

In diesem Blogbeitrag erfahren Sie mehr:
- Was Apify ist
- Warum die Verwendung von Scraping Browser mit Apify eine Win-Win-Situation ist
- So integrieren Sie den Scraping-Browser von Bright Data in ein Apify-Python-Skript
- So verwenden Sie Bright Data-Proxys auf Apify
Lasst uns eintauchen!
Was ist Apify?
Apify ist eine umfassende Plattform für Web Scraping und Datenextraktion. Sie ermöglicht es Ihnen, benutzerdefinierte Web-Scraping-Tools – bekannt als Actors – in derCloud zu erstellen und auszuführen. Diese Actors automatisieren Aufgaben im Zusammenhang mit der Datenerfassung, -verarbeitung und -automatisierung.
Auf Apify können Sie Ihre Scraping-Skripte monetarisieren, indem Sie sie veröffentlichen und anderen Nutzern zur Verfügung stellen. Ganz gleich, ob Sie Ihren Akteur privat nutzen oder veröffentlichen möchten, die Scraping-Lösungen von Bright Data helfen Ihnen, Ihren Scraper zuverlässiger und effektiver zu machen.
Warum den Scraping-Browser von Bright Data auf Apify verwenden?
Um den Wert des Scraping-Browsers von Bright Data zu schätzen, müssen Sie verstehen, was das Tool ist und was es bietet.
Die größte Einschränkung der Browser-Automatisierungstools liegt nicht in ihren APIs, sondern in den Browsern, die sie steuern. Scraping Browser ist ein Webbrowser der nächsten Generation, der speziell für Web Scraping entwickelt wurde. Er verfügt insbesondere über die folgenden Hauptfunktionen:
- Zuverlässige TLS-Fingerprints zur Vermeidung von Entdeckung
- Unbegrenzte Skalierbarkeit für die Extraktion großer Datenmengen
- Integrierte IP-Rotation, die von einem 150-Millionen-IP-Proxy-Netzwerk unterstützt wird
- Automatische Wiederholungsversuche für fehlgeschlagene Anfragen
- CAPTCHA-Lösungsmöglichkeiten
Scraping Browser ist mit allen wichtigen Browser-Automatisierungs-Frameworks kompatibel – einschließlich Playwright, Puppeteer und Selenium. Sie müssen also keine neue API erlernen oder Abhängigkeiten von Drittanbietern installieren. Sie können es einfach direkt in Ihr bestehendes Skript zur Browser-Automatisierung integrieren.
Die Verwendung von Scraping Browser mit Apify bringt jetzt noch mehr Vorteile mit sich, die sich wie folgt zusammenfassen lassen
- Geringere Cloud-Kosten: Browser verbrauchen erhebliche Ressourcen, was zu einer höheren CPU- und RAM-Auslastung führt. Scraping Browser, gehostet in der Cloud mit garantierter unbegrenzter Skalierbarkeit, reduziert die Cloud-Kosten, während der Schauspieler auf Apify läuft. Da Apify nach Server-Nutzung abrechnet, kann dieses Setup zu Kosteneinsparungen führen, selbst wenn man die Gebühren für Scraping Browser berücksichtigt.
- Alles in einem Anti-Bot-Umgehungstool: Scraping Browser umgeht IP-Sperren, CAPTCHA-Herausforderungen, Browser-Fingerprint-Probleme und andere Anti-Scraping-Barrieren. Das macht Ihren Scraping-Prozess effizienter und weniger anfällig für Störungen.
- Integrierte Proxy-Integration: Scraping Browser enthält eine Proxy-Verwaltung, so dass Sie sich nicht mehr um die Pflege und manuelle Rotation von Proxys kümmern müssen.
- Apify Vorteile: Die Verwendung des Scraping Browsers auf einem Cloud-Actor von Apify (anstelle eines generischen Skripts) bietet zusätzliche Vorteile, wie z. B.
: Polylang-Platzhalter nicht ändern
Die Integration von Bright Data und Apify vereinfacht nicht nur Ihren Scraping-Workflow, sondern verbessert auch die Zuverlässigkeit. Sie reduziert auch den Zeit- und Arbeitsaufwand, der erforderlich ist, um Ihren Web-Scraping-Bot online zu bringen.
So integrieren Sie den Scraping-Browser von Bright Data in Apify: Schritt-für-Schritt-Anleitung
Die Zielseite für diesen Abschnitt ist Amazon, eine Plattform, die reich an Informationen ist, aber für ihre strengen Anti-Bot-Maßnahmen berüchtigt ist. Ohne die richtigen Tools werden Sie wahrscheinlich auf das berüchtigte Amazon CAPTCHA stoßen, das Ihre Scraping-Versuche blockiert:

In diesem Abschnitt wird ein Scraping-Actor erstellt, der den Scraping-Browser von Bright Data nutzt, um Daten aus einer generischen Amazon-Produktsuchseite zu extrahieren:

Hinweis: Der Actor wird in Python geschrieben, aber denken Sie daran, dass Apify auch JavaScript unterstützt.
Folgen Sie den nachstehenden Schritten, um zu erfahren, wie Sie die Scraping-Tools von Bright Data in Apify! integrieren.
Voraussetzungen
Um diesem Tutorial folgen zu können, müssen Sie die folgenden Voraussetzungen erfüllen:
- Python 3.8+ lokal installiert: Für die Entwicklung und Erstellung des lokalen Actor-Skripts.
- Node.js lokal installiert: Für die Installation der Apify CLI.
- Ein Apify-Konto: Um den lokalen Akteur auf der Apify-Plattform einzusetzen.
- Ein Bright Data-Konto: So greifen Sie auf den Scraping-Browser zu.
Schritt 1: Projekt einrichten
Der einfachste Weg, ein neues Apify Actor-Projekt einzurichten, ist die Verwendung des Apify CLI. Installieren Sie es zunächst global über Node.js mit dem folgenden Befehl:
npm install -g apify-cliErstellen Sie dann ein neues Apify-Projekt, indem Sie es ausführen:
npx apify-cli createSie werden aufgefordert, ein paar Fragen zu beantworten. Beantworten Sie diese wie folgt:
✔ Name of your new Actor: amazon-scraper
✔ Choose the programming language of your new Actor: Python
✔ Choose a template for your new Actor. Detailed information about the template will be shown in the next step.
Playwright + ChromeAuf diese Weise erstellt das Apify CLI einen neuen Python-Aktor im Ordner amazon-scraper unter Verwendung der Vorlage “Playwright + Chrome”. Wenn Sie mit diesen Tools nicht vertraut sind, lesen Sie unseren Leitfaden zu Playwright Web Scraping.
Hinweis: Eine Selenium- oder Puppeteer-Vorlage würde ebenfalls funktionieren, da der Scraping Browser von Bright Data mit jedem Browser-Automatisierungstool integriert werden kann.
Ihr Apify Actor Projekt hat die folgende Struktur:
amazon-scraper
│── .dockerignore
│── .gitignore
│── README.md
│── requirements.txt
│
├── .venv/
│ └── ...
│
├── .actor/
│ │── actor.json
│ │── Dockerfile
│ └── input_schema.json
│
├── src/
│ │── main.py
│ │── __init__.py
│ │── __main__.py
│ └── py.typed
│
└── storage/
└── ...Laden Sie den Ordner amazon-scraper in Ihre bevorzugte Python-IDE, z. B. Visual Studio Code mit der Python-Erweiterung oder PyCharm Community Edition.
Um den Actor lokal auszuführen, müssen die Browser von Playwright installiert sein. Aktivieren Sie dazu zunächst den Ordner der virtuellen Umgebung (.venv) in Ihrem Projektverzeichnis. Unter Windows führen Sie aus:
.venv/Scripts/activateUnter Linux/macOS starten Sie entsprechend:
source .venv/bin/activateInstallieren Sie dann die erforderlichen Playwright-Abhängigkeiten, indem Sie den Befehl ausführen:
playwright install --with-depsWunderbar! Sie können Ihren Actor jetzt lokal mit ausführen:
apify runIhr Apify-Projekt ist nun vollständig eingerichtet und bereit für die Integration mit dem Scraping-Browser von Bright Data!
Schritt #2: Verbinden Sie sich mit der Zielseite
Wenn Sie sich die URL einer Amazon-Suchergebnisseite ansehen, werden Sie feststellen, dass sie diesem Format folgt:
https://www.amazon.com/search/s?k=<keyword>Zum Beispiel:

Die Ziel-URL Ihres Skripts sollte dieses Format verwenden, wobei dynamisch mit einem Apify-Eingangsargument gesetzt werden kann. Die Eingabeparameter, die ein Actor akzeptiert, sind in der Datei input_schema.json definiert, die sich im Verzeichnis .actor befindet.
Durch die Definition des Schlüsselwortarguments wird das Skript anpassbar, so dass die Benutzer den von ihnen bevorzugten Suchbegriff angeben können. Um diesen Parameter zu definieren, ersetzen Sie den Inhalt von input_schema.json durch den folgenden:
{
"title": "Amazon Scraper",
"type": "object",
"schemaVersion": 1,
"properties": {
"keyword": {
"title": "Search keyword",
"type": "string",
"description": "The keyword used to search products on Amazon",
"editor": "textfield"
}
},
"required": ["keyword"]
}Diese Konfiguration definiert einen erforderlichen Schlüsselwortparameter vom Typ string.
Um das Schlüsselwort-Argument zu setzen, wenn der Actor lokal ausgeführt wird, ändern Sie die Datei INPUT.json in storage/key_value_stores/default wie folgt:
{
"keyword": "laptop"
}Auf diese Weise liest der Akteur das Schlüsselwort-Eingabeargument und verwendet "laptop" als Suchbegriff.
Sobald der Actor auf der Apify-Plattform bereitgestellt wurde, sehen Sie ein Eingabefeld, in dem Sie diesen Parameter anpassen können, bevor Sie den Actor ausführen:

Denken Sie daran, dass die Eingangsdatei eines Apify-Actors main.py ist, die sich im src-Ordner befindet. Öffnen Sie diese Datei und ändern Sie sie zu:
- Lesen der Schlüsselwortparameter aus den Eingabeargumenten
- Konstruieren Sie die Ziel-URL für die Amazon-Suchseite
- Verwenden Sie Playwright, um zu dieser Seite zu navigieren
Am Ende dieses Schrittes sollte Ihre Datei main.py die folgende Python-Logik enthalten:
from apify import Actor
from playwright.async_api import async_playwright
async def main() -> None:
# Enter the context of the Actor
async with Actor:
# Retrieve the Actor input, and use default values if not provided
actor_input = await Actor.get_input() or {}
# Reading the "keyword" argument from the input data, assigning it the
# value "laptop" as a default value
keyword = actor_input.get("keyword")
# Building the target url
target_url = f"https://www.amazon.com/search/s?k={keyword}"
# Launch Playwright and open a new browser context
async with async_playwright() as playwright:
# Configure the browser to launch in headless mode as per Actor configuration
browser = await playwright.chromium.launch(
headless=Actor.config.headless,
args=["--disable-gpu"],
)
context = await browser.new_context()
try:
# Open a new page in the browser context and navigate to the URL
page = await context.new_page()
await page.goto(target_url)
# Scraping logic...
except Exception:
Actor.log.exception(f"Cannot extract data from {target_url}")
finally:
await page.close()Der obige Code:
- Initialisiert einen
Apify-Actorzur Verwaltung des Skript-Lebenszyklus - Abrufen von Eingabeargumenten mit
Actor.get_input() - Extrahiert das
Schlüsselwortargumentaus den Eingabedaten - Konstruiert die Ziel-URL unter Verwendung einer Python f-Zeichenkette
- Startet Playwright und einen Chromium-Browser ohne Grafikkarte mit deaktivierter GPU
- Erstellt einen neuen Browserkontext, öffnet eine Seite und navigiert mit
page.goto()zur Ziel-URL - Protokolliert alle Fehler mit
Actor.log.exception() - Stellt sicher, dass die Playwright-Seite nach der Ausführung geschlossen wird
Perfekt! Ihr Apify Actor ist bereit, den Scraping Browser von Bright Data für effizientes Web-Scraping zu nutzen.
Schritt Nr. 3: Integrieren Sie den Scraping-Browser von Bright Data
Verwenden Sie nun die Playwright-API, um nach der Verbindung mit der Zielseite einen Screenshot zu erstellen:
await page.screenshot(path="screenshot.png")Führen Sie Ihren Actor lokal aus, und es wird eine screenshot.png-Datei im Projektordner erzeugt. Wenn Sie diese Datei öffnen, sehen Sie wahrscheinlich etwas wie das hier:

In ähnlicher Weise können Sie die folgende Amazon-Fehlerseite erhalten:

Wie Sie sehen können, wurde Ihr Web-Scraping-Bot durch Amazons Anti-Bot-Maßnahmen blockiert. Dies ist nur eine von vielen Herausforderungen, denen Sie beim Scraping von Amazon oder anderen beliebten Websites begegnen können.
Vergessen Sie diese Herausforderungen, indem Sie den Scraping Browser von Bright Dataverwenden – eineCloud-basierte Scraping-Lösung, die unbegrenzte Skalierbarkeit, automatische IP-Rotation, CAPTCHA-Auflösung und Anti-Scraping-Bypass bietet.
Um loszulegen, erstellen Sie ein Bright Data-Konto, falls Sie dies noch nicht getan haben. Melden Sie sich dann bei der Plattform an. Klicken Sie im Abschnitt “User Dashboard” auf die Schaltfläche “Get proxy products”:

Wählen Sie in der Tabelle “Meine Zonen” auf der Seite “Proxies & Scraping-Infrastruktur” die Zeile “scraping_browser”:

Aktivieren Sie das Produkt, indem Sie den Ein/Aus-Schalter betätigen:

Vergewissern Sie sich nun auf der Registerkarte “Konfiguration”, dass die Optionen “Premium-Domains” und “CAPTCHA Solver” aktiviert sind, um maximale Wirksamkeit zu erzielen:

Kopieren Sie auf der Registerkarte “Übersicht” die Verbindungszeichenfolge für den Playwright Scraping Browser:
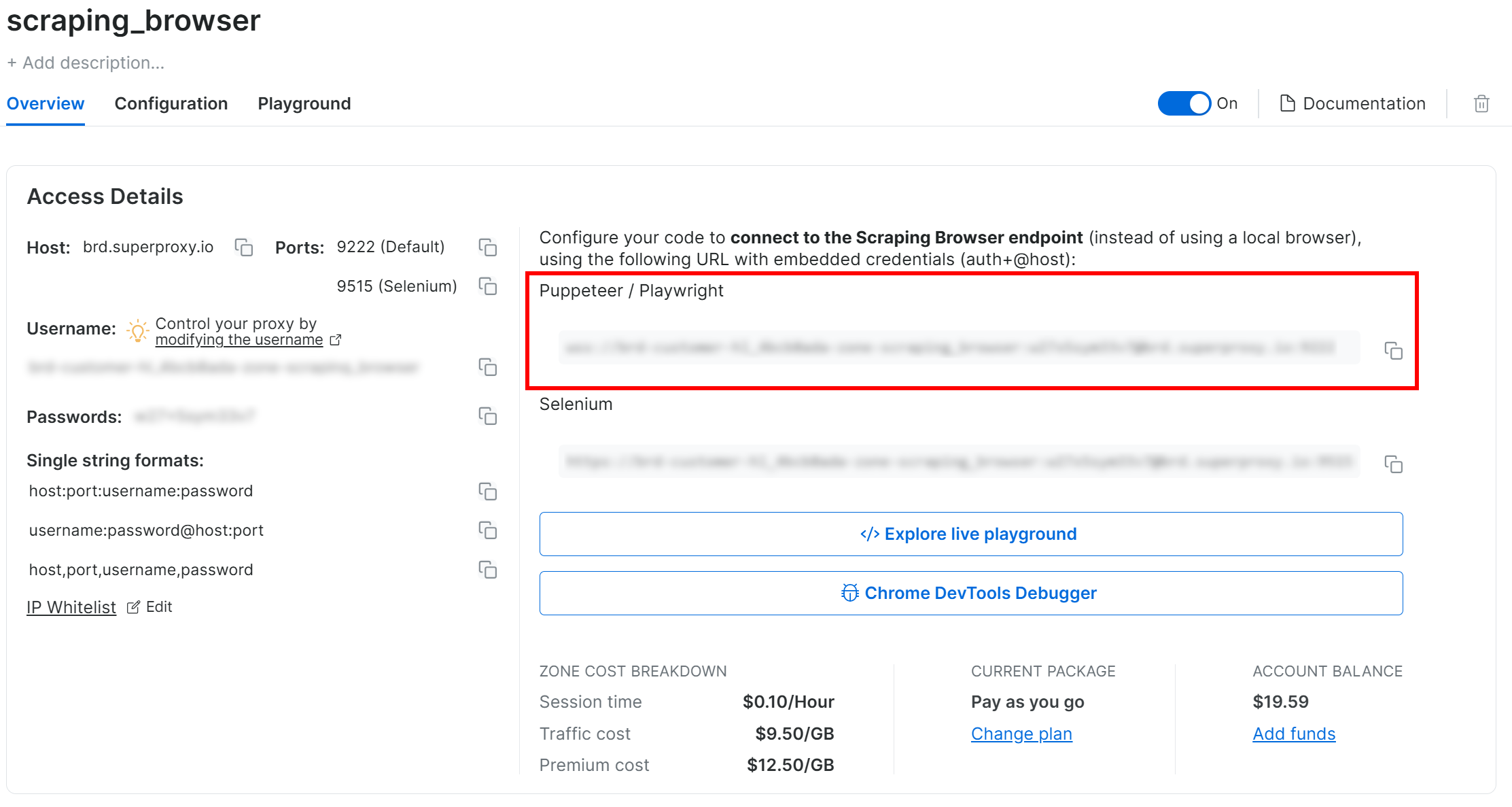
Fügen Sie die Verbindungszeichenfolge als Konstante in Ihre Datei main.py ein:
SBR_WS_CDP = "<YOUR_PLAYWRIGHT_SCRAPING_BROWSER_CONNECTION_STRING>"Ersetzen Sie durch die Verbindungszeichenfolge, die Sie zuvor kopiert haben.
Hinweis: Wenn Sie planen, Ihren Actor auf Apify zu veröffentlichen, sollten Sie SBR_WS_CDP als ein Apify Actor-Eingabeargument definieren. Auf diese Weise können Benutzer, die Ihren Actor übernehmen, ihre eigenen Scraping-Browser-Verbindungszeichenfolgen integrieren.
Aktualisieren Sie nun die Browser-Definition in main.py, um Scraping Browser mit Playwright zu verwenden:
browser = await playwright.chromium.connect_over_cdp(SBR_WS_CDP, timeout=120000)Beachten Sie, dass die Verbindungszeitüberschreitung auf einen höheren Wert als üblich eingestellt werden sollte, da die IP-Rotation durch Proxys und die CAPTCHA-Auflösung einige Zeit in Anspruch nehmen kann.
Geschafft! Sie haben Scraping Browser erfolgreich in Playwright innerhalb eines Apify Actors integriert.
Schritt #4: Bereiten Sie das Scrapen aller Produktauflistungen vor
Um Produktlisten von Amazon zu scrapen, müssen Sie zunächst die Seite untersuchen, um ihre HTML-Struktur zu verstehen. Klicken Sie dazu mit der rechten Maustaste auf eines der Produktelemente auf der Seite und wählen Sie die Option “Inspizieren”. Der folgende DevTools-Abschnitt wird angezeigt:

Hier können Sie sehen, dass jedes Element der Produktliste mit diesem CSS-Selektor ausgewählt werden kann:
[data-component-type=\"s-search-result\"]Die Ausrichtung auf benutzerdefinierte data-*-Attribute ist ideal, da diese Attribute in der Regel für Tests oder Überwachung verwendet werden. Daher bleiben sie in der Regel im Laufe der Zeit konsistent.
Verwenden Sie nun einen Playwright-Locator, um alle Produktelemente auf der Seite abzurufen:
product_elements = page.locator("[data-component-type=\"s-search-result\"]")Als Nächstes iterieren Sie über die Produktelemente und bereiten die Extraktion von Daten aus ihnen vor:
for product_element in await product_elements.all():
# Data extraction logic...Erstaunlich! Zeit für die Implementierung der Amazon-Datenextraktionslogik.
Schritt Nr. 5: Implementierung der Scraping-Logik
Prüfen Sie zunächst ein einzelnes Element der Produktliste:

In diesem Abschnitt können Sie das Produktbild aus dem src-Attribut des Elements .s-image abrufen:
image_element = product_element.locator(".s-image").nth(0)
image = await image_element.get_attribute("src")Beachten Sie, dass nth(0) erforderlich ist, um das erste HTML-Element zu erhalten, das dem Locator entspricht.
Prüfen Sie als Nächstes den Produkttitel:

Sie können die Produkt-URL und den Titel aus den Feldern und
Elementen innerhalb des Elements [data-cy="title-recipe"] entnehmen:
title_header_element = product_element.locator("[data-cy=\"title-recipe\"]").nth(0)
link_element = title_header_element.locator("a").nth(0)
url = None if url_text == "javascript:void(0)" else "https://amazon.com" + url_text
title_element = title_header_element.locator("h2").nth(0)
title = await title_element.get_attribute("aria-label")
title_header_element = product_element.locator("[data-cy=\"title-recipe\"]").nth(0)
link_element = title_header_element.locator("a").nth(0)
url = None if url_text == "javascript:void(0)" else "https://amazon.com" + url_text
title_element = title_header_element.locator("h2").nth(0)
title = await title_element.get_attribute("aria-label")Beachten Sie die Logik, mit der “javascript:void(0)” ignoriert wird. URLs (die bei speziellen Anzeigenprodukten erscheinen) und die Umwandlung der Produkt-URLs in absolute URLs.
Schauen Sie sich dann den Abschnitt mit den Bewertungen an:

Aus [data-cy="reviews-block"] können Sie die Bewertung der Rezension aus dem aria-label des Elements ablesen:
rating_element = product_element.locator("[data-cy=\"reviews-block\"] a").nth(0)
rating_text = await rating_element.get_attribute("aria-label")
rating_match = re.search(r"(\d+(\.\d+)?) out of 5 stars", rating_text)
if rating_match:
rating = rating_match.group(1)
else:
rating = NoneDa der Bewertungstext in aria-label im Format “X von 5 Sternen” vorliegt, können Sie den Bewertungswert X mit einer einfachen Regex extrahieren. Siehe , wie man Regex für Web Scraping verwendet.
Vergessen Sie nicht, re aus der Python-Standardbibliothek zu importieren:
import reUntersuchen Sie nun das Element “Anzahl der Bewertungen”:

Extrahieren Sie die Anzahl der Bewertungen aus dem Element innerhalb von [data-component-type="s-client-side-analytics"]:
review_count_element = product_element.locator("[data-component-type=\"s-client-side-analytics\"] a").nth(0)
review_count_text = await review_count_element.text_content()
review_count = int(review_count_text.replace(",", ""))Beachten Sie die einfache Logik zur Umwandlung einer Zeichenkette wie “2.539” in einen numerischen Wert in Python.
Prüfen Sie schließlich den Produktpreisknoten:

Erfassen Sie den Produktpreis aus dem Element .a-offscreen innerhalb von [data-cy="price-recipe"]:
price_element_locator = product_element.locator("[data-cy=\"price-recipe\"] .a-offscreen")
# If the price element is on the product element
if await price_element_locator.count() > 0:
price = await price_element_locator.nth(0).text_content()
else:
price = NoneDa nicht alle Produkte ein Preiselement haben, sollten Sie dieses Szenario behandeln, indem Sie die Anzahl der Preiselemente überprüfen, bevor Sie versuchen, ihren Wert abzurufen.
Damit das Skript funktioniert, aktualisieren Sie den Playwright-Import mit:
from playwright.async_api import async_playwright, TimeoutErrorWunderbar! Die Logik für das Scraping von Amazon-Produktdaten ist abgeschlossen.
Beachten Sie, dass es nicht das Ziel dieses Artikels ist, tief in die Scraping-Logik von Amazon einzutauchen. Weitere Anleitungen finden Sie in unserer Anleitung zum Scrapen von Amazon-Produktdaten in Python.
Schritt #6: Sammeln der gescrapten Daten
Als letzte Anweisung der for-Schleife füllen Sie ein Produktobjekt mit den gescrapten Daten:
product = {
"image": image,
"url": url,
"title": title,
"rating": rating,
"review_count": review_count,
"price": price
}Übertragen Sie sie dann in das Apify-Dataset:
await Actor.push_data(product)push_data() garantiert, dass die gescrapten Daten bei Apify registriert werden, so dass Sie über die API darauf zugreifen oder sie in einem der vielen unterstützten Formate (z. B. CSV, JSON, Excel, JSONL usw.) exportieren können.
Schritt #7: Alles zusammenfügen
Dies sollte Ihre endgültige Apify + Bright Data Actor main.py enthalten:
from apify import Actor
from playwright.async_api import async_playwright, TimeoutError
import re
async def main() -> None:
# Enter the context of the Actor
async with Actor:
# Retrieve the Actor input, and use default values if not provided
actor_input = await Actor.get_input() or {}
# Reading the "keyword" argument from the input data, assigning it the
# value "laptop" as a default value
keyword = actor_input.get("keyword")
# Building the target url
target_url = f"https://www.amazon.com/search/s?k={keyword}"
# Launch Playwright and open a new browser context
async with async_playwright() as playwright:
# Your Bright Data Scraping API connection string
SBR_WS_CDP = "wss://brd-customer-hl_4bcb8ada-zone-scraping_browser:[email protected]:9222"
# Configure Playwright to connect to Scraping Browser and open a new context
browser = await playwright.chromium.connect_over_cdp(SBR_WS_CDP, timeout=120000)
context = await browser.new_context()
try:
# Open a new page in the browser context and navigate to the URL
page = await context.new_page()
await page.goto(target_url)
# Use a locator to select all product elements
product_elements = page.locator("[data-component-type=\"s-search-result\"]")
# Iterate over all product elements and scrape data from them
for product_element in await product_elements.all():
# Product scraping logic
image_element = product_element.locator(".s-image").nth(0)
image = await image_element.get_attribute("src")
title_header_element = product_element.locator("[data-cy=\"title-recipe\"]").nth(0)
link_element = title_header_element.locator("a").nth(0)
url_text = await link_element.get_attribute("href")
url = None if url_text == "javascript:void(0)" else "https://amazon.com" + url_text
title_element = title_header_element.locator("h2").nth(0)
title = await title_element.get_attribute("aria-label")
rating_element = product_element.locator("[data-cy=\"reviews-block\"] a").nth(0)
rating_text = await rating_element.get_attribute("aria-label")
rating_match = re.search(r"(\d+(\.\d+)?) out of 5 stars", rating_text)
if rating_match:
rating = rating_match.group(1)
else:
rating = None
review_count_element = product_element.locator("[data-component-type=\"s-client-side-analytics\"] a").nth(0)
review_count_text = await review_count_element.text_content()
review_count = int(review_count_text.replace(",", ""))
price_element_locator = product_element.locator("[data-cy=\"price-recipe\"] .a-offscreen")
# If the price element is on the product element
if await price_element_locator.count() > 0:
price = await price_element_locator.nth(0).text_content()
else:
price = None
# Populate a new dictionary with the scraped data
product = {
"image": image,
"url": url,
"title": title,
"rating": rating,
"review_count": review_count,
"price": price
}
# Add it to the Actor dataset
await Actor.push_data(product)
except Exception:
Actor.log.exception(f"Cannot extract data from {target_url}")
finally:
await page.close()Wie Sie sehen, ist die Integration des Scraping-Browsers von Bright Data mit der Apify-Vorlage “Playwright + Chrome” einfach und erfordert nur wenige Zeilen Code.
Schritt #8: Bereitstellen auf Apify und Ausführen des Actors
Um Ihren lokalen Actor in Apify einzusetzen, führen Sie den folgenden Befehl in Ihrem Projektordner aus:
apify pushWenn Sie sich noch nicht angemeldet haben, werden Sie aufgefordert, sich über die Apify CLI zu authentifizieren.
Sobald die Bereitstellung abgeschlossen ist, wird Ihnen die folgende Frage gestellt:
✔ Do you want to open the Actor detail in your browser?Antworten Sie mit “J” oder “Ja”, um zur Akteur-Seite in Ihrer Apify-Konsole weitergeleitet zu werden:

Wenn Sie es vorziehen, können Sie die gleiche Seite auch manuell aufrufen:
- Anmeldung bei Apify in Ihrem Browser
- Navigieren zur Konsole
- Besuch der Seite “Schauspieler”.
Klicken Sie auf die Schaltfläche “Start Actor”, um Ihren Amazon Scraper Actor zu starten. Wie erwartet, werden Sie aufgefordert, ein Schlüsselwort einzugeben. Versuchen Sie etwas wie “Gaming Chair”:

Klicken Sie anschließend auf “Speichern & Starten”, um den Akteur auszuführen und “Gaming Chair”-Produktangebote von Amazon zu scrapen.
Sobald das Scraping abgeschlossen ist, sehen Sie die abgerufenen Daten im Abschnitt Ausgabe:

Um die Daten zu exportieren, gehen Sie auf die Registerkarte “Speicher”, wählen Sie die Option “CSV” und klicken Sie auf die Schaltfläche “Herunterladen”:

Die heruntergeladene CSV-Datei enthält die folgenden Daten:

Et voilà! Der Scraping-Browser von Bright Data und die Apify-Integration funktionieren wie ein Zauber. Keine CAPTCHAs oder Sperren mehr beim Scraping von Amazon oder einer anderen Website.
[Extra] Integration von Bright Data Proxy in Apify
Die Verwendung eines Scraping-Produkts wie Scraping Browser oder Web Unlocker direkt auf Apify ist nützlich und einfach.
Nehmen wir an, Sie haben bereits einen Actor auf Apify und müssen ihn nur mit Proxies erweitern (z. B. um IP-Sperren zu vermeiden). Denken Sie daran, dass Sie Bright Data-Proxys direkt in Ihren Apify-Actor integrieren können, wie in unserer Dokumentation oder Integrationsanleitung beschrieben.
Schlussfolgerung
In diesem Tutorial haben Sie gelernt, wie Sie einen Apify-Actor erstellen, der mit dem Scraping Browser in Playwright integriert wird, um programmatisch Daten von Amazon zu sammeln. Wir haben bei Null angefangen und sind alle Schritte durchgegangen, um ein lokales Scraping-Skript zu erstellen und es dann in Apify bereitzustellen.
Jetzt verstehen Sie die Vorteile der Verwendung eines professionellen Scraping-Tools wie Scraping Browser für Ihr Cloud Scraping auf Apify. Nach den gleichen oder ähnlichen Verfahren unterstützt Apify alle anderen Bright Data-Produkte:
- Proxy-Dienste: 4 verschiedene Arten von Proxys zur Umgehung von Standortbeschränkungen, einschließlich mehr als 150 Millionen privater IPs
- Web Scraper APIs: Spezielle Endpunkte zum Extrahieren von frischen, strukturierten Webdaten aus über 100 beliebten Domains.
- SERP-API: API zur Verwaltung aller laufenden Freischaltungen für SERP und Extraktion einer Seite
Melden Sie sich jetzt bei Bright Data an und testen Sie unsere interoperablen Proxy-Dienste und Scraping-Produkte kostenlos!
Keine Kreditkarte erforderlich


