

Dieses Tutorial vermittelt Ihnen Folgendes:
- Definition eines Google-Maps-Scrapers
- Welche Daten Sie damit extrahieren können
- Erstellung eines Scraping-Skripts für Google Maps mit Python
Dann legen wir mal los!
Was ist ein Google-Maps-Scraper?
Ein Google-Maps-Scraper ist ein spezialisiertes Instrument zur Extraktion von Daten aus Google Maps. Es dient zur Automatisierung der Erfassung von Kartendaten beispielsweise durch ein Python-Skript zum Scrapen. Die mit einem solchen Scraper abgerufenen Daten werden in der Regel für Marktforschung, Konkurrenzanalysen und ähnliches verwendet.
Daten, die aus Google Maps abgerufen werden können
Folgende Informationen lassen sich aus Google Maps extrahieren:
- Unternehmensname: Der Name des in Google Maps aufgeführten Unternehmens oder Standorts.
- Adresse: Physische Anschrift des Unternehmens bzw. des Standorts.
- Telefonnummer: Rufnummer des Unternehmens.
- Website: URL zur Website des Unternehmens.
- Geschäftszeiten: Öffnungs- und Schließzeiten des Unternehmens.
- Rezensionen: Kundenmeinungen, einschließlich Bewertungen und detailliertes Feedback.
- Bewertungen: Durchschnittliche Sternebewertung anhand von Benutzerfeedback.
- Fotos: Vom Unternehmen bzw. von Kunden hochgeladene Bilder.
Schritt-für-Schritt-Anleitung zum Scrapen von Google Maps mit Python
In dieser Anleitung lernen Sie, wie man ein Python-Skript zum Scrapen von Google Maps erstellt.
Ziel ist das Abrufen der in Google Maps enthaltenen Daten der Seite „Italienische Restaurants“:
Befolgen Sie die nachstehenden Schritte!
Schritt Nr. 1: Projektvorbereitung
Bevor Sie loslegen, vergewissern Sie sich, dass Python 3 auf Ihrem Rechner installiert ist. Sollte dies nicht der Fall sein, laden Sie es herunter, installieren Sie es und folgen Sie dem Installationsassistenten.
Verwenden Sie anschließend folgende Befehle, um einen Ordner für das Projekt anzulegen, diesen zu öffnen und darin eine virtuelle Umgebung zu erstellen:
mkdir google-maps-scraper
cd google-maps-scraper
python -m venv env
Das Verzeichnis google-maps-scraper stellt den Projektordner des Google-Maps-Scrapers in Python dar.
Laden Sie den Projektordner in Ihre bevorzugte Python-IDE. PyCharm Community Edition oder Visual Studio Code mit der Python- Erweiterung reichen völlig aus.
Erstellen Sie innerhalb des Projektordners eine scraper.py- Datei. Die Struktur Ihres Projekts sollte nun wie folgt lauten:
scraper.py ist jetzt ein leeres Python-Skript, das jedoch bald die Scraping-Logik enthalten wird. Führen Sie hierzu unter Linux oder macOS diesen Befehl aus
Aktivieren Sie im Terminal der IDE die virtuelle Umgebung. Führen Sie dazu unter Linux oder macOS den folgenden Befehl aus:
./env/bin/activate
Oder führen Sie unter Windows Folgendes aus:
env/Scripts/activate
Wunderbar, nun haben Sie eine Python-Umgebung für Ihren Scraper!
Schritt Nr. 2: Auswahl der Scraping-Bibliothek
Google Maps ist eine hochgradig interaktive Plattform, und es ist sinnlos, Zeit aufzuwenden, um herauszufinden, ob es sich um eine statische oder dynamische Website handelt. In Fällen wie diesem ist der beste Ansatz zum Scraping die Verwendung eines Browser-Automatisierungstools.
Falls Sie mit dieser Technologie nicht vertraut sind, können Sie mithilfe von Tools zur Browser-Automatisierung Webseiten in einer kontrollierbaren Browserumgebung darstellen und mit diesen interagieren. Zudem ist es nicht gerade einfach, eine gültige URL für die Google-Maps-Suche zu erstellen. Am Einfachsten lässt sich die Suche direkt in einem Browser durchführen.
Eines der besten Browser-Automatisierungstools für Python ist Selenium, das sich hervorragend zum Scraping von Google Maps anbietet. Bereiten Sie sich auf die Installation vor, da diese Bibliothek hauptsächlich für diese Aufgabe verwendet werden wird!
Schritt Nr. 3: Installation und Konfiguration der Scraping-Bibliothek
Installieren Sie Selenium über das selenium -pip-Paket mit diesem Befehl in einer aktiven virtuellen Python-Umgebung:
pip install selenium
Nähere Angaben zur Verwendung dieses Tools finden Sie in unserem Tutorial zu Web-Scraping mit Selenium.
Importieren Sie Selenium in scraper.py und erstellen Sie ein WebDriver- Objekt zur Steuerung einer Chrome-Instanz im Headless-Modus:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
# to launch Chrome in headless mode
options = Options()
options.add_argument("--headless") # comment it while developing
# create a Chrome web driver instance with the
# specified options
driver = webdriver.Chrome(
service=Service(),
options=options
)
Das obige Snippet initialisiert eine Chrome- WebDriver- Instanz zur programmatischen Steuerung eines Chrome-Browserfensters. Mit dem -headless -Flag wird Chrome im Headless-Modus ausgeführt, d. h. das Programm wird im Hintergrund gestartet, ohne dessen Fenster zu laden. Zum Debuggen können Sie diese Zeile kommentieren, um die Aktionen des Skripts in Echtzeit zu beobachten.
Denken Sie in der letzten Zeile Ihres Scraping-Skripts für Google Maps daran, den Web-Treiber zu schließen:
driver.quit()
Fantastisch! Damit sind Sie jetzt vollständig konfiguriert, um Google-Maps-Seiten zu scrapen.
Schritt Nr. 4: Verbindung zur Zielseite
Verwenden Sie die Funktion get() , um eine Verbindung zur Startseite von Google Maps herzustellen:
driver.get("https://www.google.com/maps")
Momentan enthält die Datei scraper.py folgende Zeilen:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
# to launch Chrome in headless mode
options = Options()
options.add_argument("--headless") # comment it while developing
# create a Chrome web driver instance with the
# specified options
driver = webdriver.Chrome(
service=Service(),
options=options
)
# connect to the Google Maps home page
driver.get("https://www.google.com/maps")
# scraping logic...
# close the web browser
driver.quit()
Super! Nun ist es an der Zeit, eine dynamische Website wie Maps zu scrapen!
Schritt Nr.5: Umgang mit dem DSGVO-Cookie-Dialog
Hinweis: Wenn Sie sich nicht in der EU (Europäische Union) befinden, können Sie diesen Schritt auslassen.
Führen Sie das Skript scraper.py im Headed-Modus aus und setzen Sie nach Möglichkeit einen Haltepunkt vor der letzten Zeile. Dadurch bleibt das Browserfenster offen, sodass Sie es überwachen können, ohne dass es sofort geschlossen wird. Wenn Sie sich in der EU befinden, sollten Sie etwa Folgendes sehen:

Hinweis: Die Meldung „Chrome wird von automatisierter Testsoftware gesteuert.“ bestätigt, dass Selenium Chrome erfolgreich steuert.
Google muss EU-Nutzern aufgrund der DSGVO-Anforderungen einige Optionen zur Cookie-Richtlinie anzeigen. Trifft dies auf Sie zu, müssen Sie diese Einstellung übernehmen, um mit der Seite interagieren zu können. Ist dies nicht der Fall, können Sie mit Schritt 6 fortfahren.
Werfen Sie einen Blick auf die URL in der Adressleiste des Browsers und Sie werden feststellen, dass sie nicht mit der in get() angegebenen Seite übereinstimmt. Das liegt daran, dass Google Sie umgeleitet hat. Nachdem Sie auf die Schaltfläche „Alles akzeptieren“ geklickt haben, werden Sie zur Zielseite – der Startseite von Google Maps – zurückgeleitet.
Um die DSGVO-Optionen zu nutzen, öffnen Sie die Google Maps- Startseite im Inkognito-Modus Ihres Browsers und warten Sie auf die Weiterleitung. Klicken Sie mit der rechten Maustaste auf die Schaltfläche „Alle akzeptieren“ und wählen Sie die Option „ Inspizieren“:

Wie Ihnen vielleicht aufgefallen ist, scheinen die CSS-Klassen der HTML-Elemente auf der Webseite nach Zufallsprinzip generiert zu sein. Das bedeutet, sie sind für Web-Scraping unzuverlässig, da sie wahrscheinlich bei jedem Einsatz aktualisiert werden. Sie müssen sich also auf stabilere Attribute wie aria-label ausrichten:
accept_button = driver.find_element(By.CSS_SELECTOR, "[aria-label="Accept all"]")
find_element() ist ein Verfahren in Selenium, das zum Auffinden von HTML-Elementen auf einer Seite mithilfe verschiedener Strategien verwendet wird. In diesem Fall haben wir einen CSS-Selektor. Sollten Sie mehr über die verschiedenen Selektor-Typen erfahren wollen, lesen Sie unseren Artikel XPath vs. CSS-Selektor.
Denken Sie daran, By zu importieren und diesen Import in scraper.py einzufügen:
from selenium.webdriver.common.by import By
Bei der nächsten Anweisung müssen Sie auf die Schaltfläche klicken:
accept_button.click()
Hier sehen Sie, wie sich alles zusammenfügt, um den optionalen Google-Cookie-Seite zu verwalten:
try:
# select the "Accept all" button from the GDPR cookie option page
accept_button = driver.find_element(By.CSS_SELECTOR, "[aria-label="Accept all"]")
# click it
accept_button.click()
except NoSuchElementException:
print("No GDPR requirenments")
Der Befehl click() betätigt die Schaltfläche „Alle akzeptieren“, woraufhin Google Sie auf die Maps-Startseite umleitet. Befinden Sie sich nicht in der EU, wird diese Schaltfläche nicht auf der Seite eingeblendet, wodurch eine NoSuchElementException ausgelöst wird. Das Skript fängt diese Ausnahme ab und setzt den Vorgang fort, da es sich nicht um einen kritischen Fehler handelt, sondern lediglich um ein mögliches Szenario.
Stellen Sie sicher, NoSuchElementException zu importieren:
from selenium.common import NoSuchElementException
Gut gemacht! Sie sind jetzt bereit, Google Maps zu scrapen.
Schritt Nr.6: Absenden des Suchformulars
Inzwischen sollte Ihr Google-Maps-Scraper eine Seite wie die folgende aufrufen:

Bedenken Sie, dass die Position auf den Karten vom Standort Ihrer IP abhängt. In diesem Beispiel befinden wir uns in New York.
Als Nächstes müssen Sie das Feld „Google Maps durchsuchen“ ausfüllen und das Suchformular einreichen. Öffnen Sie die Google-Maps-Startseite im Inkognito-Modus Ihres Browsers, um dieses Element zu lokalisieren. Klicken Sie mit der rechten Maustaste auf das Sucheingabefeld und wählen Sie die Option „Prüfen“:
search_input = WebDriverWait(driver, 5).until(
EC.presence_of_element_located((By.CSS_SELECTOR, "#searchboxinput"))
)
WebDriverWait ist eine besondere Selenium-Klasse, die das Skript pausiert, bis eine bestimmte Bedingung auf der Seite erfüllt ist. Im obigen Beispiel wird bis zu 5 Sekunden gewartet, bis das eingegebene HTML-Element erscheint. Durch dieses Warten wird gewährleistet, dass die Webseite vollständig geladen ist, was für Schritt 5 (aufgrund der Weiterleitung) notwendig ist.
Damit die obigen Zeilen funktionieren können, fügen Sie die folgenden Importe zu scraper.py hinzu:
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
Next, fill out the input with the `[send_keys()](https://www.selenium.dev/documentation/webdriver/actions_api/keyboard/#send-keys)` method:
search_query = "italian restaurants"
search_input.send_keys(search_query)
Die Suchanfrage lautet in diesem Fall „italienische Restaurants“, doch Sie können natürlich auch nach jedem anderen Begriff suchen.
Bleibt nur noch, das Formular abzusenden. Inspizieren Sie mit der Lupe die Schaltfläche „Absenden“:

Wählen Sie sie über das Attribut aria-label aus und klicken Sie darauf:
search_button = driver.find_element(By.CSS_SELECTOR, "button[aria-label="Search"]")
search_button.click()
Hervorragend! Der gesteuerte Browser lädt nun die zu scrappenden Daten.
Schritt Nr. 7: Auswahl der Google-Maps-Elemente
Ihr Skript sollte sich derzeit hier befinden:
Die abzufragenden Daten sind in den Google-Maps-Elementen am linken Rand aufgelistet. Da es sich hierbei um eine Liste handelt, empfiehlt sich ein Array als Datenstruktur für die gescrapten Daten. Initialisieren Sie einen:
items = []
Das Ziel ist die Auswahl der Google-Maps-Elemente am linken Rand. Inspizieren Sie eines davon:

Auch hier scheinen die CSS-Klassen zufällig generiert zu sein, weshalb sie für das Scraping unzuverlässig sind. Stattdessen können Sie das jsaction- Attribut ansteuern. Da Teile des Inhalts dieses Attributs ebenfalls zufällig generiert zu sein scheinen, sollten Sie sich auf die konsistenten Zeichenkette innerhalb dieses Attributs konzentrieren, konkret auf „mouseover:pane“.
Mit dem folgenden XPath-Selektor wählen Sie alle <div>– Elemente innerhalb des übergeordneten <div> , wo role="feed", dessen jsaction- Attribut die Zeichenkette „mouseover:pane“ enthält:
maps_items = WebDriverWait(driver, 10).until(
EC.presence_of_all_elements_located((By.XPATH, '//div[@role="feed"]//div[contains(@jsaction, "mouseover:pane")]'))
)
Auch hier ist WebDriverWait erforderlich, da die Inhalte am linken Rand dynamisch in die Webseite geladen werden.
Iterieren Sie über die einzelnen Elemente und bereiten Sie Ihren Google-Maps-Scraper auf die Extraktion einiger Daten vor:
for maps_item in maps_items:
# scraping logic...
Großartig! Im nächsten Schritt werden Daten aus diesen Elementen extrahiert.
Schritt Nr. 8: Scrapen von Google-Maps-Elementen
Inspizieren Sie ein einzelnes Google-Maps-Element und konzentrieren Sie sich auf die darin enthaltenen Elemente:

Hier können Sie Folgendes scrapen:
- Den Link des Maps-Elements aus dem
a[jsaction][jslog]-Element - Den Titel aus dem
div.fontHeadlineSmall-Element - Die Sterne und Anzahl der Bewertungen aus
span[role="img"]
Dies erreichen Sie mit der folgenden Logik:
link_element = maps_item.find_element(By.CSS_SELECTOR, "a[jsaction][jslog]")
url = link_element.get_attribute("href")
title_element = maps_item.find_element(By.CSS_SELECTOR, "div.fontHeadlineSmall")
title = title_element.text
reviews_element = maps_item.find_element(By.CSS_SELECTOR, "span[role="img"]")
reviews_string = reviews_element.get_attribute("aria-label")
# define a regular expression pattern to extract the stars and reviews count
reviews_string_pattern = r"(d+.d+) stars (d+[,]*d+) Reviews"
# use re.match to find the matching groups
reviews_string_match = re.match(reviews_string_pattern, reviews_string)
reviews_stars = None
reviews_count = None
# if a match is found, extract the data
if reviews_string_match:
# convert stars to float
reviews_stars = float(reviews_string_match.group(1))
# convert reviews count to integer
reviews_count = int(reviews_string_match.group(2).replace(",", ""))
Die Funktion get_attribute() gibt den Inhalt des angegebenen HTML-Attributs zurück,während .text die Zeichenkette innerhalb des Knotens zurückgibt.
Beachten Sie den Einsatz eines regulären Ausdrucks, um die spezifischen Datenfelder aus der Zeichenkette „X.Y Sterne in Z Bewertungen“ zu extrahieren. Erfahren Sie mehr darüber in unserem Artikel zur Verwendung von Regex für Web-Scraping.
Vergessen Sie nicht, das Paket re aus der Python-Standardbibliothek zu importieren:
import re
Fahren Sie mit der Inspektion des Google-Maps-Elements fort:
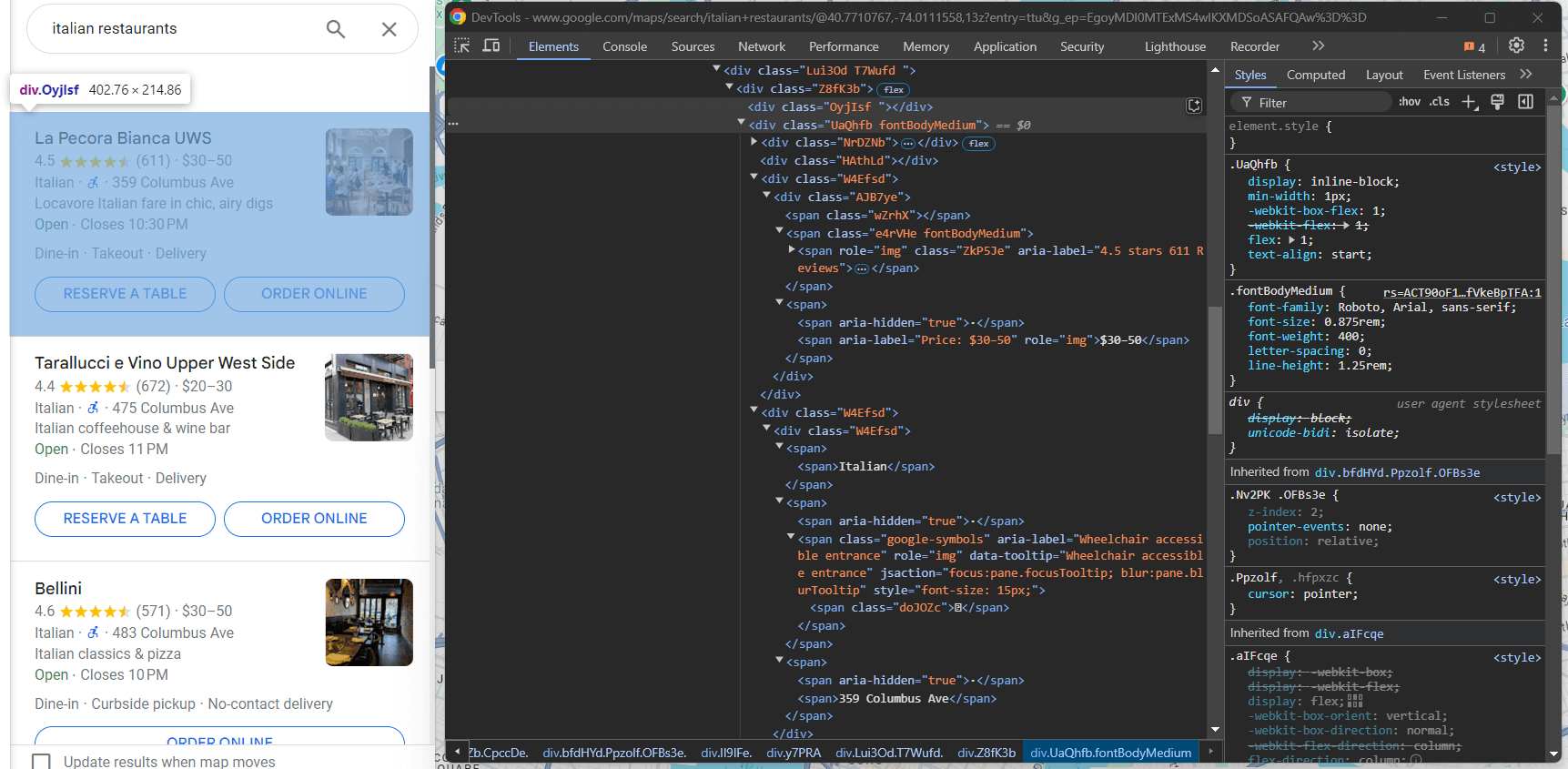
Innerhalb des <div> mit der Klasse fondBodyMedium können Sie die meisten Informationen von <span> Knoten ohneAttribute oder nur mit dem Attribut style erhalten. Das optionale Preis-Element wählen Sie über den Knoten mit dem Attribut aria-label „Preis“ aus:
info_div = maps_item.find_element(By.CSS_SELECTOR, ".fontBodyMedium")
# scrape the price, if present
try:
price_element = info_div.find_element(By.XPATH, ".//*[@aria-label[contains(., 'Price')]]")
price = price_element.text
except NoSuchElementException:
price = None
info = []
# select all <span> elements with no attributes or the @style attribute
# and descendant of a <span>
span_elements = info_div.find_elements(By.XPATH, ".//span[not(@*) or @style][not(descendant::span)]")
for span_element in span_elements:
info.append(span_element.text.replace("⋅", "").strip())
# to remove any duplicate info and empty strings
info = list(filter(None, list(set(info))))
Da das Preiselement optional ist, müssen Sie diese Logik mit atry ... exceptblock verpacken. Somit wird das Skript ohne Fehler fortgesetzt, wenn sich der Preisknoten nicht auf der Seite befindet.ten zu enthalten. Sollten Sie Schritt 5 überspringen, fügen Sie den Import für NoSuchElementException hinzu:
from selenium.common import NoSuchElementException
Zur Vermeidung von leeren Zeichenfolgen und doppelten Info-Elementen achten Sie auf den Einsatz von filter() und set().
Richten Sie Ihre Aufmerksamkeit nun auf das Bild:

Scrappen Sie es mit:
img_element = WebDriverWait(driver, 5).until(
EC.presence_of_element_located((By.CSS_SELECTOR, "img[decoding="async"][aria-hidden="true"]"))
)
image = img_element.get_attribute("src")
Vergessen Sie nicht, dass WebDriverWait benötigt wird, da die Bilder asynchron geladen werden und es daher eine Weile dauern kann, bis sie erscheinen.
Der letzte Schritt besteht im Scraping der Tags im Element am unteren Rand:

Diese können Sie alle über die <span> Knoten mit dem style -Attribut im letzten .fontBodyMedium– Element abrufen:
tags_div = maps_item.find_elements(By.CSS_SELECTOR, ".fontBodyMedium")[-1]
tags = []
tag_elements = tags_div.find_elements(By.CSS_SELECTOR, "span[style]")
for tag_element in tag_elements:
tags.append(tag_element.text)
Fantastisch! Die Python-Logik für das Scraping von Google Maps ist abgeschlossen.
Schritt Nr. 9: Erfassen der gescrapten Daten
Die gescrapten Daten liegen Ihnen nun in mehreren Variablen vor. Erstellen Sie ein neues ítem- Objekt und füllen Sie es mit diesen Daten:
item = {
"url": url,
"image": image,
"title": title,
"reviews": {
"stars": reviews_stars,
"count": reviews_count
},
"price": price,
"info": info,
"tags": tags
}
Fügen Sie es dann an dasArray ítems an:
items.append(item)
Am Ende der for -Schleife für die Google-Maps-Elementknoten enthält ítems alle Ihre Scraping-Daten. Diese Informationen müssen Sie nur noch in eine für Menschen lesbare Datei wie CSV exportieren.
Schritt Nr. 10: Als CSV exportieren
Importieren Sie das csv -Paket aus der Python-Standardbibliothek:
import csv
Als Nächstes verwenden Sie es, um eine flache CSV-Datei mit Ihren Google-Maps-Daten zu füllen:
# output CSV file path
output_file = "items.csv"
# flatten and export to CSV
with open(output_file, mode="w", newline="", encoding="utf-8") as csv_file:
# define the CSV field names
fieldnames = ["url", "image", "title", "reviews_stars", "reviews_count", "price", "info", "tags"]
writer = csv.DictWriter(csv_file, fieldnames=fieldnames)
# write the header
writer.writeheader()
# write each item, flattening info and tags
for item in items:
writer.writerow({
"url": item["url"],
"image": item["image"],
"title": item["title"],
"reviews_stars": item["reviews"]["stars"],
"reviews_count": item["reviews"]["count"],
"price": item["price"],
"info": "; ".join(item["info"]),
"tags": "; ".join(item["tags"])
})
Der obige Codeausschnitt exportiert ítems in eine CSV-Datei mit dem Namen items.csv. Verwendete Schlüsselfunktionen sind:
open(): Öffnet die angegebene Datei im Schreibmodus mit UTF-8-Kodierung, um die Textausgabe zu verarbeiten.csv.DictWriter(): Erzeugt ein CSV-Writer-Objekt unter Verwendung der angegebenen Feldnamen, sodass die Zeilen als Wörterbücher geschrieben werden können.writeheader(): Schreibt die Kopfzeile anhand der Feldnamen in die CSV-Datei.writer.writerow(): Schreibt jedes Element als Zeile in die CSV-Datei.
Berücksichtigen Sie den Einsatz der Zeichenketten-Funktion join() ,um die Anordnungen in flache Zeichenketten umzuwandeln. Auf diese Weise wird die CSV-Ausgabe zu einer sauberen, einstufigen Datei.
Schritt Nr. 11: Das Ganze zusammensetzen
Im Folgenden finden Sie den endgültigen Code für den Google-Maps-Scraper in Python:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.common import NoSuchElementException
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import re
import csv
# to launch Chrome in headless mode
options = Options()
options.add_argument("--headless") # comment it while developing
# create a Chrome web driver instance with the
# specified options
driver = webdriver.Chrome(
service=Service(),
options=options
)
# connect to the Google Maps home page
driver.get("https://www.google.com/maps")
# to deal with the option GDPR options
try:
# select the "Accept all" button from the GDPR cookie option page
accept_button = driver.find_element(By.CSS_SELECTOR, "[aria-label="Accept all"]")
# click it
accept_button.click()
except NoSuchElementException:
print("No GDPR requirenments")
# select the search input and fill it in
search_input = WebDriverWait(driver, 5).until(
EC.presence_of_element_located((By.CSS_SELECTOR, "#searchboxinput"))
)
search_query = "italian restaurants"
search_input.send_keys(search_query)
# submit the search form
search_button = driver.find_element(By.CSS_SELECTOR, "button[aria-label="Search"]")
search_button.click()
# where to store the scraped data
items = []
# select the Google Maps items
maps_items = WebDriverWait(driver, 10).until(
EC.presence_of_all_elements_located((By.XPATH, '//div[@role="feed"]//div[contains(@jsaction, "mouseover:pane")]'))
)
# iterate over the Google Maps items and
# perform the scraping logic
for maps_item in maps_items:
link_element = maps_item.find_element(By.CSS_SELECTOR, "a[jsaction][jslog]")
url = link_element.get_attribute("href")
title_element = maps_item.find_element(By.CSS_SELECTOR, "div.fontHeadlineSmall")
title = title_element.text
reviews_element = maps_item.find_element(By.CSS_SELECTOR, "span[role="img"]")
reviews_string = reviews_element.get_attribute("aria-label")
# define a regular expression pattern to extract the stars and reviews count
reviews_string_pattern = r"(d+.d+) stars (d+[,]*d+) Reviews"
# use re.match to find the matching groups
reviews_string_match = re.match(reviews_string_pattern, reviews_string)
reviews_stars = None
reviews_count = None
# if a match is found, extract the data
if reviews_string_match:
# convert stars to float
reviews_stars = float(reviews_string_match.group(1))
# convert reviews count to integer
reviews_count = int(reviews_string_match.group(2).replace(",", ""))
# select the Google Maps item <div> with most info
# and extract data from it
info_div = maps_item.find_element(By.CSS_SELECTOR, ".fontBodyMedium")
# scrape the price, if present
try:
price_element = info_div.find_element(By.XPATH, ".//*[@aria-label[contains(., 'Price')]]")
price = price_element.text
except NoSuchElementException:
price = None
info = []
# select all <span> elements with no attributes or the @style attribute
# and descendant of a <span>
span_elements = info_div.find_elements(By.XPATH, ".//span[not(@*) or @style][not(descendant::span)]")
for span_element in span_elements:
info.append(span_element.text.replace("⋅", "").strip())
# to remove any duplicate info and empty strings
info = list(filter(None, list(set(info))))
img_element = WebDriverWait(driver, 5).until(
EC.presence_of_element_located((By.CSS_SELECTOR, "img[decoding="async"][aria-hidden="true"]"))
)
image = img_element.get_attribute("src")
# select the tag <div> element and extract data from it
tags_div = maps_item.find_elements(By.CSS_SELECTOR, ".fontBodyMedium")[-1]
tags = []
tag_elements = tags_div.find_elements(By.CSS_SELECTOR, "span[style]")
for tag_element in tag_elements:
tags.append(tag_element.text)
# populate a new item with the scraped data
item = {
"url": url,
"image": image,
"title": title,
"reviews": {
"stars": reviews_stars,
"count": reviews_count
},
"price": price,
"info": info,
"tags": tags
}
# add it to the list of scraped data
items.append(item)
# output CSV file path
output_file = "items.csv"
# flatten and export to CSV
with open(output_file, mode="w", newline="", encoding="utf-8") as csv_file:
# define the CSV field names
fieldnames = ["url", "image", "title", "reviews_stars", "reviews_count", "price", "info", "tags"]
writer = csv.DictWriter(csv_file, fieldnames=fieldnames)
# write the header
writer.writeheader()
# write each item, flattening info and tags
for item in items:
writer.writerow({
"url": item["url"],
"image": item["image"],
"title": item["title"],
"reviews_stars": item["reviews"]["stars"],
"reviews_count": item["reviews"]["count"],
"price": item["price"],
"info": "; ".join(item["info"]),
"tags": "; ".join(item["tags"])
})
# close the web browser
driver.quit()
Sie haben mit etwa 150 Zeilen Code gerade ein Skript zum Scrapen von Google Maps erstellt!
Überprüfen Sie die Funktionsfähigkeit, indem Sie die Datei scraper.py ausführen. Unter Windows führen Sie den Scraper mit folgendem Befehl aus:
python scraper.py
Entsprechend führen Sie ihn unter Linux oder macOS mit folgendem Befehl aus:
python3 scraper.py
Warten Sie die Ausführung des Scrapers ab. Daraufhin wird eine items.csv- Datei im Stammverzeichnis Ihres Projekts angezeigt. Öffnen Sie diese Datei, um die extrahierten Daten einzusehen, und sie sollten etwa wie folgt aussehen:

Herzlichen Glückwunsch, Mission erfüllt!
Fazit
In diesem Tutorial haben Sie gelernt, was ein Google-Maps-Scraper ist und wie man einen solchen in Python erstellt. Wie Sie gerade gesehen haben, bedarf es nur weniger Zeilen Python-Code, um ein einfaches Skript zum automatischen Abrufen von Daten aus Google Maps zu erstellen.
Diese Lösung funktioniert zwar für kleine Projekte, ist aber für umfangreiche Scraping-Projekte nicht geeignet. Google verfügt über fortschrittliche Anti-Bot-Maßnahmen, wie CAPTCHAs und IP-Sperren, mit denen Sie blockiert werden können. Die Skalierung des Prozesses auf mehrere Seiten wäre auch mit höheren Infrastrukturkosten verbunden. Dieses einfache Beispiel berücksichtigt übrigens nicht alle komplexen Interaktionen, die auf Google-Maps-Seiten erforderlich sind.
Bedeutet das etwa, dass es unmöglich ist, Google Maps effizient und zuverlässig zu scrapen? Keineswegs! Sie brauchen einfach eine fortschrittliche Lösung wie die Goolge-Maps-Scraper-API von Bright Data.
Mit der Google-Maps-Scraper-API können Sie über Endpunkte Daten von Google Maps abrufen und dabei alle wichtigsten Hürden vergessen. Mit einfachen API-Aufrufen erhalten Sie die benötigten Daten im JSON- oder HTML-Format. Sollten API-Aufrufe nicht unbedingt Ihre Stärke sein, können Sie auch unsere gebrauchsfertigen Google-Maps-Datensätze erkunden.
Erstellen Sie noch heute ein kostenloses Bright- Data-Konto, um unsere Scraper-APIs zu testen bzw. unsere Datensätze zu erkunden!




