

In diesem Leitfaden erfahren Sie:
- Was ein Alibaba-Scraper ist und wie er funktioniert
- Welche Arten von Daten Sie automatisch von Alibaba abrufen können
- Wie Sie mit Python ein Alibaba-Scraping-Skript erstellen
Lassen Sie uns loslegen!
Was ist ein Alibaba-Scraper?
Ein Alibaba-Scraper ist einWeb-Scraping-Bot, der automatisch Daten aus den Seiten von Alibaba extrahiert. Er simuliert das Surfverhalten eines Benutzers, um durch die Seiten von Alibaba zu navigieren. Er verarbeitet Interaktionen wie Paginierung und ruft strukturierte Informationen wie Produktdetails, Preise und Unternehmensdaten ab.
Daten, die Sie von Alibaba scrapen können
Alibaba ist eine Fundgrube für wertvolle Informationen, wie zum Beispiel:
- Produktdetails: Namen, Beschreibungen, Bilder, Preisklassen, Verkäuferinformationen und mehr.
- Unternehmensinformationen: Firmennamen, Herstellerangaben, Kontaktinformationen und Bewertungen.
- Kundenfeedback: Bewertungen, Produktrezensionen und mehr.
- Logistik und Verfügbarkeit: Lagerbestand, Mindestbestellmengen, Versandoptionen und mehr.
- Kategorien und Tags: Produktkategorien, relevante Tags oder Labels.
Erfahren Sie, wie Sie diese Daten extrahieren können!
Alibaba in Python scrapen: Schritt-für-Schritt-Anleitung
In diesem Abschnitt lernen Sie in einem geführten Tutorial, wie Sie einen Alibaba-Scraper erstellen.
Das Ziel ist es, Sie durch die Erstellung eines Python-Skripts zu führen, das automatisch Daten aus der Alibaba-Seite „Laptop” extrahiert:
Sind Sie bereit? Befolgen Sie die folgenden Schritte!
Schritt 1: Projekt einrichten
Vergewissern Sie sich zunächst, dass Python 3 auf Ihrem Rechner installiert ist. Ist dies nicht der Fall, laden Sie es herunter und folgen Sie den Anweisungen des Installationsassistenten.
Erstellen Sie nun mit dem folgenden Befehl ein Verzeichnis für Ihr Projekt:
mkdir alibaba-scraper
Der Ordner „alibaba-scraper” ist der Speicherort für den Python-Alibaba-Scraper.
Geben Sie ihn in das Terminal ein und erstellen Sie darin eine virtuelle Umgebung:
cd alibaba-Scraper
python -m venv env
Laden Sie den Projektordner in Ihre bevorzugte Python-IDE, z. B. Visual Studio Code mit der Python-Erweiterung oder PyCharm Community Edition.
Erstellen Sie eine Datei scraper.py im Projektverzeichnis, das nun folgende Dateistruktur aufweisen sollte:

scraper.py ist derzeit ein leeres Python-Skript, wird aber bald die gewünschte Scraping-Logik enthalten.
Aktivieren Sie die virtuelle Umgebung im Terminal der IDE. Führen Sie unter Linux oder macOS diesen Befehl aus:
./env/bin/activate
Unter Windows führen Sie stattdessen folgenden Befehl aus:
env/Scripts/activate
Großartig, Ihre Python-Umgebung für das Web-Scraping von Alibaba ist bereit!
Schritt 2: Wählen Sie die Scraping-Bibliothek aus
Das Ziel ist nun, festzustellen, ob Alibaba dynamische oder statische Seiten verwendet. Öffnen Sie dazu die Alibaba-Zielseite in Ihrem Browser im Inkognito-Modus. Klicken Sie dann mit der rechten Maustaste auf den Hintergrund, wählen Sie „Untersuchen“, gehen Sie zur Registerkarte „Netzwerk“, filtern Sie nach „Fetch/XHR“ und laden Sie die Seite neu:
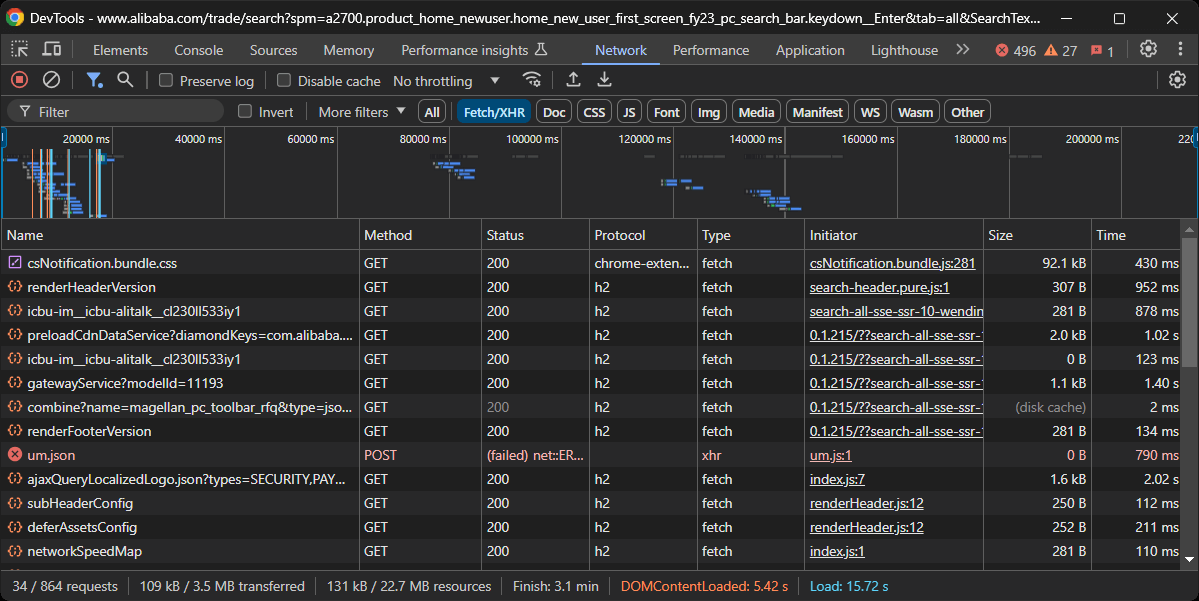
Beobachten Sie in diesem Abschnitt der DevTools, ob die Seite signifikante dynamische Anfragen stellt. In diesem Fall ist dies der Fall, was darauf hindeutet, dass die Seite dynamisch ist. Eine weitere Analyse zeigt, dass die Seite JavaScript für das Rendering verwendet.
Mit anderen Worten: Sie benötigen ein Browser-Automatisierungstool wie Selenium, um Alibaba effektiv zu scrapen. Weitere Informationen finden Sie in unserem Tutorial zum Selenium-Web-Scraping.
Mit Selenium können Sie einen Webbrowser programmgesteuert steuern, Benutzerinteraktionen simulieren und von JavaScript gerenderte Inhalte scrapen. Installieren Sie es und legen Sie los!
Schritt 3: Selenium installieren und konfigurieren
Installieren Sie Selenium in einer aktivierten virtuellen Umgebung mit diesem Befehl:
pip install -U selenium
Importieren Sie Selenium in scraper.py und erstellen Sie ein WebDriver -Objekt:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# Initialisieren einer Chrome-Webtreiberinstanz
driver = webdriver.Chrome(service=Service())
Der obige Code initialisiert eine WebDriver-Instanz zur Steuerung einer Chrome-Instanz. Beachten Sie, dass Alibaba einige Anti-Scraping-Maßnahmen eingerichtet hat, die Headless-Browser blockieren können.
Daher sollten Sie das Flag --headless nicht setzen. Als alternative Lösung sollten Sie Playwright Stealth in Betracht ziehen.
Denken Sie daran, den Webtreiber als letzte Zeile Ihres Scrapers zu schließen:
driver.quit()
Großartig! Sie sind nun vollständig konfiguriert, um mit dem Scraping von Alibaba zu beginnen.
Schritt 4: Verbindung zur Zielseite herstellen
Verwenden Sie die vom Selenium WebDriver -Objekt bereitgestellte get() -Methode, um die gewünschte Seite aufzurufen:
url = "https://www.alibaba.com/trade/search?spm=a2700.product_home_newuser.home_new_user_first_screen_fy23_pc_search_bar.keydown__Enter&tab=all&SearchText=laptop"
driver.get(url)
Die Datei scraper.py enthält nun folgende Codezeilen:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# Initialisieren einer Chrome-Webtreiberinstanz
driver = webdriver.Chrome(service=Service())
# die URL der Zielseite
url = "https://www.alibaba.com/trade/search?spm=a2700.product_home_newuser.home_new_user_first_screen_fy23_pc_search_bar.keydown__Enter&tab=all&SearchText=laptop"
# Verbindung zur Zielseite herstellen
driver.get(url)
# Scraping-Logik...
# Browser schließen
driver.quit()
Setzen Sie einen Debugging-Haltepunkt in die letzte Zeile und starten Sie das Skript mit dem Debugger. Folgendes sollte nun angezeigt werden:
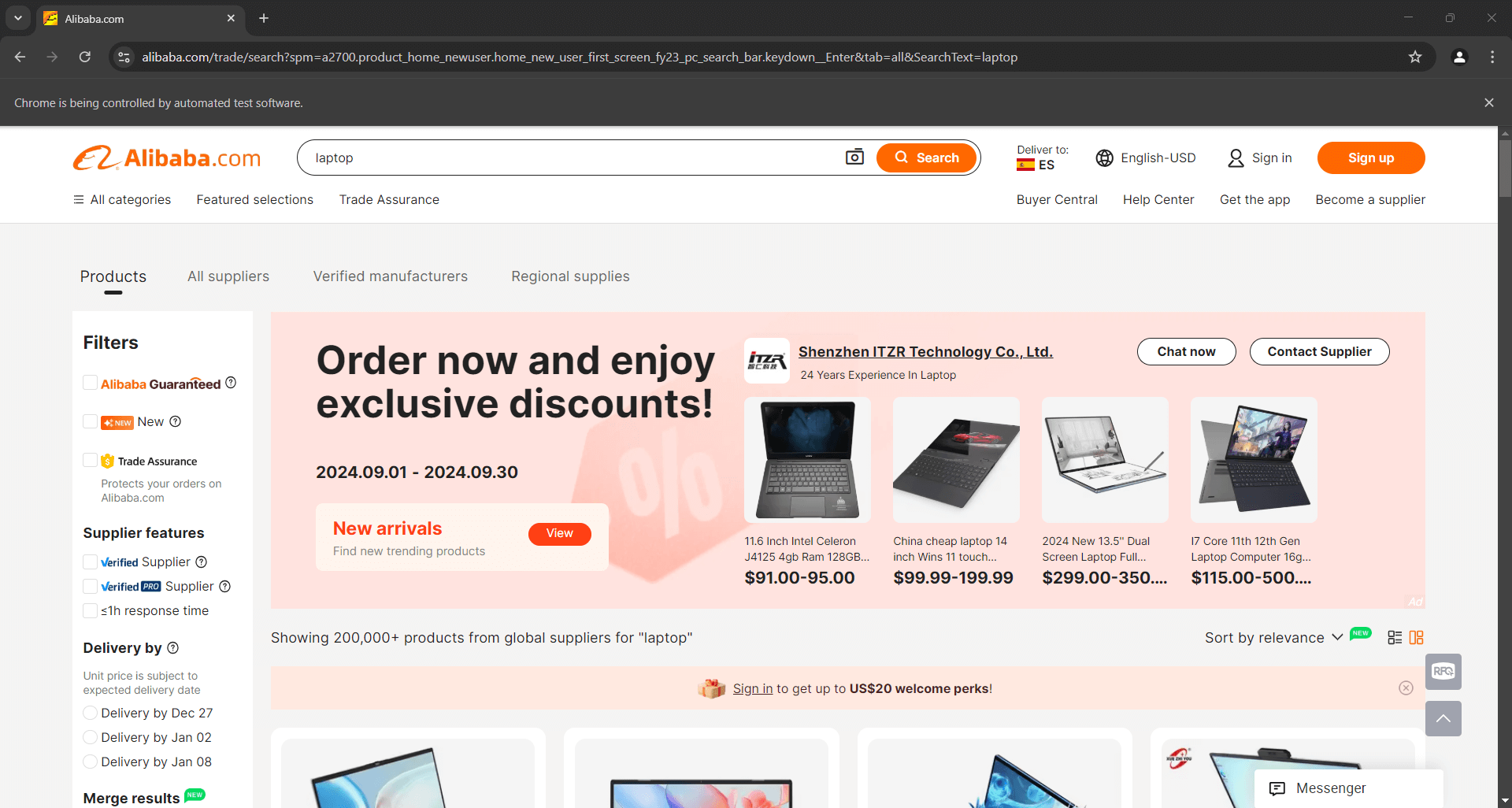
Die Meldung „Chrome wird von einer automatisierten Testsoftware gesteuert“ bestätigt, dass Selenium Chrome wie erwartet steuert. Gut gemacht!
Schritt 5: Wählen Sie die Produktelemente aus
Da die Alibaba-Produktseite mehrere Produkte enthält, müssen Sie zunächst eine Datenstruktur initialisieren, um die gescraped Daten zu speichern. Ein Array eignet sich perfekt für diesen Zweck:
products = []
Untersuchen Sie als Nächstes die HTML-Elemente der Produkte auf der Seite, um zu verstehen:
- Wie Sie sie auswählen können
- Welche Daten sie enthalten
- Wie man diese Daten extrahiert
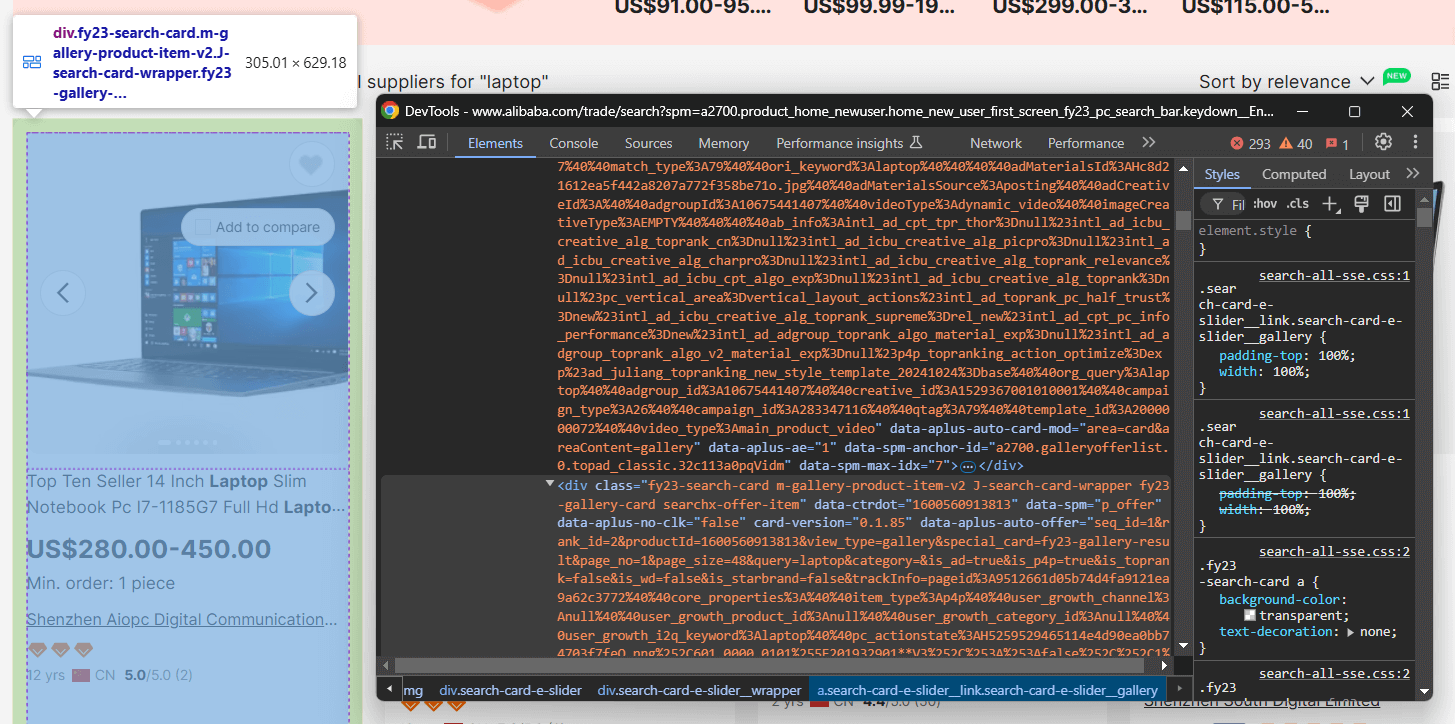
Hier sehen Sie, dass jedes Produktelement ein .m-gallery-product-item-v2 -Knoten ist.
Verwenden Sie Selenium, um alle Produktelemente auszuwählen:
product_elements = driver.find_elements(By.CSS_SELECTOR, ".m-gallery-product-item-v2")
find_elements() wendet die angegebene Selektorstrategie an, um Elemente auf der Seite abzurufen. Im obigen Fall handelt es sich bei der Selektorstrategie um einen CSS-Selektor.
Vergessen Sie nicht, By zu importieren:
from selenium.webdriver.common.by import By
Durchlaufen Sie die ausgewählten Elemente und bereiten Sie sich darauf vor, Daten aus jedem einzelnen Element zu extrahieren:
for product_element in product_elements:
# Daten aus jedem Produktelement extrahieren
Großartig! Sie sind dem erfolgreichen Scraping von Alibaba einen Schritt näher gekommen.
Schritt 6: Extrahieren Sie die Produktelemente
Untersuchen Sie ein Produktelement, um seine HTML-Struktur zu verstehen:
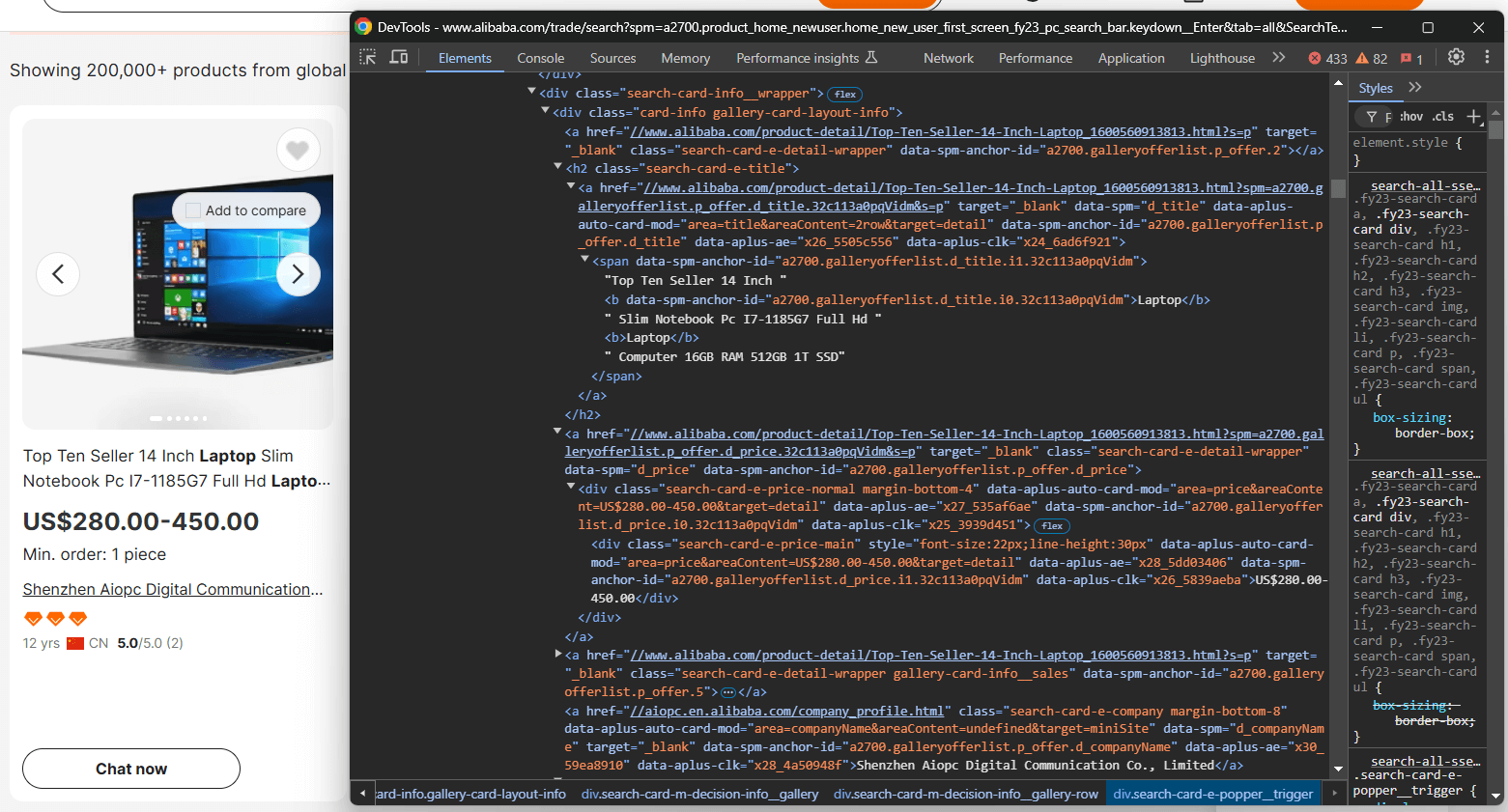
Hier sehen Sie, dass Sie Folgendes extrahieren können:
- Das Produktbild aus
.search-card-e-slider__img - Die Produktbeschreibung aus
.search-card-e-title - Die Produktpreisspanne aus
.search-card-e-price-main - Das Unternehmen/den Hersteller aus
.search-card-e-company
Übersetzen Sie diese Informationen in der for -Schleife in eine Scraping-Logik:
img_element = product_element.find_element(By.CSS_SELECTOR,".search-card-e-slider__img")
img = img_element.get_attribute("src")
description_element = product_element.find_element(By.CSS_SELECTOR,".search-card-e-title")
description = description_element.text.strip()
price_element = product_element.find_element(By.CSS_SELECTOR,".search-card-e-price-main")
price = price_element.text.strip()
company_element = product_element.find_element(By.CSS_SELECTOR,".search-card-e-company")
company = company_element.text.strip()
find_element() ruft das einzige Element ab, das dem angegebenen CSS-Selektor entspricht. Anschließend können Sie mit dem Textattribut auf dessen Textinhalt zugreifen. Um den Wert des HTML-Attributs eines Knotens zu erhalten, verwenden Sie die Methode get_attribute().
Verwenden Sie die gescrapten Daten, um ein Produktwörterbuch zu füllen und es zum Array „products” hinzuzufügen:
product = {
"img": img,
"description": description,
"price": price,
"company": company
}
products.append(product)
Fantastisch! Die Logik zur Datenextraktion aus Alibaba ist fertig.
Schritt 7: Exportieren Sie die gescrapten Daten in eine CSV-Datei
Derzeit sind Ihre gescraped Daten im Array „products” gespeichert. Um sie zugänglich zu machen und mit anderen teilen zu können, müssen Sie sie in ein für Menschen lesbares Format wie eine CSV-Datei exportieren.
Verwenden Sie den folgenden Code, um eine CSV-Datei mit den gescrapten Daten zu erstellen und zu füllen:
csv_file_name = "products.csv"
with open(csv_file_name, mode="w", newline="", encoding="utf-8") as csv_file:
writer = csv.DictWriter(csv_file, fieldnames=["image", "description", "price", "company"])
# Header-Zeile schreiben
writer.writeheader()
# Produktdatenzeilen schreiben
for product in products:
writer.writerow(product)
Vergessen Sie nicht, csv aus der Python-Standardbibliothek zu importieren:
import csv
Wow! Ihr Aliaba-Scraper ist fertig.
Schritt 8: Alles zusammenfügen
Nachfolgend finden Sie den endgültigen Code Ihres Alibaba-Scraping-Skripts:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
import csv
# Initialisieren Sie eine Chrome-Webtreiberinstanz.
driver = webdriver.Chrome(service=Service())
# die URL der Zielseite
url = "https://www.alibaba.com/trade/search?spm=a2700.product_home_newuser.home_new_user_first_screen_fy23_pc_search_bar.keydown__Enter&tab=all&SearchText=laptop"
# Verbindung zur Zielseite herstellen
driver.get(url)
# Speicherort für die gesammelten Daten
products = []
# Alle Produktelemente auf der Seite auswählen
product_elements = driver.find_elements(By.CSS_SELECTOR, ".m-gallery-product-item-v2")
# Produktknoten durchlaufen und Daten daraus sammeln
for product_element in product_elements:
# Produktdetails extrahieren
img_element = product_element.find_element(By.CSS_SELECTOR,".search-card-e-slider__img")
img = img_element.get_attribute("src")
description_element = product_element.find_element(By.CSS_SELECTOR,".search-card-e-title")
description = description_element.text.strip()
price_element = product_element.find_element(By.CSS_SELECTOR,".search-card-e-price-main")
price = price_element.text.strip()
company_element = product_element.find_element(By.CSS_SELECTOR,".search-card-e-company")
company = company_element.text.strip()
# Erstellen Sie ein Produktwörterbuch mit den
# gescrapten Daten.
product = {
"img": img,
"description": description,
"price": price,
"company": company
}
# Füge die Produktdaten zum Array hinzu
products.append(product)
# Definiere den Namen der CSV-Ausgabedatei
csv_file_name = "products.csv"
# Öffne die Datei im Schreibmodus und erstelle einen CSV-Writer
with open(csv_file_name, mode="w", newline="", encoding="utf-8") as csv_file:
writer = csv.DictWriter(csv_file, fieldnames=["img", "description", "price", "company"])
# Header-Zeile schreiben
writer.writeheader()
# Produktdatenzeilen schreiben
for product in products:
writer.writerow(product)
# Browser schließen
driver.quit()
Mit nur etwas mehr als 60 Zeilen Code haben Sie gerade einen Alibaba-Scraper in Python erstellt!
Starten Sie den Scraper mit dem folgenden Befehl:
python3 script.py
Oder unter Windows:
python script.py
Eine Datei namens products.csv wird im Ordner Ihres Projekts angezeigt. Öffnen Sie sie und Sie sehen:
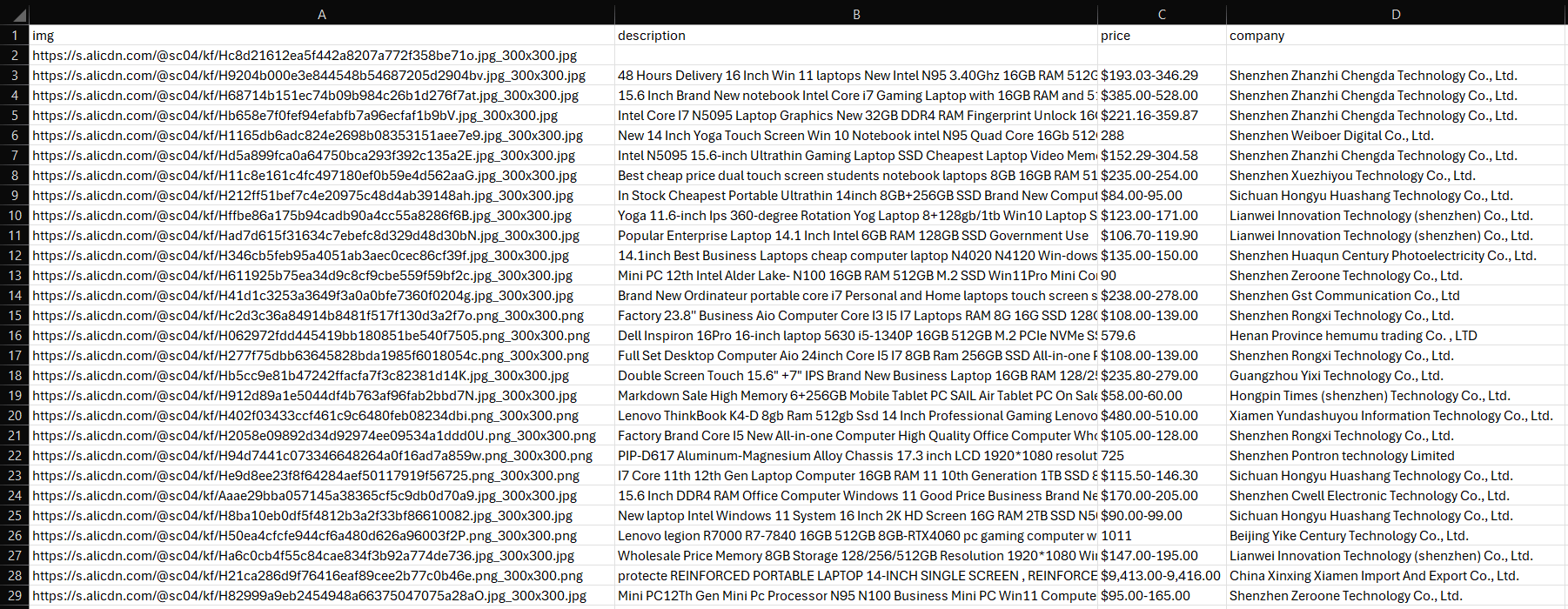
Et voilà! Mission erfüllt. Die nächsten Schritte? Paginierung bearbeiten, Skript bereitstellen, Ausführung automatisieren und für optimale Leistung weiter optimieren!
Fazit
In dieser Schritt-für-Schritt-Anleitung haben Sie gelernt, was ein Alibaba-Scraper ist und welche Arten von Daten er abrufen kann. Außerdem haben Sie gesehen, wie Sie mit weniger als 100 Zeilen Code ein Python-Skript erstellen können, um Alibaba-Produkte zu scrapen.
Das Problem ist, dass das Scraping von Alibaba mit Herausforderungen verbunden ist. Die Plattform setzt strenge Anti-Bot-Maßnahmen ein und verwendet Interaktionen wie Paginierung, die den Scraping-Prozess komplexer machen. Die Erstellung einer skalierbaren und effektiven Alibaba-Scraping-Lösung kann sehr anspruchsvoll sein.
Mit unserer Alibaba Scraper API können Sie diese Herausforderungen vergessen! Mit dieser speziellen Lösung können Sie Daten von der Zielwebsite durch einfache API-Aufrufe abrufen – ohne das Risiko, blockiert zu werden.
Wenn Web-Scraping nicht Ihr bevorzugter Ansatz ist, Sie aber dennoch an Produktdaten interessiert sind, entdecken Sie unsere gebrauchsfertigen Alibaba-Datensätze!
Erstellen Sie noch heute ein kostenloses Bright Data-Konto, um unsere Scraper-APIs auszuprobieren oder unsere Datensätze zu erkunden.






