

HtmlUnit ist ein Headless Browser, mit dem Sie HTML-Seiten modellieren können. Nach der programmatischen Modellierung der Seite können Sie mit dieser interagieren, indem Sie z. B. Formulare ausfüllen und übermitteln oder zwischen Seiten navigieren. HtmlUnit kann sowohl zum Web Scraping verwendet werden, um Daten für eine spätere Bearbeitung zu extrahieren, als auch zur Einrichtung automatisierter Tests, mit denen Sie überprüfen können, ob Ihr Programm Webseiten wie erwartet erstellt.
Web Scraping mit HtmlUnit
Um Web Scraping mit HtmlUnit und Gradle zu implementieren, wird IntelliJ IDEA verwendet; Sie können jedoch auch jede beliebige IDE bzw. den von Ihnen bevorzugten Code-Editor verwenden.
IntelliJ unterstützt eine vollständig funktionsfähige Integration mit Gradle und steht zum Download auf der JetBrains-Website bereit. Gradle ist ein Tool zur Build-Automatisierung, das den Aufbau und die Erstellung von Paketen für Ihre Anwendung unterstützt. Zudem ermöglicht es das nahtlose Hinzufügen und Verwalten von Abhängigkeiten. In den neuesten Versionen von IntelliJ IDEA sind Gradle und Gradle-Erweiterungen standardmäßig installiert und aktiviert.
Den gesamten Code für dieses Tutorial finden Sie in diesem GitHub Repo.
Erstellen eines Gradle-Projekts
Um ein neues Gradle-Projekt in der IntelliJ IDE zu erstellen, wählen Sie im Menü Datei > Neu > Projekt. Daraufhin wird der Assistent für ein neues Projekt geöffnet. Geben Sie den Namen des Projekts ein und wählen Sie den gewünschten Speicherort:

Da Sie eine Web Scraping-Anwendung in Java mit HtmlUnit erstellen werden, müssen Sie die Sprache Java auswählen. Wählen Sie außerdem das Gradle-Build-System aus. Klicken Sie anschließend auf Erstellen. Damit wird ein Gradle-Projekt mit einer Standardstruktur und sämtlichen erforderlichen Dateien erstellt. Die Datei build.gradle beispielsweise enthält alle Abhängigkeiten, die für die Erstellung dieses Projekts erforderlich sind:
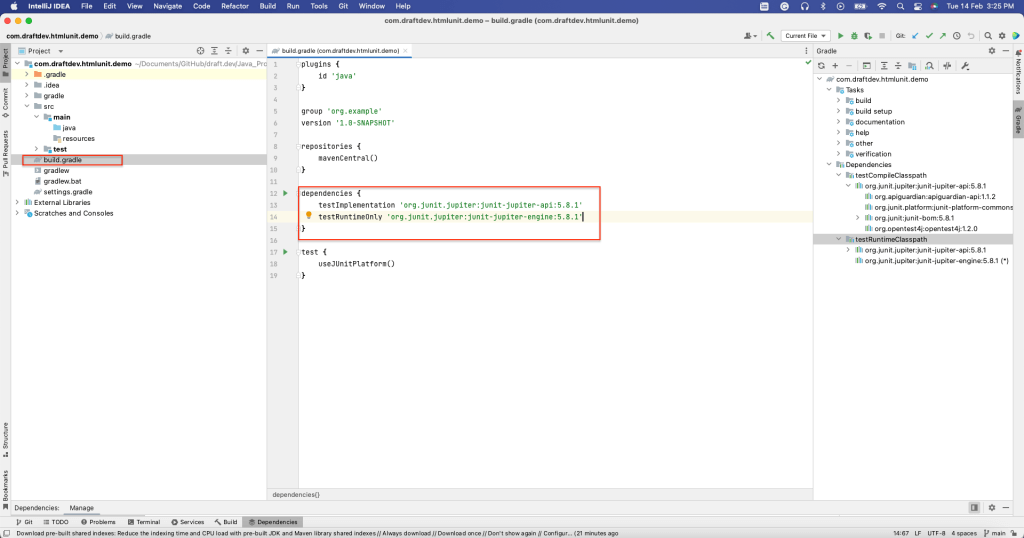
HtmlUnit installieren
Um HtmlUnit als Abhängigkeit zu installieren, öffnen Sie das Fenster Abhängigkeiten, indem Sie Ansicht > Werkzeugfenster > Abhängigkeiten auswählen.
Suchen Sie anschließend nach „htmlunit“ und wählen Sie Hinzufügen:
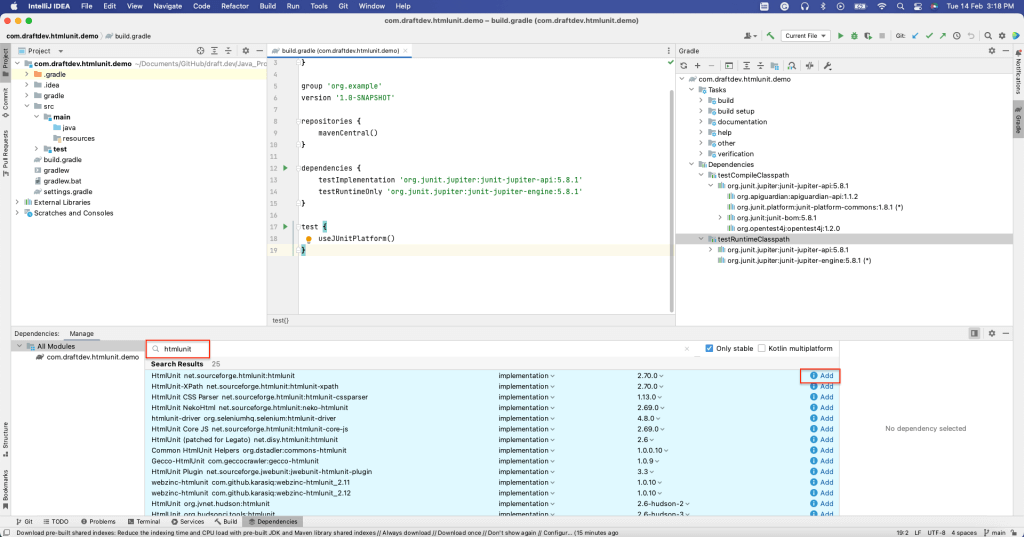
Im Abschnitt Abhängigkeiten der build.gradle-Datei sollte nun zu sehen sein, dass HtmlUnit installiert wurde:

Nach der Installation von HtmlUnit können Sie nun Daten von statischen und dynamischen Webseiten scrapen.
Scrapen einer statischen Seite
In diesem Abschnitt wird beschrieben, wie Sie HtmlUnit Wiki, eine statische Webseite, scrapen können. Diese Webseite enthält verschiedene Elemente wie z. B. Titel, Inhaltsverzeichnis, Liste der Unterüberschriften sowie die Inhalte für jede Unterüberschrift.
Jedes Element einer HTML-Webseite hat Attribute. So ist z. B. IDein Attribut, das ein Element im gesamten HTML-Dokument eindeutig identifiziert, und Name ist ein Attribut, welches das betreffende Element identifiziert. Das Attribut Name ist nicht eindeutig, so dass mehrere Elemente in einem HTML-Dokument denselben Namen haben können. Die Elemente einer Webseite können anhand eines der Attribute identifiziert werden.
Wahlweise können Sie Elemente auch mithilfe von Xpath identifizieren. XPath bedient sich einer pfadähnlichen Syntax, um Elemente im HTML-Code der Webseite zu identifizieren und durch sie zu navigieren.
In den folgenden Beispielen werden Sie beide Methoden zur Identifizierung der Elemente auf der HTML-Seite verwenden.
Zum Scrapen einer Webseite müssen Sie einen HtmlUnit WebClient erstellen. Der WebClient entspricht einem Browser innerhalb Ihrer Java-Anwendung. Das Initialisieren eines WebClients ähnelt dem Starten eines Browsers, um die Webseite anzuzeigen.
Verwenden Sie zur Initialisierung eines WebClients den folgenden Code:
WebClient webClient = new WebClient(BrowserVersion.CHROME);
Dieser Code initialisiert den Chrome-Browser. Andere Browser werden ebenfalls unterstützt.
Sie können die Webseite mit der im webClient-Objekt verfügbaren Methode getPage() abrufen. Anschließend können Sie die Daten der Webseite mithilfe unterschiedlicher Methoden auslesen.
Um den Seitentitel zu erhalten, verwenden Sie die Methode getTitleText() wie im nachfolgenden Code gezeigt:
String webPageURl = u0022https://en.wikipedia.org/wiki/HtmlUnitu0022;n try {nn HtmlPage page = webClient.getPage(webPageURl);n n System.out.println(page.getTitleText());n n } catch (FailingHttpStatusCodeException | IOException e) {n n e.printStackTrace();n n }
Daraufhin wird der Seitentitel gedruckt:
HtmlUnit - Wikipedia
Nun gehen wir einen Schritt weiter und rufen alle auf der Webseite verfügbaren H2-Elemente ab. In diesem Beispiel sind H2s in zwei Bereichen der Seite vorhanden:
- In der linken Seitenleiste, wo das Inhaltsverzeichnis angezeigt wird: Wie Sie sehen können, ist die Überschrift des Inhaltsverzeichnisses ein H2-Element.
- Im Hauptteil der Seite: Alle Unterüberschriften sind H2-Elemente.
Um sämtliche H2-Elemente im Hauptteil abzurufen, können Sie den XPath der H2-Elemente verwenden. Klicken Sie mit der rechten Maustaste auf ein beliebiges H2-Element und wählen Sie Untersuchen, um den XPath zu finden. Klicken Sie anschließend mit der rechten Maustaste auf das markierte Element und wählen Sie Kopieren > Vollständigen XPath kopieren:
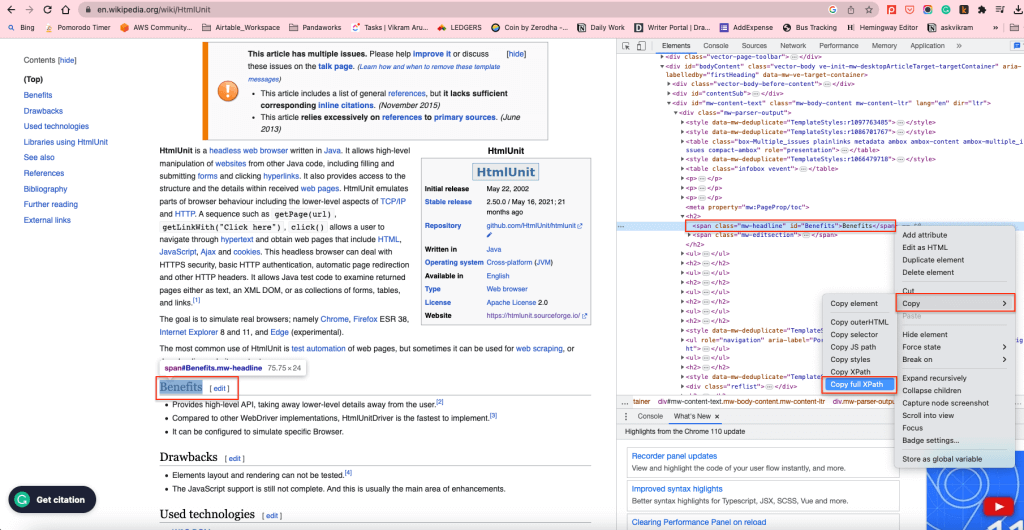
Damit wird der XPath in die Zwischenablage kopiert. Beispiel: Das XPath-Element der H2-Elemente im Hauptteil mit den Inhalten lautet /html/body/div[1]/div/div[3]/main/div[2]/div[3]/div[1]/h2.
Um sämtliche H2-Elemente über ihren XPath abzurufen, können Sie die Methode getByXpath() verwenden:
String xPath = u0022/html/body/div[1]/div/div[3]/main/div[2]/div[3]/div[1]/h2u0022;nn String webPageURL = u0022https://en.wikipedia.org/wiki/HtmlUnitu0022;n n try {n HtmlPage page = webClient.getPage(webPageURL);nn //Get all the headings using its XPath+n Listu003cHtmlHeading2u003e h2 = (Listu003cHtmlHeading2u003e)(Object) page.getByXPath(xPath);n n //print the first heading text contentn System.out.println((h2.get(0)).getTextContent());nn } catch (FailingHttpStatusCodeException | IOException e) {n n e.printStackTrace();n n }
Der Textinhalt des ersten H2-Elements wird wie folgt ausgegeben:
Benefits[edit]
Auf ähnliche Weise können Sie die Elemente über ihre ID mit der Methode getElementById() bzw. über ihren Namen mit der Methode getElementByName() abrufen.
Im folgenden Abschnitt wenden Sie diese Methoden zum Scrapen einer dynamischen Webseite an.
Scrapen einer dynamischen Webseite mit HtmlUnit
In diesem Abschnitt lernen Sie durch Ausfüllen und Absenden des Anmeldeformulars die Funktionen von HtmlUnit zum Ausfüllen von Formularen und Anklicken von Schaltflächen kennen. Sie erfahren außerdem, wie Sie mit dem Headless Browser durch Webseiten navigieren können.
Zur Veranschaulichung des Scrapings dynamischer Webseiten verwenden wir die Website von Hacker News. So sieht die Anmeldeseite aus:

Der folgende Code ist der HTML-Formularcode für diese Seite. Sie können diesen Code aufrufen, indem Sie mit der rechten Maustaste auf das Login-Label und anschließend auf Untersuchen klicken:
u003cform action=u0022loginu0022 method=u0022postu0022u003enu003cinput type=u0022hiddenu0022 name=u0022gotou0022 value=u0022newsu0022u003enu003ctable border=u00220u0022u003enu003ctbodyu003enu003ctru003eu003ctdu003eusername:u003c/tdu003eu003ctdu003eu003cinput type=u0022textu0022 name=u0022acctu0022 size=u002220u0022 autocorrect=u0022offu0022 spellcheck=u0022falseu0022 autocapitalize=u0022offu0022 autofocus=u0022trueu0022u003eu003c/tdu003eu003c/tru003enu003ctru003eu003ctdu003epassword:u003c/tdu003eu003ctdu003eu003cinput type=u0022passwordu0022 name=u0022pwu0022 size=u002220u0022u003eu003c/tdu003eu003c/tru003eu003c/tbodyu003eu003c/tableu003eu003cbru003enu003cinput type=u0022submitu0022 value=u0022loginu0022u003eu003c/formu003e
Um das Formular mithilfe von HtmlUnit auszufüllen, rufen Sie die Webseite mithilfe des webClient-Objekts auf. Die Seite enthält zwei Formulare: Login und Konto erstellen. Sie können das Anmeldeformular unter Verwendung der Methode getForms().get(0) abrufen. Wahlweise können Sie, sofern die Formulare einen eindeutigen Namen haben, auch die Methode getFormByName() verwenden.
Im nächsten Schritt müssen Sie die Formulareingaben (d. h. die Felder Benutzername und Passwort mithilfe der Methode getInputByName() und des Attributs Name abrufen.
Legen Sie die Werte für Benutzername und Passwort in den Eingabefeldern mithilfe der Methode setValueAttribute() fest und rufen Sie die Schaltfläche Senden mit der Methode getInputByValue() ab. Sie können die Schaltfläche auch mithilfe der Methode click() anklicken.
Sobald die Schaltfläche angeklickt wurde und die Anmeldung erfolgreich war, wird die Zielseite der Schaltfläche Senden als HTMLPage-Objekt ausgegeben, das für weitere Operationen verwendet werden kann.
Der folgende Code illustriert, wie man das Formular abruft, ausfüllt und übermittelt:
HtmlPage page = null;nnString webPageURl = u0022https://en.wikipedia.org/wiki/HtmlUnitu0022;nn try {n // Get the first pagenn HtmlPage signUpPage = webClient.getPage(webPageURL);nn // Get the form using its index. 0 returns the first form.n HtmlForm form = signUpPage.getForms().get(0);nn //Get the Username and Password field using its namen HtmlTextInput userField = form.getInputByName(u0022acctu0022);n HtmlInput pwField = form.getInputByName(u0022pwu0022);n n //Set the User name and Password in the appropriate fieldsn userField.setValueAttribute(u0022draftdemoacctu0022);n pwField.setValueAttribute(u0022test@12345u0022);nn //Get the submit button using its Valuen HtmlSubmitInput submitButton = form.getInputByValue(u0022loginu0022);nn //Click the submit button, and it'll return the target page of the submit buttonn page = submitButton.click();nnn } catch (FailingHttpStatusCodeException | IOException e) {n e.printStackTrace();n }
Nach Absenden des Formulars und erfolgreicher Anmeldung werden Sie zur Startseite des Benutzers weitergeleitet, auf der der Benutzername in der rechten Ecke angezeigt wird:
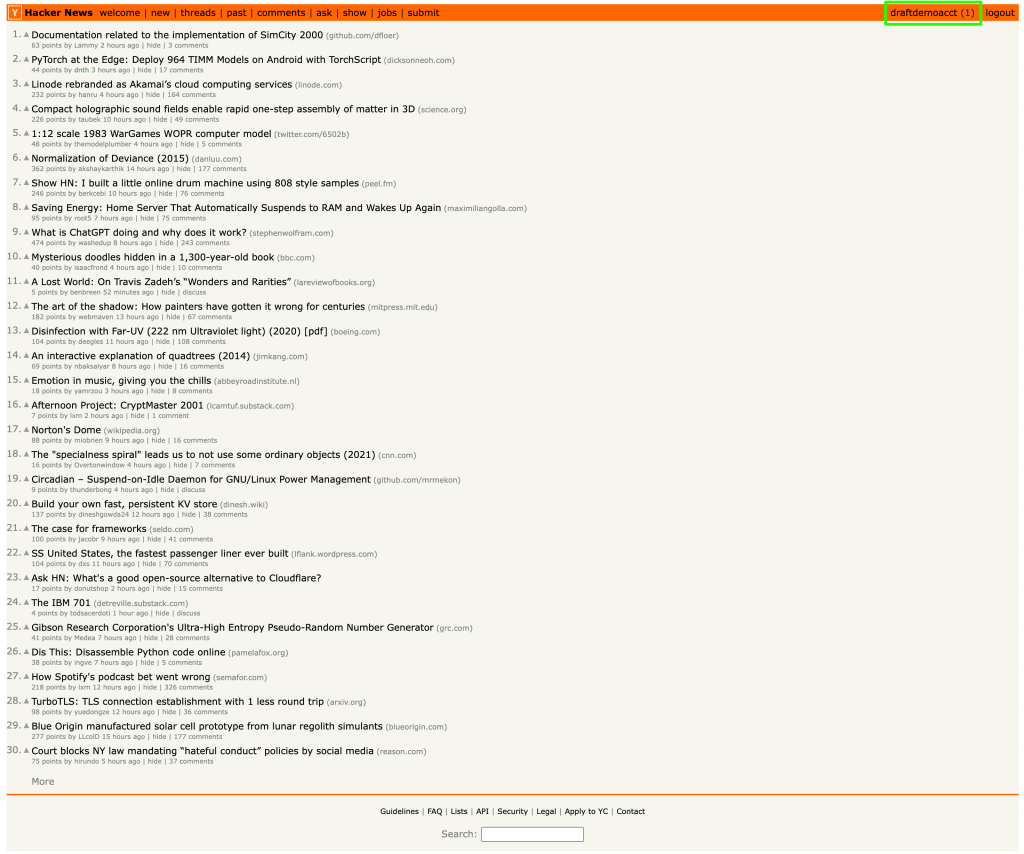
Das Benutzernamen-Element hat die ID „me“. Sie können den Benutzernamen mithilfe der Methode getElementById() abrufen und die ID „me“ wie im folgenden Code gezeigt übertragen:
System.out.println(page.getElementById(u0022meu0022).getTextContent());
Der Benutzername der Website wird ausgelesen und als Output angezeigt:
draftdemoacct
Danach müssen Sie zur zweiten Seite von Hacker News navigieren, indem Sie auf die Hyperlink-Schaltfläche Mehr am Ende der Seite klicken:

Um das Objekt der Schaltfläche Mehr zu erhalten, rufen Sie mithilfe der Funktion Untersuchen den XPath der Schaltfläche Mehr und über den Index 0 das erste Link-Objekt ab:
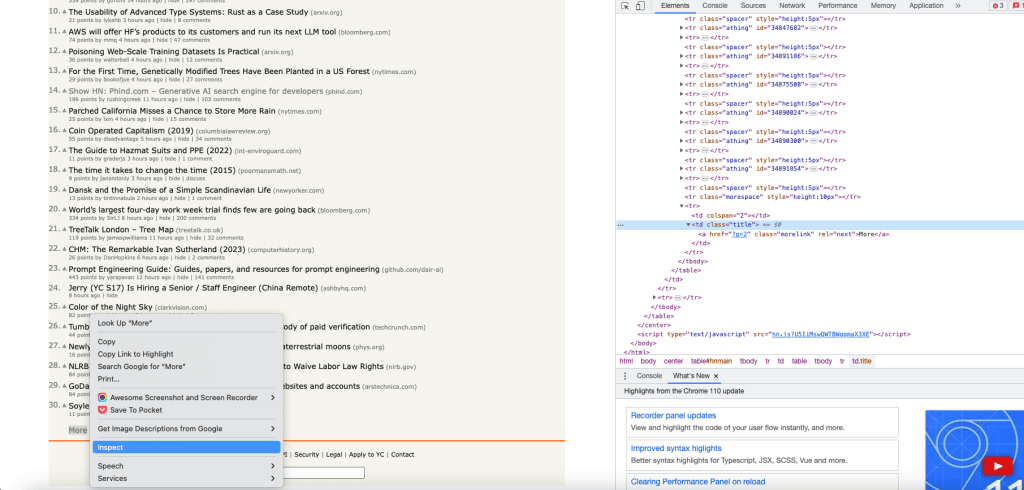
Klicken Sie mit der Methode click() auf den Link Mehr. Der Link wird angeklickt und die Zielseite des Links wird als HtmlPage-Objekt ausgegeben:
HtmlPage nextPage = null;nn try {n Listu003cHtmlAnchoru003e links = (Listu003cHtmlAnchoru003e)(Object)page.getByXPath(u0022html/body/center/table/tbody/tr[3]/td/table/tbody/tr[92]/td[2]/au0022);n n HtmlAnchor anchor = links.get(0);n n nextPage = anchor.click();nn } catch (IOException e) {n throw new RuntimeException(e);n }
An dieser Stelle sollte Ihnen die zweite Seite im HtmlPage-Objekt vorliegen.
Sie können die URL der <code>HtmlPage</code> ausdrucken, um zu überprüfen, ob die zweite Seite erfolgreich geladen wurde:
System.out.println(nextPage.getUrl().toString());
Dies ist die URL der zweiten Seite:
https://news.ycombinator.com/news?p=2
Jede Seite der Website Hacker News umfasst 30 Einträge. Daher beginnen die Einträge auf der zweiten Seite mit der laufenden Nummer 31.
Rufen wir nun die ID des ersten Eintrags auf der zweiten Seite ab und prüfen, ob sie 31 lautet. Ermitteln Sie
wie zuvor den XPath des ersten Eintrags mithilfe der Funktion Untersuchen. Anschließend rufen Sie den ersten Eintrag aus der Liste ab und lassen dessen Textinhalt anzeigen:
String firstItemId = null;nn Listu003cObjectu003e entries = nextPage.getByXPath(u0022/html/body/center/table/tbody/tr[3]/td/table/tbody/tr[1]/td[1]/spanu0022);nn HtmlSpan span = (HtmlSpan) (entries.get(0));nn firstItemId = span.getTextContent();n n System.out.println(firstItemId);
Nun wird die ID des ersten Eintrags angezeigt:
31.
Dieser Code zeigt Ihnen, wie Sie mit HtmlUnit das Formular ausfüllen, auf die Schaltflächen klicken und durch Webseiten navigieren können.
Fazit
In diesem Artikel haben Sie gelernt, wie man mithilfe von HtmlUnit statische und dynamische Webseiten scrapen kann. Darüber hinaus haben Sie durch das Scraping von Webseiten und deren Umwandlung in strukturierte Daten einige der fortgeschrittenen Fähigkeiten von HtmlUnit entdeckt.
Wenn Sie dies mit einer IDE wie IntelliJ IDEA durchführen, müssen Sie durch manuelle Überprüfung Elementattribute finden und Scraping-Funktionen unter Verwendung der Elementattribute von Grund auf neu schreiben. Im Vergleich dazu bietet die Web Scraper IDE von Bright Data eine robuste, blockierungsfreie Proxy-Infrastruktur, praktische Scraping-Funktionen und Code-Vorlagen für beliebte Websites. Eine effiziente Proxy-Infrastruktur ist erforderlich, wenn es darum geht, eine Webseite ohne IP-Blockierung und Ratenbegrenzung zu scrapen. Proxys sind auch bei der Emulation eines Benutzers von einem anderen Ort aus hilfreich.
Talk to one of Bright Data’s experts and find the right solution for your business.





