

In diesem Artikel erfahren Sie:
- Was ein Indeed-Scraper ist und wie er funktioniert
- Welche Arten von Daten Sie automatisch aus Indeed extrahieren können
- Wie Sie mit Python ein Indeed-Scraping-Skript erstellen
- Wann und warum Sie möglicherweise eine fortgeschrittenere Lösung benötigen
Los geht’s!
Was ist ein Indeed-Scraper?
Ein Indeed-Scraper extrahiert automatisch Stellenanzeigen und zugehörige Daten von der Indeed-Website. Er ahmt menschliche Interaktionen nach, um auf den Seiten für die Stellensuche zu navigieren. Anschließend identifiziert er bestimmte Elemente wie Berufsbezeichnungen, Unternehmen, Standorte und Beschreibungen. Schließlich extrahiert derScraping-BotDaten aus diesen Elementen und exportiert sie zur Analyse.
Daten, die Sie auf Indeed finden können
Indeed ist eine Fundgrube für berufsbezogene Daten, die für Marktanalysen, Rekrutierungs- oder Forschungszwecke von unschätzbarem Wert sein können. Nachfolgend finden Sie eine Liste der wichtigsten Datenpunkte, die Sie daraus extrahieren können:
- Stellenbezeichnungen: Die in der Anzeige ausgeschriebene Rolle oder Position.
- Firmennamen: Details zum Arbeitgeber, einschließlich Firmenprofilen.
- Standorte: Die Stadt, das Bundesland oder das Land, in dem die Stelle angesiedelt ist.
- Stellenbeschreibungen: Detaillierte Informationen über die Rolle, die Aufgaben und die Anforderungen.
- Gehaltsspannen: Ausgeschriebene Gehaltsspannen (sofern verfügbar).
- Beschäftigungsarten: Vollzeit, Teilzeit, befristet, Praktikum usw.
- Veröffentlichungsdatum: Datum, an dem die Stellenanzeige veröffentlicht wurde.
- Tags und Attribute: Schlüsselwörter wie „Dringend gesucht“ oder „Remote“.
- Bewertungen und Rezensionen: Arbeitgeberbewertungen und Mitarbeiterfeedback.
- Bewerbungsoptionen: Indikatoren wie die Verfügbarkeit von „Easy Apply”.
Wenn Sie sich auf Stellenangebote konzentrieren, folgen Sie unserer Anleitung zum Scrapen von Stellenanzeigen.
So scrapen Sie Indeed: Schritt-für-Schritt-Anleitung
In diesem Tutorial erfahren Sie, wie Sie einen Indeed-Scraper erstellen. Sie werden durch den Prozess der Erstellung eines Python-Skripts geführt, mit dem Sie die Indeed-Stellenanzeigenseite für „Datenwissenschaftler“ scrapen können:
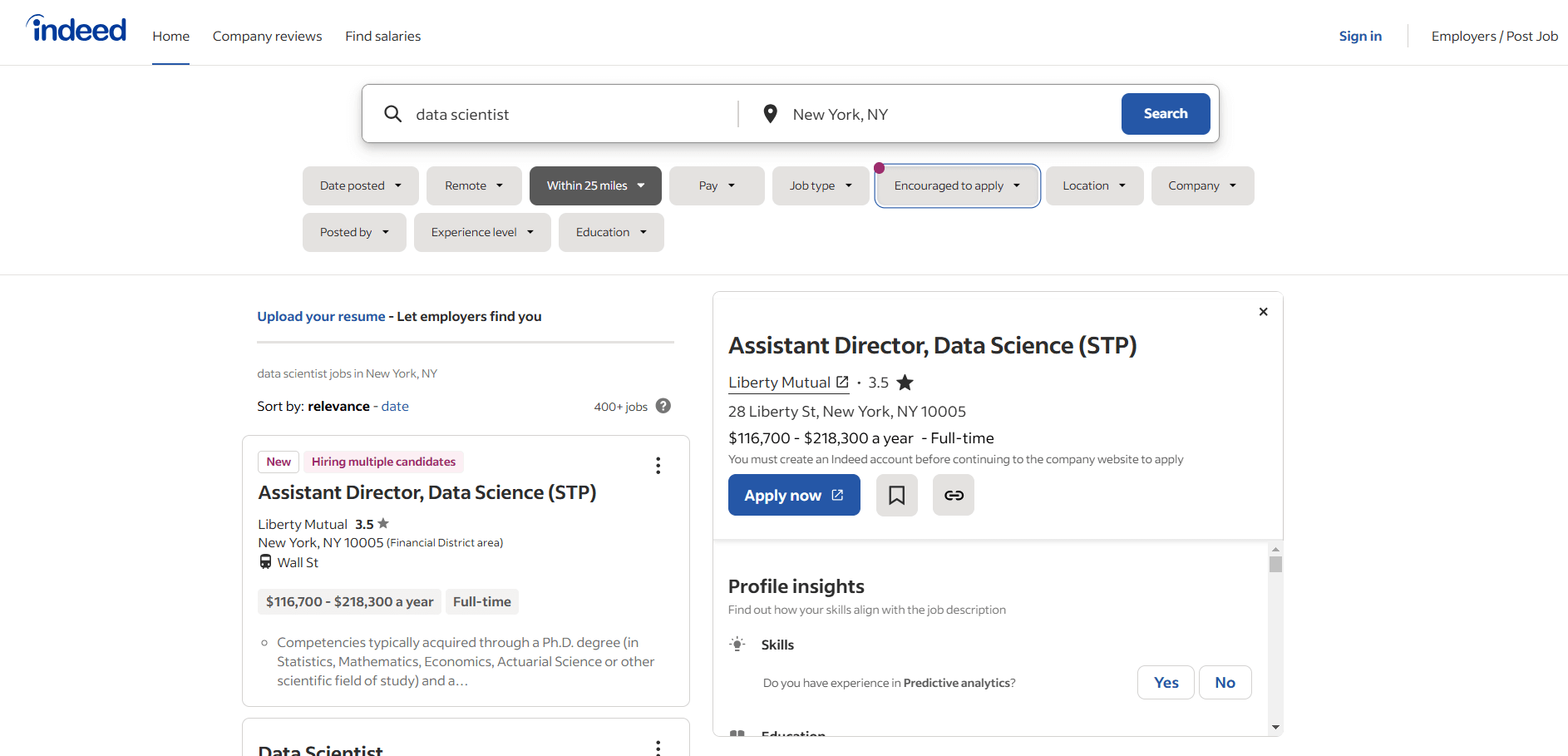
Befolgen Sie die Anweisungen und lernen Sie, wie Sie Indeed scrapen können!
Schritt 1: Projekt einrichten
Bevor Sie beginnen, stellen Sie sicher, dass Python 3 auf Ihrem Computer installiert ist. Ist dies nicht der Fall, laden Sie es herunter und installieren Sie es.
Führen Sie nun den folgenden Befehl im Terminal aus, um ein Verzeichnis für Ihr Projekt zu erstellen:
mkdir indeed_scraper
indeed_scraper enthält Ihren Python-Indeed-Scraper.
Geben Sie ihn in das Terminal ein und initialisieren Sie darin eine virtuelle Umgebung:
cd indeed_scraper
python -m venv env
Laden Sie als Nächstes den Projektordner in Ihre bevorzugte Python-IDE. Visual Studio Code mit der Python-Erweiterung und PyCharm Community Edition sind beide gute Optionen.
Erstellen Sie eine Datei scraper.py im Projektverzeichnis, das nun folgende Dateistruktur aufweisen sollte:

scraper.py wird in Kürze die gewünschte Scraping-Logik enthalten.
Jetzt ist es an der Zeit, die virtuelle Umgebung im Terminal der IDE zu aktivieren. Unter Linux oder macOS führen Sie dazu folgenden Befehl aus:
./env/bin/activate
Unter Windows führen Sie stattdessen folgenden Befehl aus:
env/Scripts/activate
Großartig! Sie haben nun eine Python-Umgebung für das Web-Scraping von Indeed.
Schritt 2: Wählen Sie die richtige Scraping-Bibliothek
Der nächste Schritt besteht darin, festzustellen, ob Indeed auf dynamischen oder statischen Seiten basiert. Öffnen Sie dazu die Indeed-Zielseite im Inkognito-Modus Ihres Browsers und probieren Sie sie aus. Wie Sie leicht erkennen können, werden die meisten Daten auf der Seite dynamisch geladen:
Das reicht aus, um zu sagen, dass Sie ein Browser-Automatisierungstool wie Selenium benötigen, um Indeed effektiv zu scrapen. Weitere Anleitungen zu diesem Vorgang finden Sie in unserem Leitfaden zum Selenium-Web-Scraping.
Mit Selenium können Sie einen Webbrowser programmgesteuert steuern, um Benutzerinteraktionen zu simulieren und mit JavaScript gerenderte Inhalte zu scrapen. Installieren Sie es und legen Sie los!
Schritt 3: Selenium installieren und konfigurieren
Führen Sie in einer aktivierten virtuellen Umgebung den folgenden Befehl aus, um Selenium zu installieren:
pip install -U selenium
Importieren Sie Selenium in scraper.py und richten Sie ein WebDriver -Objekt ein:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# Richten Sie eine steuerbare Chrome-Instanz ein.
driver = webdriver.Chrome(service=Service())
Der obige Code initialisiert alles, was Sie zur Steuerung einer Chrome-Instanz benötigen.
Hinweis: Indeed hat Anti-Scraping-Maßnahmen implementiert, um zu verhindern, dass Headless-Browser auf seine Seiten zugreifen. Daher würde die Einstellung des Flags --headless dazu führen, dass Ihr Skript fehlschlägt. Als alternativen Ansatz können Sie sich Playwright Stealth ansehen.
Vergessen Sie nicht, den Webtreiber als letzte Zeile Ihres Skripts zu schließen:
driver.quit()
Großartig! Sie sind nun vollständig für das Scraping von Indeed konfiguriert.
Schritt 4: Besuchen Sie die Zielseite
Weisen Sie den kontrollierten Browser mit der Methode get() von Selenium an, die Zielseite aufzurufen:
driver.get("https://www.indeed.com/jobs?q=data+scientist&l=New+York%2C+NY&from=searchOnHP%2Cwhatautocomplete&vjk=45d1ba700870fbef")
scraper.py enthält nun die folgenden Codezeilen:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# Richten Sie eine steuerbare Chrome-Instanz ein.
driver = webdriver.Chrome(service=Service())
# Zielseite im Browser öffnen
driver.get("https://www.indeed.com/jobs?q=data+scientist&l=New+York%2C+NY&from=searchOnHP%2Cwhatautocomplete&vjk=45d1ba700870fbef")
# Scraping logc...
# Schließen Sie den Webtreiber.
driver.quit()
Fügen Sie einen Debugging-Haltepunkt in die letzte Zeile ein. Führen Sie das Skript mit dem Debugger aus. Unten sehen Sie, was Sie sehen sollten:
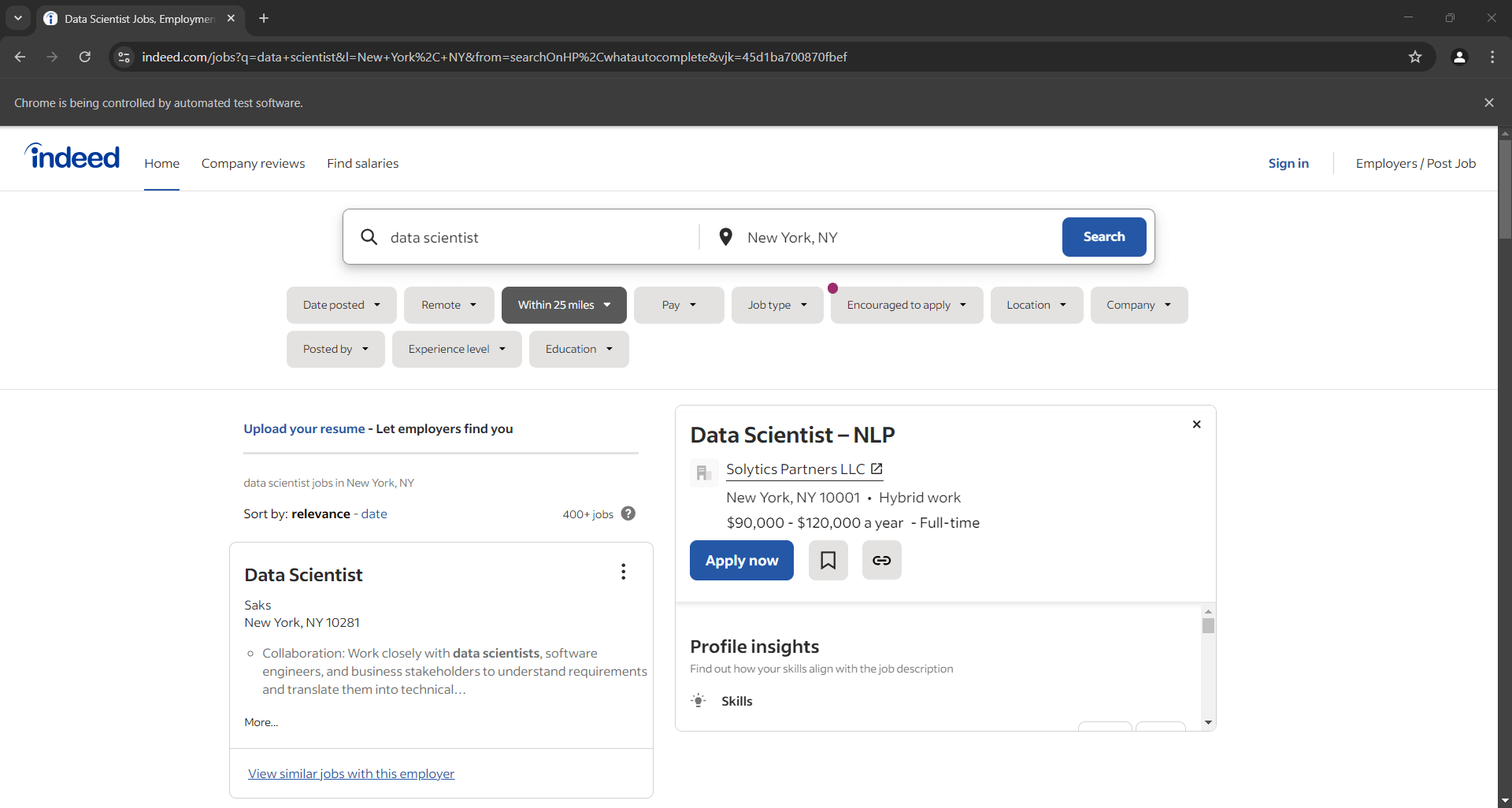
Hinweis: Die Meldung „Chrome wird von einer automatisierten Testsoftware gesteuert“ zeigt an, dass Selenium Chrome wie erwartet steuert.
Gut gemacht!
Schritt 5: Wählen Sie die Elemente der Stellenanzeige aus
Die Indeed-Jobsuche-Seite zeigt zahlreiche Stellenangebote an. Da wir alle diese Stellenangebote scrapen möchten, initialisieren Sie zunächst ein Array, um die gescrapten Daten zu speichern:
jobs = []
Untersuchen Sie als Nächstes die HTML-Elemente der Stellenangebote auf der Seite, um zu verstehen, wie Sie diese auswählen können:
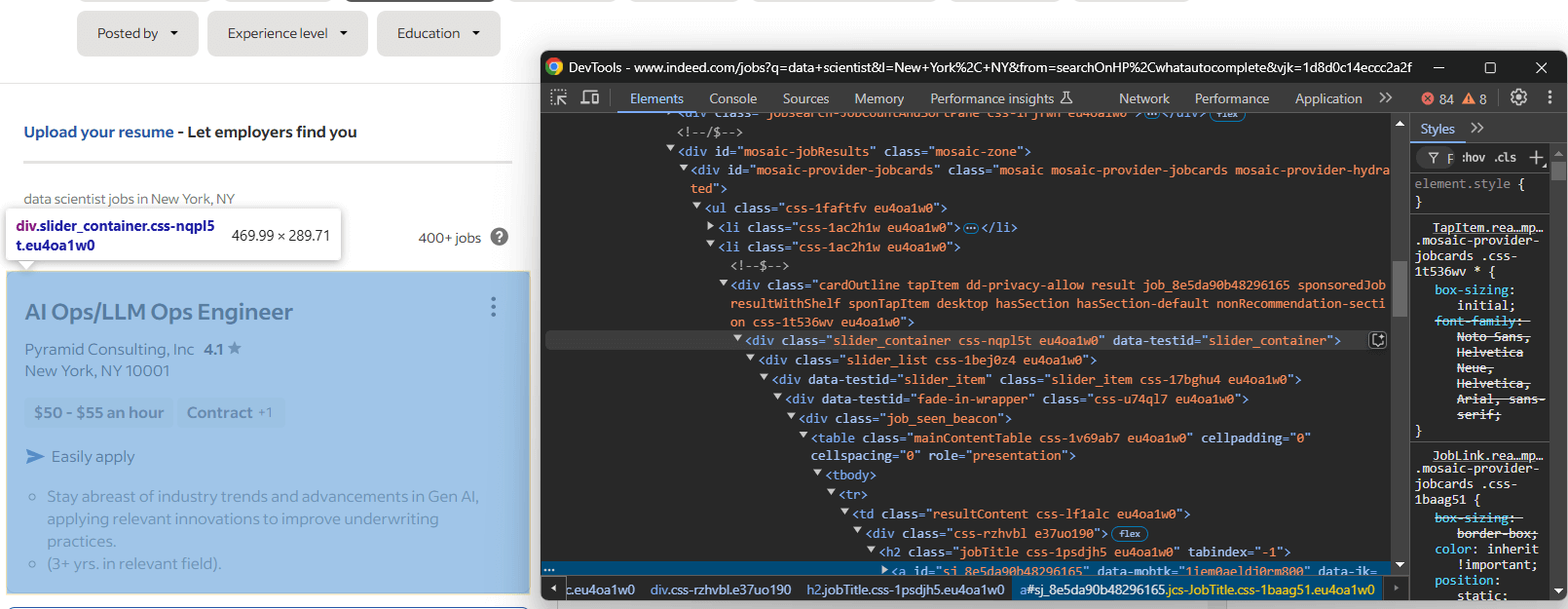
Hier ist jedes Stellenelement ein slider_item -Knoten innerhalb des Containers #mosaic-provider-jobcards.
Normalerweise würden Sie CSS-Klassen verwenden, um Elemente auf der Seite auszuwählen. Diese Klassen scheinen jedoch zufällig generiert zu werden – wahrscheinlich zum Zeitpunkt der Erstellung. Um Stabilität zu gewährleisten, ist es besser, die Attribute „id” und „data-testid” anzusprechen, die sich weniger häufig ändern.
Verwenden Sie Selenium, um die Jobelemente auszuwählen:
jobs_container_element = driver.find_element(By.CSS_SELECTOR, "#mosaic-provider-jobcards")
job_elements = jobs_container_element.find_elements(By.CSS_SELECTOR, "[data-testid="slider_item"]")
Die Methode find_elements() wendet die angegebene Selektorstrategie an, um alle übereinstimmenden Elemente von der Seite abzurufen. In diesem Fall handelt es sich bei der Selektorstrategie um einen CSS-Selektor.
Stellen Sie sicher, dass Sie By importieren, damit dies funktioniert:
from selenium.webdriver.common.by import By
Durchlaufen Sie nun die ausgewählten Elemente und bereiten Sie sich darauf vor, Daten aus jedem einzelnen zu extrahieren:
for job_element in job_elements:
# Daten aus jeder Stellenausschreibung extrahieren
Fantastisch! Sie sind nun bereit, Stellenangebote von Indeed zu scrapen.
Schritt 6: Hauptinformationen der Stellenangebote extrahieren
Untersuchen Sie ein Kartenelement und konzentrieren Sie sich dabei auf die Informationen im oberen Bereich der Karte:
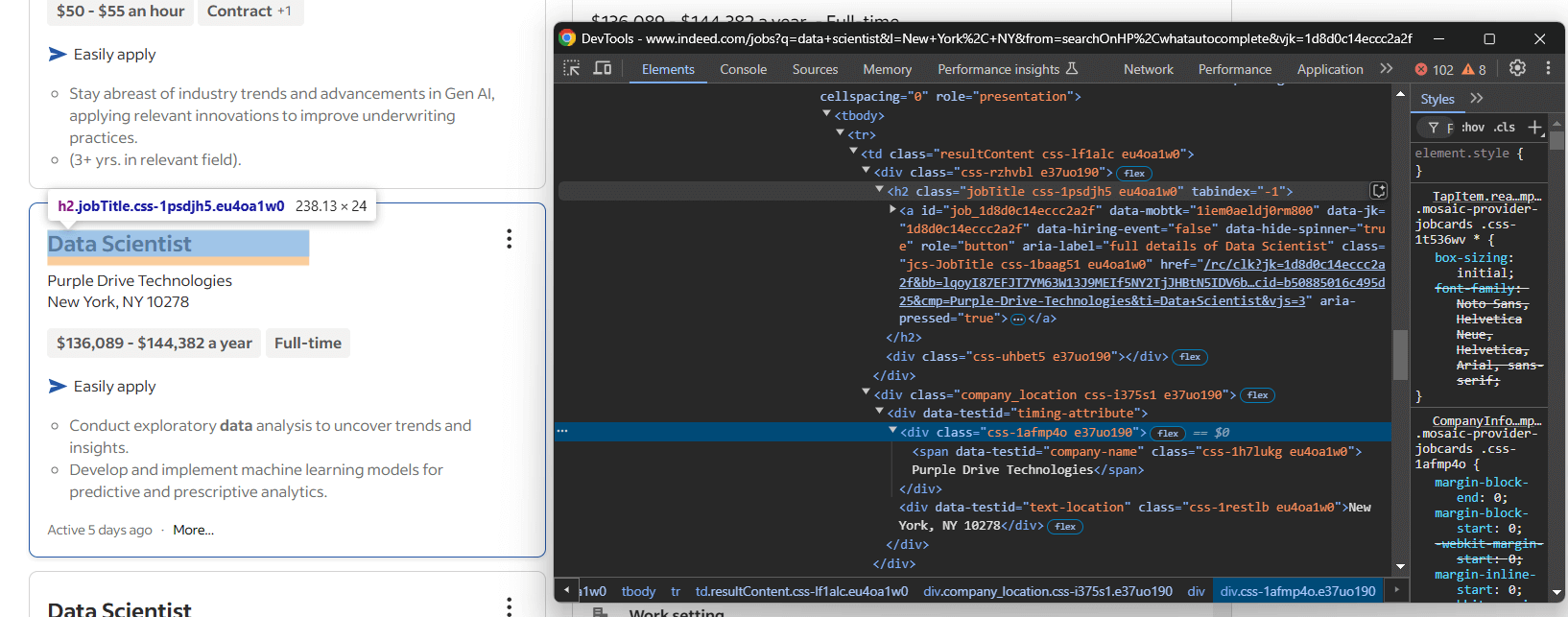
Hier sehen Sie, dass Sie Folgendes extrahieren können:
- Die Stellenbezeichnung aus dem
<h2> - Die URL der Jobseite aus dem
<a>innerhalb des Titels<h2> - Den Firmennamen aus dem Knoten
[data-testid="company-name"] - Den Standort des Unternehmens aus dem Element
[data-testid="text-location"]
Wandeln Sie die oben genannten Informationen wie folgt in eine Scraping-Logik um:
title_element = job_element.find_element(By.CSS_SELECTOR, "h2.jobTitle")
title = title_element.text
url_element = title_element.find_element(By.CSS_SELECTOR, "a")
url = url_element.get_attribute("href")
company_element =job_element.find_element(By.CSS_SELECTOR, "[data-testid="company-name"]")
company = company_element.text
location_element = job_element.find_element(By.CSS_SELECTOR, "[data-testid="text-location"]")
location = location_element.text
find_element() wählt das erste Element aus, das dem angegebenen Selektor entspricht. Bei einem Knoten können Sie dann mit dem Textattribut auf dessen Textinhalt zugreifen. Um den Wert eines HTML-Attributs des Knotens zu erhalten, müssen Sie die Methode get_attribute() verwenden.
Cool! Sie haben die Grundlage für Ihre Indeed-Scraping-Logik geschaffen, aber es gibt noch weitere nützliche Daten, die Sie scrapen können.
Schritt 7: Scrapen Sie die Jobdetails
Konzentrieren Sie sich auf den Abschnitt „Details” der Stellenanzeige:
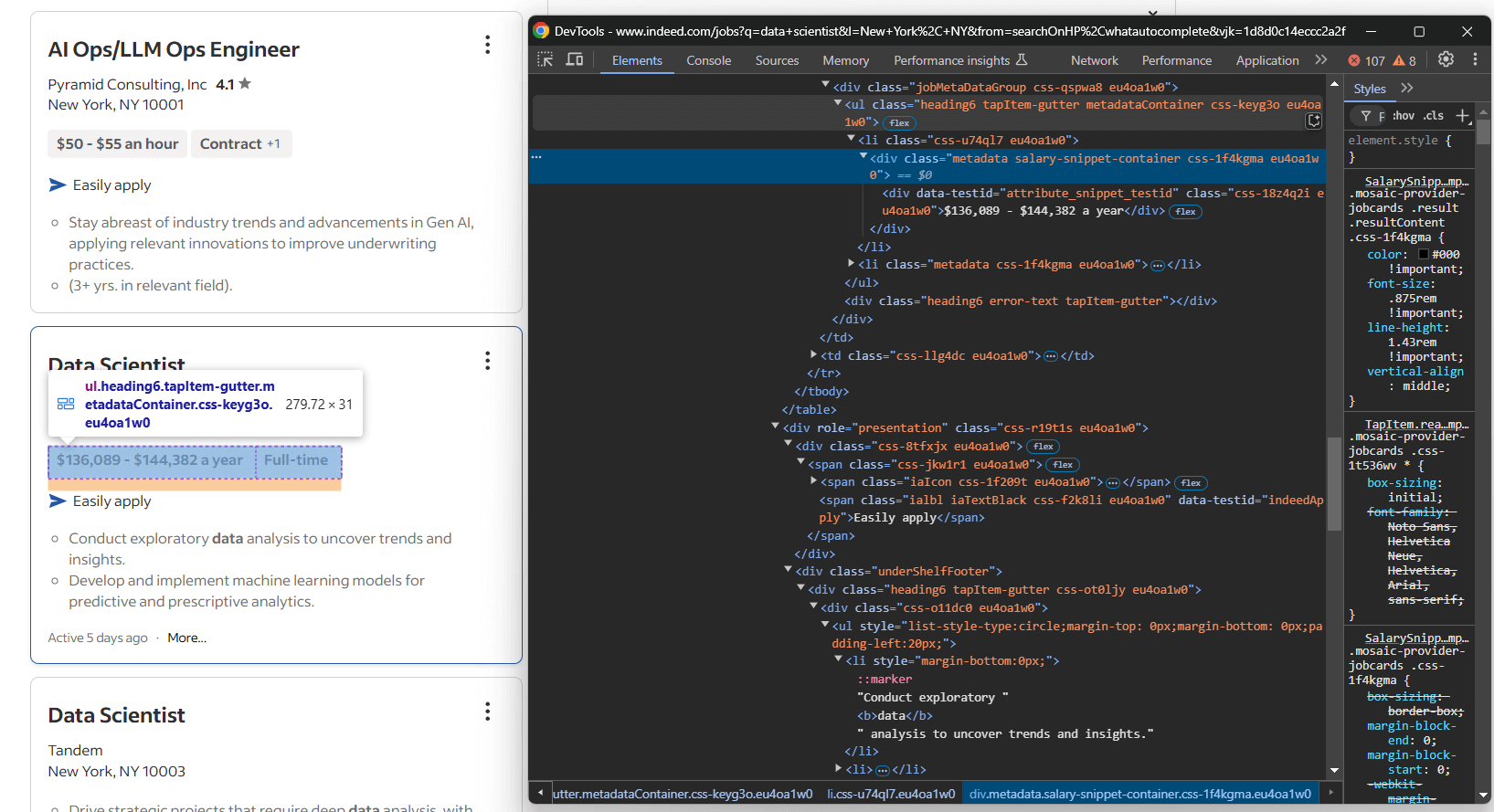
Diesmal sind folgende Informationen zu scrapen:
- Die Tags der Stellenposition in einem oder mehreren
[data-testid="attribute_snippet_testid"]-Elementen innerhalb eines.jobMetaDataGroup<div> - Gibt es eine Option, sich einfach über Indeed zu bewerben?
- Die Beschreibungselemente in einem oder mehreren
ul li-Elementen innerhalb eines[role="presentation"]<div>
Beginnen wir mit den Tags. Sie können alle mit folgendem Befehl scrapen:
tags = []
tags_container_element = job_element.find_element(By.CSS_SELECTOR, ".jobMetaDataGroup")
tag_elements = tags_container_element.find_elements(By.CSS_SELECTOR, "[data-testid="attribute_snippet_testid"]")
for tag_element in tag_elements:
tag = tag_element.text
tags.append(tag)
Zunächst müssen Sie ein Array initialisieren, in dem alle abgerufenen Tags gespeichert werden. Dies ist erforderlich, da eine einzelne Stellenanzeige mehrere Tags enthalten kann. Nachdem Sie diese ausgewählt haben, durchlaufen Sie sie, extrahieren Sie den Text daraus und fügen Sie die Tags zum Array hinzu.
Das Scraping der Informationen zu „Einfach bewerben” ist ebenfalls schwierig. Das Problem besteht darin, dass das HTML-Element, das diese Möglichkeit anzeigt, nicht in allen Stellenangeboten vorhanden ist. Es ist natürlich nur dort vorhanden, wo die Option „Einfach bewerben” unterstützt wird.
Wenn Sie versuchen, ein Element auszuwählen, das nicht auf der Seite vorhanden ist, löst Selenium eine NoSuchElementException aus. Sie können dies also nutzen, um das Kontrollkästchen „Einfach bewerben” effektiv zu scrapen:
try:
job_element.find_element(By.CSS_SELECTOR, "[data-testid="indeedApply"]")
easily_apply = True
except NoSuchElementException:
easily_apply = False
Wenn der Knoten [data-testid="indeedApply"] nicht auf der Seite vorhanden ist, löst Selenium eine NoSuchElementException aus. Diese wird abgefangen und easily_apply wird auf False gesetzt.
Was die Beschreibungselemente angeht, können Sie diese alle wie die Tags scrapen:
description = []
description_container_element = job_element.find_element(By.CSS_SELECTOR, "[role="presentation"]")
description_elements = description_container_element.find_elements(By.CSS_SELECTOR, "ul li")
for description_element in description_elements:
description_item_text = description_element.text
# Leere Beschreibungszeichenfolgen ignorieren
if (description_item_text != ""):
description.append(description_item_text)
Wow! Der Indeed-Scraper ist fast fertig.
Schritt 8: Sammeln Sie die gescrapten Daten
Füllen Sie mit den gescrapten Daten aus jeder Stellenausschreibung ein Stellen wörterbuch:
job = {
"title": title,
"url": url,
"company": company,
"location": location,
"tags": tags,
"easily_apply": easily_apply,
"description": description
}
Fügen Sie es dann zum Array „jobs” hinzu:
jobs.append(job)
Am Ende der for- Schleife sollte products etwa folgenden Inhalt haben:
[{'title': 'Data Scientist', 'url': 'https://www.indeed.com/rc/clk?jk=efc7b7f4a8be2882&bb=NM368jsOPyYGAfEtQk2NNae8tSeBHdJ8Y9tImVa1Q9GAipGe0zzddcUozFEL0Na_pYCR4W6ljgljsBxWTUrluVuL8Gom7x7UZlgMzs0spo3NRgisrZ7meuaPfaEcjWoe&xkcb=SoD767M34WNyEaSTwx0FbzkdCdPP&fccid=8678bc4e64c24580&vjs=3', 'company': 'GQR', 'location': 'New York, NY', 'tags': [], 'easily_apply': False, 'description': ['Bleiben Sie über Branchentrends und neue Technologien auf dem Laufenden, um Ihren Wettbewerbsvorteil zu sichern.', 'Wenden Sie statistische und maschinelle Lernverfahren an, um Investitionen zu verbessern…']},
# der Kürze halber ausgelassen...
{'title': 'Data Scientist, Finanzkriminalität – USDS', 'url': 'https://www.indeed.com/rc/clk?jk=aaa16dfd1cc6ef01&bb=NM368jsOPyYGAfEtQk2NNdxizAZQnHpzRrlr6WgbV1RtxmXz4vto1qiiqGiIj9CJFQQCV6cW59nE4hGw1yeNdokPfu8Fgl3EALBx5zdWjPm4COEu78DCFh4KTUMIFWkh&xkcb=SoAT67M34WNyEaSTwx0pbzkdCdPP&fccid=caed318a9335aac0&vjs=3', 'company': 'TikTok', 'location': 'Hybrid work in New York, NY', 'tags': [], 'easily_apply': False, 'description': ['Als Data Scientist für Finanzkriminalität spielen Sie eine entscheidende Rolle bei der Nutzung von Machine Learning, Analytik und Visualisierungstechniken zur Verbesserung unserer ...']}]
Großartig! Sie müssen diese Daten nur noch in ein besseres Format konvertieren.
Schritt 9: Exportieren Sie die gesammelten Daten in eine CSV-Datei
Um die gescraped Daten zugänglich und teilbar zu machen, ist es eine gute Idee, sie in ein für Menschen lesbares Format zu exportieren. Schreiben Sie sie beispielsweise in eine CSV-Datei. Verwenden Sie dazu diese Codezeilen:
csv_file = "scraped_jobs.csv"
csv_headers = ["title", "url", "company", "location", "tags", "easily_apply", "description"]
with open(csv_file, mode="w", newline="", encoding="utf-8") as file:
writer = csv.DictWriter(file, fieldnames=csv_headers)
writer.writeheader()
for job in jobs:
writer.writerow({
"title": job["title"],
"url": job["url"],
"company": job["company"],
"location": job["location"],
"tags": ";".join(job["tags"]),
"easily_apply": "Yes" if job["easily_apply"] else "No",
"description": ";".join(job["description"])
})
Die Funktion open() erstellt die CSV-Ausgabedatei, die dann mit csv.DictWriter gefüllt wird. Da die Felder „tags” und „description” Arrays sind, werden sie mit join() zu einer einzigen Zeichenfolge mit durch ; getrennten Elementen abgeflacht.
Vergessen Sie nicht, csv aus der Python-Standardbibliothek zu importieren:
import csv
Das war’s schon! Der Indeed-Scraper ist fertig.
Schritt 10: Alles zusammenfügen
Ihre endgültige scraper.py -Datei enthält nun:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.common import NoSuchElementException
import csv
# Richten Sie eine steuerbare Chrome-Instanz ein.
driver = webdriver.Chrome(service=Service())
# Öffnen Sie die Zielseite im Browser
driver.get("https://www.indeed.com/jobs?q=data+scientist&l=New+York%2C+NY&from=searchOnDesktopSerp")
# Eine Datenstruktur, in der die gescrapten Stellenangebote gespeichert werden
jobs = []
# Wählen Sie die Stellenangebotselemente auf der Seite aus
jobs_container_element = driver.find_element(By.CSS_SELECTOR, "#mosaic-provider-jobcards")
job_elements = jobs_container_element.find_elements(By.CSS_SELECTOR, "[data-testid="slider_item"]")
# Jede Stellenanzeige auf der Seite scrapen
for job_element in job_elements:
title_element = job_element.find_element(By.CSS_SELECTOR, "h2.jobTitle")
title = title_element.text
url_element = title_element.find_element(By.CSS_SELECTOR, "a")
url = url_element.get_attribute("href")
company_element =job_element.find_element(By.CSS_SELECTOR, "[data-testid="company-name"]")
company = company_element.text
location_element = job_element.find_element(By.CSS_SELECTOR, "[data-testid="text-location"]")
location = location_element.text
tags = []
tags_container_element = job_element.find_element(By.CSS_SELECTOR, ".jobMetaDataGroup")
tag_elements = tags_container_element.find_elements(By.CSS_SELECTOR, "[data-testid="attribute_snippet_testid"]")
for tag_element in tag_elements:
tag = tag_element.text
tags.append(tag)
# Überprüfen, ob das Element „Easy Apply” auf der Seite vorhanden ist
try:
job_element.find_element(By.CSS_SELECTOR, "[data-testid="indeedApply"]")
easily_apply = True
except NoSuchElementException:
easily_apply = False
description = []
description_container_element = job_element.find_element(By.CSS_SELECTOR, "[role="presentation"]")
description_elements = description_container_element.find_elements(By.CSS_SELECTOR, "ul li")
for description_element in description_elements:
description_item_text = description_element.text
# Leere Beschreibungszeichenfolgen ignorieren
if (description_item_text != ""):
description.append(description_item_text)
# Gescrapte Daten speichern
job = {
"title": title,
"url": url,
"company": company,
"location": location,
"tags": tags,
"easily_apply": easily_apply,
"description": description
}
jobs.append(job)
# Exportieren der gescrapten Daten in eine CSV-Ausgabedatei
csv_file = "jobs.csv"
csv_headers = ["title", "url", "company", "location", "tags", "easily_apply", "description"]
with open(csv_file, mode="w", newline="", encoding="utf-8") as file:
writer = csv.DictWriter(file, fieldnames=csv_headers)
writer.writeheader()
for job in jobs:
writer.writerow({
"title": job["title"],
"url": job["url"],
"company": job["company"],
"location": job["location"],
"tags": ";".join(job["tags"]),
"easily_apply": "Yes" if job["easily_apply"] else "No",
"description": ";".join(job["description"])
})
# Schließen Sie den Webtreiber.
driver.quit()
Mit weniger als 100 Zeilen Code haben Sie gerade einen Indeed-Scraper in Python erstellt!
Starten Sie den Scraper mit dem folgenden Befehl:
python3 script.py
Oder unter Windows:
python script.py
Eine Datei namens jobs.csv wird im Ordner Ihres Projekts angezeigt. Öffnen Sie sie und Sie sehen:
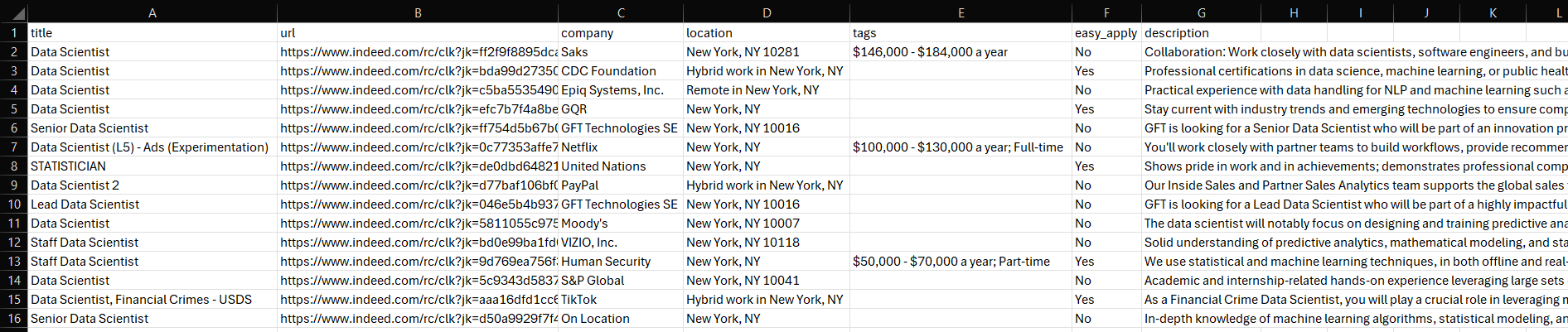
Et voilà! Mission erfüllt.
Indeed-Daten ganz einfach freischalten
Indeed ist sich des Werts seiner Daten bewusst und setzt robuste Maßnahmen zu deren Schutz ein. Aus diesem Grund werden Sie bei der Interaktion mit den Seiten mithilfe eines Browser-Automatisierungstools wie Selenium wahrscheinlich auf ein CAPTCHA stoßen:
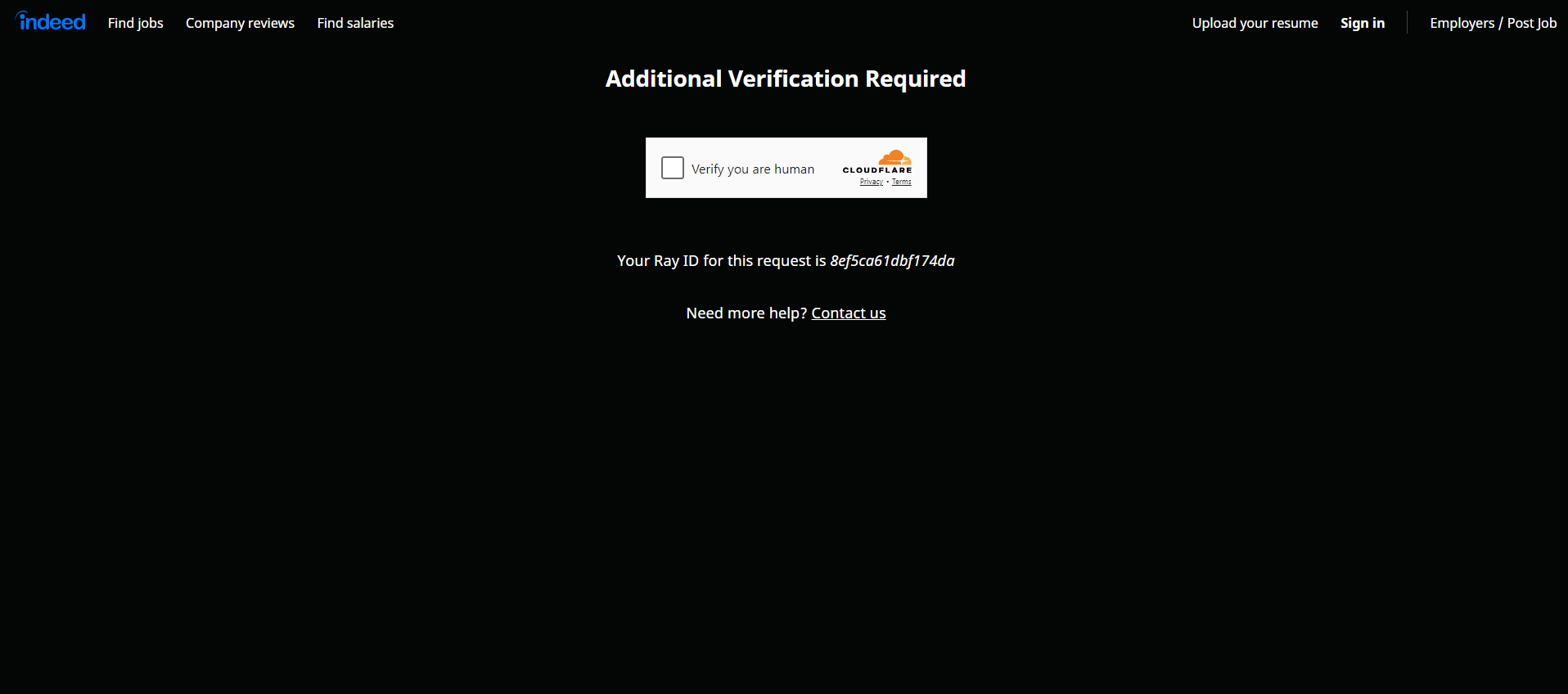
Als ersten Schritt sollten Sie unsere Anleitung zum Umgehen von CAPTCHAs in Python befolgen. Beachten Sie jedoch, dass die Website Ihre Versuche möglicherweise weiterhin mit zusätzlichen Anti-Bot-Maßnahmen blockiert. Entdecken Sie alle diese Maßnahmen in unserem Webinar zu Anti-Bot-Techniken.
Diese Herausforderungen zeigen, wie frustrierend und ineffizient das Scraping von Indeed ohne die richtigen Tools schnell werden kann. Darüber hinaus verlangsamt die Unmöglichkeit, Headless-Browser zu verwenden, Ihr Scraping-Skript und macht es ressourcenintensiver.
Die Lösung? Die Indeed Scraper API von Bright Data. Mit diesem Tool können Sie Daten von Indeed nahtlos über einfache API-Aufrufe abrufen – ohne CAPTCHAs, ohne Blockierungen und ohne Probleme!
Fazit
In dieser Schritt-für-Schritt-Anleitung haben Sie gelernt, was ein Indeed-Scraper ist, welche Arten von Daten er abrufen kann und wie man einen solchen Scraper in Python erstellt. Mit nur etwa 100 Zeilen Code haben Sie ein Skript erstellt, das automatisch Daten von Indeed sammelt.
Dennoch birgt das Scraping von Indeed einige Herausforderungen. Die Plattform wendet strenge Anti-Bot-Maßnahmen an, darunter CAPTCHAs. Diese sind schwer zu umgehen und können Ihren Scraping-Prozess verlangsamen, wodurch er weniger effizient wird. Mit unserer Indeed Scraper API können Sie all diese Herausforderungen vergessen.
Wenn Web-Scraping nicht Ihr Ding ist, Sie aber dennoch an Daten zu Stellenangeboten interessiert sind, entdecken Sie unsere gebrauchsfertigen Indeed-Datensätze!
Erstellen Sie noch heute ein kostenloses Bright Data-Konto, um unsere Scraper-APIs auszuprobieren oder unsere Datensätze zu erkunden.




