

In diesem Blogbeitrag erfahren Sie:
- Was AutoGPT ist und was es als Framework zur Erstellung von KI-Agenten so besonders macht.
- Warum AutoGPT-Agenten vom Zugriff auf Funktionen wie Websuche, Erkundung, Interaktion und Datenscraping profitieren.
- Wie Bright Data in AutoGPT integriert werden kann, um KI-Agenten genau diese Funktionen zur Verfügung zu stellen.
Lassen Sie uns loslegen!
Was ist AutoGPT
AutoGPT ist eine Open-Source-Plattform zum Erstellen, Bereitstellen und Ausführen autonomer KI-Agenten.
Was es auszeichnet, sind seine Low-Code-Schnittstelle auf Blockbasis, die kontinuierliche Ausführung von Agenten und die Möglichkeit, Tools, APIs und Datenquellen in durchgängige Automatisierungspipelines zu verbinden.
Im Gegensatz zu einfachen Skripten können AutoGPT-Agenten dauerhaft laufen, auf Trigger reagieren und mehrstufige Aufgaben verwalten. Das Projekt wird von einer großen Open-Source-Community unterstützt. Es hat auf GitHub mit über 183.000 Sternen beeindruckende Aufmerksamkeit erlangt.
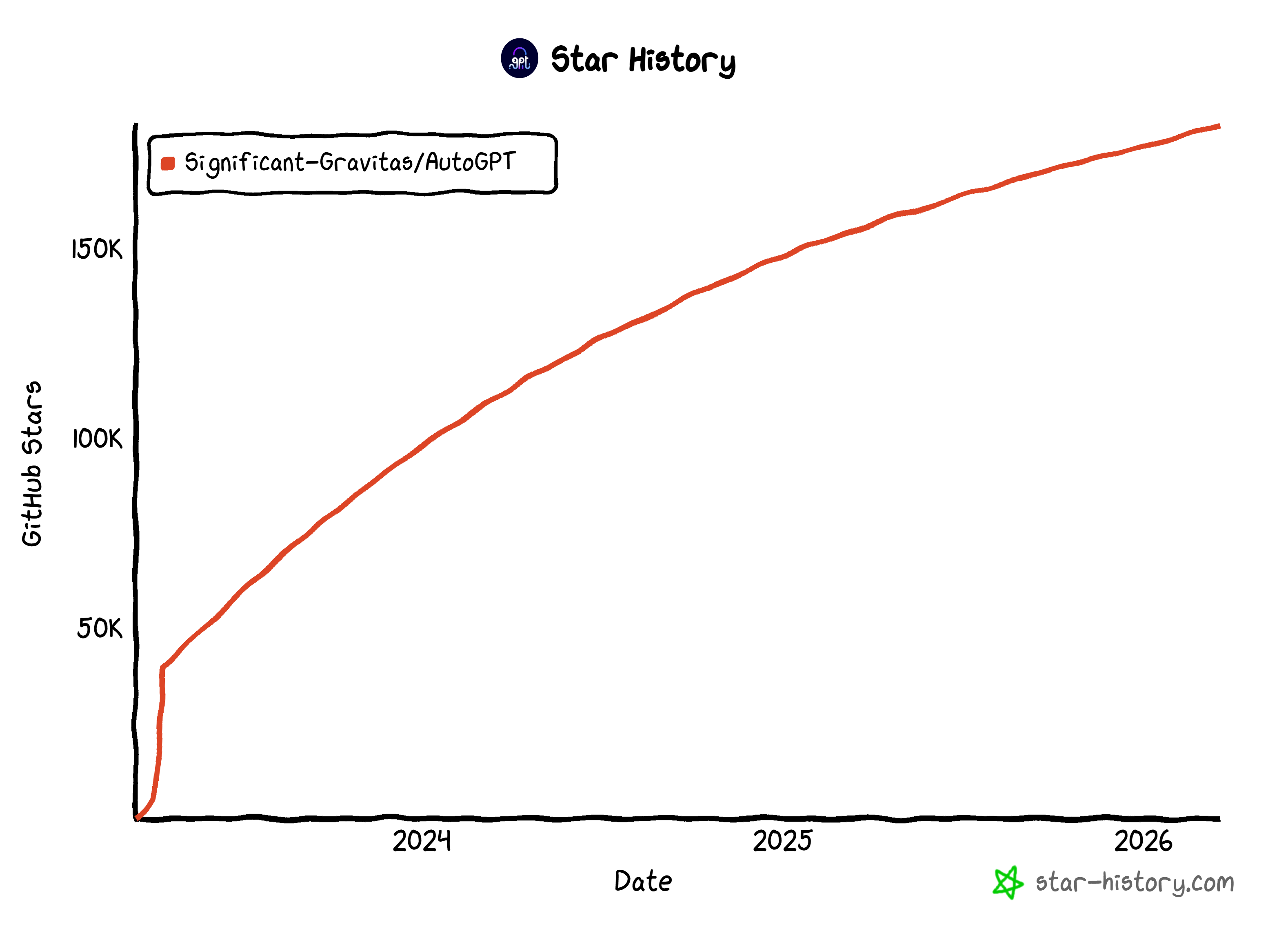
Diese Zahlen machen es zu einem der beliebtesten KI-Agenten-Frameworks der Gegenwart.
Warum Web-Exploration und Datenabruf-Funktionen in AutoGPT integrieren?
Es besteht kein Zweifel daran, dass AutoGPT eine funktionsreiche Lösung ist. Dennoch unterliegen alle LLM-basierten KI-Agenten inhärenten Einschränkungen. Standard-Sprachmodelle werden auf statischen Datensätzen trainiert, was bedeutet, dass ihr Wissen auf einen bestimmten Zeitpunkt festgelegt ist.
Dies kann zu veralteten Informationen, Halluzinationen oder Lücken führen, wenn Agenten reale Aufgaben ausführen, die aktuelle Daten erfordern. Darüber hinaus können LLMs nicht mit der realen Welt, einschließlich des Internets, interagieren. Daher sind einfache KI-Agenten durch diese inhärenten Einschränkungen begrenzt.
AutoGPT enthält zwar native Tools für die Websuche, die Erkundung und andere Interaktionen. Doch im Vergleich zu Lösungen auf Unternehmensniveau können diese integrierten Funktionen Probleme mit Skalierbarkeit, Zuverlässigkeit und ausgefeilten Anti-Bot-Maßnahmen haben.
Hier kommt Bright Data ins Spiel. Aufgebaut auf einem der größten Proxy-Netzwerke der Welt – mit über 150 Millionen IPs in 195 Ländern – bietet seine Infrastruktur eine Verfügbarkeit von 99,99 % und unbegrenzte Parallelität.
Durch die Integration von Bright Data in AutoGPT können Agenten auf Live-Webinhalte, Suchergebnisse und strukturierte Daten von jeder beliebigen Website zugreifen. Im Einzelnen gehören zu den wichtigsten Bright Data-Produkten, die AutoGPT-Workflows verbessern können:
- Web Unlocker API: Greifen Sie auf die Inhalte jeder Website im Roh-HTML- oder Markdown-Format zu und umgehen Sie dabei CAPTCHAs und Anti-Bot-Schutzmaßnahmen.
- SERP-API: Sammeln Sie Suchmaschinenergebnisse von Google, Bing, Yandex und vielen anderen Suchmaschinen.
- Web Scraper APIs: Extrahieren Sie strukturierte Daten von Plattformen wie Amazon, LinkedIn, Instagram und Yahoo Finance.
- Crawl API: Konvertiert ganze Websites in strukturierte Datensätze für die nachgelagerte KI-Verarbeitung.
Durch die Kombination der agentischen Fähigkeiten von AutoGPT mit den Lösungen von Bright Data können KI-Agenten autonom Live-Informationen abrufen und komplexe Workflows ausführen, die weit über die Grenzen von Standard-LLMs hinausgehen.
So integrieren Sie Bright Data in AutoGPT: Eine Schritt-für-Schritt-Anleitung
In diesem Leitfaden erfahren Sie, wie Sie in AutoGPT einen KI-Agenten erstellen, der sich zur Abfrage von Webdaten mit Bright Data integrieren lässt.
Insbesondere fungiert dieser Agent als Lesezeichen-Assistent und hilft Ihnen bei der Entscheidung, ob es sich lohnt, einen Online-Artikel zum späteren Lesen zu speichern. Dies ist nur ein einfaches Beispiel zur Veranschaulichung der Integration, aber es sind viele weitere Anwendungsfälle möglich.
Befolgen Sie die nachstehenden Anweisungen!
Voraussetzungen
Um AutoGPT selbst zu hosten, stellen Sie sicher, dass Ihr System die folgenden Hardwareanforderungen erfüllt:
- Betriebssystem: Linux (Ubuntu 20.04 oder neuer empfohlen), macOS (10.15 oder neuer) oder Windows 10/11 mit WSL2.
- CPU: 4+ Kerne empfohlen.
- RAM: Mindestens 8 GB (16 GB empfohlen).
- Speicherplatz: Mindestens 10 GB freier Speicherplatz.
Außerdem müssen folgende Tools lokal auf Ihrem Rechner installiert sein:
- Docker Engine 20.10.0+
- Docker Compose 2.0.0+
- Git 2.30+
- Node.js 16.x+ (mit npm 8.x+)
- Visual Studio Code 1.60+ oder ein beliebiger moderner Code-Editor
Stellen Sie außerdem sicher, dass die folgenden Netzwerkanforderungen erfüllt sind:
- Eine stabile Internetverbindung.
- Zugriff auf die erforderlichen Ports (die über Docker konfiguriert werden).
- Möglichkeit, ausgehende HTTPS-Verbindungen herzustellen.
Um den KI-Agenten in AutoGPT zu implementieren, benötigen Sie außerdem:
- Ein Bright Data-Konto mit einer eingerichteten Web Unlocker-API-Zone und einem konfigurierten API-Schlüssel.
- Einen API-Schlüssel von einem der von AutoGPT unterstützten LLM-Anbieter (in diesem Beispiel verwenden wir OpenAI).
Machen Sie sich vorerst keine Gedanken über die Konfiguration Ihres Bright Data-Kontos, da Sie in einem eigenen Kapitel durch den Vorgang geführt werden.
Schritt 1: Installieren Sie AutoGPT lokal
Stellen Sie sicher, dass Ihr System die Hardware-, Software- und Netzwerkvoraussetzungen erfüllt. Vergewissern Sie sich außerdem, dass Docker läuft.
Um den Einrichtungsprozess für das Self-Hosting von AutoGPT zu vereinfachen, empfiehlt es sich, das offizielle Einzeiler-Installationsskript zu verwenden. Dieses installiert alle erforderlichen Abhängigkeiten, ruft den neuesten Code ab und startet die Anwendung für Sie.
Führen Sie unter macOS oder Linux das einzeilige Installationsskript mit folgendem Befehl aus:
curl -fsSL https://setup.agpt.co/install.sh -o install.sh && bash install.shEntsprechend führen Sie unter Windows den folgenden Befehl in PowerShell aus:
powershell -c "iwr https://setup.agpt.co/install.bat -o install.bat; ./install.bat"Der Installationsvorgang kann einige Minuten dauern, haben Sie also etwas Geduld. Sobald er abgeschlossen ist, sollten Sie eine Ausgabe sehen, die in etwa wie folgt aussieht: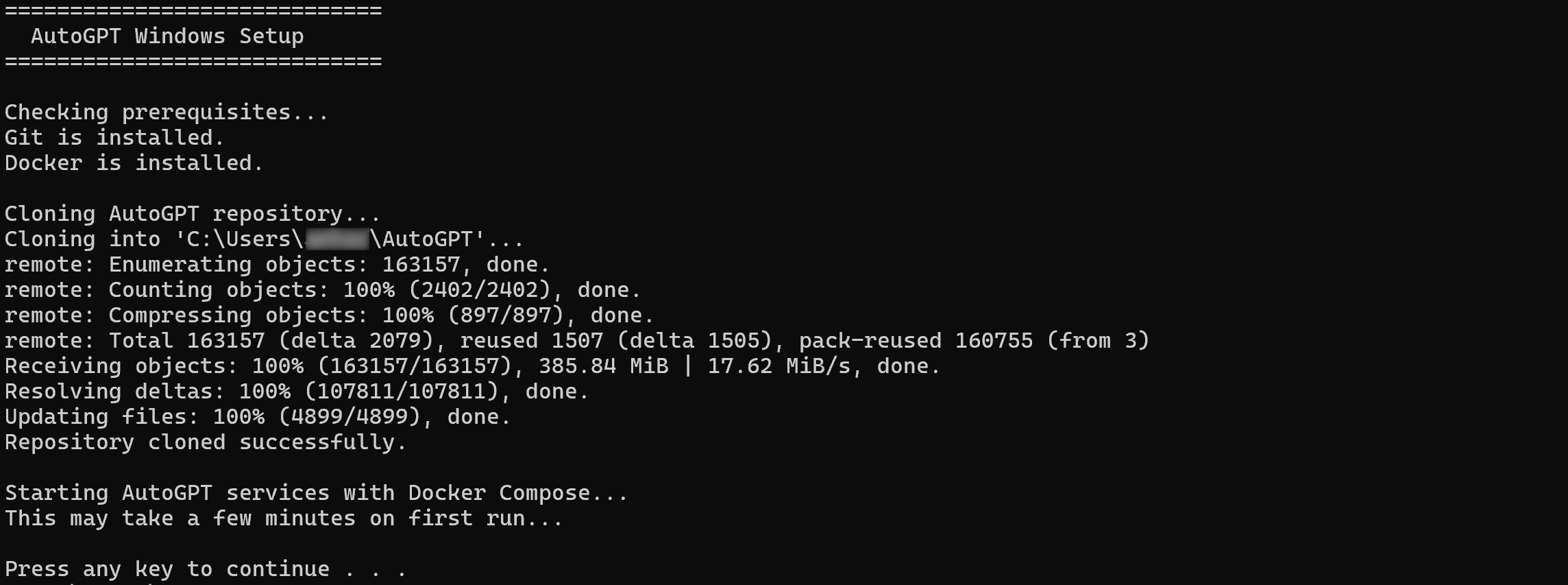
Großartig! Zu diesem Zeitpunkt sollte AutoGPT lokal erfolgreich eingerichtet und einsatzbereit sein.
Schritt 2: Starten Sie die Plattform
Navigieren Sie zum Installationsordner:
cd AutoGPT/autogpt_platformKopieren Sie anschließend die Datei .env.default aus dem geklonten Repository in den Ordner .env:
cp .env.default .envDieser Befehl erstellt eine .env-Datei im Verzeichnis autogpt_platform mit der Standardkonfiguration. Ändere diese Datei nur dann, um deine eigenen Umgebungsvariablen zu definieren, wenn du eine benutzerdefinierte Konfiguration benötigst. Andernfalls behalte die Standardwerte bei.
Starten Sie anschließend die AutoGPT-Plattform mit:
docker compose up -d --buildDieser Befehl erstellt und startet alle erforderlichen Backend-Dienste, die in der Datei docker-compose.yml definiert sind, im Detached-Modus.
Sobald die Dienste laufen, überprüfen Sie, ob alles funktioniert, indem Sie http://localhost im Browser aufrufen.
Standardmäßig sind die verschiedenen AutoGPT-Dienste unter folgenden Adressen verfügbar:
- Frontend-UI-Server:
http://localhost. - Backend-WebSocket-Server:
http://localhost:8001. - REST-Server für die Ausführungs-API:
http://localhost:8006.
Unten sehen Sie, was angezeigt werden sollte:
Registrieren Sie sich, indem Sie ein Konto erstellen. Nach der Anmeldung gelangen Sie zum Agent Builder im AutoGPT-Frontend:
Super! Sie können nun Ihren ersten Agenten erstellen und ihn mit Bright Data verbinden.
Schritt 3: Entwerfen Sie den Workflow des KI-Agenten
AutoGPT bietet mehrere Blöcke, von denen jeder eine bestimmte Aktion oder Aufgabe abwickelt. In diesem Beispiel möchten Sie einen agentenbasierten Workflow erstellen, der:
- eine Artikel-URL (von einer beliebigen Website) als Eingabe akzeptiert.
- den Artikelinhalt mithilfe der Bright Data Web Unlocker API im Markdown-Format abruft.
- den Inhalt an ein LLM weiterleitet, um eine Bewertung von 1 bis 10 zu erzeugen, die angibt, wie wertvoll der Artikel ist, um als Lesezeichen gespeichert zu werden, sowie einen menschenähnlichen Kommentar, der die Bewertung erklärt.
- die strukturierte Ausgabe zurückgibt.

In AutoGPT kann dieser Workflow mit den folgenden Blöcken implementiert werden:
- Agent-Eingabe: Nimmt die Artikel-URL vom Benutzer entgegen.
- Wörterbuch erstellen: Erstellt den Request-Body für die Bright Data Web Unlocker API unter Verwendung der angegebenen URL.
- Authentifizierte Webanfrage senden: Sendet die Anfrage an die Bright Data Web Unlocker API und ruft den Artikelinhalt ab.
- KI Structured Response Generator: Leitet den Artikelinhalt an das LLM weiter und generiert eine strukturierte Lesezeichen-Bewertung (Punktzahl + Kommentar).
- Agent-Ausgabe: Gibt das endgültige strukturierte Ergebnis zurück.
Perfekt! Nachdem nun die Schritte des agentischen Workflows klar sind, ist der nächste Schritt die Umsetzung. Aber zuerst fangen wir mit Bright Data an.
Schritt 4: Konfigurieren Sie Ihr Bright Data-Konto
Wie bereits erwähnt, basiert der KI-Agenten-Workflow, den Sie implementieren möchten, auf dem Web Unlocker-Produkt von Bright Data. Um in AutoGPT eine Verbindung herzustellen, benötigen Sie ein Bright Data-Konto mit einer konfigurierten Web Unlocker-API-Zonen-Konfiguration sowie einen API-Schlüssel.
Eine kurze Anleitung finden Sie im Artikel„Quick Start Guide for Bright Data’s Web Unlocker API“.Alternativ können Sie die folgenden Schritte befolgen.
Wenn Sie noch kein Bright Data-Konto haben, erstellen Sie ein neues. Andernfalls melden Sie sich einfach an. Rufen Sie das Control Panel auf und navigieren Sie zur Seite „Proxies & Scraping“. Sehen Sie sich die Tabelle „My Zones“ an: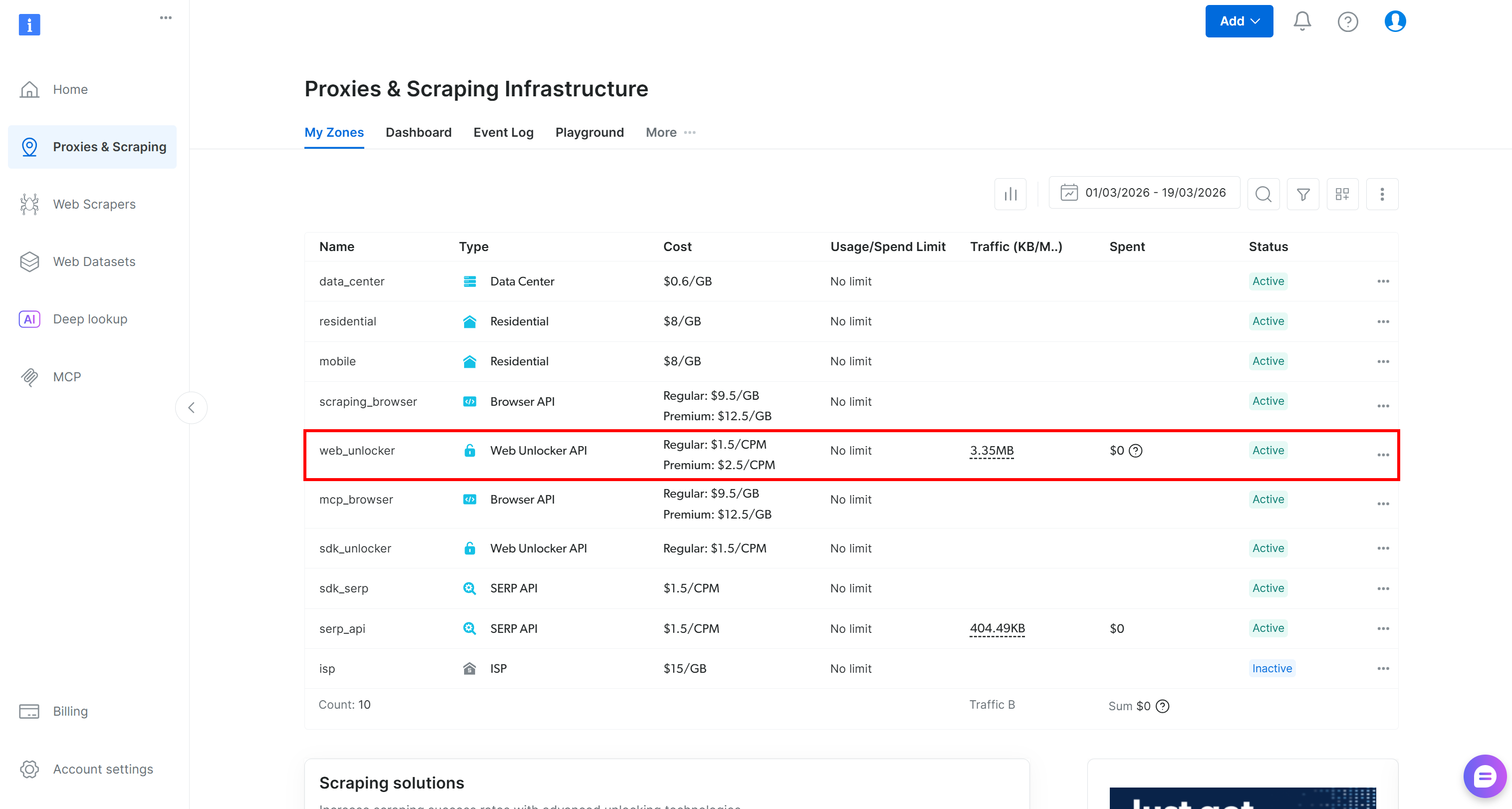
Wenn in der Tabelle bereits eine Web Unlocker API-Zone (z. B. web_unlocker) vorhanden ist, können Sie loslegen.
Falls diese fehlt, müssen Sie eine erstellen. Scrollen Sie zur Karte „Unblocker API“, klicken Sie auf die Schaltfläche „Zone erstellen“ und folgen Sie den Anweisungen des Assistenten.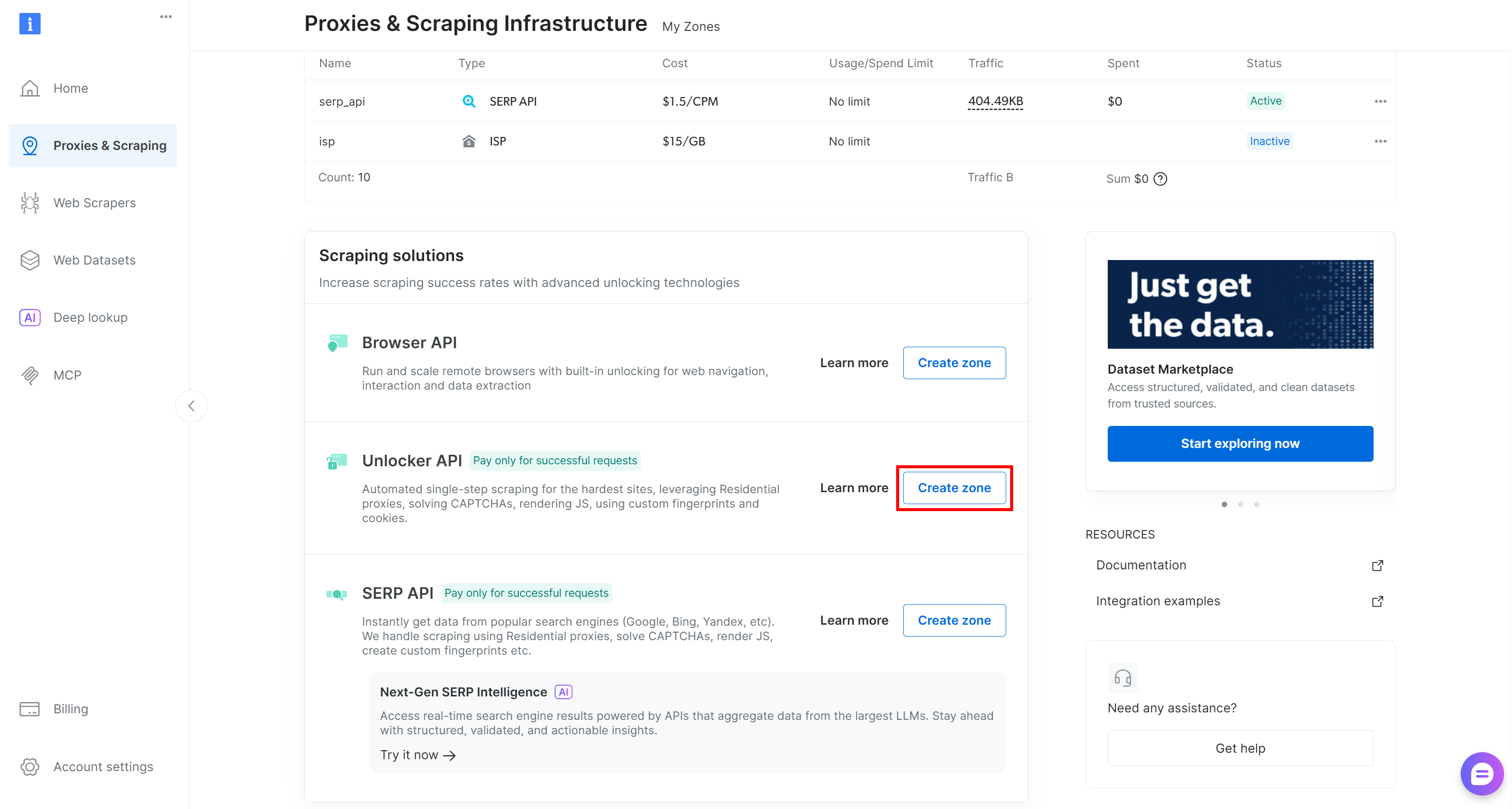
Wählen Sie den Namen Ihrer Zone sorgfältig aus, da Sie ihn später benötigen werden. In dieser Anleitung gehen wir davon aus, dass die Zone den Namen web_unlocker trägt.
Generieren Sie abschließend Ihren Bright Data API-Schlüssel und bewahren Sie ihn sicher auf. Sie benötigen ihn zur Authentifizierung von HTTP-Anfragen, die von AutoGPT an Bright Data gestellt werden.
Das war’s! Die Voraussetzungen für Bright Data sind erfüllt.
Schritt 5: Initialisieren des Agenten
Jeder AutoGPT-Agent-Workflow benötigt eine Eingabe und eine Ausgabe. Gehen Sie zunächst zum Abschnitt „Build“, um die Seite „Agent Builder“ aufzurufen:
Klicken Sie auf die Schaltfläche „Save“, geben Sie Ihrem Agenten einen Namen wie „Bookmark Likelihood Evaluator“ und klicken Sie dann auf „Save Agent“: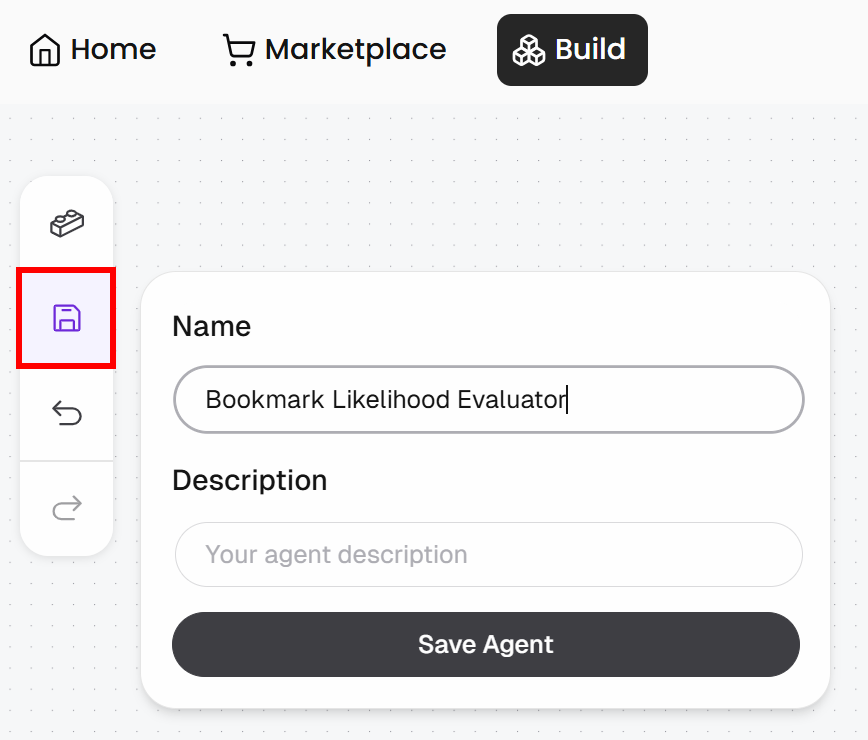
Klicken Sie auf der Seite „Agent Builder“ links auf die Schaltfläche „Blocks“ und fügen Sie einen „Agent Input“-Block hinzu: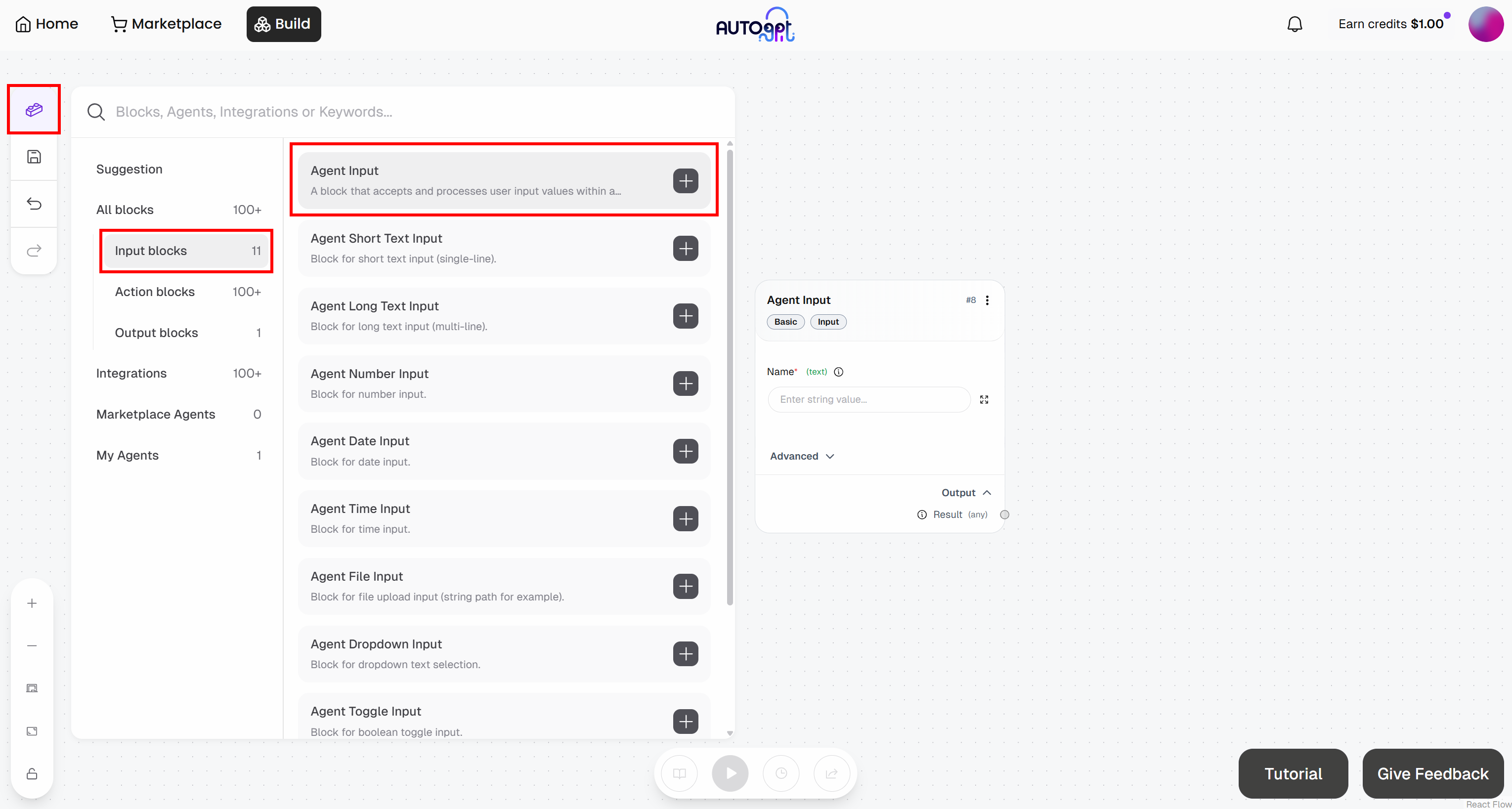
Fügen Sie auf ähnliche Weise einen „Agent Output“-Block hinzu: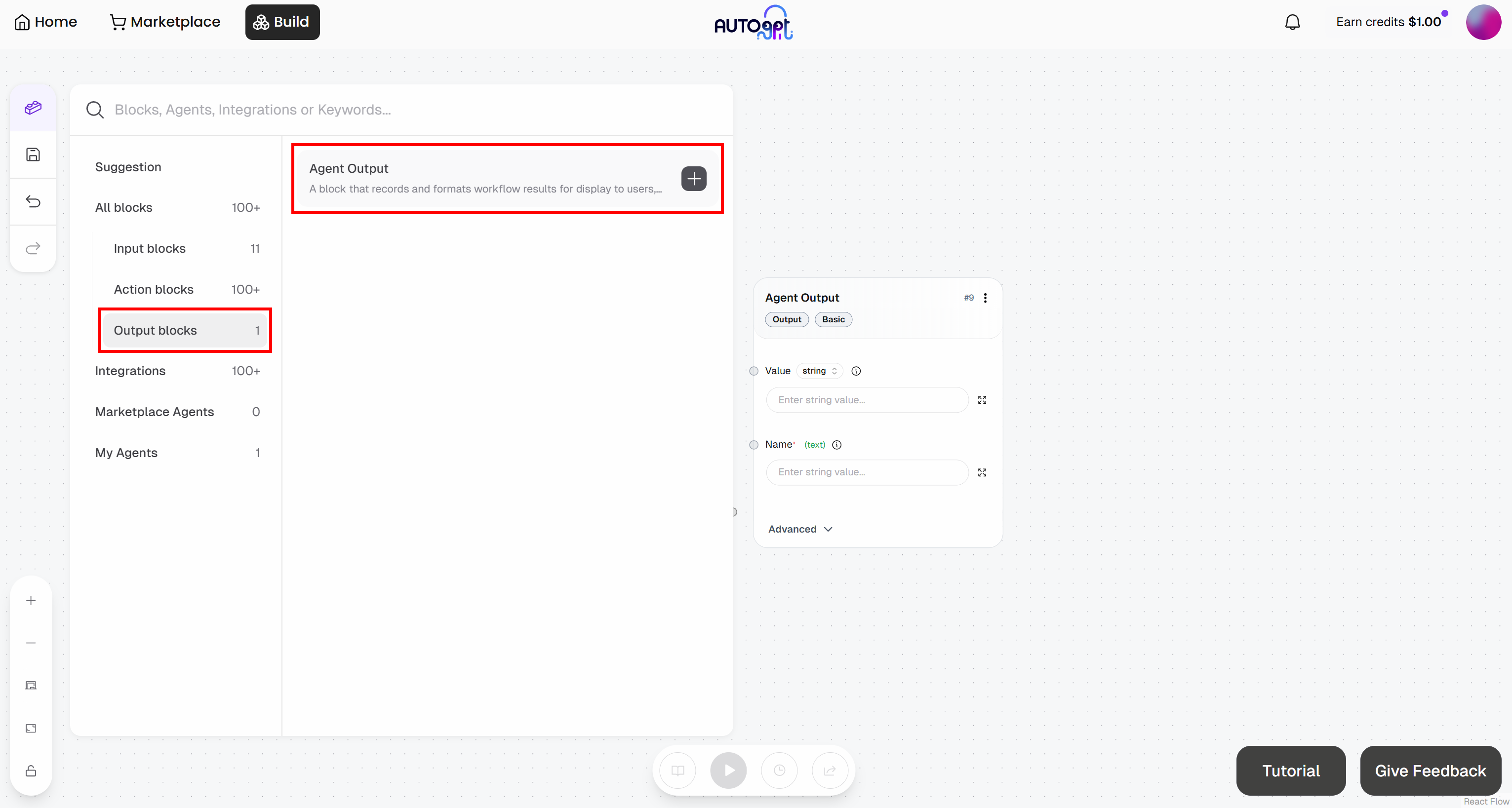
Konfigurieren Sie die Blöcke wie folgt:
- Agent Input: Benennen Sie ihn „Article URL“
- Agent-Output-Block: Benennen Sie ihn „Bookmarking-Wahrscheinlichkeit“
Zu diesem Zeitpunkt sollte Ihr anfänglicher agentischer Workflow wie folgt aussehen: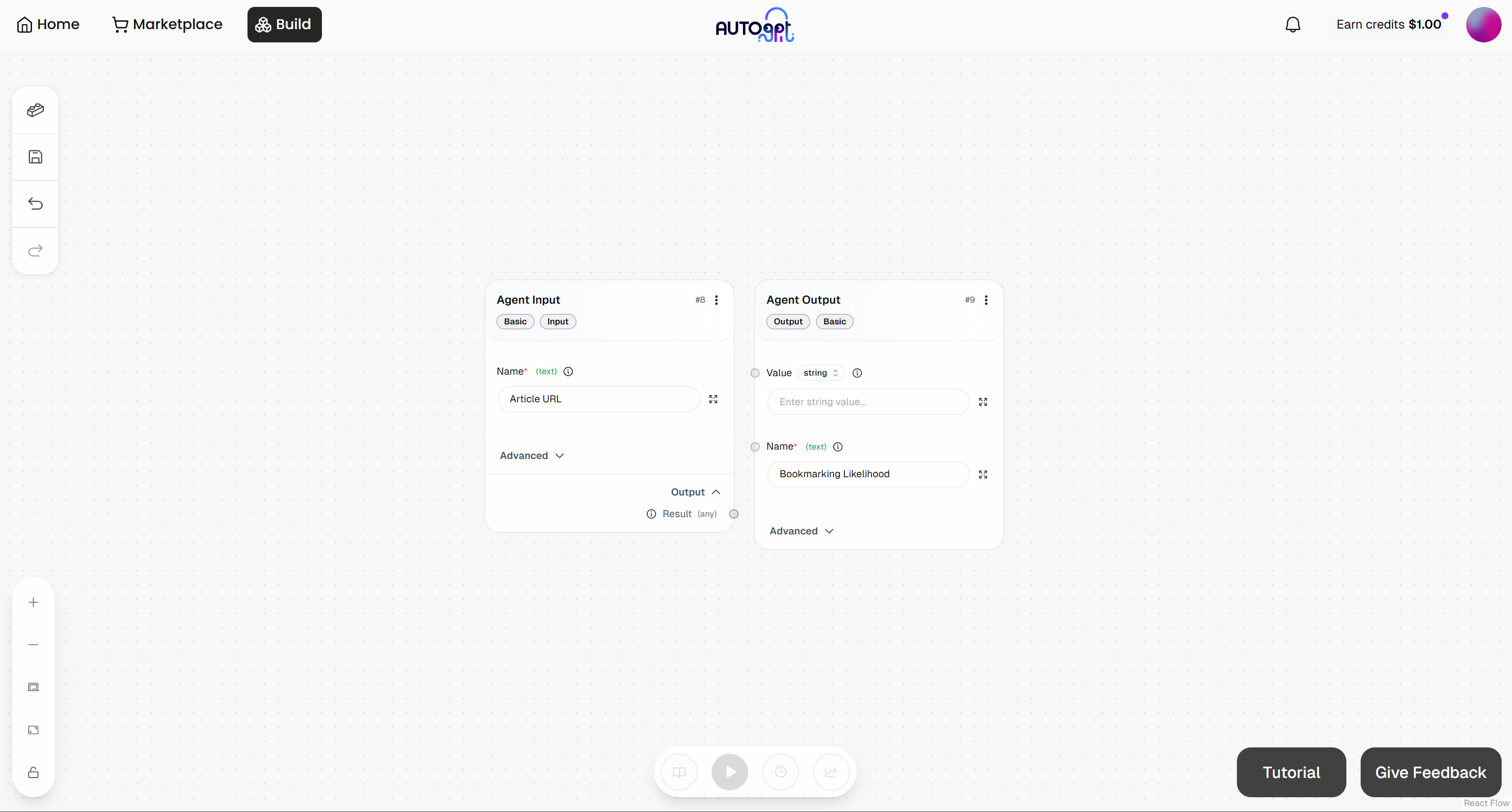
Großartig! Es ist an der Zeit, den Rest Ihres agentischen Workflows zu definieren.
Schritt 6: Erstellen Sie die Scraping-Anfrage
Um die HTTP-Anfrage an die Bright Data Web Unlocker API auszuführen, benötigen Sie zwei Blöcke:
- Create Dictionary: Definiert den Request-Body.
- Authentifizierte Webanfrage senden: Sendet die authentifizierte Anfrage an den Web Unlocker-Endpunkt der Bright Data-APIs.
Füge zunächst den Block „Create Dictionary“ hinzu: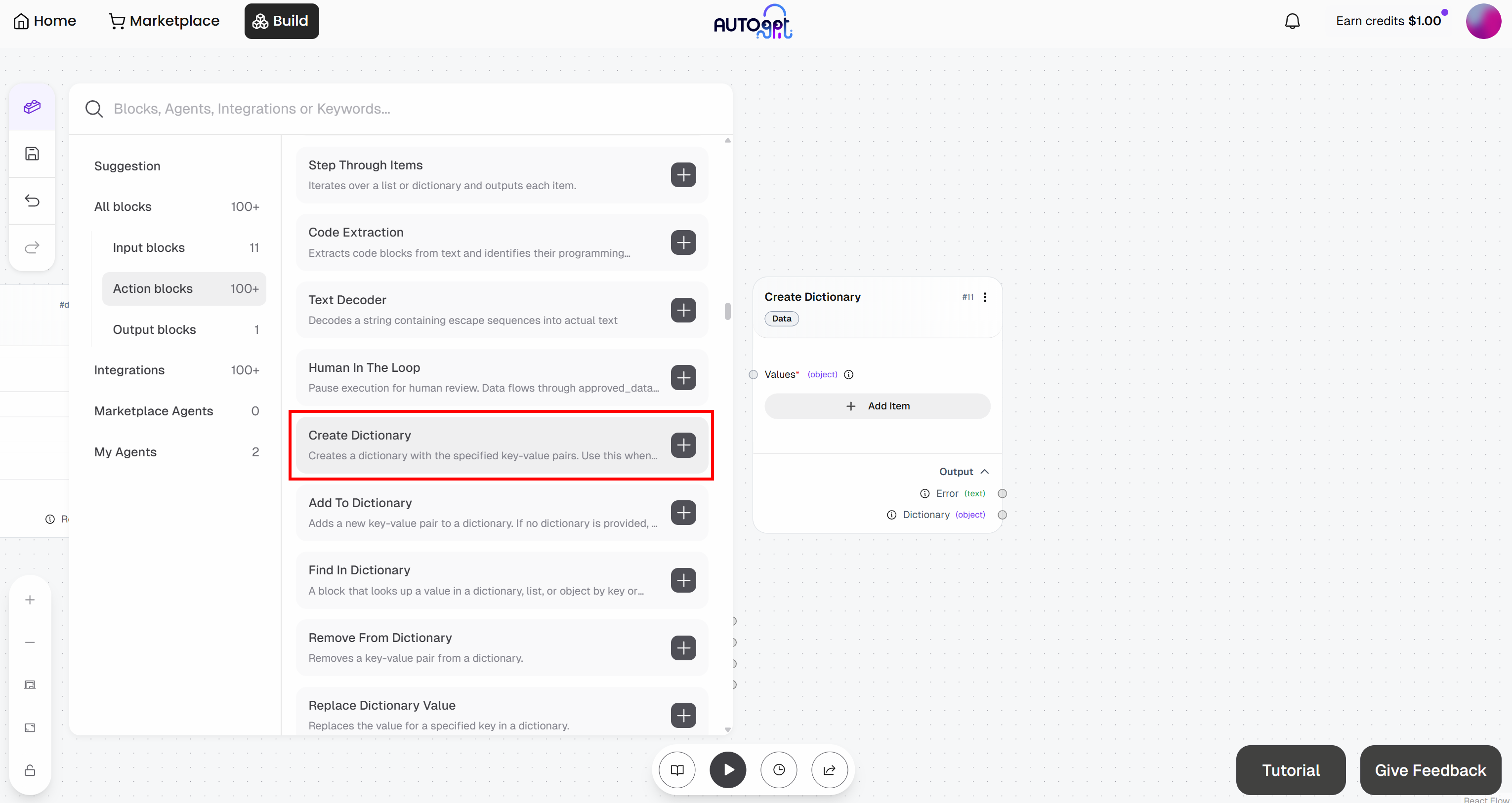
Fügen Sie anschließend den Block „Authentifizierte Webanfrage senden“ hinzu: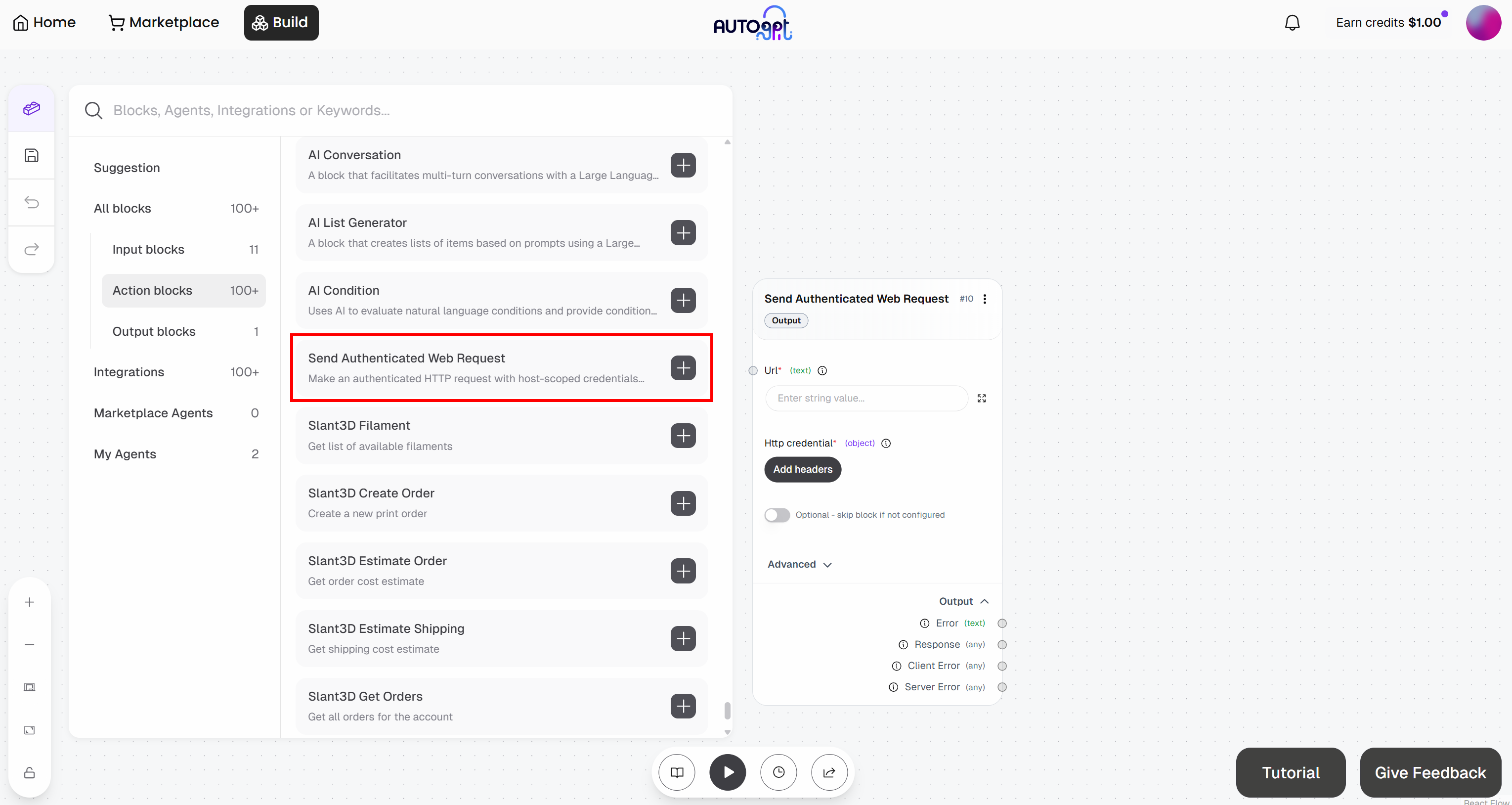
Machen Sie sich bereit, den Block „Authentifizierte Webanfrage senden“ zu konfigurieren. Dadurch wird eine Anfrage an die Web Unlocker-API gesendet. Weitere Informationen zur Funktionsweise dieses Endpunkts und zu dessen Aufruf finden Sie in der offiziellen Dokumentation.
Erweitern Sie das Dropdown-Menü „Erweitert“ und füllen Sie den gesamten Block wie folgt aus:
- URL:
https://api.brightdata.com/request. - HttpMethod:
POST
Klicken Sie anschließend unter „HTTP-Anmeldedaten“ auf die Schaltfläche „Header hinzufügen“: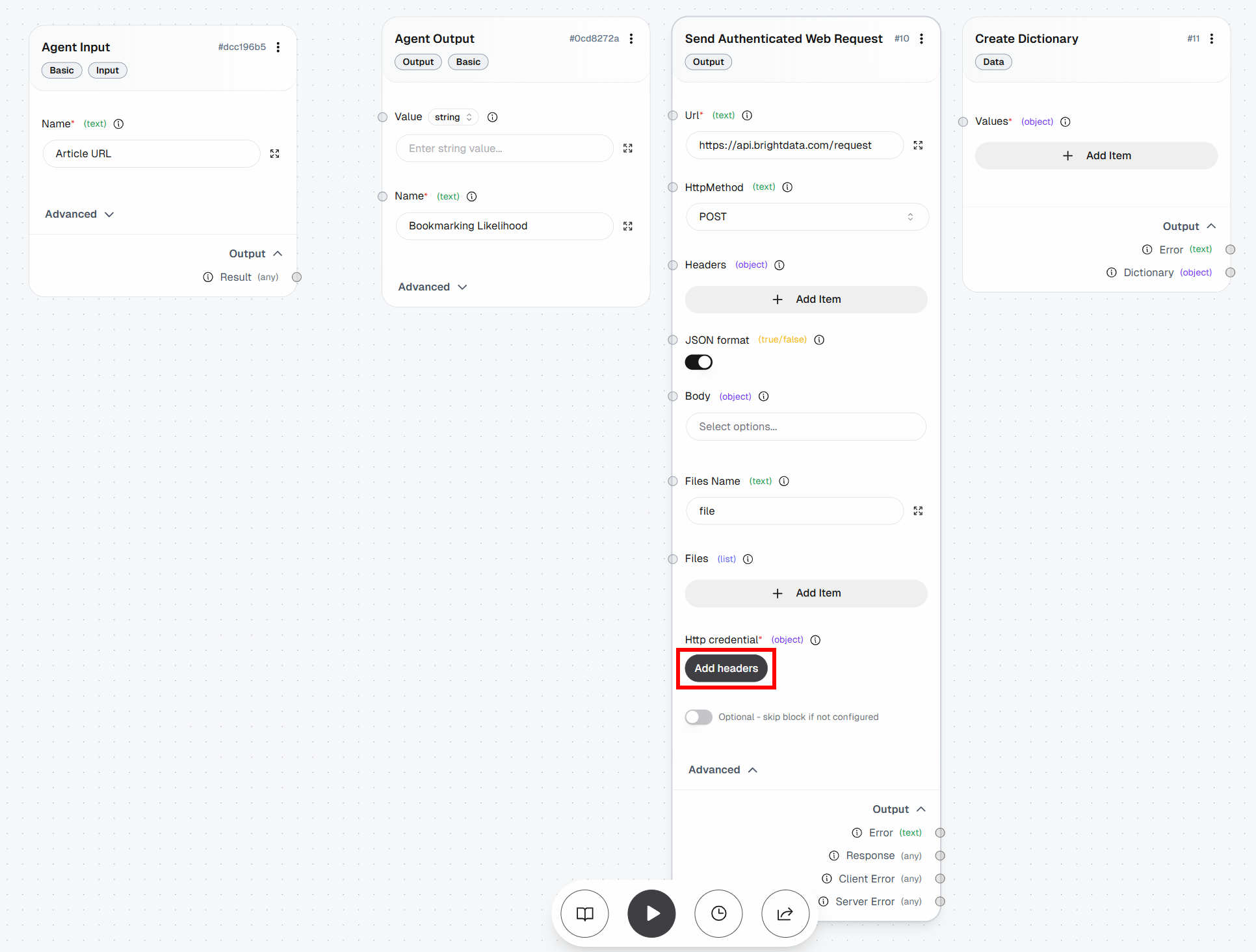
Konfigurieren Sie die headerbasierte Authentifizierung wie folgt:
- Header-Name:
Authorization - Header-Wert:
Bearer <YOUR_BRIGHT_DATA_API_KEY>
Denken Sie daran, den Platzhalter <YOUR_BRIGHT_DATA_API_KEY> durch Ihren tatsächlichen Bright Data API-Schlüssel zu ersetzen.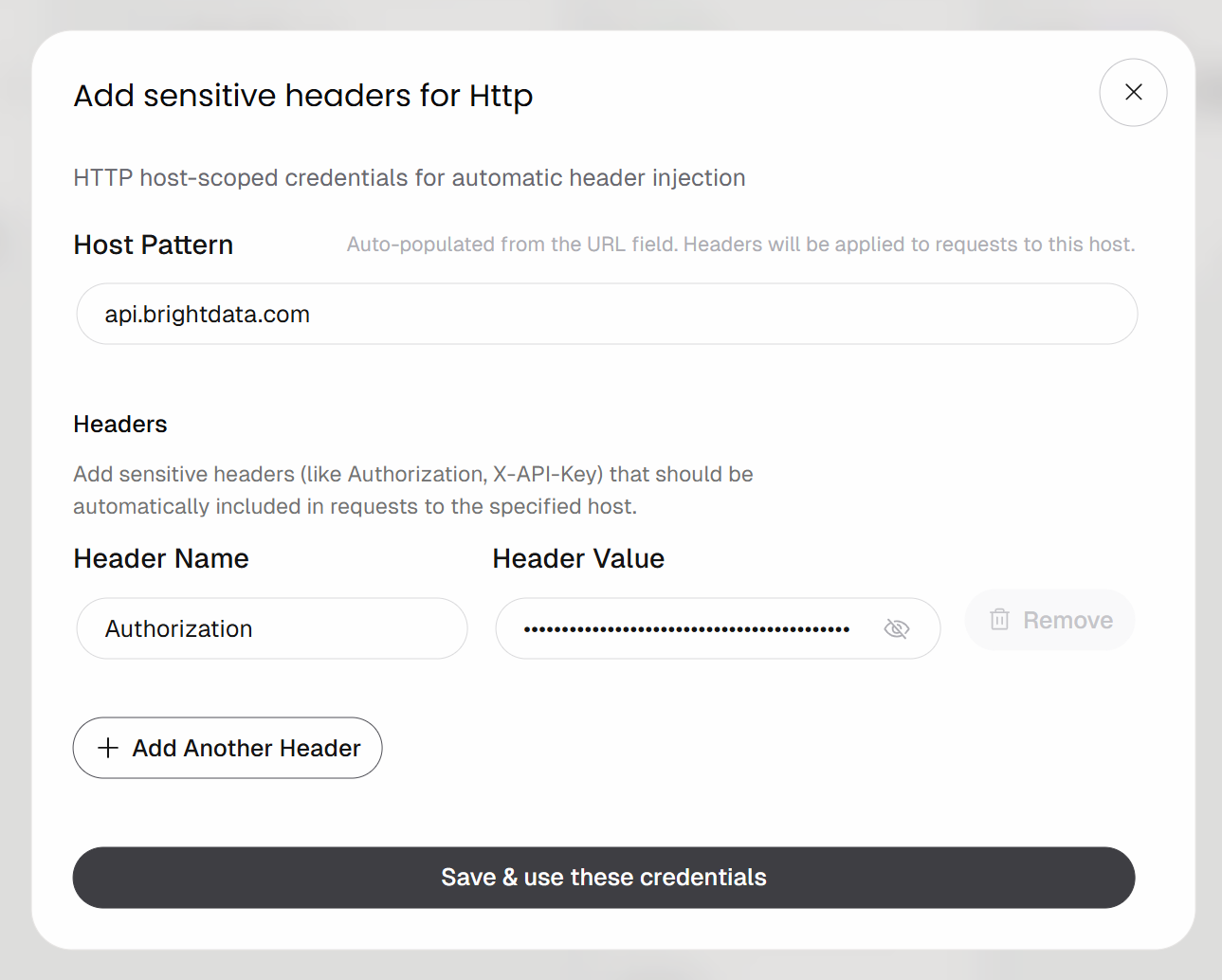
Klicken Sie zur Bestätigung auf die Schaltfläche „Speichern & diese Anmeldedaten verwenden“.
Die POST-Anfrage wird mithilfe des Authorization-Headers authentifiziert. Dies ist die empfohlene Authentifizierungsmethode für den Aufruf von Bright Data-APIs.
Nun müssen Sie den Request-Body definieren. In diesem Fall benötigen Sie eine JSON-Nutzlast wie folgt:
{
"zone": "<YOUR_WEB_UNLOCKER_API_ZONE_NAME>",
"url": "<INPUT_URL>",
"format": "raw",
"data_format": "markdown"
}Dies weist die Bright Data-API an, Ihre Web Unlocker-API-Zone (z. B. web_unlocker) auf eine Ziel-URL anzuwenden, die vom Block „Agent Input“ bereitgestellt wird. Der Parameter format: „raw“ stellt sicher, dass die API die Ausgabe direkt im Antworttext zurückgibt und nicht als JSON-Struktur. Der Parameter data_format: „markdown“ konfiguriert die API so, dass sie den Artikelinhalt im Markdown-Format extrahiert, was ein ideales Format für die Erfassung durch KI-Agenten ist.
Wechseln Sie dazu zum Block „Create Dictionary“ und klicken Sie auf „Add Item“. Definieren Sie die folgenden Felder:
Zone:<YOUR_WEB_UNLOCKER_API_ZONE_NAME>(z. B.„web_unlocker“)url: (vorerst leer lassen, da dieses Feld dynamisch ausgefüllt wird)format:„raw“data_format:„markdown“
Verbinden Sie anschließend den „Dictionary“-Ausgang des Blocks „Create Dictionary“ mit dem „Body“-Eingang des Blocks „Send Authenticated Web Request“: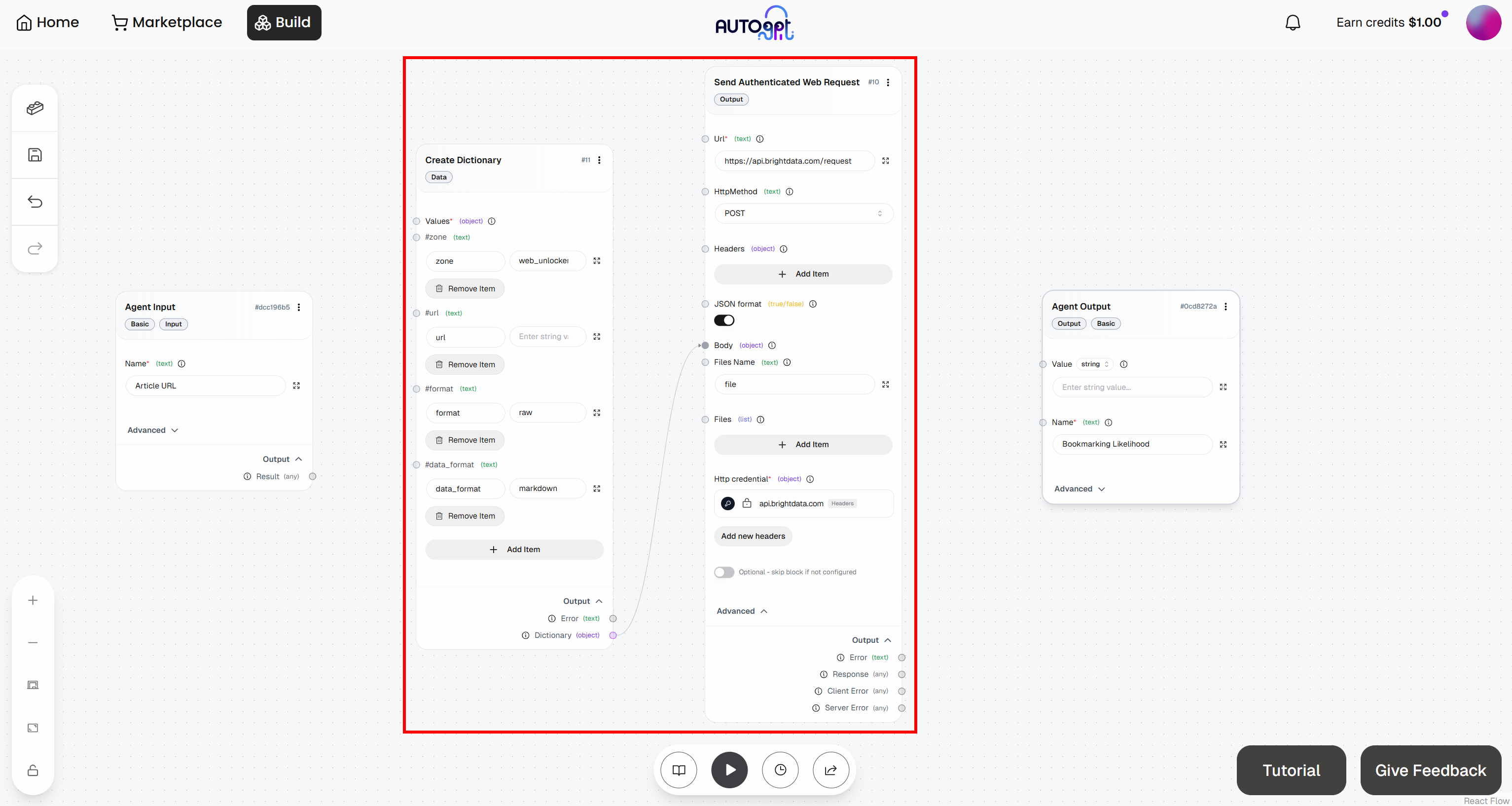
Großartig! Die Bright Data-Integration in Ihrem AutoGPT-Workflow ist nun abgeschlossen.
Schritt 7: Fügen Sie die LLM-Engine hinzu
Der letzte fehlende Block ist die LLM-Engine, die dafür zuständig ist, die über Web-Scraping mittels der Web Unlocker-API abgerufenen Markdown-Inhalte zu analysieren und ihnen einen Bookmark-Score zuzuweisen.
Da dieser Workflow im Laufe der Zeit verschiedene Artikel bewerten soll, sollte er eine konsistente, strukturierte Ausgabe liefern.
Um dieses Ziel zu erreichen, nutzen Sie den Block „KI Structured Response Generator“. Damit können Sie ein LLM anweisen, eine Aufgabe auszuführen und Ergebnisse in einem vordefinierten Format zurückzugeben.
Fügen Sie diesen Block zunächst Ihrem Workflow hinzu: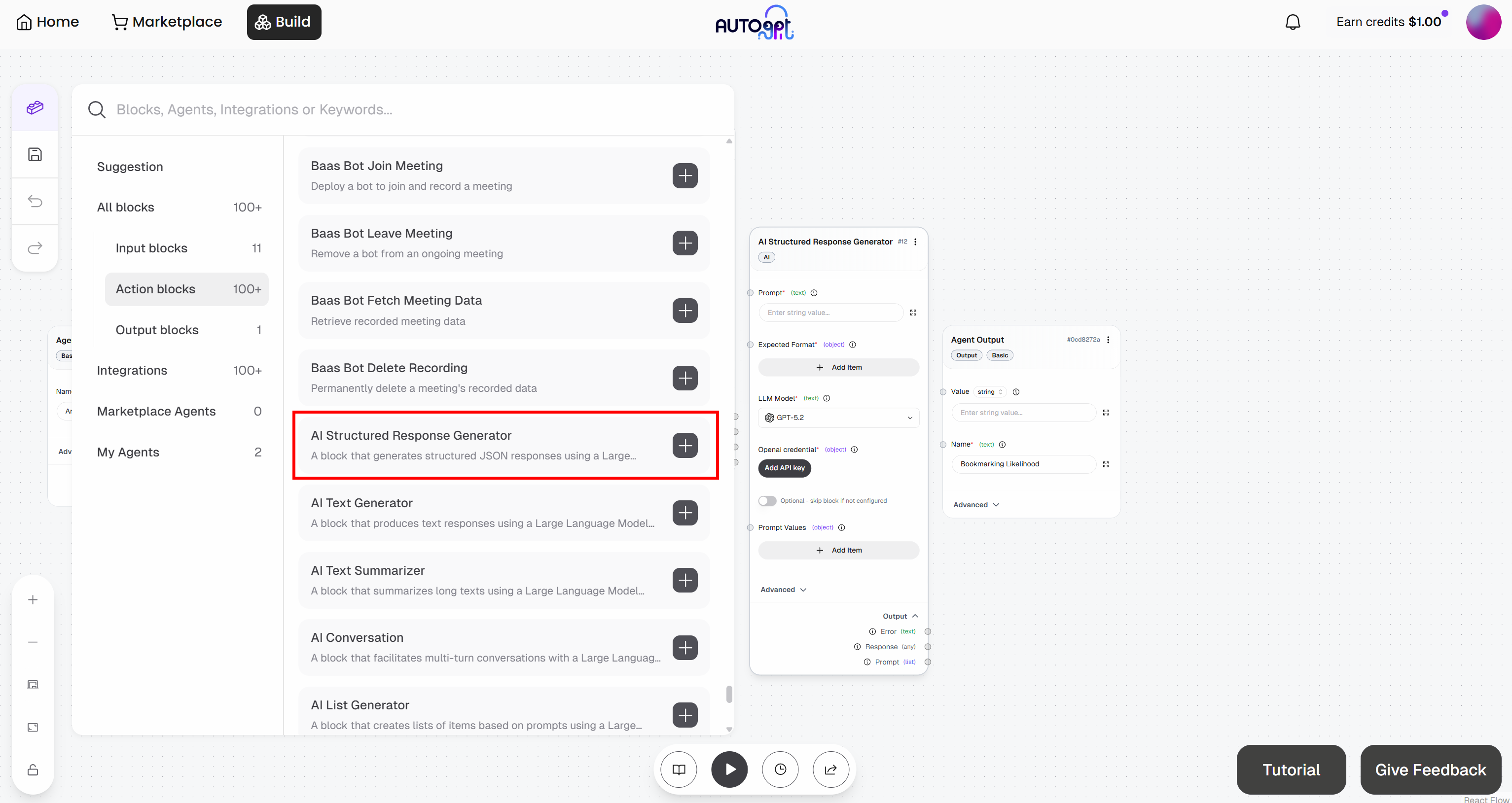
Verbinden Sie den Block mit Ihrem OpenAI-Konto, indem Sie auf die Schaltfläche „Add API Key“ klicken. Geben Sie einen Namen für Ihren Schlüssel ein, fügen Sie Ihren OpenAI-API-Schlüssel ein und klicken Sie auf „Add API Key“: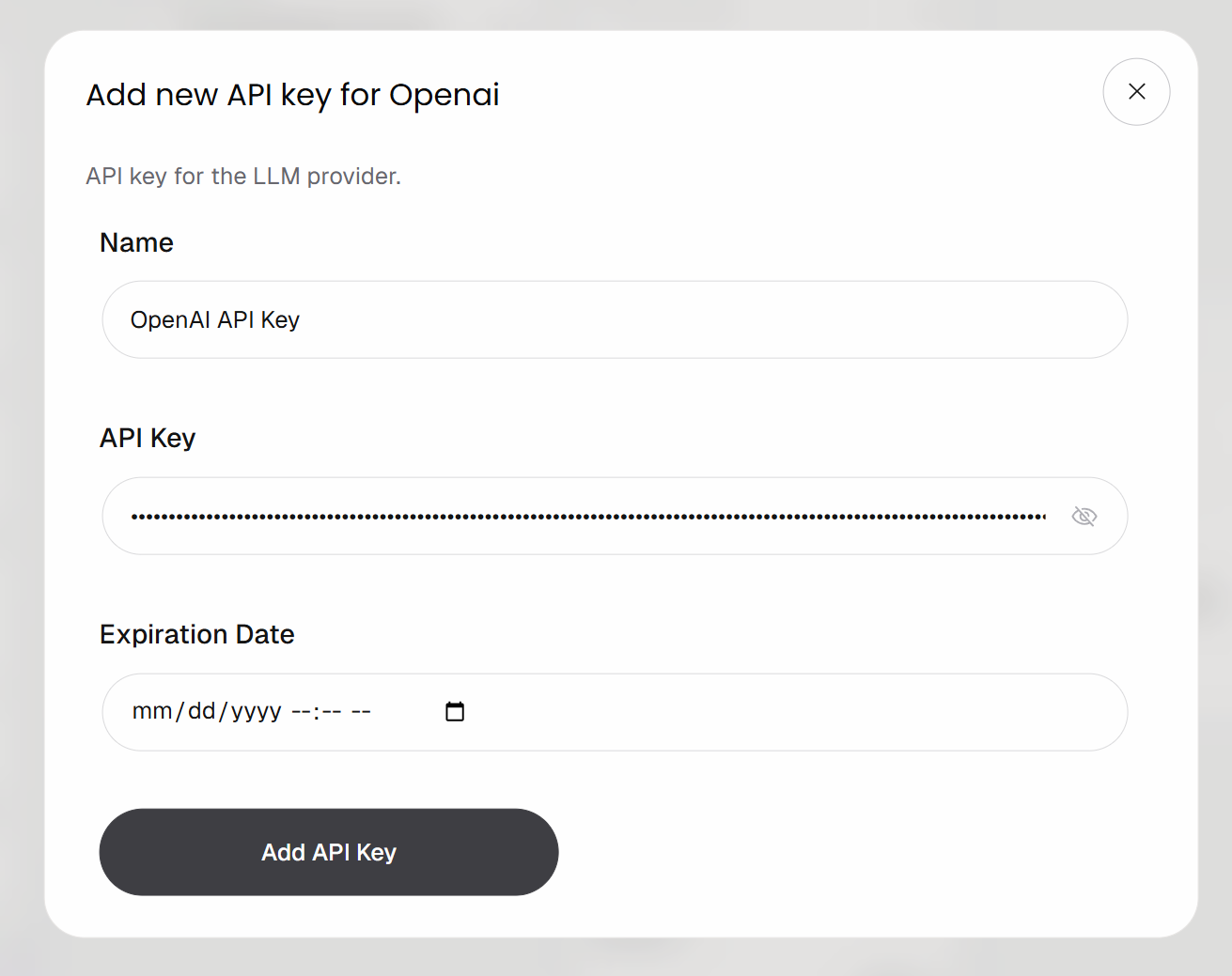
Ihr „KI Structured Response Generator“-Block ist nun authentifiziert und bereit, das konfigurierte OpenAI-Modell aufzurufen.
Füllen Sie nun den Block mit folgenden Angaben:
- Eingabeaufforderung:
Sie sind ein erfahrener Content-Bewerter.
Ihre Aufgabe ist es, den folgenden Artikel zu analysieren und zu bestimmen, wie lohnenswert es ist, ihn für spätere Referenzzwecke zu speichern.
Artikel:
„{{article}}“
Bewerten Sie den Artikel anhand folgender Kriterien:
- Praktischer Nutzen (bietet er umsetzbare Erkenntnisse?)
- Tiefe (ist er oberflächlich oder tiefgehend?)
- Signal-Rausch-Verhältnis (ist er prägnant oder voller Floskeln?)
- Wiederverwendbarkeit (lohnt es sich, später darauf zurückzukommen?)
Geben Sie ein JSON-Objekt zurück mit:
- „score“: eine ganze Zahl von 1 bis 10 (1 = nicht lesenswert, 10 = unbedingt lesen)
- „comment“: eine prägnante, menschenähnliche Erklärung (max. 1–2 Sätze)
Richtlinien:
- Sei kritisch und vermeide Überbewertungen
- Vergib höhere Bewertungen nur für Inhalte mit langfristigem Wert
- Vermeide allgemeine Kommentare
- *Modell*: GPT-5.1 Mini (oder ein anderes Allzweck-Modell von OpenAI)Beachten Sie in der Eingabeaufforderung den Platzhalter {{article}}. Dabei handelt es sich um eine Variable, die dynamisch durch einen „Prompt-Wert“ ersetzt wird. Konkret wird sie durch den Markdown-Inhalt ersetzt, der vom Block „Authentifizierte Webanfrage senden“ zurückgegeben wird.
Um einen „Prompt-Wert“ zu konfigurieren, klicken Sie auf „Element hinzufügen“ und definieren Sie eine Variable namens „article“. Verbinden Sie dann den „Response“-Ausgang des Blocks „Authentifizierte Webanfrage senden“ mit dem Prompt-Wert „article “: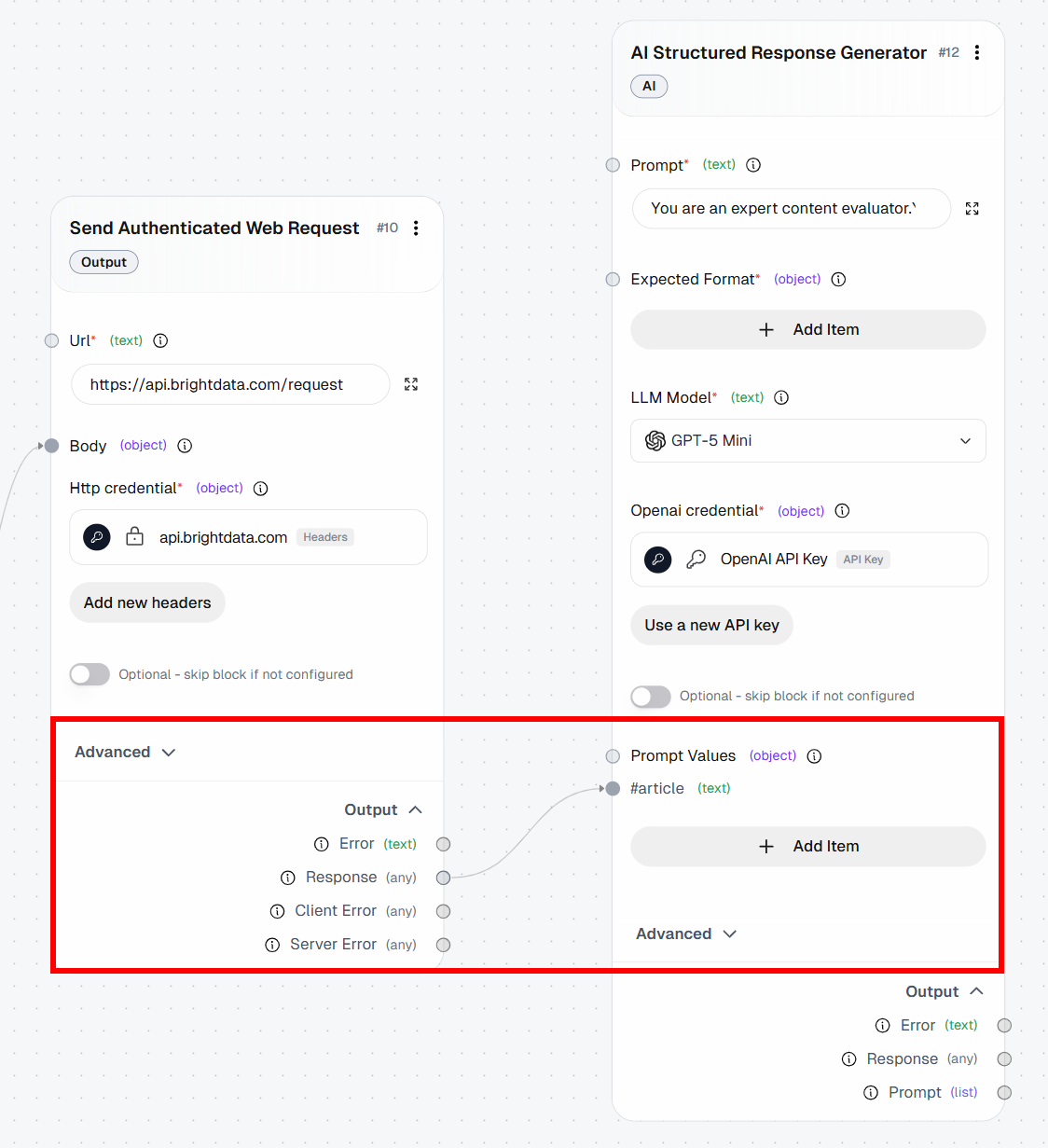
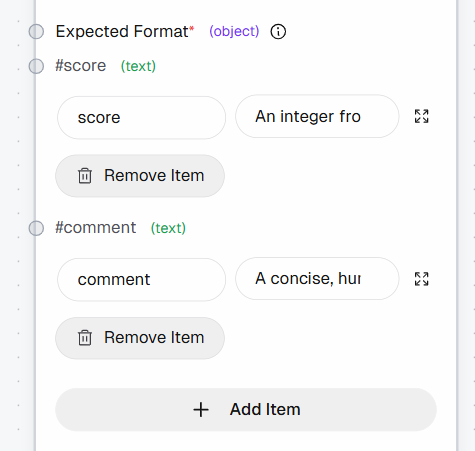
Definieren Sie als Nächstes die strukturierte Ausgabe, indem Sie die folgenden Felder zum Abschnitt „Expected Format“ hinzufügen:
score: „Eine ganze Zahl von 1 bis 10 (1 = nicht lesenswert, 10 = unbedingt lesen)“comment: „Eine prägnante, menschenähnliche Erklärung (max. 1–2 Sätze)“
Cool! Ihr von Bright Data angetriebener AutoGPT-Agent-Workflow enthält nun alle Bausteine. Es bleibt nur noch, sie alle miteinander zu verbinden.
Schritt 8: Alle Blöcke verbinden
Um den Workflow abzuschließen, verbinden Sie alle Blöcke, um eine vollständige Pipeline zu erstellen.
Verbinden Sie zunächst den „Result“-Ausgang des „Agent Input“-Blocks mit dem URL-Feld des „Create Dictionary“-Blocks. Dadurch wird sichergestellt, dass die Eingabe-URL vom Workflow-Eingang in die Web Unlocker-API-Anfrage fließt, die die Seite scrapt und das Ergebnis zur Analyse an das LLM weiterleitet.
Verbinden Sie abschließend den „Response“-Ausgang des Blocks „KI Structured Response Generator“ mit dem Block „Agent Output“. Damit ist der Workflow abgeschlossen und der Datenfluss vollständig.
So sollte Ihr endgültiger AutoGPT-Workflow aussehen, der dank Bright Data um Web-Scraping-Funktionen erweitert wurde: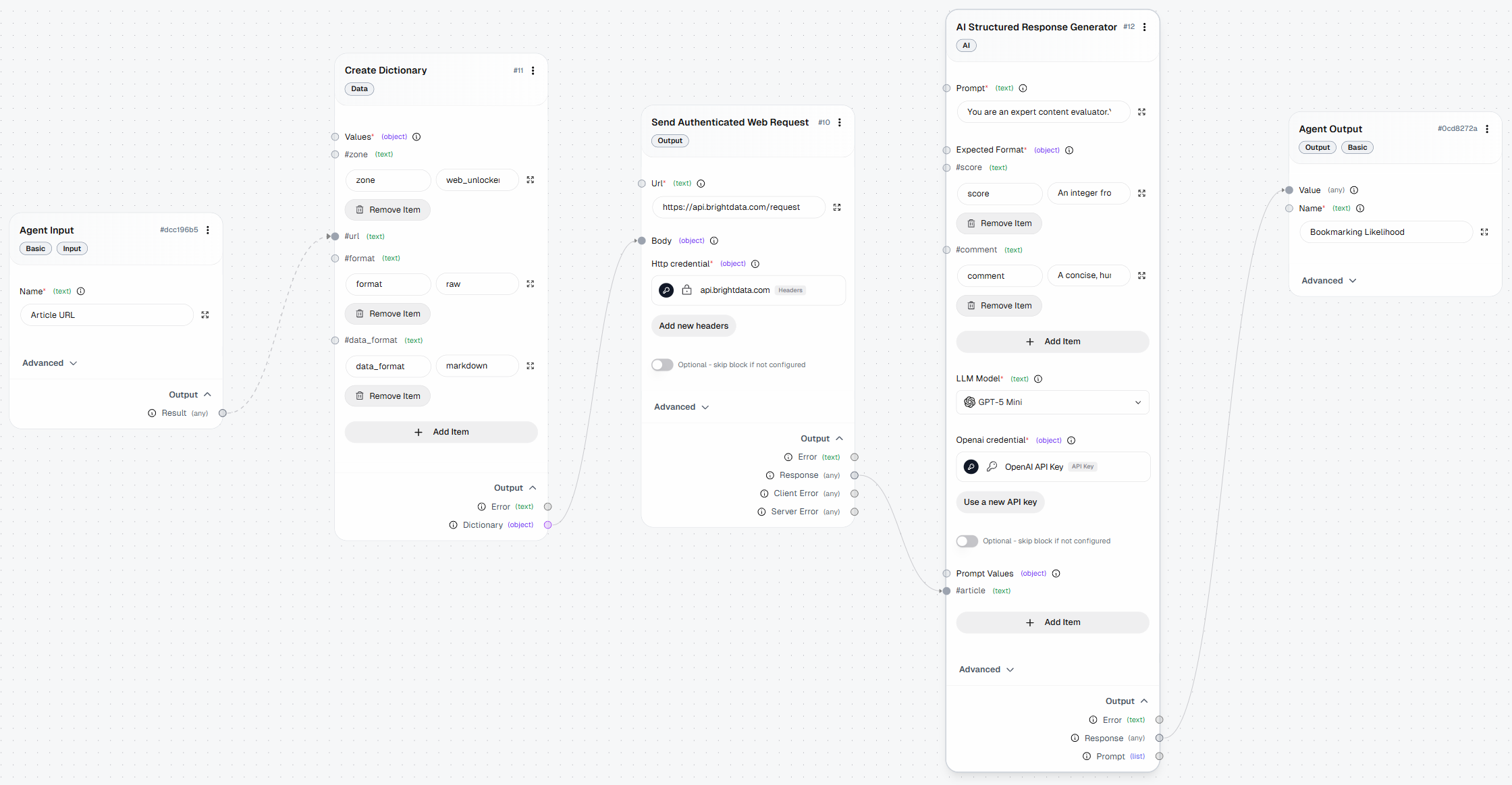
Schritt 9: Testen Sie den Agenten
Klicken Sie auf die Schaltfläche „Run agent“, um Ihren agentischen Workflow zu starten und zu testen: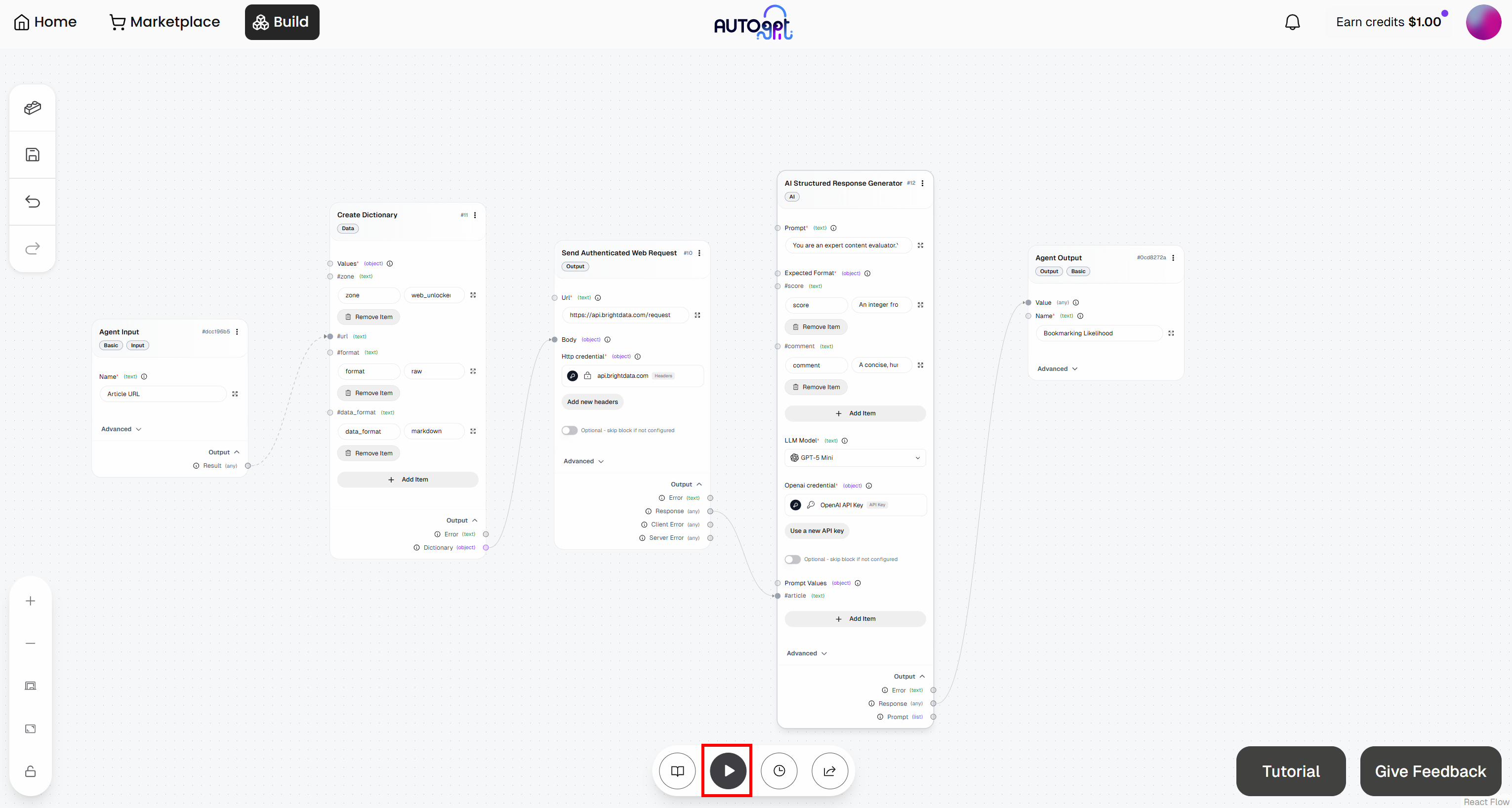
Sie werden aufgefordert, die Eingabe-URL für den Workflow (d. h. die Artikel-URL) anzugeben. Fügen Sie einen Blogbeitrag wie diesen ein:
https://awealthofcommonsense.com/2024/03/whats-the-investment-case-for-gold/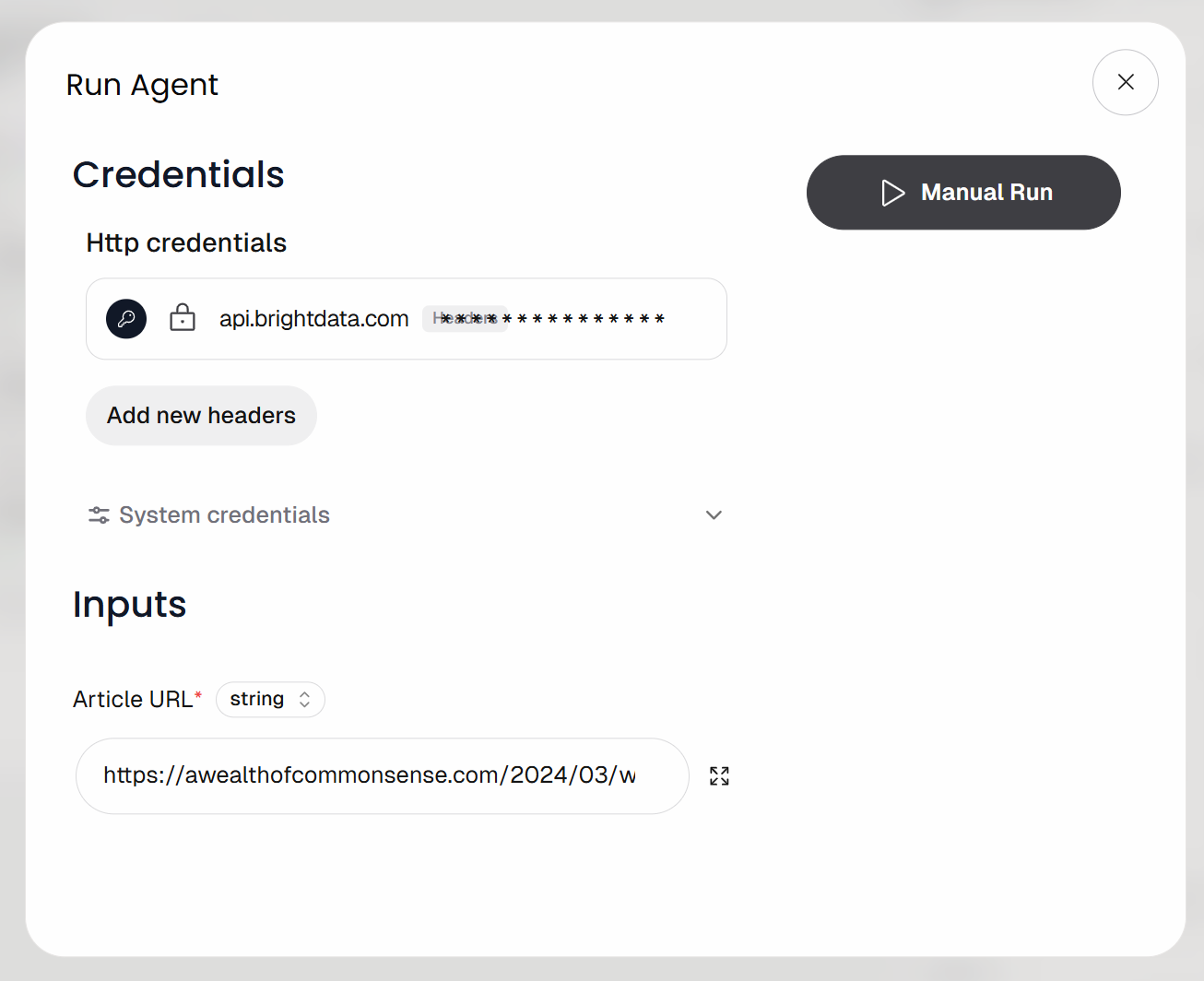
Starten Sie dann den Workflow, indem Sie auf die Schaltfläche „Manual Run“ klicken. Das sollte nun angezeigt werden: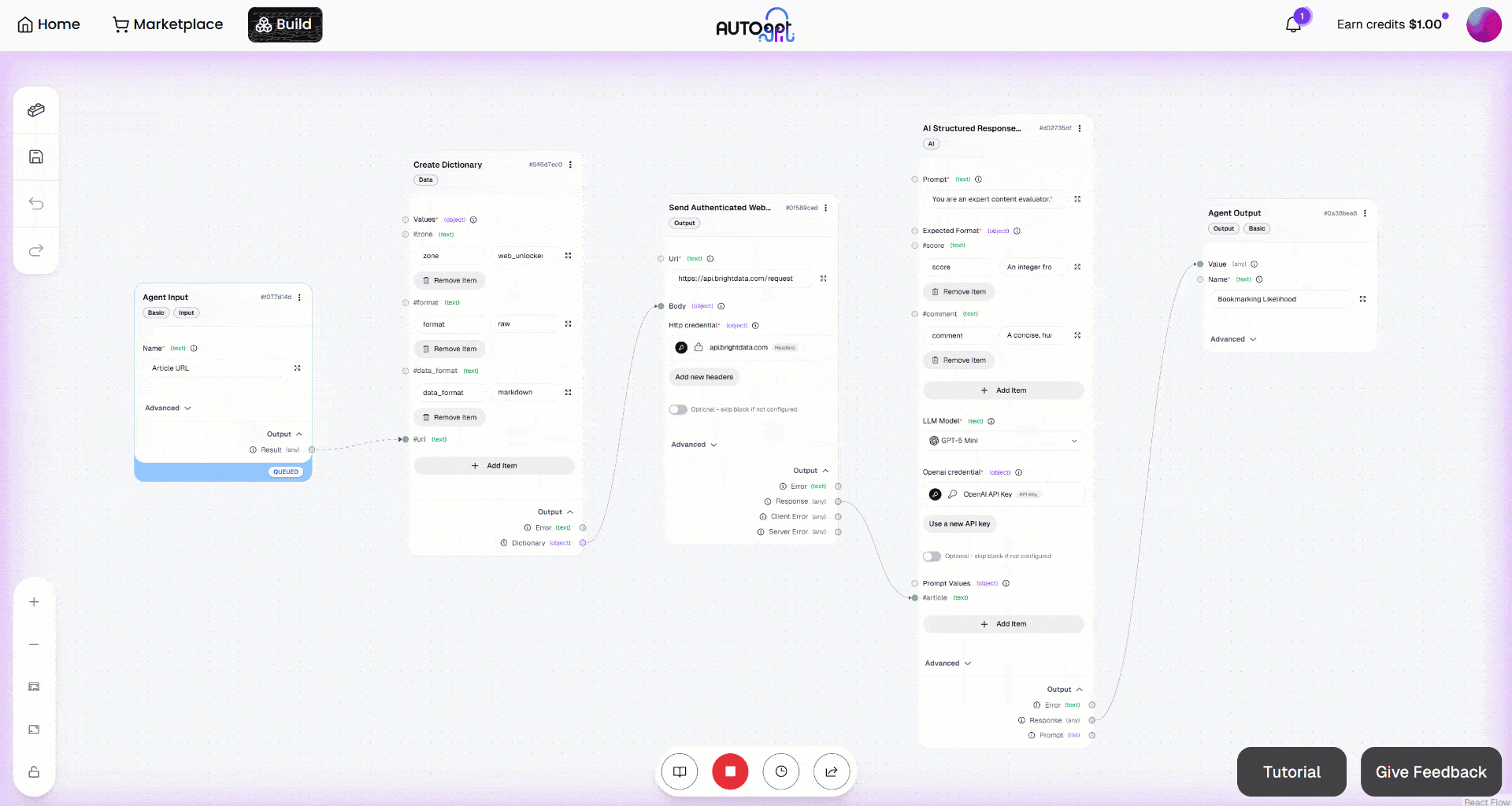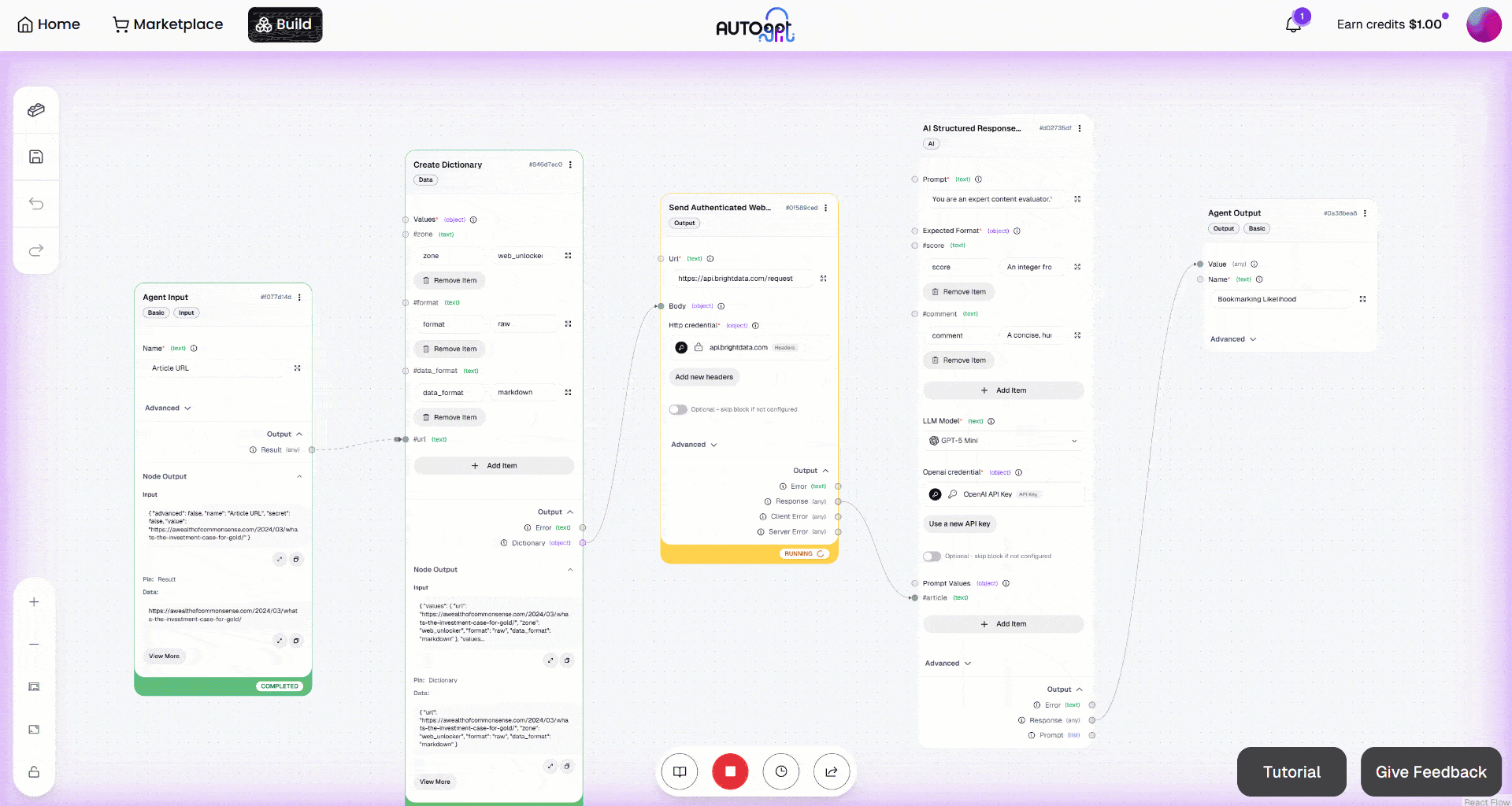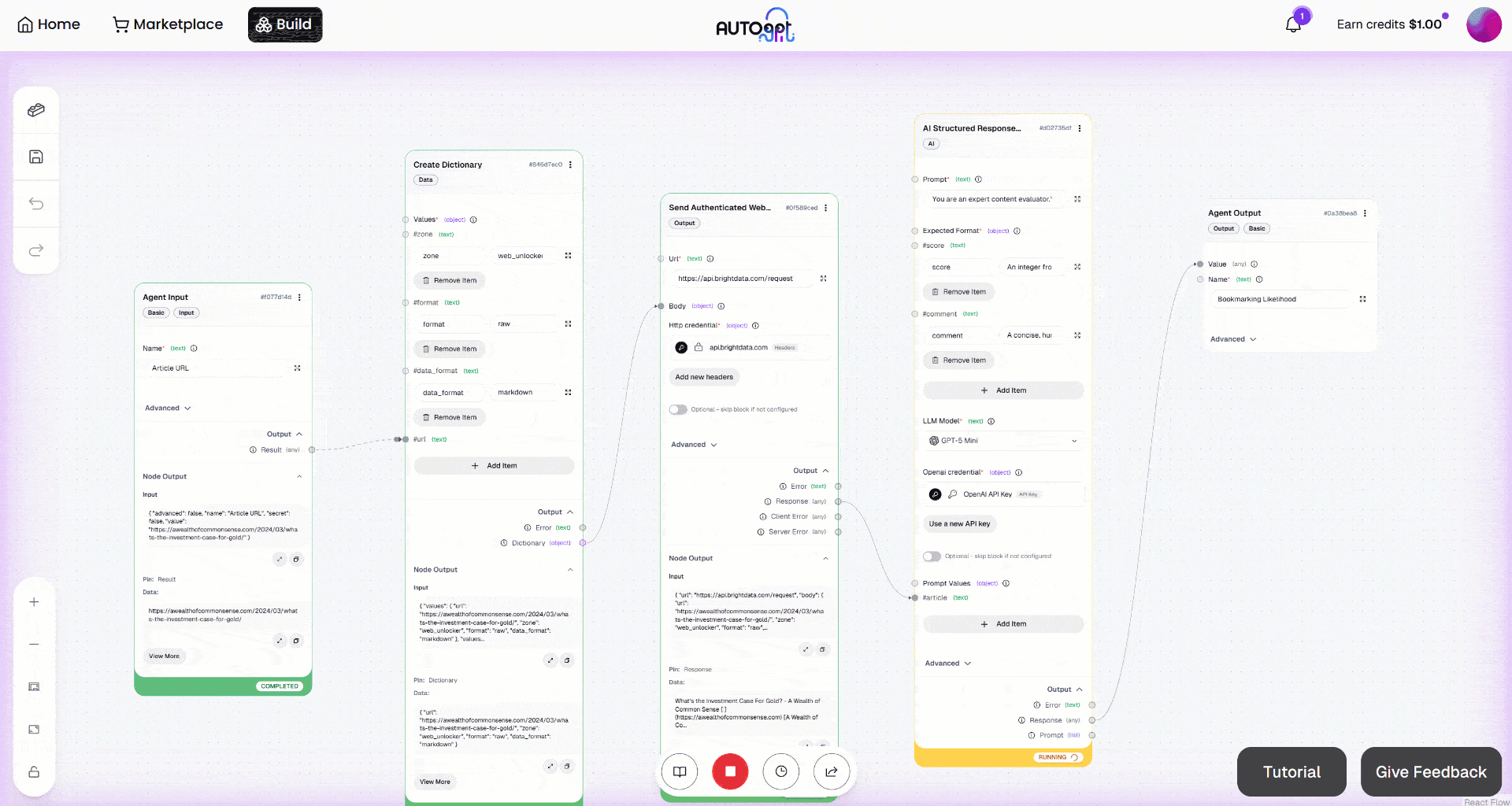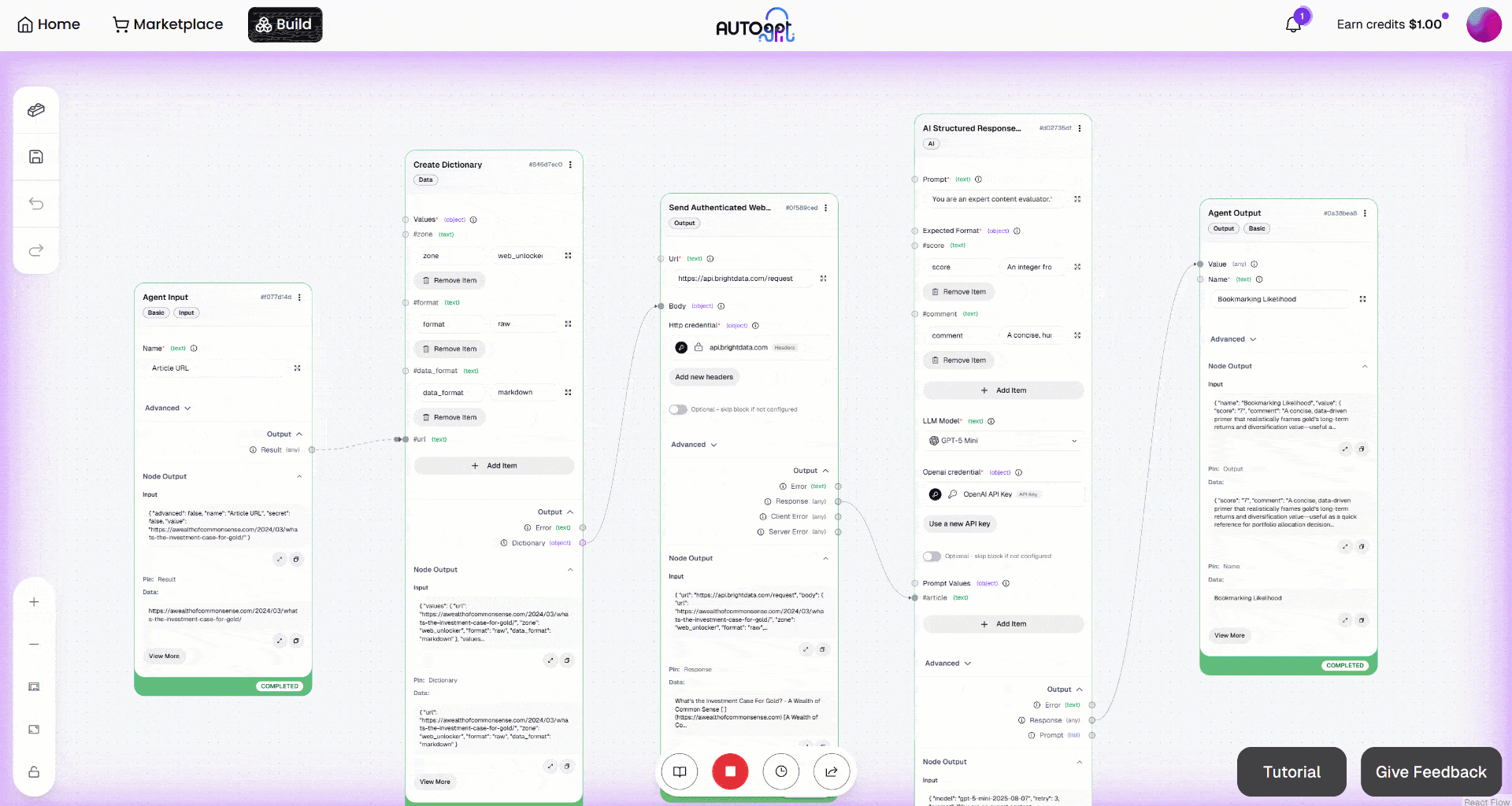
Erweitern Sie die Ausgabe im Block „Agent-Ausgabe“. Sie werden feststellen, dass der KI-Agent ein Ergebnis wie dieses erzeugt hat: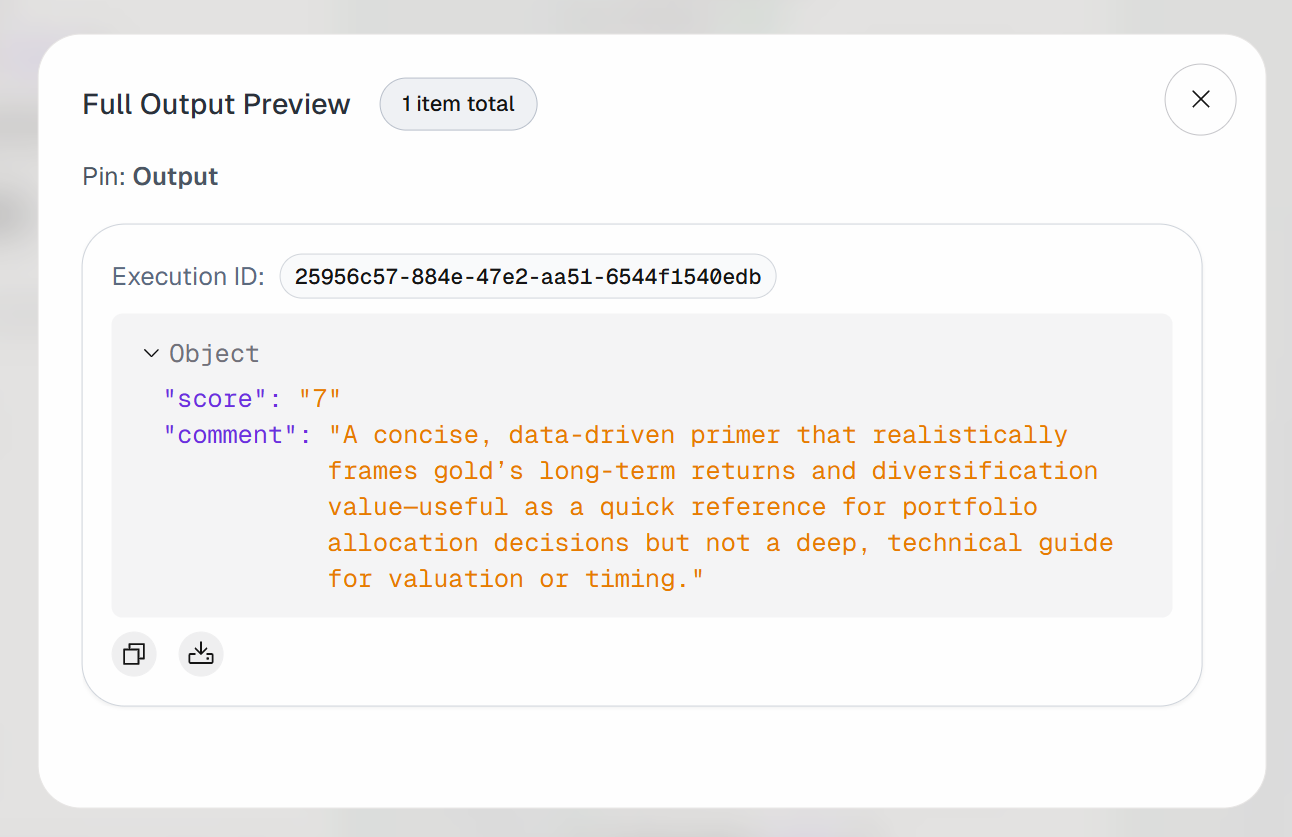
Der eingegebene Artikel wird also als wertvoll genug erachtet, um für späteres Lesen mit einem Lesezeichen versehen zu werden.
Wenn Sie die Ausgabe des Blocks „Send Authenticated Web Request“ überprüfen, werden Sie Folgendes feststellen: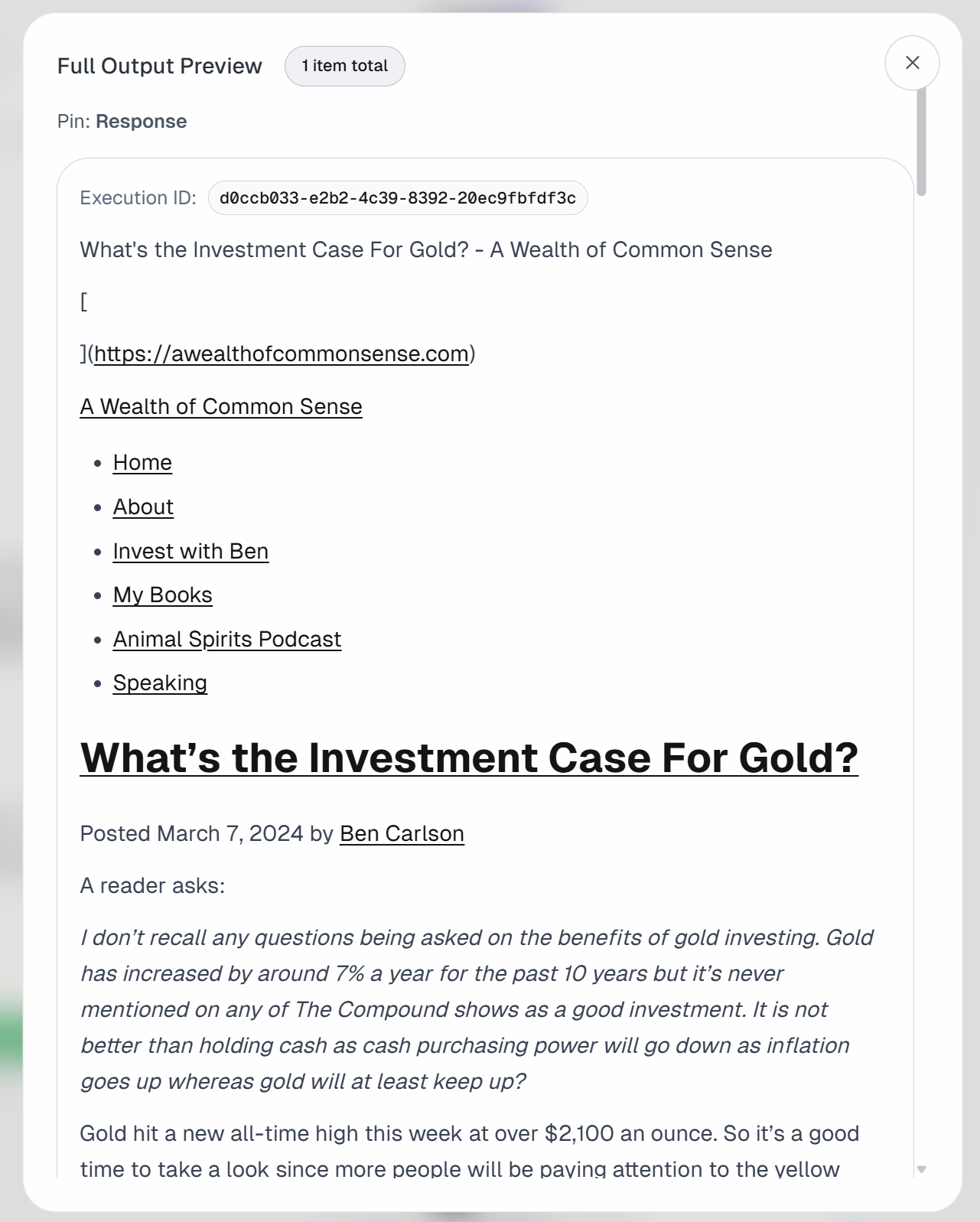
Dies entspricht der Markdown-Version des Ziel-Eingabeartikels: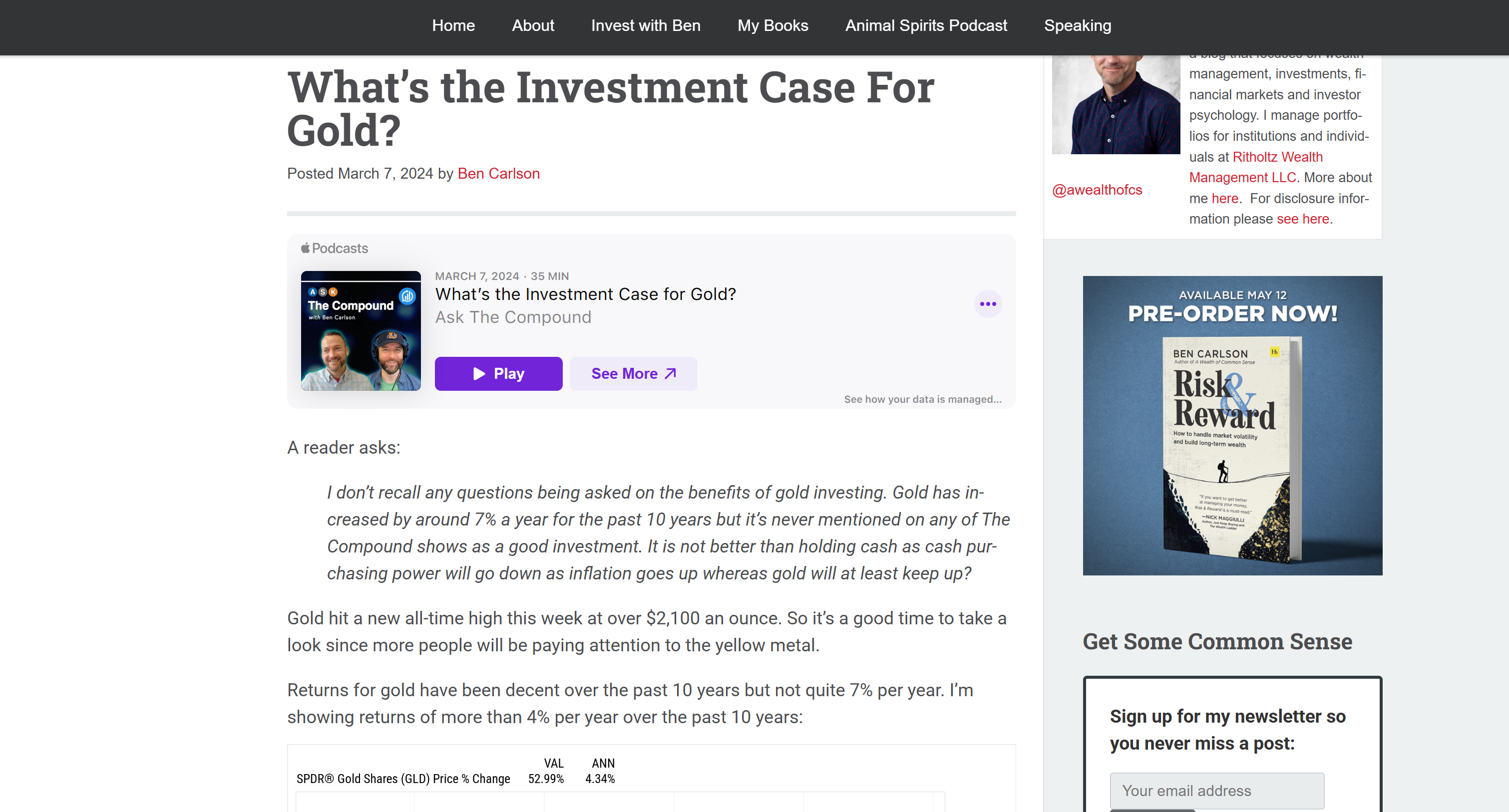
Dies bestätigt, dass die Bright Data Web Unlocker API den Seiteninhalt erfolgreich, schnell und in einem Format abgerufen hat, das die LLM-Verarbeitung effizienter und effektiver macht.
Et voilà! Sie haben soeben einen KI-Agenten in AutoGPT erstellt, der sich mit Bright Data für die dynamische Abfrage von Webdaten integriert.
Nächste Schritte
Dies war ein einfaches Beispiel, aber bedenken Sie, dass die Integration von AutoGPT und Bright Data erweitert werden kann, um weitaus komplexere agentische Workflows zu unterstützen.
Mit einem ähnlichen Ansatz können Sie Ihren Agenten beispielsweise mit anderen auf der Bright Data API basierenden Produkten verbinden, um Funktionen für die Websuche und das Crawling hinzuzufügen. Ebenso können Sie Scraping-APIs integrieren, die direkte Datenfeeds aus mehreren Domains bereitstellen.
Um Ihren Agenten leistungsfähiger zu machen, entdecken Sie die vielfältigen Möglichkeiten von AutoGPT, indem Sie sich in die offizielle Dokumentation vertiefen.
Fazit
In diesem Blogbeitrag haben Sie gelernt, wie Sie die Funktionen von Bright Data für Web-Exploration, Interaktion, Suche und Datenscraping in AutoGPT integrieren können. Dies ermöglicht es KI-Agenten, die typischen Wissens- und Interaktionsbeschränkungen von Standard-LLMs zu überwinden.
Sie haben gesehen, wie man einen einfachen KI-Agenten als Lesezeichen-Berater erstellt. Um komplexere agentische Workflows zu erstellen – die Zugriff auf Live-Web-Feeds, Websuche oder Web-Interaktionen erfordern –, integrieren Sie AutoGPT mit der gesamten Palette der Bright Data-Dienste für KI.
Erstellen Sie noch heute kostenlos ein Bright Data-Konto und beginnen Sie mit unseren KI-fähigen Webdatenlösungen zu experimentieren!





