

Bright Data ist die umfassendste Web-Scraping-Plattform auf dem Markt. Sie kombiniert das größte kommerzielle Proxy-Netzwerk mit strukturierten Scraper-APIs und fertigen Datensätzen. Außerdem bietet sie einen Scraping-Browser, SERP-APIs und KI-Agenten-Integration. Zyte ist die ältere, Scrapy-native Alternative, die auf einer einzigen verwalteten Scraping-API basiert.
Zyte (ehemals Scrapinghub) hat Scrapy entwickelt, das Open-Source-Python-Framework. Das Unternehmen verkauft jetzt drei Produkte: Zyte API, Zyte Data und Scrapy Cloud. Wir haben beide Plattformen getestet und unabhängige Benchmark-Daten ausgewertet. Wir haben sie hinsichtlich Erfolgsquote, Preisgestaltung, Produkttiefe und Praxistauglichkeit verglichen. Bright Data gewinnt in jeder Kategorie bis auf einen einzigen Preisausnahmefall.
TL;DR: Bright Data vs. Zyte
Fazit: Bright Data ist für die meisten Teams die bessere Wahl. Es erzielt höhere Werte bei geschützten Websites, bietet deutlich mehr Produkte und hat eine vorhersehbare Preisgestaltung. Zyte eignet sich für Scrapy-native Teams, die einfache, ungeschützte Websites scrapen. Die folgenden Benchmark-Zahlen stammen aus dem unabhängigen 2026-Test von Scrape.do.
| Funktion | Bright Data | Zyte |
|---|---|---|
| Erfolgsquote | 98,87% | 91,43% |
| Produktumfang | Web Scraper APIs, Web Unlocker, Scraping-Browser, SERP-API, Proxys, Datensätze, MCP | Zyte API, Zyte Data, Scrapy Cloud |
| Proxy-Zugang | Direkt: Residential-, Datacenter-, ISP-Proxys in 195 Ländern | Keiner: intern durch Zyte API verwaltet |
| Vorgefertigte Datensätze | Ja, 100+ Domains | Nein |
| KI-Agenten-Integration | MCP-Server | Keine |
| Preismodell | Pauschal: 1,50 $/1.000 Datensätze | Gestaffelt nach Website-Schwierigkeit: 0,06 $ bis 16,08 $/1.000 |
| Kostenloser Tarif | 5.000 Datensätze/Monat, keine Kreditkarte | 5 $ Guthaben, Kreditkarte erforderlich |
| Am besten geeignet für | Zuverlässigkeit im großen Maßstab, Datensätze, Proxy-Kontrolle, KI-Agenten | Scrapy-native Teams bei einfachen Websites |
Erfolgsquote: Die Benchmark-Daten
Zuverlässigkeit ist beim Scraping das Wichtigste. Der 2026-Benchmark von Scrape.do hat beide Plattformen gegen sieben schwierige Ziele getestet. Darunter waren Amazon, Indeed, Zillow, Google und X. Bright Data erzielte 98,87% – der höchste Wert aller getesteten Anbieter. Zyte erzielte 91,43%.
Dieser Unterschied von 7 Prozentpunkten multipliziert sich im großen Maßstab. Bei 100.000 Anfragen ist das der Unterschied zwischen 1.130 und 8.570 Fehlern. Jeder Fehler bedeutet verschwendete Rechenkapazität und eine erneute Anfrage. Bei geschützten Websites ist Bright Data schlicht zuverlässiger.
Die Antwortzeiten lagen im Test nah beieinander, jeweils etwa 10 bis 11 Sekunden. Geschwindigkeit ist hier nicht das entscheidende Merkmal. Die Zuverlässigkeit bei schwierigen Zielen schon.
Preisgestaltung: Pauschaltarif vs. Schwierigkeitsstufen
Hier unterscheiden sich die Plattformen am stärksten in ihrer Philosophie. Bright Data berechnet einen einheitlichen Pauschaltarif. Zyte berechnet nach der Schwierigkeit der Zielwebsite.
Bright Data: Pauschaltarif-Preisgestaltung
Die Web Scraper API von Bright Data kostet bei Bezahlung pro Nutzung 1,50 $ pro 1.000 Datensätze. Sie zahlen nur für erfolgreiche Ergebnisse. Der kostenlose Tarif umfasst 5.000 Datensätze pro Monat ohne Kreditkarte. Der Scale-Plan kostet 499 $ pro Monat für 384.000 Datensätze.
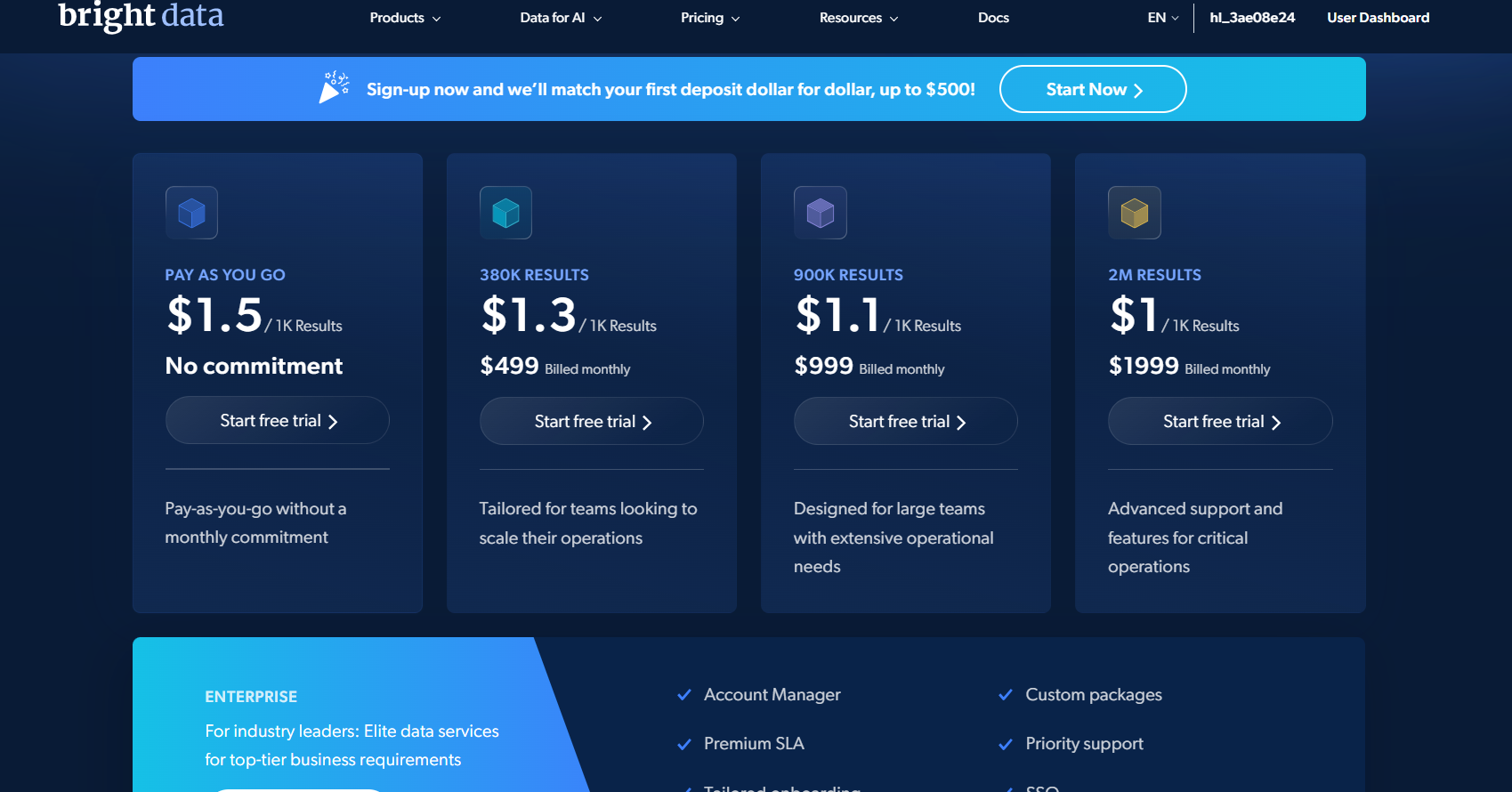
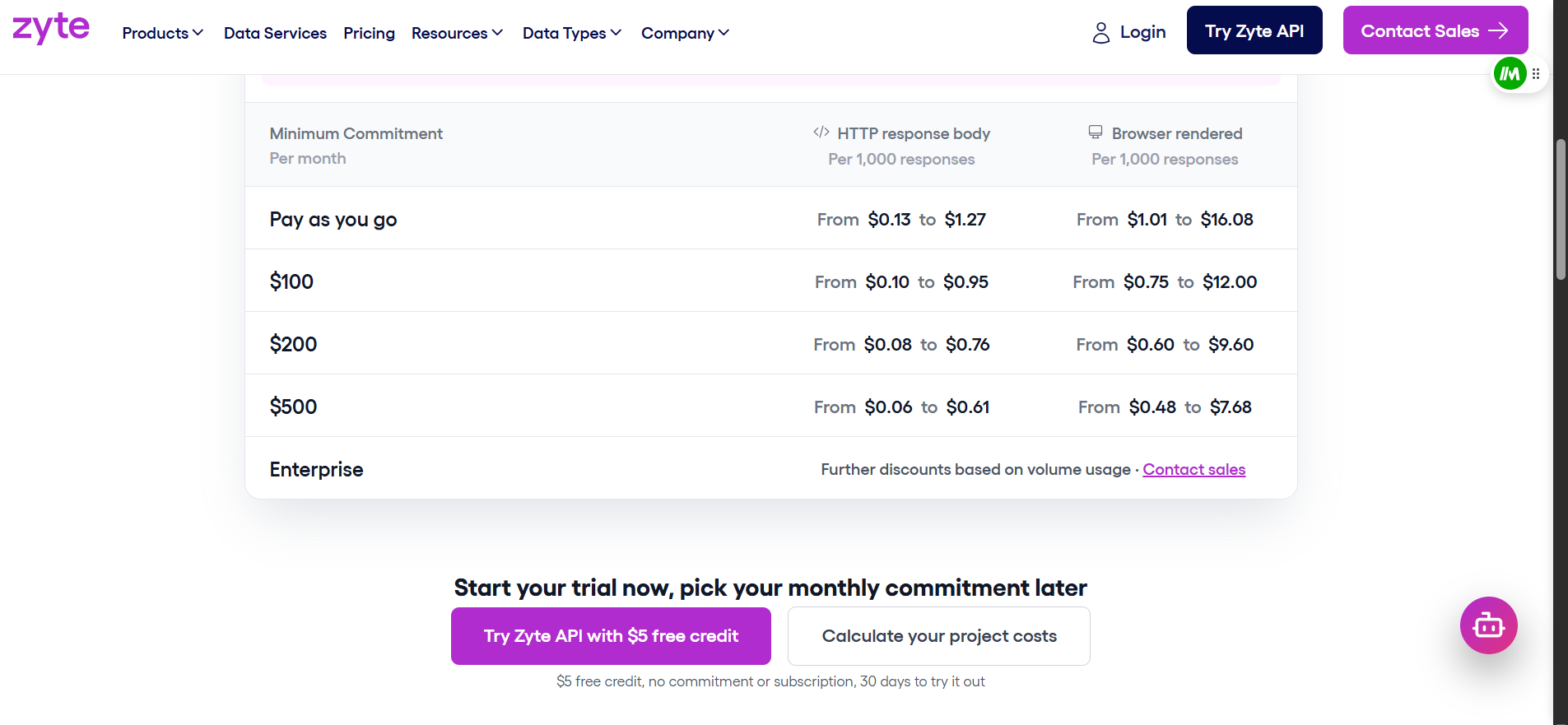
Zyte: fünf Schwierigkeitsstufen
Zyte ordnet jede Website in eine von fünf Schwierigkeitsstufen ein. HTTP-Anfragen kosten zwischen 0,06 $ und 1,27 $ pro 1.000. Browser-gerenderte Anfragen kosten zwischen 0,48 $ und 16,08 $ pro 1.000. Der genaue Preis hängt von der Stufe und Ihrem monatlichen Volumen ab.
Die Preisrechnung in der Praxis
Nehmen wir 100.000 Anfragen an eine schwierige Website mit Browser-Rendering. Bright Data kostet bei Bezahlung pro Nutzung 150 $. Zyte kostet bei einer mittleren Stufe 402 $ und bis zu 1.608 $ bei der schwierigsten Stufe.
Nehmen wir nun 100.000 Anfragen an eine einfache, reine HTTP-Website. Zyte kostet nur 13 $. Bright Data kostet nach wie vor 150 $. Zyte gewinnt bei trivialen Websites, aber solche brauchen selten eine kostenpflichtige Scraping-API.
Das tiefere Problem ist die Vorhersehbarkeit. Oft weiß man nicht, in welche Stufe eine Website fällt, bevor man sie scrapt. Die Budgetplanung wird schwierig, wenn Ziele verschiedene Stufen umfassen. Bright Datas Pauschaltarif eliminiert diese Variable vollständig.
Produkttiefe: Ein Full-Stack vs. eine API
Das ist Bright Datas größter struktureller Vorteil. Zyte bietet drei Produkte. Bright Data bietet einen vollständigen Dateninfrastruktur-Stack. Das Netzwerk umfasst 400M+ Residential-IPs, 1,300,000+ Datacenter-IPs und 1,300,000+ ISP-IPs in 195 Ländern.
Was Bright Data hat, das Zyte nicht hat
1. Vorgefertigte Datensätze. Bright Data pflegt gebrauchsfertige Datensätze für über 100 Domains. Dazu gehören LinkedIn, Amazon, Zillow und Google Maps. Sie fragen einen Datensatz mit Filtern ab und erhalten strukturierte Datensätze zurück. Kein Scraper, kein Crawl, kein Parsing.
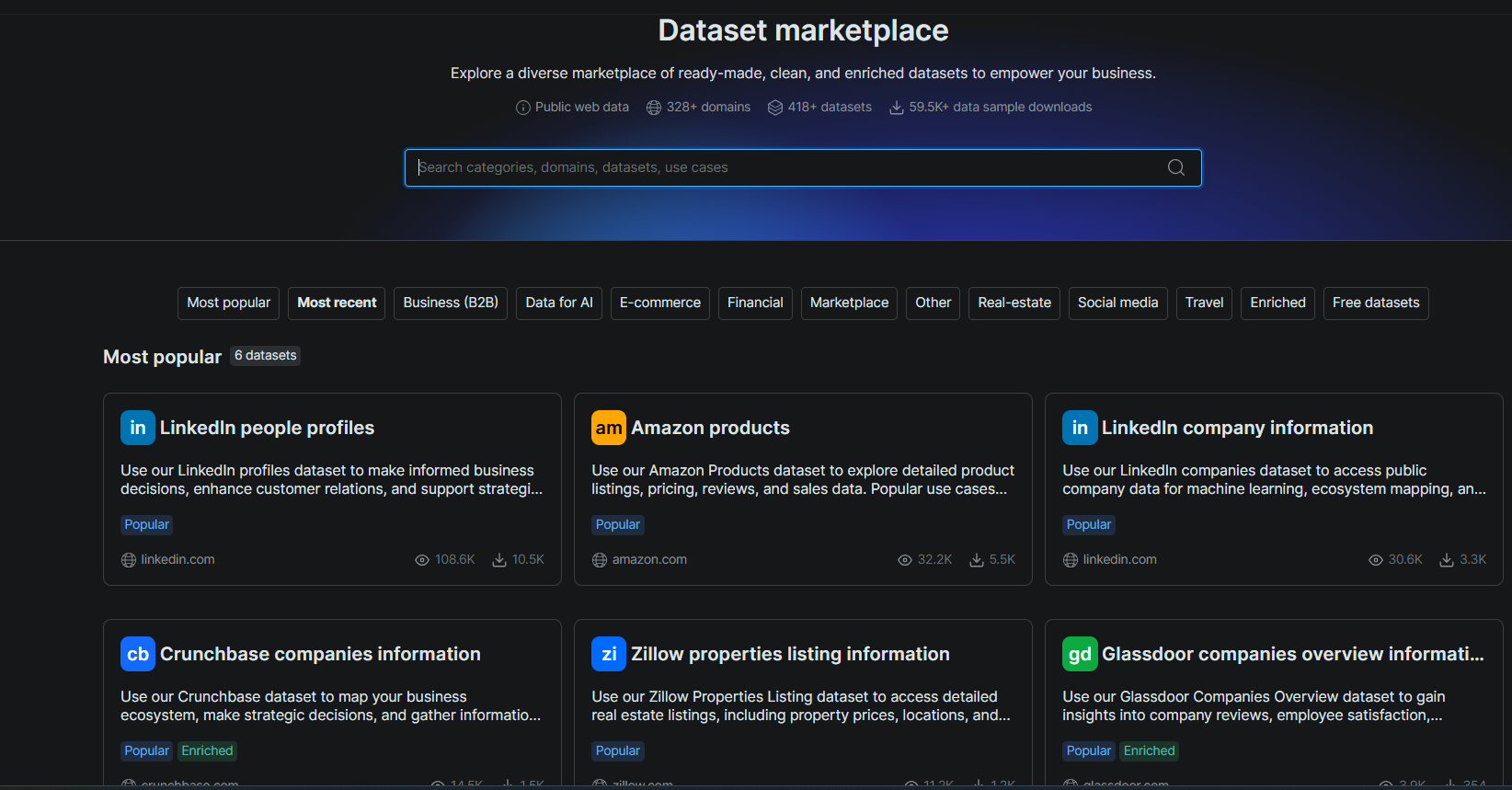
In unserem Test lieferte die Dataset Filter API 100 LinkedIn-Unternehmen in 46,5 Sekunden zurück. Jeder Datensatz enthielt Unternehmensdaten, Finanzierungshistorie und eine Crunchbase-URL. Zyte hat kein Äquivalent. Dieselbe Aufgabe bei Zyte bedeutet, einen eigenen Scraper zu entwickeln und zu pflegen.

2. Direkter Proxy-Zugang. Bright Data ermöglicht die direkte Nutzung seines Proxy-Netzwerks. Sie steuern Land, Stadt und ASN-Targeting. Zyte verwaltet Proxys intern, sodass Sie keine Kontrolle über Typ, Standort oder Rotation haben.
3. Scraping-Browser. Der Scraping-Browser verbindet Ihre bestehenden Playwright-, Puppeteer- oder Selenium-Skripte mit verwalteter Infrastruktur. Er übernimmt Proxy-Rotation, CAPTCHA-Lösung und Fingerprints. Bei Zyte müssen Sie diese Logik als API-Anfragen neu schreiben.
4. SERP-API. Die SERP-API liefert strukturierte Suchergebnisse von Google, Bing und mehr. Zyte hat kein dediziertes Suchprodukt.
5. MCP-Integration. Der MCP-Server gibt KI-Agenten native Web-Daten-Tools. Agenten, die mit LangChain, CrewAI oder LlamaIndex entwickelt wurden, können ihn direkt aufrufen. Zyte hat keine MCP-Integration.
Was Zyte hat, das Bright Data nicht hat
1. Scrapy Cloud. Zyte hat Scrapy entwickelt und betreibt den besten verwalteten Host für Scrapy-Spider. Er übernimmt Deployment, Scheduling und Monitoring ab 9 $ pro Einheit und Monat. Teams mit starkem Scrapy-Fokus finden hier eine natürliche Heimat.
2. KI-No-Code-Extraktion. Zyters KI liefert strukturierte Daten für unterstützte Seitentypen ohne Selektoren. Sie funktioniert gut für Produkte, Artikel und Stellenseiten. Bright Datas Scraper Studio deckt No-Code-Entwicklung ab, aber Zyters Zero-Config-Ansatz ist für diese Schemata reibungsloser.
3. Zyte Data. Zyte Data ist ein vollständig verwalteter Extraktionsdienst ab 500 $ pro Monat. Das Team entwickelt und pflegt die gesamte Pipeline für Sie. Bright Datas Datensätze sind Self-Service statt vollständig verwaltet.
Praxistest: Bright Data Web Scraper API
Bright Data liefert strukturiertes JSON direkt zurück. Sie senden eine URL und erhalten geparste Felder zurück, ohne HTML verarbeiten zu müssen:
import requests
response = requests.post(
"https://api.brightdata.com/datasets/v3/scrape",
params={"dataset_id": "gd_l7q7dkf244hwjntr0", "format": "json"},
headers={"Authorization": "Bearer YOUR_API_TOKEN"},
json=[{"url": "https://www.amazon.com/dp/B0D1XD1ZV3"}],
)
product = response.json()
Damit wurden Produkttitel, Preis, Bewertung, Rezensionsanzahl und Verfügbarkeit zurückgegeben. Die Ausgabe war sauberes strukturiertes JSON, sofort verwendbar.
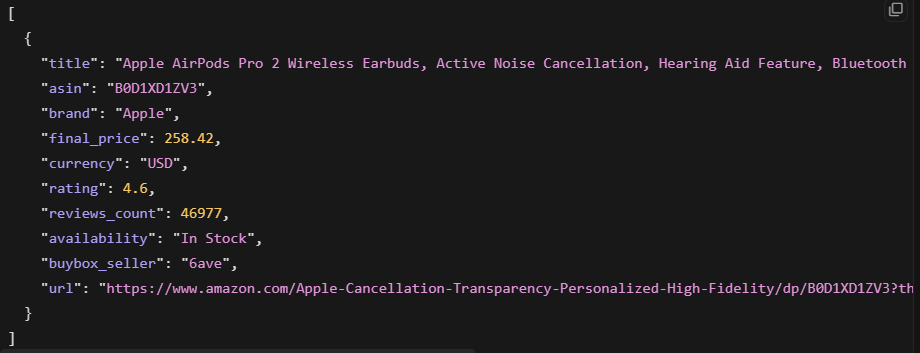
Für Websites ohne vorgefertigten Scraper liefert der Web Unlocker entsperrtes HTML zur eigenen Verarbeitung:
response = requests.post(
"https://api.brightdata.com/request",
headers={"Authorization": "Bearer YOUR_API_TOKEN"},
json={"zone": "YOUR_ZONE_NAME", "url": "https://example.com/page", "format": "json"},
)
html = response.json().get("body", "")
Der Web Unlocker übernimmt Proxy-Auswahl, CAPTCHA-Lösung und Wiederholungsversuche. Sie behalten die Kontrolle über Proxy-Typ und geografisches Targeting.
Praxistest: Wie die Zyte API funktioniert
Die Zyte API liefert rohen oder browser-gerenderten HTML zurück, und Sie übernehmen das Parsing:
import requests
response = requests.post(
"https://api.zyte.com/v1/extract",
auth=("YOUR_ZYTE_API_KEY", ""),
json={"url": "https://books.toscrape.com/", "browserHtml": True},
)
html = response.json().get("browserHtml")
Zyters KI-Extraktion fügt strukturierte Ausgabe für unterstützte Schemata hinzu. Sie setzen ein Flag und überspringen die Selektoren:
response = requests.post(
"https://api.zyte.com/v1/extract",
auth=("YOUR_ZYTE_API_KEY", ""),
json={"url": "https://books.toscrape.com/", "product": True},
)
product = response.json().get("product")
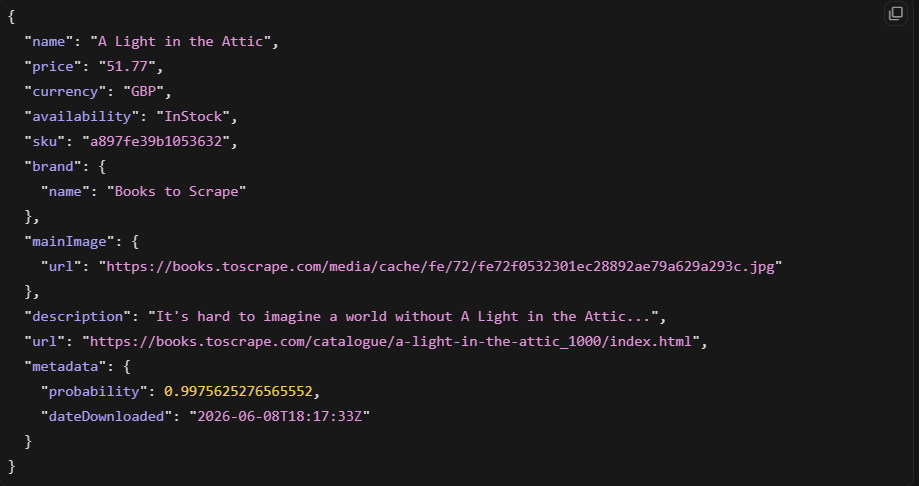
In unserem Test wurde damit ein sauberes Produktobjekt zurückgegeben. Die KI-Extraktion ist für unterstützte Seitentypen wirklich nützlich. Der Nachteil ist, dass sie nur dort funktioniert, wo Zyte Modelle trainiert hat.
Wann welche Plattform wählen
- Wählen Sie Bright Data für hohe Erfolgsquoten, vorgefertigte Datensätze, Proxy-Kontrolle, KI-Agenten und vorhersehbare Preisgestaltung
- Wählen Sie Zyte, wenn Ihr Team auf Scrapy aufgebaut ist und hauptsächlich einfache, ungeschützte Websites scrapt
- Nutzen Sie beide, wenn Sie Scrapy-Spider auf Scrapy Cloud betreiben, aber Bright Data für schwierige Ziele benötigen
Fazit
Zyte ist eine leistungsfähige Plattform für Scrapy-native Teams bei einfachen Websites. Der Unterschied zeigt sich, wenn die Arbeit anspruchsvoller wird. Bright Data erzielt höhere Werte bei geschützten Websites, bietet deutlich mehr Produkte und hat eine transparente Preisgestaltung.
Für zuverlässige Daten im großen Maßstab ist Bright Data das stärkere und breitere Fundament. Es ist durch ISO 27001-Zertifizierung sowie GDPR- und CCPA-Konformität abgesichert. Details finden Sie im Trust Center. Sie können auch unseren Vergleich Bright Data vs. Apollo lesen.
Starten Sie noch heute Ihren kostenlosen Test und testen Sie Bright Data an Ihren schwierigsten Zielen.
Häufig gestellte Fragen
Ist Bright Data oder Zyte besser für Web-Scraping?
Bright Data ist für die meisten Teams besser. Im 2026-Benchmark von Scrape.do erzielte es 98,87% gegenüber Zyters 91,43%. Es bietet außerdem deutlich mehr Produkte. Zyte eignet sich für Scrapy-native Teams, die einfache Websites scrapen.
Wie unterscheiden sich die Preise von Bright Data und Zyte?
Bright Data berechnet einen Pauschaltarif von 1,50 $ pro 1.000 Datensätze mit 5.000 kostenlosen pro Monat. Zyte berechnet nach Website-Schwierigkeit, von 0,06 $ bis 16,08 $ pro 1.000 Anfragen. Bright Datas Preisgestaltung ist vorhersehbarer.
Hat Zyte vorgefertigte Datensätze wie Bright Data?
Nein. Bright Data bietet gebrauchsfertige Datensätze für über 100 Domains, darunter LinkedIn und Amazon. Zyte hat kein Äquivalent. Sie müssten diese Scraper selbst entwickeln und pflegen.
Kann ich meinen bestehenden Scrapy- oder Playwright-Code verwenden?
Zyte betreibt Scrapy Cloud, den besten verwalteten Host für Scrapy-Spider. Bright Datas Scraping-Browser verbindet bestehende Playwright-, Puppeteer- und Selenium-Skripte mit seiner Infrastruktur.
Was soll ich wählen, Bright Data oder Zyte?
Wählen Sie Bright Data für Zuverlässigkeit im großen Maßstab, Datensätze, Proxy-Kontrolle und KI-Agenten. Wählen Sie Zyte, wenn Ihr Team Scrapy-native ist und hauptsächlich einfache, ungeschützte Websites scrapt.





