

Wenn Sie Verkäufer sind oder Marktforschung betreiben, kann Ihnen die Kenntnis der ASIN eines Produkts helfen, schnell exakte Produktübereinstimmungen zu finden, Angebote von Mitbewerbern zu analysieren und auf dem Marktplatz die Nase vorn zu haben. In diesem Artikel zeigen wir Ihnen einfache, effektive Methoden, um Amazon-ASINs in großem Umfang zu scrapen. Außerdem erfahren Sie mehr über die Lösung von Bright Data, mit der Sie diesen Prozess erheblich beschleunigen können.
Was ist eine ASIN bei Amazon?
Eine ASIN ist ein 10-stelliger Code, der aus Buchstaben und Zahlen besteht (z. B. B07PZF3QK9). Amazon weist jedem Produkt in seinem Katalog, von Büchern über Elektronik bis hin zu Kleidung, diesen eindeutigen Code zu.
Es gibt zwei einfache Möglichkeiten, die ASIN eines Produkts zu finden:
1. Schauen Sie sich die Produkt-URL an – die ASIN erscheint direkt nach „/dp/“ in der Adressleiste.
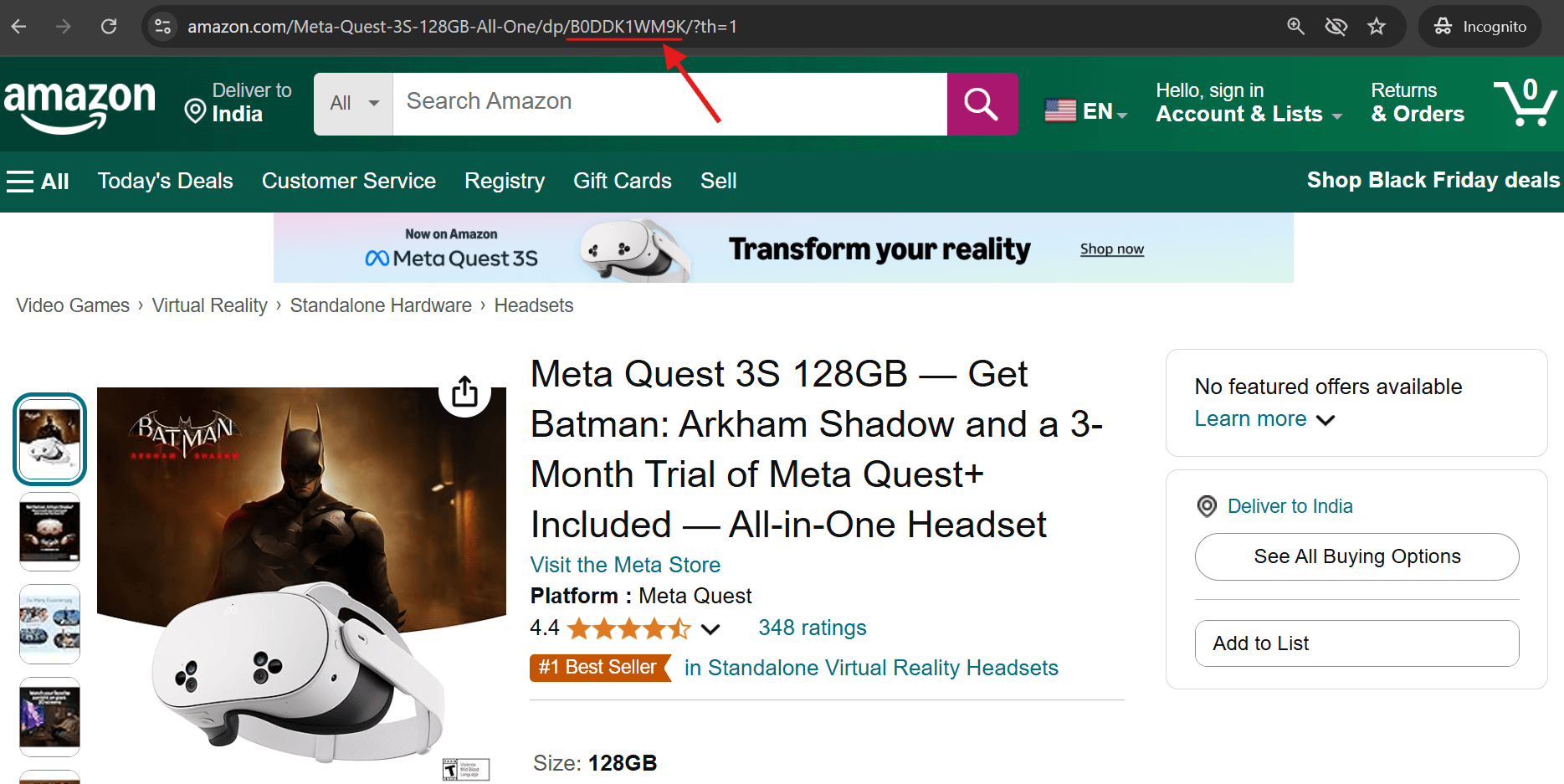
2. Scrollen Sie in einem beliebigen Amazon-Eintrag nach unten zum Abschnitt mit den Produktinformationen – dort finden Sie die ASIN.
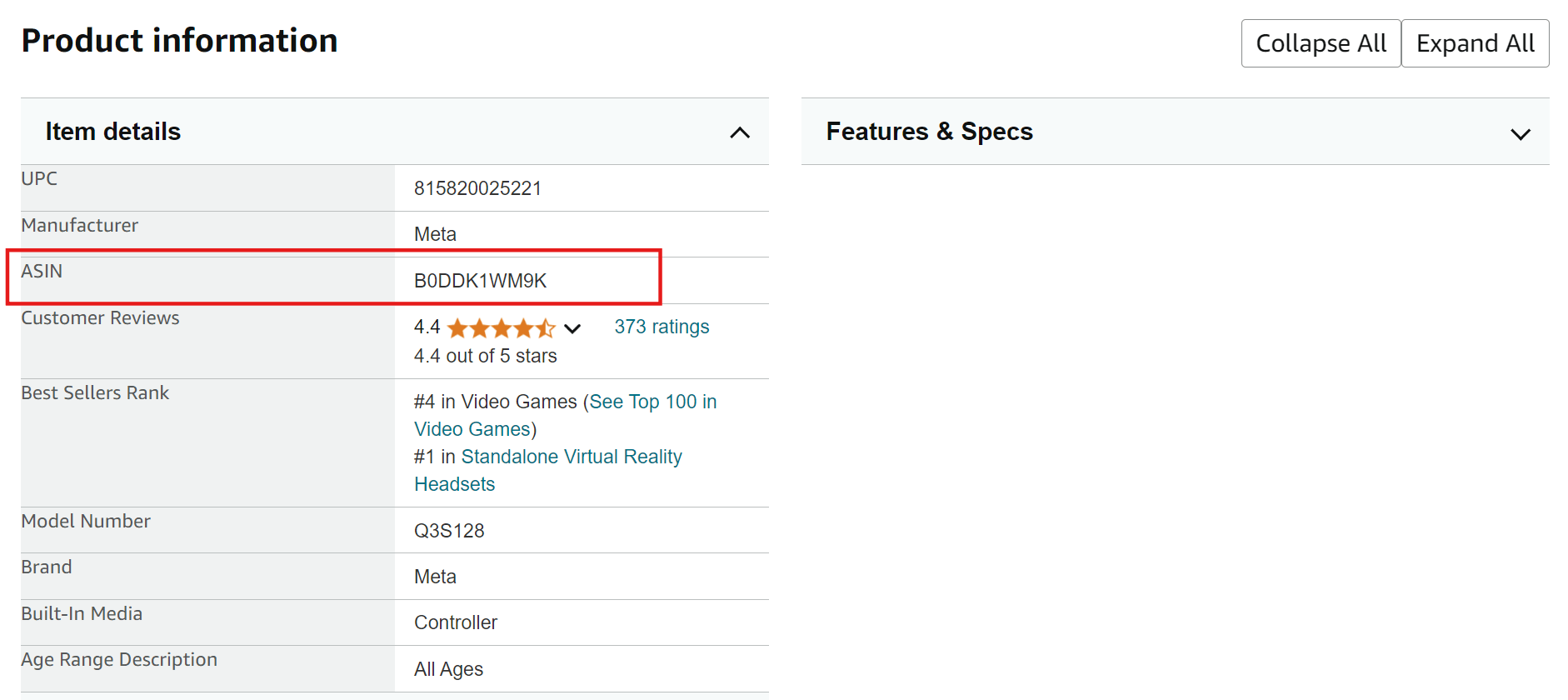
So extrahieren Sie ASINs von Amazon
Das Scraping von Daten aus Amazon mag zunächst einfach erscheinen, ist jedoch aufgrund der robusten Anti-Scraping-Maßnahmen recht schwierig. Amazon schützt sich aktiv durch mehrere ausgeklügelte Methoden vor automatisierter Datenerfassung:
- CAPTCHA-Herausforderungen
- HTTP-503-Fehler, die den Zugriff auf angeforderte Seiten blockieren
- Häufige Änderungen am Layout der Website, die das Parsing unterbrechen
Hier ist ein Screenshot eines typischen HTTP 503-Fehlers, der von Amazon ausgelöst wird:

Sie können dieses einfache Skript ausprobieren, um Amazon-ASINs zu scrapen:
import asyncio import os from curl_cffi import requests from bs4 import BeautifulSoup from tenacity import retry, stop_after_attempt, wait_random class AsinScraper: def __init__(self): self.session = requests.Session() self.asins = set() def create_url(self, keyword: str, page: int) -> str: return f"https://www.amazon.com/s?k={keyword.replace(' ', '+')}&page={page}" @retry(stop=stop_after_attempt(3), wait=wait_random(min=2, max=5)) async def fetch_page(self, url: str) -> str | None: try: print(f"Fetching URL: {url}") response = self.session.get( url, impersonate="chrome120", timeout=30) print(f"HTTP Status Code: {response.status_code}") if response.status_code == 200: # Auf Blockierungsindikatoren in der Antwort prüfen if "Sorry" not in response.text: return response.text else: print("Sorry, request blocked!") else: print(f"Unexpected HTTP status code: {response.status_code}") except Exception as e: print(f"Ausnahme während des Abrufs aufgetreten: {e}") return None def extract_asins(self, html: str) -> set[str]: soup = BeautifulSoup(html, "lxml") containers = soup.find_all( "div", {"data-component-type": "s-search-result"}) new_asins = set() for container in containers: asin = container.get("data-asin") if asin and asin.strip(): new_asins.add(asin) return new_asins def save_to_csv(self, keyword: str): if not self.asins: print("Keine ASINs zum Speichern") return # Erstelle das Verzeichnis „results”, falls es nicht existiert. os.makedirs("results", exist_ok=True) # Erzeuge einen Dateinamen. csv_path = f"results/amazon_asins_{keyword.replace(' ', '_')}.csv" # Als CSV speichern with open(csv_path, 'w') as f: f.write("asinn") for asin in sorted(self.asins): f.write(f"{asin}n") print(f"ASINs gespeichert unter: {csv_path}") async def main(): scraper = AsinScraper() keyword = "laptop" max_pages = 5 for page in range(1, max_pages + 1): print(f"Scraping page {page}...") html = await scraper.fetch_page(scraper.create_url(keyword, page)) if not html: print(f"Failed to fetch page {page}") break new_asins = Scraper.extract_asins(html) if new_asins: Scraper.asins.update(new_asins) print(f"Found {len(new_asins)} ASINs on page { page}. Gesamtzahl der ASINs: {len(scraper.asins)}") else: print("Keine weiteren ASINs gefunden. Scrape wird beendet.") break # Ergebnisse in CSV speichern scraper.save_to_csv(keyword) if __name__ == "__main__": asyncio.run(main())
Was ist also die Lösung für das Scraping von Amazon-ASINs? Der zuverlässigste Ansatz besteht darin, Residential-Proxys von den besten Proxy-Anbietern zusammen mit den richtigen HTTP-Headern zu verwenden.
Verwendung von Bright Data Proxies zum Scrapen von Amazon-ASINs
Bright Data ist ein führender Proxy-Anbieter mit einem globalen Netzwerk von Proxys. Das Unternehmen bietet verschiedene Arten von Proxys auf gemeinsam genutzten und privaten Servern an, die für eine Vielzahl von Anwendungsfällen geeignet sind. Diese Server können den Traffic über die Protokolle HTTP, HTTPS und SOCKS weiterleiten.
Warum Bright Data für das Amazon-Scraping wählen?
- Umfangreiches IP-Netzwerk: Zugriff auf 400M+ monthly IPs in 195 Ländern
- Präzise Geolokalisierung: Zielgerichtete Auswahl bestimmter Städte, Postleitzahlen oder sogar Netzbetreiber
- Mehrere Proxy-Typen: Wählen Sie zwischen Residential-Proxys, Datacenter-Proxys, Mobile-Proxys oder ISP-Proxys.
- Hohe Zuverlässigkeit: 99,9 % Erfolgsquote mit optionaler 100 % Verfügbarkeit
- Flexible Skalierung: Pay-as-you-go -Optionen für Unternehmen jeder Größe verfügbar
Einrichten von Bright Data für Amazon-Scraping
Wenn Sie Bright Data-Proxys für das Amazon ASIN-Scraping verwenden möchten, befolgen Sie diese einfachen Schritte:
Schritt 1: Registrieren Sie sich bei Bright Data
Besuchen Sie die Bright Data-Website und erstellen Sie ein Konto. Wenn Sie bereits ein Konto haben, fahren Sie mit dem nächsten Schritt fort.
Schritt 2: Erstellen Sie eine neue Proxy-Zone
Melden Sie sich an, gehen Sie zum Abschnitt „Proxy & Scraping-Infrastruktur“ und klicken Sie auf „Add“, um eine neue Proxy-Zone zu erstellen. Wählen Sie „Residential-Proxys“, da diese die beste Option sind, um Anti-Scraping-Beschränkungen zu umgehen, da sie echte Geräte-IPs verwenden.
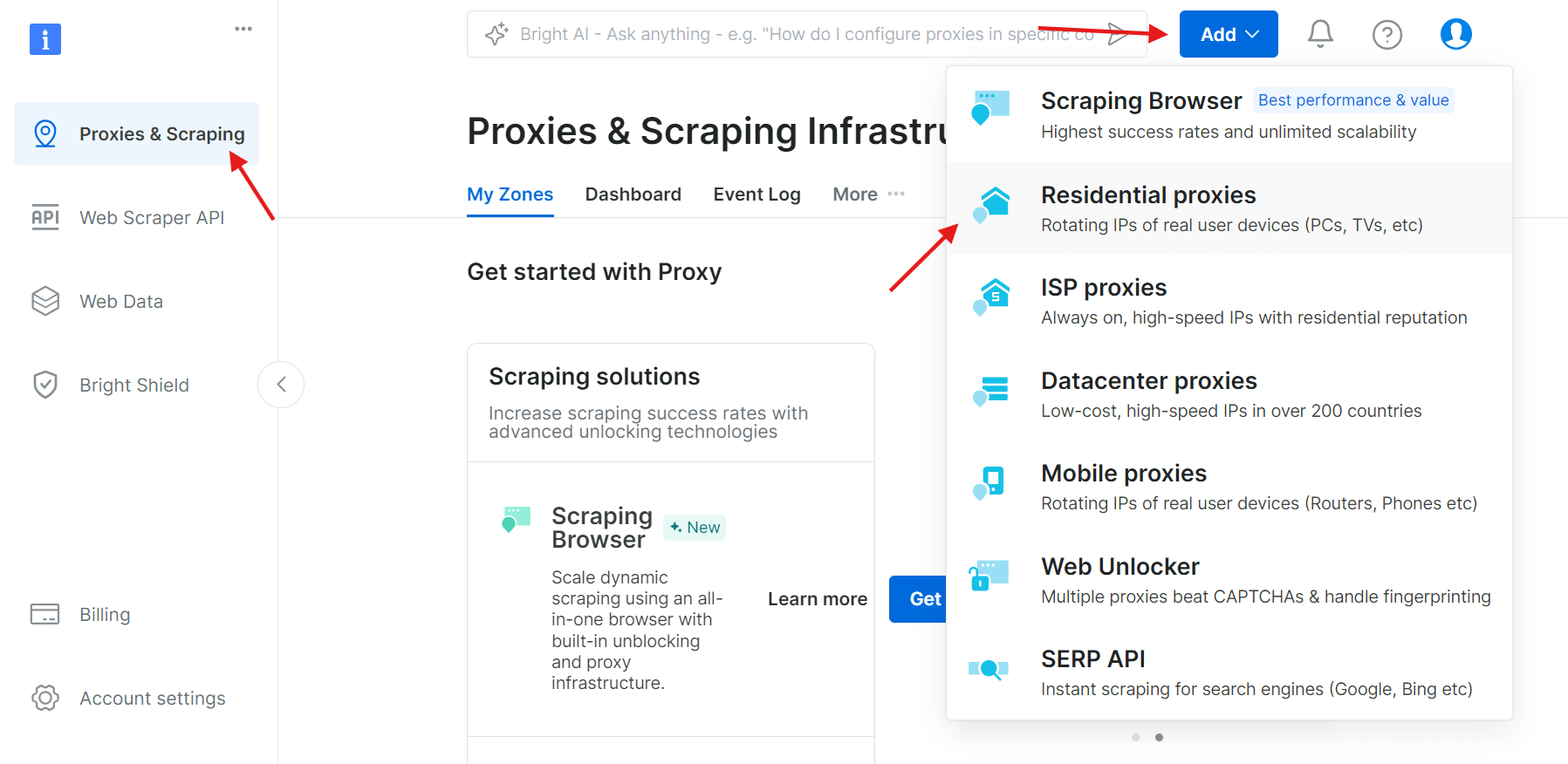
Schritt 3: Konfigurieren Sie die Proxy-Einstellungen
Wählen Sie die Regionen oder Länder für das Browsen aus. Benennen Sie Ihre Zone entsprechend (z. B. „asin_scraping“).
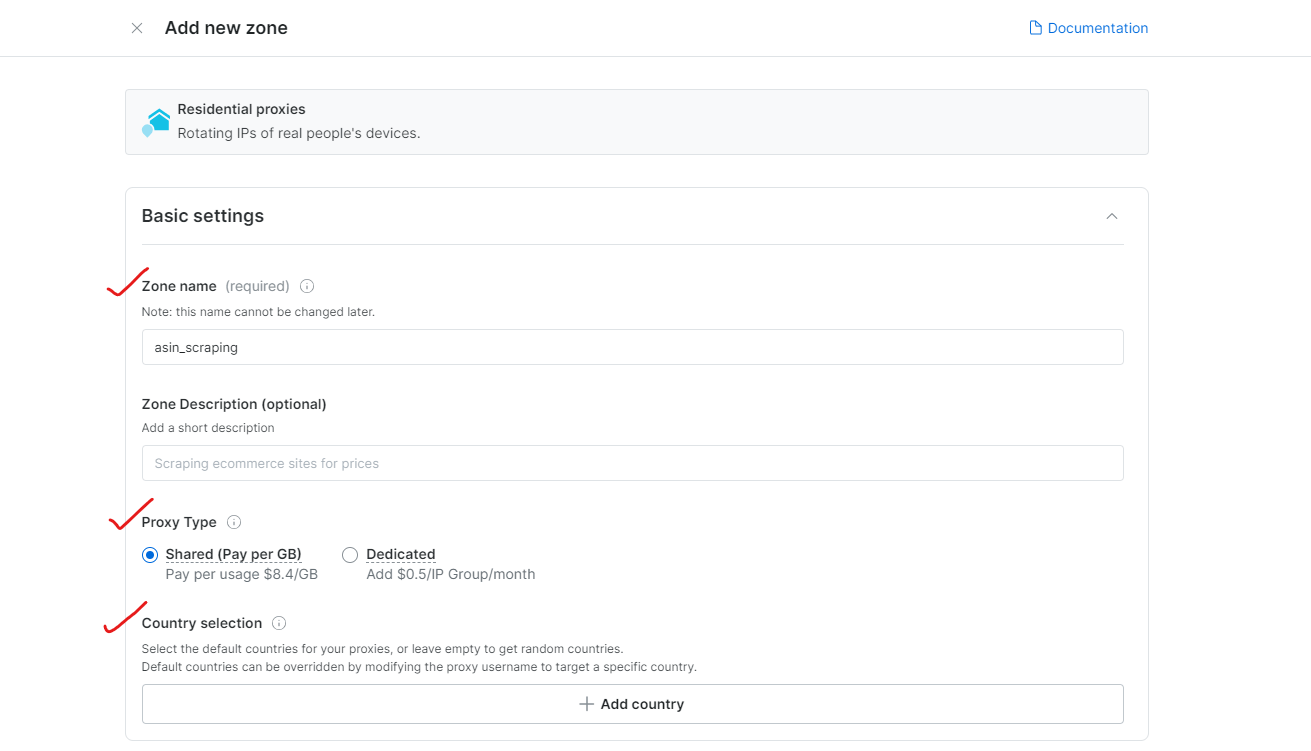
Bright Data ermöglicht eine präzise Geolokalisierung bis hin zur Stadt oder Postleitzahl.
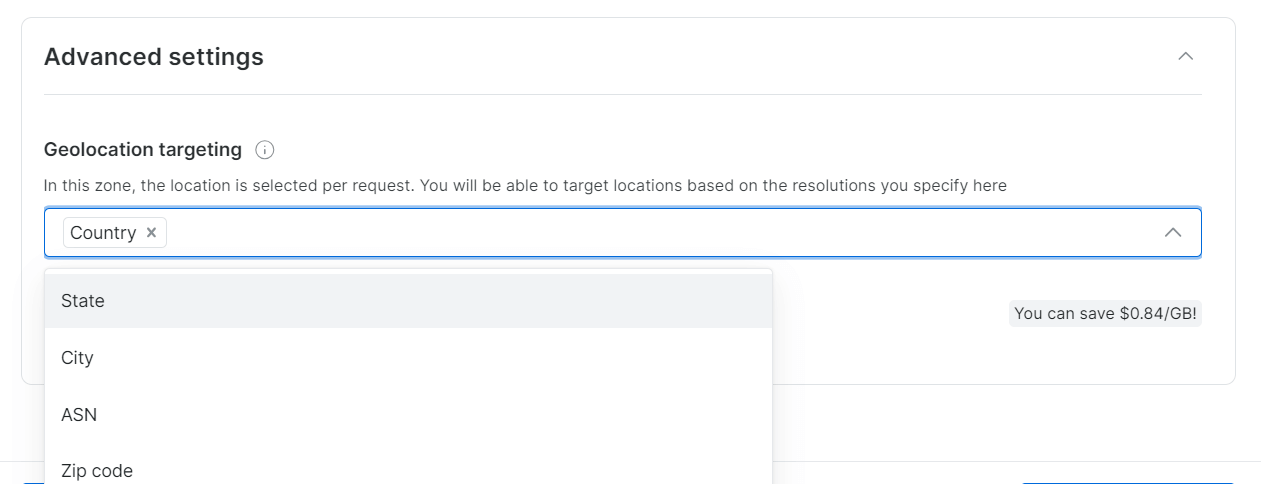
Schritt 4: KYC-Überprüfung abschließen
Um vollen Zugriff auf die Residential-Proxys von Bright Data zu erhalten, schließen Sie die KYC-Überprüfung ab.
Schritt 5: Starten Sie die Nutzung der Proxys
Sobald die Proxy-Zone erstellt ist, werden Ihnen die Anmeldedaten (Host, Port, Benutzername, Passwort) angezeigt, mit denen Sie mit dem Scraping beginnen können.
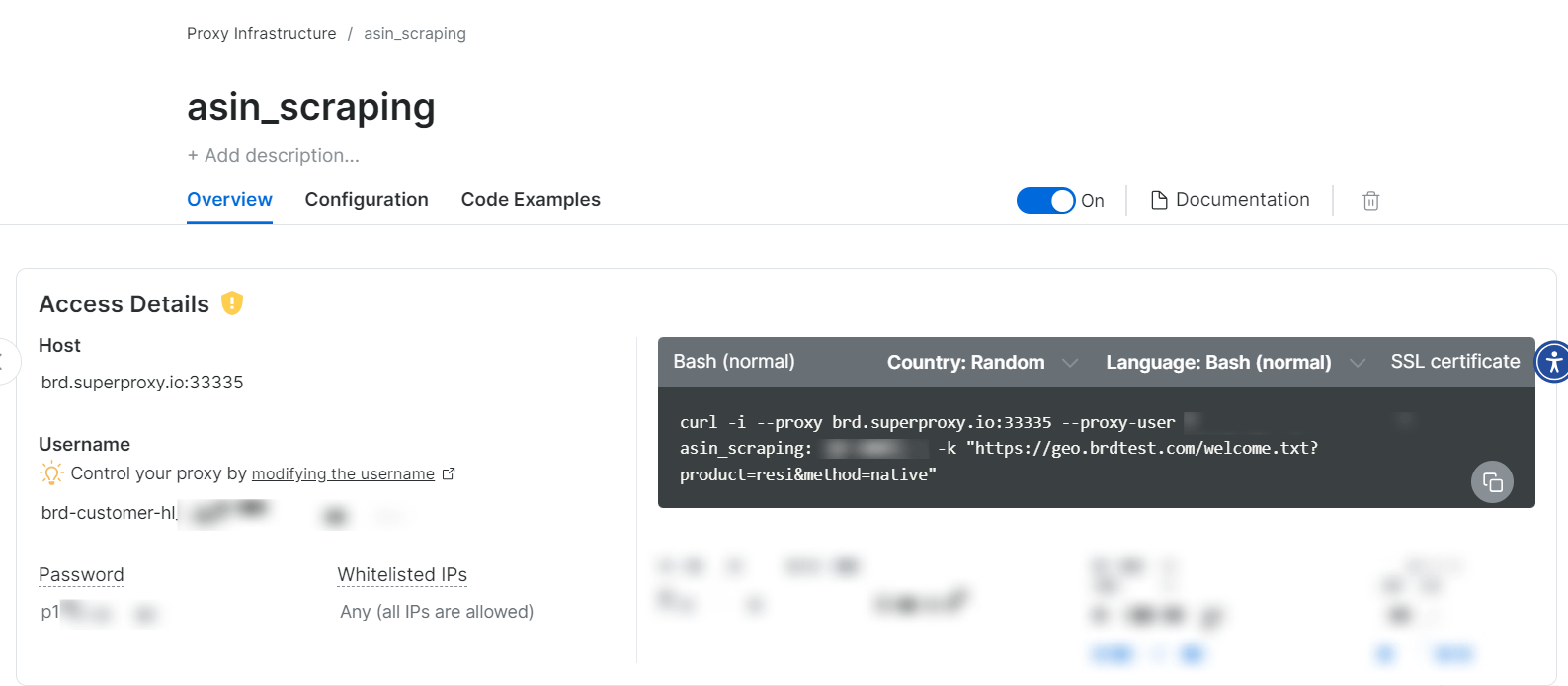
Ja, so einfach ist das!
Implementierung des Scrapers
Schritt 1: Einrichten der Browser-Header
headers = {
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8",
"accept-language": "en-US,en;q=0.9",
"sec-ch-ua": '"Chromium";v="119", "Not?A_Brand";v="24"',
"sec-ch-ua-mobile": "?0",
„sec-ch-ua-platform”: '„Windows”',
„sec-fetch-dest”: „document”,
„sec-fetch-mode”: „navigate”,
„sec-fetch-site”: „none”,
„sec-fetch-user”: „?1”,
„upgrade-insecure-requests”: „1”,
„user-agent”: „Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36”,
}
Schritt 2: Konfigurieren der Proxy-Einstellungen
proxy_config = {
"username": "IHR_BENUTZERNAME",
"password": "IHR_PASSWORT",
"server": "brd.superproxy.io:33335",
}
proxy_url = f"http://{proxy_config['username']}:{proxy_config['password']}@{proxy_config['server']}"
Schritt 3: Anfragen stellen
Stellen Sie eine Anfrage unter Verwendung von Headern und Proxys mit der Bibliothek curl_cffi:
response = session.get(
url,
headers=headers,
impersonate="chrome120",
proxies={"http": proxy_url, "https": proxy_url},
timeout=30,
verify=False,
)
Hinweis: Die Bibliothek curl_cffi eignet sich hervorragend für das Web-Scraping und bietet erweiterte Funktionen zur Browser-Identitätsübernahme, die die Standardbibliothek requests übertreffen.
Schritt 4: Ausführen Ihres Scrapers
Um Ihren Scraper auszuführen, müssen Sie Ihre Ziel-Keywords konfigurieren. Hier ein Beispiel:
keywords = [
"coffee maker",
"office desk",
"cctv camera"
]
max_pages = None # Setzen Sie diesen Wert auf None für alle Seiten
Den vollständigen Code finden Sie hier.
Der Scraper gibt die Ergebnisse in einer CSV-Datei aus, die Folgendes enthält:
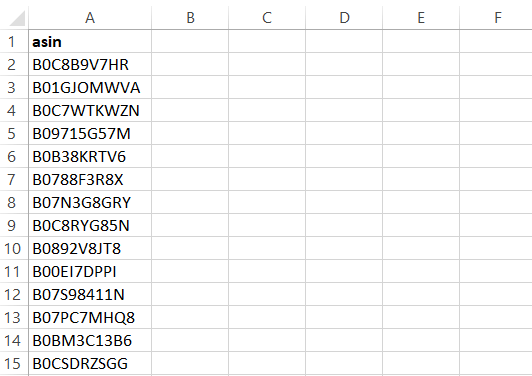
Verwenden der Bright Data Amazon Scraper API zum Extrahieren von ASINs
Proxy-basiertes Scraping funktioniert zwar, aber die Verwendung der Bright Data Amazon Scraper API bietet erhebliche Vorteile:
- Keine Infrastrukturverwaltung: Sie müssen sich keine Gedanken über Proxys, IP-Rotationen oder Captchas machen.
- Geo-Location-Scraping: Scrapen aus jeder geografischen Region
- Einfache Integration: Implementierung in wenigen Minuten mit jeder Programmiersprache
- Mehrere Optionen für die Datenübertragung:
- Exportieren Sie Daten nach Amazon S3, Google Cloud, Azure, Snowflake oder SFTP
- Daten im JSON-, NDJSON-, CSV- oder .gz-Format abrufen
- GDPR- und CCPA-konform: Gewährleistet die Einhaltung der Datenschutzbestimmungen für ethisches Web-Scraping
- 20 kostenlose API-Aufrufe: Testen Sie den Dienst, bevor Sie sich festlegen
- 24/7-Support: Spezieller Support bei allen Fragen oder Problemen im Zusammenhang mit der API
Einrichten der Amazon Scraper API
Die Einrichtung der API ist einfach und kann in wenigen Schritten abgeschlossen werden.
Schritt 1: Zugriff auf die API
Navigieren Sie zur Web Scraper API und suchen Sie unter den verfügbaren APIs nach „amazon products search“:
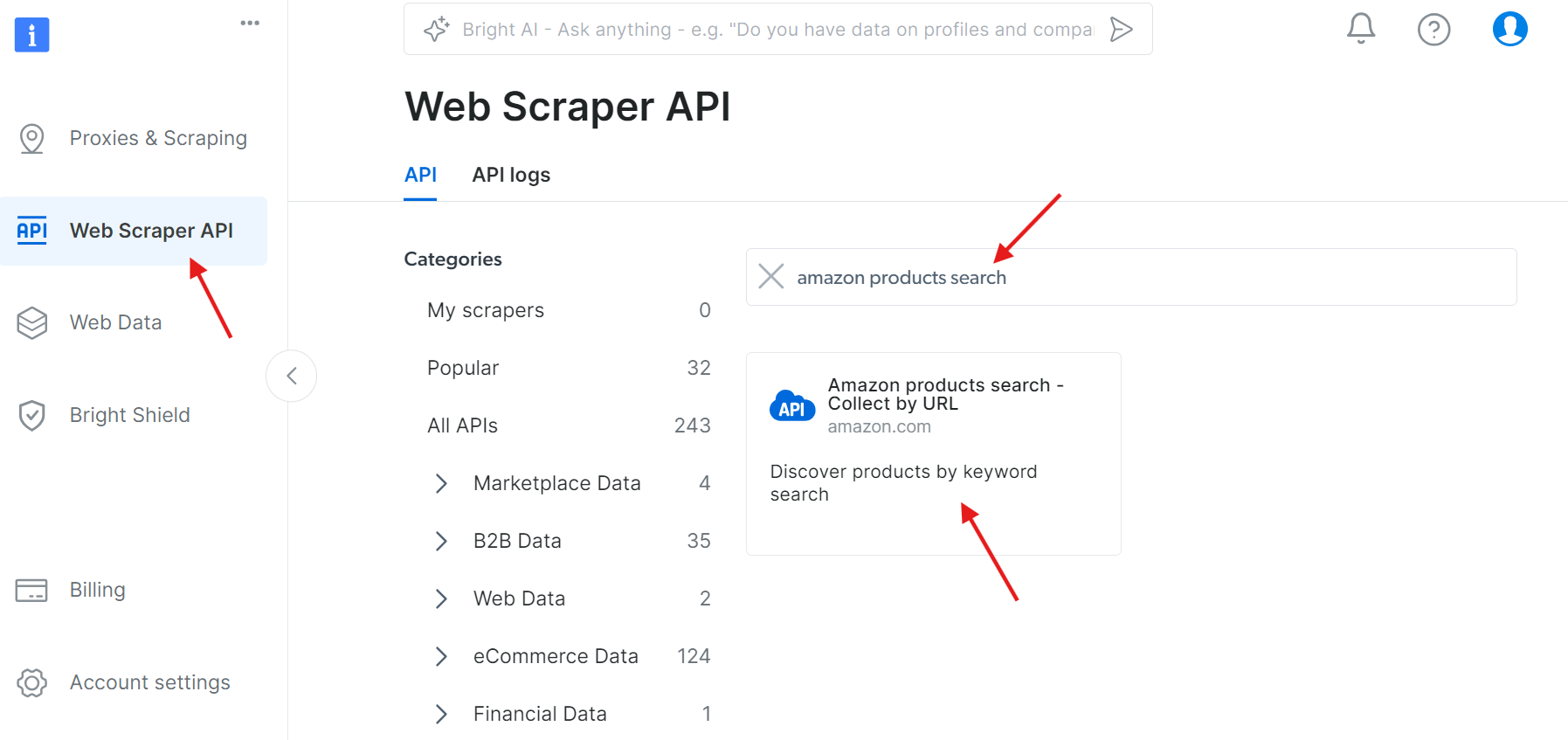
Klicken Sie auf „Start setting an API call” (API-Aufruf einrichten):
Schritt 2: API-Token abrufen
Klicken Sie auf „API-Token abrufen”:
Wählen Sie „Token hinzufügen”:
Speichern Sie Ihren neuen API-Token sicher:
Schritt 3: Konfigurieren Sie die Datenerfassung
Auf der Registerkarte „Datenerfassungs-APIs“:
- Geben Sie Schlüsselwörter für die Produktsuche an
- Legen Sie die gewünschten Amazon-Domains fest
- Legen Sie die Anzahl der zu scrapend Seiten fest
- Zusätzliche Filter (optional)
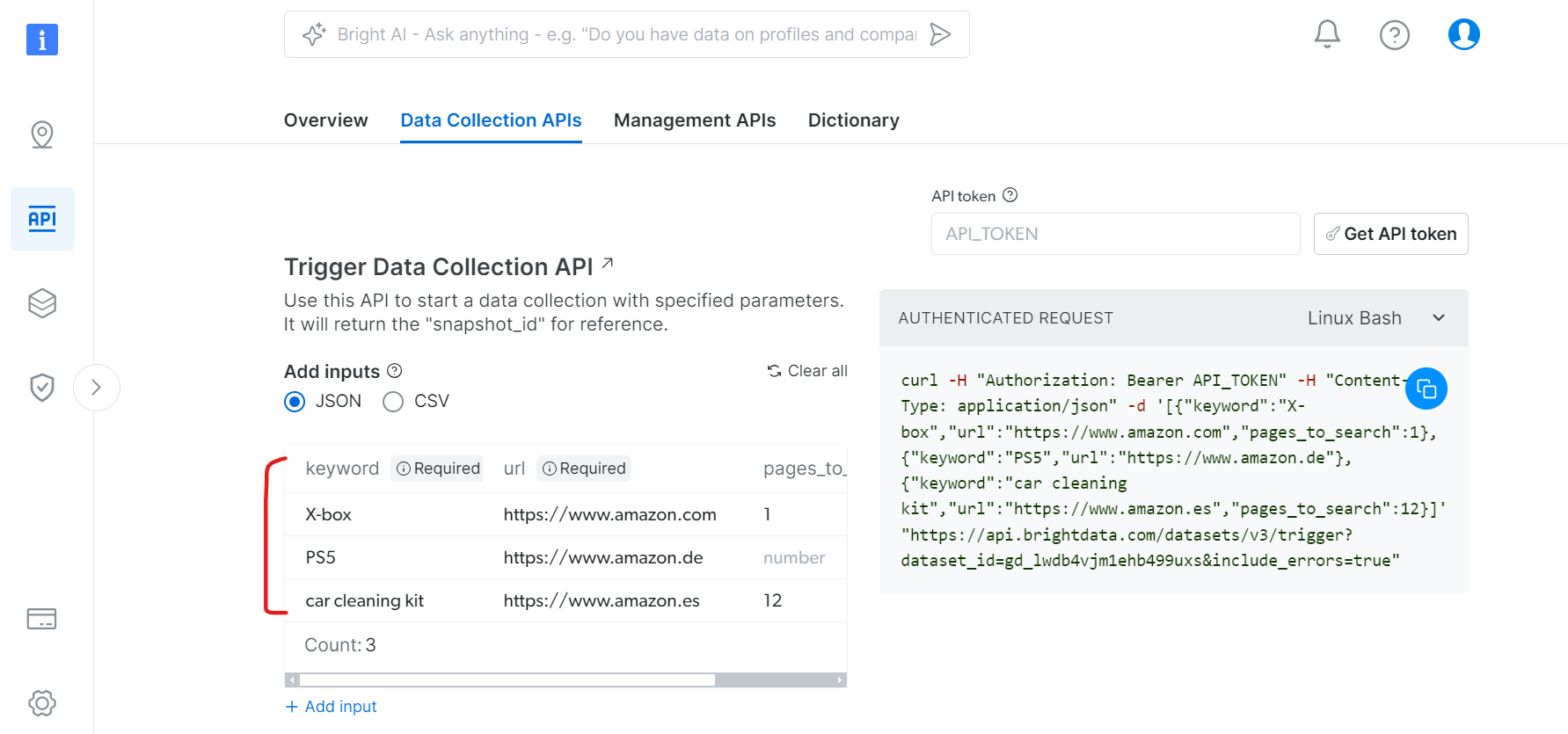
Verwendung der API mit Python
Hier ist ein Beispiel für ein Python-Skript, um die Datenerfassung auszulösen und Ergebnisse abzurufen:
import json
import requests
import time
from typing import Dict, List, Optional, Union, Tuple
from datetime import datetime, timedelta
import logging
from requests.adapters import HTTPAdapter
from urllib3.util.retry import Retry
from enum import Enum
class SnapshotStatus(Enum):
SUCCESS = "success"
PROCESSING = "processing"
FAILED = "failed"
TIMEOUT = "timeout"
class BrightDataAmazonScraper:
def __init__(self, api_token: str, dataset_id: str):
self.api_token = api_token
self.dataset_id = dataset_id
self.base_url = "https://api.brightdata.com/datensätze/v3"
self.headers = {
"Authorization": f"Bearer {api_token}",
"Content-Type": "application/json",
}
# Logging mit benutzerdefiniertem Format einrichten
logging.basicConfig(
level=logging.INFO,
format='%(message)s' # Vereinfachtes Format, um nur Meldungen anzuzeigen
)
self.logger = logging.getLogger(__name__)
# Sitzung mit Wiederholungsstrategie einrichten
self.session = self._create_session()
# Fortschritt verfolgen
self.last_progress_update = 0
def _create_session(self) -> requests.Session:
"""Erstellen einer Sitzung mit Wiederholungsstrategie"""
session = requests.Session()
retry_strategy = Retry(
total=3,
backoff_factor=0.5,
status_forcelist=[500, 502, 503, 504]
)
adapter = HTTPAdapter(max_retries=retry_strategy)
session.mount("https://", adapter)
session.mount("http://", adapter)
return session
def trigger_collection(self, datasets: List[Dict]) -> Optional[str]:
"""Datenerfassung für bestimmte Datensätze auslösen"""
trigger_url = f"{self.base_url}/trigger?dataset_id={self.dataset_id}"
try:
response = self.session.post(
trigger_url,
headers=self.headers,
json=Datensätze
)
response.raise_for_status()
snapshot_id = response.json().get("snapshot_id")
if snapshot_id:
self.logger.info("Initialisierung der Amazon-Datenerfassung...")
return snapshot_id
else:
self.logger.error("Datenerfassung kann nicht initialisiert werden.")
return None
except requests.exceptions.RequestException as e:
self.logger.error(f"Initialisierung der Erfassung fehlgeschlagen: {str(e)}")
return None
def check_snapshot_status(self, snapshot_id: str) -> Tuple[SnapshotStatus, Optional[Dict]]:
"""Aktuellen Status eines Snapshots überprüfen"""
snapshot_url = f"{self.base_url}/snapshot/{snapshot_id}?format=json"
try:
response = self.session.get(snapshot_url, headers=self.headers)
if response.status_code == 200:
return SnapshotStatus.SUCCESS, response.json()
elif response.status_code == 202:
return SnapshotStatus.PROCESSING, None
else:
return SnapshotStatus.FAILED, None
except requests.exceptions.RequestException:
return SnapshotStatus.FAILED, None
def wait_for_snapshot_data(
self,
snapshot_id: str,
timeout: Optional[int] = None,
check_interval: int = 10,
max_interval: int = 300,
callback=None
) -> Optional[Dict]:
"""Warten auf Snapshot-Daten mit minimaler Konsolenausgabe"""
start_time = datetime.now()
current_interval = check_interval
attempts = 0
progress_shown = False
while True:
attempts += 1
if timeout is not None:
elapsed_time = (datetime.now() - start_time).total_seconds()
if elapsed_time >= timeout:
self.logger.error("Data collection exceeded time limit.")
return None
status, data = self.check_snapshot_status(snapshot_id)
if status == SnapshotStatus.SUCCESS:
self.logger.info(
"Amazon-Datenerfassung erfolgreich abgeschlossen!")
return data
elif status == SnapshotStatus.FAILED:
self.logger.error("Bei der Datenerfassung ist ein Fehler aufgetreten.")
return None
elif status == SnapshotStatus.PROCESSING:
# Fortschrittsanzeige nur alle 30 Sekunden anzeigen
current_time = time.time()
if not progress_shown:
self.logger.info("Daten von Amazon werden erfasst...")
progress_shown = True
elif current_time - self.last_progress_update >= 30:
self.logger.info("Datenerfassung läuft...")
self.last_progress_update = current_time
if callback:
callback(attempts, (datetime.now() -
start_time).total_seconds())
time.sleep(current_interval)
current_interval = min(current_interval * 1.5, max_interval)
def store_data(self, data: Dict, filename: str = "amazon_data.json") -> None:
"""Gesammelte Daten in einer JSON-Datei speichern"""
if data:
try:
with open(filename, "w", encoding='utf-8') as file:
json.dump(data, file, indent=4, ensure_ascii=False)
self.logger.info(f"Daten erfolgreich in {filename} gespeichert")
except IOError as e:
self.logger.error(f"Fehler beim Speichern der Daten: {str(e)}")
else:
self.logger.warning("Keine Daten zum Speichern verfügbar.")
def progress_callback(attempts: int, elapsed_time: float):
"""Minimale Callback-Funktion – kann je nach Bedarf angepasst werden"""
pass # Standardmäßig stummgeschaltet
def main():
# Konfiguration
API_TOKEN = "YOUR_API_TOKEN"
DATASET_ID = "gd_lwdb4vjm1ehb499uxs"
# Scraper initialisieren
scraper = BrightDataAmazonScraper(API_TOKEN, DATASET_ID)
# Suchparameter definieren
datensätze = [
{"keyword": "X-box", "url": "https://www.amazon.com", "pages_to_search": 1},
{"keyword": "PS5", "url": "https://www.amazon.de"},
{"keyword": "car cleaning kit",
"url": "https://www.amazon.es", "pages_to_search": 4},
]
# Scraping-Prozess ausführen
snapshot_id = scraper.trigger_collection(Datensätze)
if snapshot_id:
data = scraper.wait_for_snapshot_data(
snapshot_id,
timeout=None,
check_interval=10,
max_interval=300,
callback=progress_callback
)
if data:
Scraper.store_data(data)
print("nScraping-Prozess erfolgreich abgeschlossen!n")
if __name__ == "__main__":
main()
Um diesen Code auszuführen, ersetzen Sie bitte die folgenden Werte:
API_TOKENdurch Ihren tatsächlichen API-Token.- Ändern Sie die Liste
der Datensätzeso, dass sie die Produkte oder Schlüsselwörter enthält, nach denen Sie suchen möchten.
Hier ist ein Beispiel für die JSON-Struktur der abgerufenen Daten:
{
"asin": "B0CJ3XWXP8",
"url": "https://www.amazon.com/Xbox-X-Console-Renewed/dp/B0CJ3XWXP8/ref=sr_1_1",
"name": "Xbox Series X Console (Renewed) Xbox Series X Console (Renewed)Sep 15, 2023",
"sponsored": "false",
"initial_price": 449.99,
"final_price": 449.99,
"currency": "USD",
"sold": 2000,
"rating": 4.1,
„num_ratings”: 1529,
„variations”: null,
„badge”: null,
„business_type”: null,
„brand”: null,
„delivery”: [„KOSTENLOSE Lieferung am Sonntag, 1. Dezember”, „Oder schnellste Lieferung am Freitag, 29. November”],
„keyword“: „X-box“,
„image“: „https://m.media-amazon.com/images/I/51ojzJk77qL._AC_UY218_.jpg“,
„domain“: „https://www.amazon.com/“,
„bought_past_month“: 2000,
„page_number“: 1,
„rank_on_page“: 1,
„timestamp“: „2024-11-26T05:15:24.590Z“,
„input”: {
„keyword”: „X-box”,
„url”: „https://www.amazon.com”,
„pages_to_search”: 1,
},
}
Sie können die vollständige Ausgabe anzeigen, indem Siediese Beispiel-JSON-Datei herunterladen.
Fazit
Wir haben den Prozess des Sammelns von Amazon-ASINs mit Python besprochen, sind dabei jedoch auch auf einige Herausforderungen gestoßen. Probleme wie CAPTCHAs und Ratenbeschränkungen können unsere Bemühungen zur Datenerfassung erheblich behindern. Als Lösung können wir Tools wie die Proxys von Bright Data oder die Amazon Scraper API verwenden. Diese Optionen können dazu beitragen, den Prozess zu beschleunigen und häufige Hindernisse zu umgehen. Wenn Sie sich die Mühe der Einrichtung Ihrer Scraping-Tools ganz ersparen möchten, bietet Bright Data auch fertige Amazon-Datensätze an, die Sie sofort verwenden können.
Melden Sie sich jetzt an und starten Sie das Gratis-Testen!





