dein Schema korrekt ist, bevor eine einzige Zeile ankommt.
Schritt #2: Snowflake als Lieferziel konfigurieren
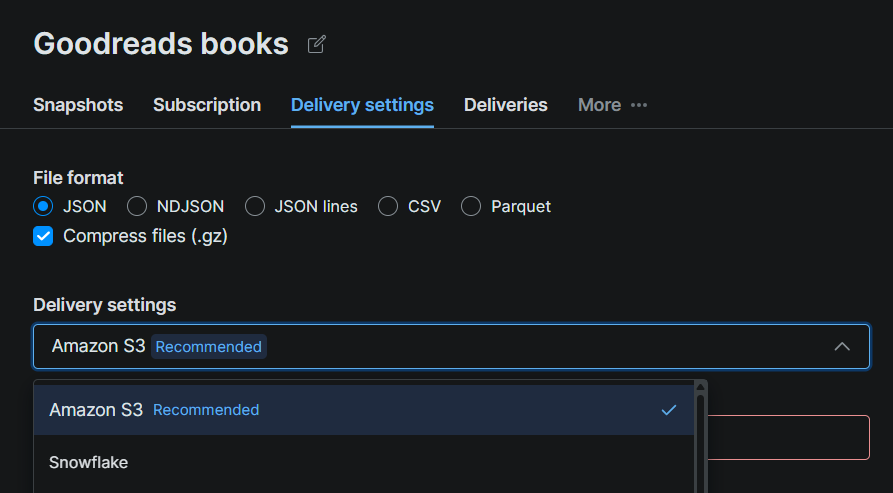
Klicke auf den Tab Delivery Settings auf der Datensatzseite und wähle Snowflake als Ziel aus. Fülle das Verbindungsformular mit den Details aus deiner Snowflake-Einrichtung aus:
| Feld | Wert |
|---|---|
| Account-Bezeichner | Deine Snowflake-Account-URL (z. B. xy12345.us-east-1) |
| Datenbank | bright_data_db |
| Schema | web_data |
| Stage | bright_data_stage |
| Warehouse | bright_data_wh |
| Rolle | bright_data_loader |
| Benutzer | brightdata_svc |
| Passwort | Das in Schritt #5 festgelegte Passwort |
Die drei Felder unterhalb des Verbindungsformulars sind optional und können für dieses Tutorial auf ihren Standardwerten belassen werden:
- Dataset-Dateiname: Ein benutzerdefiniertes Präfix für die Dateien, die Bright Data staged. Leer lassen, um die Standardbenennung zu verwenden.
- Batch-Größe (Anzahl der Datensätze): Wie viele Datensätze Bright Data in jede gestagete Datei packt. Der Standard ist für die meisten Workloads geeignet.
- Batches in eine Datei gruppieren (.tar): Kombiniert alle Batches in ein einzelnes Archiv vor dem Staging. Deaktiviert lassen, es sei denn, deine Pipeline erfordert ausdrücklich eine einzelne Datei pro Lieferung.
Klicke auf Test Snowflake. Eine grüne Bestätigung bedeutet, dass Bright Data sich authentifizieren und in deinen Stage schreiben kann. Sobald der Test bestanden ist, klicke auf Speichern.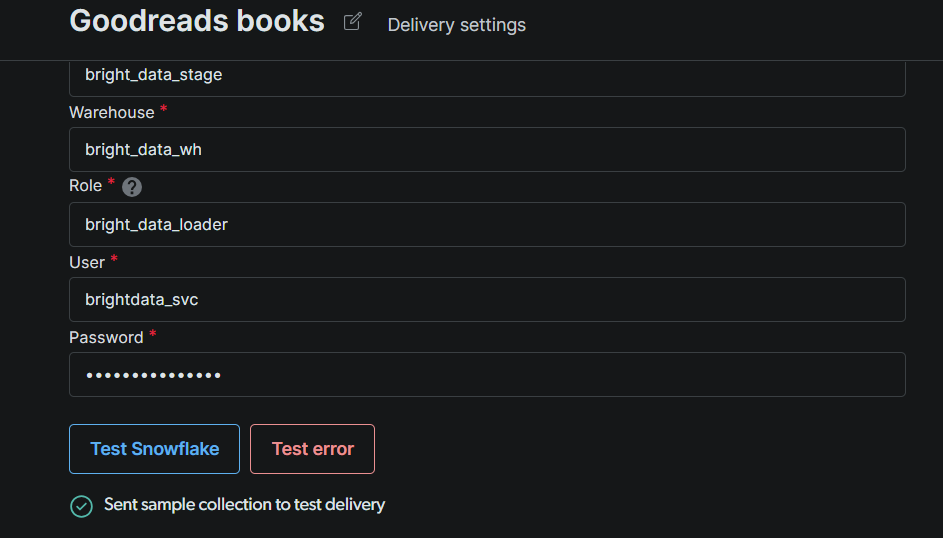
Hinweis: Wenn der Test fehlschlägt, überprüfe der Reihe nach drei Dinge: (1) das Format des Account-Bezeichners (Snowflake erwartet orgname-accountname oder das ältere Format accountid.region.cloud); (2) ob der Service-Benutzer alle Erteilungen aus Schritt #4 hat, einschließlich der Rollenzuweisung; (3) ob die IPs von Bright Data auf der Allowlist stehen, wenn dein Account eine aktive Netzwerkrichtlinie hat.
Schritt #3: Einen Snapshot anfordern
Klicke auf der Datensatzseite auf den Tab Deliveries. Klicke dann auf Add delivery + in der oberen rechten Ecke. Dies öffnet ein Lieferungskonfigurationspanel, in dem du dein Ziel (Snowflake) auswählst, einen Snapshot oder Datumsbereich für die Lieferung wählst und bestätigst.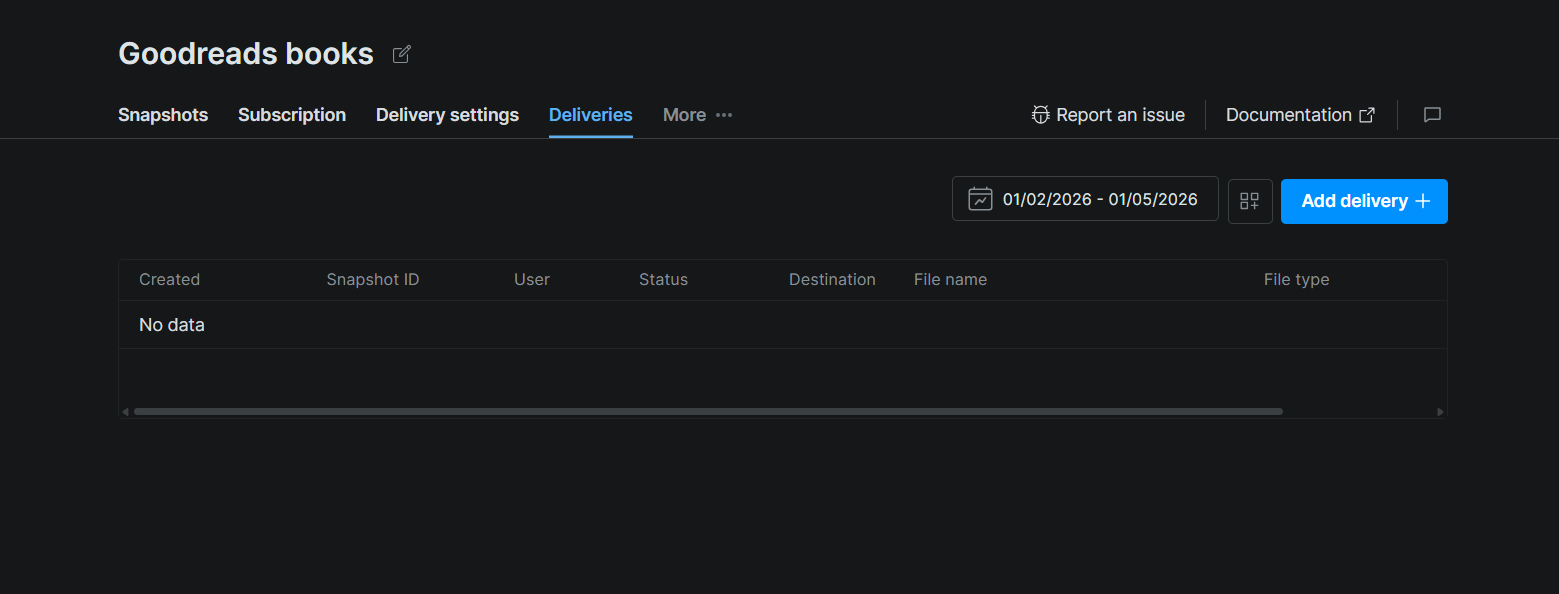
Nach dem Einreichen erscheint die Lieferung in der Tabelle mit Spalten für Snapshot-ID, Status, Ziel, Dateiname und Dateityp. Der Status wechselt von ausstehend zu abgeschlossen, wenn Bright Data die Dateien in deinen Stage übertragen hat.
Um Lieferungen programmatisch auszulösen, verwendet die Marketplace Dataset API einen zweistufigen Ablauf: Rufe zuerst die Filter-API auf, um einen gefilterten Snapshot zu erstellen, und rufe dann Deliver Snapshot auf, um ihn in deinen Snowflake-Stage zu übertragen.
Schritt 1: Einen gefilterten Snapshot erstellen:
curl --request POST \
--url "https://api.brightdata.com/datasets/filter" \
--header "Authorization: Bearer YOUR_API_TOKEN" \
--header "Content-Type: application/json" \
--data '{
"dataset_id": "YOUR_DATASET_ID",
"filter": {
"operator": "and",
"filters": [
{"name": "star_rating", "operator": ">", "value": "4"},
{"name": "num_ratings", "operator": ">", "value": "1000"}
]
}
}'Die Antwort enthält eine snapshot_id. Übergib diese an den nächsten Aufruf.
Schritt 2: Den Snapshot in deinen Snowflake-Stage liefern:
curl --request POST \
--url "https://api.brightdata.com/datasets/snapshots/YOUR_SNAPSHOT_ID/deliver" \
--header "Authorization: Bearer YOUR_API_TOKEN" \
--header "Content-Type: application/json" \
--data '{
"destination": "snowflake"
}'Bright Data verwendet standardmäßig das für deinen Datensatz konfigurierte Format. Wenn du es explizit angeben möchtest, füge "format": "parquet" oder "format": "ndjson" zum Anfrage-Body hinzu. Welches Format auch immer im Stage ankommt, das ist dasjenige, das du an FILE_FORMAT in COPY INTO übergibst.
Rufe GET /datasets/snapshots/YOUR_SNAPSHOT_ID ab, um den Lieferstatus zu prüfen, oder überwache ihn im Tab Deliveries des Control Panels. Wenn die Statusspalte abgeschlossen anzeigt, befinden sich deine Dateien im Stage und sind bereit zum Laden. Großartig!
Wenn die Lieferung abgeschlossen ist, erhältst du auch eine E-Mail mit einem Link zur Snapshot-Seite im Control Panel. Dort kannst du eine Vorschau der ersten 30 Datensätze anzeigen, die Gesamtanzahl der Datensätze prüfen und einen Kostenzusammenfassungsbericht herunterladen. Zu 2,50 $ pro 1.000 Datensätze zeigt der Bericht genau, wie viele Datensätze angekommen sind und was sie gekostet haben. Großartig!
Die Daten in Snowflake laden
Der Job von Bright Data endet, wenn die Dateien in deinem internen Stage landen. Das Laden in die Tabelle liegt in deiner Verantwortung und erfordert einen einzigen SQL-Befehl. Diese Trennung ist es wert, verstanden zu werden: Sie bedeutet, dass du kontrollierst, wann der Ladevorgang läuft, welche Fehlerbehandlung gilt und wie oft du die Tabelle aktualisierst.
Voraussetzungen
Um diesem Abschnitt zu folgen, solltest du Folgendes haben:
- Die obigen Abschnitte zur Snowflake-Einrichtung und Bright Data-Konfiguration abgeschlossen.
- Bestätigt, dass eine Snapshot-Lieferung abgeschlossen ist (per E-Mail oder über die Snapshot-Seite im Bright Data Control Panel).
Schritt #1: Bestätigen, dass Dateien im Stage angekommen sind
Führe dies zuerst aus:
LIST @bright_data_db.web_data.bright_data_stage;Du solltest eine oder mehrere Dateien mit ihren Größen und Zeitstempeln aufgelistet sehen. Wenn der Stage leer ist, ist der Snapshot noch nicht fertig geliefert. Überprüfe seinen Status auf der Snapshot-Seite im Bright Data Control Panel.
Beachte die Dateiendung in den Ergebnissen. Das von Bright Data für die Lieferung verwendete Format bestimmt das FILE_FORMAT, das du in COPY INTO im nächsten Schritt übergibst. Bei über die UI ausgelösten Snapshots liefert Bright Data typischerweise NDJSON, es sei denn, du hast bei der Konfiguration der Lieferung etwas anderes angegeben. Bei über die API ausgelösten Snapshots mit dem deliver-snapshot-Endpunkt ist das Format dasjenige, das du im Anfrage-Body übergeben hast. Wenn du .parquet-Dateien siehst, verwende TYPE = 'PARQUET'. Wenn du .json– oder .ndjson-Dateien siehst, verwende TYPE = 'JSON'.
Schritt #2: Die Dateien in die Tabelle laden
Für Parquet-Dateien:
COPY INTO bright_data_db.web_data.goodreads_books
FROM @bright_data_db.web_data.bright_data_stage
FILE_FORMAT = (TYPE = 'PARQUET')
MATCH_BY_COLUMN_NAME = CASE_INSENSITIVE
ON_ERROR = 'CONTINUE';Für JSON- oder NDJSON-Dateien:
COPY INTO bright_data_db.web_data.goodreads_books (
id, name, url, author, star_rating, num_ratings,
num_reviews, summary, genres, first_published,
about_author, community_reviews
)
FROM (
SELECT
$1:id::VARCHAR,
$1:name::VARCHAR,
$1:url::VARCHAR,
$1:author::VARIANT,
$1:star_rating::FLOAT,
$1:num_ratings::INT,
$1:num_reviews::VARCHAR,
$1:summary::VARCHAR,
$1:genres::VARIANT,
$1:first_published::VARCHAR,
$1:about_author::VARIANT,
$1:community_reviews::VARIANT
FROM @bright_data_db.web_data.bright_data_stage
)
FILE_FORMAT = (TYPE = 'JSON' STRIP_OUTER_ARRAY = TRUE)
ON_ERROR = 'CONTINUE';MATCH_BY_COLUMN_NAME (nur Parquet) ordnet Spaltennamen automatisch zu, sodass die Reihenfolge keine Rolle spielt. ON_ERROR = CONTINUE überspringt fehlerhafte Zeilen, anstatt den gesamten Ladevorgang abzubrechen.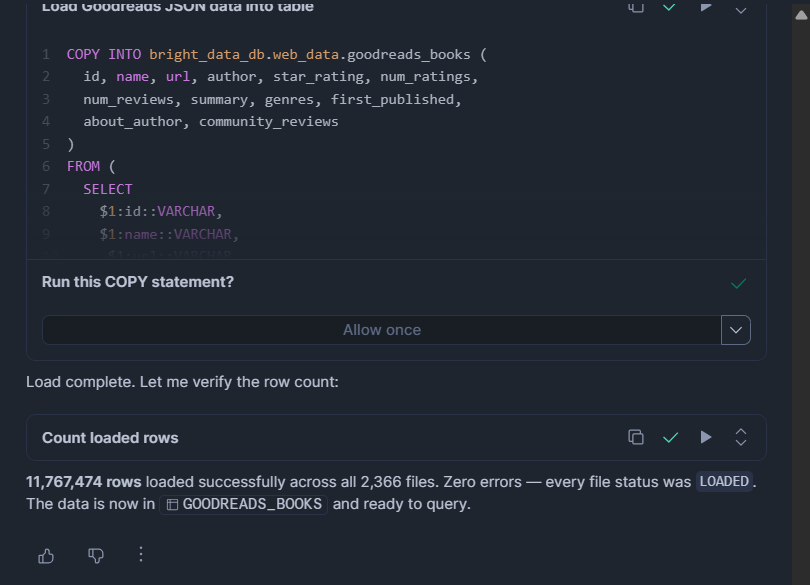
Schritt #3: Den Ladevorgang überprüfen
-- Count the loaded rows
SELECT COUNT(*) FROM bright_data_db.web_data.goodreads_books;
-- Check for skipped rows or errors in the last hour
SELECT *
FROM TABLE(BRIGHT_DATA_DB.INFORMATION_SCHEMA.COPY_HISTORY(
TABLE_NAME => 'BRIGHT_DATA_DB.WEB_DATA.GOODREADS_BOOKS',
START_TIME => DATEADD(HOURS, -1, CURRENT_TIMESTAMP())
));COPY_HISTORY zeigt geladene Zeilen, übersprungene Zeilen, verarbeitete Dateinamen und die genaue Fehlermeldung für jede fehlgeschlagene Zeile. Überprüfe dies nach jedem Ladevorgang, besonders beim ersten Mal.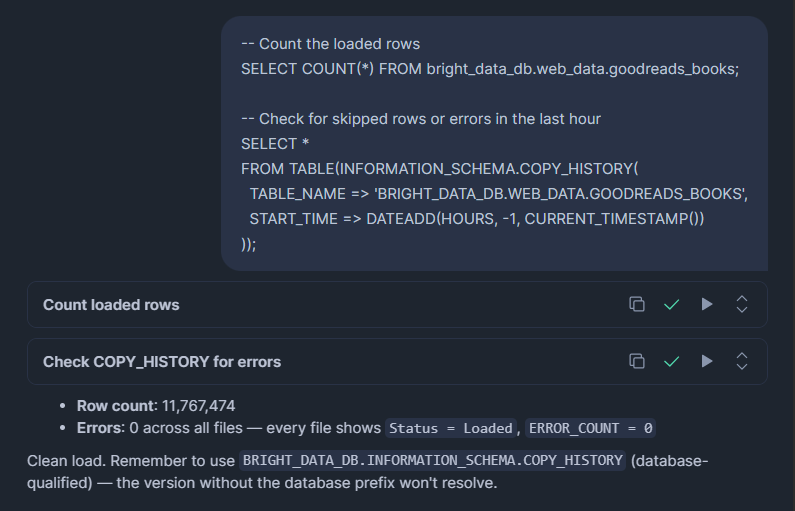
Die Daten abfragen
Mit Goodreads-Buchdaten in Snowflake liegt der Mehrwert darin, Lesetrends, Autorenleistung und Genre-Popularität in großem Maßstab über Millionen von Titeln zu verstehen. Die folgenden Abfragen spiegeln diese Anwendungsfälle direkt wider.
Die Rohdaten inspizieren
Bevor du analytische Abfragen schreibst, überprüfe, ob die Daten wie erwartet aussehen:
SELECT id, name, url, star_rating, num_ratings, first_published
FROM bright_data_db.web_data.goodreads_books
LIMIT 10;ERGEBNIS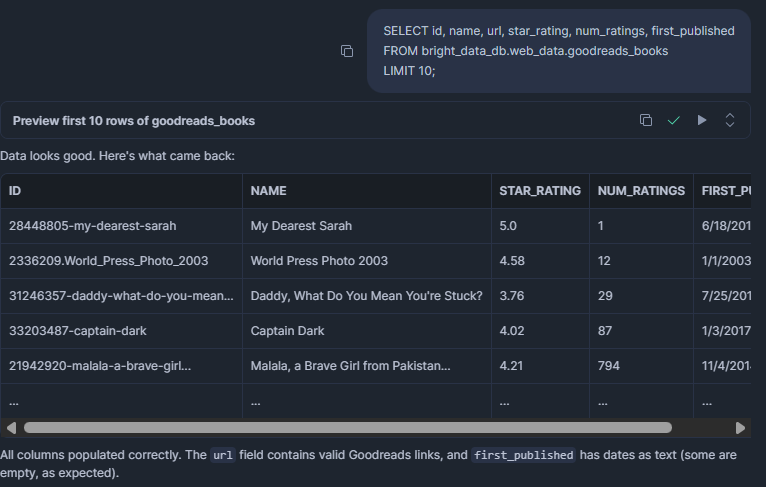
Welche Bücher haben die stärkste Leservalidierung?
Eine hohe star_rating allein reicht nicht aus. Ein Buch mit 4,8 Sternen von 12 Personen sagt dir sehr wenig. Diese Abfrage zeigt Bücher, die sowohl hoch bewertet als auch weit gelesen sind – die Kombination, die signalisiert, dass ein Buch echte Beständigkeit hat.
SELECT
name,
author[0]:name::VARCHAR AS primary_author,
star_rating,
num_ratings,
first_published
FROM bright_data_db.web_data.goodreads_books
WHERE num_ratings > 10000
AND star_rating >= 4.5
ORDER BY num_ratings DESC
LIMIT 20;Ergebnis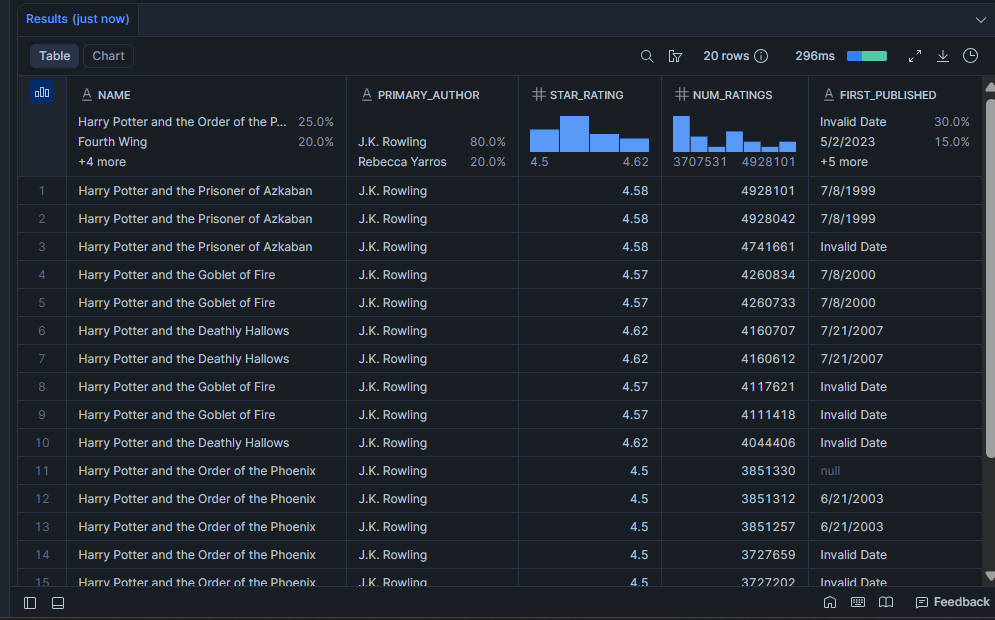
Welche Genres haben die meisten Titel und die höchste Durchschnittsbewertung?
Nützlich, um zu verstehen, wo die Lesernachfrage konzentriert ist. Ein Genre mit einer großen Anzahl von Titeln, aber einer niedrigen Durchschnittsbewertung, könnte mit minderwertigen Einträgen überschwemmt sein – eine Chance für Verlage oder Empfehlungsmaschinen.
SELECT
g.value::VARCHAR AS genre,
COUNT(*) AS book_count,
ROUND(AVG(star_rating), 2) AS avg_rating,
SUM(num_ratings) AS total_ratings
FROM bright_data_db.web_data.goodreads_books,
LATERAL FLATTEN(INPUT => genres) g
WHERE g.value IS NOT NULL
GROUP BY genre
ORDER BY total_ratings DESC
LIMIT 15;Ergebnis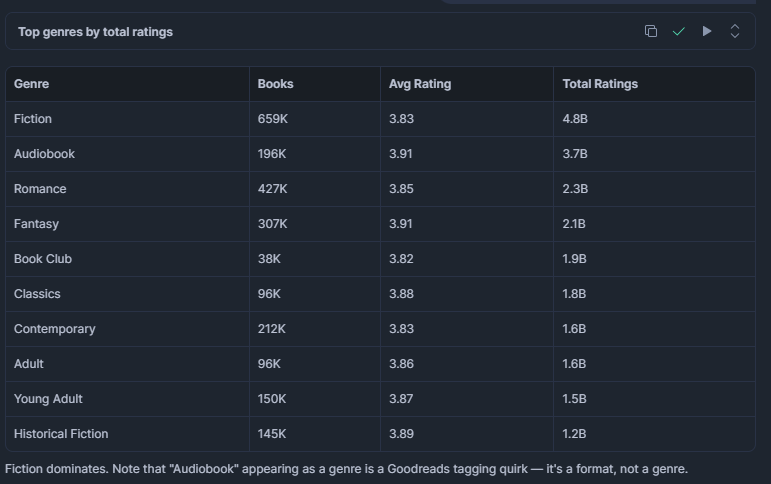
Wer sind die meistgefolgten Autoren im Datensatz?
Die Follower-Anzahl eines Autors ist ein Proxy für das Plattformpublikum. Die Kombination mit der durchschnittlichen Buchbewertung zeigt, ob die meistgefolgten Autoren auch die angesehensten sind, oder ob Follower-Anzahl und Qualität auseinanderdriften.
about_author ist ein flaches Objekt in jedem Buchdatensatz, was die Abfrage ohne Array-Indizierung unkompliziert macht. Beachte, dass dies den Autor widerspiegelt, wie er auf der Seite dieses spezifischen Buches beschrieben wird, was leicht von author (dem Array der angegebenen Autoren) abweichen kann.
SELECT
about_author:name::VARCHAR AS author_name,
about_author:num_books::INT AS books_published,
about_author:num_followers::VARCHAR AS followers,
ROUND(AVG(star_rating), 2) AS avg_book_rating,
SUM(num_ratings) AS total_ratings_received
FROM bright_data_db.web_data.goodreads_books
WHERE about_author:name IS NOT NULL
GROUP BY author_name, books_published, followers
ORDER BY followers DESC NULLS LAST
LIMIT 20;Ergebnis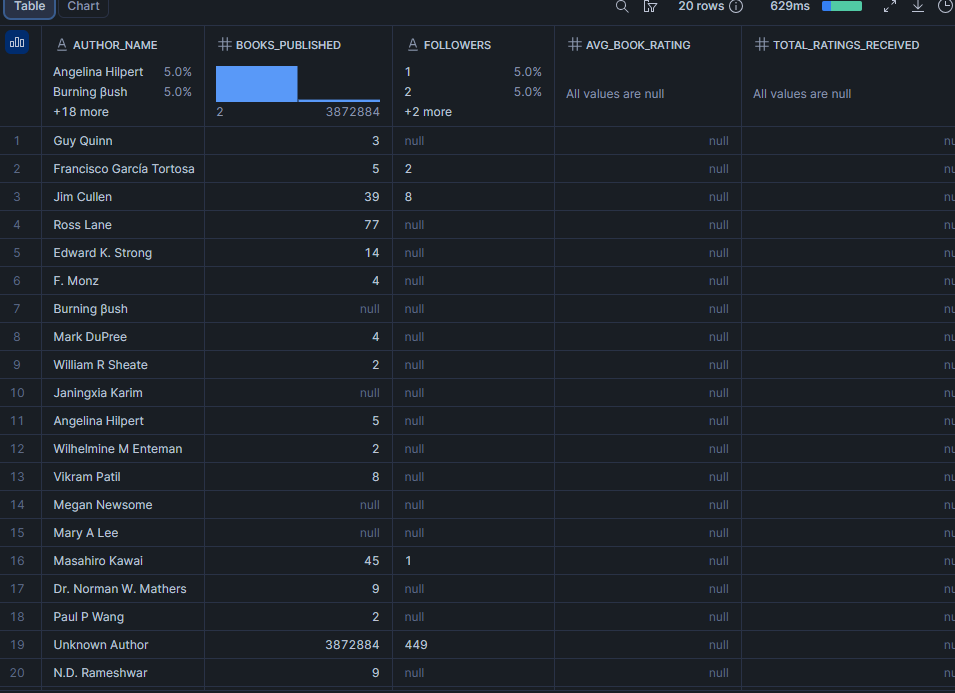
Hinweis: followers wird als Text sortiert, da das Quellfeld VARCHAR ist (es kann formatierte Werte wie "12.3k" enthalten). Wenn dein Datensatz eine saubere Ganzzahl liefert, konvertiere sie mit TO_NUMBER(followers) und sortiere numerisch.
Wie polarisierend ist ein Buch? Sternverteilung aus Community-Rezensionen extrahieren
Ein Buch mit einer hohen Durchschnittsbewertung, aber einem großen Anteil an 1-Stern-Bewertungen, ist möglicherweise kontrovers statt allgemein beliebt. Diese Abfrage ruft die Bewertungsverteilung für ein bestimmtes Buch ab.
SELECT
name,
star_rating,
num_reviews,
community_reviews['5_stars']:reviews_num::INT AS five_star_count,
community_reviews['4_stars']:reviews_num::INT AS four_star_count,
community_reviews['3_stars']:reviews_num::INT AS three_star_count,
community_reviews['2_stars']:reviews_num::INT AS two_star_count,
community_reviews['1_stars']:reviews_num::INT AS one_star_count,
community_reviews['1_stars']:reviews_percentage::FLOAT AS one_star_pct
FROM bright_data_db.web_data.goodreads_books
WHERE id = 'YOUR_BOOK_ID'; -- substitute the Goodreads book IDnum_reviews gibt die Gesamtzahl der schriftlichen Rezensionen neben der Sternverteilung an – nützlich, um Bücher zu unterscheiden, die lange schriftliche Meinungen anziehen, von solchen, die stille Sternbewertungen sammeln.
Et voilà! Du hast jetzt eine funktionierende Pipeline, die strukturierte Web-Daten aus Bright Data zieht und in Snowflake abfragbar macht.
Aktualisierungen automatisieren
Für den Produktionseinsatz möchtest du, dass neue Snapshots automatisch geladen werden, anstatt jedes Mal manuell COPY INTO auszuführen. Beginne mit Option A. Wechsle nur zu Option B, wenn du benötigst, dass die Tabelle innerhalb von Sekunden nach Abschluss der Lieferung aktualisiert wird.
Option A: Snowflake Task für zeitplangesteuerte Ingestion
Ein Snowflake Task führt COPY INTO nach einem Cron-Zeitplan aus und erfordert keine zusätzliche Infrastruktur. Lege in Bright Data einen passenden Lieferzeitplan fest, damit die Dateien im Stage bereit sind, wenn der Task ausgelöst wird.
CREATE TASK IF NOT EXISTS bright_data_db.web_data.load_goodreads_task
WAREHOUSE = bright_data_wh
SCHEDULE = 'USING CRON 0 6 * * * UTC'
AS
COPY INTO bright_data_db.web_data.goodreads_books
FROM @bright_data_db.web_data.bright_data_stage
FILE_FORMAT = (TYPE = 'PARQUET')
MATCH_BY_COLUMN_NAME = CASE_INSENSITIVE
ON_ERROR = 'CONTINUE';
ALTER TASK bright_data_db.web_data.load_goodreads_task RESUME;Profi-Tipp: Überprüfe beim ersten automatisierten Durchlauf COPY_HISTORY, nachdem der Task ausgelöst wurde, um zu bestätigen, dass das Timing des Zeitplans mit dem Zeitpunkt übereinstimmt, zu dem Bright Data die Lieferung abschließt. Ein Task, der vor Abschluss der Lieferung läuft, findet einen leeren Stage und lädt null Zeilen.
Option B: Snowpipe REST API für latenzarme ereignisgesteuerte Ingestion
Snowpipe lädt Dateien aus dem Stage innerhalb von Sekunden nach ihrer Ankunft, ausgelöst programmatisch über seinen insertFiles-REST-Endpunkt. Verwende dies nur, wenn dein Anwendungsfall nahezu echtzeitnahe Aktualität erfordert. Es fügt im Vergleich zu Option A eine erhebliche Einrichtungskomplexität hinzu.
Die Einrichtung besteht aus zwei Teilen. Erstelle zunächst die Pipe:
CREATE PIPE IF NOT EXISTS bright_data_db.web_data.goodreads_pipe
AS
COPY INTO bright_data_db.web_data.goodreads_books
FROM @bright_data_db.web_data.bright_data_stage
FILE_FORMAT = (TYPE = 'PARQUET')
MATCH_BY_COLUMN_NAME = CASE_INSENSITIVE;Beachte das Fehlen von AUTO_INGEST = TRUE. Für interne benannte Stages ist Auto-Ingest über Cloud-Messaging nur für AWS-gehostete Snowflake-Accounts verfügbar und ist derzeit eine Vorschaufunktion. Der REST-API-Ansatz funktioniert auf allen Cloud-Plattformen.
Verbinde zweitens deinen Webhook-Handler, um die gestageten Dateien aufzulisten und sie an Snowpipe zu übermitteln, wenn ein Snapshot bereit ist:
import snowflake.connector
from snowflake.ingest import SimpleIngestManager, StagedFile
SNOWFLAKE_ACCOUNT = "your-account-identifier"
SNOWFLAKE_USER = "brightdata_svc"
SNOWFLAKE_PASSWORD = "YourStrongPasswordHere"
PIPE_NAME = "bright_data_db.web_data.goodreads_pipe"
STAGE_NAME = "bright_data_db.web_data.bright_data_stage"
def handle_brightdata_webhook(snapshot_id: str):
# Step 1: list files that arrived in the stage
conn = snowflake.connector.connect(
account=SNOWFLAKE_ACCOUNT,
user=SNOWFLAKE_USER,
password=SNOWFLAKE_PASSWORD,
)
cursor = conn.cursor()
cursor.execute(f"LIST @{STAGE_NAME}")
staged_files = [StagedFile(row[0], None) for row in cursor.fetchall()]
cursor.close()
conn.close()
if not staged_files:
print(f"No files found in stage for snapshot {snapshot_id}")
return
# Step 2: tell Snowpipe to load them
ingest_manager = SimpleIngestManager(
account=SNOWFLAKE_ACCOUNT,
host=f"{SNOWFLAKE_ACCOUNT}.snowflakecomputing.com",
user=SNOWFLAKE_USER,
pipe=PIPE_NAME,
private_key=open("rsa_key.p8", "rb").read(), # Snowpipe REST requires key-pair auth
)
response = ingest_manager.ingest_files(staged_files)
print(f"Snowpipe response: {response}")Hinweis: Die Snowpipe REST API erfordert Schlüsselpaar-Authentifizierung, keine Passwort-Authentifizierung. Generiere ein RSA-Schlüsselpaar, weise den öffentlichen Schlüssel brightdata_svc in Snowflake zu (ALTER USER brightdata_svc SET RSA_PUBLIC_KEY='...'), und gib oben den Pfad zur privaten Schlüsseldatei an. Installiere das SDK mit pip install snowflake-ingest.
Fazit
In diesem Artikel hast du gelernt, wie man eine vollständige Web-Daten-Ingestion-Pipeline von Bright Data in Snowflake aufbaut. Der Workflow:
- Bereitet Snowflake mit einer dedizierten Datenbank, einem Stage, einer Rolle und einem Service-Benutzer vor, gegen den sich Bright Data direkt authentifiziert.
- Konfiguriert einen Bright Data-Datensatz mit Snowflake als Lieferziel, ohne dass ein Zwischenspeicher erforderlich ist.
- Löst einen Snapshot über den Deliveries-Tab des Control Panels oder die Dataset API aus und überwacht dann den Lieferstatus, bis die Dateien im Stage ankommen.
- Lädt die gestageten Dateien mit einem einzigen
COPY INTO-Befehl in eine strukturierte Snowflake-Tabelle und fragt die Daten mit Standard-SQL ab.
Die gleiche Einrichtung funktioniert für jeden Datensatz im Marketplace von Bright Data: Amazon-Produkte, LinkedIn-Unternehmen, Stellenanzeigen, Hoteleinträge, Crunchbase-Datensätze und mehr. Jeder folgt dem gleichen Liefermuster; nur das Tabellenschema ändert sich.
Erstelle noch heute einen kostenlosen Bright Data-Account und beginne damit, Live-Web-Daten in deine Snowflake-Umgebung zu bringen!




