

In dieser Goutte-Anleitung zum Web-Scraping lernen Sie:
- Was die PHP-Bibliothek Goutte ist
- Schritt-für-Schritt-Anleitung zur Verwendung für Web Scraping
- Alternativen zu Goutte für Web Scraping
- Die Grenzen dieses Ansatzes und mögliche Lösungen
Lasst uns eintauchen!
Was ist Goutte?
Goutte ist eine PHP-Bibliothek für Screen Scraping und Web Crawling. Sie bietet eine intuitive API zum Navigieren auf Webseiten und zum Extrahieren von Daten aus HTML/XML-Antworten. Sie enthält einen integrierten HTTP-Client und HTML-Parsing-Funktionen, mit denen Sie Webseiten über HTTP-Anfragen abrufen und für das Data Scraping verarbeiten können.
Hinweis: Seit dem 1. April 2023 wird Goutte nicht mehr gepflegt und gilt nun als veraltet. Zum Zeitpunkt dieses Schreibens funktioniert es jedoch noch zuverlässig.
Wie man Web Scraping mit Goutte durchführt: Schritt-für-Schritt-Anleitung
Folgen Sie diesem Schritt-für-Schritt-Tutorial und sehen Sie, wie Sie Goutte für die Extraktion von Daten aus der Website “Hockey Teams” verwenden:
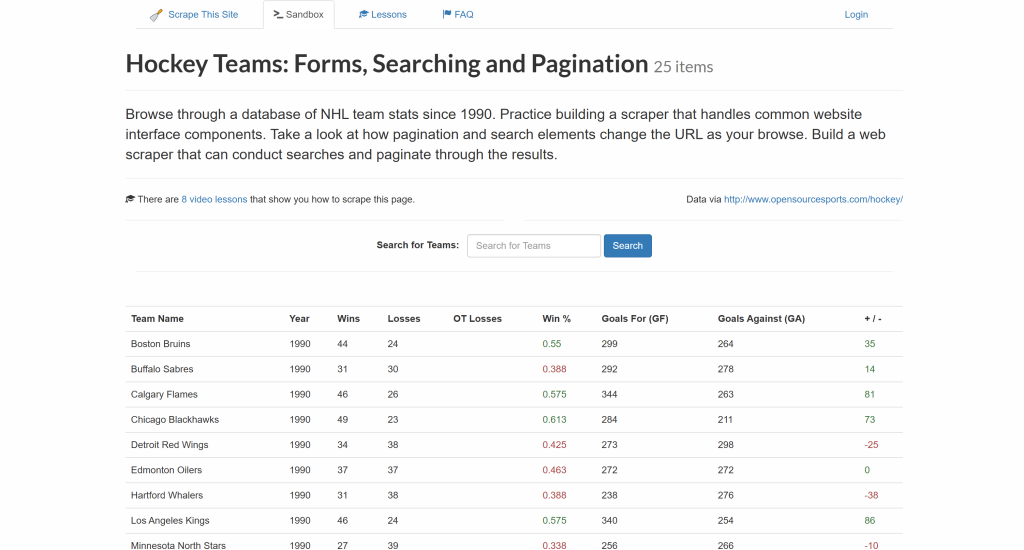
Ziel ist es, die Daten aus der obigen Tabelle zu extrahieren und sie in eine CSV-Datei zu exportieren.
Zeit zu lernen, wie man Web Scraping mit Goutte durchführt!
Schritt 1: Projekt einrichten
Bevor Sie beginnen, sollten Sie sicherstellen, dass Ihr System die Anforderungen von Goutte erfüllt – PHP7.1 oder höher. Um Ihre aktuelle PHP-Version zu überprüfen, führen Sie den folgenden Befehl aus:
php -vDie Ausgabe sollte in etwa so aussehen:
PHP 8.4.3 (cli) (built: Jan 19 2026 14:20:58) (NTS)
Copyright (c) The PHP Group
Zend Engine v4.4.3, Copyright (c) Zend Technologies
with Zend OPcache v8.4.3, Copyright (c), by Zend TechnologiesWenn Ihre PHP-Version niedriger als 7.1 ist, müssen Sie PHP aktualisieren, bevor Sie fortfahren.
Beachten Sie bitte, dass Goutte über Composer installiert wird, einen Abhängigkeitsmanager für PHP. Wenn Composer nicht auf Ihrem System installiert ist, laden Sie ihn von der offiziellen Website herunter und folgen Sie den Installationsanweisungen.
Erstellen Sie nun ein neues Verzeichnis für Ihr Goutte-Projekt und navigieren Sie im Terminal dorthin:
mkdir goutte-parser
cd goutte-parserAls nächstes verwenden Sie den Befehl composer init, um ein Composer-Projekt in diesem Ordner zu initialisieren:
composer initDer Composer fordert Sie auf, Projektdetails wie Paketname und -beschreibung einzugeben. Die Standardantworten werden funktionieren, aber Sie können sie gerne Ihren Zielen entsprechend anpassen.
Öffnen Sie nun den Projektordner in Ihrer bevorzugten PHP-IDE. Visual Studio Code mit der PHP-Erweiterung oder IntelliJ WebStorm sind beide eine gute Wahl.
Erstellen Sie eine leere index.php-Datei im Projektordner, die Folgendes enthalten sollte:
php-html-parser/
├── vendor/
├── composer.json
└── index.phpÖffnen Sie index.php und fügen Sie die folgende Codezeile für den Import der Composer-Bibliotheken ein:
<?php
require_once __DIR__ . "/vendor/autoload.php";
// scraping logic...Diese Datei wird in Kürze die Goutte-Scraping-Logik enthalten.
Sie können Ihr Skript nun mit diesem Befehl ausführen:
php index.phpGroßartig! Sie sind nun in der Lage, Daten mit Goutte in PHP zu scrapen.
Schritt #2: Goutte installieren und konfigurieren
Installieren Sie Goutte mit dem unten stehenden Compose-Befehl:
composer require fabpot/goutteDadurch wird die Abhängigkeit fabpot/goutte zu Ihrer composer.json-Datei hinzugefügt, die nun Folgendes enthält:
"require": {
"fabpot/goutte": "^4.0"
}Importieren Sie Goutte in index.php, indem Sie die folgende Codezeile hinzufügen:
use GoutteClient;Dadurch wird der Goutte-HTTP-Client offengelegt, den Sie verwenden können, um sich mit einer Zielseite zu verbinden, deren HTML zu parsen und Daten daraus zu extrahieren. Wie das geht, sehen Sie im nächsten Schritt!
Schritt #3: Holen Sie sich den HTML-Code der Zielseite
Erstellen Sie zunächst einen neuen Goutte-HTTP-Client:
$client = new Client();Hinter den Kulissen ist die Client-Klasse von Goutte einfach ein Wrapper um die BrowserKitHttpBrowser-Komponente von Symfony. Sehen Sie es in Aktion in unserem Leitfaden zum Web-Scraping mit Laravel.
Als Nächstes speichern Sie die Ziel-URL der Webseite in einer Variablen und verwenden die request() -Methode, um ihren Inhalt abzurufen:
$url = "https://www.scrapethissite.com/pages/forms/";
$crawler = $client->request("GET", $url);Dies sendet eine GET-Anfrage an die Webseite, ruft das HTML-Dokument ab und analysiert es für Sie. Insbesondere bietet das $crawler-Objekt Zugriff auf alle Methoden der DomCrawler-Komponente von Symfony. $crawler ist das Objekt, das Sie zum Navigieren und Extrahieren von Daten aus der Seite verwenden werden.
Erstaunlich! Sie haben jetzt alles, was Sie für Goutte Web Scraping brauchen.
Schritt Nr. 4: Vorbereiten des Scrappens von Daten von Interesse
Bevor Sie Daten extrahieren, müssen Sie sich mit der HTML-Struktur der Zielseite vertraut machen.
Denken Sie zunächst daran, dass die interessierenden Daten in Zeilen in einer Tabelle dargestellt werden. Da diese Tabelle mehrere Zeilen enthält, ist ein Array eine hervorragende Datenstruktur, um die ausgewerteten Daten zu speichern:
$teams = [];Konzentrieren Sie sich nun auf die HTML-Struktur der Tabelle. Rufen Sie die Zielseite in Ihrem Browser auf, klicken Sie mit der rechten Maustaste auf die Tabelle, die die gewünschten Daten enthält, und wählen Sie die Option “Inspect”:
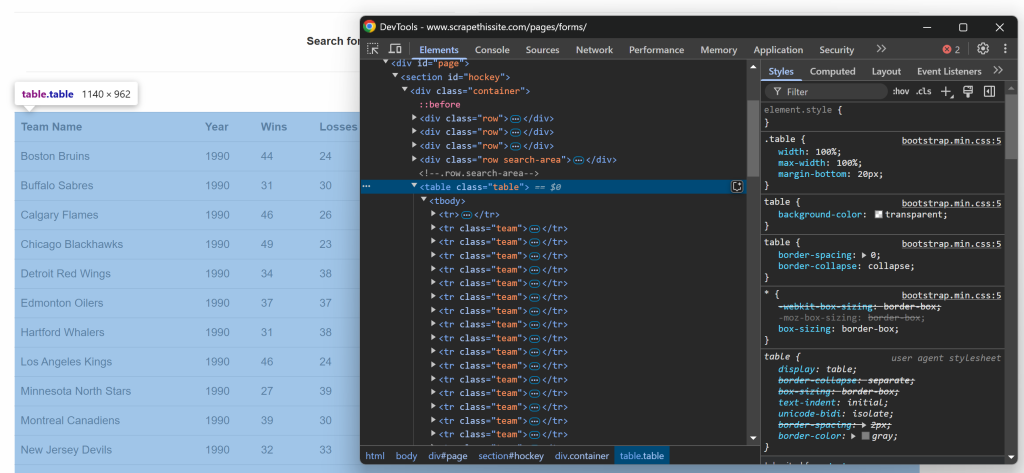
In den DevTools sehen Sie, dass die Tabelle eine Tabellenklasse hat und in einem
id=``"``Hockey``" enthalten ist. Das bedeutet, dass Sie die Tabelle mit dem folgenden CSS-Selektor ansteuern können:
#hockey .tableWenden Sie den CSS-Selektor an, um den Tabellenknoten mit der Methode $crawler->filter() auszuwählen:
$table = $crawler->filter("#hockey .table");Beachten Sie dann, dass jede Zeile durch ein
team repräsentiert wird. Wählen Sie alle Zeilen aus und führen Sie eine Iteration über sie durch, um Daten aus ihnen zu extrahieren:
$table->filter("tr.team")->each(function ($tr) use (&$teams) {
// data extraction logic...
});Wunderbar! Sie haben jetzt ein Gerüst, das für das Scrapen von Goutte-Daten bereit ist.
Schritt Nr. 5: Implementierung der Datenextraktionslogik
Prüfen Sie wie zuvor die Zeilen innerhalb der Tabelle:
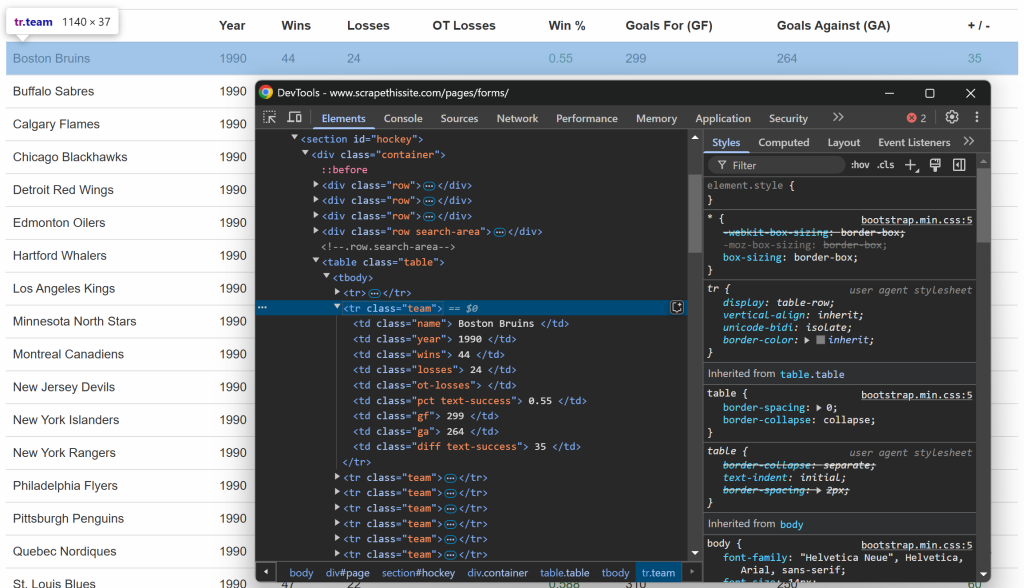
Sie können feststellen, dass jede Zeile die folgenden Informationen in speziellen Spalten enthält:
- Teamname → innerhalb des Elements
.name - Saisonjahr → innerhalb des Elements
.year - Anzahl der Gewinne → innerhalb des Elements
.wins - Anzahl der Verluste → innerhalb des Elements
.losses - Verluste in der Nachspielzeit → innerhalb des Elements
.ot-losses - Gewinnanteil → innerhalb des Elements
.pct - Erzielte Tore (Goals For – GF) → innerhalb des Elements
.gf - Gegentore (Goals Against – GA) → innerhalb des Elements
.ga - Tordifferenz → innerhalb des Elements
.diff
Um eine einzelne Information abzurufen, müssen Sie diese beiden Schritte ausführen:
- Wählen Sie das HTML-Element mit
filter()aus. - Extrahieren Sie den Textinhalt mit der Methode
text()und entfernen Sie alle zusätzlichen Leerzeichen mittrim()
Zum Beispiel können Sie den Teamnamen mit scrapen:
$teamElement = $tr->filter(".name");
$team = trim($teamElement->text());Erweitern Sie diese Logik auch auf alle anderen Spalten:
$yearElement = $tr->filter(".year");
$year = trim($yearElement->text());
$winsElement = $tr->filter(".wins");
$wins = trim($winsElement->text());
$lossesElement = $tr->filter(".losses");
$losses = trim($lossesElement->text());
$otLossesElement = $tr->filter(".ot-losses");
$otLosses = trim($otLossesElement->text());
$pctElement = $tr->filter(".pct");
$pct = trim($pctElement->text());
$gfElement = $tr->filter(".gf");
$gf = trim($gfElement->text());
$gaElement = $tr->filter(".ga");
$ga = trim($gaElement->text());
$diffElement = $tr->filter(".diff");
$diff = trim($diffElement->text());Sobald Sie die Daten von Interesse aus der Zeile extrahiert haben, speichern Sie sie im Array $teams:
$teams[] = [
"team" => $team,
"year" => $year,
"wins" => $wins,
"losses" => $losses,
"ot_losses" => $otLosses,
"win_perc" => $pct,
"goals_for" => $gf,
"goals_against" => $ga,
"goal_diff" => $diff
];Nachdem alle Zeilen durchlaufen wurden, enthält das Array $teams:
Array
(
[0] => Array
(
[team] => Boston Bruins
[year] => 1990
[wins] => 44
[losses] => 24
[ot_losses] =>
[win_perc] => 0.55
[goals_for] => 299
[goals_against] => 264
[goal_diff] => 35
)
// ...
[24] => Array
(
[team] => Chicago Blackhawks
[year] => 1991
[wins] => 36
[losses] => 29
[ot_losses] =>
[win_perc] => 0.45
[goals_for] => 257
[goals_against] => 236
[goal_diff] => 21
)
)Großartig! Goutte-Datenabfrage erfolgreich durchgeführt.
Schritt #6: Implementierung der Crawling-Logik
Vergessen Sie nicht, dass die Zielsite die Daten auf mehreren Seiten präsentiert und jeweils nur einen Teil davon anzeigt. Unterhalb der Tabelle befindet sich ein Paginierungselement, das Links zu allen Seiten enthält:

So können Sie die Paginierung in Ihrem Scraping-Skript mit diesen einfachen Schritten verwalten:
- Wählen Sie die Elemente für die Paginierung aus
- Extrahieren der URLs der paginierten Seiten
- Besuchen Sie jede Seite und wenden Sie die zuvor erarbeitete Scraping-Logik an
Beginnen Sie damit, die Elemente der Paginierungslinks zu untersuchen:
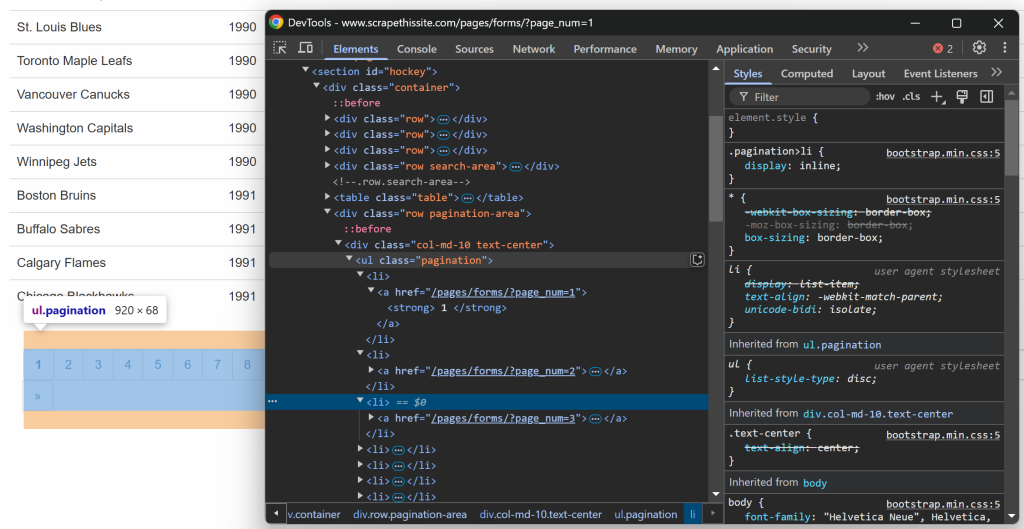
Beachten Sie, dass Sie alle Paginierungslinks mit dem folgenden CSS-Selektor auswählen können:
.pagination li aUm Schritt 2 zu implementieren und alle Paginierungs-URLs zu sammeln, verwenden Sie diese Logik:
$urls = [$url];
// select the pagination link elements
$crawler->filter(".pagination li a")->each(function ($a) use (&$urls) {
// construct the absolute URL
$url = "https://www.scrapethissite.com" . $a->attr("href");
// add the pagination URL to the list only if it is not already present
if (!in_array($url, $urls)) {
$urls[] = $url;
}
});Dies initialisiert eine Liste von URLs, die die Paginierungslinks speichern werden, beginnend mit der URL der ersten Seite. Anschließend werden alle Paginierungselemente ausgewählt und durchlaufen, wobei neue URLs nur dann zum Array $urls hinzugefügt werden, wenn sie nicht bereits vorhanden sind. Da die URLs auf der Seite relativ sind, müssen sie in absolute URLs umgewandelt werden, bevor sie der Liste hinzugefügt werden.
Da die Seitenumbruchbehandlung nur einmal ausgeführt werden sollte und nicht direkt mit der Datenextraktion verbunden ist, ist es am besten, sie in eine Funktion zu verpacken:
function getPaginationUrls($client, $url)
{
// connect to the first page of the site
$crawler = $client->request("GET", $url);
// initialize the list of URLs to scrape with the current URL
$urls = [$url];
// select the pagination link elements
$crawler->filter(".pagination li a")->each(function ($a) use (&$urls) {
// construct the absolute URL
$url = "https://www.scrapethissite.com" . $a->attr("href");
// add the pagination URL to the list only if it is not already present
if (!in_array($url, $urls)) {
$urls[] = $url;
}
});
return $urls;
}Sie können die Funktion getPaginationUrls() wie folgt aufrufen:
$urls = getPaginationUrls($client, "https://www.scrapethissite.com/pages/forms/?page_num=1");Nach der Ausführung wird $urls alle paginierten URLs enthalten:
Array
(
[0] => https://www.scrapethissite.com/pages/forms/?page_num=1
[1] => https://www.scrapethissite.com/pages/forms/?page_num=2
[2] => https://www.scrapethissite.com/pages/forms/?page_num=3
[3] => https://www.scrapethissite.com/pages/forms/?page_num=4
[4] => https://www.scrapethissite.com/pages/forms/?page_num=5
[5] => https://www.scrapethissite.com/pages/forms/?page_num=6
[6] => https://www.scrapethissite.com/pages/forms/?page_num=7
[7] => https://www.scrapethissite.com/pages/forms/?page_num=8
[8] => https://www.scrapethissite.com/pages/forms/?page_num=9
[9] => https://www.scrapethissite.com/pages/forms/?page_num=10
[10] => https://www.scrapethissite.com/pages/forms/?page_num=11
[11] => https://www.scrapethissite.com/pages/forms/?page_num=12
[12] => https://www.scrapethissite.com/pages/forms/?page_num=13
[13] => https://www.scrapethissite.com/pages/forms/?page_num=14
[14] => https://www.scrapethissite.com/pages/forms/?page_num=15
[15] => https://www.scrapethissite.com/pages/forms/?page_num=16
[16] => https://www.scrapethissite.com/pages/forms/?page_num=17
[17] => https://www.scrapethissite.com/pages/forms/?page_num=18
[18] => https://www.scrapethissite.com/pages/forms/?page_num=19
[19] => https://www.scrapethissite.com/pages/forms/?page_num=20
[20] => https://www.scrapethissite.com/pages/forms/?page_num=21
[21] => https://www.scrapethissite.com/pages/forms/?page_num=22
[22] => https://www.scrapethissite.com/pages/forms/?page_num=23
[23] => https://www.scrapethissite.com/pages/forms/?page_num=24
)Perfekt! Sie haben soeben Web Crawling in Goutte implementiert.
Schritt #7: Scrapen Sie Daten von allen Seiten
Nun, da Sie alle Seiten-URLs in einem Array gespeichert haben, können Sie sie nacheinander abrufen:
- Iteration über die Liste
- Abrufen und Parsen des HTML-Inhalts für jede URL
- Extrahieren der erforderlichen Daten
- Speichern der ausgewerteten Informationen im Array
$teams.
Implementieren Sie die obige Logik wie folgt:
$teams = [];
// iterate over all pages and scrape them all
foreach ($urls as $_ => $url) {
// logging which page the scraper is currently working on
echo "Scraping webpage "$url"...n";
// retrieve the HTML of the current page and parse it
$crawler = $client->request("GET", $url);
// $table = $crawler-> ...
// data extraction logic
}Beachten Sie die echo-Anweisung zur Protokollierung der aktuellen Seite, auf der der Scraper arbeitet. Diese Information ist nützlich, um zu verstehen, was das Skript während der Ausführung tut.
Wunderbar! Es bleibt nur noch, die gescrapten Daten in ein für Menschen lesbares Format wie CSV zu exportieren.
Schritt Nr. 8: Exportieren Sie die gescrapten Daten in CSV
Im Moment werden die gesammelten Daten im Array $teams gespeichert. Um sie für andere Teams zugänglich zu machen und leichter zu analysieren, exportieren Sie sie in eine CSV-Datei.
PHP bietet integrierte Unterstützung für den CSV-Export durch die Funktion fputcsv(). Verwenden Sie diese Funktion, um die gesammelten Daten in eine Datei mit dem Namen teams.csv zu schreiben (siehe unten):
// open the output file for writing
$file = fopen("teams.csv", "w");
// write the header row
fputcsv($file, ["Team Name", "Year", "Wins", "Losses", "OT Losses", "Win %","Goals For (GF)", "Goals Against (GA)", "+ / -"]);
// append each team as a new row
foreach ($teams as $team) {
fputcsv($file, [
$team["team"],
$team["year"],
$team["wins"],
$team["losses"],
$team["ot_losses"],
$team["win_perc"],
$team["goals_for"],
$team["goals_against"],
$team["goal_diff"]
]);
}
// close the file
fclose($file);Auftrag erfüllt! Der Goutte-Schaber ist voll funktionsfähig.
Schritt #9: Alles zusammenfügen
Ihr Goutte Web Scraping Skript sollte nun enthalten:
<?php
require_once __DIR__ . "/vendor/autoload.php";
use GoutteClient;
function getPaginationUrls($client, $url)
{
// connect to the first page of the site
$crawler = $client->request("GET", $url);
// initialize the list of URLs to scrape with the current URL
$urls = [$url];
// select the pagination link elements
$crawler->filter(".pagination li a")->each(function ($a) use (&$urls) {
// construct the absolute URL
$url = "https://www.scrapethissite.com" . $a->attr("href");
// add the pagination URL to the list only if it is not already present
if (!in_array($url, $urls)) {
$urls[] = $url;
}
});
return $urls;
}
// initialize a new Goutte HTTP client
$client = new Client();
// get the URLs of the pages to scrape
$urls = getPaginationUrls($client, "https://www.scrapethissite.com/pages/forms/?page_num=1");
// where to store the scraped data
$teams = [];
// iterate over all pages and scrape them all
foreach ($urls as $_ => $url) {
// logging which page the scraper is currently working on
echo "Scraping webpage "$url"...n";
// retrieve the HTML of the current page and parse it
$crawler = $client->request("GET", $url);
// select the table element with the data of interest
$table = $crawler->filter("#hockey .table");
// iterate over each row and extract data from them
$table->filter("tr.team")->each(function ($tr) use (&$teams) {
// data extraction logic
$teamElement = $tr->filter(".name");
$team = trim($teamElement->text());
$yearElement = $tr->filter(".year");
$year = trim($yearElement->text());
$winsElement = $tr->filter(".wins");
$wins = trim($winsElement->text());
$lossesElement = $tr->filter(".losses");
$losses = trim($lossesElement->text());
$otLossesElement = $tr->filter(".ot-losses");
$otLosses = trim($otLossesElement->text());
$pctElement = $tr->filter(".pct");
$pct = trim($pctElement->text());
$gfElement = $tr->filter(".gf");
$gf = trim($gfElement->text());
$gaElement = $tr->filter(".ga");
$ga = trim($gaElement->text());
$diffElement = $tr->filter(".diff");
$diff = trim($diffElement->text());
// add the scraped data to the array
$teams[] = [
"team" => $team,
"year" => $year,
"wins" => $wins,
"losses" => $losses,
"ot_losses" => $otLosses,
"win_perc" => $pct,
"goals_for" => $gf,
"goals_against" => $ga,
"goal_diff" => $diff
];
});
}
// open the output file for writing
$file = fopen("teams.csv", "w");
// write the header row
fputcsv($file, ["Team Name", "Year", "Wins", "Losses", "OT Losses", "Win %","Goals For (GF)", "Goals Against (GA)", "+ / -"]);
// append each team as a new row
foreach ($teams as $team) {
fputcsv($file, [
$team["team"],
$team["year"],
$team["wins"],
$team["losses"],
$team["ot_losses"],
$team["win_perc"],
$team["goals_for"],
$team["goals_against"],
$team["goal_diff"]
]);
}
// close the file
fclose($file);Starten Sie es mit diesem Befehl:
php index.phpDer Scraper würde die folgende Ausgabe protokollieren:
Scraping webpage "https://www.scrapethissite.com/pages/forms/?page_num=1"...
// omitted for brevity..
Scraping webpage "https://www.scrapethissite.com/pages/forms/?page_num=24"...Am Ende der Ausführung wird eine Datei teams.csv mit diesen Daten im Projektordner erscheinen:
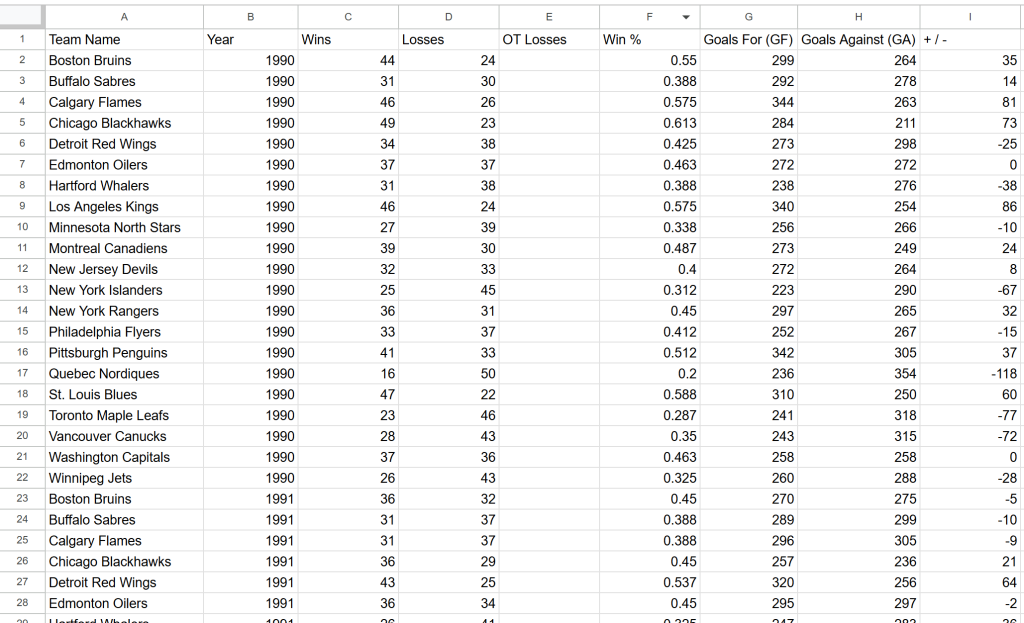
Et voilà! Die genauen Daten der Zielsite sind nun in einem strukturierten Format verfügbar.
Alternativen zur PHP-Goutte-Bibliothek für Web-Scraping
Wie bereits zu Beginn dieses Artikels erwähnt, ist Goutte veraltet und wird nicht mehr gepflegt. Das bedeutet, dass Sie alternative Lösungen in Betracht ziehen sollten.
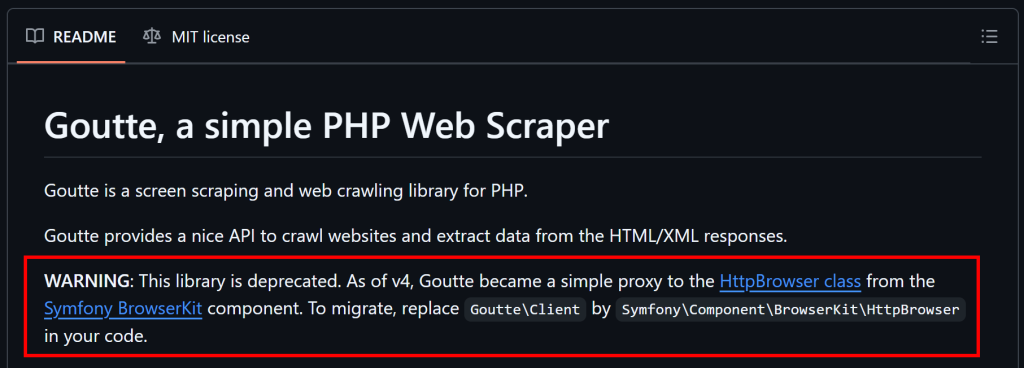
Wie auf GitHub erklärt, ist Goutte v4 im Wesentlichen ein Proxy für die HttpBrowser-Klasse von Symfony geworden, so dass Sie darauf migrieren sollten. Um dies zu tun, müssen Sie nur diese Bibliotheken installieren:
composer require symfony/browser-kit symfony/http-clientDann ersetzen:
use GoutteClient;mit
use SymfonyComponentBrowserKitHttpBrowser;Entfernen Sie schließlich Goutte als Abhängigkeit in Ihrem Projekt. Die zugrundeliegende API bleibt dieselbe, so dass Sie in Ihrem Skript nicht viel ändern müssen.
Anstelle von Goutte können Sie auch einen HTTP-Client mit einem HTML-Parser kombinieren. Einige empfohlene Alternativen:
- Guzzle oder cURL für die Erstellung von HTTP-Anfragen.
DomHTMLDocument, Simple HTML DOM Parser, oderDomCrawlerzum Parsen von HTML in PHP.
All diese Alternativen bieten Ihnen mehr Flexibilität und garantieren, dass Ihr Web-Scraping-Skript auf lange Sicht wartbar bleibt.
Beschränkungen dieses Ansatzes für Web Scraping
Goutte ist ein leistungsfähiges Werkzeug, aber seine Verwendung für Web Scraping ist mit einigen Einschränkungen verbunden:
- Die Bibliothek ist veraltet
- Seine API wird nicht mehr gepflegt
- Sie unterliegt Ratenbegrenzern und Anti-Scraping-Blöcken
- Es kann keine dynamischen Seiten verarbeiten, die auf JavaScript basieren.
- Es hat eine begrenzte integrierte Proxy-Unterstützung, die für die Umgehung von IP-Sperren unerlässlich ist
Einige dieser Einschränkungen lassen sich durch die Verwendung alternativer Bibliotheken oder anderer Ansätze abmildern, wie in unserem Leitfaden zum Web Scraping mit PHP beschrieben. Dennoch werden Sie immer mit Anti-Scraping-Maßnahmen konfrontiert sein, die nur mit einer Web Unlocker API umgangen werden können.
Eine Web Unlocker API ist ein spezieller Scraping-Endpunkt, der entwickelt wurde, um Anti-Bot-Schutzmaßnahmen zu umgehen und den rohen HTML-Code einer beliebigen Webseite abzurufen. Die Verwendung ist so einfach wie ein API-Aufruf und das Parsen des zurückgegebenen Inhalts. Dieser Ansatz lässt sich nahtlos in Goutte (oder die aktualisierten Komponenten von Symfony) integrieren, wie in diesem Artikel gezeigt.
Schlussfolgerung
In diesem Leitfaden haben Sie anhand eines Schritt-für-Schritt-Tutorials herausgefunden, was Goutte ist und was es für Web Scraping bietet. Da diese Bibliothek inzwischen veraltet ist, hatten Sie auch die Gelegenheit, einige ihrer Alternativen kennenzulernen.
Unabhängig davon, welche PHP-Scraping-Bibliothek Sie wählen, besteht die größte Herausforderung darin, dass die meisten Websites ihre Daten mit Anti-Bot- und Anti-Scraping-Technologien schützen. Diese Mechanismen können automatisierte Anfragen erkennen und blockieren, wodurch herkömmliche Scraping-Methoden unwirksam werden.
Zum Glück bietet Bright Data eine Reihe von Lösungen an, um solche Probleme zu vermeiden:
- Web Unlocker: Eine API, die Anti-Scraping-Schutzmaßnahmen umgeht und mit minimalem Aufwand sauberes HTML von jeder Webseite liefert.
- Scraping-Browser: Ein Cloud-basierter, kontrollierbarer Browser mit JavaScript-Rendering. Er verwaltet automatisch CAPTCHAs, Browser-Fingerprinting, Wiederholungsversuche und mehr für Sie. Er lässt sich nahtlos mit Panther oder Selenium PHP integrieren.
- Web Scraping APIs: Endpunkte für den programmatischen Zugriff auf strukturierte Webdaten aus Dutzenden von beliebten Domains.
Sie wollen sich nicht mit Web Scraping beschäftigen, sind aber dennoch an “Online-Webdaten” interessiert? Erkunden Sie unsere gebrauchsfertigen Datensätze!
Melden Sie sich jetzt bei Bright Data an und starten Sie Ihre kostenlose Testversion, um unsere Scraping-Lösungen zu testen.





