
In diesem Artikel erfahren Sie:
- Was Apache Airflow und Apache Spark sind und was sie bieten.
- Warum die Orchestrierung der Web Unlocker-API von Bright Data mit Airflow und Spark eine leistungsstarke Strategie zur Lead-Generierung ist.
- Wie man eine End-to-End-Pipeline aufbaut, die strukturierte Geschäftsdaten in großem Maßstab sammelt, verarbeitet und speichert.
Bevor wir uns mit den konkreten Tools und der Implementierung befassen, wollen wir zunächst die grundlegenden Konzepte klären und sehen, wie sie innerhalb eines Workflows zur Lead-Generierung zusammenwirken.
Was ist Apache Airflow?
Apache Airflow ist eine Open-Source-Plattform zur Workflow-Orchestrierung für die programmatische Erstellung, Planung und Überwachung von Datenpipelines. Ursprünglich bei Airbnb entwickelt, ermöglicht sie Dateningenieuren, Workflows als gerichtete azyklische Graphen (DAGs) mit einfachem Python zu definieren, und bietet dabei volle Kontrolle über Aufgabenabhängigkeiten, Wiederholungsversuche, Zeitplanung und Benachrichtigungen.
Das Hauptziel besteht darin, Ihnen dabei zu helfen, komplexe, mehrstufige Datenpipelines zuverlässig auszuführen. Dies wird durch ein umfangreiches Ökosystem an Operatoren (für Bash, Python, HTTP, Spark, SQL und mehr), eine visuelle Web-Benutzeroberfläche zur Überwachung von Ausführungen, integrierte Wiederholungs- und Benachrichtigungslogik sowie native Integrationen mit Cloud-Plattformen wie AWS, GCP und Azure erreicht.
Nachdem wir nun die Workflow-Orchestrierung verstanden haben, wollen wir uns die Datenverarbeitungsseite der Pipeline ansehen.
Apache Spark ist eine einheitliche Analyse-Engine für die Verarbeitung großer Datenmengen. Es bietet ein Framework für verteilte Berechnungen, das riesige Datensätze im Arbeitsspeicher über einen Cluster von Rechnern hinweg verarbeiten kann, wodurch es deutlich schneller ist als herkömmliche festplattenbasierte Verarbeitungssysteme.
Spark unterstützt Batch-Verarbeitung, Streaming, SQL-Abfragen, maschinelles Lernen und Graphberechnungen über eine einheitliche API, die in Python (PySpark), Scala, Java und R verfügbar ist. Für datenintensive Workloads wie das Bereinigen, Deduplizieren, Anreichern und Transformieren großer Mengen gescrapter Geschäftsdaten ist Spark das branchenübliche Werkzeug.
Apache Airflow vs. Apache Spark: Was ist der Unterschied?
Wenn Sie mit diesem Stack noch nicht vertraut sind, kann man die beiden leicht verwechseln, da sie oft zusammen auftreten. Sie dienen jedoch sehr unterschiedlichen Zwecken:
- Apache Airflow ist ein Orchestrator. Es entscheidet, wann Aufgaben ausgeführt werden, in welcher Reihenfolge, wie mit Fehlern umgegangen wird und wie die gesamte Pipeline überwacht wird. Es verarbeitet selbst keine Daten.
- Apache Spark ist ein Datenprozessor. Es nimmt Rohdaten oder semistrukturierte Daten auf und transformiert sie in großem Maßstab mithilfe verteilter Berechnungen über viele Kerne oder Maschinen hinweg.
Sie ergänzen sich gut. Airflow plant und löst Ihre Spark-Jobs zum richtigen Zeitpunkt und in der richtigen Reihenfolge aus, während Spark die Hauptarbeit der Datentransformation übernimmt. In diesem Tutorial sehen Sie, wie Airflow die gesamte Pipeline durchgängig orchestriert: Auslösen von Bright Data zur Erfassung von Unternehmensdaten, Weiterleitung der Rohdaten an Spark zur Bereinigung und Anreicherung sowie Speichern der endgültigen Leads in einer Datenbank.
Warum Bright Data in eine Airflow + Spark-Pipeline integrieren?
Airflow bietet einen SimpleHttpOperator und einen PythonOperator, mit denen Sie jede REST-API als Pipeline-Aufgabe aufrufen können. Das bedeutet, dass Sie die Erfassung von Webdaten als vollwertigen Schritt in Ihrem DAG neben Ihren Transformations- und Ladeaufträgen auslösen können.
Um jedoch zuverlässige, strukturierte Unternehmensdaten in großem Maßstab in Ihre Pipeline einzuspeisen, benötigen Sie eine Quelle, die Anti-Bot-Maßnahmen, geografisches Targeting und strukturierte Ausgabe bewältigen kann, ohne dass eine eigene Scraper-Wartung erforderlich ist. Hier kommt die Web Unlocker API von Bright Data ins Spiel.
Die Web Unlocker API ermöglicht Ihnen den Zugriff auf jede öffentliche Webseite, unabhängig von Bot-Schutz, JavaScript-Rendering-Anforderungen oder geografischen Einschränkungen. Sie senden eine POST-Anfrage mit einer Ziel-URL, und Bright Data gibt den Seiteninhalt zurück. Kein Browser-Automatisierungscode, keine Proxy-Verwaltung, keine CAPTCHA-Bearbeitung.
Dieser Ansatz eignet sich besonders für:
- Pipelines zur Lead-Generierung, die regelmäßig aktuelle Brancheneinträge aus Verzeichnissen sammeln und in ein CRM- oder Outreach-Tool einspeisen.
- Marktforschungs-Workflows, die Unternehmensdaten über Regionen oder Branchen hinweg für Wettbewerbsanalysen aggregieren.
- Datenanreicherungssysteme, die Kontaktdaten, Unternehmensgröße oder Branchenklassifizierung an eine bestehende Lead-Datenbank anhängen.
- Sales-Intelligence-Plattformen, die Änderungen in Unternehmensverzeichnissen überwachen und Benachrichtigungen auslösen, wenn Zielunternehmen ihre Profile aktualisieren.
Durch die Kombination von Airflows Scheduling und Orchestrierung mit Sparks verteilter Datenverarbeitung und Bright Datas Webdaten-Infrastruktur können Sie eine produktionsreife Lead-Generierungs-Engine aufbauen, die im Autopilot-Modus läuft.
So erstellen Sie eine Pipeline zur Lead-Generierung mit Airflow, Spark und Bright Data
In diesem angeleiteten Abschnitt erstellen Sie eine End-to-End-Pipeline, die aus drei Hauptphasen besteht:
- Abholen von Unternehmensverzeichnissen: Eine Airflow-Aufgabe ruft die Web Unlocker-API von Bright Data auf, um Suchergebnisse aus den Gelben Seiten für drei Städte zu sammeln.
- Validiert die gesammelten Daten: Eine zweite Aufgabe liest die gespeicherten Ergebnisse ein und bestätigt, dass die Daten erfolgreich erfasst wurden.
- Verarbeitung mit Spark: Ein PySpark-Job bereinigt, dedupliziert und bewertet die Rohdatensätze.
Hinweis: Dies ist eine von vielen möglichen Architekturen. Sie könnten die Spark-Ausgabe in ein Data Warehouse wie BigQuery oder Snowflake schreiben, sie über deren API direkt an ein CRM übertragen oder sie in einen LLM-basierten Anreicherungsschritt für automatisiertes Lead-Scoring einspeisen.
Befolgen Sie die nachstehenden Anweisungen, um eine automatisierte Pipeline zur Lead-Generierung zu erstellen, die auf der Web Unlocker-API von Bright Data in Apache Airflow und Spark basiert!
Voraussetzungen
Um mitzumachen, benötigen Sie:
- Ein Bright Data-Konto mit einer aktiven Web Unlocker -Zone. Melden Sie sich bei Ihrem Bright Data-Dashboard an, gehen Sie zu den Kontoeinstellungen und kopieren Sie Ihren API-Token. Dieser liegt im UUID-Format vor. Notieren Sie sich außerdem Ihren Zonennamen.
- Docker Desktop (macOS oder Windows) ODER eine native Python-Umgebung (Ubuntu/Linux). Siehe Schritt 1 für beide Optionen.
Schritt 1: Projekteinrichtung
Installieren Sie Docker Desktop und stellen Sie sicher, dass es läuft, bevor Sie fortfahren. Gehen Sie in den Docker Desktop-Einstellungen zu „Ressourcen“ und weisen Sie mindestens 5 GB Arbeitsspeicher zu. Der Multi-Container-Stack von Airflow benötigt dies.
Schritt 2: Erstellen Sie Ihre Projektstruktur
Erstellen Sie ein Arbeitsverzeichnis und die von Airflow benötigten Ordner:
mkdir airflow-lead-pipeline && cd airflow-lead-pipeline
mkdir dags spark_jobs logs plugins configIhre Projektstruktur sieht wie folgt aus:
airflow-lead-pipeline/
├── dags/
│ └── lead_generation_dag.py
├── spark_jobs/
│ └── process_leads.py
├── logs/
├── plugins/
├── config/
├── Dockerfile
└── docker-compose.yamlSchritt 3: Docker Compose einrichten
Laden Sie die offizielle Airflow-Docker-Compose-Datei herunter:
curl -LfO 'https://airflow.apache.org/docs/apache-airflow/2.7.3/docker-compose.yaml'Erstellen Sie eine Dockerfile-Datei im selben Verzeichnis. Diese erweitert das Basis-Airflow-Image um die Requests -Bibliothek:
FROM apache/airflow:2.7.3
RUN pip install requests pysparkÖffnen Sie docker-compose.yaml. Suchen Sie den x-airflow-common-Block oben im Dokument und fügen Sie build: . direkt unter der Zeile image: ein:
x-airflow-common:
&airflow-common
image: ${AIRFLOW_IMAGE_NAME:-apache/airflow:2.7.3}
build: .Stellen Sie außerdem sicher, dass die Zeile _PIP_ADDITIONAL_REQUIREMENTS leer ist. Die Abhängigkeiten gehören in die Dockerfile-Datei, nicht in diese Umgebungsvariable:
_PIP_ADDITIONAL_REQUIREMENTS: ""Fügen Sie abschließend einen Volume-Mount für spark_jobs/ in die Liste volumes: desselben Blocks ein. Die Standarddatei mountet nur dags/, logs/, plugins/ und config/, sodass der Worker-Container Ihre Spark-Job-Datei ohne diesen Zusatz nicht finden kann:
volumes:
- ${AIRFLOW_PROJ_DIR:-.}/spark_jobs:/opt/airflow/spark_jobsDer Rest der Datei bleibt genau so, wie er heruntergeladen wurde. Standardmäßig erhalten Sie CeleryExecutor mit Redis als Message Broker und PostgreSQL als Metadaten-Datenbank, die Ordner dags/, logs/, config/ und plugins/ als Volumes aus Ihrem Projektordner eingebunden, Standard-Anmeldedaten mit dem Benutzernamen airflow und dem Passwort airflow sowie einen airflow-init-Dienst, der beim ersten Start einmalig ausgeführt wird, um die Datenbank zu migrieren und den Admin-Benutzer anzulegen.
Erstellen Sie das benutzerdefinierte Image und starten Sie alle Dienste:
docker compose build
docker compose up -dWarten Sie etwa 60 Sekunden und überprüfen Sie dann, ob alle sechs Container ordnungsgemäß laufen:
docker compose psErwartete Ausgabe:

Öffnen Sie http://localhost:8080 in Ihrem Browser und melden Sie sich mit dem Benutzernamen airflow und dem Passwort airflow an.
Schritt 4: Erstellen Sie den Airflow-DAG
Erstellen Sie die Datei dags/lead_generation_dag.py:
import json
import requests
from datetime import datetime, timedelta
from pathlib import Path
from airflow import DAG
from airflow.operators.python import PythonOperator
API_KEY = "your-brightdata-api-token-here"
Zone = "web_unlocker1"
BASE_URL = "https://api.brightdata.com/request"
RAW_DATA_PATH = "/tmp/brightdata_raw/leads.json"
HEADERS = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json",
}
TARGETS = [
"https://www.yellowpages.com/search?search_terms=software+company&geo_location_terms=San+Francisco+CA",
"https://www.yellowpages.com/search?search_terms=marketing+agency&geo_location_terms=New+York+NY",
"https://www.yellowpages.com/search?search_terms=fintech+startup&geo_location_terms=Austin+TX",
]
default_args = {
"owner": "data-team",
"retries": 2,
"retry_delay": timedelta(minutes=5),
}
def fetch_business_listings(**context):
results = []
for url in TARGETS:
print(f"Abrufen: {url}")
response = requests.post(
BASE_URL,
headers=HEADERS,
json={
"zone": Zone,
"url": url,
"format": "raw",
"data_format": "markdown",
},
timeout=60,
)
response.raise_for_status()
results.append({
"url": url,
"content": response.text,
"status": response.status_code,
})
print(f"{len(response.text)} Zeichen von {url} abgerufen")
Path(RAW_DATA_PATH).parent.mkdir(parents=True, exist_ok=True)
with open(RAW_DATA_PATH, "w") as f:
json.dump(results, f, indent=2)
print(f"{len(results)} Seiten wurden unter {RAW_DATA_PATH} gespeichert")
context["ti"].xcom_push(key="record_count", value=len(results))
def validate_output(**context):
count = context["ti"].xcom_pull(key="record_count", task_ids="fetch_listings")
with open(RAW_DATA_PATH) as f:
data = json.load(f)
print(f"Validierung bestanden: {count} Seiten gesammelt")
for item in data:
print(f" URL: {item['url']} | Status: {item['status']} | Größe: {len(item['content'])} Zeichen")
with DAG(
dag_id="brightdata_lead_generation",
default_args=default_args,
description="Geschäftskontakte mit Bright Data Web Unlocker sammeln",
schedule_interval="0 6 * * 1",
start_date=datetime(2026, 3, 12),
catchup=False,
tags=["lead-generation", "brightdata"],
) as dag:
fetch_listings = PythonOperator(
task_id="fetch_listings",
python_callable=fetch_business_listings,
)
validate_data = PythonOperator(
task_id="validate_data",
python_callable=validate_output,
)
fetch_listings >> validate_dataErsetzen Sie „your-brightdata-api-token-here“ durch Ihren tatsächlichen API-Token und passen Sie „ZONE“ an den Namen Ihrer Web Unlocker-Zone an.
Schauen wir uns einmal an, was die einzelnen Teile bewirken:
API_KEYundZONE: Ihre Bright Data-Anmeldedaten. Der API-Token ist der Token im UUID-Format aus Ihren Kontoeinstellungen, kein Zonenpasswort.TARGETS: Drei Yellow-Pages-Such-URLs für Softwareunternehmen in San Francisco, Marketingagenturen in New York und Fintech-Startups in Austin.fetch_business_listings: Durchläuft jede Ziel-URL und sendet eine POST-Anfrage an die Web Unlocker-API. Bright Data übernimmt Anti-Bot-Maßnahmen, Proxy-Rotation und JavaScript-Rendering und gibt den Seiteninhalt als Markdown zurück. Die Ergebnisse werden auf der Festplatte gespeichert, und die Datensatzanzahl wird an den XCom-Speicher von Airflow weitergeleitet, damit die nächste Aufgabe sie lesen kann.validate_output: Liest die gespeicherte Datei und protokolliert jede URL, den HTTP-Status und die Inhaltsgröße. Dies dient als einfache Datenqualitätsprüfung vor der nachgelagerten Verarbeitung.fetch_listings >> validate_data: Der>>-Operator definiert die Aufgabenabhängigkeit. Die Validierung wird erst ausgeführt, nachdem das Abrufen erfolgreich war.
Wichtig: Setzen Sie bei der ersten Bereitstellung eines DAG mit wiederkehrendem Zeitplan immer
start_dateauf das heutige Datum undcatchup=False. Wenn Siestart_dateauf ein Datum in der Vergangenheit setzen undcatchup=Trueverwenden, stellt Airflow für jedes seit diesem Datum verpasste Intervall einen Nachhollauf in die Warteschlange. Bei einem wöchentlichen Zeitplan, der vor zehn Wochen begann, bedeutet dies zehn gleichzeitige Läufe, die in dem Moment, in dem Sie den DAG aus der Pause holen, um Worker-Slots konkurrieren.
Schritt 5: Schreiben Sie den PySpark-Transformationsjob
Erstellen Sie die Datei spark_jobs/process_leads.py:
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, trim, regexp_replace, when, lit
import sys
def main(input_path: str, output_path: str):
spark = SparkSession.builder
.appName("BrightData Lead Processing")
.config("spark.sql.adaptive.enabled", "true")
.getOrCreate()
raw_df = spark.read.option("multiLine", True).json(input_path)
cleaned_df = raw_df.select(
trim(col("name")).alias("company_name"),
trim(col("phone")).alias("phone"),
trim(col("website")).alias("website"),
trim(col("address")).alias("address"),
trim(col("city")).alias("city"),
trim(col("state")).alias("state"),
trim(col("category")).alias("industry"),
col("rating").cast("float").alias("rating"),
col("reviews_count").cast("integer").alias("reviews_count"),
)
.filter(col("company_name").isNotNull())
.filter(col("phone").isNotNull())
.dropDuplicates(["company_name", "phone"])
enriched_df = cleaned_df.withColumn(
"lead_score",
when(
(col("rating") >= 4.0) & (col("reviews_count") >= 50), lit("hot")
).when(
(col("rating") >= 3.0) & (col("reviews_count") >= 10), lit("warm")
).otherwise(lit("cold"))
).withColumn(
"website_clean",
regexp_replace(col("website"), "^https?://", "")
)
enriched_df.write.mode("overwrite").parquet(output_path)
print(f"{enriched_df.count()} Leads verarbeitet. Ausgabe in {output_path} geschrieben")
spark.stop()
if __name__ == "__main__":
main(sys.argv[1], sys.argv[2])Dieser Job führt vier Schritte aus. Er lädt die von fetch_listings erstellten JSON-Rohdaten von der Festplatte. Er bereinigt die Daten, indem er Leerzeichen normalisiert, numerische Felder umwandelt und Datensätze ohne Namen oder Telefonnummer entfernt. Er dedupliziert Datensätze nach Firmennamen und Telefonnummer, um doppelte Einträge in verschiedenen Städten zu entfernen. Schließlich bewertet er jeden Datensatz mit einem „lead_score “-Label: Unternehmen mit einer Bewertung von 4,0 oder höher und mindestens 50 Bewertungen werden als „hot“ markiert, solche mit einer Bewertung von 3,0 oder höher und mindestens 10 Bewertungen als „warm“ und alle anderen als „cold“.
Schritt 6: Auslösen und Überwachen der Pipeline
Sobald sich Ihre DAG-Datei im Ordner „dags/“ befindet, wird sie von Airflow innerhalb von 30 Sekunden automatisch erkannt.
Docker-Benutzer: Setzen Sie die DAG fort und lösen Sie sie aus:
docker compose exec --user airflow airflow-scheduler airflow dags unpause brightdata_lead_generation
docker compose exec --user airflow airflow-scheduler airflow dags trigger brightdata_lead_generation
Beobachten Sie die Worker-Protokolle:
docker compose logs airflow-worker -f --tail=20Sobald die Aufgaben ausgeführt werden, sehen Sie eine Ausgabe wie diese:
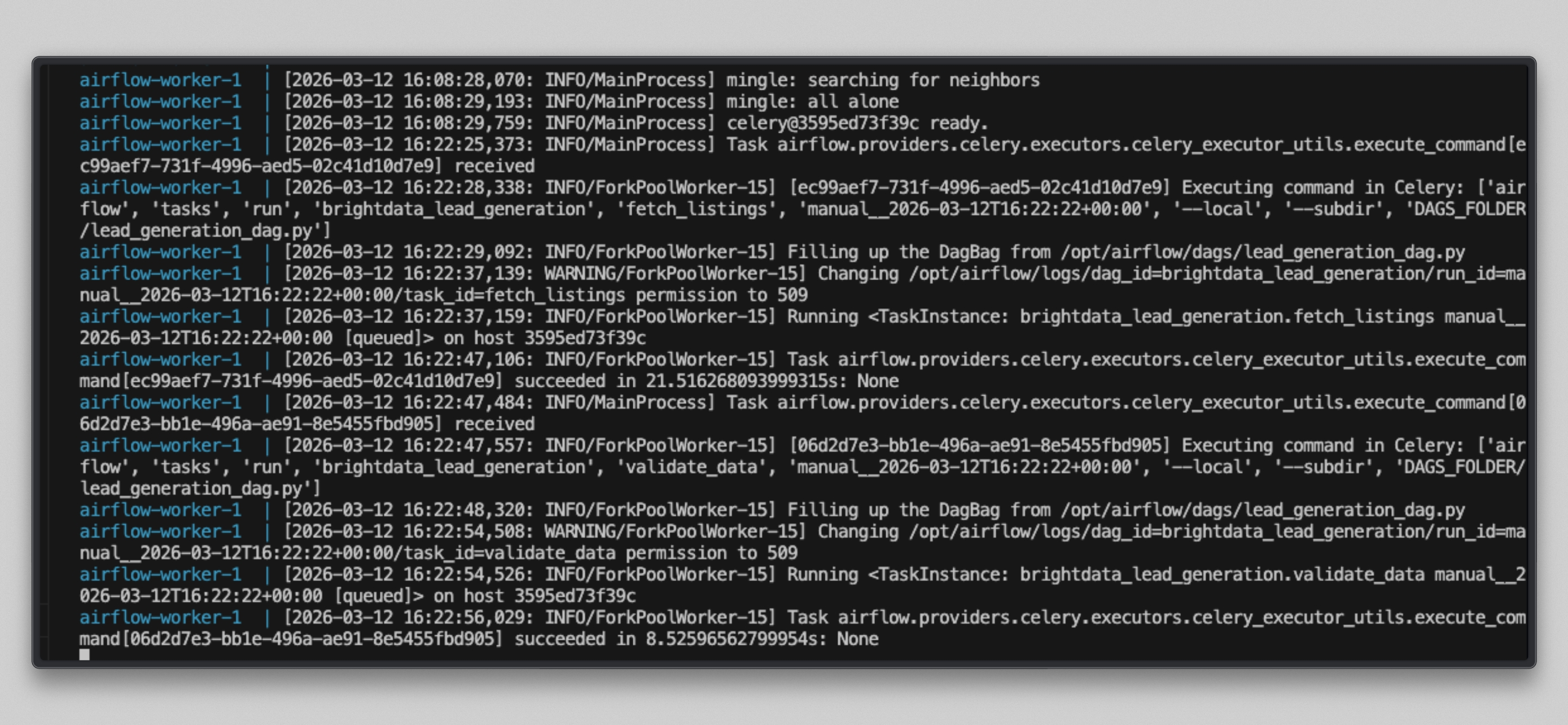
Öffnen Sie http://localhost:8080, klicken Sie auf den DAG „brightdata_lead_generation“ und wechseln Sie zur Grid-Ansicht. Jede Aufgabenkachel wird grün, sobald sie abgeschlossen ist. Klicken Sie auf eine beliebige Aufgabenkachel und wählen Sie „Log“, um die Echtzeit-Ausgabe anzuzeigen, einschließlich jeder abgerufenen URL und der von Bright Data zurückgegebenen Zeichenanzahl.
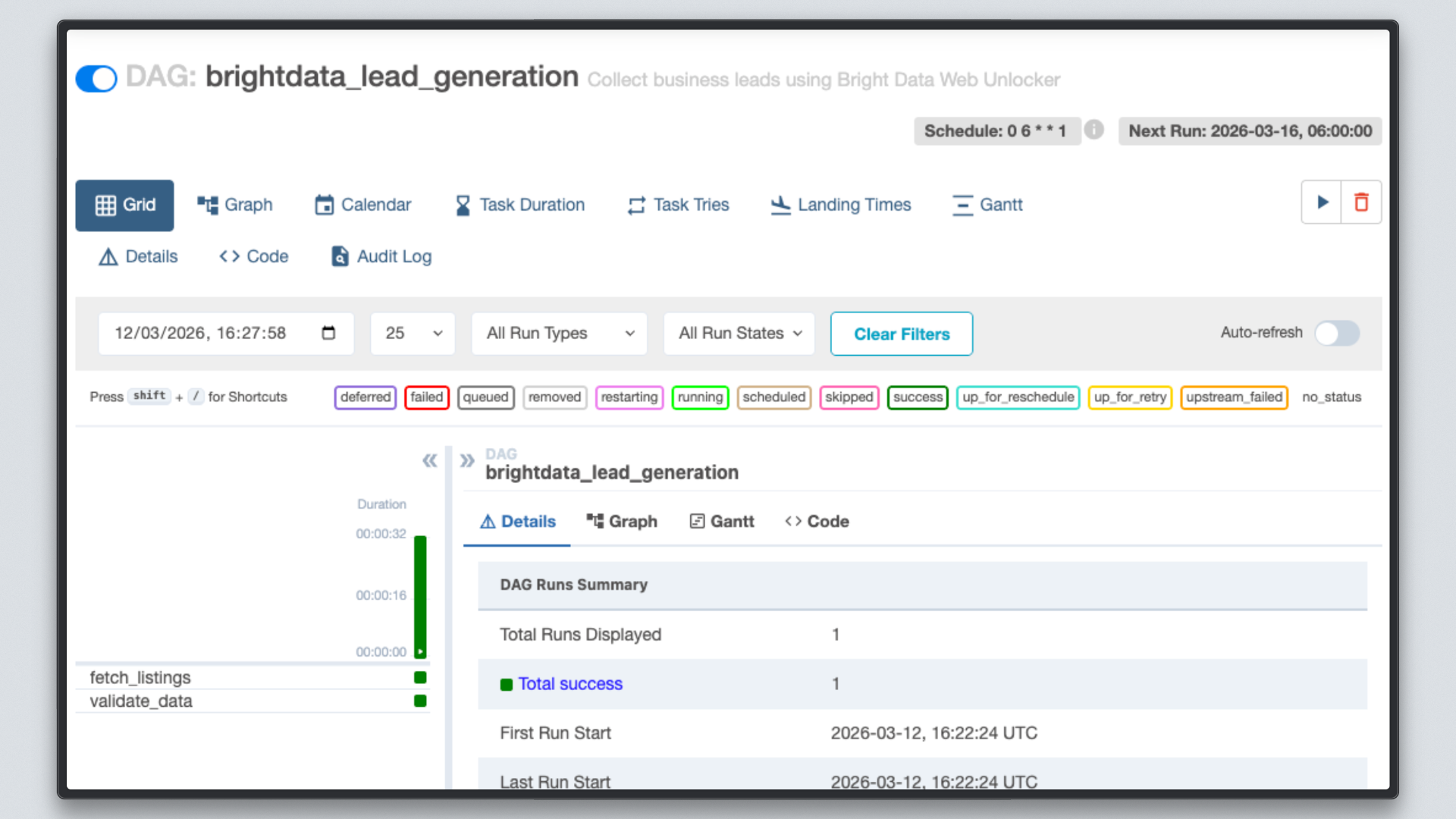
Schritt 7: Überprüfen Sie die Ergebnisse
Sobald beide Aufgaben grün angezeigt werden, überprüfen Sie die Ausgabedatei.
Docker-Benutzer:
docker compose exec --user airflow airflow-worker cat /tmp/brightdata_raw/leads.jsonUbuntu-Benutzer:
cat /tmp/brightdata_raw/leads.jsonSie sehen ein JSON-Array mit drei Einträgen, einen pro Ziel-URL:
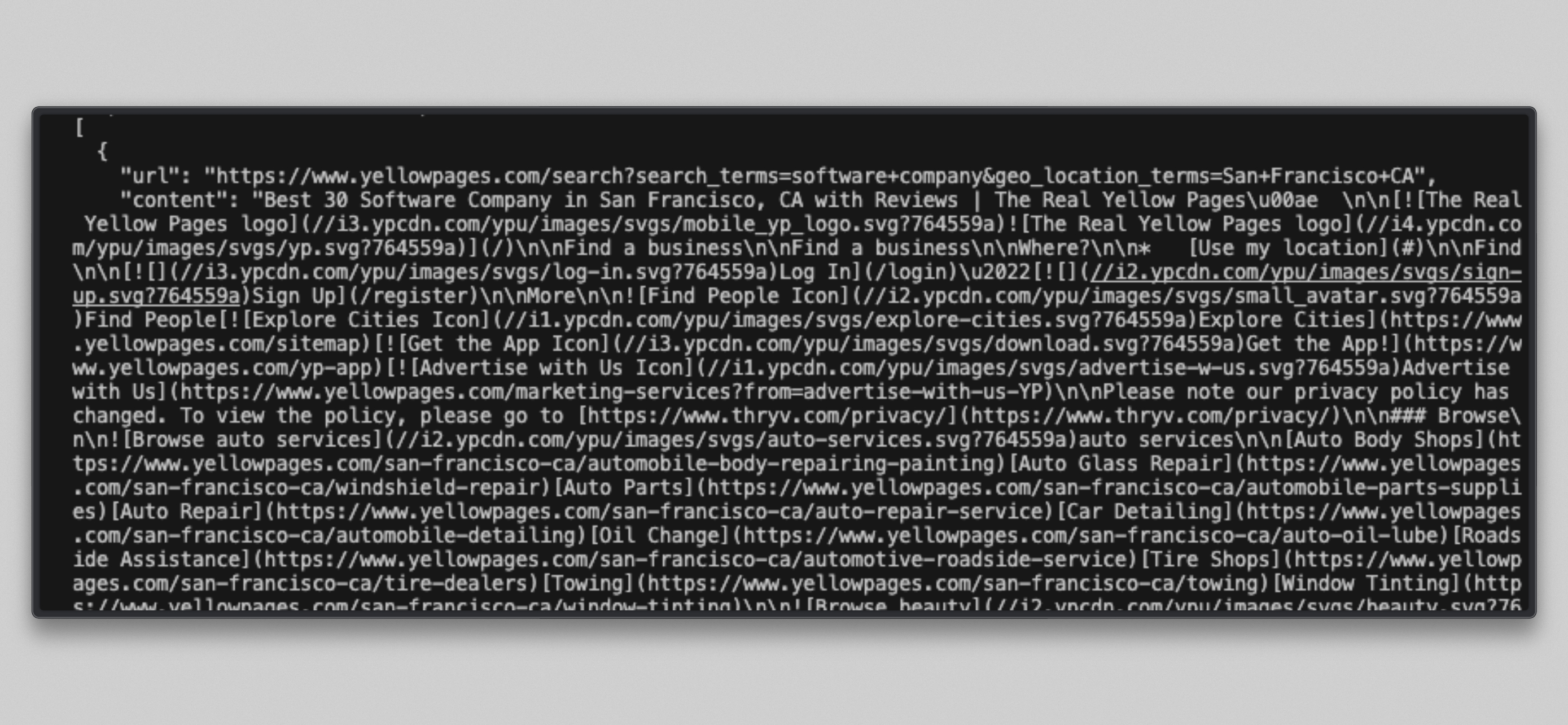
Hinweis: Einige Yellow-Pages-URLs geben möglicherweise die Meldung
„bad_endpoint“zurück, wenn die Website im Sofortzugriffsmodus von Bright Data eingeschränkt ist. Dies ist normal. Bright Data zeigt den Fehler in der Antwort an, anstatt stillschweigend zu scheitern. Wenden Sie sich an Ihren Bright-Data-Account Manager, wenn Sie vollen Zugriff auf eine eingeschränkte Website benötigen.
Führen Sie abschließend den Spark-Job für die Ausgabe aus:
docker compose exec --user airflow airflow-worker python /opt/airflow/spark_jobs/process_leads.py
/tmp/brightdata_raw/leads.json
/tmp/brightdata_processed/leadsDadurch werden bereinigte, bewertete Parquet-Dateien in /tmp/brightdata_processed/leads geschrieben, bereit zum Laden in PostgreSQL oder ein beliebiges nachgelagertes System.
Die Web Unlocker-API lieferte aktuelle Echtzeit-Inhalte aus den Gelben Seiten, und Ihre Pipeline bereinigte, bewertete und speicherte diese automatisch, ohne dass Sie auch nur eine einzige Zeile Code für das Web-Scraping oder die Proxy-Verwaltung schreiben mussten. Das manuelle Sammeln von Brancheneinträgen ist aufgrund von Bot-Erkennungssystemen und Ratenbeschränkungen bekanntermaßen schwierig. Durch die Verwendung von Bright Datas Web Unlocker können Sie Seiteninhalte zuverlässig von jeder öffentlichen Website in jeder Region abrufen, ohne dass Sie eine Infrastruktur warten müssen.
Weiterentwicklung
Diese Pipeline ist eine funktionierende Grundlage, die Sie in viele Richtungen erweitern können:
- Ersetzen Sie das lokale Dateisystem durch Amazon S3 oder Google Cloud Storage für die Zwischendatenebene, damit die Pipeline über verteilte Worker hinweg funktioniert.
- Fügen Sie zwischen der Spark-Verarbeitung und dem Laden der Datenbank einen LLM-Anreicherungsschritt hinzu, wobei Sie die OpenAI- oder Anthropic-API nutzen, um personalisierte Outreach-Zusammenfassungen für jeden vielversprechenden Lead zu generieren.
- Ersetzen Sie die lokale Ausgabe durch einen direkten CRM-Push an Salesforce, HubSpot oder Pipedrive unter Verwendung der vorhandenen Provider-Operatoren von Airflow.
- Fügen Sie eine Aufgabe zur Datenqualitätsprüfung mit Great Expectations oder Airflows SQLCheckOperator hinzu, um die Anzahl der Datensätze und die Vollständigkeit der Felder zu validieren, bevor die Daten übernommen werden.
Skalieren Sie den Spark-Job auf einen verwalteten Cluster unter Verwendung von AWS EMR, - Google Dataproc oder Databricks, indem Sie die Spark-Verbindungs-URL in Airflow aktualisieren; der DAG- und PySpark-Code bleibt unverändert.
- Verwenden Sie die SERP-API von Bright Data als parallele Erfassungsaufgabe, um jeden Lead mit aktuellen Nachrichten oder Daten zur Suchsichtbarkeit anzureichern.
Die Möglichkeiten sind nahezu unbegrenzt!
Fazit
In diesem Artikel haben Sie eine funktionierende Pipeline zur Lead-Generierung erstellt, indem Sie die Web Unlocker API von Bright Data, Apache Airflow und Apache Spark kombiniert haben.
Airflow übernimmt die Zeitplanung, die Wiederholungslogik, das Abhängigkeitsmanagement und die Beobachtbarkeit. Spark übernimmt die verteilte Bereinigung, Deduplizierung und Bewertung der rohen Geschäftsdaten. Bright Data übernimmt den schwierigsten Teil: das Sammeln aktueller Seiteninhalte aus dem Web, ohne dass Sie Proxys verwalten, Scraper-Code schreiben oder gegen Anti-Bot-Systeme kämpfen müssen.
Im Gegensatz zu No-Code-Automatisierungstools gibt Ihnen dieser Stack die volle Kontrolle über jede Ebene der Pipeline: Erfassungsparameter, Transformationslogik, Ausgabeschema und Zeitplan. Er lässt sich nahtlos in jede moderne Datenplattform integrieren und skaliert mit Ihrem Datenvolumen.
Um umfangreichere Pipelines zu erstellen, entdecken Sie die gesamte Palette der Datenerfassungstools von Bright Data, darunter die SERP-API für Suchdaten, den Web Unlocker für JavaScript-lastige Seiten und vorgefertigte Datensätze für gängige Anwendungsfälle.
Eröffnen Sie noch heuteein kostenloses Bright Data-Konto und beginnen Sie mit der Erfassung der Geschäftsdaten, die Ihre Pipeline benötigt.






