

In diesem Leitfaden erfahren Sie mehr:
- Was LlamaIndex ist.
- Warum KI-Agenten, die mit LlamaIndex entwickelt wurden, in der Lage sein sollten, Websuchen durchzuführen.
- Wie man einen LlamaIndex-KI-Agenten mit Websuchfunktionen erstellt.
Lasst uns eintauchen!
Was ist LlamaIndex?
LlamaIndex ist ein quelloffenes Python-Framework zur Erstellung von Anwendungen, die auf LLMs basieren. Es dient als Brücke zwischen unstrukturierten Daten und LLMs. Insbesondere macht es die Orchestrierung von LLM-Workflows über eine Vielzahl von Datenquellen einfach.
Mit LlamaIndex können Sie produktionsreife KI-Workflows und Agenten erstellen. Diese können nach relevanten Informationen suchen und diese abrufen, Erkenntnisse synthetisieren, detaillierte Berichte erstellen, automatisierte Aktionen durchführen und vieles mehr.
Zum Zeitpunkt der Erstellung dieses Artikels ist sie eine der am schnellsten wachsenden Bibliotheken im KI-Ökosystem, mit über 42k Sternen auf GitHub.
Warum sollten Sie Web-Suchdaten in Ihren LlamaIndex AI Agent integrieren?
Im Vergleich zu anderen KI-Agenten-Frameworks wurde LlamaIndex entwickelt, um eine der größten Einschränkungen von LLMs zu lösen. Das ist ihr Mangel an aktuellem, realitätsnahem Wissen.
Um dieses Problem zu lösen, bietet LlamaIndex Integrationen mit verschiedenen Datenkonnektoren, mit denen Sie Inhalte aus verschiedenen Quellen aufnehmen können. Nun fragen Sie sich vielleicht: Welche ist die wertvollste Datenquelle für einen KI-Agenten?
Um diese Frage zu beantworten, ist es hilfreich, sich anzusehen, welche Datenquellen für die Ausbildung von LLMs verwendet werden. Erfolgreiche LLMs erhielten die meisten ihrer Trainingsdaten aus dem Internet, der größten und vielfältigsten Quelle für öffentliche Daten.
Wenn Sie möchten, dass Ihr LlamaIndex-KI-Agent über seine statischen Trainingsdaten hinausgeht, ist die Schlüsselfähigkeit, die er benötigt, die Fähigkeit, das Web zu durchsuchen und aus dem, was er findet, zu lernen. Ihr Agent sollte also in der Lage sein, strukturierte Informationen aus den resultierenden Suchergebnissen (den sogenanntenSERPs) zu extrahieren. Dann sollte er sie sinnvoll verarbeiten und daraus lernen.
Die Herausforderung besteht darin, dass SERP-Scraping aufgrund des jüngsten Vorgehens von Google gegen einfache Scraping-Skripte viel schwieriger geworden ist. Aus diesem Grund benötigen Sie ein Tool, das sich in LlamaIndex integriert und diesen Prozess vereinfacht. Hier kommt die Bright Data-Integration von LlamaIndex ins Spiel!
Bright Data übernimmt die komplexe Arbeit des SERP Scraping. Mit seinem search_engine-Tool kann Ihr LlamaIndex-Agent Suchanfragen durchführen und strukturierte Ergebnisse im Markdown- oder JSON-Format erhalten.
Das ist es, was Ihr KI-Agent braucht, um auf Fragen vorbereitet zu sein, sowohl jetzt als auch in Zukunft. Sehen Sie im nächsten Kapitel, wie diese Integration funktioniert!
Erstellen eines LlamaIndex-Agenten, der das Web mit Hilfe von Bright Data Tools durchsuchen kann
In dieser Schritt-für-Schritt-Anleitung sehen Sie, wie Sie mit LlamaIndex einen Python-KI-Agenten erstellen, der das Web durchsuchen kann.
Durch die Integration mit Bright Data ermöglichen Sie Ihrem Agenten den Zugriff auf frische, kontextbezogene, reichhaltige Websuchdaten. Weitere Einzelheiten finden Sie in unserer offiziellen Dokumentation.
Führen Sie die folgenden Schritte aus, um mit LlamaIndex Ihren Bright Data-gestützten KI-SERP-Agenten zu erstellen!
Voraussetzungen
Um diesem Tutorial folgen zu können, benötigen Sie Folgendes:
- Python 3.9 oder höher muss auf Ihrem Rechner installiert sein (wir empfehlen die Verwendung der neuesten Version).
- Ein Bright Data-API-Schlüssel zur Integration in die SERP-APIs von Bright Data.
- Ein API-Schlüssel von einem unterstützten LLM. (In diesem Leitfaden verwenden wir Gemini, das die Integration über API kostenlos unterstützt. Sie können aber auch jeden anderen LLM-Anbieter verwenden , der von LlamaIndex unterstützt wird).
Machen Sie sich keine Sorgen, wenn Sie noch keinen Gemini- oder Bright Data-API-Schlüssel haben. Wir zeigen Ihnen in den nächsten Schritten, wie Sie beide erstellen können.
Schritt #1: Initialisieren Sie Ihr Python-Projekt
Starten Sie zunächst Ihr Terminal und erstellen Sie einen neuen Ordner für Ihr LlamaIndex AI Agent Projekt:
mkdir llamaindex-bright-data-serp-agentllamaindex-bright-data-serp-agent/ enthält den gesamten Code für Ihren KI-Agenten mit Websuchfunktionen, die von Bright Data unterstützt werden.
Navigieren Sie anschließend in das Projektverzeichnis und erstellen Sie darin eine virtuelle Python-Umgebung:
cd llamaindex-bright-data-serp-agent
python -m venv venvÖffnen Sie nun den Projektordner in Ihrer bevorzugten Python-IDE. Wir empfehlen Visual Studio Code mit der Python-Erweiterung oder PyCharm Community Edition.
Erstellen Sie eine neue Datei namens agent.py im Stammverzeichnis Ihres Projekts. Die Struktur Ihres Projekts sollte wie folgt aussehen:
llamaindex-bright-data-serp-agent/
├── venv/
└── agent.pyAktivieren Sie im Terminal die virtuelle Umgebung. Unter Linux oder macOS führen Sie aus:
source venv/bin/activateUnter Windows führen Sie entsprechend aus:
venv/Scripts/activateIn den nächsten Schritten werden Sie durch die Installation der erforderlichen Pakete geführt. Wenn Sie jedoch alles im Voraus installieren möchten, führen Sie aus:
pip install python-dotenv llama-index-tools-brightdata llama-index-llms-google-genai llama-indexHinweis: Wir installieren llama-index-llms-google-genai, weil dieses Tutorial Gemini als LlamaIndex LLM-Anbieter verwendet. Wenn Sie einen anderen Anbieter verwenden möchten, müssen Sie stattdessen die entsprechende LLM-Integration installieren.
Gut gemacht! Ihre Python-Entwicklungsumgebung ist bereit für die Erstellung eines KI-Agenten mit der SERP-Integration von Bright Data unter Verwendung von LlamaIndex.
Schritt #2: Umgebungsvariablen einbinden Lesen
Ihr LlamaIndex-Agent stellt über die API eine Verbindung zu externen Diensten wie Gemini und Bright Data her. Aus Sicherheitsgründen sollten Sie API-Schlüssel niemals direkt in Ihren Python-Code codieren. Verwenden Sie stattdessen Umgebungsvariablen, um sie geheim zu halten.
Installieren Sie die Bibliothek python-dotenv, um die Verwaltung von Umgebungsvariablen zu erleichtern. Starten Sie in Ihrer aktivierten virtuellen Umgebung:
pip install python-dotenvAls nächstes öffnen Sie Ihre agent.py-Datei und fügen Sie die folgenden Zeilen am Anfang ein, um envs aus einer .env-Datei zu laden:
from dotenv import load_dotenv
load_dotenv()load_dotenv() sucht nach einer .env-Datei im Hauptverzeichnis Ihres Projekts und lädt deren Werte in die Umgebung.
Erstellen Sie nun eine .env-Datei neben Ihrer agent.py-Datei. Die Struktur Ihrer neuen Projektdatei sollte wie folgt aussehen:
llamaindex-bright-data-serp-agent/
├── venv/
├── .env # <-------------
└── agent.pyFantastisch! Sie haben soeben eine sichere Methode zur Verwaltung sensibler API-Anmeldedaten für Dienste von Drittanbietern eingerichtet.
Setzen Sie die Ersteinrichtung fort, indem Sie Ihre .env-Datei mit den erforderlichen Umgebungsvariablen füllen!
Schritt 3: Konfigurieren Sie Bright Data
Um eine Verbindung zu den Bright Data SERP APIs in LlamaIndex über das offizielle Integrationspaket herzustellen, müssen Sie zunächst eine Verbindung herstellen:
- Aktivieren Sie die Web Unlocker Lösung in Ihrem Bright Data Dashboard.
- Rufen Sie Ihr Bright Data-API-Token ab.
Folgen Sie den nachstehenden Schritten, um die Einrichtung abzuschließen!
Wenn Sie noch kein Bright Data-Konto haben, [erstellen Sie eines](). Wenn Sie bereits ein Konto haben, melden Sie sich an. Klicken Sie im Dashboard auf die Schaltfläche “Proxy-Produkte abrufen”:
Sie werden zur Seite “Proxies & Scraping Infrastructure” weitergeleitet:
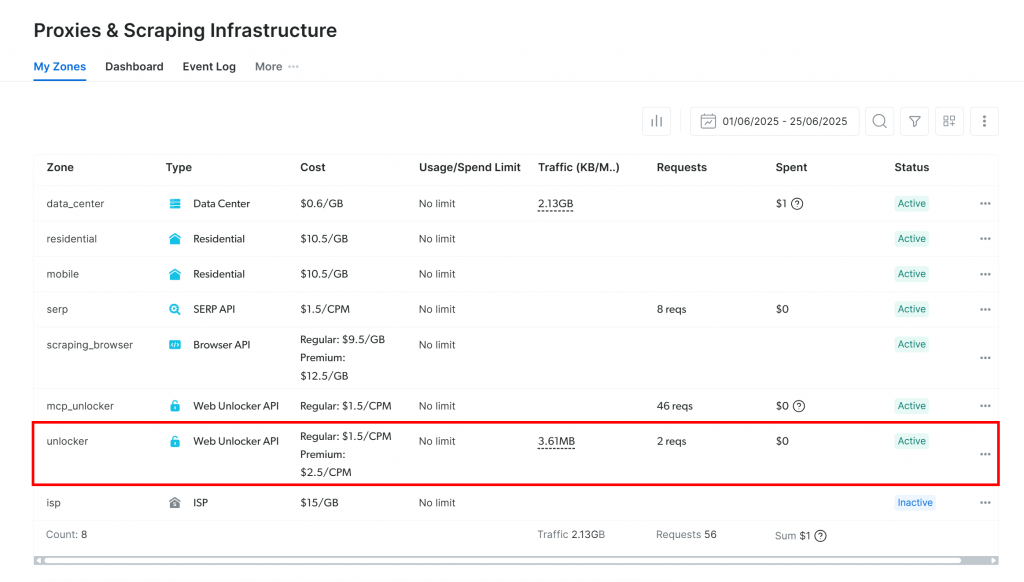
Wenn Sie bereits eine aktive Web Unlocker API-Zone sehen (wie im Bild oben), sind Sie bereit. Notieren Sie sich den Zonennamen (z. B. unlocker), da Sie ihn später in Ihrem Code verwenden werden.
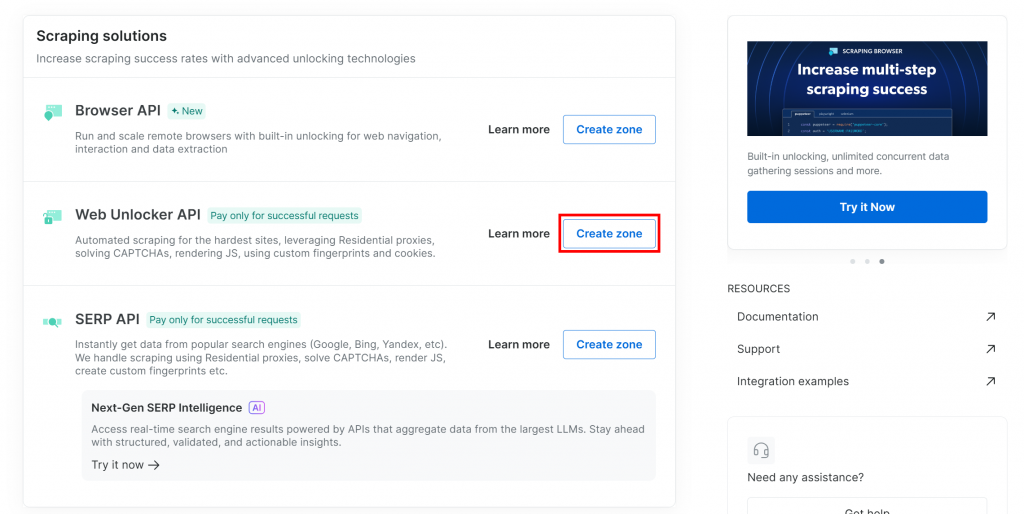
Wenn Sie noch keine Web Unlocker Zone haben, scrollen Sie nach unten zum Abschnitt “Web Unlocker API” und drücken Sie die Schaltfläche “Zone erstellen”:
Warum die Web Unlocker API anstelle der speziellen SERP API verwenden?
Die LlamaIndex-SERP-Integration von Bright Data funktioniert über die Web Unlocker-API. Wenn sie richtig konfiguriert ist, funktioniert Web Unlocker auf die gleiche Weise wie die dedizierten SERP-APIs. Kurz gesagt, wenn Sie eine Web Unlocker API-Zone mit der LlamaIndex Bright Data-Integration einrichten, erhalten Sie automatisch auch Zugriff auf die SERP-APIs.
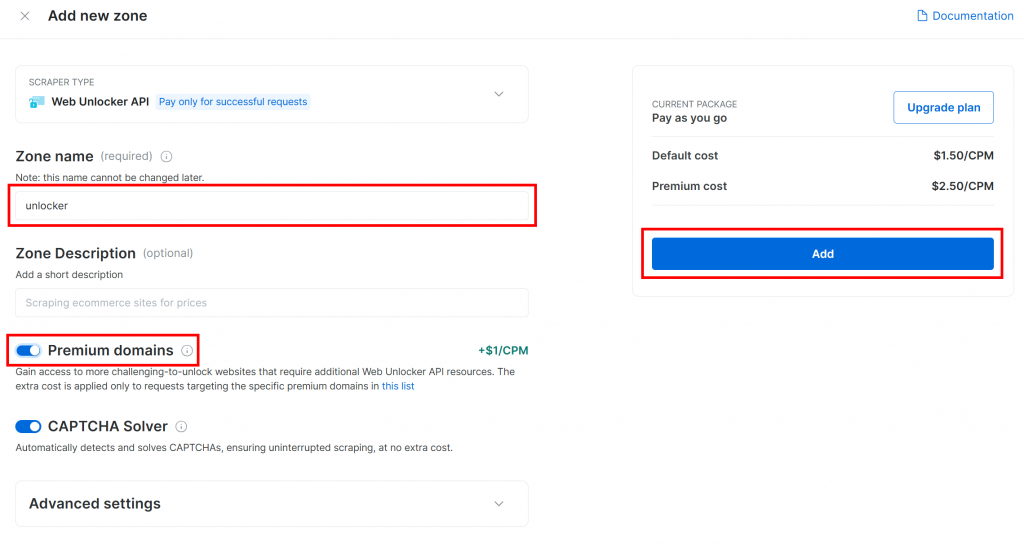
Geben Sie Ihrer neuen Zone einen Namen, z. B. unlocker, aktivieren Sie alle erweiterten Funktionen für eine bessere Leistung, und klicken Sie auf “Hinzufügen”:
Nach der Erstellung werden Sie zur Konfigurationsseite der Zone weitergeleitet:
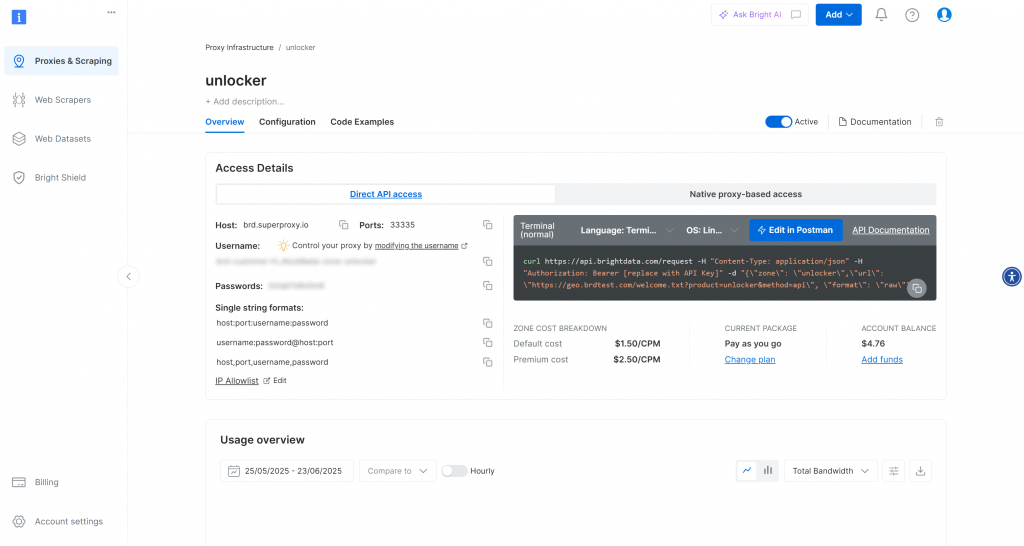
Vergewissern Sie sich, dass der Aktivierungsschalter auf den Status “Aktiv” eingestellt ist. Dies bestätigt, dass Ihre Zone einsatzbereit ist.
Folgen Sie anschließend der offiziellen Bright Data-Anleitung, um Ihren API-Schlüssel zu generieren. Sobald Sie Ihren Schlüssel haben, speichern Sie ihn sicher in Ihrer .env-Datei wie folgt:
BRIGHT_DATA_API_KEY="<YOUR_BRIGHT_DATA_API_KEY>"Ersetzen Sie den Platzhalter durch Ihren tatsächlichen API-Schlüsselwert.
Großartig! Konfigurieren Sie das Bright Data SERP-Tool in Ihrem LlamaIndex-Agentenskript.
Schritt #4: Zugriff auf das Bright Data LlamaIndex SERP Tool
Laden Sie in agent.py zunächst Ihren Bright Data-API-Schlüssel aus der Umgebung:
BRIGHT_DATA_API_KEY = os.getenv("BRIGHT_DATA_API_KEY")Stellen Sie sicher, dass Sie os aus der Python-Standardbibliothek importieren:
import osInstallieren Sie in Ihrer aktivierten virtuellen Umgebung das LlamaIndex Bright Data Tools-Paket:
pip install llama-index-tools-brightdataImportieren Sie als Nächstes die BrightDataToolSpec-Klasse in Ihre agent.py-Datei:
from llama_index.tools.brightdata import BrightDataToolSpecErstellen Sie eine Instanz von BrightDataToolSpec, indem Sie Ihren API-Schlüssel und den Namen der Web Unlocker-Zone angeben:
brightdata_tool_spec = BrightDataToolSpec(
api_key=BRIGHT_DATA_API_KEY,
zone="unlocker", # Replace with the name of your Web Unlocker zone
verbose=True,
)Ersetzen Sie den Zonenwert durch den Namen der Web Unlocker API-Zone, die Sie zuvor eingerichtet haben (in diesem Fall ist es unlocker).
Beachten Sie, dass die Einstellung verbose=True bei der Entwicklung nützlich ist. Auf diese Weise gibt die Bibliothek hilfreiche Protokolle aus, wenn Ihr LlamaIndex-Agent Anfragen über Bright Data stellt.
BrightDataToolSpec bietet mehrere Tools, aber hier konzentrieren wir uns auf das Tool search_engine. Dieses Tool kann Google, Bing, Yandex und andere abfragen und Ergebnisse in Markdown oder JSON zurückgeben.
Um genau dieses Werkzeug zu extrahieren, schreiben Sie:
brightdata_serp_tools = brightdata_tool_spec.to_tool_list(["search_engine"])Das an to_tool_list() übergebene Array dient als Filter, der nur das Werkzeug namens search_engine einschließt.
Hinweis: Standardmäßig wählt LlamaIndex das am besten geeignete Werkzeug für eine bestimmte Benutzeranfrage aus. Eine Filterung der Tools ist daher nicht unbedingt erforderlich. Da es in diesem Lernprogramm speziell um die Integration der SERP-Funktionen von Bright Data geht, ist es sinnvoll, sich aus Gründen der Übersichtlichkeit auf das Tool search_engine zu beschränken.
Großartig! Bright Data ist jetzt integriert und bereit, Ihren LlamaIndex-Agenten mit Web-Suchfunktionen auszustatten.
Schritt #5: Verbinden Sie ein LLM-Modell
Die Anweisungen in diesem Schritt verwenden Gemini als LLM-Anbieter für diese Integration. Ein guter Grund für die Wahl von Gemini ist, dass es kostenlosen API-Zugang zu einigen seiner Modelle bietet.
Um mit Gemini in LlamaIndex zu beginnen, installieren Sie das erforderliche Integrationspaket:
pip install llama-index-llms-google-genaiAls nächstes importieren Sie die GoogleGenAI-Klasse in agent.py:
from llama_index.llms.google_genai import GoogleGenAINun initialisieren Sie den Gemini LLM wie folgt:
llm = GoogleGenAI(
model="models/gemini-2.5-flash",
)In diesem Beispiel verwenden wir das Modell gemini-2.5flash. Sie können aber auch jedes andere unterstützte Gemini-Modell wählen.
Hinter den Kulissen sucht die GoogleGenAI-Klasse automatisch nach einer Umgebungsvariablen namens GEMINI_API_KEY. Sie verwendet den aus dieser Umgebungsvariable gelesenen API-Schlüssel, um eine Verbindung zu den Gemini-APIs herzustellen.
Konfigurieren Sie es, indem Sie Ihre .env-Datei öffnen und hinzufügen:
GEMINI_API_KEY="<YOUR_GEMINI_API_KEY>"Ersetzen Sie den Platzhalter durch Ihren tatsächlichen Gemini-API-Schlüssel. Wenn Sie noch keinen haben, können Sie ihn kostenlos erhalten, indem Sie die offizielle Gemini-API-Abfrageanleitung befolgen.
Hinweis: Wenn Sie einen anderen LLM-Anbieter verwenden möchten, unterstützt LlamaIndex viele Optionen. Schauen Sie einfach in die offiziellen LlamaIndex-Dokumente für Anweisungen zur Einrichtung.
Gut gemacht! Sie haben nun alle wichtigen Teile für den Aufbau eines LlamaIndex-KI-Agenten, der das Internet durchsuchen kann, beisammen.
Schritt #6: Definieren Sie den LlamaIndex Agent
Installieren Sie zunächst das Hauptpaket von LlamaIndex:
pip install llama-indexAls nächstes importieren Sie in Ihrer agent.py-Datei die Klasse FunctionAgent:
from llama_index.core.agent.workflow import FunctionAgentFunctionAgent ist ein spezialisierter LlamaIndex-KI-Agent, der mit externen Tools interagieren kann, wie z. B. dem Bright Data SERP-Tool, das Sie zuvor eingerichtet haben.
Initialisieren Sie den Agenten mit Ihrem LLM und dem SERP-Tool von Bright Data wie folgt:
agent = FunctionAgent(
tools=brightdata_serp_tools,
llm=llm,
verbose=True, # Useful while developing
system_prompt="""
You are a helpful assistant that can retrieve SERP results in JSON format.
"""
)Dadurch wird ein KI-Agent erstellt, der Benutzereingaben über Ihr LLM verarbeitet und bei Bedarf die SERP-Tools von Bright Data aufrufen kann, um Websuchen in Echtzeit durchzuführen. Beachten Sie das Argument system_prompt, das die Rolle und das Verhalten des Agenten definiert. Auch hier ist das verbose=True-Flag nützlich, um die internen Aktivitäten zu überprüfen.
Wunderbar! Die Integration von LlamaIndex und Bright Data SERP ist abgeschlossen. Der nächste Schritt ist die Implementierung der REPL für die interaktive Nutzung.
Schritt #7: Erstellen der REPL
REPL, die Abkürzung für “Read-Eval-Print Loop“, ist ein interaktives Programmiermuster, bei dem Sie Befehle eingeben, sie auswerten lassen und die Ergebnisse sehen.
In diesem Zusammenhang funktioniert die REPL wie folgt:
- Sie beschreiben die Aufgabe, die der KI-Agent erledigen soll.
- Der KI-Agent übernimmt die Aufgabe und führt bei Bedarf Online-Recherchen durch.
- Sie sehen die Antwort im Terminal ausgedruckt.
Diese Schleife läuft so lange, bis Sie "exit" eingeben.
Fügen Sie in agent.py diese asynchrone Funktion hinzu, um die REPL-Logik zu behandeln:
async def main():
print("Gemini-based agent with web searching capabilities powered by Bright Data. Type 'exit' to quit.n")
while True:
# Read the user request for the AI agent from the CLI
request = input("Request -> ")
# Terminate the execution if the user type "exit"
if request.strip().lower() == "exit":
print("nAgent terminated")
break
try:
# Execute the request
response = await agent.run(request)
print(f"nResponse ->:n{response}n")
except Exception as e:
print(f"nError: {str(e)}n")Diese REPL-Funktion:
- Akzeptiert Benutzereingaben von der Kommandozeile über
input(). - Verarbeitet die Eingabe mit dem LlamaIndex-Agenten, der von Gemini und Bright Data durch
agent.run()unterstützt wird. - Zeigt die Antwort auf der Konsole an.
Da agent.run() asynchron ist, muss die REPL-Logik innerhalb einer asynchronen Funktion stehen. Führen Sie sie wie folgt am Ende Ihrer Datei aus:
if __name__ == "__main__":
asyncio.run(main())Vergessen Sie nicht, asyncio zu importieren:
import asyncioJetzt geht’s los! Der LlamaIndex AI-Agent mit SERP-Scraping-Tools ist fertig.
Schritt Nr. 8: Alles zusammenfügen und den KI-Agenten ausführen
Dies sollte Ihre agent.py-Datei enthalten:
from dotenv import load_dotenv
import os
from llama_index.tools.brightdata import BrightDataToolSpec
from llama_index.llms.google_genai import GoogleGenAI
from llama_index.core.agent.workflow import FunctionAgent
import asyncio
# Load environment variables from the .env file
load_dotenv()
# Read the Bright Data API key from the envs
BRIGHT_DATA_API_KEY = os.getenv("BRIGHT_DATA_API_KEY")
# Set up the Bright Data Tools
brightdata_tool_spec = BrightDataToolSpec(
api_key=BRIGHT_DATA_API_KEY,
zone="unlocker", # Replace with the name of your Web Unlocker zone
verbose=True, # Useful while developing
)
# Get only the "search_engine" (SERP scraping) tool
brightdata_serp_tools = brightdata_tool_spec.to_tool_list(["search_engine"])
# Configure the connection to Gemini
llm = GoogleGenAI(
model="models/gemini-2.5-flash",
)
# Create the LlamaIndex agent powered by Gemini and connected to Bright Data tools
agent = FunctionAgent(
tools=brightdata_serp_tools,
llm=llm,
verbose=True, # Useful while developing
system_prompt="""
You are a helpful assistant that can retrieve SERP results in JSON format.
"""
)
# Async REPL loop
async def main():
print("Gemini-based agent with web searching capabilities powered by Bright Data. Type 'exit' to quit.n")
while True:
# Read the user request for the AI agent from the CLI
request = input("Request -> ")
# Terminate the execution if the user type "exit"
if request.strip().lower() == "exit":
print("nAgent terminated")
break
try:
# Execute the request
response = await agent.run(request)
print(f"nResponse ->:n{response}n")
except Exception as e:
print(f"nError: {str(e)}n")
if __name__ == "__main__":
asyncio.run(main())Starten Sie Ihren LlamaIndex SERP-Agenten mit:
python agent.pyWenn das Skript startet, sehen Sie eine Eingabeaufforderung wie diese in Ihrem Terminal:

Versuchen Sie zum Beispiel, Ihren Agenten um etwas zu bitten, das neue Informationen erfordert:
Write a short Markdown report on the new AI protocols, including some real-world links for further reading.Um diese Aufgabe effektiv zu erfüllen, muss der KI-Agent im Internet nach aktuellen Informationen suchen.
Das Ergebnis wird sein:
Das ging ziemlich schnell, also lassen Sie uns aufschlüsseln, was passiert ist:
- Der Agent erkennt die Notwendigkeit, nach “neuen KI-Protokollen” zu suchen, und ruft die SERP-API von Bright Data über das search_engine-Tool mit dieser Eingabe-URL auf:
https://www.google.com/search?q=new%20AI%20protocols&num=10&brd_json=1. - Das Tool holt asynchron SERP-Daten im JSON-Format aus der Google Search API von Bright Data.
- Der Agent übergibt die JSON-Antwort an den Gemini LLM.
- Gemini verarbeitet die neuen Daten und erstellt einen klaren, präzisen Markdown-Bericht mit relevanten Links.
In diesem Fall kehrte der KI-Agent zurück:
## New AI Protocols: A Brief Report
The rapid advancement of Artificial Intelligence has led to the emergence of new protocols designed to enhance interoperability, communication, and data handling among AI systems and with external data sources. These protocols aim to standardize how AI agents interact, leading to more scalable and integrated AI deployments.
Here are some of the key new AI protocols:
### 1. Model Context Protocol (MCP)
The Model Context Protocol (MCP) is an open standard that facilitates secure, two-way connections between AI-powered tools and various data sources. It fundamentally changes how AI assistants interact with the digital world by allowing them to access and utilize external information more effectively. This protocol is crucial for enabling AI models to communicate with external data sources and for building more capable and context-aware AI applications.
**Further Reading:**
* **Introducing the Model Context Protocol:** [https://www.anthropic.com/news/model-context-protocol](https://www.anthropic.com/news/model-context-protocol)
* **How A Simple Protocol Is Changing Everything About AI:** [https://www.forbes.com/sites/craigsmith/2025/04/07/how-a-simple-protocol-is-changing-everything-about-ai/](https://www.forbes.com/sites/craigsmith/2025/04/07/how-a-simple-protocol-is-changing-everything-about-ai/)
* **The New Model Context Protocol for AI Agents:** [https://evergreen.insightglobal.com/the-new-model-context-protocol-for-ai-agents/](https://evergreen.insightglobal.com/the-new-model-context-protocol-for-ai-agents/)
* **Model Context Protocol: The New Standard for AI Interoperability:** [https://techstrong.ai/aiops/model-context-protocol-the-new-standard-for-ai-interoperability/](https://techstrong.ai/aiops/model-context-protocol-the-new-standard-for-ai-interoperability/)
* **Hot new protocol glues together AI and apps:** [https://www.axios.com/2025/04/17/model-context-protocol-anthropic-open-source](https://www.axios.com/2025/04/17/model-context-protocol-anthropic-open-source)
### 2. Agent2Agent Protocol (A2A)
The Agent2Agent Protocol (A2A) is a cross-platform specification designed to enable AI agents to communicate with each other, securely exchange information, and coordinate actions. This protocol is vital for fostering collaboration among different AI agents, allowing them to work together on complex tasks and delegate responsibilities across various enterprise systems.
**Further Reading:**
* **Announcing the Agent2Agent Protocol (A2A):** [https://developers.googleblog.com/en/a2a-a-new-era-of-agent-interoperability/](https://developers.googleblog.com/en/a2a-a-new-era-of-agent-interoperability/)
* **What Every AI Engineer Should Know About A2A, MCP & ACP:** [https://medium.com/@elisowski/what-every-ai-engineer-should-know-about-a2a-mcp-acp-8335a210a742](https://medium.com/@elisowski/what-every-ai-engineer-should-know-about-a2a-mcp-acp-8335a210a742)
* **What a new AI protocol means for journalists:** [https://www.dw.com/en/what-coding-agents-and-a-new-ai-protocol-mean-for-journalists/a-72976193](https://www.dw.com/en/what-coding-agents-and-a-new-ai-protocol-mean-for-journalists/a-72976193)
### 3. Agent Communication Protocol (ACP)
The Agent Communication Protocol (ACP) is an open standard specifically for agent-to-agent communication. Its purpose is to transform the current landscape of siloed AI agents into interoperable agentic systems, promoting easier integration and collaboration between them. ACP provides a standardized messaging framework for structured communication.
**Further Reading:**
* **MCP, ACP, and Agent2Agent set standards for scalable AI:** [https://www.cio.com/article/3991302/ai-protocols-set-standards-for-scalable-results.html](https://www.cio.com/article/3991302/ai-protocols-set-standards-for-scalable-results.html)
* **What is Agent Communication Protocol (ACP)?** [https://www.ibm.com/think/topics/agent-communication-protocol](https://www.ibm.com/think/topics/agent-communication-protocol)
* **MCP vs A2A vs ACP: AI Protocols Explained:** [https://www.bluebash.co/blog/mcp-vs-a2a-vs-acp-agent-communication-protocols/](https://www.bluebash.co/blog/mcp-vs-a2a-vs-acp-agent-communication-protocols/)
These emerging protocols are crucial steps towards a more interconnected and efficient AI ecosystem, enabling more sophisticated and collaborative AI applications across various industries.Beachten Sie, dass die Antwort des KI-Agenten neue Protokolle und aktuelle Links enthält, die nach dem letzten Trainings-Update von Gemini veröffentlicht wurden. Dies unterstreicht den Wert der Integration von Live-Web-Suchfunktionen.
Genauer gesagt enthält die Antwort kontextbezogene Links, die genau dem entsprechen, was man bei der Suche nach “new ai protocols” auf Google finden würde:
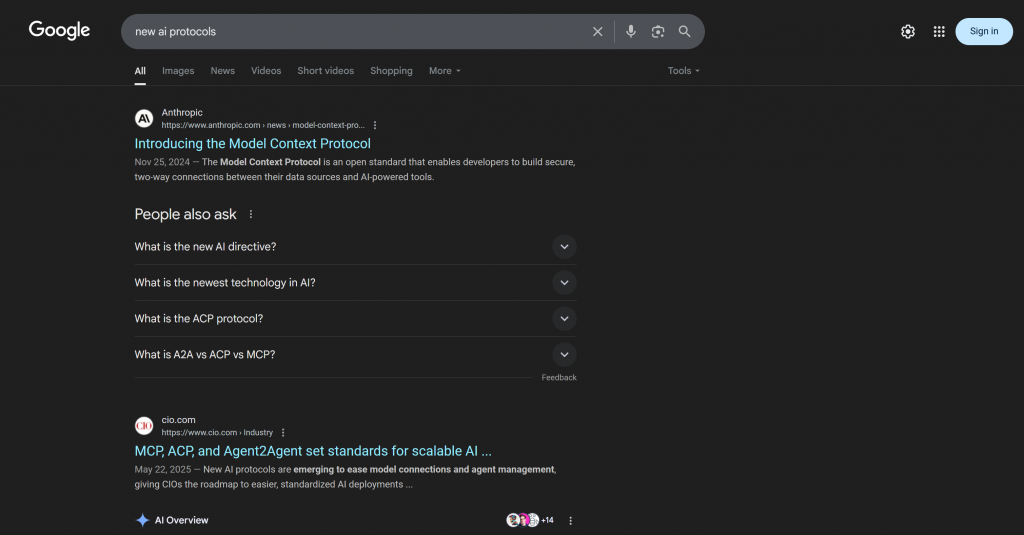
Beachten Sie, dass die Antwort viele der gleichen Links enthält, die Sie in der aktuellen SERP für “neue KI-Protokolle” finden würden (zumindest zum Zeitpunkt der Erstellung dieses Artikels).
Et voilà! Sie haben jetzt einen LlamaIndex-KI-Agenten mit Suchmaschinen-Scraping-Fähigkeiten, die von Bright Data unterstützt werden.
Schritt #9: Nächste Schritte
Der aktuelle LlamaIndex SERP AI Agent ist nur ein einfaches Beispiel, das nur das search_engine Tool von Bright Data verwendet.
In fortgeschrittenen Szenarien wollen Sie Ihren Agenten wahrscheinlich nicht auf ein einziges Werkzeug beschränken. Stattdessen ist es besser, Ihrem Agenten Zugang zu allen verfügbaren Werkzeugen zu geben und eine klare Systemaufforderung zu schreiben, die dem LLM hilft, zu entscheiden, welche Werkzeuge er für jedes Ziel verwenden soll.
Sie könnten zum Beispiel Ihre Aufforderung erweitern, um einen Schritt weiter zu gehen und:
- Führen Sie mehrere Suchanfragen durch.
- Wählen Sie die obersten N Links aus den SERP-Ergebnissen aus.
- Besuchen Sie diese Seiten und scrapen Sie deren Inhalt in Markdown.
- Lernen Sie aus diesen Informationen, um ein reichhaltigeres, detaillierteres Ergebnis zu erzielen.
Weitere Hinweise zur Integration mit allen verfügbaren Tools finden Sie in unserem Tutorial zur Erstellung von KI-Agenten mit LlamaIndex und Bright Data.
Schlussfolgerung
In diesem Artikel haben Sie gelernt, wie Sie mit LlamaIndex einen KI-Agenten erstellen, der das Web über Bright Data durchsuchen kann. Diese Integration ermöglicht es Ihrem Agenten, Suchanfragen in den wichtigsten Suchmaschinen wie Google, Bing, Yandex und vielen anderen auszuführen.
Denken Sie daran, dass das hier beschriebene Beispiel nur ein Ausgangspunkt ist. Wenn Sie fortgeschrittenere Agenten entwickeln möchten, benötigen Sie robuste Tools zum Abrufen, Validieren und Umwandeln von Live-Webdaten. Genau das bietet die KI-Infrastruktur für Agenten von Bright Data.
Erstellen Sie ein kostenloses Bright Data-Konto und erkunden Sie noch heute unsere agentenbasierten KI-Datentools!




