

- API-basierter Scraper
Verwenden Sie unsere Schnittstelle, um Ihre API-Anfrage zu erstellen - Automatisierung in großem Maßstab
Erstellen Sie Ihren eigenen Scheduler, um die Häufigkeit zu steuern - Lieferung
Liefern Sie die Daten an Ihren bevorzugten Speicherort oder laden Sie sie herunter



Social Media Scraper
Scrapen Sie Social-Media-Plattformen wie Facebook, Twitter, Instagram, TikTok, YouTube und mehr. Behalten Sie die volle Kontrolle, Flexibilität und Skalierung, ohne sich um Infrastruktur, Proxy-Server oder Blockierungen sorgen zu müssen.
Keine Kreditkarte erforderlich

90 Scraper
- Scrape auf Abruf via API oder No-Code Scraper
- Dedizierter Account Manager
- Massenanfragenbearbeitung, bis zu 5K URLs
- Ergebnisse in mehreren Formaten abrufen
Weltweit vertrauen 20,000+ Kunden auf uns.
Social Media-Daten mühelos scrapen

Vollständig verwaltete Option
Genießen Sie problemlose Daten mit unseren Managed Services.
Web Scrapers
Social Media Scrapers
Entfällt die Notwendigkeit, die Infrastruktur zu entwickeln und zu pflegen. Extrahieren Sie einfach große Mengen an Web-Daten und gewährleisten Sie Skalierbarkeit und Zuverlässigkeit mithilfe von Web-Scraper-APIs oder No-Code-Scrapern.
Instagram - Profiles
Account, Fbid, ID, Followers, Posts count, Is business account, Is professional account, Is verified, and more.
 20.9K+
20.9K+ 3.3K+
3.3K+Instagram - Profiles - Collect profile information by user name
Account, Fbid, ID, Followers, Posts count, Is business account, Is professional account, Is verified, and more.
Instagram - Posts
URL, User posted, Description, Hashtags, Num comments, Date posted, Likes, Photos, and more.
Instagram - Posts - Collects posts from a specific URLs by using profile URL
URL, User posted, Description, Hashtags, Num comments, Date posted, Likes, Photos, and more.
LinkedIn posts
URL, ID, User id, Use url, Title, Headline, Post text, Date posted, and more.
LinkedIn posts - Discover user's articles by URL
URL, ID, User id, Use url, Title, Headline, Post text, Date posted, and more.
LinkedIn posts - Discover posts by Profile URL
URL, ID, User id, Use url, Title, Headline, Post text, Date posted, and more.
LinkedIn posts - Discover new posts company URL
URL, ID, User id, Use url, Title, Headline, Post text, Date posted, and more.
X (formerly Twitter) - Posts
ID, User posted, Name, Description, Date posted, Photos, URL, Quoted post, and more.
X (formerly Twitter) - Posts - Collecting Twitter posts URLs
ID, User posted, Name, Description, Date posted, Photos, URL, Quoted post, and more.
X (formerly Twitter) - Posts - Getting x posts by array of profiles
ID, User posted, Name, Description, Date posted, Photos, URL, Quoted post, and more.
TikTok - Profiles
Account id, Nickname, Biography, Awg engagement rate, Comment engagement rate, Like engagement rate, Bio link, Predicted lang, and more.
TikTok - Profiles - Discover by search URL and country
Account id, Nickname, Biography, Awg engagement rate, Comment engagement rate, Like engagement rate, Bio link, Predicted lang, and more.
Youtube - Videos posts
URL, Title, Youtuber, Youtuber md5, Video url, Video length, Likes, Views, and more.
Youtube - Videos posts - Search new youtube videos by keyword
URL, Title, Youtuber, Youtuber md5, Video url, Video length, Likes, Views, and more.
Youtube - Videos posts - Discover videos by channel URL
URL, Title, Youtuber, Youtuber md5, Video url, Video length, Likes, Views, and more.
Youtube - Videos posts - Search videos by keyword and then apply relevant video filters
URL, Title, Youtuber, Youtuber md5, Video url, Video length, Likes, Views, and more.
Youtube - Videos posts - Collect YouTube posts by hashtags
URL, Title, Youtuber, Youtuber md5, Video url, Video length, Likes, Views, and more.
Youtube - Videos posts - Discovery records by Explore page URL
URL, Title, Youtuber, Youtuber md5, Video url, Video length, Likes, Views, and more.
Youtube - Videos posts - Discovery videos by podcast url
URL, Title, Youtuber, Youtuber md5, Video url, Video length, Likes, Views, and more.
Facebook - Pages Posts by Profile URL
URL, Post id, User url, User username raw, Content, Date posted, Hashtags, Num comments, and more.
TikTok - Posts
URL, Post id, Description, Create time, Digg count, Share count, Collect count, Comment count, and more.
TikTok - Posts - Input specific profile URL to get posts published by it
URL, Post id, Description, Create time, Digg count, Share count, Collect count, Comment count, and more.
TikTok - Posts - Search posts by specific keyword or hashtag
URL, Post id, Description, Create time, Digg count, Share count, Collect count, Comment count, and more.
TikTok - Posts - discover new records by TikTok discover URL
URL, Post id, Description, Create time, Digg count, Share count, Collect count, Comment count, and more.
YouTube - Channels
URL, Handle, Handle md5, Banner img, Profile image, Name, Subscribers, Description, and more.
YouTube - Channels - Collects channel by keyword related to the channel or video's of the channel
URL, Handle, Handle md5, Banner img, Profile image, Name, Subscribers, Description, and more.
Reddit- Posts
Post id, URL, User posted, Title, Description, Num comments, Date posted, Community name, and more.
Reddit- Posts - Discover Reddit posts by Subreddit URL
Post id, URL, User posted, Title, Description, Num comments, Date posted, Community name, and more.
Reddit- Posts - Discovery by keyword of Reddit posts
Post id, URL, User posted, Title, Description, Num comments, Date posted, Community name, and more.
Reddit- Posts - Discover posts by author
Post id, URL, User posted, Title, Description, Num comments, Date posted, Community name, and more.
Instagram - Reels
URL, User posted, Description, Hashtags, Num comments, Date posted, Likes, Views, and more.
Instagram - Reels - Discover reels video from Instagram profile or direct search url
URL, User posted, Description, Hashtags, Num comments, Date posted, Likes, Views, and more.
Instagram - Reels - Collect all Reels from Instagram profiles (without the post timestamp)
URL, User posted, Description, Hashtags, Num comments, Date posted, Likes, Views, and more.
X (formerly Twitter) - Profiles
X id, URL, ID, Profile name, Biography, Is verified, Profile image link, External link, and more.
X (formerly Twitter) - Profiles - Collect profile information by user name
X id, URL, ID, Profile name, Biography, Is verified, Profile image link, External link, and more.
Instagram - Comments
URL, Comment user, Comment user url, Comment date, Comment, Likes number, Replies number, Replies, and more.
Facebook - Comments
URL, Post id, Post url, Comment id, User name, User id, User url, Date created, and more.
Facebook - Posts by group URL
URL, Post id, User url, User username raw, Content, Date posted, Hashtags, Num comments, and more.
Facebook Marketplace
URL, Title, Initial price, Final price, Currency, Product id, Breadcrumbs, Condition, and more.
Facebook Marketplace - Collect Facebook marketplace listings by keyword
URL, Title, Initial price, Final price, Currency, Product id, Breadcrumbs, Condition, and more.
Facebook Marketplace - discover by url
URL, Title, Initial price, Final price, Currency, Product id, Breadcrumbs, Condition, and more.
Facebook - Posts by post URL
URL, Post id, User url, User username raw, Content, Date posted, Hashtags, Num comments, and more.
TikTok - Comments
URL, Post url, Post id, Post date created, Date created, Comment text, Num likes, Num replies, and more.
Reddit - Comments
URL, Comment id, User posted, Comment, Date posted, Post url, Post id, Community name, and more.
Facebook - Profiles
URL, Name, ID, Profile photo, Cover photo, Work, College, High school, and more.
Youtube - Comments
Comment id, Comment text, Likes, Replies, Username, Username md5, User channel, Date, and more.
Facebook - Pages and Profiles
ID, URL, Page name, Username, Entity type, Summary text, Primary category, Work, and more.
Pinterest - Posts
URL, Post id, Title, Content, Date posted, User name, User url, User id, and more.
Pinterest - Posts - Collects posts by specific keywords
URL, Post id, Title, Content, Date posted, User name, User url, User id, and more.
Pinterest - Posts - Discover posts by using specific profile url
URL, Post id, Title, Content, Date posted, User name, User url, User id, and more.
Facebook Events
Event id, URL, Main image, Event date, Title, People responded, Event by, Location, and more.
Facebook Events - discover Facebook events search URL
Event id, URL, Main image, Event date, Title, People responded, Event by, Location, and more.
Facebook Events - Discover events by venue URL
Event id, URL, Main image, Event date, Title, People responded, Event by, Location, and more.
Facebook - Reels by profile URL
URL, Post id, User url, User username raw, Content, Date posted, Hashtags, Num comments, and more.
Facebook Company Reviews
Company name, Company id, Company url, URL, Review time, Recommends, Review content, Review attachments, and more.
Quora posts
URL, Post id, Author name, Title, Post date, Originally answered, Over all answers, Post text, and more.
Quora posts - Search url of a question on Quora to discover answers given
URL, Post id, Author name, Title, Post date, Originally answered, Over all answers, Post text, and more.
Pinterest - Profiles
URL, Profile picture, Name, Nickname, Website, Bio, Following count, Follower count, and more.
Pinterest - Profiles - Discover profiles by Keyword in profile name and profile posts
URL, Profile picture, Name, Nickname, Website, Bio, Following count, Follower count, and more.
Vimeo - Videos posts
Video id, Title, URL, Uploader, Video url, Video length, Views, Likes, and more.
Vimeo - Videos posts - focus on licensed videos with "common creative" license
Video id, Title, URL, Uploader, Video url, Video length, Views, Likes, and more.
Vimeo - Videos posts - scrape videos by URL
Video id, Title, URL, Uploader, Video url, Video length, Views, Likes, and more.
Bluesky - Posts
URL, Post id, Post date, Posted by, Post text, Comments, Reposts, Likes, and more.
Bluesky - Posts - Collect posts from profile URL
URL, Post id, Post date, Posted by, Post text, Comments, Reposts, Likes, and more.
Snapchat posts
URL, Post id, Profile name, Profile handle, Profile link, Num comments, Num shares, Num views, and more.
Snapchat posts - Discover posts by profile url
URL, Post id, Profile name, Profile handle, Profile link, Num comments, Num shares, Num views, and more.
Snapchat posts - Discover new posts by search url
URL, Post id, Profile name, Profile handle, Profile link, Num comments, Num shares, Num views, and more.
Threads - Profiles
URL, Profile name, Profile id, About formatted, Number of followers, Website, Instagram profile url, Threads, and more.
Twitch - streams dataset
URL, Stream id, Streamer name, Verified partner, Stream title, Tags, Viewers number, Stream time, and more.
Twitch - streams dataset - Discover stream by a search term
URL, Stream id, Streamer name, Verified partner, Stream title, Tags, Viewers number, Stream time, and more.
Twitch - streams dataset - Discover stream by category url
URL, Stream id, Streamer name, Verified partner, Stream title, Tags, Viewers number, Stream time, and more.
Threads - Posts
Post id, URL, Post time, Profile name, Profile url, Post content, Number of likes, Number of comments, and more.
Threads - Posts - Discover posts by profile URL
Post id, URL, Post time, Profile name, Profile url, Post content, Number of likes, Number of comments, and more.
Snapchat profile
URL, Profile id, Profile name, Profile username, Profile alternate name, Profile description, Profile address, Profile image url, and more.
TikTok - Posts by Profile Fast API
URL, Post id, Description, Create time, Digg count, Share count, Collect count, Comment count, and more.
TikTok - Posts by URL Fast API
URL, Post id, Description, Create time, Digg count, Share count, Collect count, Comment count, and more.
TikTok - Posts by Search URL Fast API
URL, Post id, Description, Create time, Digg count, Share count, Collect count, Comment count, and more.
Social-Media-Scraper-Playground
Code-Beispiele
Möchten Sie nur Social-Media-Daten? Überspringen Sie das Scraping.
Kaufen Sie Social-Media-Datensätze
Social Media Scraper API Preise
Zahlen Sie nur für erfolgreich zugestellte Daten. Keine versteckten Gebühren, keine Kosten für fehlgeschlagene Lieferungen.
Erhalten Sie 25% Rabatt auf die Scraper-API für 3 Monate. Verwenden Sie den Code APIS25 beim Checkout.
Wir akzeptieren diese Zahlungsmethoden:
Jeder Plan bietet vollen Zugriff – zahlen Sie weniger pro Datensatz, wenn Sie skalieren
Datensammlung
- Automatisiertes Proxy-Management
- Vollständige Browser-Darstellung
- CAPTCHA-Lösung
Leistung im großen Maßstab
- Unbegrenzte Parallelität
- Batch- und geplante Sammlung
- Job-Management-APIs
Datenlieferung
- Datenvalidierung & -entdeckung
- Datenanalyse (JSON oder CSV)
- Webhook- oder API-Lieferung
Web Scraper API demo
UNDER THE HOOD
Mach dir nie wieder Sorgen um Proxys und CAPTCHAs
- Automatische IP-Rotation
- CAPTCHA-Lösung
- User-Agent-Rotation
- Benutzerdefinierte Header
- JavaScript-Rendering
- Residential-Proxys
SCHNELLERE BEREITSTELLUNG
Ein API-Aufruf. Unmengen von Daten.
Datenerkennung
Erkennung von Datenstrukturen und -mustern zur effizienten, gezielten Extraktion von Daten.
Bearbeitung von Massenanfragen
Reduzieren Sie die Serverbelastung und optimieren Sie die Datenerfassung für hochvolumige Scraping-Aufgaben.
Parsing von Daten
Effiziente Konvertierung von HTML-Rohdaten in strukturierte Daten zur Vereinfachung der Datenintegration und -analyse.
Datenvalidierung
Gewährleisten Sie die Zuverlässigkeit der Daten und sparen Sie Zeit für manuelle Überprüfungen und Vorverarbeitungen.
API für nahtlosen Social Media-Datenzugriff
Umfassende, skalierbare und konforme Web-Datenextraktion
API für nahtlosen Social Media-Datenzugriff
Umfassende, skalierbare und konforme Web-Datenextraktion
Auf Ihren Workflow zugeschnitten
Erhalten Sie strukturierte Daten in JSON-, NDJSON- oder CSV-Dateien per Webhook- oder API-Lieferung.
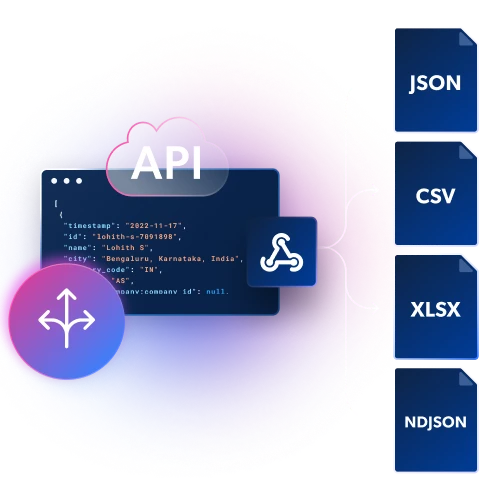
Integrierte Infrastruktur und Entsperrung
Maximale Kontrolle und Flexibilität ohne Wartung von Proxy- und Entsperrungsinfrastruktur. Scrapen Sie mühelos Daten aus beliebigen Geo-Standorten und umgehen Sie dabei CAPTCHAs und Sperren.

Bewährte Infrastruktur
Die Plattform von Bright Data unterstützt über 20.000 Unternehmen weltweit und bietet 99,99 % Betriebszeit sowie Zugang zu über 150 Millionen echten Nutzer-IPs in 195 Ländern.

Branchenführende Compliance
Unsere Datenschutzpraktiken entsprechen den Datenschutzgesetzen, einschließlich des EU-Datenschutzrahmens, der GDPR und der CCPA.

API für nahtlosen Social Media-Datenzugriff
Umfassende, skalierbare und konforme Web-Datenextraktion
FLEXIBEL
Auf Ihren Workflow zugeschnitten
Erhalten Sie strukturierte Daten in JSON-, NDJSON- oder CSV-Dateien per Webhook- oder API-Lieferung.SKALIERBAR
Integrierte Infrastruktur und Entsperrung
Maximale Kontrolle und Flexibilität ohne Wartung von Proxy- und Entsperrungsinfrastruktur. Scrapen Sie mühelos Daten aus beliebigen Geo-Standorten und umgehen Sie dabei CAPTCHAs und Sperren.STABIL
Bewährte Infrastruktur
Die Plattform von Bright Data unterstützt über 20.000 Unternehmen weltweit und bietet 99,99 % Betriebszeit sowie Zugang zu über 150 Millionen echten Nutzer-IPs in 195 Ländern.KONFORM
Branchenführende Compliance
Unsere Datenschutzpraktiken entsprechen den Datenschutzgesetzen, einschließlich des EU-Datenschutzrahmens, der GDPR und der CCPA.Social Media Scraper use cases
Scrapen Sie alle wichtigen Social-Media-Plattformen
Erkennen Sie Trends
Führen Sie Recherchen vor wichtigen Ereignissen durch
Analysieren Sie verschiedene Altersgruppen
Warum 20,000+ Kunden Bright Data wählen
100% konform
Gescrapte Daten werden ethisch gewonnen und entsprechen allen Datenschutzgesetzen.
24/7 globaler Support
Ein engagiertes Team von Datenexperten steht Ihnen jederzeit zur Verfügung.
Vollständige Datenabdeckung
Greifen Sie auf 400 million+ globale IPs zu, um Daten von jeder Website zu scrapen.
Unübertroffene Datenqualität
Fortschrittliche Technologien und Validierungsmethoden für qualitativ hochwertige Daten.
Leistungsstarke Infrastruktur
Scrapen Sie große Datenmengen, ohne blockiert zu werden.
Maßgeschneiderte Lösungen
Erhalten Sie maßgeschneiderte Lösungen für individuelle Bedürfnisse und Ziele.
Bright Data wird von den weltweit führenden Marken genutzt
Wir helfen Unternehmen mit sicherem, skalierbarem und flexiblem Datenmanagement zu wachsen.
 Ich empfehle die Produkte von Bright Data für jedes Unternehmen, insbesondere in der Finanzbranche. Bright Data ist vertrauenswürdig und konform, der Service ist großartig, die Produkte sind einwandfrei und das Netzwerk ist schnell und stabil.
Ich empfehle die Produkte von Bright Data für jedes Unternehmen, insbesondere in der Finanzbranche. Bright Data ist vertrauenswürdig und konform, der Service ist großartig, die Produkte sind einwandfrei und das Netzwerk ist schnell und stabil. Xiaolong ShiCrawler Engineer at Bitget
Xiaolong ShiCrawler Engineer at Bitget Ohne die Möglichkeit, öffentliche Webdaten aus dem Internet zu sammeln, können wir nicht wissen, wann eine Marke in allen Medien präsent war und welche Reichweite sie hatte. Ohne die Unterstützung von Bright Data könnten wir nicht so schnell wachsen, wie wir es tun.
Ohne die Möglichkeit, öffentliche Webdaten aus dem Internet zu sammeln, können wir nicht wissen, wann eine Marke in allen Medien präsent war und welche Reichweite sie hatte. Ohne die Unterstützung von Bright Data könnten wir nicht so schnell wachsen, wie wir es tun. Sarah MelvilleMedia Director at YouGov Sport
Sarah MelvilleMedia Director at YouGov Sport Meiner Erfahrung nach war der Service von Bright Data von unschätzbarem Wert. Bright Data half uns dabei, genügend öffentliche Webdaten zu sammeln, um unseren Anforderungen gerecht zu werden, und mit Unterstützung des Support- und Entwicklungsteams konnten wir viele unserer Prozesse optimieren.
Meiner Erfahrung nach war der Service von Bright Data von unschätzbarem Wert. Bright Data half uns dabei, genügend öffentliche Webdaten zu sammeln, um unseren Anforderungen gerecht zu werden, und mit Unterstützung des Support- und Entwicklungsteams konnten wir viele unserer Prozesse optimieren. Charmagne CruzHead of Reporting & Analytics, Business Technologies and Pricing at Shopee Philippines Inc.
Charmagne CruzHead of Reporting & Analytics, Business Technologies and Pricing at Shopee Philippines Inc.- Die beste Qualität und Quantität der Daten ist das Wichtigste, und genau hier kommt die Kombination aus Bright Data und tgndata zum Tragen.Jetzt anschauen
 George KoutsoudopoulosCEO at tgndata
George KoutsoudopoulosCEO at tgndata  Wir sind sehr beeindruckt von der Zuverlässigkeit und insgesamt sehr zufrieden mit Bright Data. Wir stehen in regelmäßigem Kontakt mit unserem Account Manager, der uns sehr hilfreich ist.
Wir sind sehr beeindruckt von der Zuverlässigkeit und insgesamt sehr zufrieden mit Bright Data. Wir stehen in regelmäßigem Kontakt mit unserem Account Manager, der uns sehr hilfreich ist. Yorgos PanzarisCTO at Convert Group
Yorgos PanzarisCTO at Convert Group Wir sind sehr zufrieden mit der Partnerschaft mit Bright Data. Alles läuft gut, das Netzwerk ist sehr stabil, wir sind mit dem Kundenservice zufrieden und die Support-Mitarbeiter sind unserer Meinung nach unübertroffen.
Wir sind sehr zufrieden mit der Partnerschaft mit Bright Data. Alles läuft gut, das Netzwerk ist sehr stabil, wir sind mit dem Kundenservice zufrieden und die Support-Mitarbeiter sind unserer Meinung nach unübertroffen. Cheddi RaiCEO at AdRetreaver
Cheddi RaiCEO at AdRetreaver

Möchten Sie mehr erfahren?
Sprechen Sie mit einem Experten, um Ihre Scraping Anforderungen zu besprechen.
Social Media Scraper API FAQs
Was ist die Social Media Scraper API?
Die Social Media Scraper API ist ein einheitliches Set von APIs, das für die nahtlose Datenerfassung von führenden sozialen Plattformen entwickelt wurde. Sie ermöglicht es Nutzern, öffentliche soziale Daten wie Nutzerprofile, Beiträge und Kommentare über mehrere Plattformen hinweg mit einer einheitlichen Schnittstelle zu extrahieren, zu analysieren und zu überwachen.
Welche Arten von Daten kann ich erfassen?
Jede API innerhalb der Suite konzentriert sich auf einen zentralen Datentyp:
- Profile API: Follower, Abonnenten, Profil-/Kanalinformationen, Zielgruppenstatistiken.
- Beitrags-API: Inhaltsinformationen (Beiträge, Videos), Engagement-Statistiken (Likes, Aufrufe), Hashtags und Analysen auf Beitragsebene.
- Kommentar-API: Kommentare zu Beiträgen und Videos, einschließlich Antworten und Likes auf Kommentare.
Wie arbeiten die APIs zusammen, um Erkenntnisse zu gewinnen?
Die APIs sind miteinander verbunden, was bedeutet, dass Daten aus einer API (z. B. ein Profil) als Eingabe für eine andere (z. B. Beitrags- oder Kommentaranalyse) verwendet werden können. Dies ermöglicht durchgängiges Social Listening, Influencer-Tracking und Engagement-Analysen über Plattformen hinweg.
Sind die bereitgestellten Daten aktuell und auf dem neuesten Stand?
Ja. Alle unsere Social-Media-APIs bieten eine On-Demand-Erfassung und garantieren bei jeder Anfrage die aktuellsten öffentlichen Daten.
Kann ich die Datenausgabe oder den Erfassungsprozess anpassen?
Absolut. Der Social Media Scraper ermöglicht benutzerdefinierte Abfragen, Ausgabeformate und individuelle Feldauswahl. Sie können APIs für plattformübergreifende und mehrdimensionale Berichte kombinieren, die auf Ihre spezifischen Bedürfnisse zugeschnitten sind.
Wie integriere ich die Social Media Scraper APIs in meine bestehenden Systeme?
Die Integration ist einfach – verwenden Sie einfach unsere unkomplizierten API-Endpunkte in Ihrer bevorzugten Entwicklungsumgebung. Vollständige Dokumentation und Code-Beispiele sind in der Dokumentation verfügbar.
Was sind die Anwendungsfälle für diese APIs?
Typische Anwendungsfälle umfassen Wettbewerbsanalyse, Marken- und Stimmungsanalyse, Influencer-Recherche, Erfassung von Zielgruppendemografien und Verfolgung sozialer Trends.
Wie wird der Social Media Scraper abgerechnet?
Die Abrechnung basiert auf der Anzahl der erfassten Datensätze, abhängig von Ihrem Preisplan. Weitere Details finden Sie auf der Preisseite oder in Ihrem Account-Dashboard.
Ist es legal, Daten mit den Social Media Scraper APIs zu erfassen?
Unsere Datenschutzpraktiken entsprechen den Datenschutzgesetzen, einschließlich des EU-Datenschutzrechtsrahmens, der GDPR-Konformität und der CCPA – unter Wahrung von Anfragen zur Ausübung von Datenschutzrechten und mehr.
Wo kann ich Support erhalten oder neue Funktionen anfordern?
Für Hilfe wenden Sie sich an unser Support-Team oder Ihren Account Manager. Sie können auch benutzerdefinierte Datenfelder oder neue Plattformunterstützung als Teil unserer verwalteten Datendienste anfordern.
Gibt es Ratenlimits oder Nutzungsbeschränkungen?
Es gibt keine spezifischen Nutzungslimits für die Social Media Scraper API, was Ihnen die Flexibilität bietet, nach Bedarf zu skalieren. Die Preise beginnen ab 0,001 $ pro Datensatz und gewährleisten eine kosteneffiziente Skalierbarkeit für Ihre Web-Scraping-Projekte.