

In diesem Artikel lernen Sie, Finanzdaten manuell zu erfassen und die Finanzdaten-API von Bright Data zur Automatisierung des Prozesses einzusetzen.
Verstehen Sie, welche Daten Sie scrapen möchten und wie sie organisiert sind
Finanzdaten umfassen ein umfangreiches und mitunter komplexes Spektrum an Informationen. Bevor Sie mit dem Scrapen anfangen, sollten Sie genau wissen, welche Art von Daten Sie benötigen.
Vielleicht möchten Sie bspw. Aktienkurse scrapen, die den aktuellen Kurs einer Aktie sowie den Eröffnungs- und Schlusskurs, die Tageshoch- und -tiefstände sowie etwaige Kursänderungen im Verlauf des Tages anzeigen. Finanzielle Details wie Gewinn- und Verlustrechnungen, Bilanzen (mit Angaben zu Aktiva und Passiva) und Cashflow-Rechnungen (mit Angaben zu Geldein- und -ausgängen) sind zur Bewertung der Wertentwicklung eines Unternehmens ebenfalls erforderlich. Finanzkennzahlen, Bewertungen von Analysten und Berichte können bei Kauf- und Verkaufsentscheidungen hilfreich sein, während Aktualisierungen und Stimmungsanalysen in den sozialen Medien weitere Einblicke in Markttrends bieten.
Ein Verständnis dafür, wie die Daten auf einer Website organisiert sind, kann Ihnen das Auffinden und Scrapen der benötigten Informationen erleichtern.
Analyse der rechtlichen und ethischen Aspekte
Bevor Sie eine Website scrapen, sollten Sie unbedingt die Nutzungsbedingungen der betreffenden Website lesen. Viele Websites untersagen das Scraping ohne vorherige Zustimmung oder Genehmigung.
Ferner sind die Regeln in der Datei robots.txt zu beachten, aus der hervorgeht, auf welche Teile der Website Sie zugreifen dürfen. Achten Sie auch darauf, dass Sie den Server nicht mit Anfragen überlasten und planen Sie Verzögerungen zwischen Ihren Anfragen ein. Dadurch können Sie die Ressourcen der Website schützen und Probleme vermeiden.
Verwendung von Browser-Entwickler-Tools
Zur Anzeige der HTML-Elemente einer Website können Sie die Entwickler-Tools Ihres Browsers verwenden. Diese Tools sind Bestandteil der meisten modernen Browser, darunter Chrome, Safari und Edge. Um die Entwickler-Tools aufzurufen, drücken Sie Ctrl + Shift + I unter Windows, Cmd + Option + I auf Mac, oder klicken Sie mit der rechten Maustaste auf die Seite und wählen Sie Inspizieren.
Sobald diese aufgerufen sind, können Sie die HTML-Struktur der Seite inspizieren und bestimmte Datenelemente identifizieren. Auf der Registerkarte „ Elemente “ wird die Baumstruktur des Document Object Model (DOM) angezeigt, über die Sie Elemente auf der Seite lokalisieren und markieren können. Die Registerkarte „ Netzwerk “ zeigt alle Netzwerkanfragen an. Dies ist sinnvoll, um API-Endpunkte oder dynamisch geladene Daten zu finden. Auf der Registerkarte „ Konsole “ können Sie JavaScript-Befehle ausführen und mit den Skripten der Seite interagieren.
In diesem Tutorial werden Sie die APPL-Aktie von Yahoo Finance scrapen. Um die relevanten HTML-Tags zu finden, rufen Sie die Seite der APPL-Aktie auf, klicken mit der rechten Maustaste auf einen auf der Seite angezeigten Kurs und anschließend auf Inspizieren. Die Registerkarte „ Elemente “ hebt das HTML-Element hervor, das den Kurs enthält:

Notieren Sie sich den Tag-Namen und etwaige eindeutige Attribute, wie class oder id, um dieses Element in Ihrem Scraper leichter auffinden zu können.
Einrichtung von Umgebung und Projekt
In diesem Tutorial wird aufgrund seiner Einfachheit und der verfügbaren Bibliotheken [Python]((https://www.python.or) für Web-Scraping verwendet. Bevor Sie anfangen, stellen Sie sicher, dass Sie Python 3.10 oder eine neuere Version auf Ihrem System installiert haben.
Sobald Sie Python installiert haben, öffnen Sie Ihr Terminal bzw. Ihre Shell und führen Sie die folgenden Befehle aus, um ein Verzeichnis und eine virtuelle Umgebung anzulegen:
mkdir scrape-financial-data
cd scrape-financial-data
python3 -m venv myenv
Nach der Einrichtung Ihrer virtuellen Umgebung müssen Sie diese nun noch aktivieren. Die Befehle für die Aktivierung unterscheiden sich je nach Ihrem Betriebssystem.
Bei Windows führen Sie den folgenden Befehl aus:
.myenvScriptsactivate
Unter macOS/Linux führen Sie diesen Befehl aus:
source myenv/bin/activate
Nach Aktivierung der virtuellen Umgebung installieren Sie die erforderlichen Bibliotheken mit pip:
pip3 install requests beautifulsoup4 lxml
Dieser Befehl installiert die Requests-Bibliothek zur Bearbeitung von HTTP-Anfragen, Beautiful Soup zum Parsen von HTML-Inhalten und lxml für effizientes Parsen von XML und HTML.
Manuelles Scrapen von Finanzdaten
Zum manuellen Scrapen von Finanzdaten erstellen Sie eine Datei namens manual_scraping.py und ergänzen den folgenden Code, um die erforderlichen Bibliotheken zu importieren:
import requests
from bs4 import BeautifulSoup
Geben Sie die URL der zu scrappenden Finanzdaten ein. Wie bereits erwähnt, verwendet dieses Tutorial die Yahoo-Finance-Seite für die Apple-Aktie (AAPL):
url = 'https://finance.yahoo.com/quote/AAPL?p=AAPL&.tsrc=fin-srch'
Senden Sie nach Eingabe der URL eine GET-Anfrage an diese URL:
headers = {'User-Agent': 'Mozilla/5.0'}
response = requests.get(url, headers=headers)
Dieser Code enthält einen User-Agent-Header, um eine Browser-Anfrage zu imitieren, sodass sie von der Ziel-Website nicht blockiert wird.
Bestätigen Sie den Erfolg der Anfrage:
if response.status_code == 200:
print('Successfully retrieved the webpage')
else:
print(f'Failed to retrieve the webpage. Status code: {response.status_code}')
exit()
Parsen Sie anschließend den Inhalt der Website mit dem lxml-Parser:
soup = BeautifulSoup(response.content, 'lxml')
Identifizieren Sie die Elemente anhand ihrer eindeutigen Attribute, extrahieren Sie den Textinhalt und drucken Sie die extrahierten Daten:
# Extract specific company details
try:
# Extract specific company details
previous_close = soup.find('fin-streamer', {'data-field': 'regularMarketPreviousClose'}).text.strip()
open_price = soup.find('fin-streamer', {'data-field': 'regularMarketOpen'}).text.strip()
day_range = soup.find('fin-streamer', {'data-field': 'regularMarketDayRange'}).text.strip()
week_52_range = soup.find('fin-streamer', {'data-field': 'fiftyTwoWeekRange'}).text.strip()
market_cap = soup.find('fin-streamer', {'data-field': 'marketCap'}).text.strip()
# Extract PE Ratio (TTM)
pe_label = soup.find('span', class_='label', title='PE Ratio (TTM)')
pe_value = pe_label.find_next_sibling('span').find('fin-streamer').text.strip()
# Extract EPS (TTM)
eps_label = soup.find('span', class_='label', title='EPS (TTM)')
eps_value = eps_label.find_next_sibling('span').find('fin-streamer').text.strip()
# Print the scraped details
print("n### Stock Price ###")
print(f"Open Price: {open_price}")
print(f"Previous Close: {previous_close}")
print(f"Day's Range: {day_range}")
print(f"52 Week Range: {week_52_range}")
print("n### Company Details ###")
print(f"Market Cap: {market_cap}")
print(f"PE Ratio (TTM): {pe_value}")
print(f"EPS (TTM): {eps_value}")
except AttributeError as e:
print("Error while scraping data. Some fields may not be found.")
print(e)
Ausführen und Testen des Codes
Öffnen Sie zum Testen des Codes Ihr Terminal oder Ihre Shell und führen Sie den folgenden Befehl aus:
python3 manual_scraping.py
Ihre Ausgabe sollte wie folgt aussehen:
Successfully retrieved the webpage
### Stock Price ###
Open Price: 225.20
Previous Close: 225.00
Day's Range: 225.18 - 229.74
52 Week Range: 164.08 - 237.49
### Company Details ###
Market Cap: 3.447T
PE Ratio (TTM): 37.50
EPS (TTM): 37.50
Bewältigung von Herausforderungen beim manuellen Scraping
Das manuelle Scraping von Daten kann aus verschiedenen Gründen eine Herausforderung darstellen. Beispielsweise müssen Sie mit CAPTCHAs oder IP-Sperren fertig werden, für deren Umgehung Strategien erforderlich sind. Unstrukturierte oder unordentliche Daten können Analysefehler verursachen, während ein Scraping ohne entsprechende Berechtigungen rechtliche Fragen nach sich ziehen kann. Auch häufige Aktualisierungen der Website können Ihren Scraper beeinträchtigen und erfordern eine regelmäßige Wartung des Codes, um eine kontinuierliche Funktionalität zu gewährleisten.
Für die Erstellung und Automatisierung Ihres Scrapers müssen Sie viel Zeit aufwenden, um den Code zu schreiben und ihn zu korrigieren, anstatt sich auf die Analyse der Daten zu konzentrieren. Wenn Sie sich mit größeren Datenmengen befassen, kann es sogar noch schwieriger sein, da Sie die Reinheit und Ordnung der Daten sicherstellen müssen. Wenn Sie verschiedene Website-Strukturen verwalten, sind auch Kenntnisse verschiedener Web-Technologien erforderlich.
Das bedeutet, wenn Sie regelmäßig und schnell Daten scrapen müssen, ist manuelles Web-Scraping nicht die beste Wahl.
Scrapen von Daten mit der Finanzdaten-Scraper-API von Bright Data
Bright Data löst die Problematik des manuellen Scrapings mit seiner Finanzdaten-Scraper-API, mit der die Datenextraktion automatisiert wird. Die API verfügt über eine integrierte Proxy-Verwaltung mit rotierenden Proxys, um IP-Sperren auszuschließen. Die API liefert strukturierte Daten im JSON- und CSV-Format. Zudem ist sie in hohem Maße skalierbar, sodass große Datenmengen problemlos verarbeitet werden können.
Um die Finanzdaten-Scraper-API zu nutzen, melden Sie sich auf der Bright-Data-Website für ein kostenloses Konto an. Verifizieren Sie Ihre E-Mail-Adresse und führen Sie alle notwendigen Schritte zur Identitätsüberprüfung durch.
Sobald Ihr Konto eingerichtet ist, melden Sie sich an, um auf das Dashboard zuzugreifen und Ihre API-Schlüssel zu erhalten.
Konfiguration der Finanzdaten-Scraper-API
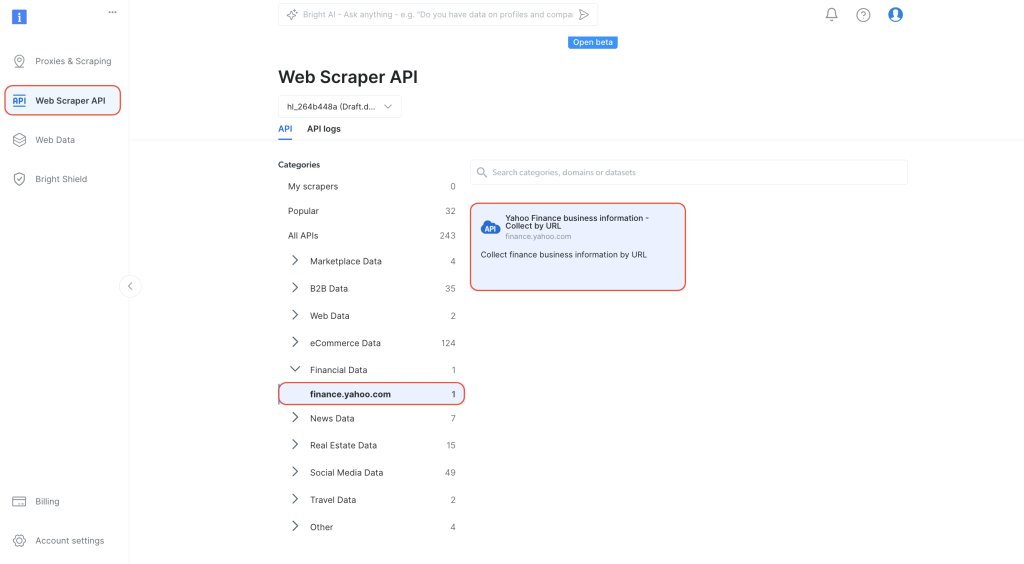
Rufen Sie im Dashboard auf der linken Navigationsregisterkarte die Web-Scraper-API auf. Wählen Sie unter „
Kategorien“ die Option „Finanzdaten“ und öffnen Sie die Seite „Yahoo Finance Business Information – Collect by URL“:
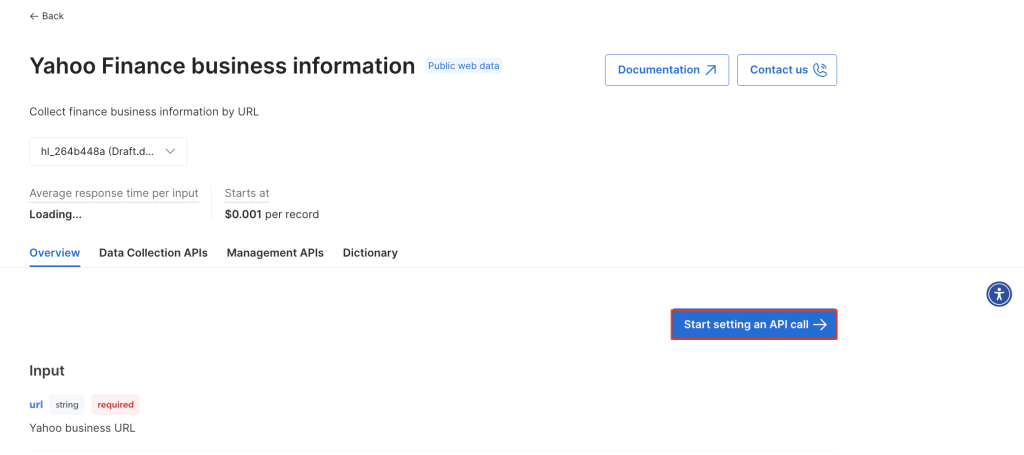
Wählen Sie Einstellung eines API-Aufrufs beginnen:
Um die API nutzen zu können, müssen Sie ein Token erstellen, das Ihre API-Aufrufe an den Bright-Data-Scraper authentifiziert. Um ein neues Token zu erzeugen, klicken Sie auf Token erzeugen:

Ein Dialog wird geöffnet. Legen Sie die Berechtigungen auf „Admin“ und die Dauer auf „Unbegrenzt“ fest:

Sobald Sie diese Informationen gesichert haben, wird das Token erstellt und Sie werden zur Eingabe des neuen Tokens aufgefordert. Bewahren Sie das Token an einem sicheren Ort auf, denn Sie werden es bald erneut benötigen:
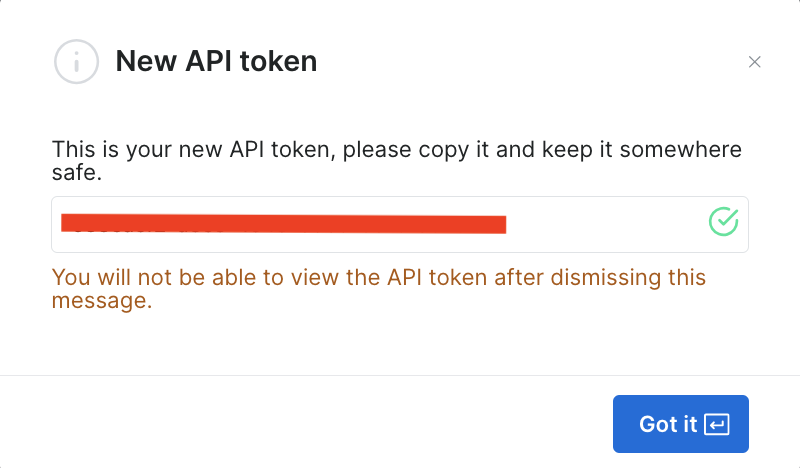
Wenn Sie das Token bereits erzeugt haben, können Sie es in den Benutzereinstellungen unter API-Token abrufen. Wählen Sie die Registerkarte Mehr Ihres Benutzers und klicken Sie dann auf Token kopieren.
Ausführen des Scrapers zum Abrufen von Finanzdaten
Fügen Sie auf der Seite Yahoo Finance Business Information Ihr API-Token unter dem Feld API-Token ein und geben Sie dann die Aktien-URL der gewünschten Website ein, nämlich https://finance.yahoo.com/quote/AAPL/. Kopieren Sie die Anfrage unter dem Abschnitt AUTHENTICATED REQUEST auf der rechten Seite:
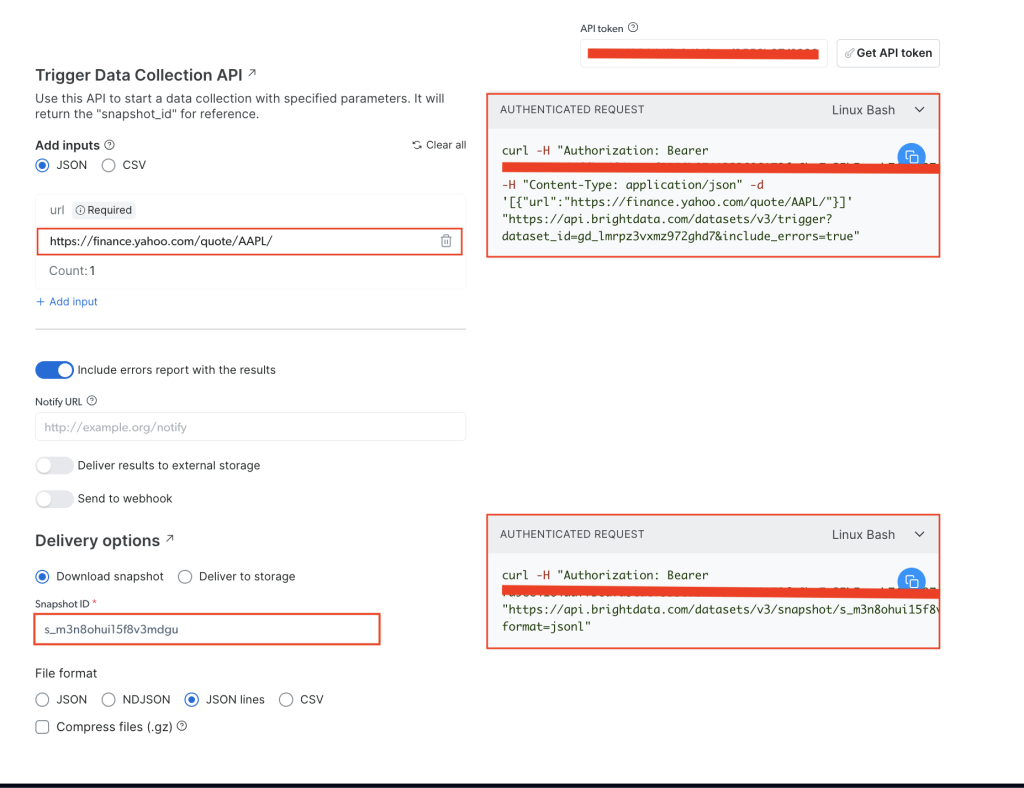
Öffnen Sie Ihr Terminal bzw. Ihre Shell und führen Sie den API-Aufruf curlaus. Dieser sollte wie folgt aussehen:
curl -H "Authorization: Bearer YOUR_TOKEN" -H "Content-Type: application/json" -d '[{"url":"https://finance.yahoo.com/quote/AAPL/"}]' "https://api.brightdata.com/datasets/v3/trigger?dataset_id=YOUR_DATA_SET_ID&include_errors=true"
Nachdem Sie den Befehl ausgeführt haben, erhalten Sie die snapshot_id als Antwort:
{"snapshot_id":"s_m3n8ohui15f8v3mdgu"}
Kopieren Sie die snapshot_id und führen Sie folgenden API-Aufruf von Ihrem Terminal bzw. Ihrer Shell aus:
curl -H "Authorization: Bearer YOUR_TOKEN" "https://api.brightdata.com/datasets/v3/snapshot/YOUR_SNAP_SHOT_ID?format=jsonl"
Achten Sie darauf, dass Sie
YOUR_TOKENundYOUR_SNAP_SHOT_IDdurch Ihre Anmeldedaten ersetzen.
Nach der Ausführung dieses Codes sollten Sie die ausgewerteten Daten als Ausgabe erhalten. Diese Daten sollten der folgenden JSON-Datei ähneln.
Sollten Sie eine Antwort erhalten, dass der Snapshot nicht bereit ist, lassen Sie zehn Sekunden verstreichen und versuchen Sie es erneut.
Die Finanzdaten-Scraper-API von Bright Data hat alle von Ihnen benötigten Daten extrahiert, ohne dass Sie die HTML-Struktur analysieren oder bestimmte Tags lokalisieren mussten. Die API ruft die gesamten Daten der Seite ab, einschließlich zusätzlicher Felder wie earning_estimate, earnings_history und growth_estinates.
Der gesamte Code für dieses Tutorial ist in diesem GitHub-Repo verfügbar.
Vorteile der Verwendung der Bright-Data-API
Mit der Finanzdaten-Scraper-API von Bright Data wird der Scraping-Prozess vereinfacht, da kein Scraping-Code mehr geschrieben bzw. verwaltet werden muss. Ferner hilft die API bei der Einhaltung von Vorschriften, indem sie die Proxy-Rotation verwaltet und die Nutzungsbedingungen von Websites einhält. Auf diese Weise können Sie ohne Bedenken Daten erfassen, ohne gesperrt zu werden oder gegen Vorschriften zu verstoßen.
Bright Datas Finanzdaten-Scraper-API liefert strukturierte, zuverlässige Daten bei minimalem Programmieraufwand. Die API übernimmt die Navigation durch Seiten und das HTML-Parsing für Sie und vereinfacht somit den Prozess. Dank der Skalierbarkeit der API können Sie Daten zu einer Vielzahl von Aktien und anderen Finanzmetriken einholen, ohne große Änderungen an Ihrem Code vornehmen zu müssen. Der Wartungsaufwand ist ebenfalls denkbar gering, denn Bright Data aktualisiert den Scraper, sobald sich die Struktur von Websites ändert, weshalb Ihre Datenerfassung reibungslos und ohne Zusatzaufwand weiterläuft.
Fazit
Die Erfassung von Finanzdaten stellt für Entwickler und Datenteams, die sich mit Finanzanalysen, algorithmischem Trading und Marktforschung beschäftigen, eine äußerst anspruchsvolle Aufgabe dar. In diesem Artikel haben Sie erfahren, wie Sie mit Python und der Finanzdaten-Scraper-API von Bright Data Finanzdaten manuell scrapen können. Obwohl das manuelle Scrapen von Daten mehr Kontrolle bietet, kann es bei der Bewältigung der Anti-Scraping-Maßnahmen und des Wartungsaufwands eine Herausforderung darstellen und lässt sich nur schwer skalieren.
Die Finanzdaten-Scraper-API von Bright Data rationalisiert die Datenerfassung, indem sie komplexe Aufgaben wie die Proxy-Rotation und die Auflösung von CAPTCHAs verwaltet. Zusätzlich zur API bietet Bright Data auch Datensätze, Proxys für Privatanwenderund den Scraping-Browser , um Ihre Web-Scraping-Projekte zu optimieren. Melden Sie sich für eine kostenlose Testversion an und entdecken Sie das gesamte Angebot von Bright Data.






