

In diesem Leitfaden erfahren Sie:
- Was ein Crunchbase-Scraper ist und wie er funktioniert
- Welche Daten Sie automatisch aus Crunchbase sammeln können
- Wie Sie mit Python ein Crunchbase-Scraping-Skript erstellen
- Warum Sie möglicherweise eine fortschrittlichere Lösung benötigen, um die Website zu scrapen
Lassen Sie uns loslegen!
Was ist ein Crunchbase-Scraper?
Ein Crunchbase-Scraper ist ein automatisiertes Tool, das Daten aus Crunchbase-Webseiten extrahiert. Es navigiert durch die Website, identifiziert die gewünschten Informationen und sammelt sie durch Web-Scraping.
Crunchbase setzt fortschrittliche Anti-Bot- und Anti-Scraping-Maßnahmen ein, um seine Daten zu schützen. Daher muss ein effektiver Crunchbase-Scraper Funktionen wie JavaScript-Rendering, CAPTCHA-Lösung und Browser-Fingerprint-Spoofing enthalten.
Welche Daten können von Crunchbase gescrapt werden?
Nachfolgend finden Sie eine Liste der Daten, die Sie über Web-Scraping automatisch aus Crunchbase abrufen können:
- Unternehmensinformationen: Name, Beschreibung, Branche, Standort der Zentrale, Gründungsdatum, Status (z. B. aktiv, übernommen) und mehr
- Finanzierungsdaten: Gesamtfinanzierungsbetrag, Finanzierungsrunden, Investoren und mehr
- Wichtige Personen: Gründer, Führungskräfte, Mitglieder, Rollen und Titel und mehr
- Produkte und Dienstleistungen: Produktbeschreibungen, Kategorien der angebotenen Produkte oder Dienstleistungen und mehr
- Übernahmen und Fusionen: Details zu übernommenen Unternehmen, Daten und Bedingungen der Übernahmen und mehr
- Markt- und Finanzdaten: Umsatzschätzungen, Anzahl der Mitarbeiter und mehr
- Nachrichten und Ereignisse: Pressemitteilungen, wichtige Meilensteine oder Ereignisse und mehr
- Wettbewerber: Liste konkurrierender Unternehmen und mehr
So erstellen Sie einen Crunchbase-Scraper in Python
In diesem Tutorial-Abschnitt erfahren Sie, wie Sie einen Crunchbase-Scraper mit Python erstellen. Das Ziel ist es, ein Skript zu entwickeln, das automatisch Daten von der Bright Data Crunchbase-Seite sammelt:
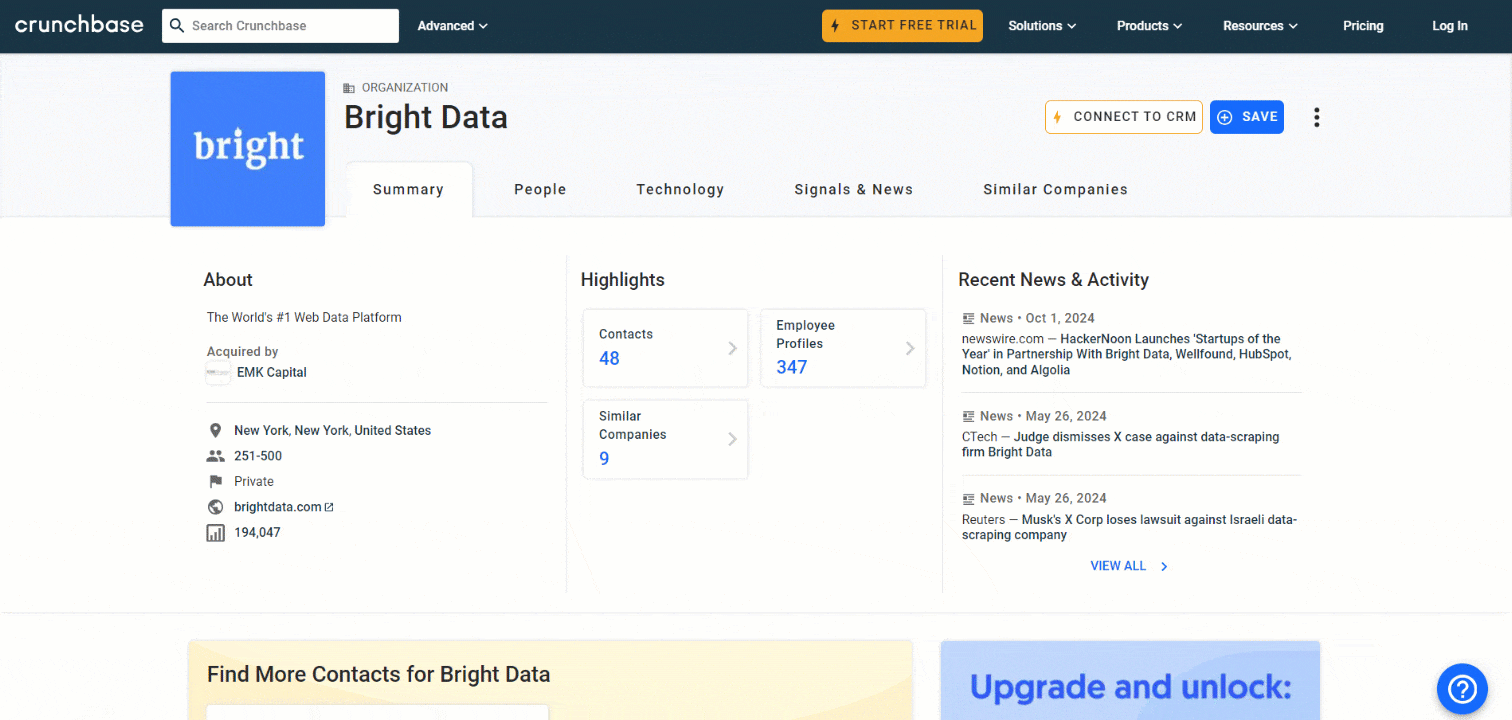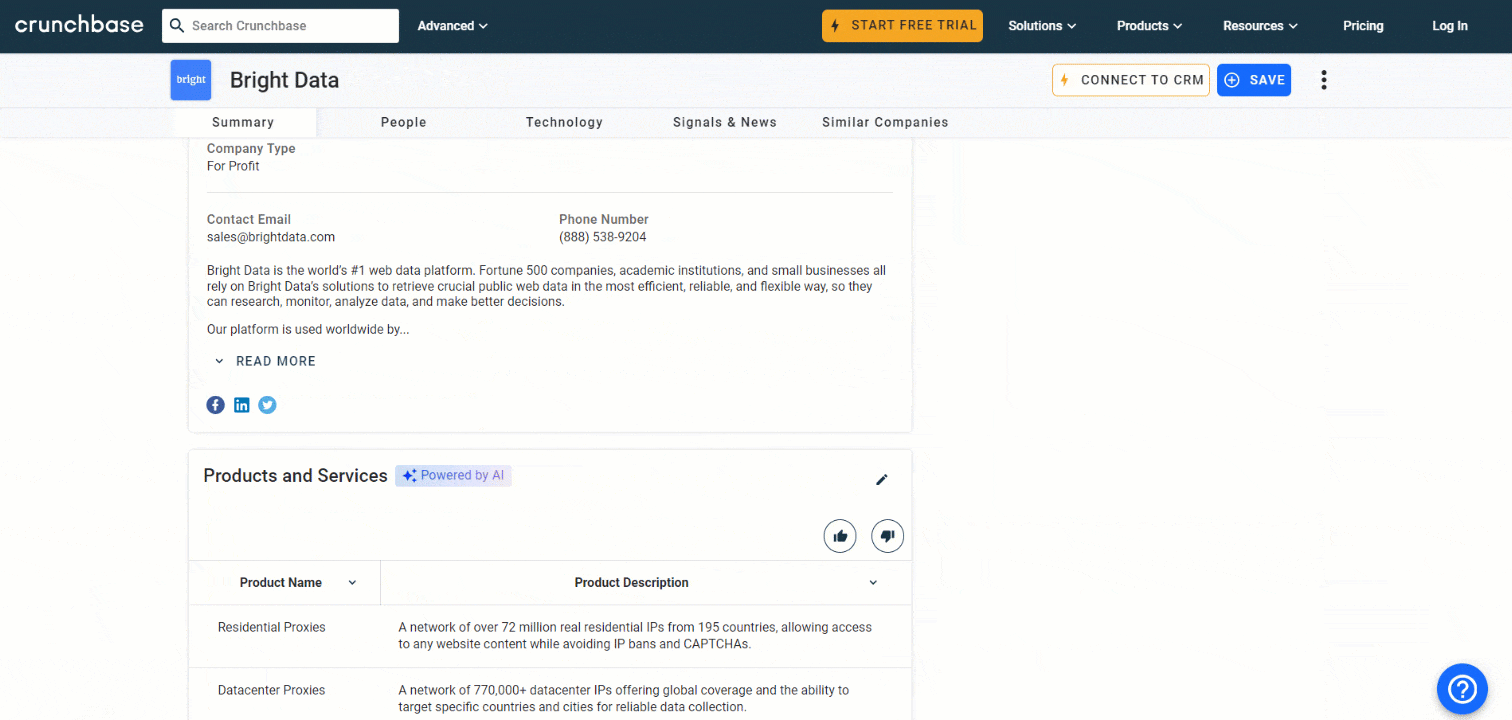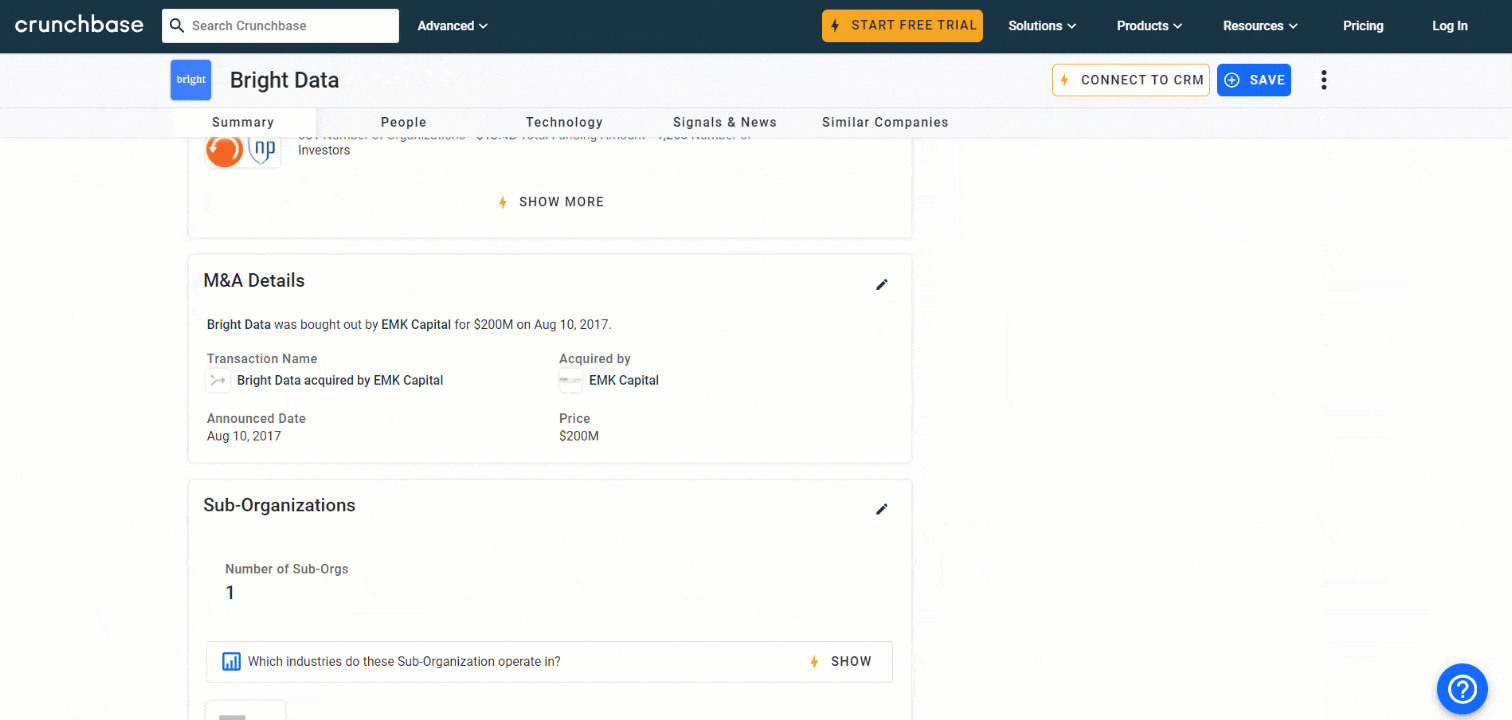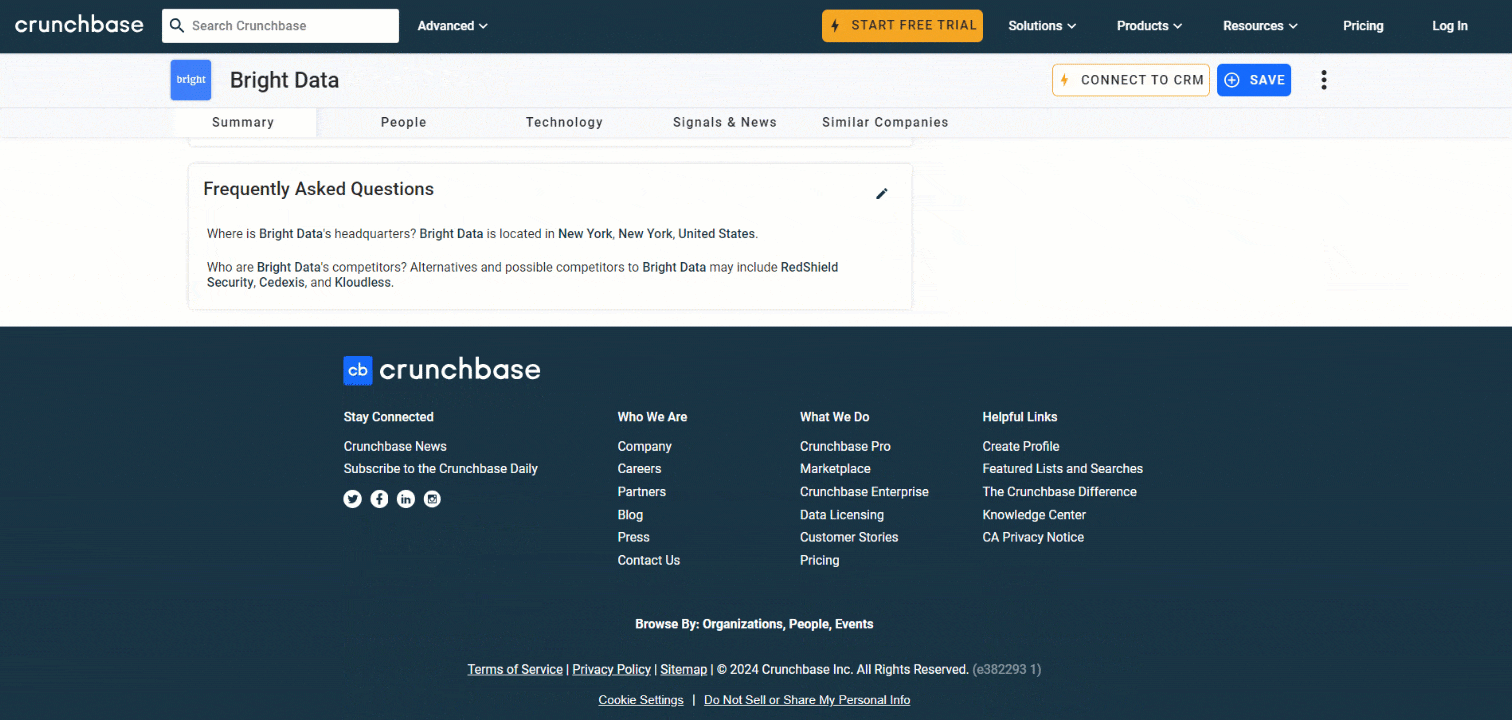
Befolgen Sie die folgenden Schritte, um zu erfahren, wie Sie Crunchbase mit Python scrapen können!
Schritt 1: Erstellen Sie ein Python-Projekt
Stellen Sie zunächst sicher, dass Python 3+ auf Ihrem Computer installiert ist. Ist dies nicht der Fall, laden Sie es von der offiziellen Website herunter und befolgen Sie die Anweisungen.
Erstellen Sie ein Verzeichnis für Ihren Python Crunchbase-Scraper:
mkdir crunchbase-scraperDer Ordner „crunchbase-scraper” enthält Ihren Scraper.
Öffnen Sie den Projektordner in Ihrer bevorzugten Python-IDE, z. B. PyCharm Community Edition oder Visual Studio Code mit der Python-Erweiterung.
Erstellen Sie als Nächstes eine Datei namens scraper.py im Projektordner. Diese Datei enthält die Crunchbase-Scraping-Logik.
Initialisieren Sie nun eine virtuelle Python-Umgebung. Wenn Sie macOS oder Linux verwenden, führen Sie folgenden Befehl aus:
python3 -m venv envUnter Windows führen Sie stattdessen folgenden Befehl aus:
python -m venv envDadurch wird Ihrem Projekt ein Verzeichnis „env“ hinzugefügt.
Jetzt sollte dein Projekt die folgende Struktur haben:

Aktivieren Sie die virtuelle Umgebung mit diesem Befehl:
source env/bin/activateOder unter Windows:
envScriptsactivateGroßartig! Sie haben nun ein Python-Projekt, in dem Sie lokale Abhängigkeiten installieren können.
Beachten Sie, dass Sie Ihr Skript mit folgendem Befehl starten können:
python3 Scraper.pyOder unter Windows:
python Scraper.pySchritt 2: Scraping-Bibliotheken ermitteln und installieren
Sie müssen nun herausfinden, welche Scraping-Bibliotheken für die Extraktion von Daten aus Crunchbase am besten geeignet sind. Beginnen Sie damit, eine GET-HTTP-Anfrage an die Zielwebseite mit einem Desktop-HTTP-Client zu senden. Hier ist das Ergebnis, das Sie erhalten werden:
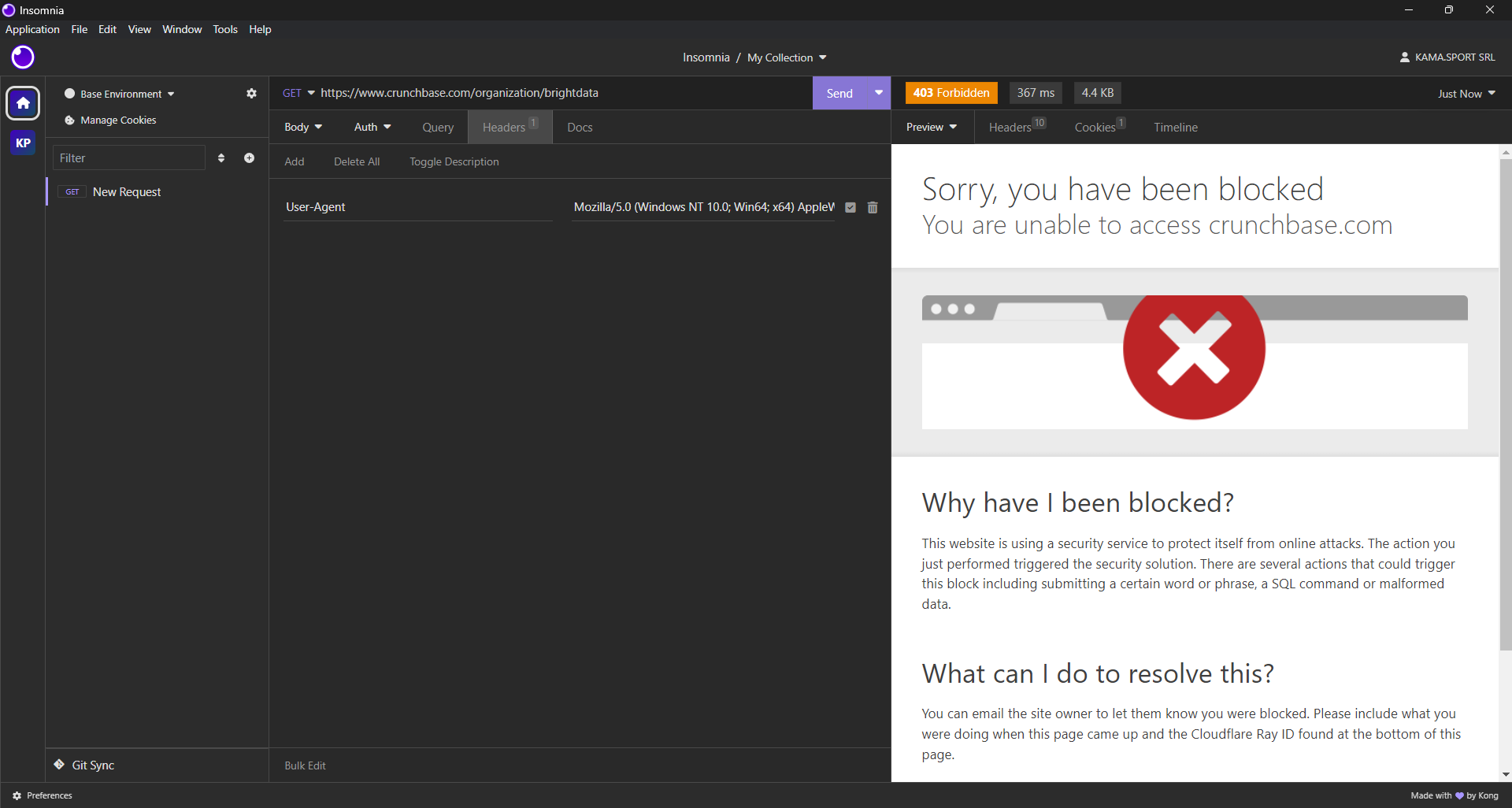
Wie Sie sehen können, blockiert Crunchbase Ihre Anfrage – selbst wenn Sie realistische Browser-Header verwenden. Mit anderen Worten: Sie benötigen ein Browser-Automatisierungstool, um Crunchbase effektiv zu scrapen. Weitere Informationen finden Sie in unserem Artikel über die besten Headless-Browser.
Für Python ist Selenium eines der beliebtesten Headless-Browser-Automatisierungstools. Im Detail ermöglicht es Ihnen, einen Browser anzuweisen, bestimmte Interaktionen durchzuführen und Daten aus dynamischen Seiten zu scrapen.
Um Selenium zu installieren, verwenden Sie das Selenium -Pip-Paket. Führen Sie in einer aktivierten virtuellen Python-Umgebung den folgenden Befehl aus:
pip install -U seleniumImportieren Sie dann Selenium in Ihre scraper.py-Datei mit der folgenden Zeile:
from selenium import webdriverGroßartig! Jetzt haben Sie alles, was Sie für das Web-Scraping auf Crunchbase benötigen.
Schritt 3: Besuchen Sie die Zielseite
Initialisieren Sie eine Chrome WebDriver-Instanz und verwenden Sie die Methode get(), um den kontrollierten Browser anzuweisen, die gewünschte Seite aufzurufen:
driver = webdriver.Chrome()
url = "https://www.crunchbase.com/organization/brightdata"
driver.get(url)Vergessen Sie anschließend nicht, den WebDriver zu schließen und die Browser-Ressourcen freizugeben mit:
driver.quit()Derzeit enthält Ihr Crunchbase-Scraper-Skript Folgendes:
from selenium import webdriver
# Initialisieren Sie den Treiber, um eine Chrome-Instanz zu steuern.
# Im Header-Modus.
driver = webdriver.Chrome()
# Navigieren Sie zur gewünschten Crunchbase-Seite.
url = "https://www.crunchbase.com/organization/brightdata"
driver.get(url)
# Scraping-Logik...
# Schließen Sie den Treiber und geben Sie die Browser-Ressourcen frei.
driver.quit()Wenn Sie das Skript ausführen, wird für den Bruchteil einer Sekunde die folgende Seite angezeigt, bevor das Skript beendet wird:
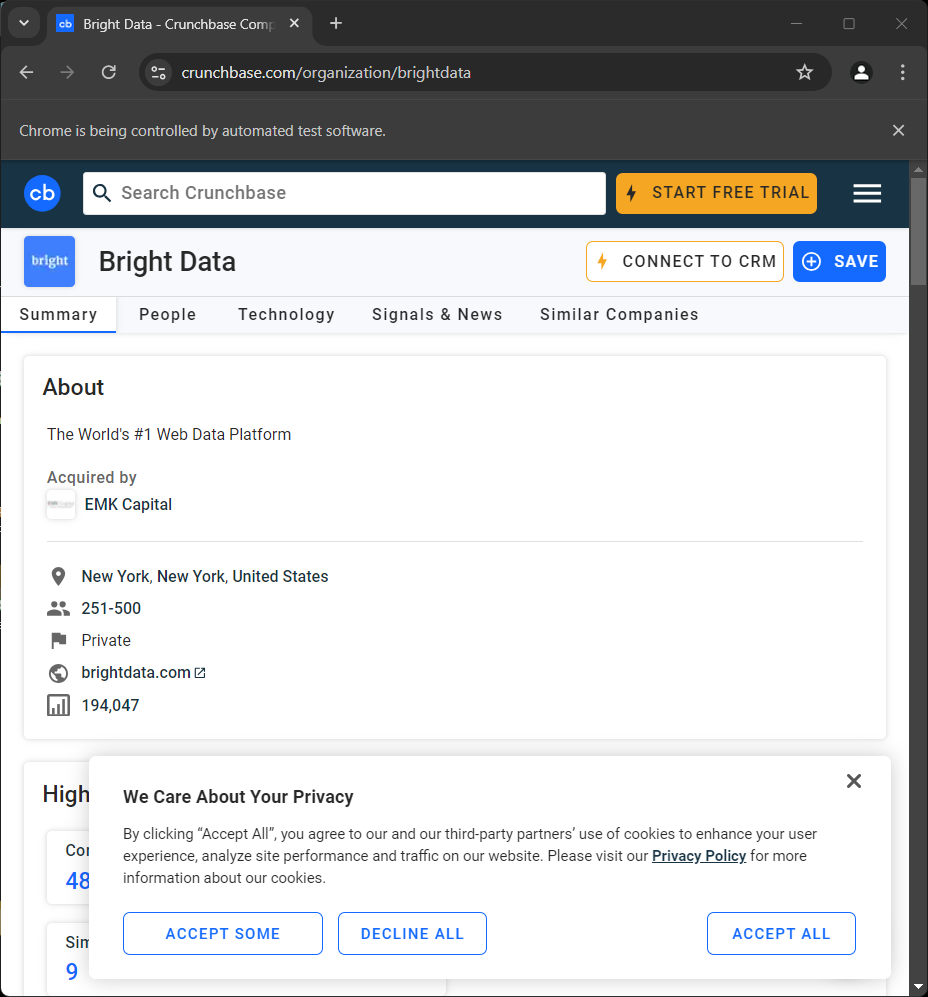
Die Meldung „Chrome wird von Testsoftware gesteuert” signalisiert, dass Selenium wie vorgesehen auf Chrome läuft.
Normalerweise werden Browser in Selenium-Scraping-Skripten im Headless-Modus gestartet, um Ressourcen zu sparen. Leider verfügt Crunchbase über ein fortschrittliches Anti-Bot-Erkennungssystem, das Headless-Browser blockiert. Daher müssen Sie den Browser im Head-Modus lassen. Alternativ können Sie versuchen, Playwright Stealth zu verwenden, um diese Erkennungsmechanismen zu umgehen.
Schritt 4: Umgang mit dem Cookie-Popup
Wenn Sie ein europäischer Nutzer sind, wird nach einigen Sekunden das folgende Cookie-Popup angezeigt:
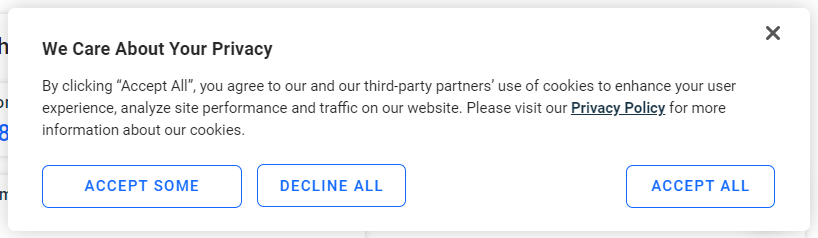
Wenn Sie nicht auf die Schaltfläche „Alle akzeptieren“ klicken, ist eine Interaktion mit der Seite nicht möglich. Überprüfen Sie die Schaltfläche:
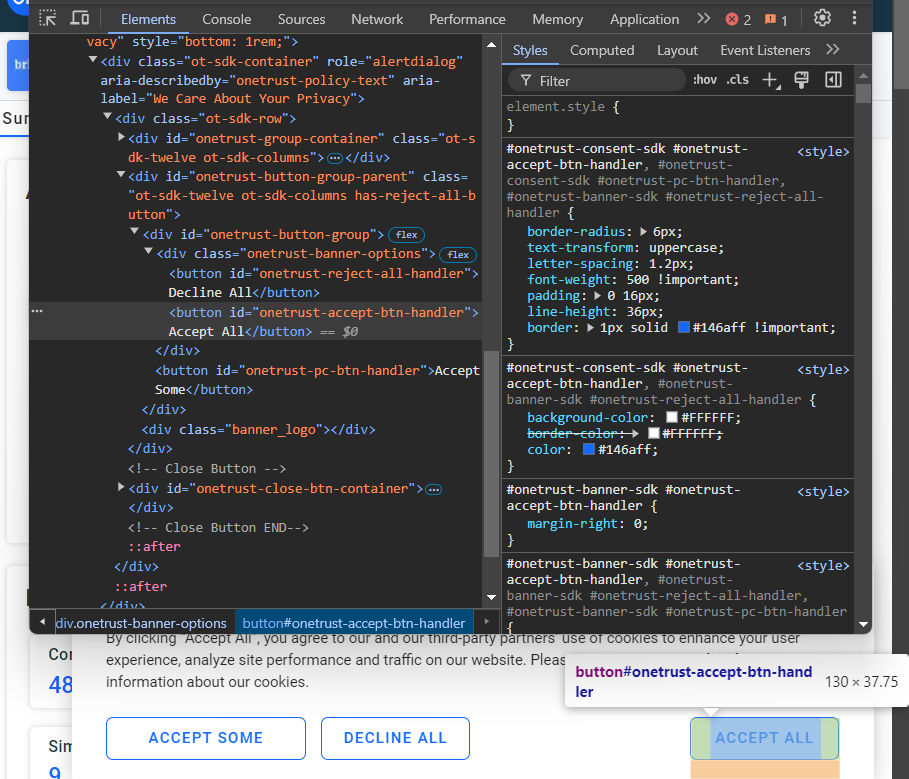
Sie können ihn mit dem CSS-Selektor #onetrust-accept-btn-handler auswählen.
Schreiben Sie nun eine Funktion, die bis zu 60 Sekunden wartet, bis die Schaltfläche „Alle akzeptieren“ auf der Seite angezeigt wird und anklickbar ist, und klicken Sie dann darauf:
def handle_cookie_banner(driver, seconds=60):
try:
# warte die angegebene Anzahl von Sekunden, bis die Schaltfläche „Alle akzeptieren“
# des Cookie-Banners auf der Seite erscheint
accept_button = WebDriverWait(driver, seconds).until(
EC.element_to_be_clickable((By.CSS_SELECTOR, "#onetrust-accept-btn-handler"))
)
# Klicke über JavaScript auf das Banner, um
# ElementClickInterceptedException-Fehler zu vermeiden
driver.execute_script("arguments[0].click();", accept_button)
print("Schaltfläche 'Alle akzeptieren' angeklickt")
except:
print("Schaltfläche 'Alle akzeptieren' innerhalb von {seconds} Sekunden nicht gefunden")Beachten Sie:
- Der
try ... except-Block ist erforderlich, da das Cookie-Popup möglicherweise nicht auf der Seite angezeigt wird. In diesem Falllöst WebDriverWaiteineNoSuchElementExceptionaus, die vonexceptabgefangen wird. - „Alle akzeptieren“ wird über JavaScript und nicht über die Methode
click()angeklickt. Der Grund dafür ist, dass die HTML-Schaltfläche langsam mit einer Einblendanimation erscheint. Wenn Sie also versuchen, sie mitclick()anzuklicken, erhalten Sie möglicherweise eineElementClickInterceptedException.
Damit die obige Funktion funktioniert, sind die folgenden Importe erforderlich:
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import BySie können das Cookie-Popup nun wie folgt aufrufen:
handle_cookie_banner(driver)Fantastisch! Machen Sie sich bereit, mit dem Scraping der Daten auf der Seite zu beginnen.
Schritt 5: Scrapen Sie die Informationen unter „Über uns“
Die erste Information, die Sie in der Karte „Zusammenfassung” scrapen sollten, ist die „Über”-Beschreibung des Unternehmens:
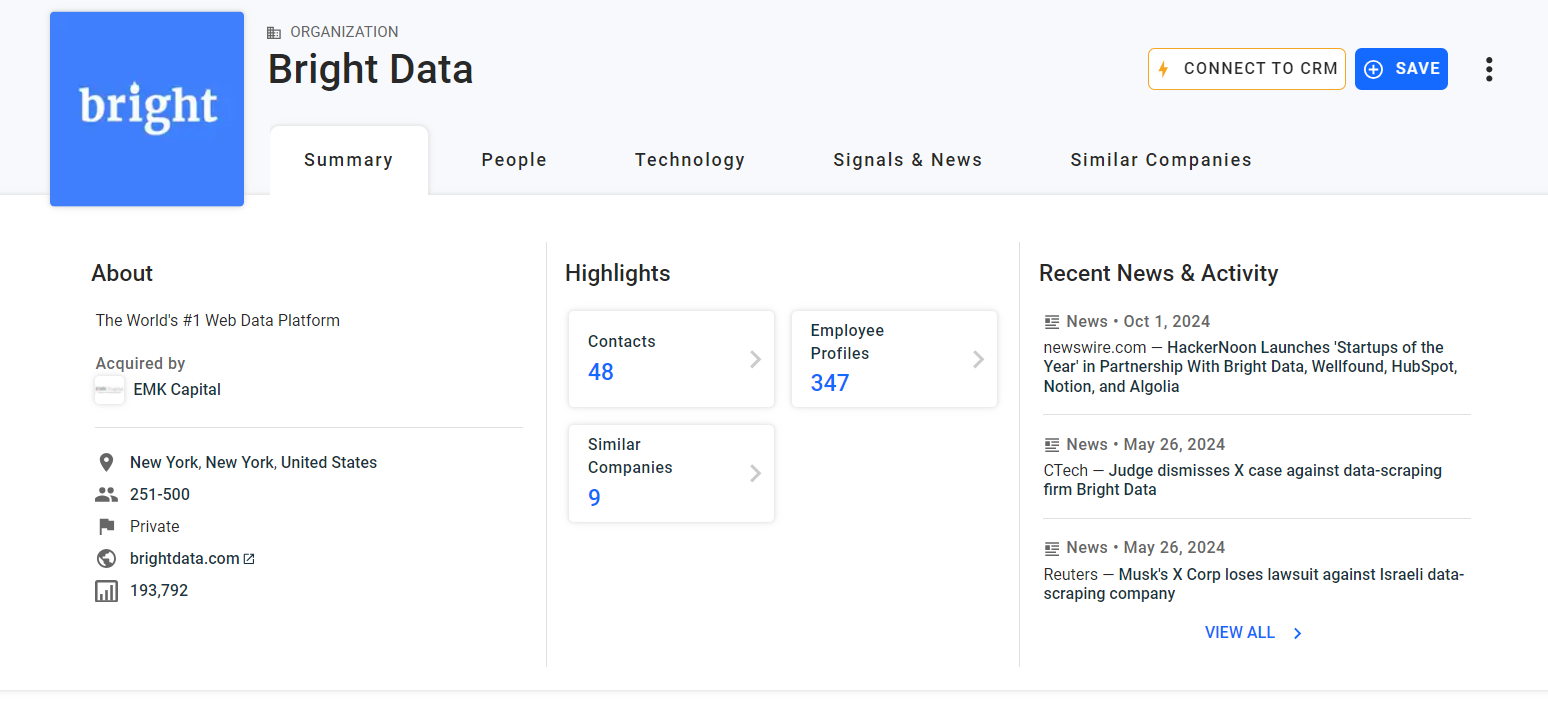
Überprüfen Sie das HTML-Element „Über uns”:
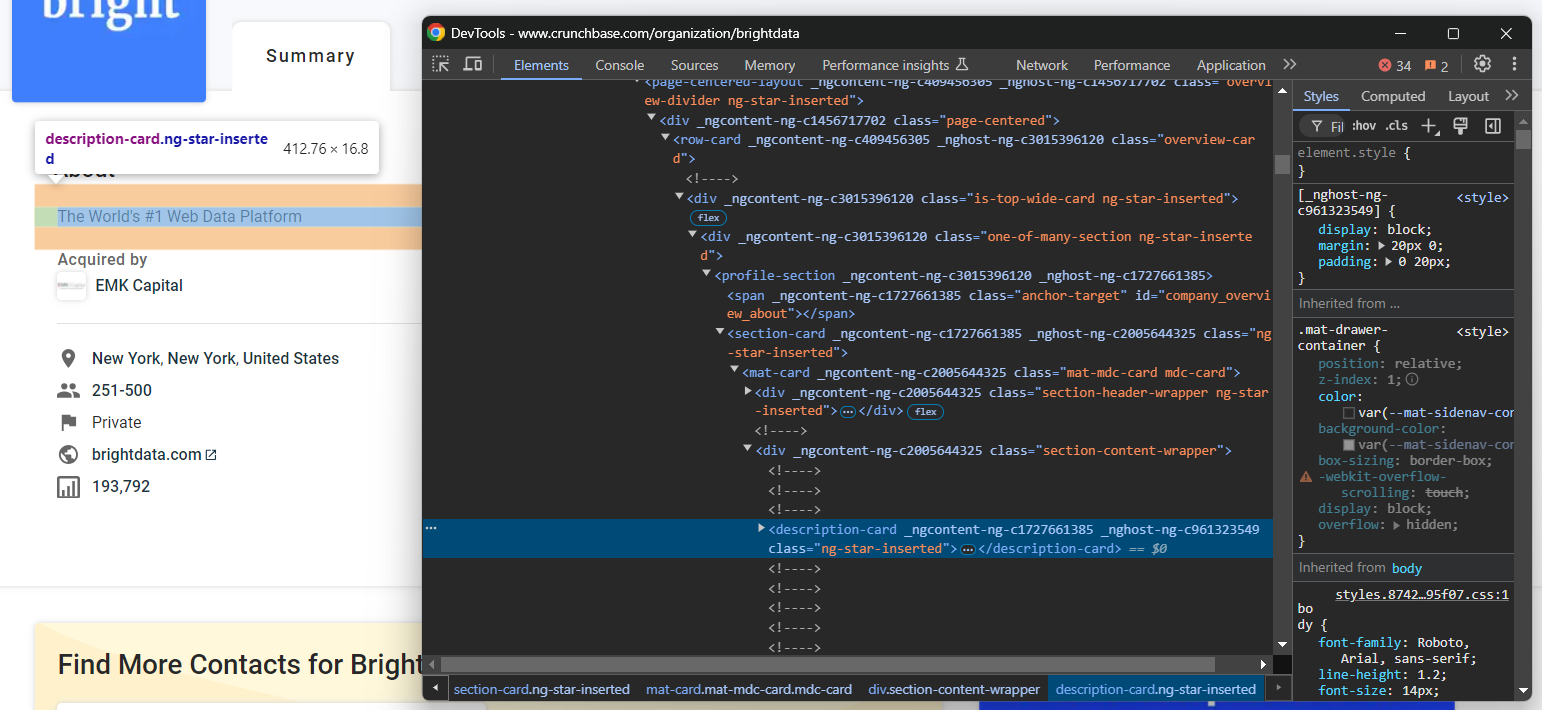
Beachten Sie, dass Sie es mit dem folgenden CSS-Selektor auswählen können:
profile-section description-cardVerwenden Sie die Methode find_element(), um den CSS-Selektor auf die Seite anzuwenden. Extrahieren Sie dann den Text innerhalb des Knotens mit dem Textattribut:
about_node = driver.find_element(By.CSS_SELECTOR, "profile-section description-card")
about = about_node.textDie Variable „about“ enthält nun:
„Die weltweit führende Webdatenplattform”Los geht’s!
Schritt 6: Überprüfen Sie die Seitenstruktur
Konzentrieren Sie sich nun auf die Informationen, die in der Karte „Details” auf der Seite enthalten sind:
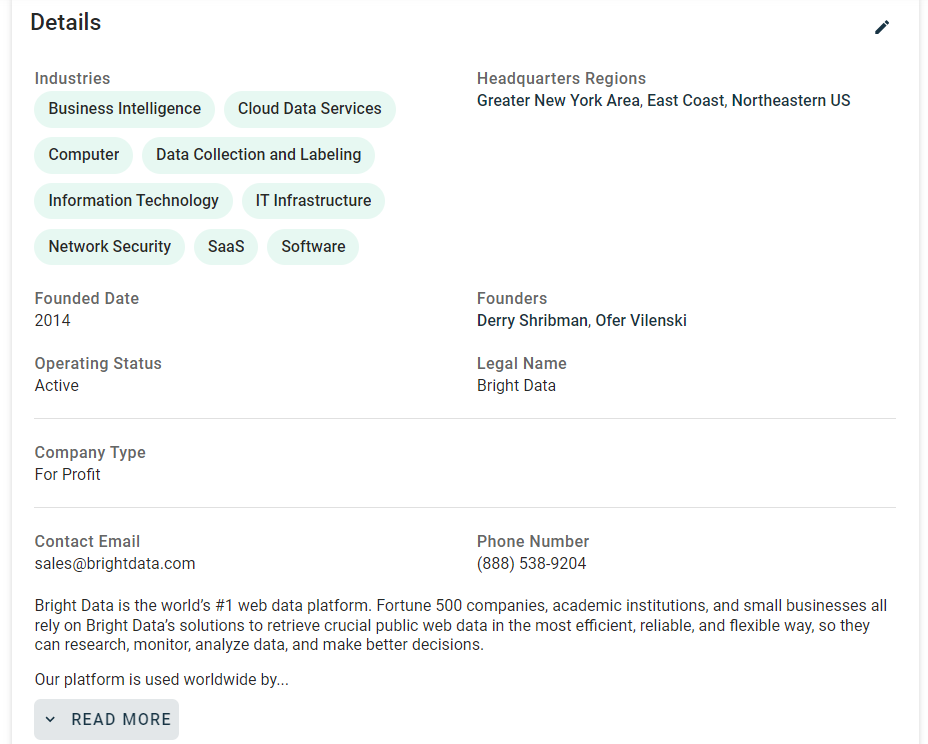
Wenn Sie diesen Abschnitt überprüfen, werden Sie feststellen, dass es keine einfache Möglichkeit gibt, die HTML-Elemente auszuwählen, aus denen Daten extrahiert werden sollen:
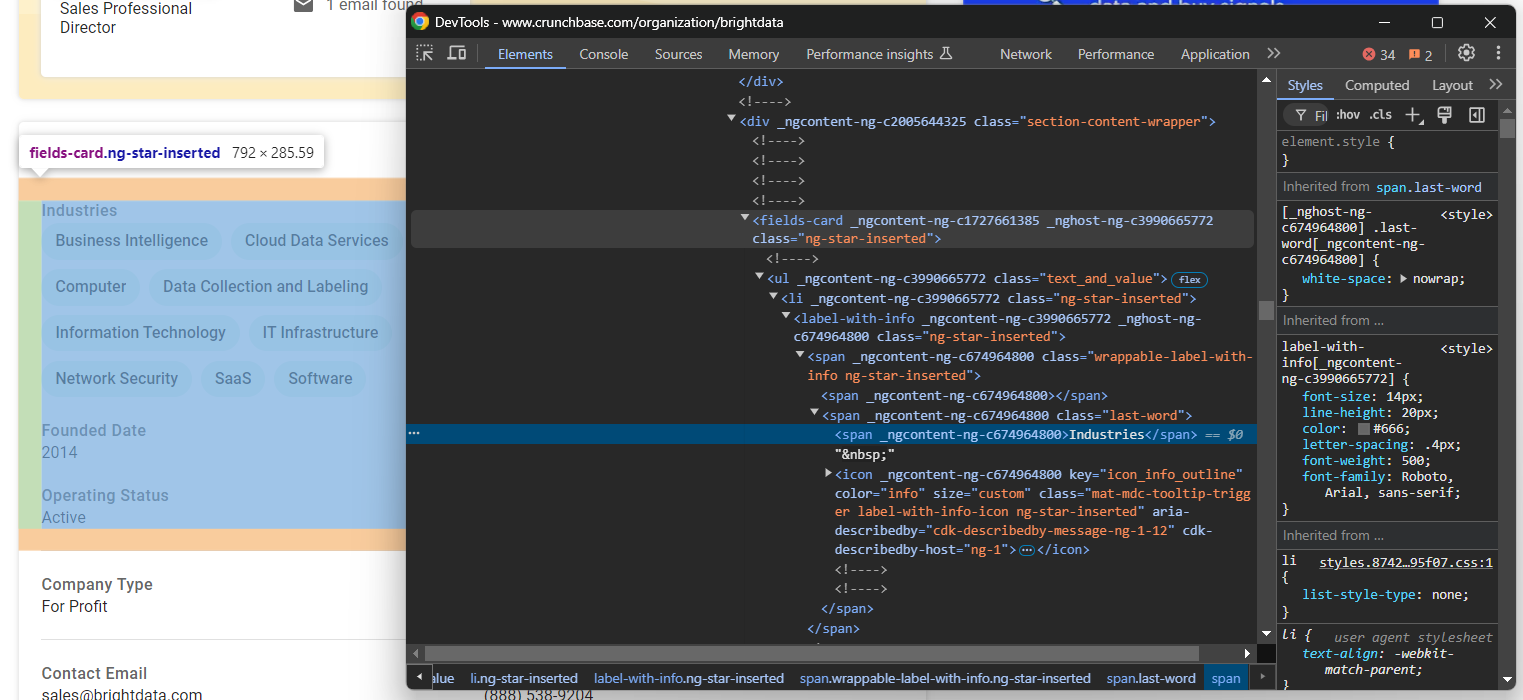
Die meisten dieser Knoten haben zufällige HTML-Attribute, die wahrscheinlich zum Zeitpunkt der Erstellung generiert wurden. Diese Attribute ändern sich nach jeder Bereitstellung, sodass Sie sich bei der Auswahl der Knoten nicht auf sie verlassen können. Darüber hinaus sind viele dieser Elemente nicht mit eindeutigen Klassen oder IDs gekennzeichnet.
Ein effektiver Ansatz für die Auswahl der gewünschten Elemente besteht darin, sich auf ihre Bezeichnungen zu konzentrieren. Sie können beispielsweise den Knoten „fields-card“ auswählen, der die Brancheninformationen enthält, indem Sie ermitteln, welche „fields-card“ einen Knoten „label-with-info“ hat, der die Zeichenfolge „Industries“ enthält.
Diese Technik wird verwendet, um Daten aus diesem Abschnitt zu extrahieren. Daher ist es sinnvoll, die Logik in einer Funktion zu zentralisieren:
def find_parent_node_based_on_child_node_text(parent_nodes_selector, child_node_selector, text):
# alle übergeordneten Knoten auswählen
parent_nodes = driver.find_elements(By.CSS_SELECTOR, parent_nodes_selector)
# alle übergeordneten Knoten durchlaufen, um denjenigen zu finden,
# dessen spezifischer untergeordneter Knoten den gewünschten Text enthält
for parent_node in parent_nodes:
try:
# den spezifischen untergeordneten Knoten innerhalb des aktuellen übergeordneten Knotens abrufen
child_node = parent_node.find_element(By.CSS_SELECTOR, child_node_selector)
# Überprüfen, ob er den gewünschten Text enthält
if text.upper() in child_node.text.upper():
return parent_node
except:
continue
return NoneVerwenden Sie die obige Funktion, um den Feldkarten-Knoten „Industries” mit folgendem Befehl auszuwählen:
industries_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Industries")Großartig! Das Scraping von Crunchbase wird jetzt viel einfacher.
Schritt 7: Unternehmensdaten scrapen
Untersuchen Sie den Knoten „Industries“:
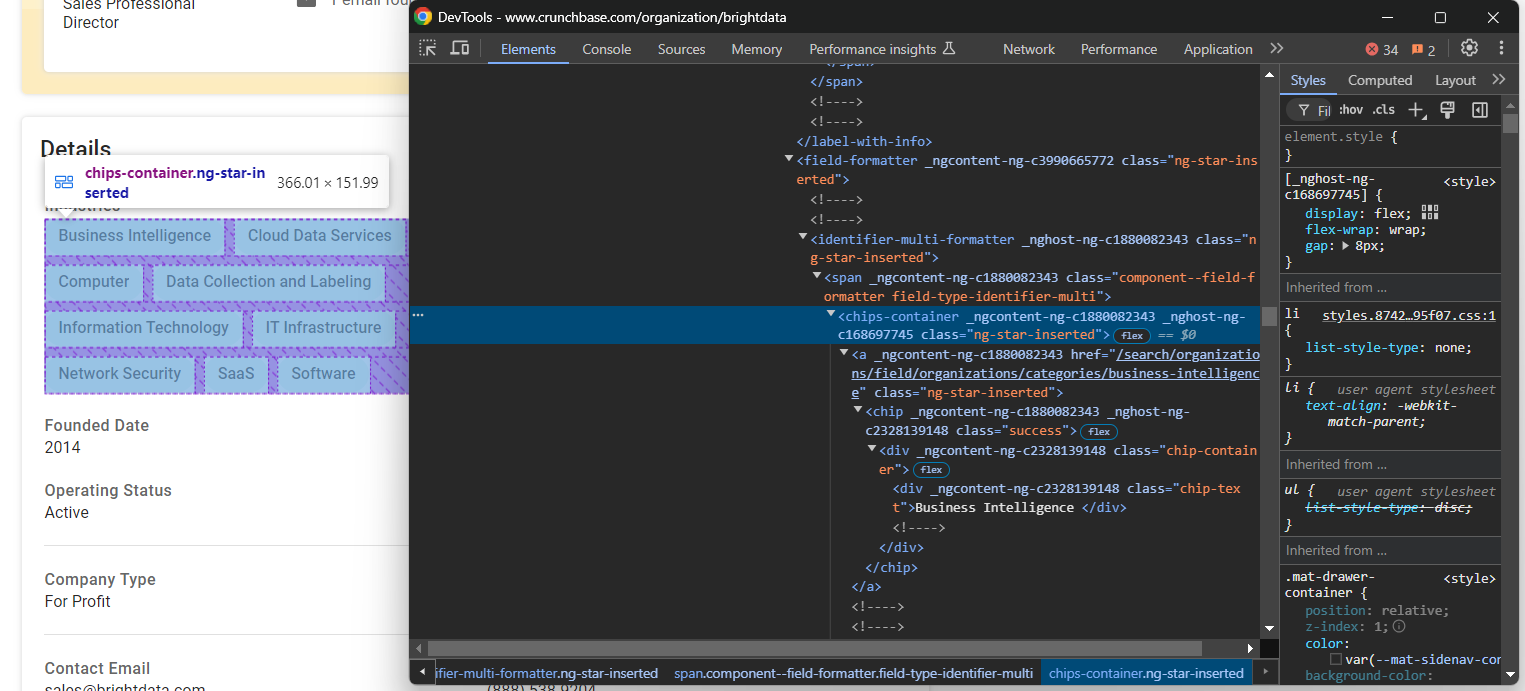
Dort sind die Branchen gespeichert, in denen das Unternehmen tätig ist, gespeichert in chips-container a nodes. Wählen Sie alle aus, durchlaufen Sie sie und extrahieren Sie Daten daraus:
industries_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Industries")
industries_nodes = industries_parent_node.find_elements(By.CSS_SELECTOR, "chips-container a")
industries = []
for industry_node in industries_nodes:
industries.append(industry_node.text)Konzentrieren Sie sich nun auf das Element „Gründungsdatum“:
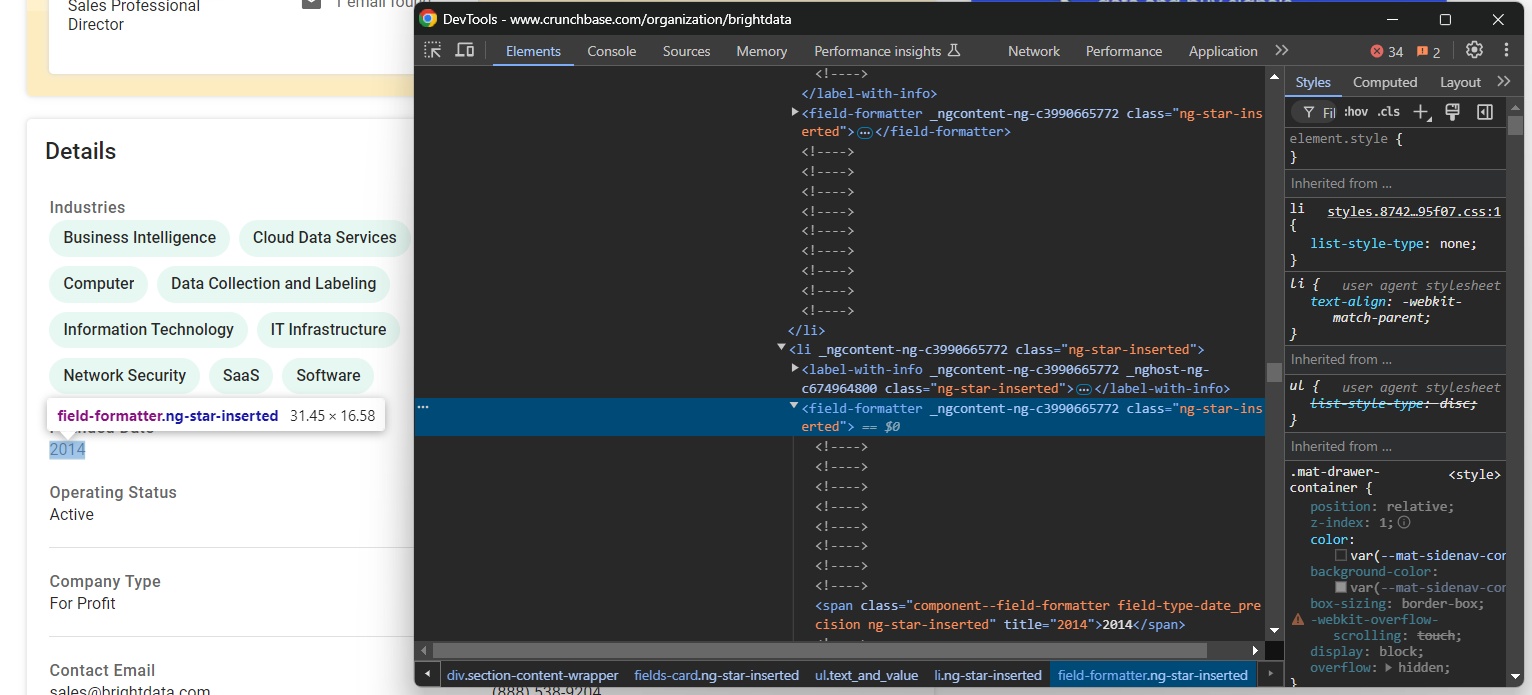
In diesem Fall ist die Scraping-Logik einfacher, da Sie nur den Text aus dem Feldformatierungselement innerhalb des übergeordneten Feldkarten-li- Knotens extrahieren müssen:
founded_date_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Founded Date")
founded_date_node = founded_date_parent_node.find_element(By.CSS_SELECTOR, "field-formatter")
founded_date = founded_date_node.textDie gleiche Logik kann auf die meisten anderen Elemente mit Unternehmensdetails angewendet werden:
company_type_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Company Type")
company_type_node = company_type_parent_node.find_element(By.CSS_SELECTOR, "field-formatter")
company_type = company_type_node.text
operating_status_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Operating Status")
operating_status_node = operating_status_parent_node.find_element(By.CSS_SELECTOR, "field-formatter")
operating_status = operating_status_node.text
headquarters_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Hauptsitzregionen")
headquarters_node = headquarters_parent_node.find_element(By.CSS_SELECTOR, "field-formatter")
headquarters = headquarters_node.text
legal_name_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Legal Name")
legal_name_node = legal_name_parent_node.find_element(By.CSS_SELECTOR, "field-formatter")
legal_name = legal_name_node.text
contact_email_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Kontakt-E-Mail")
contact_email_node = contact_email_parent_node.find_element(By.CSS_SELECTOR, "field-formatter")
contact_email = contact_email_node.text
phone_number_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Telefonnummer")
phone_number_node = phone_number_parent_node.find_element(By.CSS_SELECTOR, "field-formatter")
phone_number = phone_number_node.textEin weiterer Knoten, der besondere Aufmerksamkeit erfordert, ist das Element „Gründer“:
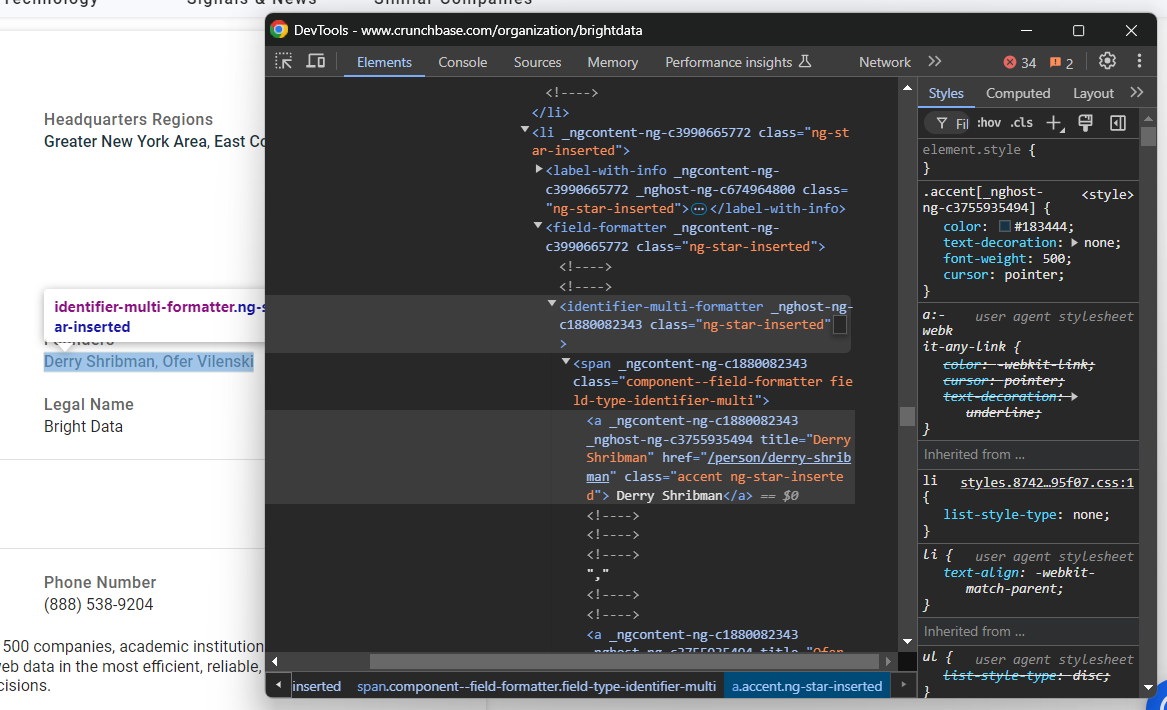
In diesem Fall müssen Sie die Knoten „identifier-multi-formatter a” durchlaufen und Daten daraus extrahieren:
founders_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Founders")
founders_nodes = founders_parent_node.find_elements(By.CSS_SELECTOR, "identifier-multi-formatter a")
founders = []
for founders_node in founders_nodes:
founders.append(founders_node.text)Schauen Sie sich zum Schluss den Beschreibungsknoten am Ende des Abschnitts „Details” an:
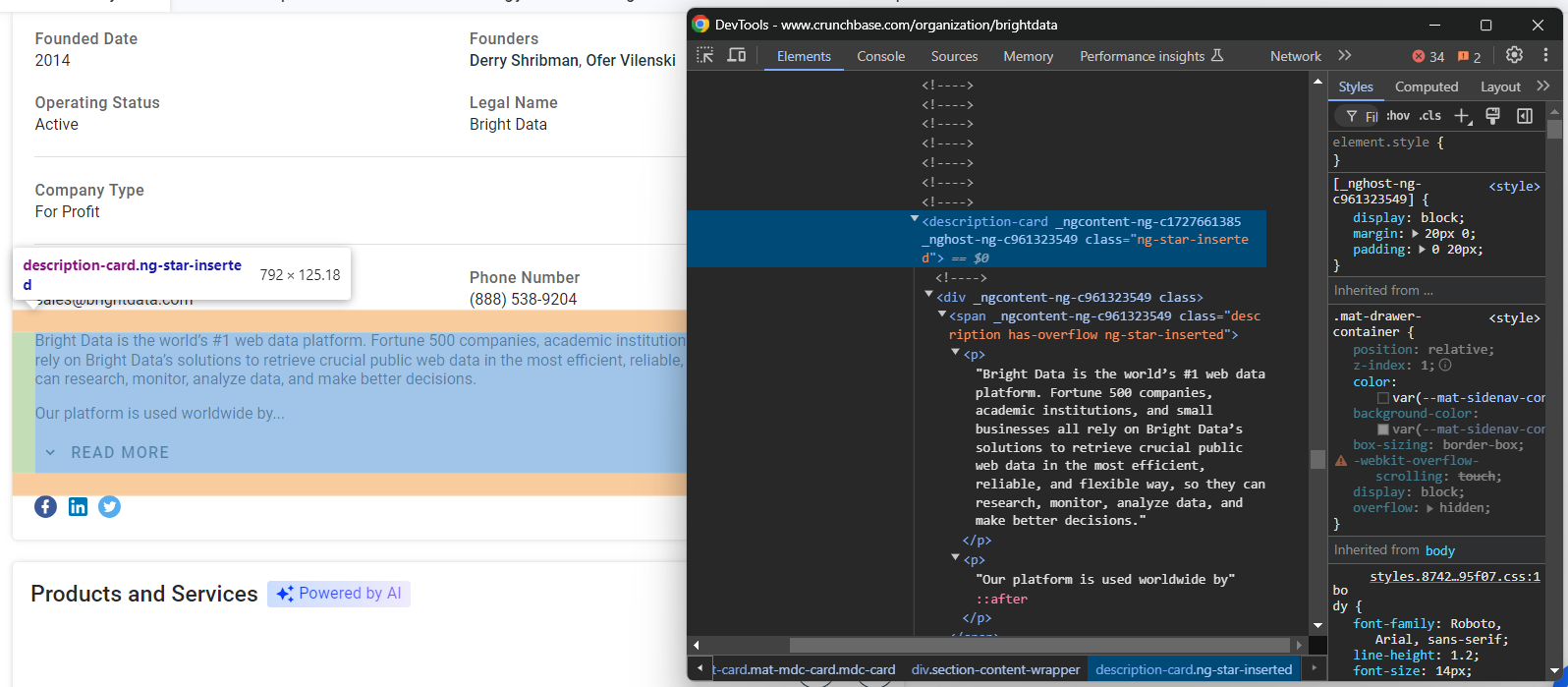
Kratzen Sie diese Daten mit:
description_node = driver.find_element(By.CSS_SELECTOR, "section-card description-card")
description = description_node.textFantastisch! Ihr Crunchbase-Scraper ist fast fertig.
Schritt 8: Scrapen Sie die Tabelle „Produkte und Dienstleistungen”
Weitere Informationen, die es sich zu sammeln lohnt, sind die Liste der vom Unternehmen angebotenen Produkte und Dienstleistungen:
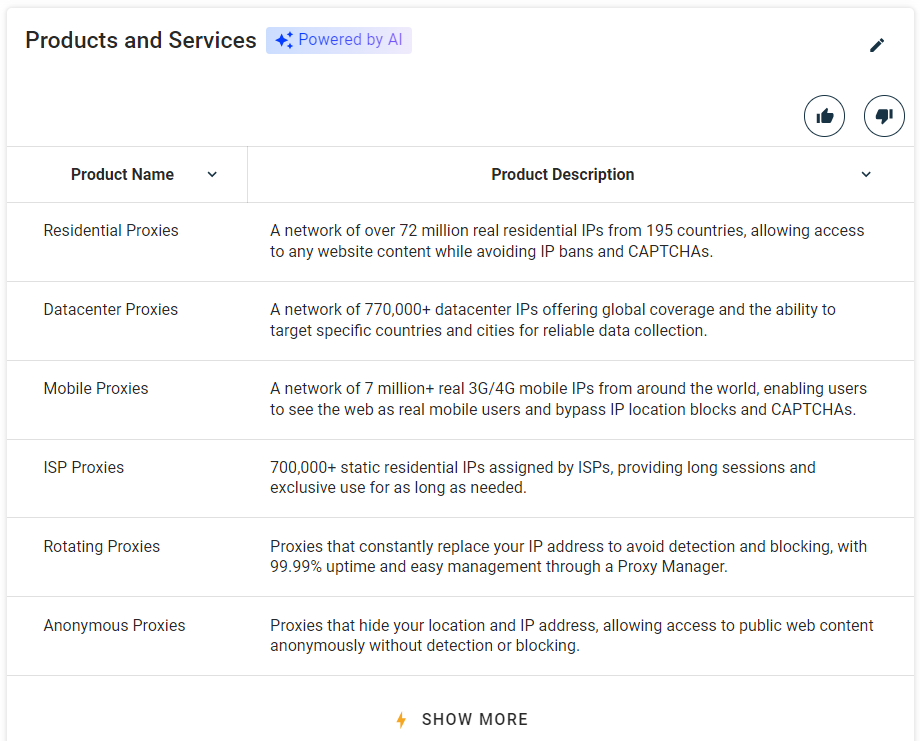
Wählen Sie den Abschnitt „Produkte und Dienstleistungen” mit der zuvor definierten Funktion aus:
products_parent_node = find_parent_node_based_on_child_node_text("profile-section", ".section-title", "Produkte und Dienstleistungen")Scrapen Sie dann die Daten aus der Tabelle mit:
products = []
for row in products_table_rows:
# extrahiere den Namen und die Beschreibung aus den Spalten jeder Zeile
name = row.find_element(By.CSS_SELECTOR, "td:nth-child(1)").text
description = row.find_element(By.CSS_SELECTOR, "td:nth-child(2)").text
product = {
"name": name,
"description": description
}
products.append(product)Beeindruckend! Die Crunchbase-Scraping-Logik ist fertiggestellt.
Schritt 9: Exportieren der gescrapten Daten
Füllen Sie ein Unternehmenswörterbuch mit den gescrapten Daten:
company = {
"about": about,
"industries": industries,
"founded_date": founded_date,
"company_type": company_type,
„operating_status”: operating_status,
„headquarters”: headquarters,
„founders”: founders,
„email”: contact_email,
„phone”: phone_number,
„description”: description,
„products”: products
}Als Nächstes exportieren Sie es in eine Datei namens company.json:
with open("company.json", "w") as json_file:
json.dump(company, json_file, indent=4)Zunächst erstellt open() eine Ausgabedatei namens company.json. Anschließend wandelt json.dump() company in seine JSON-Darstellung um und schreibt sie in die Ausgabedatei.
Denken Sie daran, json aus der Python-Standardbibliothek zu importieren:
import jsonSchritt 10: Alles zusammenfügen
Hier ist die endgültige Datei scraper.py:
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
import json
def find_parent_node_based_on_child_node_text(parent_nodes_selector, child_node_selector, text):
# alle übergeordneten Knoten auswählen
parent_nodes = driver.find_elements(By.CSS_SELECTOR, parent_nodes_selector)
# die übergeordneten Knoten durchlaufen, um denjenigen zu finden,
# dessen spezifischer untergeordneter Knoten den gewünschten Text enthält
for parent_node in parent_nodes:
try:
# den spezifischen untergeordneten Knoten innerhalb des aktuellen übergeordneten Knotens abrufen
child_node = parent_node.find_element(By.CSS_SELECTOR, child_node_selector)
# Prüfe, ob er den gewünschten Text enthält
if text.upper() in child_node.text.upper():
return parent_node
except:
continue
return None
def handle_cookie_popup(driver, seconds=60):
try:
# warte die angegebene Anzahl von Sekunden, bis die Schaltfläche „Alle akzeptieren”
# des Cookie-Popups auf der Seite erscheint
accept_button = WebDriverWait(driver, seconds).until(
EC.element_to_be_clickable((By.CSS_SELECTOR, "#onetrust-accept-btn-handler"))
)
# Klicke über JavaScript auf das Popup, um
# ElementClickInterceptedException-Fehler zu vermeiden.
driver.execute_script("arguments[0].click();", accept_button)
print("Schaltfläche 'Alle akzeptieren' angeklickt")
except:
print("Schaltfläche 'Alle akzeptieren' innerhalb von {seconds} Sekunden nicht gefunden")
# Initialisieren Sie den Treiber, um eine Chrome-Instanz
# im Header-Modus zu steuern.
driver = webdriver.Chrome()
# Navigieren Sie zur gewünschten Crunchbase-Seite.
url = "https://www.crunchbase.com/organization/brightdata"
driver.get(url)
# Behandeln Sie das Cookie-Popup, falls vorhanden.
handle_cookie_popup(driver)
# Scraping-Logik
about_node = driver.find_element(By.CSS_SELECTOR, "profile-section description-card")
about = about_node.text
industries_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Industries")
industries_nodes = industries_parent_node.find_elements(By.CSS_SELECTOR, "chips-container a")
industries = []
for industry_node in industries_nodes:
industries.append(industry_node.text)
founded_date_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Gründungsdatum")
founded_date_node = founded_date_parent_node.find_element(By.CSS_SELECTOR, "field-formatter")
founded_date = founded_date_node.text
company_type_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Unternehmenstyp")
company_type_node = company_type_parent_node.find_element(By.CSS_SELECTOR, "field-formatter")
company_type = company_type_node.text
operating_status_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Betriebsstatus")
operating_status_node = operating_status_parent_node.find_element(By.CSS_SELECTOR, "field-formatter")
operating_status = operating_status_node.text
headquarters_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Hauptsitzregionen")
headquarters_node = headquarters_parent_node.find_element(By.CSS_SELECTOR, "field-formatter")
headquarters = headquarters_node.text
founders_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Gründer")
founders_nodes = founders_parent_node.find_elements(By.CSS_SELECTOR, "identifier-multi-formatter a")
founders = []
for founders_node in founders_nodes:
founders.append(founders_node.text)
legal_name_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Legal Name")
legal_name_node = legal_name_parent_node.find_element(By.CSS_SELECTOR, "field-formatter")
legal_name = legal_name_node.text
contact_email_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Contact Email")
contact_email_node = contact_email_parent_node.find_element(By.CSS_SELECTOR, "field-formatter")
contact_email = contact_email_node.text
phone_number_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Telefonnummer")
phone_number_node = phone_number_parent_node.find_element(By.CSS_SELECTOR, "field-formatter")
phone_number = phone_number_node.text
description_node = driver.find_element(By.CSS_SELECTOR, "section-card description-card")
description = description_node.text
products_parent_node = find_parent_node_based_on_child_node_text("profile-section", ".section-title", "Produkte und Dienstleistungen")
products_table_rows = products_parent_node.find_elements(By.CSS_SELECTOR, "table tbody tr")
# Produkt-Tabelle scrapen
products = []
for row in products_table_rows:
# extrahiere den Namen und die Beschreibung aus den Spalten jeder Zeile
name = row.find_element(By.CSS_SELECTOR, "td:nth-child(1)").text
description = row.find_element(By.CSS_SELECTOR, "td:nth-child(2)").text
product = {
"name": name,
"description": description
}
products.append(product)
# Füllen Sie ein Wörterbuch mit den extrahierten Daten.
company = {
"about": about,
"industries": industries,
"founded_date": founded_date,
"company_type": company_type,
"operating_status": operating_status,
"headquarters": headquarters,
"founders": founders,
"email": contact_email,
"phone": phone_number,
"description": description,
"products": products
}
# exportiere die gescrapten Daten in eine JSON-Datei
with open("company.json", "w") as json_file:
json.dump(company, json_file, indent=4)
# schließe den Treiber und gib die Browser-Ressourcen frei
driver.quit()Mit etwas mehr als 100 Zeilen Code haben Sie gerade einen Crunchbase-Scraper in Python erstellt!
Starten Sie das Skript mit dem folgenden Befehl:
python3 script.pyOder unter Windows:
python script.pyEine Datei namens company.json wird im Ordner Ihres Projekts angezeigt. Öffnen Sie sie, um folgenden Inhalt anzuzeigen:
{
"about": "Die weltweit führende Webdatenplattform",
"industries": [
"Business Intelligence",
"Cloud-Datendienste",
"Computer",
"Datenerfassung und -kennzeichnung",
"Informationstechnologie",
„IT-Infrastruktur“,
„Netzwerksicherheit“,
„SaaS“,
„Software“
],
„founded_date“: „2014“,
„Unternehmenstyp“: „Gewinnorientiert“,
„Betriebsstatus“: „Aktiv“,
„Hauptsitz“: „Großraum New York, Ostküste, Nordosten der USA“,
„Gründer“: [
„Derry Shribman“,
„Ofer Vilenski“
],
„email”: „[email protected]”,
„phone”: „(888) 538-9204”,
„description”: „Proxys, die Ihren Standort und Ihre IP-Adresse verbergen und Ihnen den anonymen Zugriff auf öffentliche Webinhalte ermöglichen, ohne dass Sie entdeckt oder blockiert werden.”,
„products“: [
{
„name“: „Residential-Proxys“,
„description“: „Ein Netzwerk aus 400M+ monthly echten Residential-IPs aus 195 Ländern, das den Zugriff auf beliebige Website-Inhalte ermöglicht und gleichzeitig IP-Sperren und CAPTCHAs umgeht.“
},
{
"name": "Datacenter-Proxys",
"description": "Ein Netzwerk aus über 770.000 IP-Adressen von Rechenzentren, das globale Abdeckung und die Möglichkeit bietet, bestimmte Länder und Städte für eine zuverlässige Datenerfassung anzusprechen."
},
{
"name": "Mobile-Proxies",
"description": "Ein Netzwerk von über 7 Millionen echten 3G/4G-Mobil-IPs aus aller Welt, das es Benutzern ermöglicht, das Internet wie echte Mobilfunknutzer zu sehen und IP-Standortblockierungen und CAPTCHAs zu umgehen."
},
{
"name": "ISP-Proxys",
"description": "Über 700.000 statische Residential-IPs, die von ISPs zugewiesen werden und lange Sitzungen sowie exklusive Nutzung für einen beliebig langen Zeitraum ermöglichen."
},
{
"name": "Rotierende Proxys",
"description": "Proxys, die Ihre IP-Adresse ständig ersetzen, um eine Erkennung und Blockierung zu vermeiden, mit einer Verfügbarkeit von 99,99 % und einfacher Verwaltung über einen Proxy-Manager."
},
{
"name": "Anonyme Proxys",
"description": "Proxys, die Ihren Standort und Ihre IP-Adresse verbergen und Ihnen den anonymen Zugriff auf öffentliche Webinhalte ermöglichen, ohne dass Sie entdeckt oder blockiert werden."
}
]
}Das sind die Daten, die auf der Crunchbase-Unternehmensseite für Bright Data verfügbar sind.
Et voilà! Sie haben gerade gelernt, wie Sie mit Python Web-Scraping auf Crunchbase durchführen können.
Crunchbase-Daten mühelos freischalten
Crunchbase bietet eine Fülle wertvoller Daten, ergreift jedoch auch umfangreiche Maßnahmen, um diese vor Scrapers und automatisierten Bots zu schützen. Bei der Interaktion mit der Website über einen Headless Browser oder bei bestimmten Aktionen können 403 Forbidden-Seiten oder CAPTCHAs auftreten.
Als ersten Schritt können Sie unseren Leitfaden zum Umgehen von CAPTCHAs in Python zu Rate ziehen. Crunchbase setzt jedoch zusätzliche fortschrittliche Anti-Scraping-Lösungen ein, die dennoch zu Blockierungen führen können.
Ohne die richtigen Tools kann das Scraping von Crunchbase schnell zu einer langsamen und frustrierenden Erfahrung werden. Die beste Lösung ist die spezielle Crunchbase Scraper API von Bright Data. Rufen Sie Daten von Crunchbase ab, ohne blockiert zu werden!
Fazit
In dieser Schritt-für-Schritt-Anleitung haben Sie gelernt, was ein Crunchbase-Scraper ist und welche Arten von Daten er abrufen kann. Sie haben auch gesehen, wie Sie ein Python-Skript erstellen können, um Crunchbase nach Unternehmensübersichtsdaten zu durchsuchen, wofür nur etwa 150 Zeilen Code erforderlich waren.
Das Problem ist, dass Crunchbase strenge Maßnahmen gegen Bots und automatisierte Skripte ergreift. CAPTCHAs, Browser-Fingerprinting und IP-Sperren sind nur einige der Abwehrmaßnahmen, die zum Schutz vor Scraping eingesetzt werden. Mit unserer Crunchbase Scraper API können Sie all diese Herausforderungen vergessen.
Wenn Web-Scraping nichts für Sie ist, Sie aber dennoch an Crunchbase-Daten interessiert sind, entdecken Sie unsere Crunchbase-Datensätze!
Sprechen Sie mit einem unserer Experten, um herauszufinden, welche Lösung von Bright Data Ihren Anforderungen am besten entspricht.





