

In diesem Tutorial werden Sie lernen, ein Python-Skript zu erstellen, um den Abschnitt „People Also Ask“ von Google zu scrapen. Dieser enthält häufig gestellte Fragen in Bezug auf Ihre Suchanfrage sowie weitere wertvolle Informationen.
Dann legen wir mal los!
Grundlegendes zur Funktion „People Also Ask“ von Google
„People also ask“ (PAA) bezeichnet einen Abschnitt innerhalb der Google-Suchergebnisseiten (SERPs), der eine dynamische Liste von Fragen mit Bezug auf ihre Suchanfrage enthält:

Dieser Bereich dient der Vertiefung von Themen, die mit Ihrer Suchanfrage zusammenhängen. PAA wurde erstmals 2015 eingeführt und erscheint in den Suchergebnissen als eine Reihe von erweiterbaren Fragen. Sobald Sie auf eine Frage klicken, wird diese erweitert und eine kurze Antwort von einer relevanten Webseite angezeigt, samt einem Link zur Quelle:
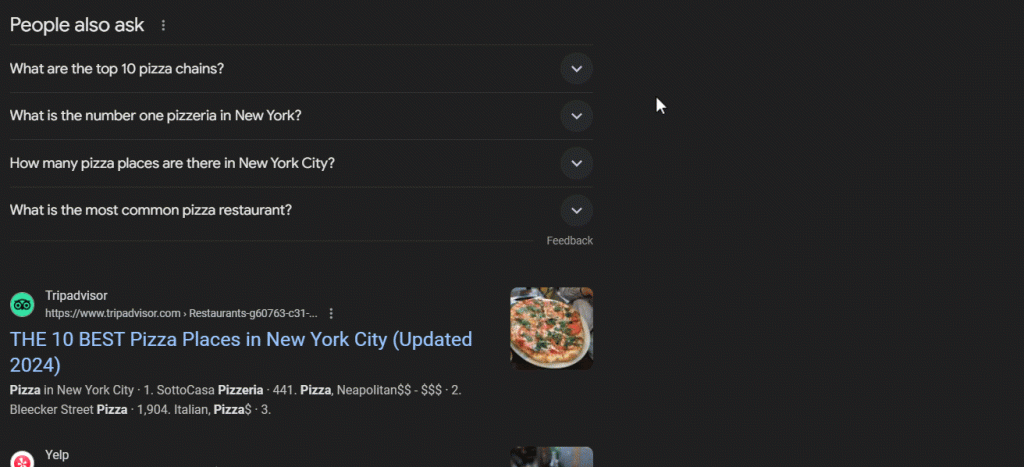
Der Abschnitt „People Also Ask“ wird laufend aktualisiert und entsprechend den Suchanfragen der Benutzer angepasst, sodass Ihnen stets neue und relevante Informationen bereitgestellt werden. Beim Öffnen von Dropdowns werden neue Fragen dynamisch geladen.
Scrapen von Googles „People Also Ask“: Schritt-für-Schritt-Anleitung
Folgen Sie dieser Anleitung und lernen Sie, wie man ein Python-Skript erstellen, um „People Also Ask“ aus einer Google-SERP zu scrapen.
Ziel ist es, die Daten aus den einzelnen Fragen aus dem „People-Also-Ask“-Abschnitt der Seite abzurufen. Sollten Sie sich stattdessen für das Scraping von Google interessieren, folgen Sie unserer Anleitung zum SERP-Scraping.
Schritt 1: Projektvorbereitung
Stellen Sie vor Beginn sicher, dass Sie Python 3 auf Ihrem Rechner installiert haben. Ansonsten laden Sie es herunter, starten Sie die ausführbare Datei und folgen Sie den Anweisungen des Installationsassistenten.
Als nächstes verwenden Sie die nachfolgenden Befehle, um ein Python-Projekt mit einer virtuellen Umgebung zu initialisieren:
mkdir people-also-ask-scraper
cd people-also-ask-scraper
python -m venv env
Das Verzeichnis people-also-ask-scraper stellt den Projektordner Ihres Python PAA-Scrapers dar.
Laden Sie den Projektordner in Ihre bevorzugte Python-IDE.Hierfür sind PyCharm Community Edition oder Visual Studio Code mit der Python-Erweiterung zwei gute Optionen.
Erstellen Sie im Projektordner eine scraper.py- Datei. Dies ist zunächst ein leeres Skript, das aber bald die Scraping-Logik beinhalten wird:

Aktivieren Sie im Terminal der IDE die virtuelle Umgebung. Führen Sie unter Linux oder macOS folgenden Befehl aus:
./env/bin/activate
Oder führen Sie ihn wie folgt unter Windows aus:
env/Scripts/activate
Großartig, nun haben Sie eine Python-Umgebung für Ihren Scraper!
Schritt 2: Installation von Selenium
Google ist eine Plattform, die Benutzerinteraktion erfordert. Zudem kann das Fälschen einer gültigen Google-Such-URL eine Herausforderung sein. Daher ist es am sinnvollsten, innerhalb eines Browsers mit der Suchmaschine zu arbeiten.
Anders ausgedrückt: Um den Abschnitt „People Also Ask“ zu scrapen, bedarf es eines Browser-Automatisierungstools. Falls Sie mit diesem Konzept nicht vertraut sind, ermöglichen Browser-Automatisierungstools das Rendern und die Interaktion mit Webseiten innerhalb eines steuerbaren Browsers. Eine der besten Optionen in Python ist Selenium!
Führen Sie zur Installation von Selenium den nachstehenden Befehl in einer aktivierten virtuellen Python-Umgebung aus:
pip install selenium
Das Paket selenium pip wird zu Ihren Projektabhängigkeiten hinzugefügt. Das kann eine Weile in Anspruch nehmen. Seien Sie also geduldig.
Nähere Angaben zur Verwendung dieses Tools finden Sie in unserem Leitfaden zu Web-Scraping mit Selenium.
Großartig, damit haben Sie nun alles, was Sie zum Scrapen von Google-Seiten benötigen!
Schritt 3: Besuchen Sie die Google-Startseite
Importieren Sie Selenium in scraper.py und initialisieren Sie ein WebDriver- Objekt zur Steuerung einer Chrome-Instanz im Headless-Modus:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
# to control a Chrome window in headless mode
options = Options()
options.add_argument("--headless") # comment it while developing
# initialize a web driver instance with the
# specified options
driver = webdriver.Chrome(
service=Service(),
options=options
)
Das obige Snippet erzeugt eine Chrome- WebDriver- Instanz, d. h. das Objekt zur programmatischen Steuerung eines Chrome-Fensters. Die Headless- Option konfiguriert Chrome für die Ausführung im Headless-Modus. Zur Fehlersuche sollte diese Zeile kommentiert werden, damit Sie die Vorgänge des automatisierten Skripts in Echtzeit beobachten können.
Verwenden Sie anschließend die get()- Methode, um eine Verbindung mit der Google-Startseite herzustellen:
driver.get("https://google.com/")
Denken Sie daran, die Ressourcen für den Treiber am Ende des Skripts freizugeben:
driver.quit()
Alles zusammengenommen erhalten Sie:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
# to control a Chrome window in headless mode
options = Options()
options.add_argument("--headless") # comment it while developing
# initialize a web driver instance with the
# specified options
driver = webdriver.Chrome(
service=Service(),
options=options
)
# connect to the Google home page
driver.get("https://google.com/")
# scraping logic...
# close the browser and free up the resources
driver.quit()
Fantastisch, Sie sind bereit, dynamische Websites zu scrapen!
Schritt 4: Umgang mit dem DSGVO-Cookie-Dialog
Hinweis: Wenn Sie sich nicht in der EU (Europäische Union) befinden, können Sie diesen Schritt auslassen.
Führen Sie das Skript scraper.py im Headed-Modus aus. Dadurch wird kurz ein Chrome-Browserfenster geöffnet, das eine Google-Seite anzeigt, ehe der Befehl quit() es wieder schließt. Sollten Sie sich in der EU befinden, wird Folgendes eingeblendet:
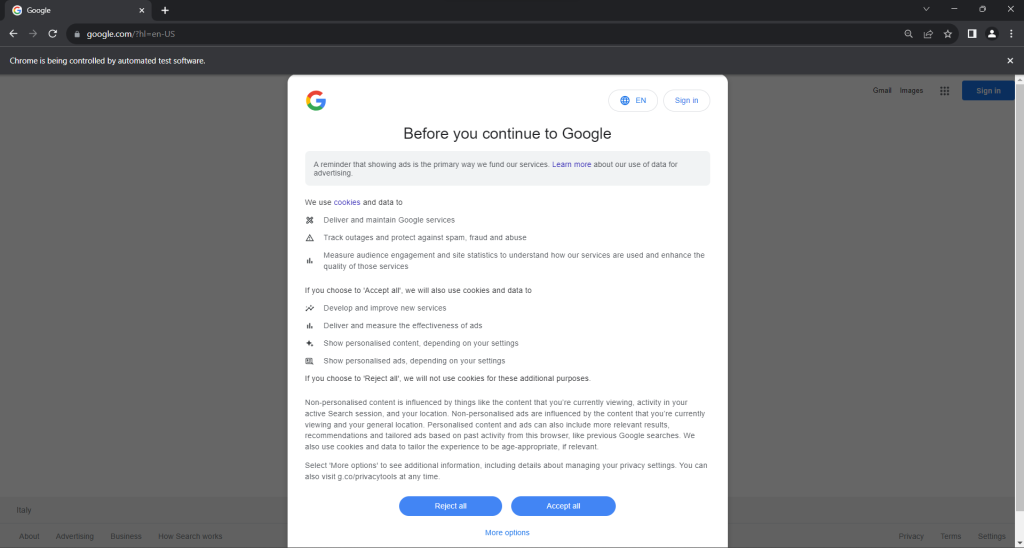
Die Meldung „Chrome wird von automatisierter Testsoftware gesteuert.“ gewährleistet, dass Selenium Chrome wunschgemäß steuert.
EU-Benutzern wird aus DSGVO- Gründen ein Dialog zur Cookie-Richtlinie angezeigt. Sollte dies bei Ihnen der Fall sein, müssen Sie sich damit befassen, wenn Sie mit der zugrunde liegenden Seite interagieren möchten. Andernfalls können Sie zu Schritt 5 übergehen.
Öffnen Sie eine Google-Seite im Inkognito-Modus und überprüfen Sie den DSGVO-Cookie-Dialog. Klicken Sie mit der rechten Maustaste darauf und wählen Sie die Option „Überprüfen“:
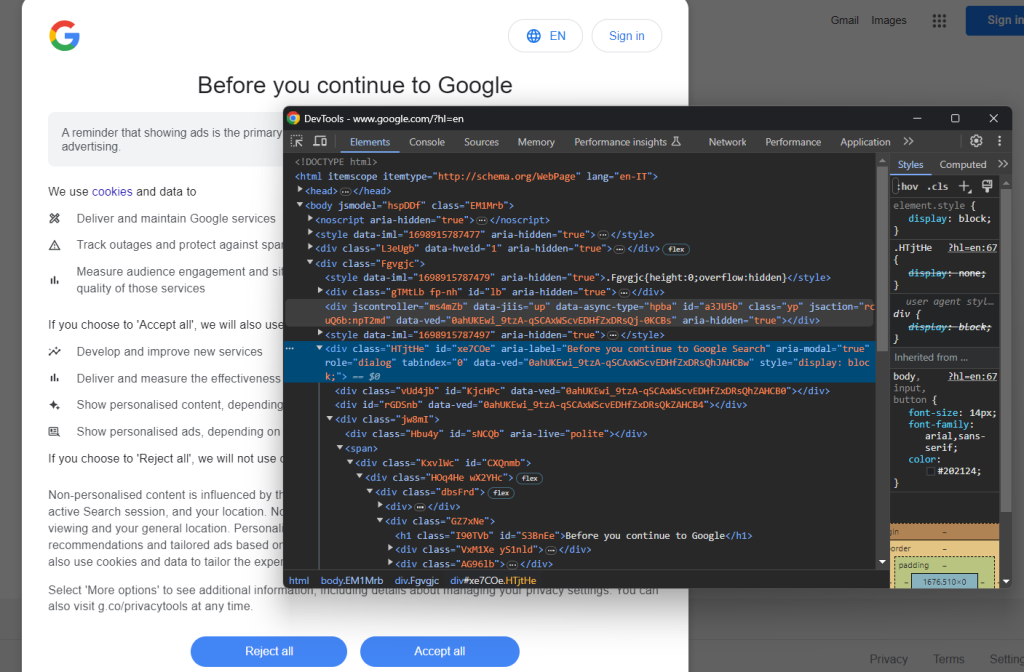
Anmerkung: Das HTML-Element des Dialogs finden Sie mit:
cookie_dialog = driver.find_element(By.CSS_SELECTOR, "[role='dialog']")
find_element() ist eine von Selenium bereitgestellte Methode, um HTML-Elemente auf der Seite über verschiedene Strategien zu finden. Im vorliegenden Fall haben wir einen CSS-Selektor verwendet.
Achten Sie darauf, By wie folgt zu importieren:
from selenium.webdriver.common.by import By
Konzentrieren Sie sich nun auf die Schaltfläche „Alle akzeptieren“:
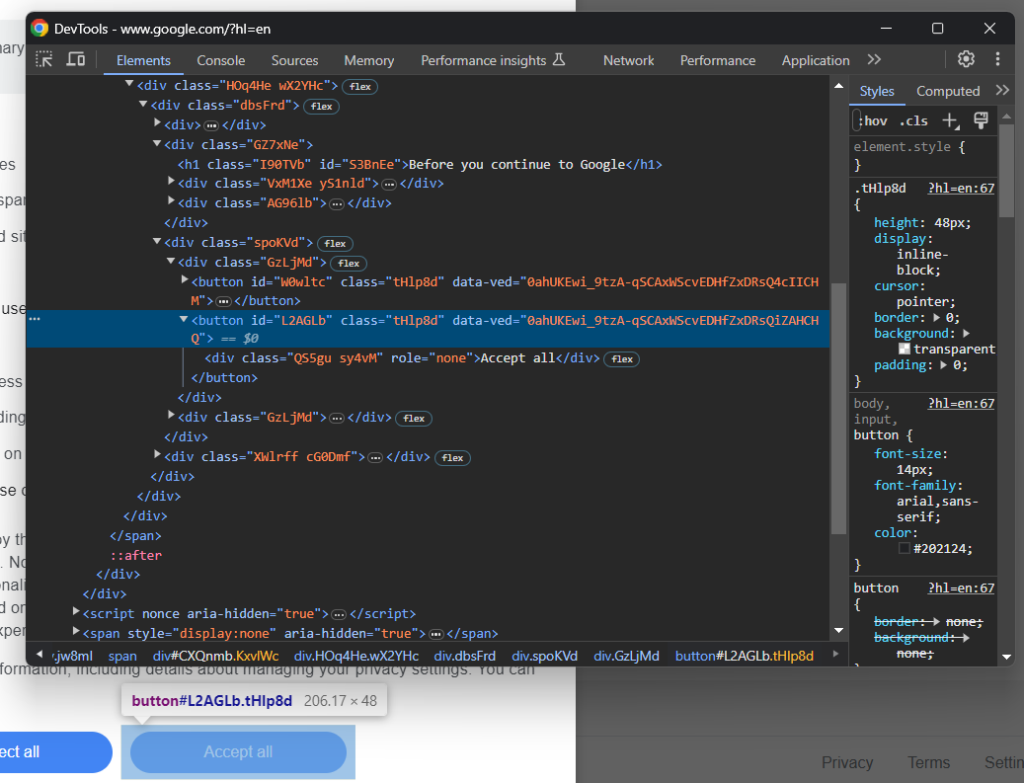
Wie Sie sehen können, gibt es keine einfache Methode, sie auszuwählen, da ihre CSS-Klasse zufällig generiert zu sein scheint. Deswegen können Sie sie mit einem XPath-Ausdruck, der auf ihren Inhalt abzielt, abrufen:
accept_button = cookie_dialog.find_element(By.XPATH, "//button[contains(., 'Accept')]")
Mit dieser Anweisung wird die erste Schaltfläche im Dialog gefunden, deren Text die Zeichenfolge „Akzeptieren“ enthält. Weitere Informationen finden Sie in unserem Leitfaden zu XPath- vs. CSS-Selektor.
Hier sehen Sie, wie sich alles zusammenfügt, um den optionalen Google-Cookie-Dialog zu verwalten:
try:
# select the dialog and accept the cookie policy
cookie_dialog = driver.find_element(By.CSS_SELECTOR, "[role='dialog']")
accept_button = cookie_dialog.find_element(By.XPATH, "//button[contains(., 'Accept')]")
if accept_button is not None:
accept_button.click()
except NoSuchElementException:
print("Cookie dialog not present")
Die click()- Anweisung betätigt die Schaltfläche „Alle akzeptieren“, um den Dialog zu schließen und eine Benutzerinteraktion zuzulassen. Ist das Dialogfeld für die Cookie-Richtlinie jedoch nicht enthalten, wird stattdessen eine NoSuchElementException ausgelöst. Das Skript fängt diese ab und fährt fort.
Denken Sie daran, die NoSuchElementException zu importieren:
from selenium.common import NoSuchElementException
Gut gemacht! Nun sind Sie bereit, sich auf die Seite mit dem Abschnitt „People-Also-Ask“ zu begeben.
Schritt 5: Absenden des Suchformulars
Rufen Sie die Google-Startseite in Ihrem Browser auf und untersuchen Sie das Suchformular. Klicken Sie dazu mit der rechten Maustaste darauf und wählen Sie die Option „Überprüfen“:
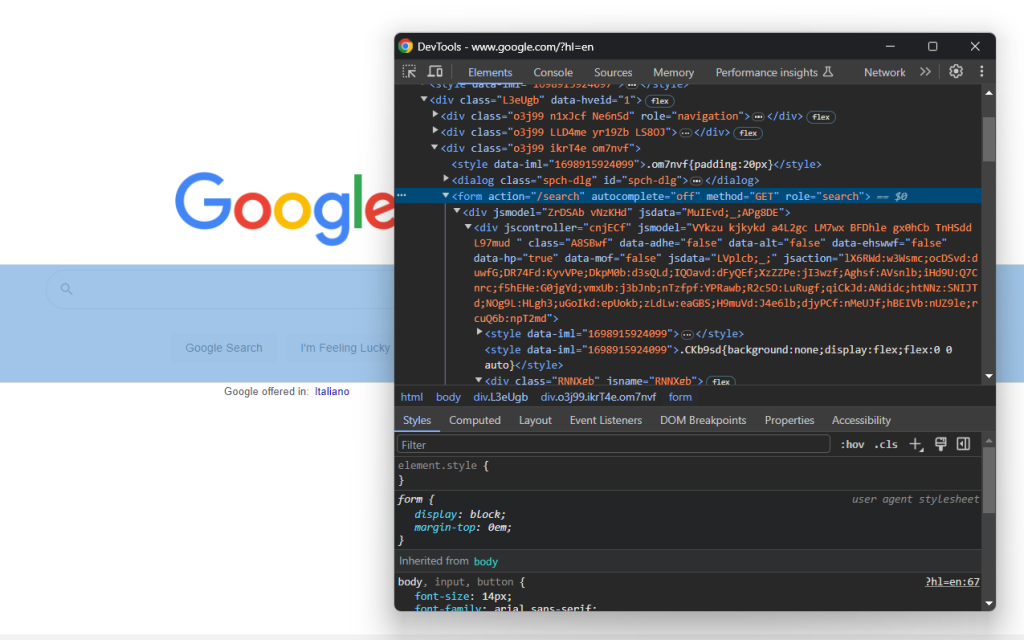
Dieses Element hat keine CSS-Klasse, aber Sie können es über sein action- Attribut auswählen:
search_form = driver.find_element(By.CSS_SELECTOR, "form[action='/search']")
Wenn Sie Schritt 4 übersprungen haben, importieren Sie By mit:
from selenium.webdriver.common.by import By
Erweitern Sie den HTML-Code des Formulars und werfen Sie einen Blick auf den Suchtext Abschnitt:
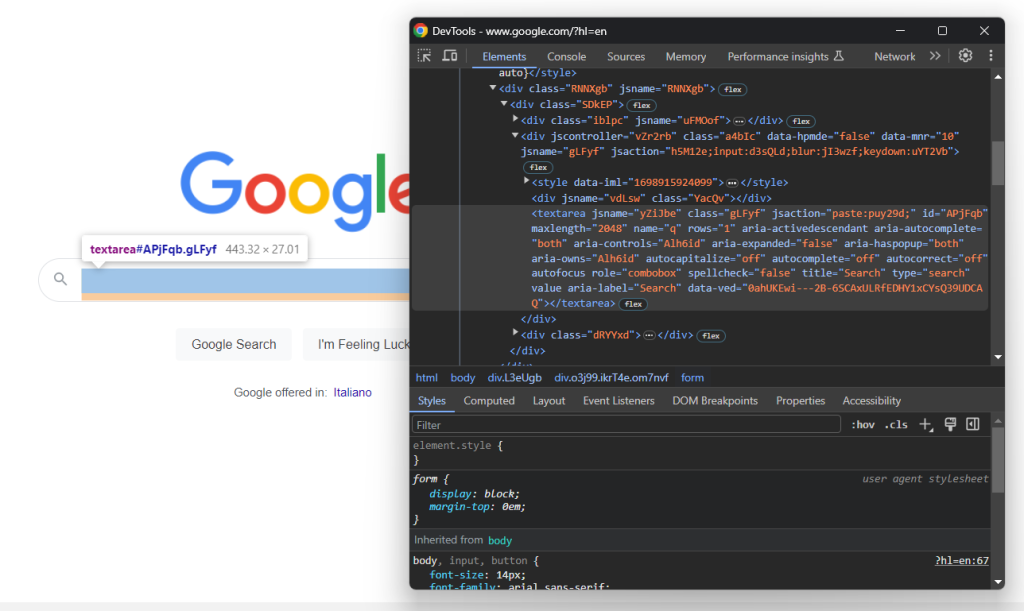
Die CSS-Klasse dieses Knotens scheint zufällig generiert zu sein. Wählen Sie sie daher über ihr aria-label- Attribut aus. Geben Sie dann mit der Methode send_keys() die gewünschte Suchanfrage ein:
search_textarea = search_form.find_element(By.CSS_SELECTOR, "textarea[aria-label='Search']")
search_query = "Bright Data"
search_textarea.send_keys(search_query)
In diesem Beispiel lautet die Suchanfrage „Bright Data“, aber auch jede andere Suche ist möglich.
Senden Sie das Formular ab und lösen Sie damit einen Seitenwechsel aus:
search_form.submit()
Großartig! Der gesteuerte Browser leitet daraufhin zur Google-Seite weiter, die den Abschnitt „People Also Ask“ enthält.
Wenn Sie das Skript im Headed-Modus ausführen, sollten Sie vor dem Schließen des Browsers folgendes sehen:
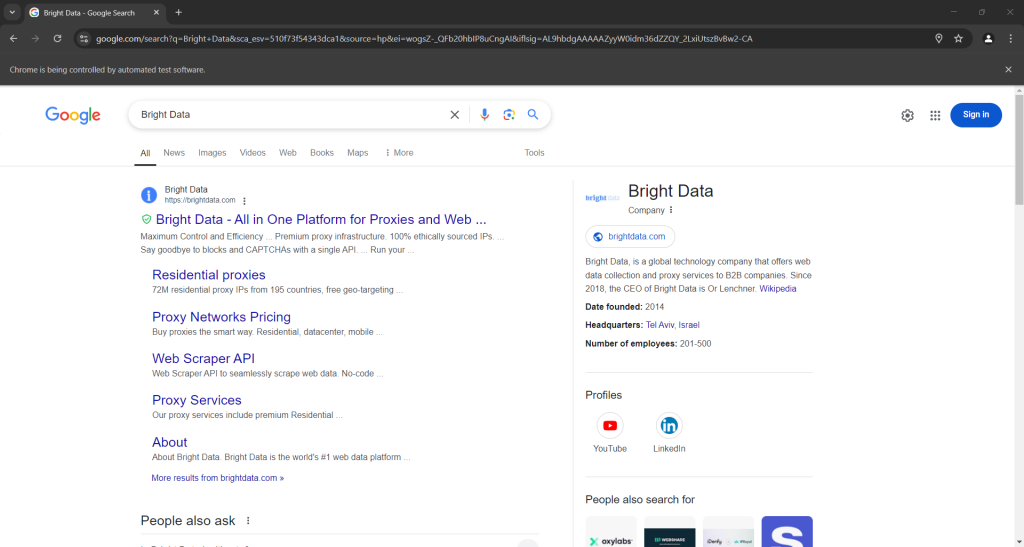
Achten Sie auf den Abschnitt „People Also Ask“ am unteren Rand des obigen Screenshots.
Schritt 6: Wählen Sie den „People-Also-Ask“-Knoten
Inspizieren Sie das HTML-Element „People-Also-Ask“:
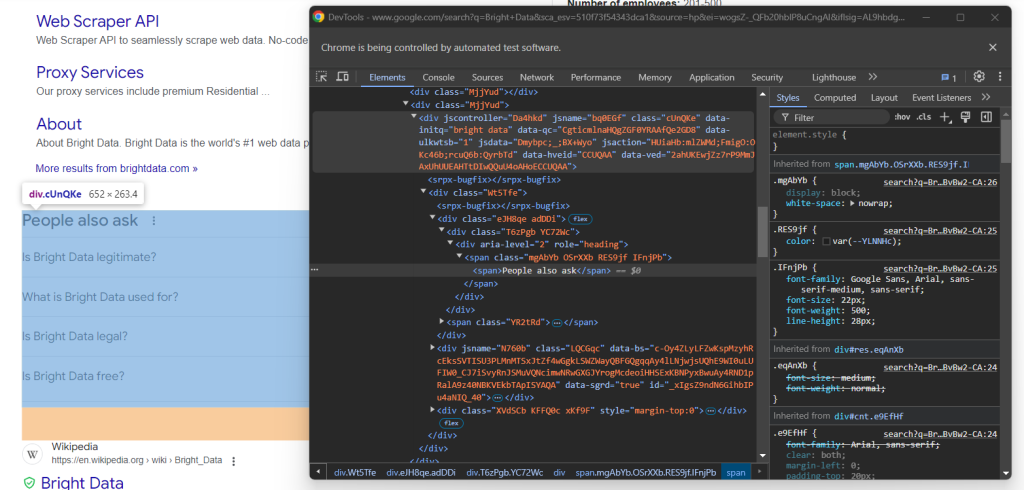
Auch hier gibt es keine einfache Möglichkeit, es auszuwählen. Diesmal geht es darum, das <div> Element mit den Attributen jscontroller, jsname und jsaction abzurufen, das ein div mit role=heading und dem Text „People Also Ask“ enthält:
people_also_ask_div = WebDriverWait(driver, 5).until(
EC.presence_of_element_located((
By.XPATH, "//div[@jscontroller and @jsname and @jsaction][.//div[@role='heading' and contains(., 'People also ask')]]"
))
)
Bei WebDriverWait handelt es sich um eine spezielle Selenium-Klasse, die das Skript pausiert, bis eine bestimmte Bedingung auf der Seite erfüllt ist. Oben wird bis zu 5 Sekunden gewartet, bevor das gewünschte HTML-Element erscheint. Dieser Vorgang ist erforderlich, damit die Seite nach dem Absenden des Formulars vollständig geladen werden kann.
Der XPath-Ausdruck, der in presence_of_element_located() genutzt wird, ist zwar komplex, beschreibt aber genau die Kriterien, die für die Auswahl des Elements „People Also Ask“ erforderlich sind.
Denken Sie daran, die erforderlichen Importe zu ergänzen:
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
Zeit, Daten aus dem „People-Also-Ask“-Abschnitt von Google zu scrapen!
Schritt 7: Scrapen von „People-Also-Ask“
Initialisieren Sie als Erstes eine Datenstruktur, in der die gescrapten Daten gespeichert werden sollen:
people_also_ask_questions = []
Dabei muss es sich um ein Array handeln, da der Abschnitt „People-Also-Ask“ diverse Fragen enthält.
Überprüfung Sie nun das Dropdown-Menü der ersten Frage des Knotens „People Also Ask“:
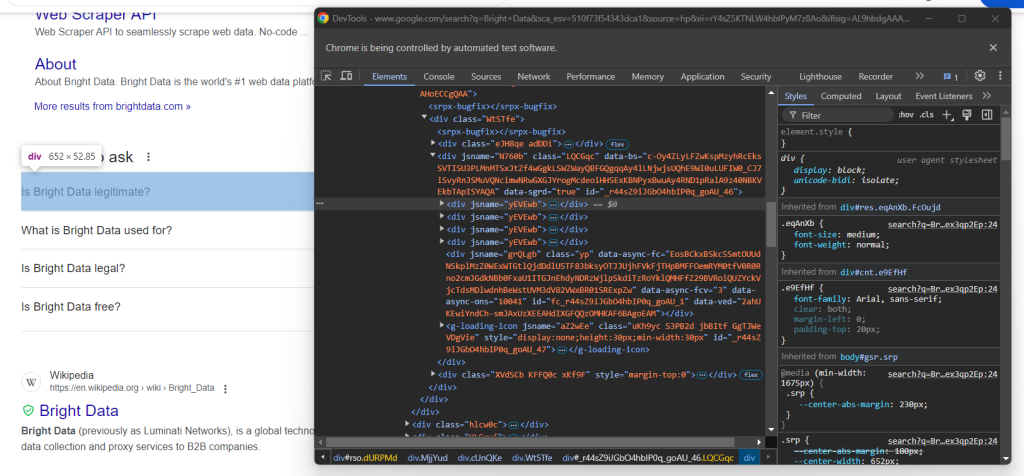
Hier sieht man, dass die relevanten Elemente die Unterelemente des data-sgrd="true" <div> innerhalb des Elements „People Also Ask“ mit nur dem Attribut jsname sind. Die letzten beiden Unterelemente werden von Google als Platzhalter verwendet und dynamisch ausgefüllt, sobald Sie Dropdowns öffnen.
Wählen Sie die Frage-Dropdowns mit folgender Logik aus:
people_also_ask_inner_div = people_also_ask_div.find_element(By.CSS_SELECTOR, "[data-sgrd='true']")
people_also_ask_inner_div_children = people_also_ask_inner_div.find_elements(By.XPATH, "./*")
for child in people_also_ask_inner_div_children:
# if the current element is a question dropdown
if child.get_attribute("jsname") is not None and child.get_attribute("class") == '':
# scraping logic...
Klicken Sie auf das Element, um es zu erweitern:
child.click()
Konzentrieren Sie sich nun auf den Inhalt innerhalb der Frageelemente:
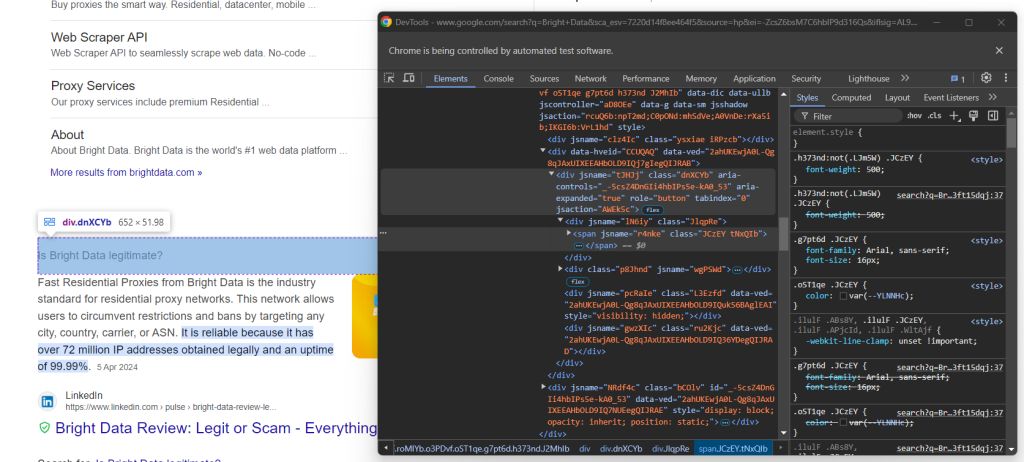
Achten Sie darauf, dass die Frage in dem <span> innerhalb des aria-expanded="true" Knotens enthalten ist. Scrapen Sie sie wie folgt:
question_title_element = child.find_element(By.CSS_SELECTOR, "[aria-expanded='true'] span")
question_title = question_title_element.text
Überprüfen Sie anschließend das Antwort-Element:
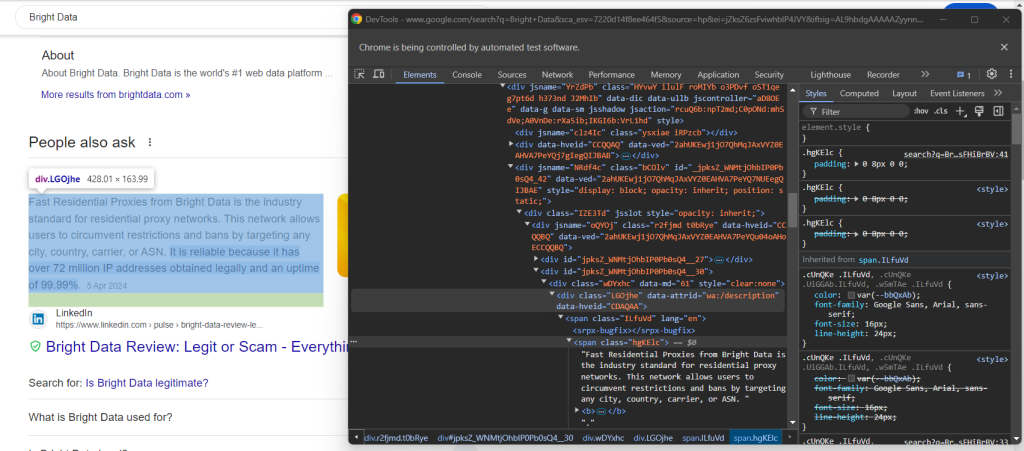
Stellen Sie fest, wie Sie die Antwort abrufen können, indem Sie den Text im Knoten <span> mit dem Attribut Lang innerhalb des Elements data-attrid="wa:/description" erfassen:
question_description_element = child.find_element(By.CSS_SELECTOR, "[data-attrid='wa:/description'] span[lang]")
question_description = question_description_element.text
Überprüfen Sie anschließend das optionale Bild im Antwortfeld:
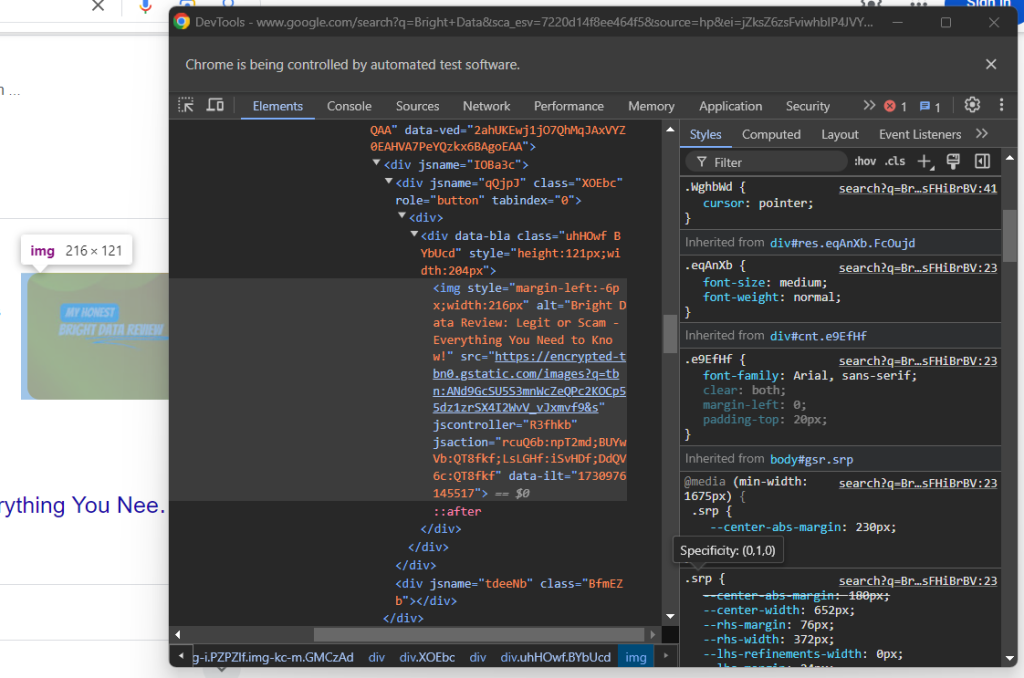
Die URL erhalten Sie, indem Sie mit dem Attribut data-ilt auf das Attribut src des Elements <img> zugreifen:
try:
question_image_element = child.find_element(By.CSS_SELECTOR, "img[data-ilt]")
question_image = question_image_element.get_attribute("src")
except NoSuchElementException:
question_image = None
Da das Bildelement optional ist, muss der obige Code in einen try ... except -Block eingeschlossen werden. Ist der Knoten nicht in der aktuellen Frage vorhanden, löst find_element() eine NoSuchElementException aus. Der Code fängt sie ab und fährt fort, in diesem Fall,
Wenn Sie Schritt 4 übersprungen haben, importieren Sie die Ausnahme:
from selenium.common import NoSuchElementException
Überprüfen Sie abschließend den Quelltextabschnitt:
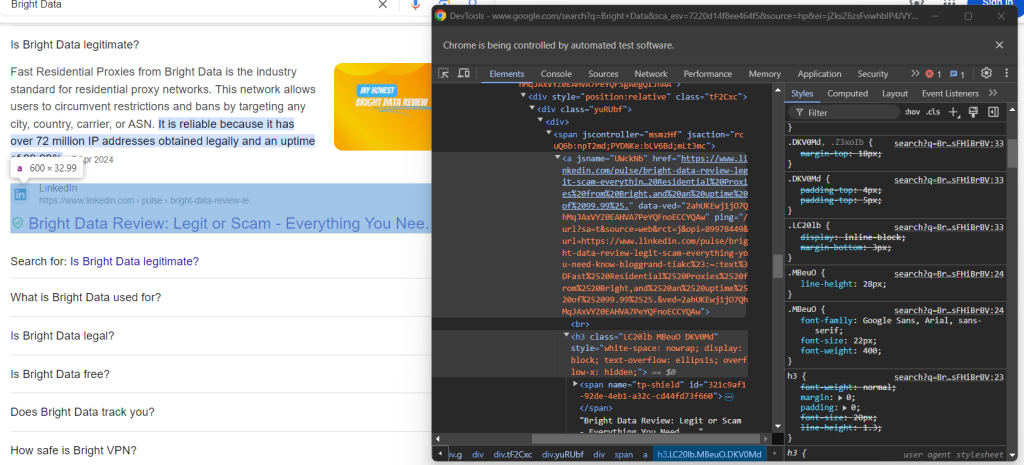
Sie können die URL der Quelle abrufen, indem Sie das <a> übergeordnete Element des<h3> Elements auswählen:
question_source_element = child.find_element(By.XPATH, ".//h3/ancestor::a")
question_source = question_source_element.get_attribute("href")
Verwenden Sie die gescrapten Daten, um ein neues Objekt zu erstellen und fügen Sie es dem Array people_also_ask_questions hinzu:
people_also_ask_question = {
"title": question_title,
"description": question_description,
"image": question_image,
"source": question_source
}
people_also_ask_questions.append(people_also_ask_question)
Super gemacht! Sie haben soeben den Abschnitt „People Also Ask“ von einer Google-Seite abgerufen.
Schritt 8: Export der gescrapten Daten nach CSV
Wenn Sie people_also_ask_questions ausdrucken, erhalten Sie folgende Ausgabe:
[{'title': 'Is Bright Data legitimate?', 'description': 'Fast Residential Proxies from Bright Data is the industry standard for residential proxy networks. This network allows users to circumvent restrictions and bans by targeting any city, country, carrier, or ASN. It is reliable because it has 400M+ monthly IP addresses obtained legally and an uptime of 99.99%.', 'image': 'https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcSU5S3mnWcZeQPc2KOCp55dz1zrSX4I2WvV_vJxmvf9&s', 'source': 'https://www.linkedin.com/pulse/bright-data-review-legit-scam-everything-you-need-know-bloggrand-tiakc#:~:text=Fast%20Residential%20Proxies%20from%20Bright,and%20an%20uptime%20of%2099.99%25.'}, {'title': 'What is Bright Data used for?', 'description': "Bright Data is the world's #1 web data platform, supporting the public data needs of over 22,000 organizations in nearly every industry. Using our solutions, organizations research, monitor, and analyze web data to make better decisions.", 'image': None, 'source': "https://brightdata.com/about#:~:text=Bright%20Data%20is%20the%20world's,data%20to%20make%20better%20decisions."}, {'title': 'Is Bright Data legal?', 'description': "Bright Data's platform, technology, and network (collectively, “Services”) are meant for legitimate and legal purposes only and are subject to the Bright Data Master Service Agreement.", 'image': None, 'source': "https://brightdata.com/acceptable-use-policy#:~:text=Bright%20Data's%20platform%2C%20technology%2C%20and,Bright%20Data%20Master%20Service%20Agreement."}, {'title': 'Is Bright Data free?', 'description': 'Bright Data offers four free proxy solutions to meet various needs: Anonymous Proxies: These top-performing anonymous proxies let you access websites anonymously, routing traffic through a vast Residential IP Network of 400M+ monthly IPs, concealing your true location.', 'image': None, 'source': 'https://brightdata.com/solutions/free-proxies#:~:text=Bright%20Data%20offers%20four%20free,IPs%2C%20concealing%20your%20true%20location.'}]
Sicher, das ist toll, aber es wäre viel besser, wenn es in einem Format vorliegt, das leicht mit anderen Teammitgliedern geteilt werden kann. Exportieren Sie also people_also_ask_questions in eine CSV-Datei!
Importieren Sie das csv -Paket aus der Python-Standardbibliothek:
import csv
Verwenden Sie es, um eine CSV-Ausgabedatei mit Ihren SERP-Daten aufzufüllen:
csv_file = "people_also_ask.csv"
header = ["title", "description", "image", "source"]
with open(csv_file, "w", newline="", encoding="utf-8") as csvfile:
writer = csv.DictWriter(csvfile, fieldnames=header)
writer.writeheader()
writer.writerows(people_also_ask_questions)
Endlich! Ihr „People-Also-Ask“ Scraping-Skript ist bereit.
Schritt 9: Das Ganze zusammenfügen
Ihr endgültiges scraper.py- Skript sollte den folgenden Code enthalten:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.common import NoSuchElementException
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import csv
# to control a Chrome window in headless mode
options = Options()
options.add_argument("--headless") # comment it while developing
# initialize a web driver instance with the
# specified options
driver = webdriver.Chrome(
service=Service(),
options=options
)
# connect to the Google home page
driver.get("https://google.com/")
# deal with the optional Google cookie GDPR dialog
try:
# select the dialog and accept the cookie policy
cookie_dialog = driver.find_element(By.CSS_SELECTOR, "[role='dialog']")
accept_button = cookie_dialog.find_element(By.XPATH, "//button[contains(., 'Accept')]")
if accept_button is not None:
accept_button.click()
except NoSuchElementException:
print("Cookie dialog not present")
# select the search form
search_form = driver.find_element(By.CSS_SELECTOR, "form[action='/search']")
# select the textarea and fill it out
search_textarea = search_form.find_element(By.CSS_SELECTOR, "textarea[aria-label='Search']")
search_query = "Bright Data"
search_textarea.send_keys(search_query)
# submit the form to perform a Google search
search_form.submit()
# wait up to 5 seconds for the "People also ask" section
# to be on the page after page change
people_also_ask_div = WebDriverWait(driver, 5).until(
EC.presence_of_element_located((
By.XPATH, "//div[@jscontroller and @jsname and @jsaction][.//div[@role='heading' and contains(., 'People also ask')]]"
))
)
# where to store the scraped data
people_also_ask_questions = []
# select the question dropdowns and iterate over them
people_also_ask_inner_div = people_also_ask_div.find_element(By.CSS_SELECTOR, "[data-sgrd='true']")
people_also_ask_inner_div_children = people_also_ask_inner_div.find_elements(By.XPATH, "./*")
for child in people_also_ask_inner_div_children:
# if the current element is a question dropdown
if child.get_attribute("jsname") is not None and child.get_attribute("class") == '':
# expand the element
child.click()
# scraping logic
question_title_element = child.find_element(By.CSS_SELECTOR, "[aria-expanded='true'] span")
question_title = question_title_element.text
question_description_element = child.find_element(By.CSS_SELECTOR, "[data-attrid='wa:/description'] span[lang]")
question_description = question_description_element.text
try:
question_image_element = child.find_element(By.CSS_SELECTOR, "img[data-ilt]")
question_image = question_image_element.get_attribute("src")
except NoSuchElementException:
question_image = None
question_source_element = child.find_element(By.XPATH, ".//h3/ancestor::a")
question_source = question_source_element.get_attribute("href")
# populate the array with the scraped data
people_also_ask_question = {
"title": question_title,
"description": question_description,
"image": question_image,
"source": question_source
}
people_also_ask_questions.append(people_also_ask_question)
# export the scraped data to a CSV file
csv_file = "people_also_ask.csv"
header = ["title", "description", "image", "source"]
with open(csv_file, "w", newline="", encoding="utf-8") as csvfile:
writer = csv.DictWriter(csvfile, fieldnames=header)
writer.writeheader()
writer.writerows(people_also_ask_questions)
# close the browser and free up the resources
driver.quit()
In 100 Codezeilen haben Sie soeben einen PAA-Scraper erstellt!
Überprüfen Sie, dass er funktioniert, indem Sie ihn ausführen. Unter Windows starten Sie den Scraper mit:
python scraper.py
Alternativ können Sie ihn auch unter Linux oder macOS ausführen:
python3 scraper.py
Nach der Ausführung des Scrapers wird eine people_also_ask.csv- Datei im Stammverzeichnis Ihres Projekts angezeigt. Beim Öffnen dieser Datei werden Sie Folgendes sehen:
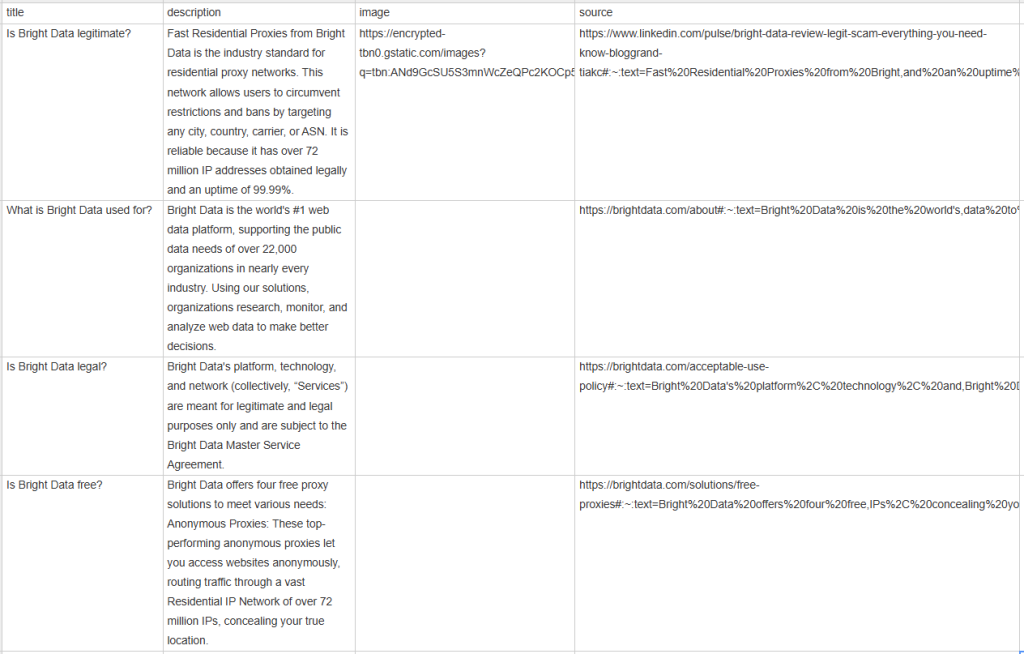
Herzlichen Glückwunsch, Mission erfüllt!
Fazit
In diesem Tutorial haben Sie gelernt, was der Abschnitt „People Also Ask“ auf Google-Seiten ist, welche Daten er enthält und wie Sie ihn mit Python scrapen können. Wie Sie hier lernen konnten, bedarf es nur weniger Zeilen Python-Code, um ein einfaches Skript zu erstellen, das automatisch Daten aus diesem Bereich abruft.
Die hier vorgestellte Lösung eignet sich zwar hervorragend für kleine Projekte, ist aber für umfangreiches Scraping nicht sinnvoll. Das Problem liegt darin, dass Google über eine der fortschrittlichsten Anti-Bot-Technologien der Branche verfügt. Folglich könnte Google Sie mit CAPTCHAs oder IP-Sperren blockieren. Darüber hinaus würde die Skalierung dieses Prozesses auf mehrere Seiten die Infrastrukturkosten erhöhen.
Aber bedeutet dies, dass ein effizientes und zuverlässiges Scraping von Google unmöglich ist? Keineswegs! Dazu benötigt man lediglich eine fortschrittliche Lösung, wie die Google Search API von Bright Data, die diese Herausforderungen bewältigt.
Die Google Search API stellt einen Endpunkt zum Abrufen von Daten aus den Google SERP-Seiten bereit, einschließlich des Abschnitts „People Also Ask“. Mit einem einfachen API-Aufruf lassen sich die gewünschten Daten im JSON- oder HTML-Format abrufen. In der offiziellen Dokumentation erfahren Sie, wie Sie damit loslegen können.
Melden Sie sich jetzt an und starten Sie Ihre kostenlose Testversion!




