

Wikipedia ist eine umfangreiche und umfassende Informationsquelle mit Millionen von Artikeln zu fast jedem Thema. Für Forscher, Datenwissenschaftler und Entwickler eröffnen diese Daten unzählige Möglichkeiten, von der Erstellung von Datensätzen für maschinelles Lernen bis hin zur Durchführung akademischer Forschung. In diesem Artikel führen wir Sie Schritt für Schritt durch den Prozess des Scrapings von Wikipedia.
Verwendung der Bright Data Wikipedia Scraper API
Wenn Sie Daten effizient aus Wikipedia extrahieren möchten, ist die Bright Data Wikipedia Scraper API eine großartige Alternative zum manuellen Web-Scraping. Diese leistungsstarke API automatisiert den Prozess und erleichtert das Sammeln großer Informationsmengen erheblich.
Wichtige Anwendungsfälle:
- Sammeln Sie Erklärungen zu einer Vielzahl von Themen
- Vergleichen Sie Informationen aus Wikipedia mit anderen Datenquellen
- Führen Sie Recherchen anhand großer Datensätze durch
- Bilder aus Wikipedia Commons scrapen
Sie können Ihre Daten in Formaten wie JSON, CSV und .gz abrufen, und es werden verschiedene Lieferoptionen unterstützt, darunter Amazon S3, Google Cloud Storage und Microsoft Azure.
Mit nur einem API-Aufruf können Sie schnell und einfach auf eine Fülle von Daten zugreifen!
Wie man Wikipedia mit Python scrapt
Befolgen Sie diese Schritt-für-Schritt-Anleitung, um Wikipedia mit Python zu scrapen.
1. Einrichtung und Voraussetzungen
Bevor Sie beginnen, stellen Sie sicher, dass Ihre Entwicklungsumgebung ordnungsgemäß konfiguriert ist:
- Installieren Sie Python: Laden Sie die neueste Version von Python von der offiziellen Python-Website herunter und installieren Sie sie.
- Wählen Sie eine IDE: Verwenden Sie für Ihre Entwicklungsarbeit eine IDE wie PyCharm, Visual Studio Code oder Jupyter Notebook.
- Grundkenntnisse: Stellen Sie sicher, dass Sie mit CSS-Selektoren vertraut sind und mit den DevTools Ihres Browsers umgehen können, um Seitenelemente zu überprüfen.
Wenn Sie Python noch nicht kennen, lesen Sie diese Anleitung zum Scrapen mit Python, um detaillierte Anweisungen zu erhalten.
Erstellen Sie als Nächstes ein neues Projekt mit Poetry, einem Tool zur Verwaltung von Abhängigkeiten, das die Verwaltung von Paketen und virtuellen Umgebungen in Python vereinfacht.
poetry new wikipedia-Scraper
Dieser Befehl generiert die folgende Projektstruktur:
wikipedia-Scraper/
├── pyproject.toml
├── README.md
├── wikipedia_Scraper/
│ └── __init__.py
└── tests/
└── __init__.py
Navigieren Sie in das Projektverzeichnis und installieren Sie die erforderlichen Abhängigkeiten:
cd wikipedia-Scraper
poetry add requests beautifulsoup4 pandas lxml
Zunächst wird BeautifulSoup zum Parsing von HTML- und XML-Dokumenten verwendet, wodurch es einfach ist, zu navigieren und bestimmte Elemente aus Webseiten zu extrahieren. Die Bibliothek „requests” übernimmt das Senden von HTTP-Anfragen und das Abrufen des Inhalts von Webseiten. Pandas ist ein leistungsstarkes Tool zum Bearbeiten und Analysieren der gescrapten Daten, das besonders bei der Arbeit mit Tabellen nützlich ist. Schließlich wird lxml verwendet, um den Parsing-Prozess zu beschleunigen und die Leistung von BeautifulSoup zu verbessern.
Aktivieren Sie als Nächstes die virtuelle Umgebung und öffnen Sie den Projektordner in Ihrem bevorzugten Code-Editor (in diesem Fall VS Code):
poetry shell
code .
Öffnen Sie die Datei pyproject.toml, um die Abhängigkeiten Ihres Projekts zu überprüfen. Sie sollte wie folgt aussehen:
[tool.poetry.dependencies]
python = "^3.12"
requests = "^2.32.3"
beautifulsoup4 = "^4.12.3"
pandas = "^2.2.3"
lxml = "^5.3.0"
Erstellen Sie schließlich eine Datei main.py im Ordner wikipedia_scraper, in der Sie Ihre Scraping-Logik schreiben. Ihre aktualisierte Projektstruktur sollte nun wie folgt aussehen:
wikipedia-Scraper/
├── pyproject.toml
├── README.md
├── wikipedia_Scraper/
│ ├── __init__.py
│ └── main.py
└── tests/
└── __init__.py
Ihre Umgebung ist nun eingerichtet und Sie können mit dem Schreiben des Python-Codes zum Scrapen von Wikipedia beginnen.
2. Verbindung zur gewünschten Wikipedia-Seite herstellen
Stellen Sie zunächst eine Verbindung zur gewünschten Wikipedia-Seite her. In diesem Beispiel scrapen wir die folgende Wikipedia-Seite.
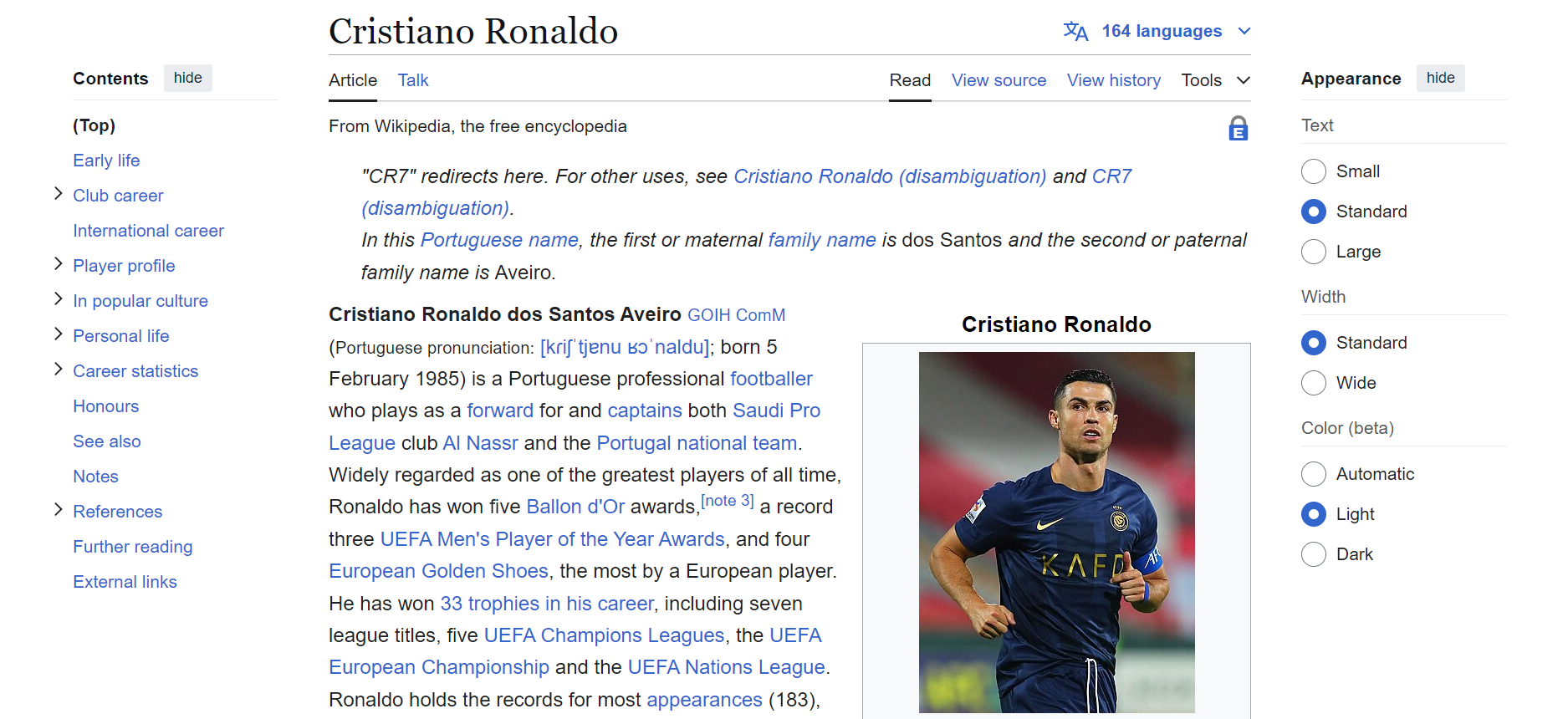
Hier ist ein einfacher Code-Schnipsel, um mit Python eine Verbindung zu einer Wikipedia-Seite herzustellen:
import requests # Für HTTP-Anfragen
from bs4 import BeautifulSoup # Für das Parsing von HTML-Inhalten
def connect_to_wikipedia(url):
response = requests.get(url) # Senden einer GET-Anfrage an die URL
# Überprüfen, ob die Anfrage erfolgreich war
if response.status_code == 200:
return BeautifulSoup(response.text, "html.parser") # HTML parsen und zurückgeben
else:
print(f"Failed to retrieve the page. Statuscode: {response.status_code}")
return None # None zurückgeben, wenn die Anfrage fehlschlägt
wikipedia_url = "<https://en.wikipedia.org/wiki/Cristiano_Ronaldo>"
soup = connect_to_wikipedia(wikipedia_url) # Das Soup-Objekt für die angegebene URL abrufen
Im Code können Sie mit der Python-Bibliothek „requests“ eine HTTP-Anfrage an die URL senden und mit BeautifulSoup den HTML-Inhalt der Seite parsen.
3. Überprüfen der Seite
Um Daten effektiv zu scrapen, müssen Sie die Struktur des DOM (Document Object Model) der Webseite verstehen. Um beispielsweise alle Links auf der Seite zu extrahieren, können Sie die <a> -Tags anvisieren, wie unten gezeigt:
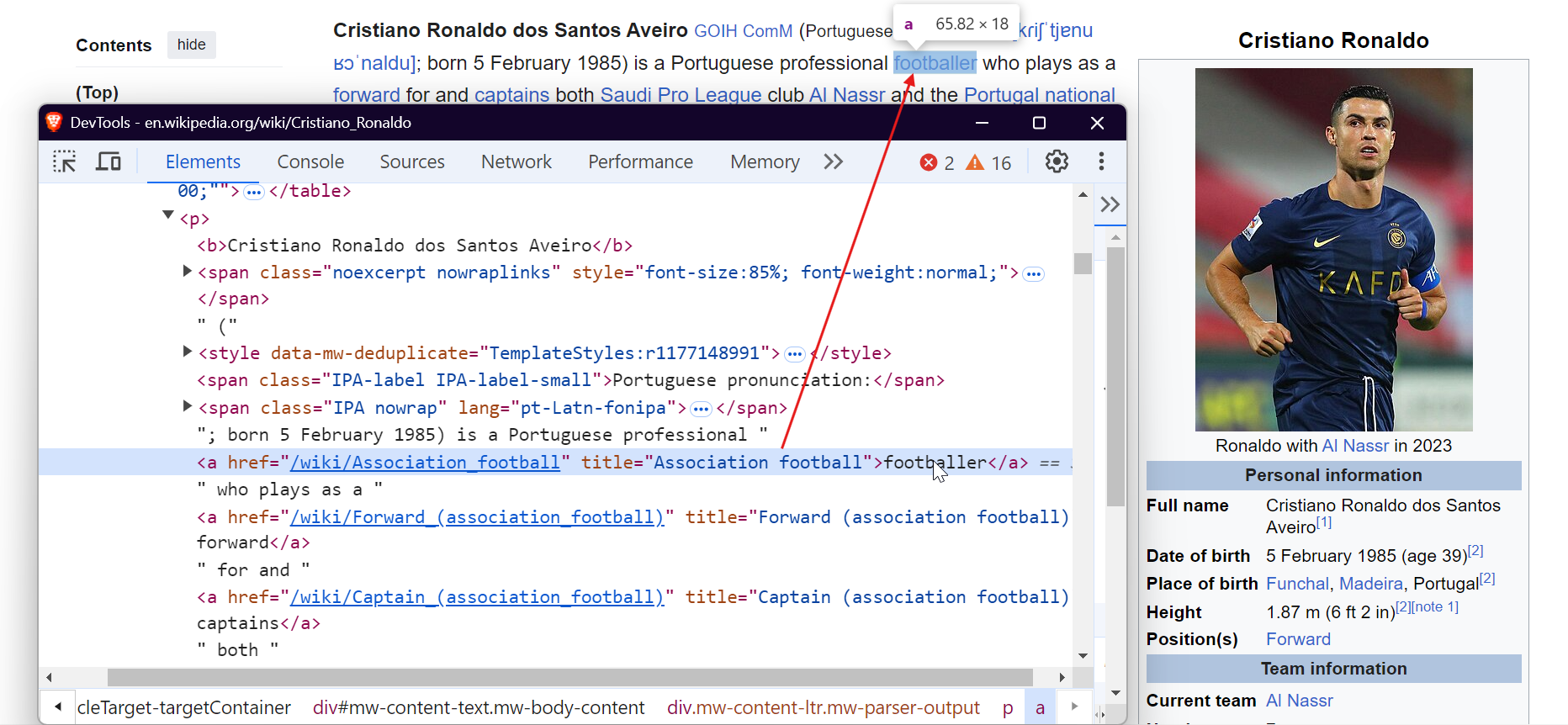
Um Bilder zu scrapen, zielen Sie auf die <img> -Tags und extrahieren Sie das src-Attribut, um die Bild-URLs zu erhalten.
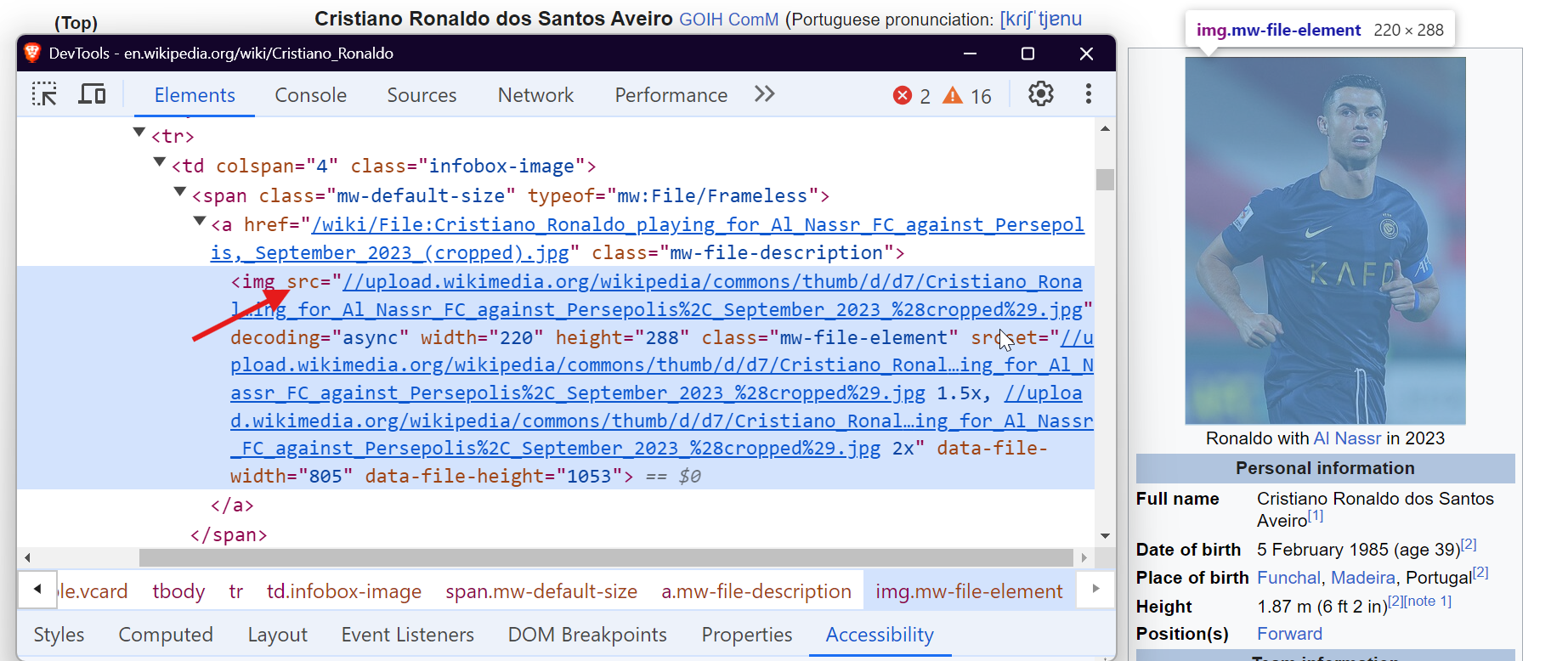
Um Daten aus Tabellen zu extrahieren, können Sie das <table> -Tag mit der Klasse wikitable anvisieren. Auf diese Weise können Sie alle Zeilen und Spalten der Tabelle erfassen und die erforderlichen Daten extrahieren.
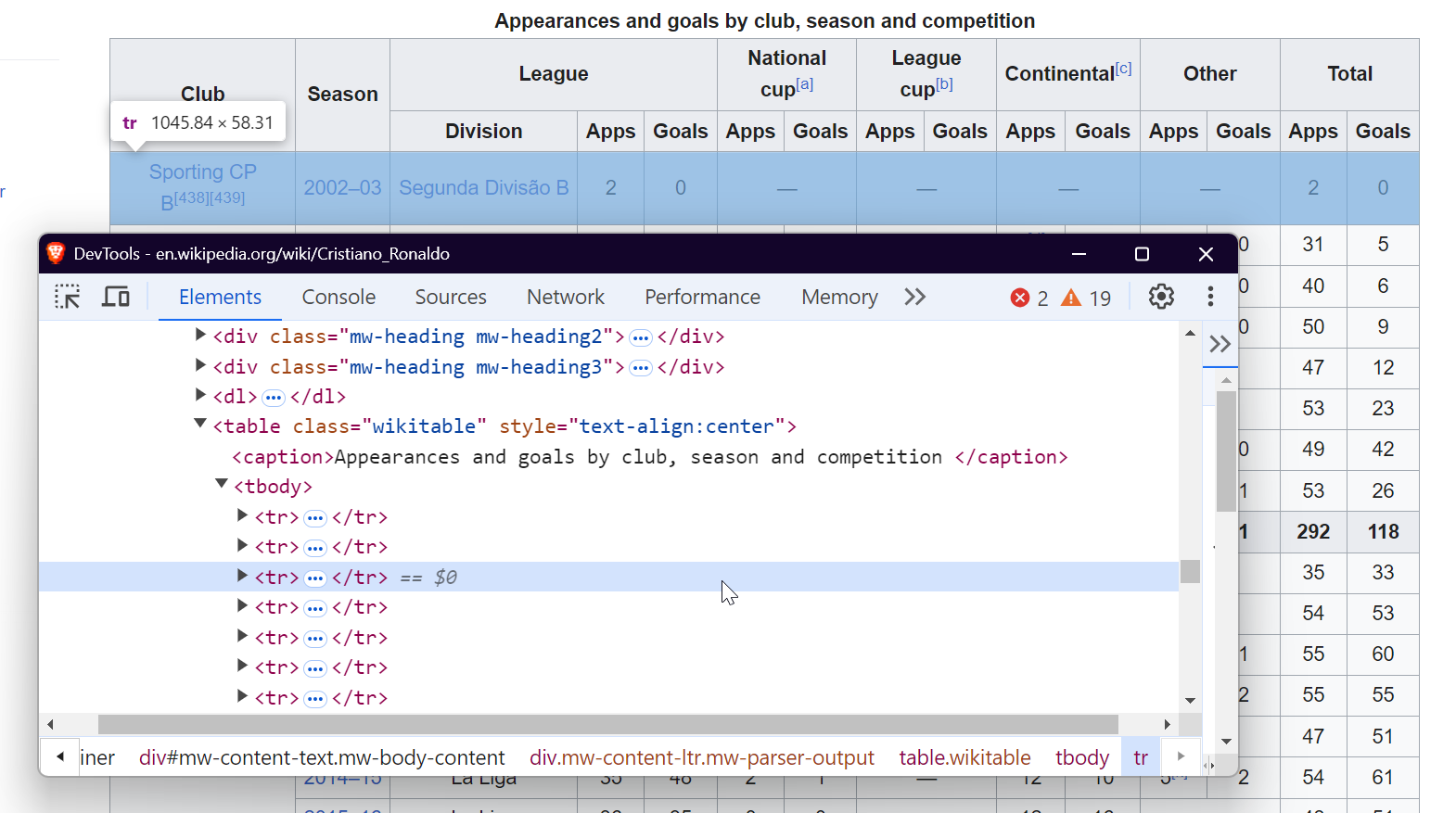
Um Absätze zu extrahieren, wählen Sie einfach die <p> -Tags aus, die den Haupttextinhalt der Seite enthalten.
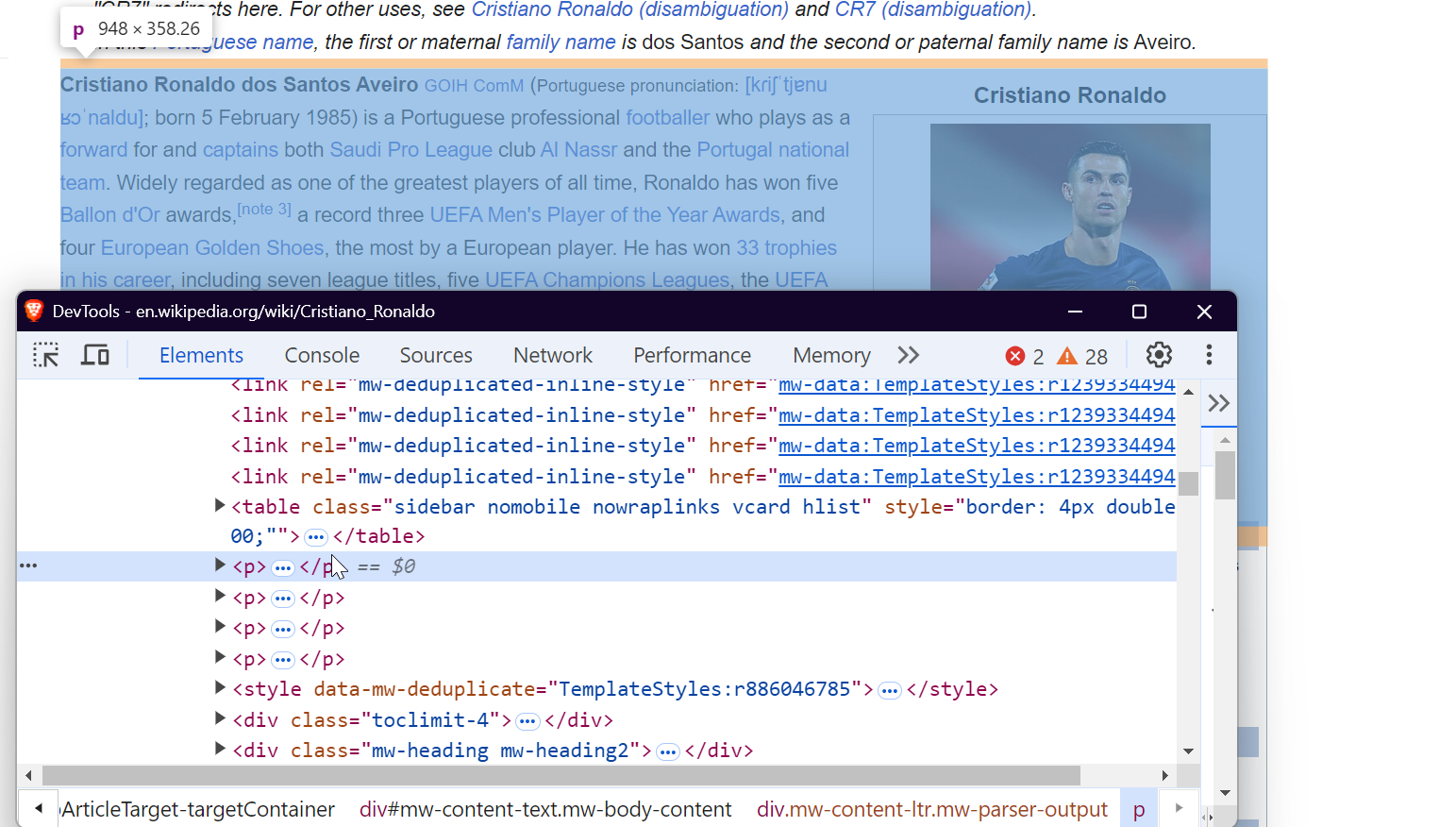
Das war’s schon! Indem Sie diese spezifischen Elemente ansprechen, können Sie die gewünschten Daten aus jeder Wikipedia-Seite extrahieren.
4. Extrahieren von Links
Wikipedia-Artikel enthalten interne und externe Links, die Benutzer zu verwandten Themen, Referenzen oder externen Ressourcen weiterleiten. Um alle Links aus einer Wikipedia-Seite zu extrahieren, können Sie den folgenden Code verwenden:
def extract_links(soup):
links = []
for link in soup.find_all("a", href=True): # Alle Anker-Tags mit href-Attribut suchen
url = link["href"]
if not url.startswith("http"): # Prüfen, ob die URL relativ ist
url = "<https://en.wikipedia.org>" + url # Relative Links in absolute URLs konvertieren
links.append(url)
return links # Liste der extrahierten Links zurückgeben
Die Funktion soup.find_all('a', href=True) ruft alle <a> -Tags auf der Seite ab, die ein href-Attribut enthalten, darunter sowohl interne als auch externe Links. Der Code stellt außerdem sicher, dass relative URLs korrekt formatiert sind.
Das Ergebnis könnte wie folgt aussehen:
<https://en.wikipedia.org#Early_life>
<https://en.wikipedia.org#Club_career>
<https://en.wikipedia.org/wiki/Real_Madrid>
<https://en.wikipedia.org/wiki/Portugal_national_football_team>
5. Extrahieren von Absätzen
Um Textinhalte aus einem Wikipedia-Artikel zu extrahieren, können Sie die <p> -Tags anvisieren, die den Hauptteil des Textes enthalten. So extrahieren Sie Absätze mit BeautifulSoup:
def extract_paragraphs(soup):
paragraphs = [p.get_text(strip=True) for p in soup.find_all("p")] # Text aus Absatz-Tags extrahieren
return [p for p in paragraphs if p and len(p) > 10] # Absätze mit mehr als 10 Zeichen zurückgeben
Diese Funktion erfasst alle Absätze auf der Seite und filtert leere oder zu kurze Absätze heraus, um irrelevante Inhalte wie Zitate oder einzelne Wörter zu vermeiden.
Ein Beispielergebnis:
Cristiano Ronaldo dos Santos AveiroGOIHComM (portugiesische Aussprache: [kɾiʃˈtjɐnuʁɔˈnaldu]; geboren am 5. Februar 1985) ist ein portugiesischer Profifußballer, der als Stürmer für den saudischen Pro-League-Club Al Nassr und die portugiesische Nationalmannschaft spielt und deren Kapitän ist. Ronaldo gilt weithin als einer der größten Spieler aller Zeiten und hat fünf Ballon d'Or-Auszeichnungen [Anmerkung 3], drei UEFA-Auszeichnungen als Spieler des Jahres und vier Goldene Schuhe gewonnen, die meisten, die ein europäischer Spieler je erhalten hat. Er hat in seiner Karriere 33 Trophäen gewonnen, darunter sieben Meistertitel, fünf UEFA Champions Leagues, die UEFA-Europameisterschaft und die UEFA Nations League. Ronaldo hält die Rekorde für die meisten Einsätze (183), Tore (140) und Vorlagen (42) in der Champions League, die meisten Einsätze (30), Vorlagen (8) und Tore in der Europameisterschaft (14), Länderspieltore (133) und Länderspieleinsätze (215). Er ist einer der wenigen Spieler, die mehr als 1.200 Profi-Einsätze absolviert haben, die meisten von allen Feldspielern, und hat mehr als 900 offizielle Tore für seinen Verein und sein Land erzielt, was ihn zum erfolgreichsten Torschützen aller Zeiten macht.
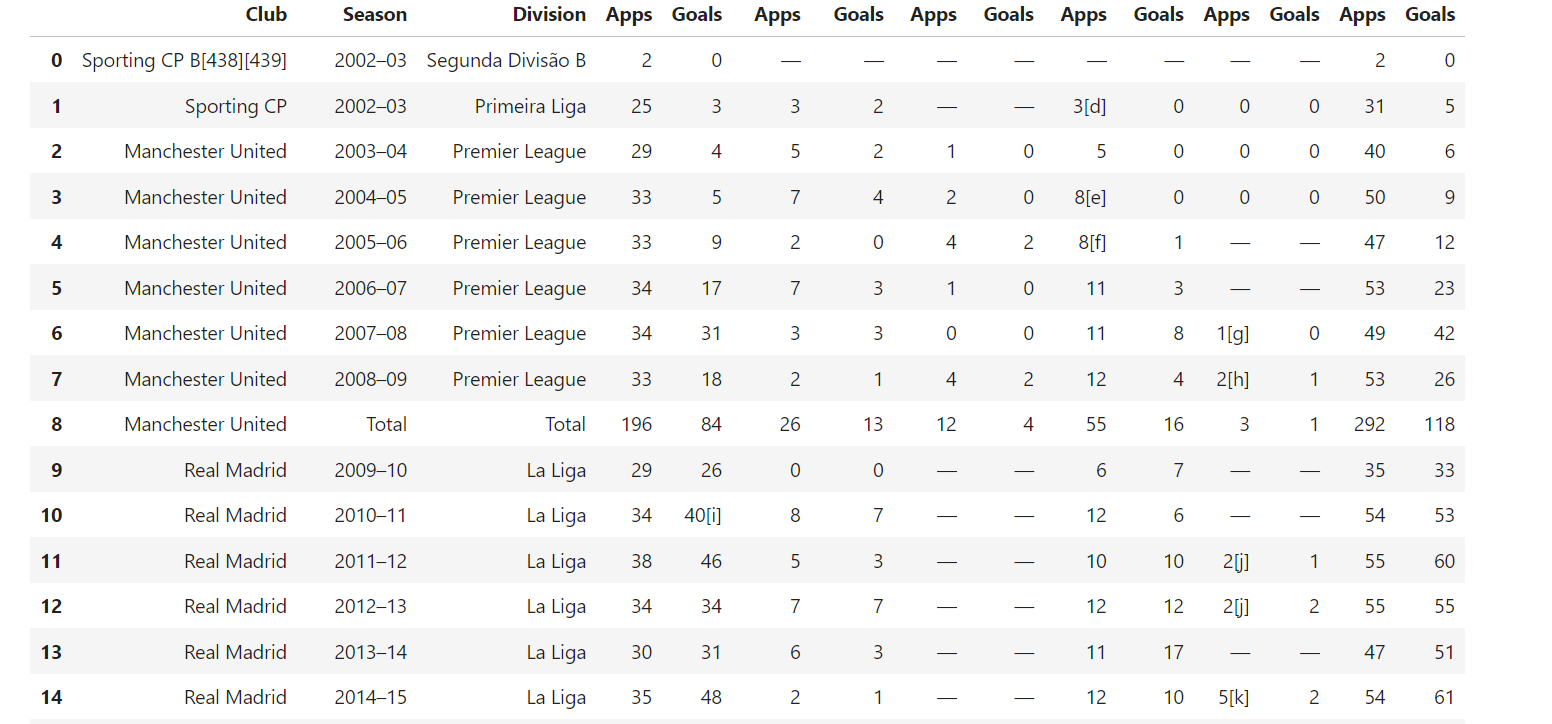
6. Tabellen extrahieren
Wikipedia enthält oft Tabellen mit strukturierten Daten. Um diese Tabellen zu extrahieren, verwenden Sie diesen Code:
def extract_tables(soup):
tables = []
for table in soup.find_all("table", {"class": "wikitable"}): # Tabellen mit der Klasse „wikitable” suchen
table_html = StringIO(str(table)) # Tabellen-HTML in Zeichenfolge konvertieren
df = pd.read_html(table_html)[0] # HTML-Tabelle in einen DataFrame einlesen
tables.append(df)
return tables # Liste der DataFrames zurückgeben
Diese Funktion findet alle Tabellen mit der Klasse „wikitable” und konvertiert sie mit pandas.read_html() in DataFrames, um sie weiter zu bearbeiten.
Beispielergebnis:
7. Bilder extrahieren
Bilder sind eine weitere wertvolle Ressource, die Sie aus Wikipedia extrahieren können. Die folgende Funktion erfasst Bild-URLs von der Seite:
def extract_images(soup):
images = []
for img in soup.find_all("img", src=True): # Alle Bild-Tags mit src-Attribut finden
img_url = img["src"]
if not img_url.startswith("http"): # 'https:' für relative URLs voranstellen
img_url = "https:" + img_url
if "static/images" not in img_url: # Statische oder nicht relevante Bilder ausschließen
images.append(img_url)
return images # Liste der Bild-URLs zurückgeben
Diese Funktion findet alle Bilder (<img> -Tags) auf der Seite, hängt https: an relative URLs an und filtert nicht zum Inhalt gehörende Bilder heraus, sodass nur relevante Bilder extrahiert werden.
Beispielergebnis:
<https://upload.wikimedia.org/wikipedia/commons/d/d7/Cristiano_Ronaldo_2018.jpg>
<https://upload.wikimedia.org/wikipedia/commons/7/76/Cristiano_Ronaldo_Signature.svgb>
8. Speichern der gescrapten Daten
Nachdem Sie die Daten extrahiert haben, müssen Sie sie für die spätere Verwendung speichern. Speichern wir die Daten in separaten Dateien für Links, Bilder, Absätze und Tabellen.
def store_data(links, images, tables, paragraphs):
# Links in einer Textdatei speichern
with open("wikipedia_links.txt", "w", encoding="utf-8") as f:
for link in links:
f.write(f"{link}n")
# Bilder in einer JSON-Datei speichern
with open("wikipedia_images.json", "w", encoding="utf-8") as f:
json.dump(images, f, indent=4)
# Absätze in einer Textdatei speichern
with open("wikipedia_paragraphs.txt", "w", encoding="utf-8") as f:
for para in paragraphs:
f.write(f"{para}nn")
# Jede Tabelle als separate CSV-Datei speichern
for i, table in enumerate(tables):
table.to_csv(f"wikipedia_table_{i+1}.csv", index=False, encoding="utf-8-sig")
Die Funktion „store_data” organisiert die gesammelten Daten:
- Links werden in einer Textdatei gespeichert.
- Bild-URLs werden in einer JSON-Datei gespeichert.
- Absätze werden in einer weiteren Textdatei gespeichert.
- Tabellen werden in CSV-Dateien gespeichert.
Diese Organisation erleichtert den späteren Zugriff auf die Daten und die Arbeit damit.
In unserem Leitfaden erfahren Sie mehr darüber, wie Sie Daten in Python in JSON parsen und serialisieren können.
Alles zusammenfügen
Kombinieren wir nun alle Funktionen, um einen vollständigen Scraper zu erstellen, der Daten aus einer Wikipedia-Seite extrahiert und speichert:
import requests
from bs4 import BeautifulSoup
import pandas as pd
from io import StringIO
import json
# Extrahieren Sie alle Links von der Seite.
def extract_links(soup):
links = []
for link in soup.find_all("a", href=True):
url = link["href"]
if not url.startswith("http"):
url = "<https://en.wikipedia.org>" + url
links.append(url)
return links
# Bild-URLs aus der Seite extrahieren
def extract_images(soup):
images = []
for img in soup.find_all("img", src=True):
img_url = img["src"]
if not img_url.startswith("http"):
img_url = "https:" + img_url
if "static/images" not in img_url: # Unerwünschte statische Bilder ausschließen
images.append(img_url)
return images
# Alle Tabellen aus der Seite extrahieren
def extract_tables(soup):
tables = []
for table in soup.find_all("table", {"class": "wikitable"}):
table_html = StringIO(str(table))
df = pd.read_html(table_html)[0] # HTML-Tabelle in DataFrame konvertieren
tables.append(df)
return tables
# Absätze aus der Seite extrahieren
def extract_paragraphs(soup):
paragraphs = [p.get_text(strip=True) for p in soup.find_all("p")]
return [p for p in paragraphs if p and len(p) > 10] # Leere oder kurze Absätze herausfiltern
# Extrahierte Daten in separaten Dateien speichern
def store_data(links, images, tables, paragraphs):
# Links in einer Textdatei speichern
with open("wikipedia_links.txt", "w", encoding="utf-8") as f:
for link in links:
f.write(f"{link}n")
# Bilder in einer JSON-Datei speichern
with open("wikipedia_images.json", "w", encoding="utf-8") as f:
json.dump(images, f, indent=4)
# Absätze in einer Textdatei speichern
with open("wikipedia_paragraphs.txt", "w", encoding="utf-8") as f:
for para in paragraphs:
f.write(f"{para}nn")
# Jede Tabelle als CSV-Datei speichern
for i, table in enumerate(tables):
table.to_csv(f"wikipedia_table_{i+1}.csv", index=False, encoding="utf-8-sig")
# Hauptfunktion zum Scrapen einer Wikipedia-Seite und Speichern der extrahierten Daten
def scrape_wikipedia(url):
response = requests.get(url) # Seiteninhalt abrufen
soup = BeautifulSoup(response.text, "html.parser") # Inhalt mit BeautifulSoup parsen
links = extract_links(soup)
images = extract_images(soup)
tables = extract_tables(soup)
paragraphs = extract_paragraphs(soup)
# Speichern aller extrahierten Daten in Dateien
store_data(links, images, tables, paragraphs)
# Anwendungsbeispiel: Scrape Cristiano Ronaldos Wikipedia-Seite
if __name__ == "__main__":
scrape_wikipedia("<https://en.wikipedia.org/wiki/Cristiano_Ronaldo>")
Wenn Sie das Skript ausführen, werden mehrere Dateien in Ihrem Verzeichnis erstellt:
wikipedia_images.jsonenthält alle Bild-URLs.wikipedia_links.txtmit allen Links der Seite.wikipedia_paragraphs.txtmit den extrahierten Absätzen.- CSV-Dateien für jede Tabelle auf der Seite (z. B.
wikipedia_table_1.csv,wikipedia_table_2.csv).
Das Ergebnis könnte wie folgt aussehen:

Das war’s! Sie haben erfolgreich Daten aus Wikipedia extrahiert und in separaten Dateien gespeichert.
Einrichten der Bright Data Wikipedia Scraper API
Die Einrichtung und Verwendung der Bright Data Wikipedia Scraper API ist unkompliziert und in wenigen Minuten erledigt. Befolgen Sie diese Schritte, um schnell loszulegen und mühelos mit dem Sammeln von Daten aus Wikipedia zu beginnen.
Schritt 1: Erstellen Sie ein Bright Data-Konto
Gehen Sie zur Bright Data-Website und melden Sie sich bei Ihrem Konto an. Wenn Sie noch kein Konto haben, erstellen Sie eines – die Anmeldung ist kostenlos. Befolgen Sie diese Schritte:
- Gehen Sie zur Bright Data-Website.
- Klicken Sie auf „Gratis testen“ und folgen Sie den Anweisungen, um Ihr Konto zu erstellen.
- Sobald Sie sich in Ihrem Dashboard befinden, suchen Sie das Kreditkartensymbol in der linken Seitenleiste, um zur Seite „Abrechnung“ zu gelangen.
- Fügen Sie eine gültige Zahlungsmethode hinzu, um Ihr Konto zu aktivieren.
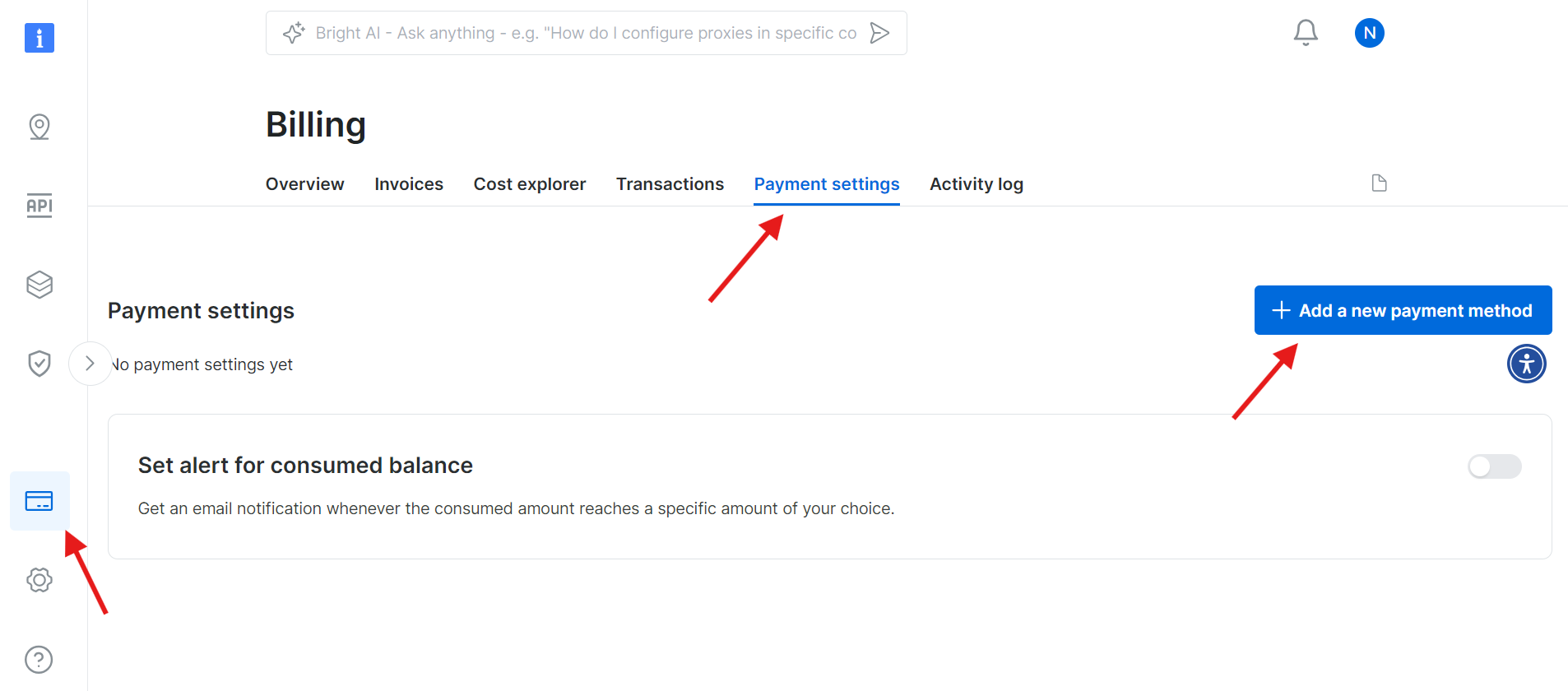
Sobald Ihr Konto erfolgreich aktiviert wurde, navigieren Sie zum Abschnitt „Web Scraper API“ im Dashboard. Hier können Sie nach jeder beliebigen Web-Scraper-API suchen, die Sie verwenden möchten. Suchen Sie für unsere Zwecke nach Wikipedia.
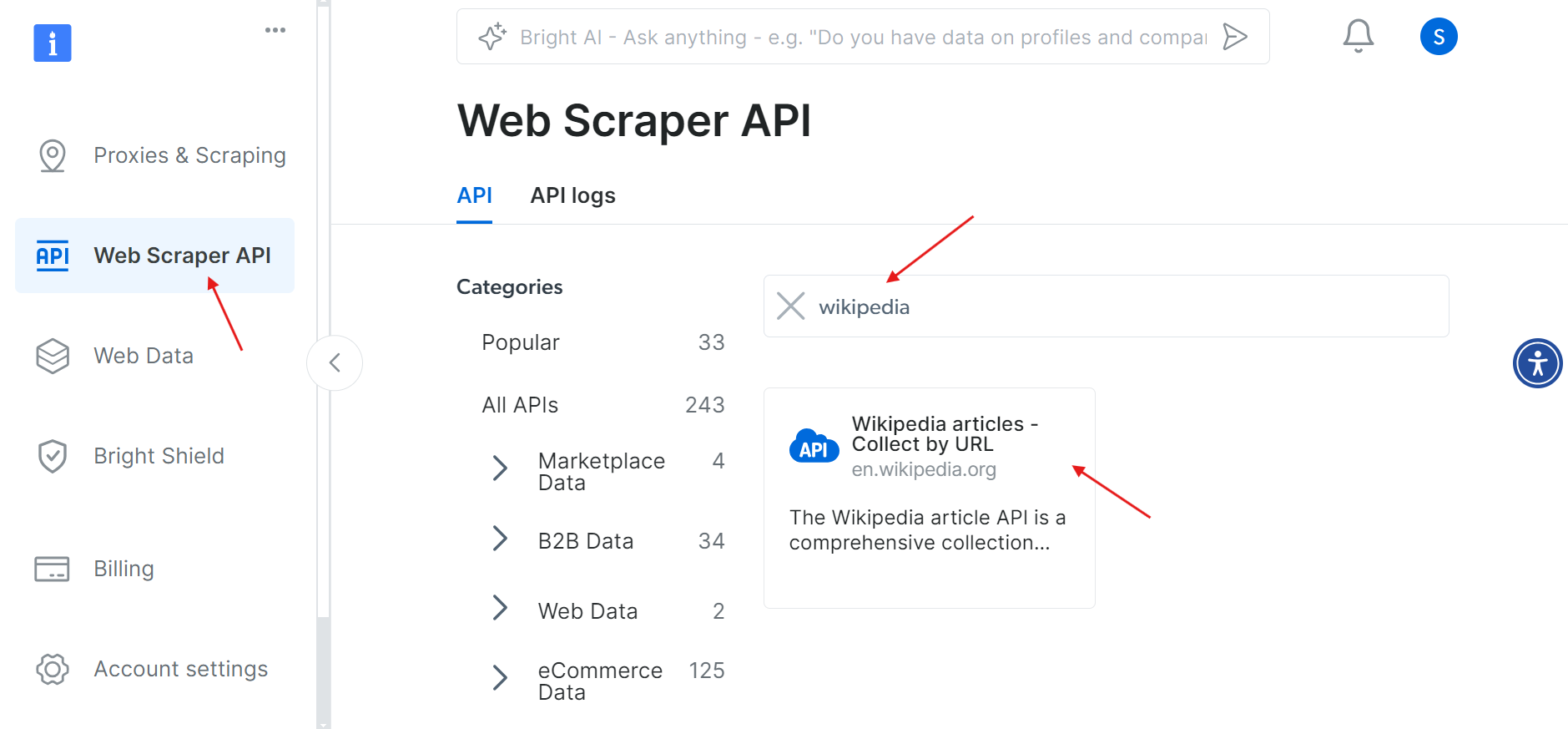
Klicken Sie auf die Option „Wikipedia-Artikel – Nach URL sammeln “. Damit können Sie Wikipedia-Artikel einfach durch Angabe der URLs sammeln.
Schritt 2: Einrichten eines API-Aufrufs
Nachdem Sie geklickt haben, werden Sie zu einer Seite weitergeleitet, auf der Sie Ihren API-Aufruf einrichten können.
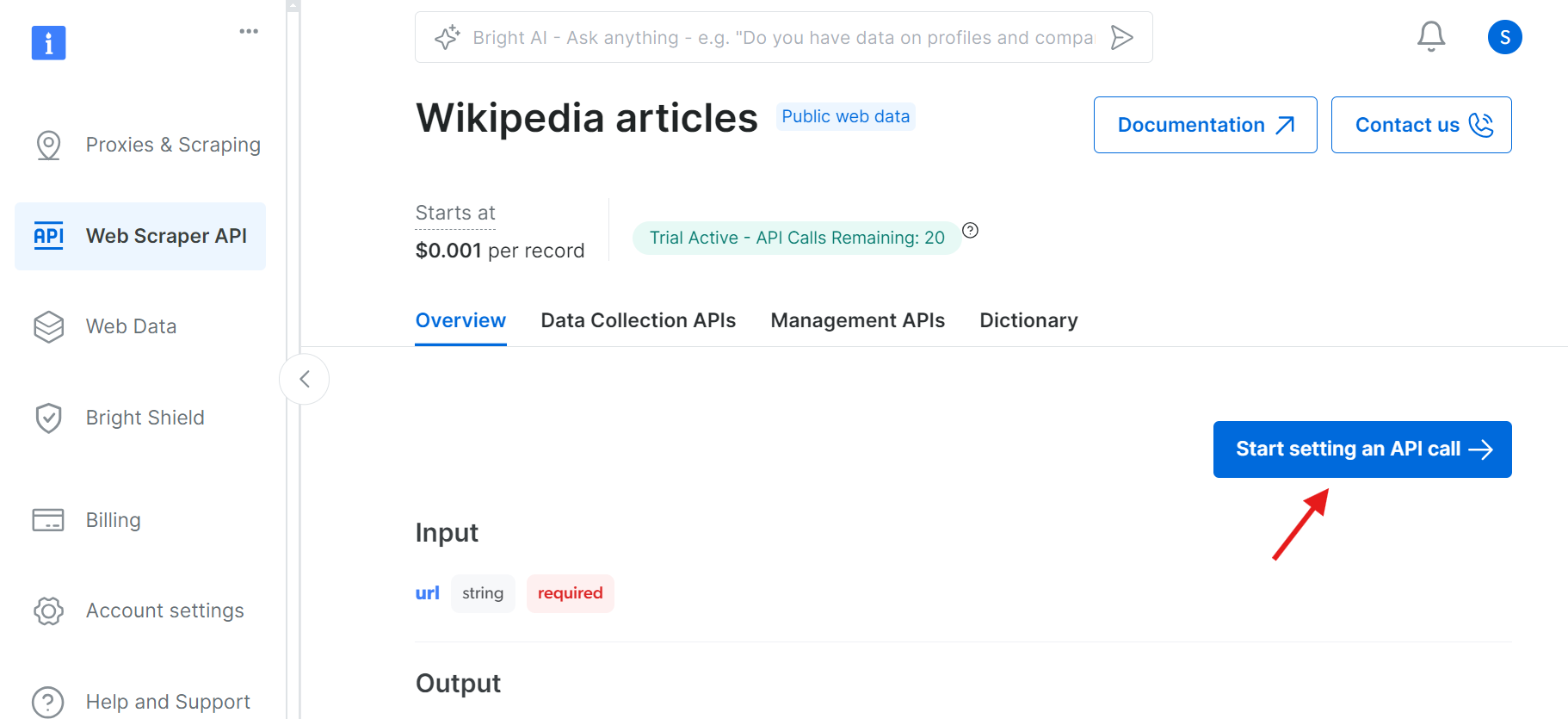
Bevor Sie fortfahren, müssen Sie einen API-Token erstellen, um Ihre API-Aufrufe zu authentifizieren. Klicken Sie auf die Schaltfläche „Token erstellen“ und kopieren Sie den generierten Token. Bewahren Sie diesen Token sicher auf, da Sie ihn später benötigen.
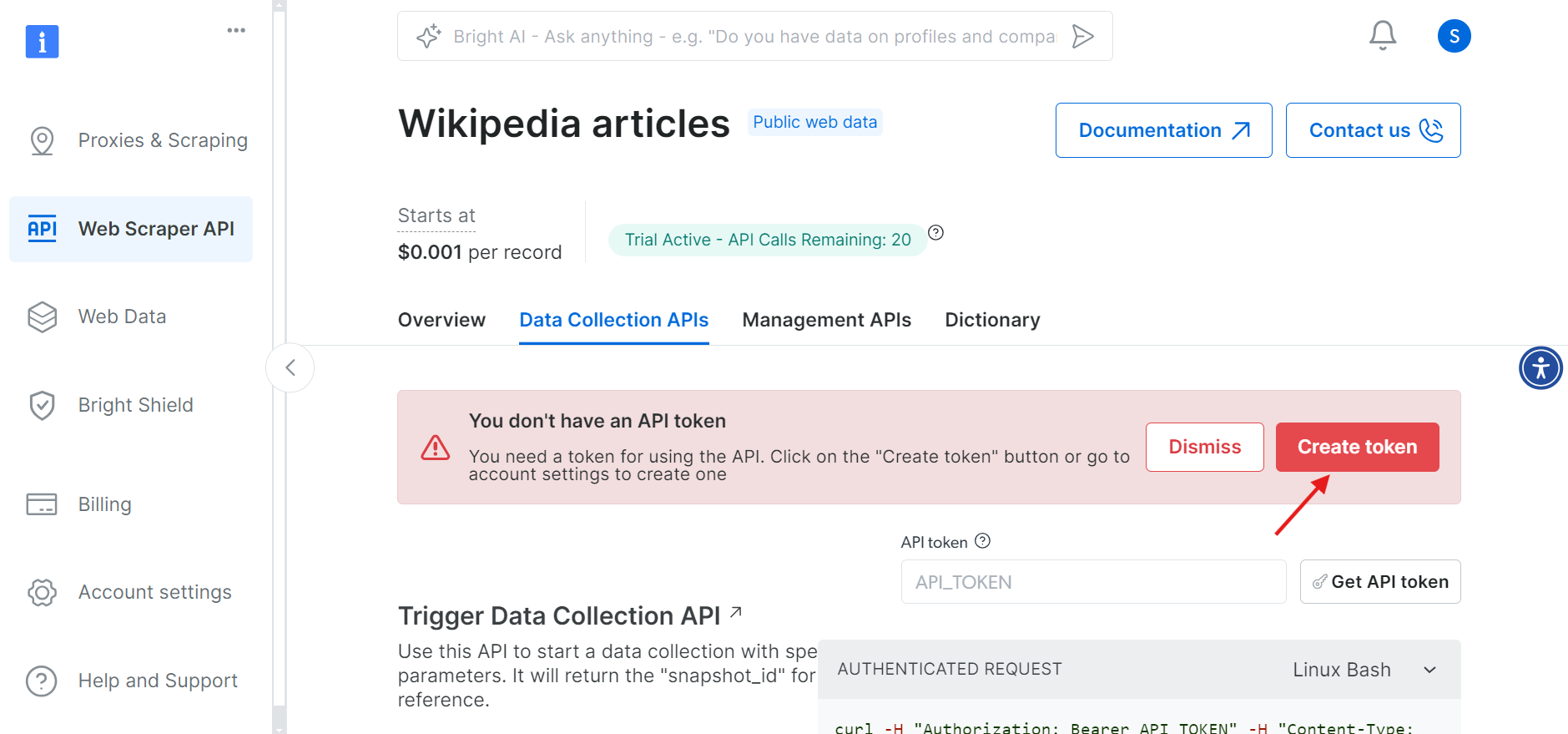
Schritt 3: Parameter festlegen und API-Aufruf generieren
Nachdem Sie nun Ihr Token haben, können Sie Ihren API-Aufruf konfigurieren. Geben Sie die URLs der Wikipedia-Seiten ein, die Sie scrapen möchten, und auf der rechten Seite wird basierend auf Ihrer Eingabe ein cURL-Befehl generiert.
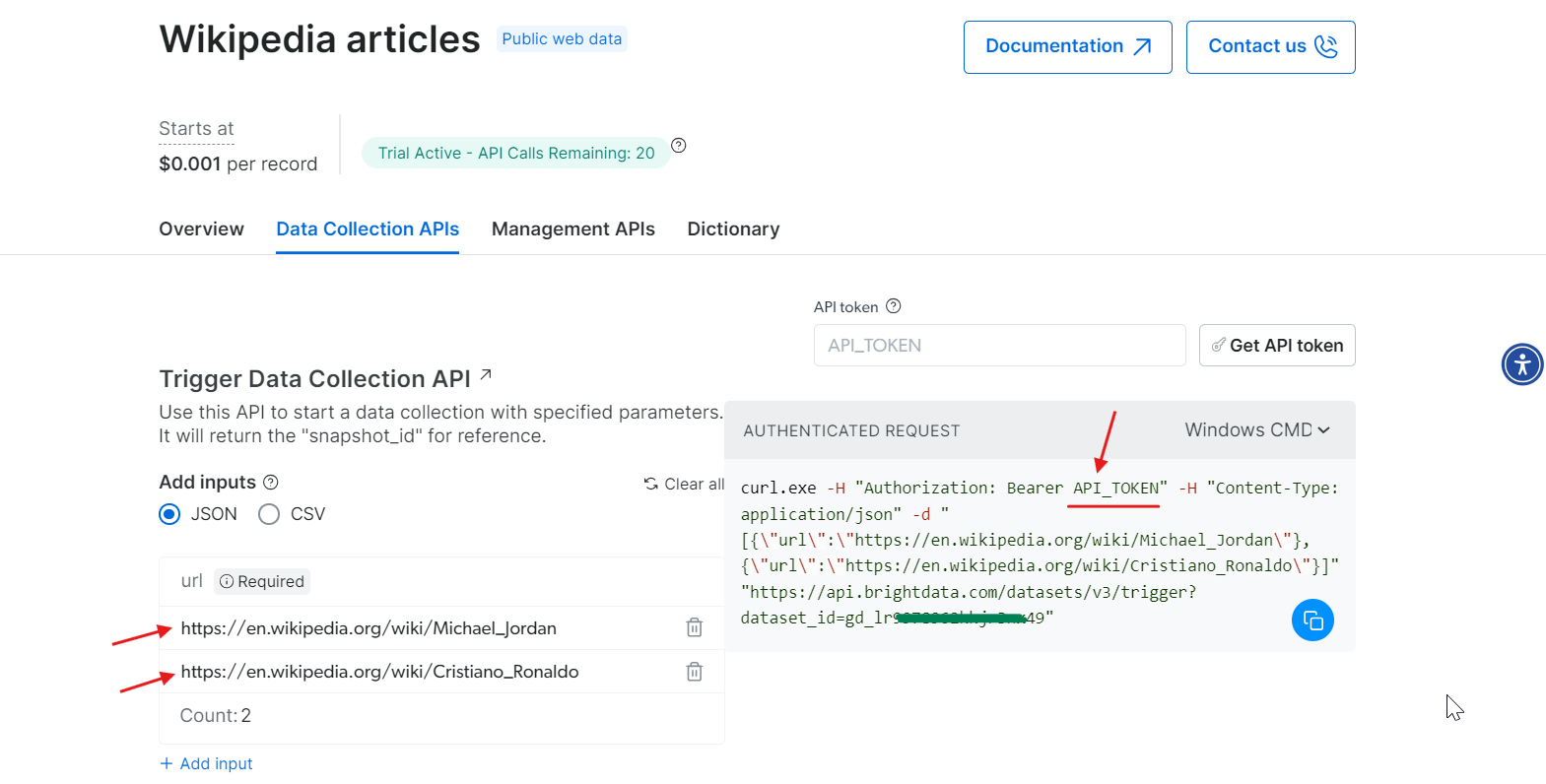
Kopieren Sie den cURL-Befehl, ersetzen Sie API_Token durch Ihr tatsächliches Token und führen Sie ihn in Ihrem Terminal aus. Dadurch wird eine snapshot_id generiert, mit der Sie die gescraped Daten abrufen können.
Schritt 4: Abrufen der Daten
Mit der von Ihnen generierten snapshot_id können Sie nun die Daten abrufen. Fügen Sie diese ID einfach in das Feld „Snapshot ID“ ein, und die API generiert automatisch einen neuen cURL-Befehl auf der rechten Seite. Mit diesem Befehl können Sie die Daten abrufen. Zusätzlich können Sie das Dateiformat für die Daten auswählen, z. B. JSON, CSV oder andere verfügbare Optionen.
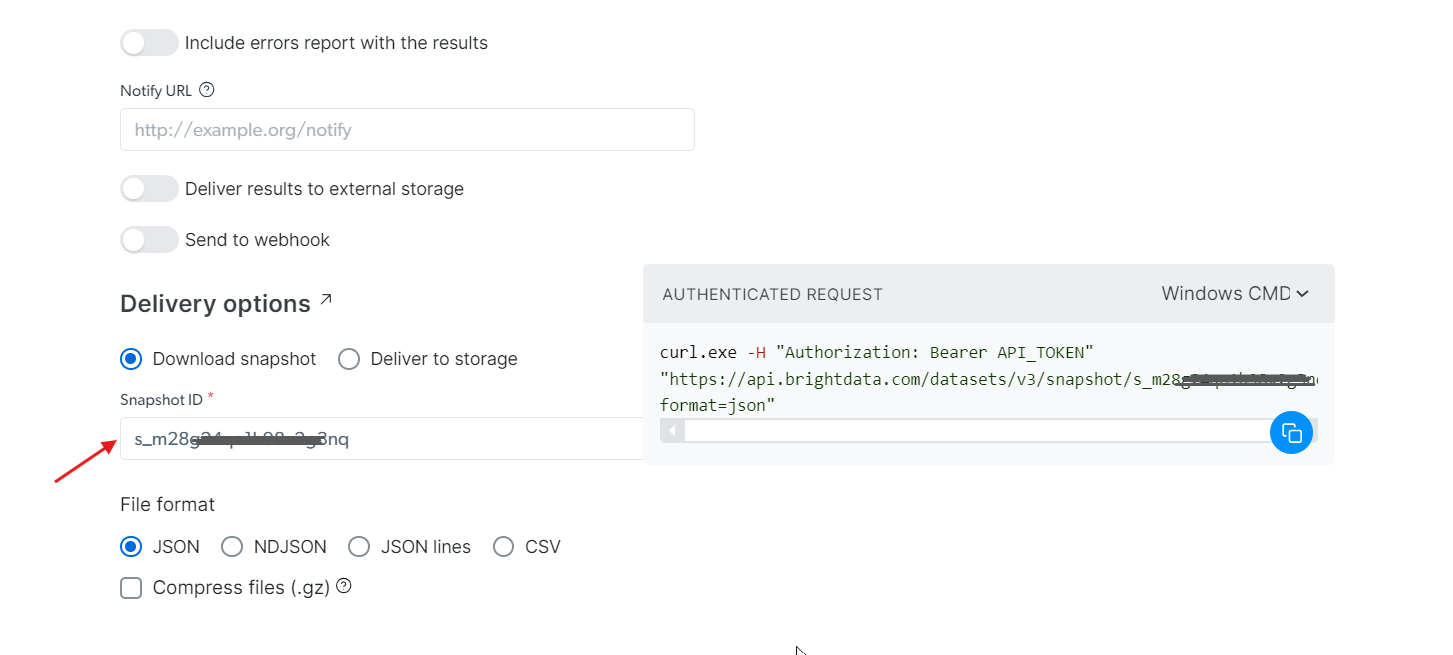
Sie haben auch die Möglichkeit, die Daten an verschiedene Speicherdienste wie Amazon S3, Google Cloud Storage oder Microsoft Azure Storage zu liefern.
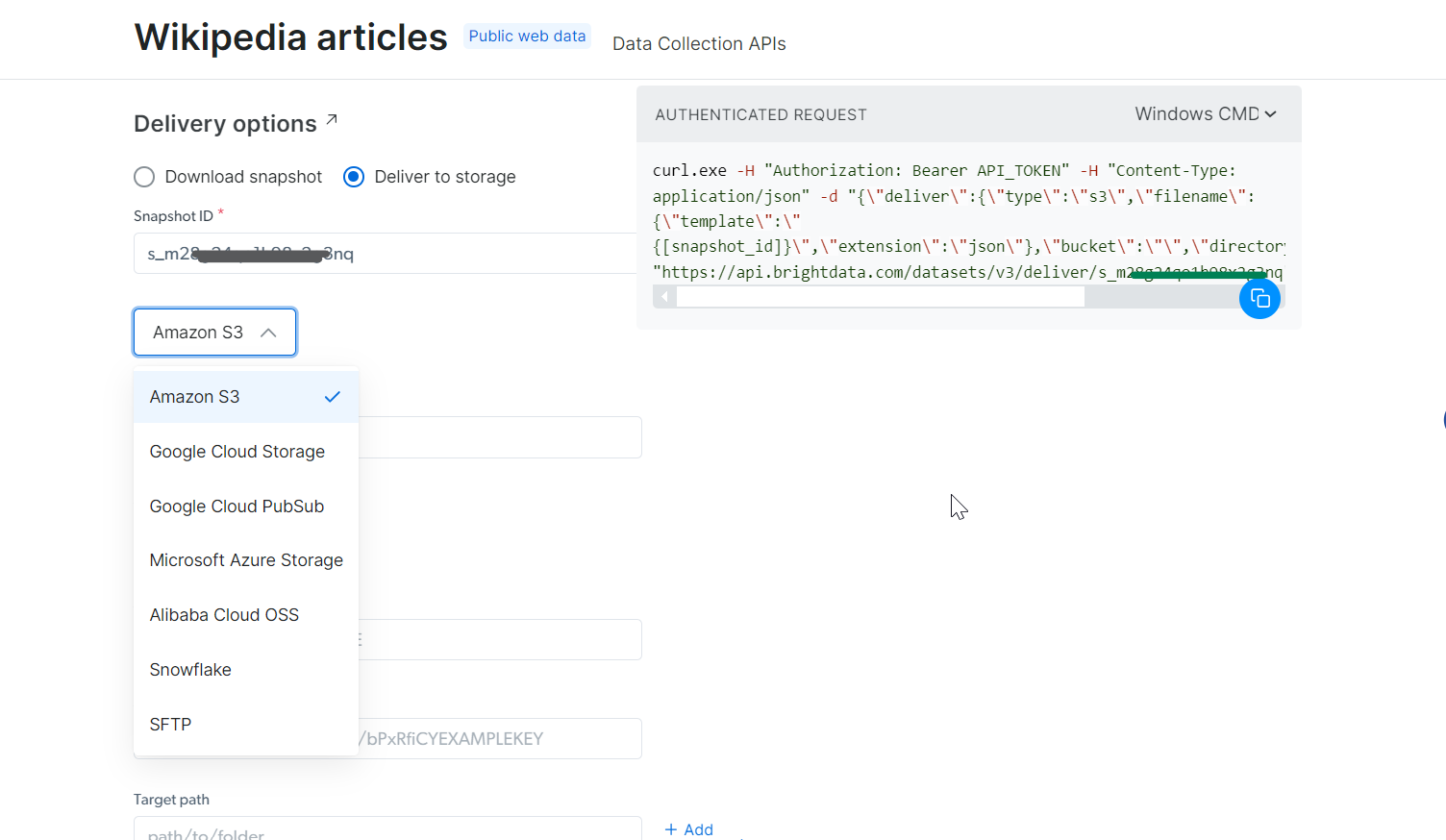
Schritt 5: Befehl ausführen
Nehmen wir für dieses Beispiel an, Sie möchten die Daten in einer JSON-Datei erhalten. Wählen Sie JSON als Dateiformat und kopieren Sie den generierten cURL-Befehl. Wenn Sie die Daten direkt in einer Datei speichern möchten, fügen Sie einfach -o my_data.json am Ende des cURL-Befehls hinzu. Wenn Sie diese Daten lieber auf Ihrem lokalen Rechner speichern möchten, werden die Daten durch Hinzufügen von -o automatisch in der angegebenen Datei gespeichert.
Führen Sie ihn in Ihrem Terminal aus, und Sie erhalten alle extrahierten Daten in nur wenigen Sekunden!
curl.exe -H „Authorization: Bearer 50xxx52c-xxxx-xxxx-xxxx-2748xxxxx487“ „<HTTPS://api.brightdata.com/Datensätze/v3/snapshot/s_mxxg2xxxxx2g3nq?format=json>“ -o my_data.json
Sie möchten das Web-Scraping von Wikipedia nicht selbst durchführen, benötigen aber dennoch die Daten? Dann sollten Sie den Kauf eines Wikipedia-Datensatzes in Betracht ziehen.
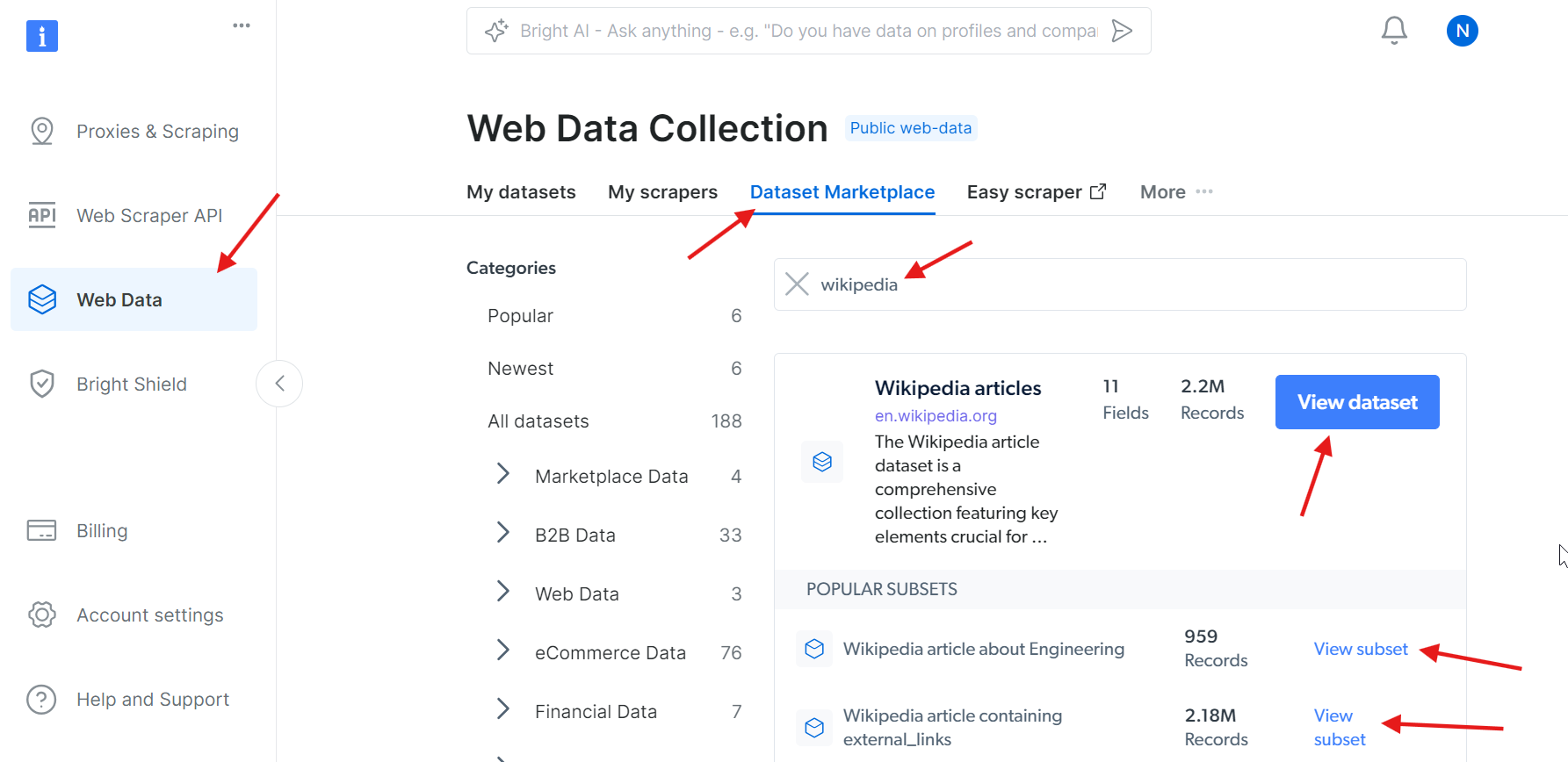
Ja, so einfach ist das!
Fazit
Dieser Artikel behandelt alles, was Sie benötigen, um mit dem Scraping von Wikipedia mit Python zu beginnen. Wir haben erfolgreich eine Vielzahl von Daten extrahiert, darunter Bild-URLs, Textinhalte, Tabellen sowie interne und externe Links. Für eine schnellere und effizientere Datenextraktion ist die Verwendung der Wikipedia Scraper API von Bright Data jedoch eine einfache Lösung.
Möchten Sie andere Websites scrapen? Registrieren Sie sich jetzt und testen Sie unsere Web Scraper API. Starten Sie noch heute Ihre Gratis-Testversion!





