
In diesem Artikel erfahren Sie:
- Was Akamai ist und wie sein Anti-Bot-System funktioniert.
- Wie Sie überprüfen, ob eine Website Akamai verwendet.
- Übergeordnete Ansätze zur Umgehung der Akamai-Bot-Erkennung.
- Wie Sie Open-Source-Tools zum Bestehen von Akamai-Challenges verwenden.
- Wie Sie die Akamai-Umgehung mit Bright Data zuverlässiger handhaben, sowohl bei statischen Anfragen als auch in Browser-Automatisierungsszenarien.
Legen wir los!
So funktioniert Akamais Anti-Bot-Mechanismus
Akamai fungiert sowohl als CDN als auch als Bot-Management-Schicht, die zwischen Benutzern und Ursprungsservern positioniert ist. Jede Anfrage durchläuft das Edge-Netzwerk, wo sie geprüft und entweder zugelassen, herausgefordert oder blockiert wird.
Aus Anti-Bot-Perspektive setzt Akamai auf ein mehrschichtiges Erkennungssystem:
- Schicht #1 – Netzwerk- und Anfragenanalyse: Bewertet IP-Reputation und Muster auf Protokollebene (wie TLS-Fingerprinting).
- Schicht #2 – Fingerprinting und clientseitige Analyse: Akamai injiziert JavaScript-Challenges, die im Browser ausgeführt werden, um Signale wie Geräteeigenschaften, Browser-Konfiguration und das Verhalten der Ausführungsumgebung zu erfassen. Diese Fingerabdrücke helfen dabei, echte Browser von Headless- oder automatisierten Browsern zu unterscheiden, selbst wenn HTTP-Anfragen gültig erscheinen.
- Schicht #3: Verhaltensanalyse: Umfasst Mausbewegungen, Tastenanschlagmuster, Navigationsfluss und Timing zwischen Aktionen. Hier versuchen fortgeschrittenere Bots, Menschen nachzuahmen, um der Erkennung zu entgehen und in einen ‘Graubereich’ der Ungewissheit zu fallen.
Basierend auf diesen Signalen weist Akamai einen Risiko-Score (Bot Score) zu und klassifiziert Traffic in Kategorien wie legitime Nutzer, bekannte Bots und verdächtigen Traffic. Die Reaktionen variieren entsprechend: Traffic kann zugelassen, ratenbegrenzt, mit Mechanismen wie CAPTCHAs herausgefordert oder vollständig blockiert werden.
So prüfen Sie, ob eine Website durch Akamai geschützt ist
Um festzustellen, ob eine Website auf Akamai setzt, sollten Sie nach einer Kombination aus Netzwerk- und Browser-Indikatoren suchen.
Betrachten Sie zum Beispiel eine Zalando-Produktseite, die bekanntermaßen hinter Akamais CDN- und Anti-Bot-Schicht liegt. Öffnen Sie die Browser-DevTools, navigieren Sie zum Tab ‘Netzwerk’ und laden Sie die Seite neu. Prüfen Sie die vom Browser gesendete Anfrage mit Fokus auf die Antwort-Header: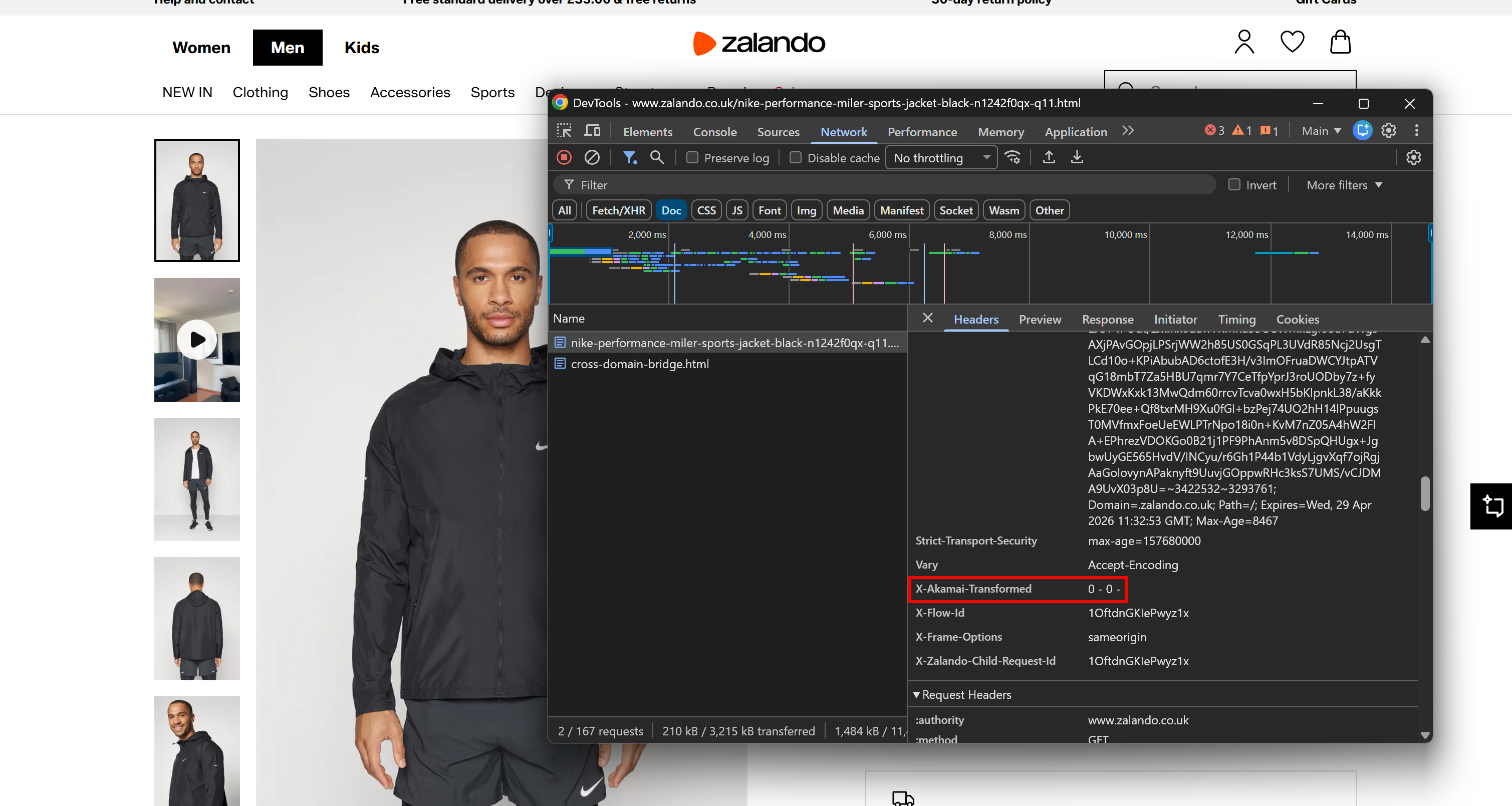
Sie werden möglicherweise einen X-Akamai-Transformed-Header bemerken. Das Vorhandensein von X-Akamai-*-Headern zeigt an, dass der Traffic über Akamais CDN-Schicht verarbeitet wird.
Ein weiteres starkes Signal liefern die vom Server gesetzten Cookies. Diese finden Sie im Bereich ‘Cookies’ unter dem Tab ‘Anwendung’. Auf Akamai-gesicherten Seiten werden Sie _abck und ak_bmsc bemerken.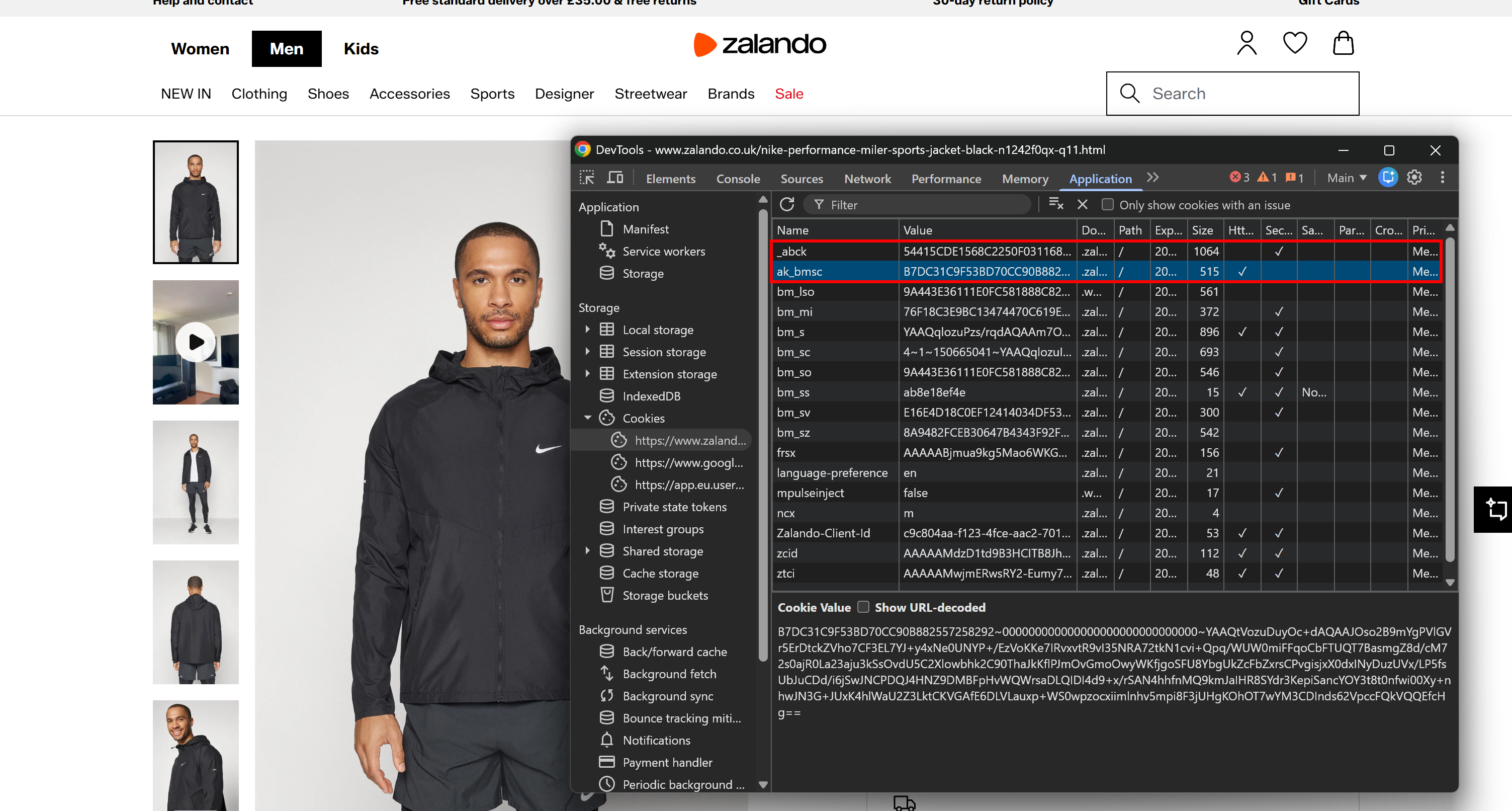
Das sind die wesentlichen Cookies, die von Akamais Bot-Erkennungssystemen gesetzt werden:
_abck: Ein langlebiger Cookie für Verhaltens-Tracking und Risikobewertung (kann monatelang bestehen bleiben).ak_bmsc: Ein kurzlebiger Session-Cookie zur Erkennung von Anomalien im Browsing-Verhalten (läuft innerhalb weniger Stunden ab).
Obwohl es weitere Signale geben kann, sind diese ausreichend, um die meisten Akamai-gesicherten Websites zu identifizieren.
Akamai-Bot-Erkennung in der Praxis
Um zu verstehen, wie sich Akamais Anti-Bot-Mechanismen in einem Automatisierungsszenario verhalten, betrachten Sie zwei gängige Ansätze:
- Senden Sie eine direkte Anfrage an den Zielserver mit einem HTTP-Client wie Requests.
- Rendern Sie die Seite im Headless-Modus mit einem Browser-Automatisierungstool wie Playwright.
Hinweis: Die Zielseite ist dieselbe Zalando-Produktseite wie zuvor.
Akamai vs. Requests
Versuchen Sie, eine Akamai-verwaltete Seite über die requests-Bibliothek abzurufen:
# pip install requests
import requests
url = "https://www.zalando.co.uk/nike-performance-miler-sports-jacket-black-n1242f0qx-q11.html"
response = requests.get(url)
print("Status code:", response.status_code)
print("\nPage HTML:\n")
print(response.text[:2500])Das Skript gibt Folgendes aus:
Status code: 403Dies zeigt, dass der Server die Anfrage mit einer 403 Forbidden-Antwort abgelehnt hat. Das zurückgegebene HTML enthält eine Fehlerseite anstelle des erwarteten Produktinhalts.
Ein einfacher requests-Aufruf reicht also nicht aus, um auf eine Akamai-verwaltete Seite zuzugreifen. Das gleiche Ergebnis tritt bei den meisten Standard-HTTP-Clients auf.
Akamai vs. Playwright
Besuchen Sie die Zielseite mit Playwright im Headless-Modus. Geben Sie dann den HTTP-Statuscode aus und erstellen Sie einen Screenshot:
# pip install playwright
# python -m playwright install
from playwright.sync_api import sync_playwright
url = "https://www.zalando.co.uk/nike-performance-miler-sports-jacket-black-n1242f0qx-q11.html"
with sync_playwright() as p:
# Visit the target page in headless mode
browser = p.chromium.launch(headless=True)
context = browser.new_context()
page = context.new_page()
response = page.goto(url)
# Print the response's HTTP status code
if response:
print("Status code:", response.status)
else:
print("No response received")
# Take a screenshot of the page
page.screenshot(path="zalando.png")
browser.close()Auch hier wird die Anfrage blockiert, und die Ausgabe lautet:
Status code: 403Der resultierende Screenshot enthält eine Zugriffsverweigungsseite anstelle des erwarteten Produktinhalts: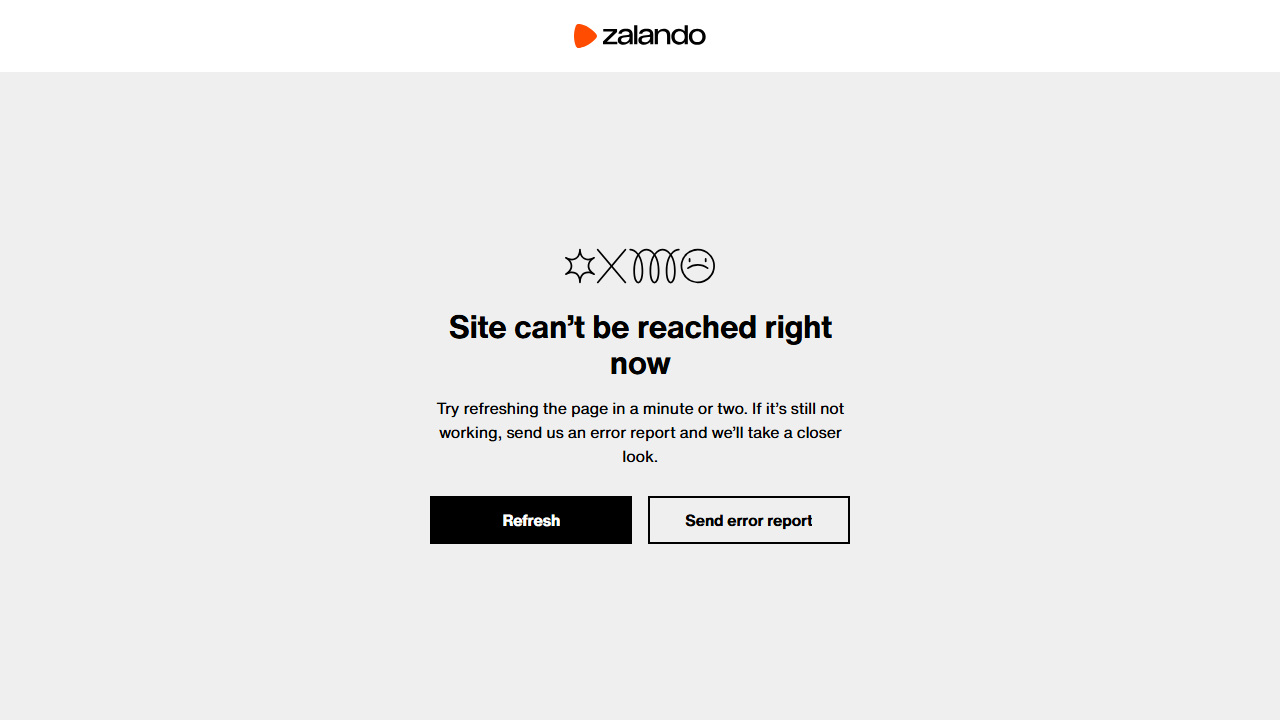
Die Fehlerseite zeigt an, dass der Zugriff ohne detaillierte Informationen nicht erlaubt ist.
Hinweis: Im Gegensatz zu anderen Anti-Bot-Systemen (z. B. Cloudflare) variieren Akamai-Fehlerantworten in der Regel je nach Website.
Übergeordnete Ansätze zur Umgehung der Akamai-Bot-Erkennung
In diesem Kapitel erkunden Sie die wichtigsten Ansätze zur Umgehung der Akamai-Bot-Erkennung. Wenn Sie es eilig haben, schauen Sie sich die zusammenfassende Tabelle unten an.
| Ansatz | Kurzbeschreibung | Vorteile | Nachteile |
|---|---|---|---|
| Direktzugriff auf den Ursprungsserver | Versucht, das CDN zu umgehen, indem Anfragen direkt an den Ursprungsserver gesendet werden, sofern seine IP bekannt ist | Keine zusätzlichen Tools erforderlich | Funktioniert in der Praxis selten |
| Open-Source-Browser-Automatisierungs-Bypass-Tools | Verwendet spezifische Automatisierungs-Frameworks zur Simulation echter Nutzer-Browser-Sitzungen | Kostenlos | Erkennbar durch Reverse Engineering und IP-basierte Blockierung |
| Premium-Anti-Bot-Scraping-Tools | Verwendet verwaltete cloudbasierte Dienste, die alles für Sie erledigen | Sehr zuverlässig, skalierbar, minimaler Einrichtungsaufwand, verwaltet den gesamten Anti-Bot-Stack | Kostenpflichtig |
Ansatz #1: Direktzugriff auf den Ursprungsserver
Letztendlich ist Akamai ein CDN. Das bedeutet, es sitzt zwischen dem Ziel-Ursprungsserver und Ihnen (dem Nutzer) und cached sowie schützt Inhalte, während es Traffic über sein verteiltes Edge-Netzwerk leitet.
Theoretisch könnten Sie, wenn die IP-Adresse des Ursprungsservers bekannt wäre (z. B. durch historische DNS-Einträge oder Fehlkonfigurationen), versuchen, Anfragen direkt an ihn zu senden. Das würde bedeuten, das Akamai-Netzwerk direkt zu umgehen, da Ihr Traffic nun außerhalb der CDN-Schicht geleitet würde.
In der Praxis ist dieser Ansatz aus mehreren Gründen unzuverlässig:
- Zugangsbeschränkungen am Ursprungsserver: Ordnungsgemäß konfigurierte Ursprungsserver akzeptieren nur Traffic aus den IP-Bereichen des CDN oder erfordern authentifizierte Anfragen (z. B. signierte Header oder Tokens).
- Netzwerkseitige Kontrollen: Firewalls und Sicherheitsgruppen blockieren in der Regel den direkten öffentlichen Zugriff.
- Begrenzte Exposition: Die Ursprungs-IP hinter einem CDN zu entdecken ist ungewöhnlich, da moderne Setups darauf ausgelegt sind, diese Art von Datenleck zu verhindern.
Aufgrund dieser Einschränkungen ist der Direktzugriff auf den Ursprungsserver in gut konfigurierten Umgebungen generell nicht praktikabel. Dies ist eher ein theoretisches Konzept als ein praktischer Ansatz.
Ansatz #2: Open-Source-Browser-Automatisierungs-Bypass-Tools nutzen
Verschiedene Open-Source-Browser-Automatisierungsbibliotheken erzeugen automatisierte Sitzungen, die echtem Nutzerverhalten ähneln. Dazu gehören Tools wie Camoufox, SeleniumBase, NODRIVER und andere Anti-Bot-orientierte Automatisierungs-Frameworks. Einige All-in-one-Scraping-Frameworks wie Scrapling bieten ähnliche Funktionen.
Diese Tools passen den zugrunde liegenden Browser an, um realistische Fingerabdrücke zu erzielen, und bieten dabei eine Selenium- oder Playwright-ähnliche Browser-Automatisierungs-API. Dies gilt auch beim Betrieb der Browser-Automatisierung im Headless-Modus.
Dieser Ansatz zur Umgehung der Akamai-Bot-Erkennung hat jedoch zwei wesentliche Einschränkungen:
- Open-Source-Transparenz: Da diese Tools Open Source sind, sind ihre Implementierungsdetails öffentlich zugänglich. Infolgedessen können Anti-Bot-Anbieter wie Akamai sie per Reverse Engineering analysieren und ihre Wirksamkeit vorübergehend einschränken oder verringern (bis Updates veröffentlicht werden). Dies schafft einen anhaltenden Katz-und-Maus-Kreislauf zwischen Erkennungssystemen und Automatisierungstools.
- IP-basierte Durchsetzung: Dieser Ansatz eignet sich hervorragend zur Umgehung fingerabdruckbasierter Überprüfungen. Scraping-Anfragen stammen jedoch weiterhin von Ihrer IP-Adresse. Daher kann Akamai Sie immer noch durch Rate-Limiting oder IP-Reputationsmechanismen blockieren. Um dem entgegenzuwirken, müssen Sie einen Premium-Proxy-Rotationsdienst eines Drittanbieters integrieren.
Ansatz #3: Premium-Akamai-Bypass-Scraping-Tools integrieren
Der zuverlässigste und skalierbarste Weg zur Umgehung des Akamai-Bot-Schutzes ist die Nutzung von Premium-Web-Scraping-Tools. Diese Dienste bewältigen den gesamten Stack an Herausforderungen, einschließlich Browser-Fingerprinting, Automatisierungserkennung, IP-Management, CAPTCHA-Lösung und Infrastrukturskalierung.
Anstatt Anfragen direkt zu verwalten, geben Sie eine Ziel-URL an und erhalten den entsperrten Inhalt zurück. Dieser kann entweder über Standard-HTTP-Antworten oder in manchen Fällen über Browser-Automatisierungssitzungen bereitgestellt werden.
Da diese Lösungen in der Cloud bereitgestellt werden, besteht anders als bei Open-Source-Bibliotheken kein Risiko durch Reverse Engineering. Außerdem basieren sie in der Regel auf großangelegten Proxy-Netzwerken, was eine Skalierbarkeit auf Unternehmensebene ermöglicht.
Der Hauptnachteil sind die Kosten, da es sich um kommerzielle Produkte handelt. Dennoch sind die Kosten pro erfolgreicher Anfrage oft sehr niedrig (manchmal Bruchteile eines Cents).
So umgehen Sie Akamai mit Open-Source-Lösungen
Der Direktzugriff auf den Ursprungsserver ist eher ein theoretischer als ein praktischer Ansatz. Beginnen wir daher mit der Demonstration des Einsatzes Anti-Bot-spezifischer Browser-Automatisierungstools zur Umgehung von Akamai-Schutzmaßnahmen.
In diesem Abschnitt testen wir Camoufox und SeleniumBase, obwohl auch andere Tools vertrauenswürdig sind. Das Ziel des Tests ist es, die zuvor erwähnte geschützte Zalando-Produktseite zu besuchen und einen Screenshot davon zu erstellen.
Hinweis: Das folgende Ergebnis bezieht sich auf einen einzelnen Skript-Lauf mit einer Residential-IP. Dasselbe Skript schlägt bei Ausführung von einem Server oder in großem Maßstab wahrscheinlich aufgrund von Rate-Limiting oder IP-Reputationsproblemen fehl.
Sehen Sie Camoufox und SeleniumBase im Einsatz gegen Akamai-geschützte Inhalte!
Akamai-Bypass-Test mit Camoufox
Zuerst installieren Sie Camoufox in Ihrem Python-Projekt:
pip install camoufoxLaden Sie dann die Browser-Binärdateien herunter:
python -m camoufox fetchCamoufox basiert auf Playwright, daher ist seine API sehr ähnlich. Besuchen Sie die Zielseite, geben Sie den HTTP-Statuscode aus und erstellen Sie einen Screenshot mit:
# pip install camoufox
# python -m camoufox fetch
from camoufox.sync_api import Camoufox
url = "https://www.zalando.co.uk/nike-performance-miler-sports-jacket-black-n1242f0qx-q11.html"
with Camoufox(headless=True) as browser:
# Visit the target page
page = browser.new_page()
response = page.goto(url)
# Print the response's HTTP status code
if response:
print("Status code:", response.status)
else:
print("No response received")
# Take a screenshot of the page
page.screenshot(path="camoufox_zalando.png")Weitere Informationen zu dieser Bibliothek finden Sie in unserem Leitfaden zum Web-Scraping mit Camoufox.
Auch im Headless-Modus sollte das erwartete Ergebnis sein:
Status code: 200Und die generierte Datei camoufox_zalando.png sollte die gerenderte Seite enthalten: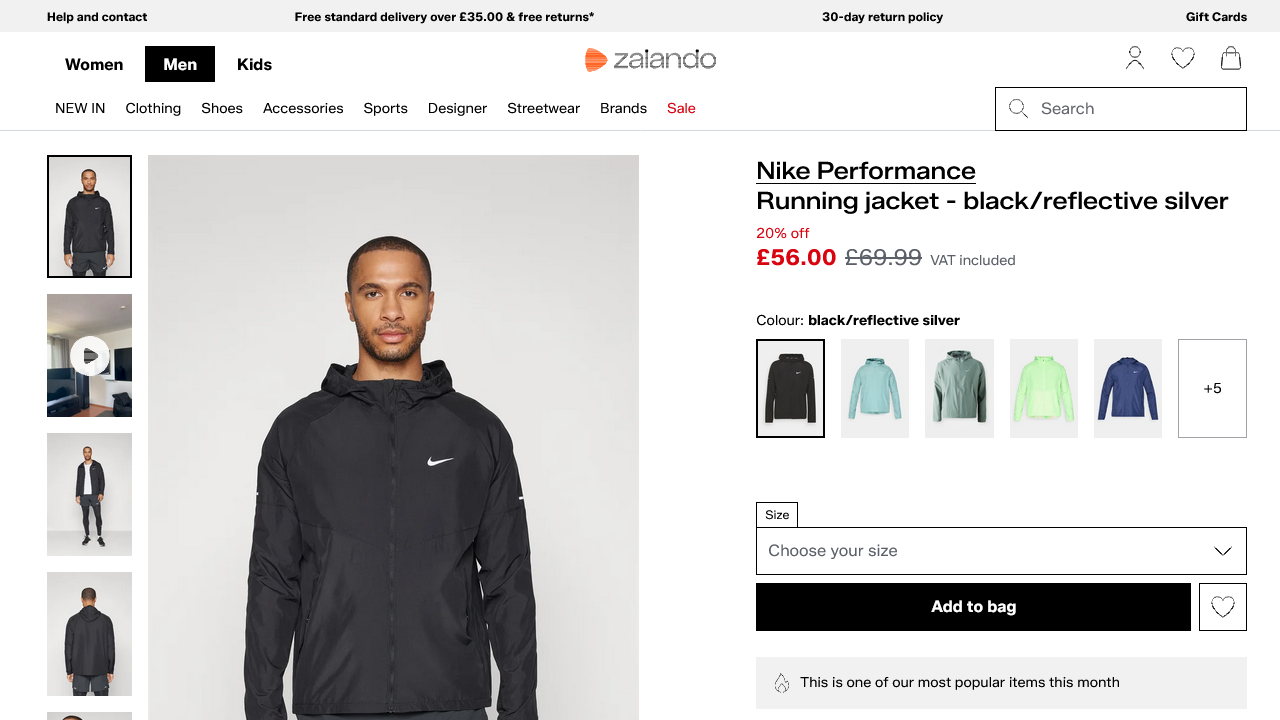
Wunderbar! Camoufox hat es geschafft, Akamai zu umgehen.
Akamai-Bypass-Test mit SeleniumBase
Installieren Sie SeleniumBase mit:
pip install seleniumbaseVerwenden Sie es anschließend, um die Zielseite im UC-Modus zu besuchen und einen Screenshot zu erstellen:
# pip install seleniumbase
from seleniumbase import SB
url = "https://www.zalando.co.uk/nike-performance-miler-sports-jacket-black-n1242f0qx-q11.html"
with SB(uc=True, headless=True) as sb:
# Open the page
sb.open(url)
# Get status code via JS (as Selenium does not expose it directly)
status = sb.execute_script(
"return window.performance.getEntries()[0]?.responseStatus || 'unknown';"
)
print("Status code:", status)
# Wait for page load
sb.sleep(3)
# Take a screenshot
sb.save_screenshot("seleniumbase_zalando.png")Weitere Informationen zur Funktionsweise des UC-Modus und seiner Konfiguration finden Sie im SeleniumBase-Scraping-Leitfaden.
Das erwartete Ergebnis sollte sein:
Status code: 200Und die erzeugte Datei seleniumbase_zalando.png sollte zeigen: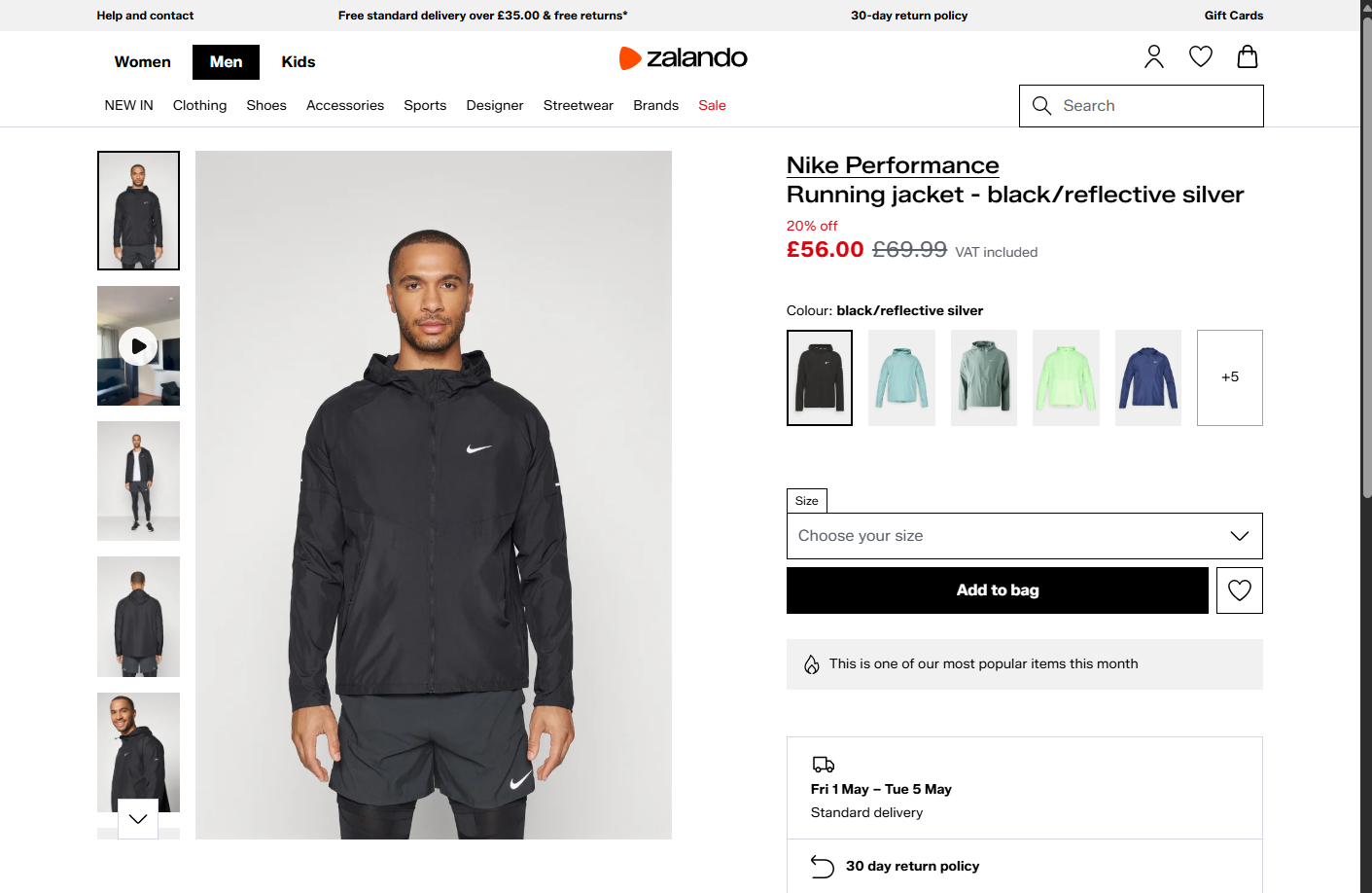
Toll! SeleniumBase hat die Akamai-Anti-Bot-Schutzmaßnahmen ebenfalls umgangen.
So umgehen Sie Akamai im großen Maßstab mit Bright Data
Bright Data ermöglicht Ihnen den Zugriff auf praktisch jede Webseite, unabhängig davon, ob sie durch Akamai, Cloudflare oder andere Anti-Bot-Systeme geschützt ist.
Insbesondere sind alle Bright Data Scraping-Dienste durch ein dediziertes Akamai Bot Bypass-System unterstützt. Dieses verwaltet automatisch Akamais Anti-Bot-Challenges für Sie.
Ein wesentlicher Vorteil von Bright Data ist, dass es von einem der größten Proxy-Netzwerke der Welt betrieben wird, mit über 400 Millionen IPs. Dies ermöglicht unbegrenzte Parallelität mit 99,99 % Uptime und einer Anfrage-Erfolgsrate von 99,95 %. Außerdem ist es dadurch nicht von IP-bezogenen oder Rate-Limiting-Blockierungen betroffen, anders als Open-Source-Browser-Automatisierungstools.
Im Folgenden demonstrieren wir, wie Sie den Akamai-Schutz umgehen können mit:
- Web Unlocker API: Eine Scraping-API, die Proxy-Rotation, Anti-Bot-Challenges (einschließlich Akamai) und CAPTCHA-Lösung in einer einzigen Anfrage verwaltet.
- Browser API: Eine cloudbasierte, Anti-Bot-optimierte Browser-Sitzung, die über Playwright, Selenium, Puppeteer oder ein beliebiges CDP-kompatibles Automatisierungstool gesteuert werden kann.
Folgen Sie den Anweisungen in den nächsten Kapiteln!
Akamai mit Bright Datas Web Unlocker API umgehen
Erleben Sie die Umgehung der Akamai-Bot-Erkennung mit der Bright Data Web Unlocker API in einem statischen Scraping-Szenario.
Voraussetzungen
Um diesem Abschnitt zu folgen, stellen Sie sicher, dass Sie haben:
- Ein Bright Data-Konto mit einem konfigurierten API-Schlüssel.
- Eine in Ihrem Konto eingerichtete Web Unlocker API-Zone.
- Ein Scraping-Skript basierend auf einem HTTP-Client-Ansatz.
Zur Einrichtung Ihres Bright Data-Kontos für die Web Unlocker API-Nutzung folgen Sie dem offiziellen Leitfaden “Create Your First Unlocker API“.
Beispiel
Wenn Sie stattdessen das Akamai-entsperrte HTML einer Seite abrufen möchten, verwenden Sie die Web Unlocker API wie folgt:
import requests
# Replace with your Bright Data API key and Web Unlocker API zone name
BRIGHT_DATA_API_KEY = "<YOUR_BRIGHT_DATA_API_KEY>"
BRIGHT_DATA_WEB_UNLOCKER_API_ZONE = "<YOUR_WEB_UNLOCKER_API_ZONE_NAME>"
target_url = "https://www.zalando.co.uk/nike-performance-miler-sports-jacket-black-n1242f0qx-q11.html"
payload = {
"zone": BRIGHT_DATA_WEB_UNLOCKER_API_ZONE,
"url": target_url,
"format": "raw"
}
headers = {
"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}",
"Content-Type": "application/json"
}
# Perform a request to the Bright Data Web Unlocker API
response = requests.post(
"https://api.brightdata.com/request",
json=payload,
headers=headers
)
print("Status code:", response.status_code)
html = response.text
print("\nPage HTML:\n")
print(html)
# Perform web scraping on the returned HTML...Das Ergebnis wird sein:
Status code: 200Die Variable html enthält dann den vollständigen Seitenquelltext. Sie können ihn einfach mit einem HTML-Parser parsen und die gewünschten Daten in einem Web-Scraping-Workflow extrahieren. Für groß angelegtes Scraping nutzen Sie unseren Zalando Scraper.
Akamai mit Bright Datas Browser API umgehen
Hier sehen Sie, wie Sie Akamai-Anti-Bot-Prüfungen mithilfe der Bright Data Browser API in einem Browser-Automatisierungsszenario bestehen.
Voraussetzungen
Um diesen Abschnitt durchzuarbeiten, stellen Sie sicher, dass Sie haben:
- Eine in Ihrem Bright Data-Konto konfigurierte Browser API-Zone.
- Ein Browser-Automatisierungs-Scraping-Skript.
Zum Abrufen der Browser API-Verbindungs-URL lesen Sie den offiziellen Leitfaden “Create Your First Browser API“.
Hier zeigen wir ein Playwright-Beispiel, daher sieht die Browser API-Verbindungs-URL wie folgt aus:
wss://<BRIGHT_DATA_BROWSER_API_USERNAME>:<BRIGHT_DATA_BROWSER_API_PASSWORD>@brd.superproxy.io:9222Beispiel
Verbinden Sie Ihr Playwright-Automatisierungsskript mit Bright Datas Browser API und wiederholen Sie die zuvor gezeigte Screenshot-Logik:
# pip install playwright
# python -m playwright install
from playwright.sync_api import sync_playwright
url = "https://www.zalando.co.uk/nike-performance-miler-sports-jacket-black-n1242f0qx-q11.html"
BRIGHT_DATA_BROWSER_API_CDP_URL = "wss://<BRIGHT_DATA_BROWSER_API_USERNAME>:<BRIGHT_DATA_BROWSER_API_PASSWORD>@brd.superproxy.io:9222"
with sync_playwright() as p:
# Connect to Bright Data CDP endpoint
browser = p.chromium.connect_over_cdp(BRIGHT_DATA_BROWSER_API_CDP_URL)
# Create a new context and page
context = browser.new_context()
page = context.new_page()
# Visit the target page in headless mode
response = page.goto(url)
# Print the response's HTTP status code
if response:
print("Status code:", response.status)
else:
print("No response received")
# Take a screenshot of the page
page.screenshot(path="zalando.png")
browser.close()Bei der Ausführung gibt das Skript zurück:
Status code: 200Der resultierende Screenshot enthält den gerenderten Seiteninhalt: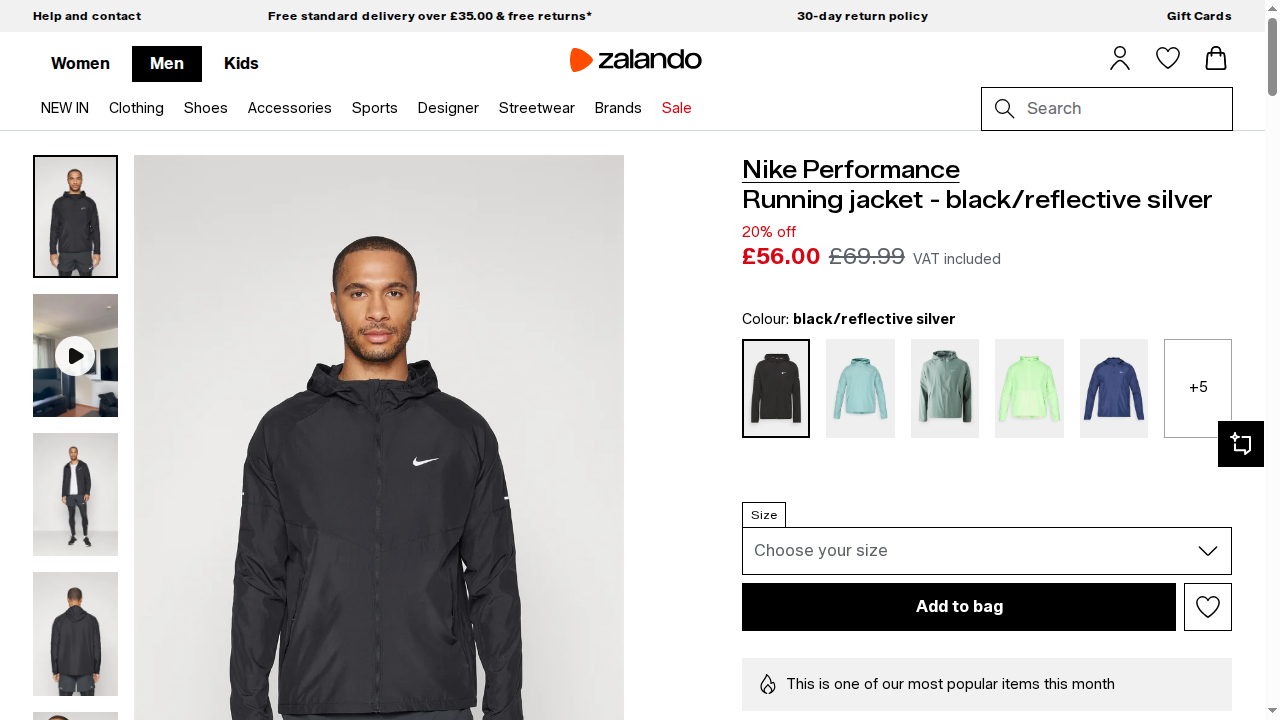
Fantastisch! Dank der Browser API-Integration hat das Playwright-Skript diesmal korrekt funktioniert. Die Browser API verwaltet die Automatisierung in echten Browser-Sitzungen, die in der Bright Data Cloud-Infrastruktur betrieben werden.
Sie können jetzt automatisierte Workflows erstellen, um ohne Einschränkungen mit der Seite zu interagieren!
Fazit
In diesem Artikel haben Sie gelernt, wie Akamais Anti-Bot-System funktioniert, und praktische Ansätze zur Handhabung in Automatisierungs- und Scraping-Workflows erkundet.
Unabhängig von der gewählten Methode wird der Prozess mit professionellen, schnellen und zuverlässigen Enterprise-Lösungen einfacher, wie zum Beispiel:
- Web Unlocker API: Ein API-Endpunkt, der automatisch Rate-Limiting, Fingerprinting-Challenges und andere Anti-Bot-Mechanismen verwaltet.
- Browser API: Ein verwalteter Cloud-Anti-Erkennungs-Browser, mit dem Sie Interaktionen mit jeder Website im großen Maßstab automatisieren können.
Wie andere Bright Data Scraping-Produkte werden diese Dienste vom Akamai Bot Solver betrieben.
Erstellen Sie noch heute kostenlos ein neues Bright Data-Konto und erkunden Sie unsere Scraping-Lösungen!




