

In diesem Leitfaden gehen wir auf folgende Punkte ein:
- Was ist Jsoup?
- Voraussetzungen
- Erstellen eines Web Scrapers mit Jsoup
- Fazit
Was ist Jsoup?
Jsoup ist ein Java-HTML-Parser. Mit anderen Worten: Jsoup ist eine Java-Bibliothek, die es Ihnen ermöglicht, jedes beliebige HTML-Dokument zu parsen. Mit Jsoup können Sie eine lokale HTML-Datei parsen oder ein Remote-HTML-Dokument von einer URL herunterladen.
Darüber hinaus bietet Jsoup eine Vielzahl von Methoden für den Umgang mit dem DOM. Sie können CSS-Selektoren und Jquery-ähnliche Methoden verwenden, um HTML-Elemente auszuwählen und aus ihnen Daten zu extrahieren. Daher ist Jsoup eine effektive Java-Bibliothek zum Web Scraping für Anfänger und Profis.
Jsoup ist jedoch nicht die einzige Bibliothek, die Web Scraping in Java ermöglicht. HtmlUnit ist eine weitere beliebte Java-Bibliothek zum Web Scraping. Sehen Sie sich unsere HtmlUnit-Anleitung zum Web Scraping in Java an.
Voraussetzungen
Bevor Sie die erste Zeile Code schreiben, müssen die nachstehenden Voraussetzungen erfüllt sein:
- Java >= 8: jede beliebige Java-Version ab Version 8 oder höher ist ausreichend. Wir empfehlen Download und Installation einer LTS-Version (Long Term Support) von Java. Dieses Tutorial basiert auf Java 17. Zum Zeitpunkt der Erstellung der vorliegenden Anleitung stellt Java 17 die neueste LTS-Version von Java dar.
- Maven oder Gradle: Wählen Sie das von Ihnen bevorzugte Java-Automatisierungstool. Maven oder Gradle werden insbesondere aufgrund ihrer Funktionen zur Verwaltung von Abhängigkeiten benötigt.
- Eine fortgeschrittene IDE, die Java unterstützt: Jede IDE, die Java mit Maven oder Gradle unterstützt, ist geeignet. Dieses Tutorial basiert auf IntelliJ IDEA, der wahrscheinlich besten auf dem Markt erhältlichen Java-IDE.
Rufen Sie die oben stehenden Links auf, um alle erforderlichen Komponenten herunterzuladen und zu installieren, damit sämtliche Voraussetzungen erfüllt sind. Richten Sie der Reihe nach Java, Maven oder Gradle und eine IDE für Java ein. Befolgen Sie die offiziellen Installationsanleitungen, um häufig auftretende Probleme und Fehler zu vermeiden.
Nun wollen wir überprüfen, ob Sie alle Voraussetzungen erfüllen.
Stellen Sie sicher, dass Java ordnungsgemäß konfiguriert ist
Öffnen Sie Ihr Terminal. Mithilfe des nachstehenden Befehls können Sie überprüfen, ob Java ordnungsgemäß installiert und der Java-PATH richtig eingerichtet wurde:
java -versionDieser Befehl sollte in etwa das folgende Ergebnis liefern:
java version "17.0.5" 2022-10-18 LTS
Java(TM) SE Runtime Environment (build 17.0.5+9-LTS-191)
Java HotSpot(TM) 64-Bit Server VM (build 17.0.5+9-LTS-191, mixed mode, sharing)Stellen Sie sicher, dass Maven oder Gradle installiert ist
Wenn Sie Maven gewählt haben, führen Sie folgenden Befehl in Ihrem Terminal aus:
mvn -vDaraufhin sollten Sie einige Informationen über die von Ihnen konfigurierte Version von Maven erhalten:
Apache Maven 3.8.6 (84538c9988a25aec085021c365c560670ad80f63)
Maven home: C:Mavenapache-maven-3.8.6
Java version: 17.0.5, vendor: Oracle Corporation, runtime: C:Program FilesJavajdk-17.0.5
Default locale: en_US, platform encoding: Cp1252
OS name: "windows 11", version: "10.0", arch: "amd64", family: "windows"Wenn Sie Gradle gewählt haben, führen Sie folgenden Befehl in Ihrem Terminal aus:
gradle -vDies sollte Ihnen auch Informationen über die installierte Version von Gradle liefern, wie nachfolgend dargestellt:
------------------------------------------------------------
Gradle 7.5.1
------------------------------------------------------------
Build time: 2022-08-05 21:17:56 UTC
Revision: d1daa0cbf1a0103000b71484e1dbfe096e095918
Kotlin: 1.6.21
Groovy: 3.0.10
Ant: Apache Ant(TM) version 1.10.11 compiled on July 10 2021
JVM: 17.0.5 (Oracle Corporation 17.0.5+9-LTS-191)
OS: Windows 11 10.0 amd64Klasse! Jetzt können Sie lernen, wie das Web Scraping mit Jsoup in Java funktioniert!
Erstellen eines Web Scrapers mit Jsoup
Hier lernen Sie, wie Sie mit Jsoup ein Skript zum Web Scraping erstellen. Dieses Skript wird in der Lage sein, Daten automatisch aus einer Website zu extrahieren. Die Zielwebsite für unser Projekt ist Quotes to Scrape. Falls Sie damit noch nicht vertraut sein sollten: Es handelt sich um nichts anderes als eine Testumgebung für Web Scraping.
So sieht Quotes to Scrape aus:

Wie Sie sehen können, enthält die Zielwebsite schlicht und einfach eine paginierte Liste mit Zitaten. Der Jsoup Web Scraper hat die Aufgabe, jede Seite zu durchsuchen, sämtliche Zitate abzurufen und diese Daten im CSV-Format zurückzugeben.
Folgen Sie jetzt unserem Jsoup-Tutorial Schritt für Schritt und lernen Sie, wie Sie einen einfachen Web Scraper erstellen können!
Schritt 1: Erstellen eines Java-Projekts
Hier erfahren Sie, wie Sie ein Java-Projekt in IntelliJ IDEA 2022.2.3 initialisieren. Bitte beachten Sie, dass jede andere IDE ebenfalls geeignet ist. In IntelliJ IDEA genügen wenige Klicks, um ein Java-Projekt einzurichten. Starten Sie IntelliJ IDEA und warten Sie, bis es geladen ist. Wählen Sie dann im oberen Menü Datei > Neu > Projekt... aus.

Initialisieren Sie nun Ihr Java-Projekt im Dialogfenster Neues Projekt wie folgt:

Legen Sie einen Namen und einen Speicherort für Ihr Projekt fest, wählen Sie Java als Programmiersprache und entscheiden Sie sich – je nachdem, welches Build-Tool Sie installiert haben – für Maven oder Gradle. Klicken Sie auf die Schaltfläche „Erstellen“ und warten Sie, bis IntelliJ IDEA Ihr Java-Projekt initialisiert hat. Es sollte nun das folgende leere Java-Projekt angezeigt werden:

Als Nächstes installieren wir Jsoup und dann beginnen wir mit dem Scraping von Daten aus dem Web!
Schritt 2: Installieren von Jsoup
Wenn Sie Maven verwenden, fügen Sie die folgenden Zeilen in das dependencies-Tag Ihrer pom.xml-Datei ein:
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.15.3</version>
</dependency>Ihre pom.xml-Datei in Maven sollte wie folgt aussehen:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.brightdata</groupId>
<artifactId>web-scraper-jsoup</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>17</maven.compiler.source>
<maven.compiler.target>17</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.15.3</version>
</dependency>
</dependencies>
</project>Wenn Sie Gradle verwenden, fügen Sie diese Zeile in das dependencies-Objekt Ihrer build.gradle-Datei ein:
implementation "org.jsoup:jsoup:1.15.3"Sie haben soeben jsoup zu den Abhängigkeiten Ihres Projekts hinzugefügt. Nun folgt die Installation. Klicken Sie in IntelliJ IDEA auf die unten angezeigte Schaltfläche „Gradle/Maven neu laden“:

Damit wird die jsoup-Abhängigkeit installiert. Warten Sie, bis der Installationsvorgang abgeschlossen ist. Jetzt haben Sie Zugriff auf alle Funktionen von Jsoup. Sie können überprüfen, ob Jsoup ordnungsgemäß installiert wurde, indem Sie diese Importzeile am Anfang Ihrer Main.java-Datei einfügen:
import org.jsoup.*;Meldet IntelliJ IDEA keinen Fehler, so bedeutet dies, dass Sie Jsoup jetzt in Ihrem Java Web-Scraping-Skript verwenden können.
Im nächsten Schritt programmieren wir einen Web Scraper mit Jsoup!
Schritt 3: Verbinden mit der Ziel-Website
Sie können Jsoup verwenden, um in einer einzigen Codezeile eine Verbindung zu Ihrer Zielwebsite herzustellen:
// downloading the target website with an HTTP GET request
Document doc = Jsoup.connect("https://quotes.toscrape.com/").get();Dank der connect()-Methode von Jsoup können Sie eine Verbindung zu einer Website herstellen. Jsoup führt im Hintergrund eine HTTP-GET-Anfrage an die als Parameter angegebene URL aus, ruft das vom Zielserver zurückgegebene HTML-Dokument ab und speichert es im Jsoup-Document-Objekt doc.
Bitte beachten Sie, dass Jsoup eine IOException auslöst, falls connect() fehlschlägt. Dafür kann es mehrere Gründe geben. Allerdings sollten Sie bedenken, dass viele Websites Anfragen blockieren, die keinen gültigen User-Agent-Header enthalten. Falls Sie damit nicht vertraut sind: Der User-Agent-Header ist ein String-Wert, der die Anwendung und die Betriebssystemversion angibt, von der eine Anfrage ausgeht. Erfahren Sie mehr über User-Agents beim Web Scrapings.
Sie können einen User-AgentJsoup wie folgt festlegen:
Document doc = Jsoup
.connect("https://quotes.toscrape.com/")
.userAgent("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36")
.get();Die Jsoup-Methode userAgent() ermöglicht es Ihnen, den User-Agent-Header einzustellen. Bitte beachten Sie, dass Sie jeden anderen HTTP-Header mithilfe der header()-Methode auf einen Wert festlegen.
Ihre Main.java-Klasse sollte nun wie folgt aussehen:
package com.brightdata;
import org.jsoup.*;
import org.jsoup.nodes.*;
import java.io.IOException;
public class Main {
public static void main(String[] args) throws IOException {
// downloading the target website with an HTTP GET request
Document doc = Jsoup
.connect("https://quotes.toscrape.com/")
.userAgent("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36")
.get();
}
}Im nächsten Schritt analysieren wir die Zielwebsite, um zu erfahren, wie wir daraus Daten extrahieren können.
Schritt 4: Untersuchen der HTML-Seite
Wenn Sie Daten aus einem HTML-Dokument extrahieren möchten, müssen Sie zuerst den HTML-Code der Webseite analysieren. Zunächst sind die HTML-Elemente zu ermitteln, die die gewünschten auszulesenden Daten enthalten. Danach müssen Sie einen Weg finden, um diese HTML-Elemente auszuwählen.
All dies lässt sich mithilfe der Entwicklerwerkzeuge Ihres Browsers bewerkstelligen. Klicken Sie in Google Chrome oder einem anderen Chromium-basierten Browser mit der rechten Maustaste auf ein HTML-Element, das die gewünschten Daten enthält. Wählen Sie dann die Option „Untersuchen“ aus.
Jetzt sollte Folgendes angezeigt werden:
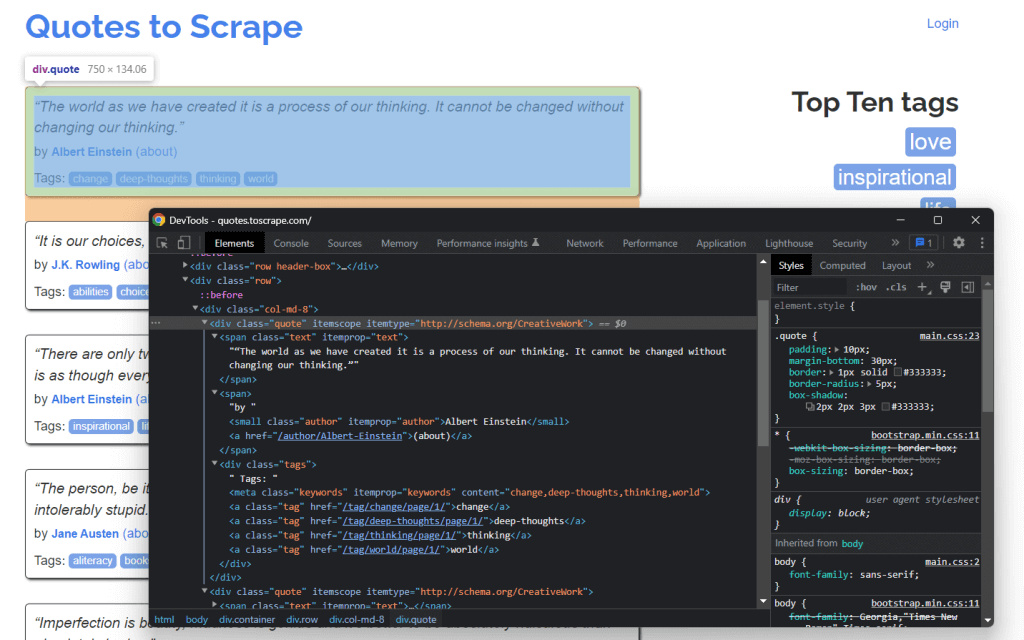
Ein Blick in den HTML-Code zeigt, dass jedes Zitat von einem <div>-HTML-Element umschlossen ist. Dieses <div>-Element enthält:
- Ein
< span>-HTML-Element mit dem Text des Zitats - Ein
<small>-HTML-Element mit dem Namen des Autors - Ein
<div>-Element mit einer Liste von<a>-HTML-Elementen, welche die mit dem Zitat verknüpften Tags enthalten.
Sehen wir uns nun die von diesen HTML-Elementen verwendeten CSS-Klassen an. Dank dieser Klassen können Sie die CSS-Selektoren definieren, die Sie zum Extrahieren der HTML-Elemente aus dem DOM benötigen. Durch Anwendung der unten stehenden CSS-Selektoren auf .quote lassen sich sämtliche mit einem Zitat verknüpften Daten abrufen:
.text.author.tags .tag
Lernen Sie als Nächstes, wie das in Jsoup funktioniert.
Schritt 5: Auswählen von HTML-Elementen mit Jsoup
Die Jsoup-Klasse Document bietet Ihnen mehrere Möglichkeiten, um HTML-Elemente aus dem DOM auszuwählen. Sehen wir uns die wichtigsten davon an.
Jsoup ermöglicht es, HTML-Elemente anhand ihrer Tags zu extrahieren:
// selecting all <div> HTML elements
Elements divs = doc.getElementsByTag("div");Dadurch wird die Liste mit den im DOM enthaltenen <div>-HTML-Elementen zurückgegeben.
Analog dazu können Sie HTML-Elemente nach Klassen auswählen:
// getting the ".quote" HTML element
Elements quotes = doc.getElementsByClass("quote");Wenn Sie ein einzelnes HTML-Element anhand seines id-Attributs abrufen möchten, können Sie dazu Folgendes verwenden:
// getting the "#quote-1" HTML element
Element div = doc.getElementById("quote-1");Darüber hinaus können Sie HTML-Elemente über ein Attribut auswählen:
// selecting all HTML elements that have the "value" attribute
Elements htmlElements = doc.getElementsByAttribute("value");Oder Elemente, die einen bestimmten Textabschnitt enthalten:
// selecting all HTML elements that contain the word "for"
Elements htmlElements = doc.getElementsContainingText("for");Dies sind nur einige Beispiele. Beachten Sie, dass Jsoup über 20 verschiedene Methoden zur Auswahl von HTML-Elementen auf einer Webseite bietet. Hier finden Sie eine vollständige Auflistung.
Wie Sie bereits erfahren haben, stellen CSS-Selektoren eine wirksame Methode zur Auswahl von HTML-Elementen dar. Sie können einen CSS-Selektor anwenden, um Elemente in Jsoup über die Methode select() abzurufen:
// selecting all quote HTML elements
Elements quoteElements = doc.getElementsByClass(".quote");Da Elements ArrayList erweitert, können Sie darüber iterieren, um jedes Jsoup-Element zu erhalten. Bitte beachten Sie, dass Sie alle HTML-Auswahlmethoden auch auf ein einzelnes Element anwenden können. Dadurch wird die Auswahllogik auf die Kinder des ausgewählten HTML-Elements begrenzt.
Sie können also die gewünschten HTML-Elemente für jedes .quote wie nachfolgend dargestellt auswählen:
for (Element quoteElement: quoteElements) {
Element text = quoteElement.select(".text").first();
Element author = quoteElement.select(".author").first();
Elements tags = quoteElement.select(".tag");
}Sehen wir uns nun an, wie man Daten aus diesen HTML-Elementen extrahieren kann.
Schritt 6: Extrahieren von Daten aus einer Webseite mit Jsoup
Zunächst benötigen Sie eine Java-Klasse, in der Sie die gescrapten Daten speichern können. Erstellen Sie eine Quote.java-Datei im Hauptpaket und initialisieren Sie diese wie folgt:
package com.brightdata;
package com.brightdata;
public class Quote {
private String text;
private String author;
private String tags;
public String getText() {
return text;
}
public void setText(String text) {
this.text = text;
}
public String getAuthor() {
return author;
}
public void setAuthor(String author) {
this.author = author;
}
public String getTags() {
return tags;
}
public void setTags(String tags) {
this.tags = tags;
}
}Nun wird das am Ende des vorherigen Abschnitts beschriebene Snippet erweitert. Extrahieren Sie die gewünschten Daten aus den ausgewählten HTML-Elementen und speichern Sie sie wie folgt in Quote-Objekten:
// initializing the list of Quote data objects
// that will contain the scraped data
List<Quote> quotes = new ArrayList<>();
// retrieving the list of product HTML elements
// selecting all quote HTML elements
Elements quoteElements = doc.select(".quote");
// iterating over the quoteElements list of HTML quotes
for (Element quoteElement : quoteElements) {
// initializing a quote data object
Quote quote = new Quote();
// extracting the text of the quote and removing the
// special characters
String text = quoteElement.select(".text").first().text()
.replace("“", "")
.replace("”", "");
String author = quoteElement.select(".author").first().text();
// initializing the list of tags
List<String> tags = new ArrayList<>();
// iterating over the list of tags
for (Element tag : quoteElement.select(".tag")) {
// adding the tag string to the list of tags
tags.add(tag.text());
}
// storing the scraped data in the Quote object
quote.setText(text);
quote.setAuthor(author);
quote.setTags(String.join(", ", tags)); // merging the tags into a "A, B, ..., Z" string
// adding the Quote object to the list of the scraped quotes
quotes.add(quote);
}Da jedes Zitat mehr als ein Tag aufweisen kann, können Sie diese alle in einer Java-Liste speichern. Anschließend können Sie die Liste der Zeichenketten mithilfe der Methode String.join() zu einer einzigen Zeichenkette reduzieren. Danach können Sie diese Zeichenfolge im Quote-Objekt speichern.
Am Ende der for-Schleife speichert quotes sämtliche Zitatdaten, die aus der Startseite der Zielwebsite extrahiert wurden. Allerdings umfasst die Zielwebsite viele verschiedene Seiten!
Erfahren Sie daher als Nächstes, wie Sie mit Jsoup eine ganze Website crawlen können.
Schritt 7: Crawlen der gesamten Website mit Jsoup
Bei genauer Betrachtung der Startseite von Quotes to Scrape werden Sie eine Schaltfläche mit dem Text „Next →“ entdecken. Untersuchen Sie dieses HTML-Element mithilfe der Entwicklerwerkzeuge Ihres Browsers. Klicken Sie mit der rechten Maustaste darauf und wählen Sie „Untersuchen“.
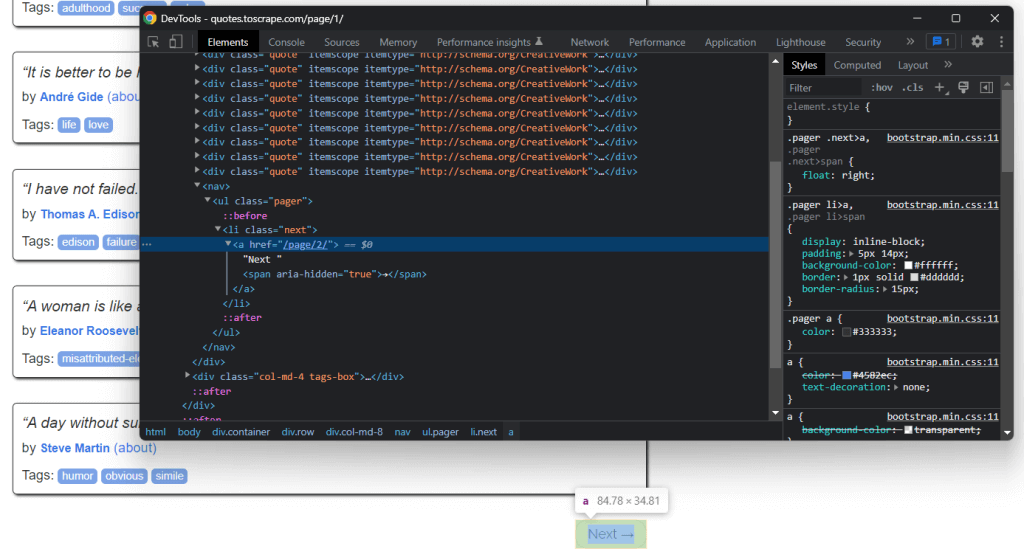
Sie werden feststellen, dass es sich bei der Schaltfläche „Next →“ um ein <li>-HTML-Element handelt. Dieses enthält ein <a>-HTML-Element, welches die jeweilige URL speichert, die zur nächsten Seite führt. Bitte beachten Sie, dass die Schaltfläche „Next →“ – mit Ausnahme der letzten Seite – auf allen Seiten der Zielwebsite zu finden ist. Die meisten paginierten Websites sind nach einem solchen Prinzip aufgebaut.
Durch Extrahieren des Links, der in diesem <a>-HTML-Element gespeichert ist, können Sie die nächste zu scrapende Seite abrufen. Wenn Sie daher die gesamte Website scrapen möchten, sollten Sie die folgende Logik anwenden:
- Suche nach dem HTML-Element
.next.- sofern dieses vorhanden ist: Extrahieren der in seinem
<a>-Kind enthaltenen relativen URL und weiter zu 2. - Wenn nicht vorhanden, ist dies die letzte Seite und Sie können hier aufhören.
- sofern dieses vorhanden ist: Extrahieren der in seinem
- Verketten Sie die durch das
<a>-HTML-Element extrahierte relative URL mit der Basis-URL der Website. - Verwenden Sie die vollständige URL, um eine Verbindung zur neuen Seite herzustellen
- Scrapen Sie die Daten von der neuen Seite
- Gehen Sie zu 1.
Genau darum geht es beim Web Crawling. Sie können eine paginierte Website mit Jsoup wie folgt crawlen:
// the URL of the target website's home page
String baseUrl = "https://quotes.toscrape.com";
// initializing the list of Quote data objects
// that will contain the scraped data
List<Quote> quotes = new ArrayList<>();
// retrieving the home page...
// looking for the "Next →" HTML element
Elements nextElements = doc.select(".next");
// if there is a next page to scrape
while (!nextElements.isEmpty()) {
// getting the "Next →" HTML element
Element nextElement = nextElements.first();
// extracting the relative URL of the next page
String relativeUrl = nextElement.getElementsByTag("a").first().attr("href");
// building the complete URL of the next page
String completeUrl = baseUrl + relativeUrl;
// connecting to the next page
doc = Jsoup
.connect(completeUrl)
.userAgent("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36")
.get();
// scraping logic...
// looking for the "Next →" HTML element in the new page
nextElements = doc.select(".next");
}Wie Sie sehen, können Sie die zuvor erläuterte Crawling-Logik mithilfe eines einfachen while-Zyklus implementieren. Dafür sind nur wenige Codezeilen mit einer do-while-Schleife erforderlich.
Herzlichen Glückwunsch! Jetzt sind Sie in der Lage, eine ganze Website zu crawlen. Nun müssen Sie nur noch lernen, wie Sie die gescrapten Daten in ein nützlicheres Format umwandeln können.
Schritt 8: Exportieren der gescrapten Daten in CSV
Sie können die gescrapten Daten wie folgt in eine CSV-Datei umwandeln:
// initializing the output CSV file
File csvFile = new File("output.csv");
// using the try-with-resources to handle the
// release of the unused resources when the writing process ends
try (PrintWriter printWriter = new PrintWriter(csvFile)) {
// iterating over all quotes
for (Quote quote : quotes) {
// converting the quote data into a
// list of strings
List<String> row = new ArrayList<>();
// wrapping each field with between quotes
// to make the CSV file more consistent
row.add(""" + quote.getText() + """);
row.add(""" +quote.getAuthor() + """);
row.add(""" +quote.getTags() + """);
// printing a CSV line
printWriter.println(String.join(",", row));
}
}Dieses Snippet konvertiert das Zitat in das CSV-Format und speichert es in einer output.csv-Datei. Wie Sie sehen, werden dafür keine zusätzlichen Abhängigkeiten benötigt. Sie müssen lediglich eine CSV-Datei mit File initialisieren. Anschließend können Sie einen PrintWriter verwenden, um jedes Zitat als CSV-formatierte Zeile in der Datei output.csv auszugeben.
Bitte beachten Sie, dass ein PrintWriter immer geschlossen werden sollte, wenn er nicht mehr benötigt wird. Im Einzelnen sorgt das obige Statement try-with-resources dafür, dass die PrintWriter-Instanz am Ende der try-Anweisung geschlossen wird.
Sie haben mit der Navigation auf einer Website begonnen und können nun alle Daten abrufen, um sie in einer CSV-Datei zu speichern. Nun ist es an der Zeit, einen Blick auf den gesamten Jsoup Web Scraper zu werfen.
Alles zusammenfügen
So sieht das komplette Jsoup-Skript zum Web Scraping in Java aus:
package com.brightdata;
import org.jsoup.*;
import org.jsoup.nodes.*;
import org.jsoup.select.Elements;
import java.io.File;
import java.io.IOException;
import java.io.PrintWriter;
import java.nio.charset.StandardCharsets;
import java.util.ArrayList;
import java.util.List;
public class Main {
public static void main(String[] args) throws IOException {
// the URL of the target website's home page
String baseUrl = "https://quotes.toscrape.com";
// initializing the list of Quote data objects
// that will contain the scraped data
List<Quote> quotes = new ArrayList<>();
// downloading the target website with an HTTP GET request
Document doc = Jsoup
.connect(baseUrl)
.userAgent("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36")
.get();
// looking for the "Next →" HTML element
Elements nextElements = doc.select(".next");
// if there is a next page to scrape
while (!nextElements.isEmpty()) {
// getting the "Next →" HTML element
Element nextElement = nextElements.first();
// extracting the relative URL of the next page
String relativeUrl = nextElement.getElementsByTag("a").first().attr("href");
// building the complete URL of the next page
String completeUrl = baseUrl + relativeUrl;
// connecting to the next page
doc = Jsoup
.connect(completeUrl)
.userAgent("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36")
.get();
// retrieving the list of product HTML elements
// selecting all quote HTML elements
Elements quoteElements = doc.select(".quote");
// iterating over the quoteElements list of HTML quotes
for (Element quoteElement : quoteElements) {
// initializing a quote data object
Quote quote = new Quote();
// extracting the text of the quote and removing the
// special characters
String text = quoteElement.select(".text").first().text();
String author = quoteElement.select(".author").first().text();
// initializing the list of tags
List<String> tags = new ArrayList<>();
// iterating over the list of tags
for (Element tag : quoteElement.select(".tag")) {
// adding the tag string to the list of tags
tags.add(tag.text());
}
// storing the scraped data in the Quote object
quote.setText(text);
quote.setAuthor(author);
quote.setTags(String.join(", ", tags)); // merging the tags into a "A; B; ...; Z" string
// adding the Quote object to the list of the scraped quotes
quotes.add(quote);
}
// looking for the "Next →" HTML element in the new page
nextElements = doc.select(".next");
}
// initializing the output CSV file
File csvFile = new File("output.csv");
// using the try-with-resources to handle the
// release of the unused resources when the writing process ends
try (PrintWriter printWriter = new PrintWriter(csvFile, StandardCharsets.UTF_8)) {
// to handle BOM
printWriter.write('ufeff');
// iterating over all quotes
for (Quote quote : quotes) {
// converting the quote data into a
// list of strings
List<String> row = new ArrayList<>();
// wrapping each field with between quotes
// to make the CSV file more consistent
row.add(""" + quote.getText() + """);
row.add(""" +quote.getAuthor() + """);
row.add(""" +quote.getTags() + """);
// printing a CSV line
printWriter.println(String.join(",", row));
}
}
}
}Wie hier zu sehen ist, können Sie mit weniger als 100 Zeilen Code einen Web Scraper in Java implementieren. Mithilfe von Jsoup können Sie eine Verbindung zu einer Website herstellen, die gesamte Website crawlen und sämtliche Daten automatisch extrahieren. Anschließend können Sie alle extrahierten Daten in eine CSV-Datei schreiben. Genau darum geht es bei diesem Jsoup Web Scraper.
Starten Sie in IntelliJ IDEA das Jsoup Web-Scraping-Skript, indem Sie auf die folgende Schaltfläche klicken:

Daraufhin kompiliert IntelliJ IDEA die Datei Main.java und führt die Klasse Main aus. Am Ende des Scraping-Vorgangs finden Sie im Stammverzeichnis des Projekts eine output.csv-Datei. Öffnen Sie die Datei. Sie sollte die folgenden Daten enthalten:
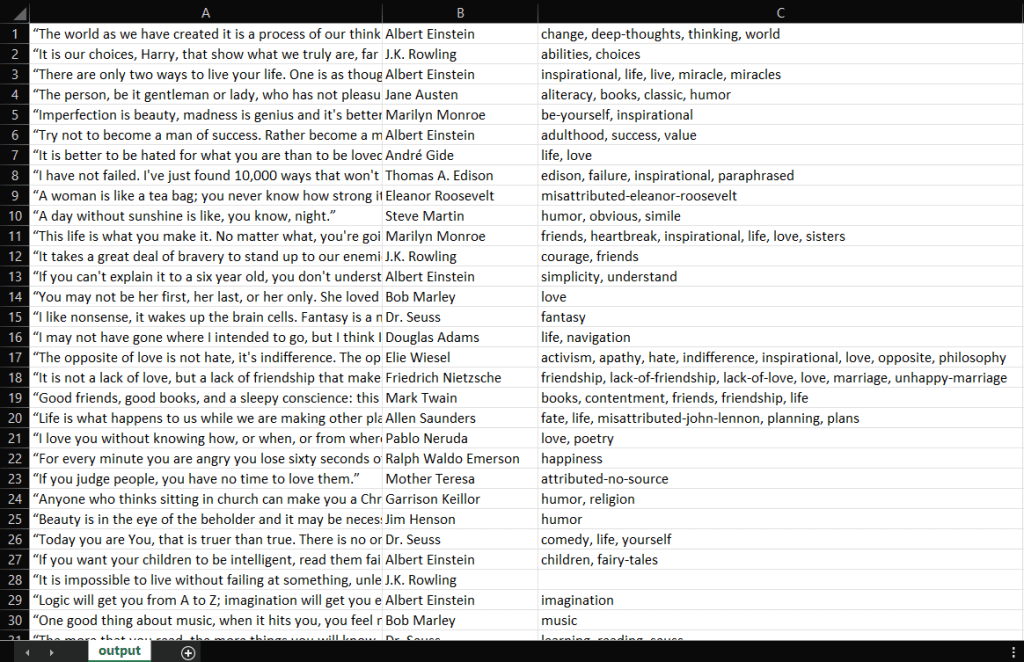
Gut gemacht! Jetzt haben Sie eine CSV-Datei mit allen 100 Zitaten von Quotes to Scrape! Sie haben also gerade gelernt, wie man einen Web Scraper mit Jsoup erstellt!
Fazit
In diesem Tutorial haben Sie gelernt, was Sie für die Erstellung eines Web Scrapers benötigen, was Jsoup ist und wie Sie damit Daten aus dem Web scrapen können. Sie haben erfahren, wie man Jsoup verwendet, um eine Web-Scraping-Anwendung anhand eines realen Beispiels zu erstellen. Sie wissen nun, dass zum Web Scraping mit Jsoup nur ein paar Zeilen Code erforderlich sind.
Trotzdem ist Web Scraping kein Kinderspiel, denn Sie müssen einige Herausforderungen meistern. Vergessen Sie nicht, dass Anti-Bot- und Anti-Scraping-Technologien heutzutage verbreiteter sind als je zuvor. Daher benötigen Sie ein leistungsstarkes und voll funktionsfähiges Web-Scraping-Tool, wie es von Bright Data bereitgestellt wird. Sie möchten sich nicht mit Scraping auseinandersetzen? Sehen Sie sich unsere Datensätze an.
Wenn Sie wissen möchten, wie Sie Sperren umgehen können, empfehlen wir Ihnen, sich aus einem der vielen Proxy-Dienste, die Bright Data anbietet, einen für Ihre Zwecke geeigneten Proxy auszuwählen.




