

Einfach ausgedrückt beziehen sich schlechte Daten auf unvollständige, ungenaue, inkonsistente, irrelevante oder doppelte Daten, die aus verschiedenen Gründen in Ihre Dateninfrastruktur gelangen.
Am Ende dieses Artikels werden Sie Folgendes verstehen:
- Was schlechte Daten sind
- Verschiedene Arten von schlechten Daten
- Was schlechte Daten verursacht
- welche Folgen sie haben und wie man sie verhindern kann
Schauen wir uns das also genauer an:
Verschiedene Arten von fehlerhaften Daten
Datenqualität und -zuverlässigkeit sind in fast allen Bereichen von entscheidender Bedeutung, von der Geschäftsanalyse bis zum Training von KI-Modellen. Schlechte Datenqualität kann verschiedene Formen annehmen, die jeweils einzigartige Herausforderungen für die Verwendbarkeit und Integrität der Daten mit sich bringen.

Unvollständige Daten
Unvollständige Daten liegen vor, wenn in einem Datensatz eines oder mehrere der für eine genaue Analyse erforderlichen Attribute, Felder oder Einträge fehlen. Diese fehlenden Informationen machen den gesamten Datensatz unzuverlässig und manchmal sogar unbrauchbar.
Häufige Ursachen für unvollständige Daten sind die absichtliche Auslassung bestimmter Daten, nicht erfasste Transaktionen, unvollständige Datenerfassung, Fehler bei der Dateneingabe, unsichtbare technische Probleme bei der Datenübertragung usw.
Betrachten wir beispielsweise eine Situation, in der in einer Kundenumfrage die Kontaktdaten fehlen. Dadurch ist es unmöglich, später mit den Befragten in Kontakt zu treten, wie unten dargestellt.

Ein weiteres Beispiel ist eine Krankenhausdatenbank mit Krankenakten von Patienten, in denen wichtige Informationen wie Allergien und Vorerkrankungen fehlen, was sogar zu lebensbedrohlichen Situationen führen kann.
Doppelte Daten
Doppelte Daten treten auf, wenn dieselbe Dateneingabe oder nahezu identische Dateneingaben mehrfach in der Datenbank gespeichert werden. Diese Redundanz führt zu irreführenden Analysen und falschen Schlussfolgerungen und erschwert manchmal Zusammenführungsvorgänge und verursacht Systemstörungen. Die aus einem Datensatz mit doppelten Daten abgeleiteten Statistiken werden für die Entscheidungsfindung unzuverlässig und ineffizient.
Beispiele:
- Eine CRM-Datenbank (Customer Relationship Management) mit mehreren Datensätzen für denselben Kunden kann die nach der Analyse abgeleiteten Informationen verzerren, wie z. B. die Anzahl der unterschiedlichen Kunden oder den Umsatz pro Kunde.
- Ein Bestandsverwaltungssystem, das dasselbe Produkt unter verschiedenen SKU-Nummern speichert, führt zu ungenauen Schätzungen der Lagerbestände.
Ungenaue Daten
Falsche, fehlerhafte Informationen in einem oder mehreren Datensätzen werden als ungenaue Daten identifiziert.
Ein einfacher Fehler in einem Code oder einer Zahl aufgrund eines Tippfehlers oder eines unbeabsichtigten Versehens kann schwerwiegende Komplikationen und Verluste verursachen, insbesondere wenn die Daten für Entscheidungen in einem Bereich mit hohem Risiko verwendet werden. Das Vorhandensein ungenauer Daten mindert die Vertrauenswürdigkeit und Zuverlässigkeit des gesamten Datensatzes.
Beispiele:
- Eine Datenbank einer Versandfirma, in der falsche Lieferadressen gespeichert sind, kann dazu führen, dass Pakete an falsche Orte oder sogar in falsche Länder verschickt werden, was sowohl für das Unternehmen als auch für den Kunden enorme Verluste und Verzögerungen zur Folge hat.
- Situationen, in denen ein Personalmanagementsystem (HRMS) falsche Informationen über die Gehälter von Mitarbeitern enthält, können zu Unstimmigkeiten bei der Gehaltsabrechnung und potenziellen rechtlichen Problemen führen.
Inkonsistente Daten
Inkonsistente Daten, die entstehen, wenn verschiedene Personen oder Teams innerhalb eines Unternehmens unterschiedliche Einheiten oder Formate für denselben Datentyp verwenden, sind eine häufige Ursache für Verwirrung und Ineffizienz bei der Arbeit mit Daten. Sie stören die Einheitlichkeit und den kontinuierlichen Fluss zwischen den Daten und führen zu fehlerhafter Datenverarbeitung.
Beispiele:
- Inkonsistente Datumsformate in mehreren Dateneinträgen (MM/TT/JJJJ vs. TT/MM/JJJJ), beispielsweise in einem Bankensystem, können zu Konflikten und Problemen bei der Datenaggregation und -analyse führen.
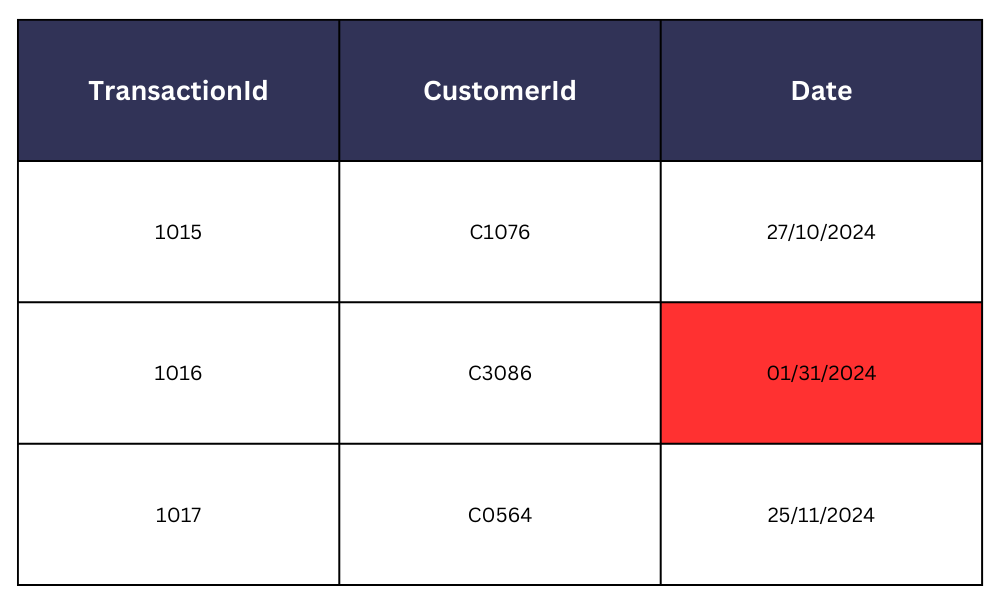
- Zwei Filialen derselben Einzelhandelskette, die Daten über Lagerbestände in unterschiedlichen Maßeinheiten eingeben (Anzahl der Kartons vs. Anzahl der einzelnen Artikel), können bei der Wiederauffüllung und Verteilung zu Verwirrung führen.
Veraltete Daten
Einfach ausgedrückt sind veraltete Daten Datensätze, die nicht mehr aktuell, relevant und anwendbar sind. Insbesondere in schnelllebigen Bereichen sind veraltete Daten aufgrund der raschen Veränderungen, die dort ständig stattfinden, recht häufig. Daten, die ein Jahrzehnt, ein Jahr oder sogar einen Monat alt sind, können je nach Kontext nicht mehr nützlich sein oder sogar irreführend sein.
Beispiele:
- Eine Person kann im Laufe der Zeit neue Allergien entwickeln. Ein Krankenhaus, das einem Patienten Medikamente verschreibt, dessen Allergieinformationen veraltet sind, kann die Sicherheit des Patienten gefährden.
- Eine Immobilienagentur, die Immobilien aus einer veralteten Datenquelle auflistet, kann Zeit und Mühe für bereits verkaufte oder nicht mehr verfügbare Immobilien verschwenden. Das ist unproduktiv und kann den Ruf des Unternehmens schädigen.
Darüber hinaus sind nicht konforme, irrelevante, unstrukturierte und verzerrte Daten ebenfalls Arten von schlechten Daten, die die Datenqualität in Ihrem Datenökosystem beeinträchtigen können. Das Verständnis dieser verschiedenen Arten von schlechten Daten ist unerlässlich, um ihre Ursachen und die Gefahren, die sie für Ihr Unternehmen darstellen, zu erkennen und Strategien zur Minderung der Auswirkungen zu entwickeln.
Was verursacht schlechte Daten?
Nachdem Sie nun ein klares Verständnis der Arten von schlechten Daten haben, ist es wichtig zu verstehen, was sie verursacht, damit Sie proaktive Maßnahmen ergreifen können, um solche Vorkommnisse in Ihren Datensätzen zu verhindern.
Zu den Ursachen für fehlerhafte Daten gehören unter anderem
- Menschliche Fehler bei der Dateneingabe: Es versteht sich von selbst, dass dies die häufigste Ursache für fehlerhafte Daten ist, insbesondere wenn es um unvollständige, ungenaue und doppelte Daten geht. Unzureichende Schulungen, mangelnde Aufmerksamkeit für Details, Missverständnisse über den Dateneingabeprozess und meist unbeabsichtigte Fehler wie Tippfehler können letztendlich zu unzuverlässigen Datensätzen und enormen Komplikationen bei der Analyse führen.
- Mangelhafte Praktiken und Standards bei der Dateneingabe: Ein solides Set an Standards ist der Schlüssel zum Aufbau solider und gut strukturierter Praktiken. Wenn Sie beispielsweise Freitexteingaben für ein Feld wie „Land“ zulassen, kann ein Benutzer unterschiedliche Bezeichnungen für dasselbe Land eingeben (Beispiel: USA, Vereinigte Staaten, U.S.A.), was zu einer ineffizienten Vielfalt von Antworten für denselben Wert führt. Solche Inkonsistenzen und Verwirrungen entstehen, wenn keine ordnungsgemäßen Standards festgelegt wurden.

- Migrationsprobleme: Schlechte Daten sind nicht immer das Ergebnis manueller Eingaben. Sie können auch durch die Migration von Daten von einer Datenbank in eine andere entstehen. Ein solches Problem führt zu einer Fehlausrichtung von Datensätzen und Feldern, Datenverlusten und sogar Datenbeschädigungen, deren Überprüfung und Behebung unter Umständen viele Stunden in Anspruch nehmen kann.
- Datenverfall: Jede kleine Änderung, von Kundenpräferenzen bis hin zu Verschiebungen der Markttrends, kann zu einer Aktualisierung der Unternehmensdaten führen. Wenn die Datenbank nicht ständig aktualisiert wird, um diesen Änderungen Rechnung zu tragen, werden die Daten veraltet und es kommt zu Datenverfall oder Datenverschlechterung. Veraltete Daten sind für die Entscheidungsfindung und Analyse nicht wirklich von Nutzen und führen bei ihrer Verwendung zu irreführenden Informationen.
- Zusammenführung von Daten aus mehreren Quellen: Eineineffiziente Zusammenführung von Daten aus mehreren Quellen oder eine fehlerhafte Datenintegration kann zu ungenauen und inkonsistenten Daten führen. Dies geschieht, wenn die verschiedenen Datenquellen, die zusammengeführt werden, unterschiedliche Standards, Formate und Qualitätsstufen aufweisen.
Auswirkungen schlechter Daten
Wenn Sie Datensätze mit schlechten Daten verarbeiten, gefährden Sie Ihre Endanalyse. Tatsächlich können schlechte Daten langfristige und verheerende Auswirkungen haben, insbesondere auf datengesteuerte Unternehmen und Bereiche, wie zum Beispiel:
- Eine schlechte Datenqualität kann Ihrem Unternehmen schaden, indem sie das Risiko erhöht, aufgrund irreführender Informationen falsche Entscheidungen zu treffen und Fehlinvestitionen zu tätigen.
- Fehlerhafte Daten verursachen erhebliche finanzielle Kosten, darunter verschwendete Ressourcen und entgangene Einnahmen. Die Beseitigung der Auswirkungen fehlerhafter Daten kann viel Geld und Zeit kosten.
- Die Anhäufung fehlerhafter Daten kann sogar zum Scheitern eines Unternehmens führen, da sie den Nachbearbeitungsaufwand erhöht, zu verpassten Chancen führt und sich negativ auf die Produktivität insgesamt auswirkt.
- Infolgedessen sinkt die Vertrauenswürdigkeit und Zuverlässigkeit des Unternehmens, was die Kundenzufriedenheit und -bindung erheblich beeinträchtigt. Ungenaue und unvollständige Daten seitens des Unternehmens führen zu schlechtem Kundenservice und inkonsistenter Kommunikation.
Darüber hinaus können fehlerhafte Daten zu kritischen Fehlern führen, die zu rechtlichen oder lebensbedrohlichen Komplikationen führen können, insbesondere im Finanz- und Gesundheitswesen.
So kam es beispielsweise im Jahr 2020 während der COVID-19-Pandemie bei Public Health England (PHE) zu einem schwerwiegenden Fehler im Datenmanagement, der dazu führte, dass 15.841 COVID-19-Fälle aufgrund fehlerhafter Daten nicht gemeldet wurden. Das Problem wurde auf die veraltete Version der von PHE verwendeten Excel-Tabellen zurückgeführt, die nur bis zu 65.000 Zeilen aufnehmen konnten, anstatt der über eine Million Zeilen, die sie tatsächlich aufnehmen konnten. Einige der Datensätze, die von den Drittfirmen zur Analyse der Abstrich-Tests bereitgestellt wurden, gingen verloren, was zu unvollständigen Daten führte. Die Zahl der aufgrund dieses technischen Fehlers übersehenen engen Kontakte mit Infektionsrisiko belief sich auf etwa 50.000.
Darüber hinaus führte ein Tippfehler von Samsung im Jahr 2018 dazu, dass die Aktienkurse innerhalb eines einzigen Tages um rund 11 % fielen und fast 300 Millionen US-Dollar an Marktwert verloren gingen. Verursacht wurde dies durch einen Mitarbeiter von Samsung Securities, der bei der Dateneingabe einen Fehler machte und statt 2,8 Milliarden „Südkoreanische Won” 2,8 Milliarden „Aktien” (im Wert von 105 Milliarden Dollar) eingab, die an die Mitarbeiter verteilt werden sollten, die am Aktienbeteiligungsprogramm des Unternehmens teilnahmen.
Daher sollten die Folgen fehlerhafter Daten nicht auf die leichte Schulter genommen werden, und es müssen geeignete Präventivmaßnahmen ergriffen werden, um das Risiko zu beseitigen.
Verhindern von fehlerhaften Daten
Kein Datensatz ist perfekt. Ihre Daten enthalten zwangsläufig Fehler. Der erste Schritt zur Vermeidung fehlerhafter Daten besteht darin, diese Tatsache anzuerkennen, damit Sie die notwendigen Präventionsstrategien zur Sicherstellung der Datenqualität umsetzen können.
Einige Maßnahmen zur Vermeidung fehlerhafter Daten sind:
- Die Implementierung einer robusten Datenverwaltung ist ein entscheidender Schritt zur Festlegung von Verantwortlichkeiten und Standards im gesamten Unternehmen. Sie kann Ihnen dabei helfen, klare Richtlinien und Verfahren für die Verwaltung, den Zugriff und die Pflege von Daten festzulegen, um das Risiko fehlerhafter Daten zu minimieren.
- Führen Sie regelmäßige Datenprüfungen durch, um Inkonsistenzen und veraltete Daten zu finden, bevor Komplikationen auftreten.
- Regulieren Sie die Dateneingabeprozesse, indem Sie Standards, Datenvalidierungsregeln sowie Standardformate und -vorlagen im gesamten Unternehmen festlegen, um menschliche Fehler zu minimieren.
- Gut informierte Mitarbeiter neigen dazu, bei der Datenverarbeitung und -verwaltung nur minimale Fehler zu machen. Daher sind regelmäßige Schulungen und Aktualisierungssitzungen erforderlich, um die Mitarbeiter über die Standardprozesse auf dem Laufenden zu halten.
- Sichern Sie Daten regelmäßig, um Datenverluste bei unvorhergesehenen Ereignissen zu vermeiden.
- Verwenden Sie speziell für die Datenvalidierung entwickelte fortschrittliche Tools, um die Konsistenz und Integrität Ihrer Daten sicherzustellen. Diese Tools können die Richtigkeit und Vollständigkeit Ihrer Daten bestätigen und potenzielle Fehler erkennen und korrigieren.
Zusammenfassung
In diesem Artikel wurde erläutert, was schlechte Daten sind, welche verschiedenen Arten von schlechten Daten auftreten können und was ihre Ursachen sind. Darüber hinaus wurden die erheblichen negativen Auswirkungen schlechter Daten auf ein datengesteuertes Unternehmen hervorgehoben, die von finanziellen Verlusten bis hin zu Geschäftsausfällen reichen können. Das Verständnis dieser Faktoren ist der erste Schritt zur Vermeidung schlechter Daten.
Auch wenn es mehrere Präventionsstrategien zur Sicherstellung der Datenqualität gibt, wird der Einsatz eines zuverlässigen, speziell für diesen Zweck entwickelten Tools Ihnen sicherlich Arbeit abnehmen.
Erwägen Sie den Einsatz von Data-Scraping-Tools, mit denen Sie automatisch zuverlässige und saubere Datensätze erstellen können. Dies erspart Ihnen Aufwand und liefert Ihnen saubere, direkt verwendbare Daten. Ein solches Tool ist die Web Scraper API von Bright Data. Sie möchten sich überhaupt nicht mit Scraping beschäftigen? Registrieren Sie sich jetzt und laden Sie unsere kostenlosen Datensatz-Beispiele herunter!





