

Das Scraping von Zillow, einer Online-Website für Immobilientransaktionen, bietet Ihnen wertvolle Einblicke in den Immobilienmarkt, einschließlich Marktanalysen, Trends in der Wohnungswirtschaft und Übersichten über Wettbewerber. Durch das Scraping von Zillow können Sie umfassende Informationen über Immobilienpreise, Standorte, Merkmale und historische Trends sammeln, wodurch Sie in die Lage versetzt werden, Marktanalysen durchzuführen, sich über Trends in der Wohnungswirtschaft auf dem Laufenden zu halten, die Strategien Ihrer Wettbewerber zu bewerten und datengestützte Entscheidungen zu treffen, die mit Ihren Investitionszielen übereinstimmen.
In diesem Tutorial erfahren Sie, wie Sie Zillow mit Beautiful Soup scrapen können. Neben dem Sammeln nützlicher Daten lernen Sie auch die Anti-Scraping-Techniken von Zillow kennen und erfahren, wie Bright Data Ihnen dabei helfen kann.
Möchten Sie das Scraping überspringen und einfach nur die Daten erhalten? Schauen Sie sich unsere Zillow-Datensätze an.
Zillow scrapen
Egal, ob Sie Python-Neuling oder bereits erfahrener Nutzer sind, dieses Tutorial hilft Ihnen dabei, einen Web-Scraper mit kostenlosen Bibliotheken wie Beautiful Soup oder Requests zu erstellen. Also legen Sie los!
Voraussetzungen
Bevor Sie beginnen, sollten Sie über grundlegende Kenntnisse im Bereich Web-Scraping und HTML verfügen. Außerdem müssen Sie Folgendes tun:
- Offizielle Dokumentation
- Playwright
pip3 install beautifulsoup4
pip3 install requests
pip3 install pandas
pip3 install playwright
Die Struktur der Zillow-Website verstehen
Bevor Sie mit dem Scraping von Zillow beginnen, ist es wichtig, dessen Struktur zu verstehen. Beachten Sie, dass die Homepage von Zillow über eine praktische Suchleiste verfügt, mit der Sie nach Häusern, Wohnungen und verschiedenen Immobilien suchen können. Sobald Sie eine Suche starten, werden die Ergebnisse auf einer Seite angezeigt, die eine Liste der Immobilien mit deren Preisen, Adressen und anderen relevanten Details enthält. Es ist erwähnenswert, dass diese Suchergebnisse nach Parametern wie Preis, Anzahl der Schlafzimmer und Anzahl der Badezimmer sortiert werden können.
Wenn Sie mehr Suchergebnisse als die zunächst angezeigten sehen möchten, können Sie die Paginierungsschaltflächen am unteren Rand der Seite verwenden. Jede Seite enthält in der Regel vierzig Einträge, sodass Sie auf weitere Immobilien zugreifen können. Mithilfe der Filter auf der linken Seite können Sie Ihre Suche nach Ihren Vorlieben und Anforderungen eingrenzen.
Um sich mit der HTML-Struktur der Website vertraut zu machen, sollten Sie die folgenden Schritte ausführen:
- Besuchen Sie die Website von Zillow: www.zillow.com.
- Geben Sie eine Stadt oder Postleitzahl in die Suchleiste ein und drücken Sie die Eingabetaste.
- Klicken Sie mit der rechten Maustaste auf eine Immobilienkarte und klicken Sie auf „Untersuchen“, um die Entwicklertools des Browsers zu öffnen.
- Analysieren Sie die HTML-Struktur, um die Tags und Attribute zu identifizieren, die die Daten enthalten, die Sie scrapen möchten.
Identifizieren Sie wichtige Datenpunkte
Um Informationen von Zillow effektiv zu sammeln, müssen Sie den genauen Inhalt identifizieren, den Sie extrahieren möchten. In dieser Anleitung erfahren Sie, wie Sie Informationen zu einer Immobilie extrahieren können, darunter die folgenden wichtigen Datenpunkte:
- Adresse: Der Standort der Immobilie, einschließlich Straße, Stadt und Bundesstaat.
- Preis: Der angegebene Preis der Immobilie, der Aufschluss über ihren aktuellen Marktwert gibt.
- Zestimate: Der von Zillow geschätzte Marktwert der Immobilie. Der Zestimate berücksichtigt verschiedene Faktoren und liefert eine ungefähre Bewertung auf der Grundlage von Markttrends und vergleichbaren Immobiliendaten.
- Schlafzimmer: Die Anzahl der Schlafzimmer in der Immobilie.
- Badezimmer: Die Anzahl der Badezimmer in der Immobilie.
- Quadratmeterzahl: Die Gesamtfläche der Immobilie in Quadratmetern.
- Baujahr: Das Jahr, in dem die Immobilie erbaut wurde.
- Typ: Der Typ der Immobilie, der Optionen wie Haus, Wohnung, Eigentumswohnung oder andere relevante Klassifizierungen umfassen kann.
Zillow bietet Ihnen eine Vielzahl von Informationen, mit denen Sie verschiedene Angebote einfach bewerten und vergleichen, Preisentwicklungen in bestimmten Stadtvierteln berücksichtigen, den Zustand der Immobilie beurteilen und zusätzliche Ausstattungsmerkmale identifizieren können. Darüber hinaus können Sie durch die Analyse historischer und aktueller Marktdaten über Trends auf dem Laufenden bleiben und strategische Entscheidungen hinsichtlich des Kaufs, Verkaufs oder der Investition in Immobilien treffen.
Erstellen Sie den Scraper
Nachdem Sie nun festgelegt haben, was Sie scrapen möchten, ist es an der Zeit, den Scraper zu erstellen. Hier verwenden Sie die Requests-Bibliothek, um HTTP-Anfragen an Zillow zu stellen, Beautiful Soup, um den HTML-Code zu parsen, und Python, um die Daten zu extrahieren.
Extrahieren Sie die Daten
Der erste Schritt besteht darin, die gesuchten Daten zu extrahieren. Erstellen Sie eine neue Datei mit dem Namen scraper.py und fügen Sie den folgenden Code hinzu:
import requests
from bs4 import BeautifulSoup
url = 'https://www.zillow.com/homes/for_sale/San-Francisco_rb/'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.content, 'html.parser')
listings = []
for listing in soup.find_all('div', {'class': 'property-card-data'}):
result = {}
result['address'] = listing.find('address', {'data-test': 'property-card-addr'}).get_text().strip()
result['price'] = listing.find('span', {'data-test': 'property-card-price'}).get_text().strip()
details_list = listing.find('ul', {'class': 'dmDolk'})
details = details_list.find_all('li') if details_list else []
result['bedrooms'] = details[0].get_text().strip() if len(details) > 0 else ''
result['bathrooms'] = details[1].get_text().strip() if len(details) > 1 else ''
result['sqft'] = details[2].get_text().strip() if len(details) > 2 else ''
type_div = listing.find('div', {'class': 'gxlfal'})
result['type'] = type_div.get_text().split("-")[1].strip() if type_div else ''
listings.append(result)
print(listings)
Dieser Code sendet eine HTTP-GET-Anfrage an die Suchergebnisseite von Zillow und verwendet dann Beautiful Soup, um den HTML-Code zu parsen. Er extrahiert die Datenpunkte für jede Immobilie und gibt dann alle Immobilien aus.
Den Scraper ausführen
Um den Scraper auszuführen, müssen Sie ihm eine URL für eine Zillow-Suchergebnisseite bereitstellen. Die URL sollte wie folgt aussehen: https://www.zillow.com/homes/for_sale/{city-or-zip}_rb/, wobei {city-or-zip} durch den Namen der Stadt oder die Postleitzahl ersetzt wird, die Sie scrapen möchten.
Wenn Sie beispielsweise Informationen über Häuser sammeln möchten, die in San Francisco verkauft werden, lautet die Webadresse https://www.zillow.com/homes/for_sale/San-Francisco_rb/.
Nachdem Sie die Website-URL eingegeben haben, können Sie Ihr Programm ausführen und mit dem Scraping beginnen. Speichern Sie die Änderungen in scraper.py und führen Sie den folgenden Befehl in Ihrer Shell oder Ihrem Terminal aus:
python3 Scraper.py
…Ausgabe…
[{'address': '19 Tehama St SUITE 3, San Francisco, CA 94105', 'price': '$1,025,000', 'bedrooms': '1 bd', 'bathrooms': '1 ba', 'sqft': '956 sqft', 'type': 'Condo for sale'}, {'address': '267A Chattanooga St, San Francisco, CA 94114', 'price': '$1.740.000', 'bedrooms': '2 Schlafzimmer', 'bathrooms': '3 Badezimmer', 'sqft': '2.114 Quadratfuß', 'type': 'Eigentumswohnung zu verkaufen'}, {'address': '998 Union St, San Francisco, CA 94133', 'price': '1.650.000 $', 'bedrooms': '2 Schlafzimmer', 'bathrooms': '1 Badezimmer', 'sqft': '1.181 Quadratfuß', 'type': 'Eigentumswohnung zu verkaufen'}, {'address': '37-39 Mirabel Ave, San Francisco, CA 94110', 'price': '2.395.000 $', 'bedrooms': '7 Schlafzimmer', 'bathrooms': '6 Badezimmer', 'sqft': '2.300 Quadratfuß', 'type': 'Multi'}, {'address': '304 Yale St, San Francisco, CA 94134', 'price': '1.399.900 $', 'bedrooms': '3 Schlafzimmer', 'bathrooms': '4 Badezimmer', 'sqft': '1.764 Quadratfuß', 'type': 'Neubau'}, {'address': '173 Coleridge St, San Francisco, CA 94110', 'price': '745.000 $', 'bedrooms': '2 Schlafzimmer', 'bathrooms': '2 Badezimmer', 'sqft': '905 sqft', 'type': 'Eigentumswohnung zu verkaufen'}, {'address': '289 Sadowa St, San Francisco, CA 94112', 'price': '698.000 $', 'bedrooms': '4 Schlafzimmer', 'bathrooms': '2 Bäder', 'sqft': '1.535 sqft', 'type': 'Haus zu verkaufen'}, {'address': '1739 19th Ave, San Francisco, CA 94122', 'price': '475.791 $', 'bedrooms': '2 Schlafzimmer', 'bathrooms': '2 Badezimmer', 'sqft': '1.780 Quadratfuß', 'type': 'Reihenhaus zu verkaufen'}, {'address': '1725 Quesada Ave, San Francisco, CA 94124', 'price': '600.000 $', 'bedrooms': '3 Schlafzimmer', 'bathrooms': '2 Badezimmer', 'sqft': '1.011 Quadratfuß', 'type': 'Eigentumswohnung zu verkaufen'}]
Bitte beachten Sie, dass beim Web-Scraping die
robots.txt-Dateiund die Nutzungsbedingungen der Website zu beachten sind und dass übermäßiges Scraping dazu führen kann, dass Ihre IP-Adresse gesperrt wird.
Speichern Sie Ihre Daten
Nachdem Sie Ihre Daten extrahiert haben, müssen Sie sie in einer JSON- oder CSV-Datei speichern. Durch das Speichern der Daten in einer Datei können Sie diese verarbeiten und auf der Grundlage Ihrer gesammelten Daten Analysen erstellen.
Um die Daten zu speichern, importieren Sie zunächst die Bibliotheken pandas und json am Anfang Ihrer Datei scraper.py:
import pandas as pd
import json
Fügen Sie dann den folgenden Code am Ende Ihrer Datei hinzu:
#Daten in Json-Datei schreiben
with open('listings.json', 'w') as f:
json.dump(listings, f)
print('Daten in Json-Datei geschrieben')
#Daten in CSV schreiben
df = pd.DataFrame(listings)
df.to_csv('listings.csv', index=False)
print('Daten in CSV-Datei geschrieben')
Dieser Code schreibt die Listings-Daten, eine Liste von Wörterbüchern, mit json.dump() in eine JSON-Datei namens listings.json. Anschließend erstellt er aus den Listings-Daten einen Pandas-DataFrame und schreibt diesen mit der Methode to_csv() in eine CSV-Datei namens listings.csv. Der Code gibt Meldungen aus, die anzeigen, dass die Daten erfolgreich in die JSON- und CSV-Dateien geschrieben wurden.
Führen Sie anschließend den Code in Ihrer Shell oder Ihrem Terminal aus:
python3 Scraper.py
…Ausgabe…
[{'address': '19 Tehama St SUITE 3, San Francisco, CA 94105', 'price': '$1,025,000', 'bedrooms': '1 bd', 'bathrooms': '1 ba', 'sqft': '956 sqft', 'type': 'Condo for sale'}, {'address': '267A Chattanooga St, San Francisco, CA 94114', 'price': '$1,740,000', 'bedrooms': '2 bds', 'bathrooms': '3 ba', 'sqft': '2,114 sqft', 'type': 'Condo for sale'}, {'address': '998 Union St, San Francisco, CA 94133', 'price': '1.650.000 $', 'bedrooms': '2 Schlafzimmer', 'bathrooms': '1 Badezimmer', 'sqft': '1.181 Quadratfuß', 'type': 'Eigentumswohnung zu verkaufen'}, {'address': '37-39 Mirabel Ave, San Francisco, CA 94110', 'price': '2.395.000 $', 'bedrooms': '7 Schlafzimmer', 'bathrooms': '6 Badezimmer', 'sqft': '2.300 Quadratfuß', 'type': 'Multi'}, {'address': '304 Yale St, San Francisco, CA 94134', 'price': '1.399.900 $', 'bedrooms': '3 Schlafzimmer', 'bathrooms': '4 Badezimmer', 'sqft': '1.764 Quadratfuß', 'type': 'Neubau'}, {'address': '173 Coleridge St, San Francisco, CA 94110', 'price': '745.000 $', 'bedrooms': '2 Schlafzimmer', 'bathrooms': '2 Badezimmer', 'sqft': '905 sqft', 'type': 'Eigentumswohnung zu verkaufen'}, {'address': '289 Sadowa St, San Francisco, CA 94112', 'price': '698.000 $', 'bedrooms': '4 Schlafzimmer', 'bathrooms': '2 Bäder', 'sqft': '1.535 sqft', 'type': 'Haus zu verkaufen'}, {'address': '1739 19th Ave, San Francisco, CA 94122', 'price': '475.791 $', 'bedrooms': '2 Schlafzimmer', 'bathrooms': '2 Badezimmer', 'sqft': '1.780 Quadratfuß', 'type': 'Reihenhaus zu verkaufen'}, {'address': '1725 Quesada Ave, San Francisco, CA 94124', 'price': '$600,000', 'bedrooms': '3 bds', 'bathrooms': '2 ba', 'sqft': '1,011 sqft', 'type': 'Condo for sale'}]
In die Json-Datei geschriebene Daten
In die CSV-Datei geschriebene Daten
Wenn alles funktioniert hat, sollten Sie zwei neue Dateien in Ihrem Projektverzeichnis finden: eine Datei „listings.csv“ und eine Datei „listings.json “. Diese beiden Dateien sollten ähnliche Inhalte wie die folgenden GitHub-Repo-Dateien haben: listings.csv und listings.json.
Wenn Sie versuchen, den Code mehrmals auszuführen, werden Sie eine hohe Fehlerquote (etwa 50 Prozent) feststellen. Das liegt daran, dass Zillow manchmal eine CAPTCHA-Seite anstelle des eigentlichen Inhalts zurückgibt, wenn es automatisiertes Scraping erkennt. Um eine bessere Erfolgsquote beim Scraping einer Website wie Zillow zu erzielen, müssen Sie Tools verwenden, mit denen Sie zwischen verschiedenen IPs wechseln und CAPTCHA umgehen können.
Von Zillow eingesetzte Anti-Scraping-Techniken
Um zu verhindern, dass Personen ohne Erlaubnis Daten entnehmen, verwendet Zillow eine Reihe verschiedener Methoden, um das automatische Kopieren von Daten (auch bekannt als Scraping) von seiner Website zu unterbinden. Zu diesen Methoden gehören die Verwendung von CAPTCHAs, das Blockieren von IP-Adressen und das Einrichten von Honeypot-Fallen.
Ein CAPTCHA ist ein Test, mit dem festgestellt werden kann, ob ein Benutzer ein Mensch oder ein Computerprogramm ist. Für Menschen ist es in der Regel leicht zu lösen, für Programme jedoch schwierig, wodurch das Scraping von Daten verlangsamt oder sogar gestoppt werden kann.
Eine weitere Methode, mit der Zillow das Scraping verhindert, ist das Blockieren von IP-Adressen. IP-Adressen sind wie Hausadressen, nur für Computer. Wenn ein Computer zu viele Anfragen stellt, was beim Daten-Scraping häufig vorkommt, kann Zillow diese IP-Adresse blockieren, um weitere Anfragen zu verhindern. Diese Blockierungen können je nach Schwere der Situation kurz- oder langfristig sein.
Zillow verwendet auch Honeypot-Fallen. Diese Fallen sind Datenbits oder Links, die nur von Programmen, nicht aber von Menschen gesehen werden können. Wenn ein Programm mit einer Honeypot-Falle interagiert, weiß Zillow, dass es sich um einen Bot handelt, und kann ihn blockieren.
All diese Methoden erschweren das Scraping von Daten aus Zillow. Es kann zeitaufwändig, schwierig und manchmal sogar unmöglich sein. Wer Daten aus Zillow scrapen möchte, muss nicht nur diese Methoden kennen, sondern auch die rechtlichen und moralischen Fragen rund um das Data Scraping verstehen. Denken Sie daran, dass Zillow die Art und Weise, wie es diese Methoden einsetzt, ändern kann, ohne dies öffentlich bekannt zu geben.
Eine bessere Alternative: Verwenden Sie Bright Data zum Scrapen von Zillow
Bright Data bietet eine bessere Alternative zum Scraping von Zillow, indem es die von der Website eingesetzten Anti-Scraping-Techniken mitdem Scraping-Browser von Bright Data umgeht. Mit dem Scraping-Browser können Sie Puppeteer-Skripte im Netzwerk von Bright Data ausführen, das Zugriff auf Millionen von IP-Adressen bietet und die Erkennung durch die Anti-Scraping-Techniken von Zillow verhindert.
Zillow mit dem Scraping-Browser von Bright Data scrapen
Um Zillow mit dem Scraping-Browser von Bright Data zu scrapen, führen Sie die folgenden Schritte aus:
1. Erstellen Sie ein Bright Data-Konto
Wenn Sie noch kein Bright Data-Konto haben, besuchen Sie die Website von Bright Data, klicken Sie auf „Gratis testen“ und folgen Sie den Anweisungen.
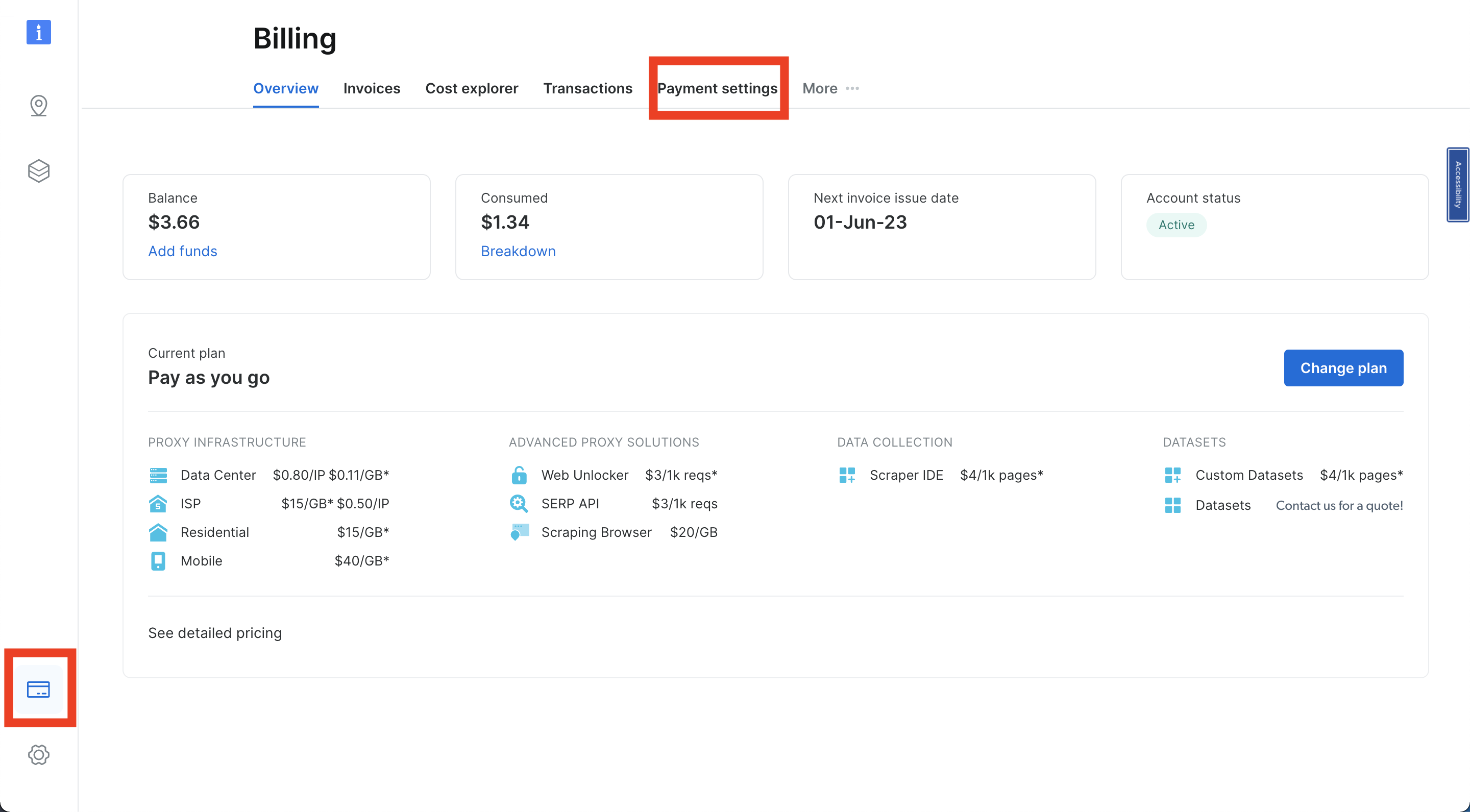
Sobald Sie in Ihrem Bright Data-Konto angemeldet sind, navigieren Sie zu „Abrechnung“, indem Sie auf das Kreditkartensymbol unten links in Ihrer Navigationsleiste klicken. Fügen Sie eine Zahlungsmethode Ihrer Wahl hinzu, da Sie Ihr Konto sonst nicht aktivieren können:
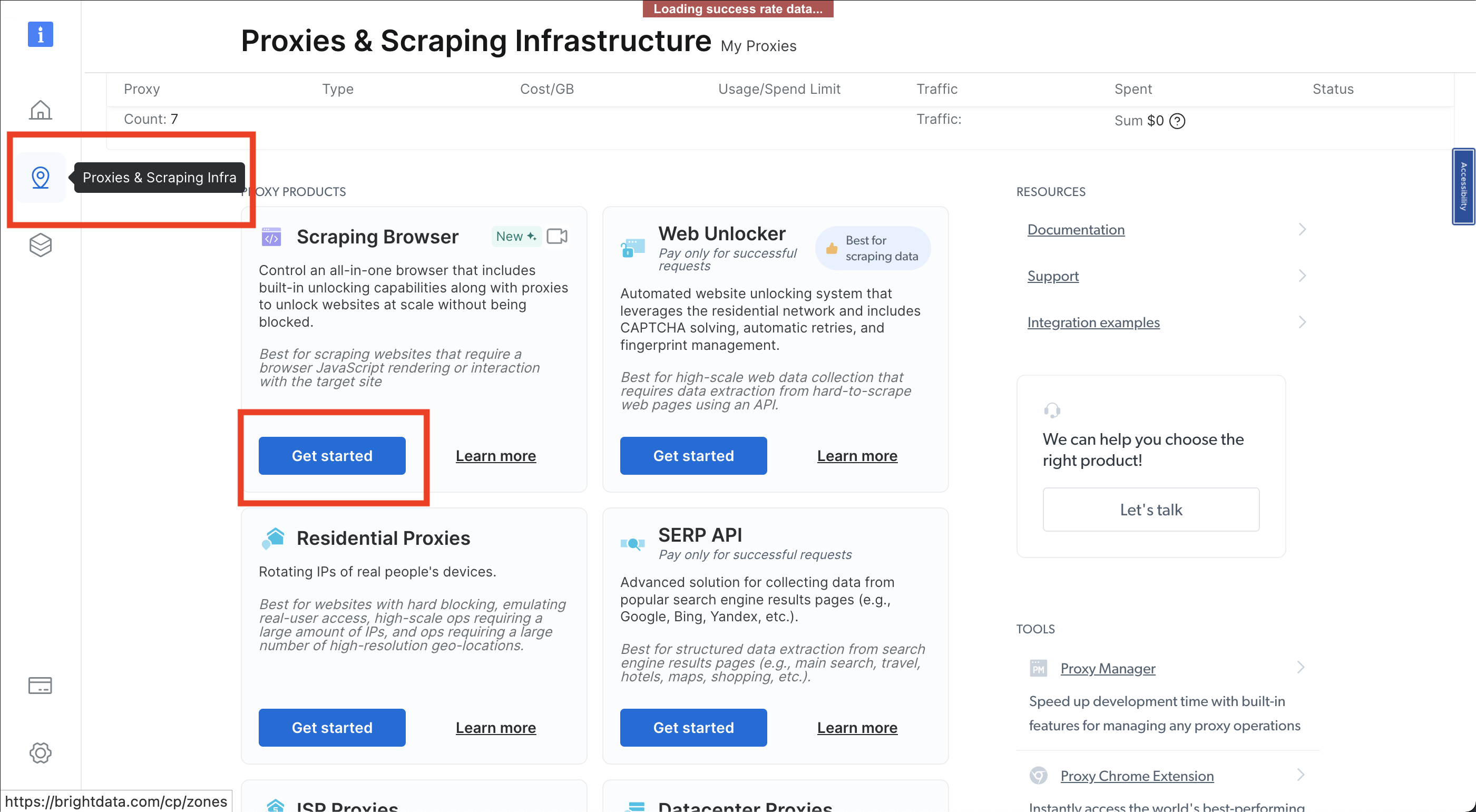
Klicken Sie anschließend auf das Pin-Symbol, um die Seite „Proxies & Scraping-Infrastruktur“ (Proxys und Scraping-Infrastruktur) zu öffnen, und wählen Sie dann „Scraping-Browser“ > „Get started“ (Loslegen):
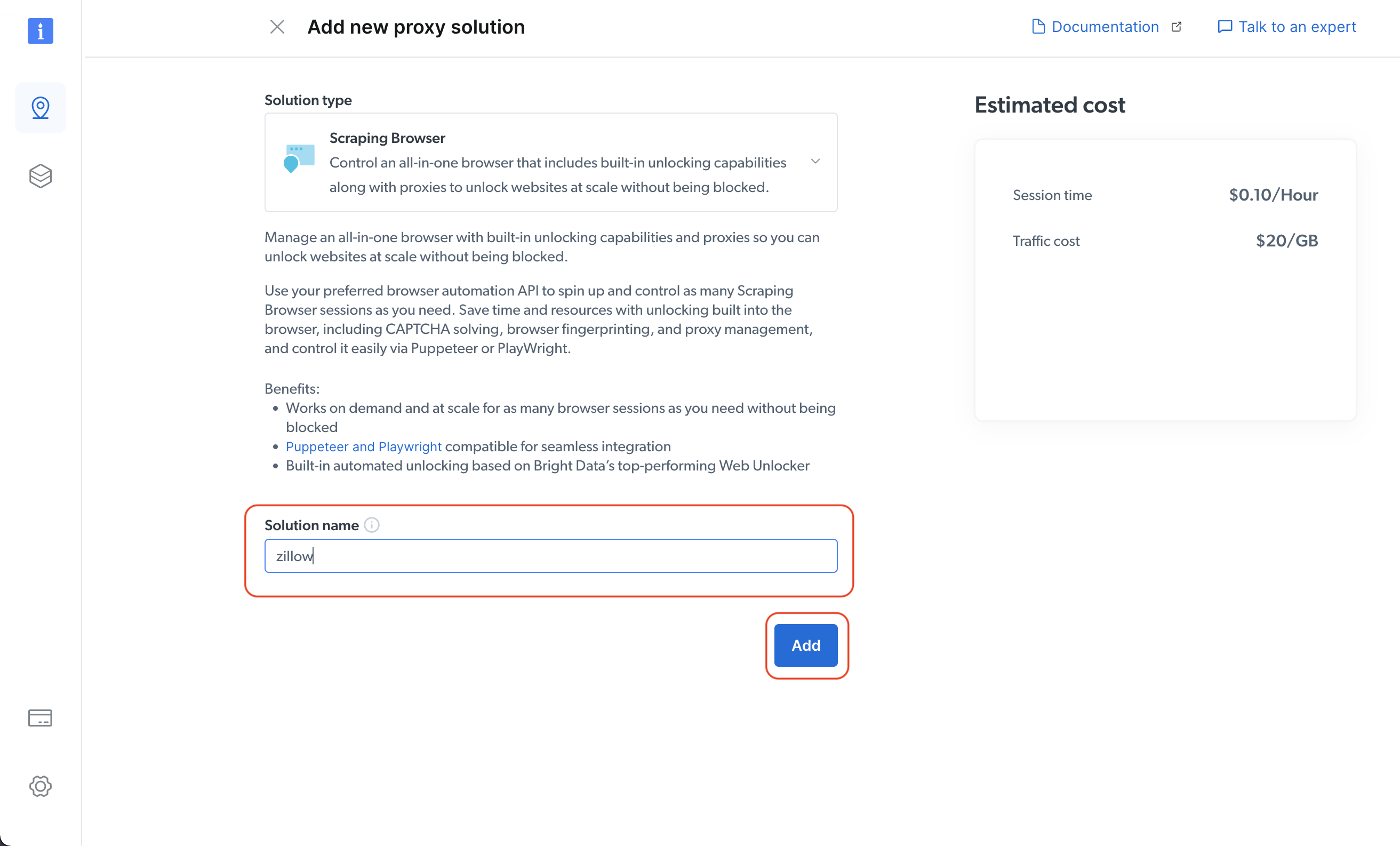
Geben Sie als Nächstes den Namen Ihrer Lösung an und klicken Sie dann auf die Schaltfläche „Hinzufügen “:
Klicken Sie dann auf „Zugriffsparameter“ und notieren Sie sich Ihren Benutzernamen, Host und Ihr Passwort, da diese später im Tutorial benötigt werden:
Nachdem Sie die vorherigen Schritte abgeschlossen haben, können Sie fortfahren.
2. Schreiben Sie den Scraper
Erstellen Sie eine neue Datei mit dem Namen „scraper-brightdata.py“ und fügen Sie den folgenden Code hinzu:
import asyncio
from playwright.async_api import async_playwright
import json
import pandas as pd
username='IHR_BRIGHTDATA_BENUTZERNAME'
password='IHR_BRIGHTDATA_PASSWORT'
auth=f'{username}:{password}'
host = 'IHR_BRIGHTDATA_HOST'
browser_url = f'wss://{auth}@{host}'
async def main():
async with async_playwright() as pw:
print('Verbindung zu einem Remote-Browser wird hergestellt...')
browser = await pw.chromium.connect_over_cdp(browser_url)
print('Verbunden. Öffne neue Seite...')
page = await browser.new_page()
print('Navigiere zu Zillow...')
await page.goto('https://www.zillow.com/homes/for_sale/San-Francisco_rb/', timeout=3600000)
print('Daten werden gescrapt...')
listings = []
properties = await page.query_selector_all('div.property-card-data')
for property in properties:
result = {}
address = await property.query_selector('address[data-test="property-card-addr"]')
result['address'] = await address.inner_text() if address else ''
price = await property.query_selector('span[data-test="property-card-price"]')
result['price'] = await price.inner_text() if price else ''
details = await property.query_selector_all('ul.dmDolk > li')
result['bedrooms'] = await details[0].inner_text() if len(details) >= 1 else ''
result['bathrooms'] = await details[1].inner_text() if len(details) >= 2 else ''
result['sqft'] = await details[2].inner_text() if len(details) >= 3 else ''
type_div = await property.query_selector('div.gxlfal')
result['type'] = (await type_div.inner_text()).split("-")[1].strip() if type_div else ''
listings.append(result)
await browser.close()
return listings
# Asynchrone Funktion ausführen
listings = asyncio.run(main())
# Listings ausgeben
for listing in listings:
print(listing)
# Daten in Json-Datei schreiben
with open('listings-brightdata.json', 'w') as f:
json.dump(listings, f)
print('Daten in Json-Datei geschrieben')
# Daten in CSV schreiben
df = pd.DataFrame(listings)
df.to_csv('listings-brightdata.csv', index=False)
print('Daten in CSV-Datei geschrieben')
Ersetzen Sie YOUR_BRIGHTDATA_USERNAME, YOUR_BRIGHTDATA_PASSWORD und YOUR_BRIGHTDATA_HOST durch Ihre tatsächlichen Bright Data-Kontodaten.
3. Scraper ausführen
Speichern Sie die Änderungen in scraper-brightdata.py und führen Sie den Code über Ihre Shell oder Ihr Terminal aus:
python3 scraper-brightdata.py
…Ausgabe…
Verbindung zu einem Remote-Browser wird hergestellt...
Verbindung hergestellt. Neue Seite wird geöffnet...
Navigation zu Zillow...
Daten werden gescrapt...
{'address': '1438 Green St UNIT 2B, San Francisco, CA 94109', 'price': '$995,000', 'bedrooms': '1 bd', 'bathrooms': '1 ba', 'sqft': '974 sqft', 'type': 'Condo for sale'}
{'address': '815 Tennessee St UNIT 504, San Francisco, CA 94107', 'price': '1.195.000 $', 'bedrooms': '2 Schlafzimmer', 'bathrooms': '2 Badezimmer', 'sqft': '-- Quadratfuß', 'type': ''}
{'address': '455 27th Ave, San Francisco, CA 94121', 'price': '1.375.000 $', 'bedrooms': '2 Schlafzimmer', 'bathrooms': '1 Badezimmer', 'sqft': '1.040 Quadratfuß', 'type': 'Haus zu verkaufen'}
{'address': '19 Tehama St SUITE 3, San Francisco, CA 94105', 'price': '1.025.000 $', 'bedrooms': '1 Schlafzimmer', 'bathrooms': '1 Badezimmer', 'sqft': '956 sqft', 'type': 'Eigentumswohnung zu verkaufen'}
{'address': '267A Chattanooga St, San Francisco, CA 94114', 'price': '1.740.000 $', 'bedrooms': '2 Schlafzimmer', 'bathrooms': '3 Badezimmer', 'sqft': '2.114 Quadratfuß', 'type': 'Eigentumswohnung zu verkaufen'}
{'address': '998 Union St, San Francisco, CA 94133', 'price': '1.650.000 $', 'bedrooms': '2 Schlafzimmer', 'bathrooms': '1 Badezimmer', 'sqft': '1.181 Quadratfuß', 'type': 'Eigentumswohnung zu verkaufen'}
{'address': '37-39 Mirabel Ave, San Francisco, CA 94110', 'price': '2.395.000 $', 'bedrooms': '7 Schlafzimmer', 'bathrooms': '6 Badezimmer', 'sqft': '2.300 Quadratfuß', 'type': 'Mehrfamilienhaus'}
{'address': '304 Yale St, San Francisco, CA 94134', 'price': '1.399.900 $', 'bedrooms': '3 Schlafzimmer', 'bathrooms': '4 Badezimmer', 'sqft': '1.764 sqft', 'type': 'Neubau'}
{'address': '173 Coleridge St, San Francisco, CA 94110', 'price': '745.000 $', 'bedrooms': '2 Schlafzimmer', 'bathrooms': '2 Badezimmer', 'sqft': '905 sqft', 'type': 'Eigentumswohnung zu verkaufen'}
In Json-Datei geschriebene Daten
In CSV-Datei geschriebene Daten
Dieser Code stellt eine Verbindung zum Bright Data Scraping-Browser her, navigiert zur Suchergebnisseite von Zillow und extrahiert die Daten. Als Nächstes gibt der Code die Ergebnisse aus und schreibt sie dann mithilfe von json.dump() in die Listings-Daten, eine Liste von Wörterbüchern, in eine JSON-Datei namens listings-brightdata.json. Anschließend erstellt er aus den Listings-Daten einen Pandas-DataFrame und schreibt ihn mit der Methode to_csv() in eine CSV-Datei namens listings-brightdata.csv. Der Code gibt Meldungen aus, die anzeigen, dass die Daten erfolgreich in die JSON- und CSV-Dateien geschrieben wurden.
Wenn alles funktioniert hat, sollten Sie zwei Dateien finden: eine Datei namens listings-brightdata.csv und eine Datei namens listings-brightdata.json. Diese Dateien sollten ähnlich wie listings-brightdata.json und listings-brightdata.csv aussehen.
Wenn Sie versuchen, diesen Code mehrmals auszuführen, und feststellen, dass keine Daten in Ihren Dateien gespeichert sind, bedeutet dies, dass Ihre IP-Adresse von Zillow blockiert wurde oder dass der Browser vor Abschluss des Vorgangs geschlossen wurde. Wenn der Scraping-Browser vor Abschluss des Scrapings geschlossen wurde, müssen Sie das Timeout auf einen größeren Wert ändern, der im vorherigen Code mit await page.goto('https://www.zillow.com/homes/for_sale/San-Francisco_rb/', timeout=3600000) zusammenhängt.
Wenn Ihre IP-Adresse von Zillow blockiert wurde, müssen Sie Ihre Zone ändern. Glücklicherweise bietet Ihnen Bright Data Zugriff auf mehrere Zonen.
Um zwischen verschiedenen Zonen zu wechseln, gehen Sie zu „Proxies & Scraping-Infrastruktur“, klicken Sie auf das Pin-Symbol, wählen Sie „Scraping-Browser “ und klicken Sie auf „Access parameters“. Klicken Sie anschließend auf „ </> Check out code and integration examples“:
Wählen Sie Python als Sprache aus. Auf der rechten Seite finden Sie eine Dropdown-Liste mit Ländern. Wählen Sie das gewünschte Land aus, und Ihre Zone wird gleichzeitig aktualisiert. Sie sollten sehen, dass sich die Authentifizierungsvariable im Python-Beispielcode ändert. Sie müssen den mit dieser Zone verbundenen Benutzer aus der Authentifizierungsvariable abrufen. Dabei handelt es sich hauptsächlich um den Wert vor dem :, da die Authentifizierungsvariable den Benutzernamen und das Passwort mit der folgenden Syntax enthält: Benutzername:Passwort:
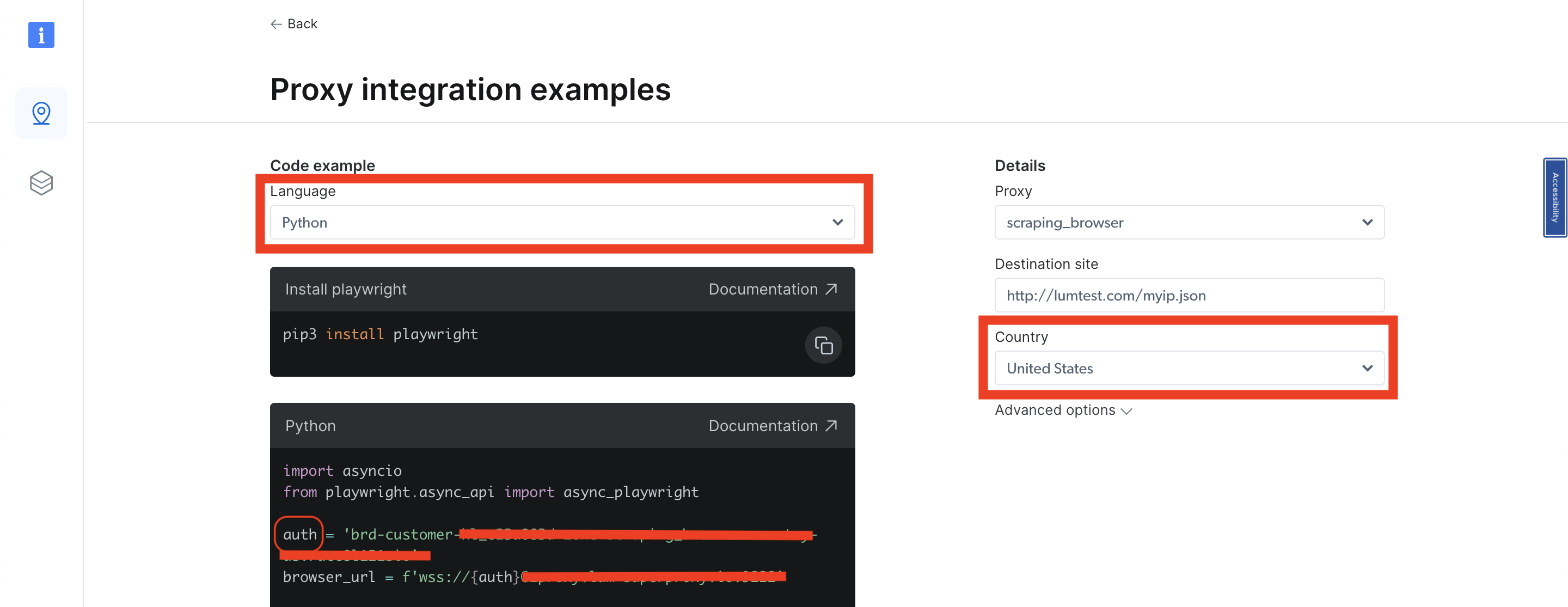
Jedes Mal, wenn Sie Ihr Land ändern, erhalten Sie einen anderen Benutzer für dieses bestimmte Land/diese bestimmte Zone. Nehmen Sie den Benutzer basierend auf dem erhaltenen Benutzernamen und dem ausgewählten Land, fügen Sie ihn in Ihren Code ein und führen Sie ihn erneut aus.
Fazit
In diesem Tutorial haben Sie gelernt, wie Sie Zillow mit Beautiful Soup scrapen können. Außerdem haben Sie erfahren, welche
Anti-Scraping-Techniken von Zillow eingesetzt werden und wie man sie umgehen kann. Um diese Probleme zu lösen, wurde der Bright Data Scraping-Browser eingeführt, mit dem Sie die Anti-Scraping-Mechanismen von Zillow umgehen und die gewünschten Daten nahtlos extrahieren können.
Zusätzlich zum Scraping-Browser bietet die Zillow Scraper API von Bright Data nahtlosen Zugriff auf umfassende Zillow-Daten und umgeht für Sie Anti-Scraping-Maßnahmen.
Hinweis: Dieser Leitfaden wurde zum Zeitpunkt der Erstellung von unserem Team gründlich getestet, aber da Websites ihren Code und ihre Struktur häufig aktualisieren, funktionieren einige Schritte möglicherweise nicht mehr wie erwartet.






